Good. Bad. You’re the Guy With the Gun this GFN Thursday. Get ready for some horrifyingly good fun with Evil Dead: The Game streaming on GeForce NOW tomorrow at release. It’s the 1,300th game to join GeForce NOW, joining on Friday the 13th. And it’s part of eight total games joining the GeForce NOW library Read article >
I’m currently an intern trying to wrap Face-api.js as a component, my problem is – and I think I know too little about to fully understand – the models.
I was wondering if there are other ways to save and load (already feeded) models, other than using script tags. I need to be looking into it to get a better performance rate, but I honestly don’t know if this is even a possibility.
I am migrating from a laptop with a RTX 3080 mobile to a desktop with a RTX3080 Ti. I am using the Tensorflow Docker image from the NGC Catalog (tensorflow:22.03-tf2-py3) in both instances and the same code/dataset. The laptop was running Pop OS 20.04 LTS and the desktop Ubuntu 20.04 LTS, basically the same setup.
The laptop took about 2 seconds per epoch (can’t re test again because I have to turn in the device, but epoch time is stored in the Jupiter notebook) while the desktop (with better a GPU) takes between 4 to 5 seconds. I already re-installed drivers and the whole docker engine with no luck. Currently while checking nvidia-smi gpu usage is only about 30%.
Does anyone has encountered a problem like this? Thanks.
A30 enables researchers, engineers, and data scientists to deliver real-world results and deploy solutions into production at scale.
NVIDIA A30 GPU is built on the latest NVIDIA Ampere Architecture to accelerate diverse workloads like AI inference at scale, enterprise training, and HPC applications for mainstream servers in data centers. The A30 PCIe card combines the third-generation Tensor Cores with large HBM2 memory (24 GB) and fast GPU memory bandwidth (933 GB/s) in a low-power envelope (maximum 165 W).
A30 supports a broad range of math precisions:
double-precision (FP64)
single-precision (FP32)
half-precision (FP16)
Brain Float 16 (BF16)
Integer (INT8)
It also supports innovations such as Tensor Float 32 (TF32) and Tensor Core FP64, providing a single accelerator to speed up every workload.
Figure 1 shows TF32, which has the range of FP32 and precision of FP16. TF32 is the default option in PyTorch, TensorFlow, and MXNet, so no code change is needed to achieve speedup over the last-generation NVIDIA Volta Architecture.
Figure 1. TF32 and other precisions in bit numbers
Another important feature of A30 is Multi-Instance GPU (MIG) capability. MIG can maximize the GPU utilization across big to small workloads and ensure quality of service (QoS). A single A30 can be partitioned to up to four MIG instances to run four applications simultaneously, each fully isolated with its own streaming multiprocessors (SMs), memory, L2 cache, DRAM bandwidth, and decoder. For more information, see Supported MIG Profiles.
For interconnection, A30 supports both PCIe Gen4 (64 GB/s) and the high-speed third-generation NVLink (maximum 200 GB/s). Each A30 can support one NVLink bridge connection with a single adjacent A30 card. Wherever an adjacent pair of A30 cards exists in the server, the pair should be connected by the NVLink bridge that spans two PCIe slots for best bridging performance and balanced bridge topology.
NVIDIA T4
NVIDIA A30
Design
Small Footprint Data Center& Edge Inference
AI Inference & Mainstream Compute
Form Factor
x16 PCIe Gen3 1 slot LP
x16 PCIe Gen4 2 Slot FHFL 1 NVLink bridge
Memory
16GB GDDR6
24GB HBM2
Memory Bandwidth
320 GB/s
933 GB/s
Multi-Instance GPU
Up to 4
Media Acceleration
1 Video Encoder 2 Video Decoder
1 JPEG Decoder 4 Video Decoder
Fast FP64
No
Yes
Ray Tracing
Yes
No
Power
70W
165W
Table 1. Summary of the features of A30 and T4
In addition to the hardware benefits summarized in Table 1, A30 can achieve higher performance per dollar compared to the T4 GPU. A30 also supports end-to-end software stack solutions:
Libraries
GPU-accelerated deep learning frameworks like PyTorch, TensorFlow, and MXNet
Optimized deep learning models
Over 2,000 HPC and AI applications, which can be obtained from NGC containers
Performance analysis
To analyze the performance improvement of A30 over T4, and CPUs, we benchmarked six models from MLPerf Inference v1.1 with the datasets:
ResNet-50 v1.5 (ImageNet)
SSD-Large ResNet-34 (COCO)
3D-Unet (BraTS 2019)
DLRM (1TB Click Logs, offline scenario)
BERT (SQuAD v1.1, seq-len: 384)
RNN-T (LibriSpeech)
The MLPerf benchmark suite covers a broad range of inference use cases, from image classification and object detection to recommenders, and natural language processing (NLP).
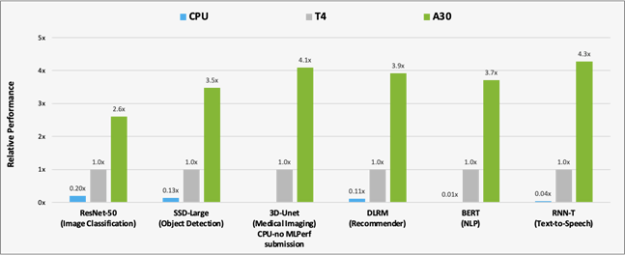
Figure 2 shows the results of the performance comparison of A30 with T4 and CPU on AI inference workloads.A30 is around 300x faster than a CPU for BERT inference.
Compared to T4, A30 delivers around 3-4x performance speedup for inference using the six models. The performance speedup is due to A30 larger memory size. This enables larger batch size for the models and faster GPU memory bandwidth (almost 3x T4), which can send the data to compute cores in a much shorter time.
Figure 2. Performance comparison of A30 over T4 and CPU using MLPerf. CPU: 8380H (no submission on 3D-Unet)
In addition to AI inference, A30 can rapidly pre-train AI models such as BERT Large with TF32, as well as accelerate HPC applications using FP64 Tensor Cores. A30 Tensor Cores with TF32 provide up to 10x higher performance over the T4 without requiring any changes in your code. They also provide an additional 2x boost with automatic mixed precision, delivering a combined 20x throughput increase.
Hardware decoders
While building a video analytics or video processing pipeline, there are several operations that must be considered:
Compute requirements for your model or preprocessing steps. This comes down to the Tensor Cores, GPU DRAM, and other hardware components that accelerate the models or frame preprocessing kernels.
Video stream encoding before transmission. This is done to minimize the bandwidth required on the network. To accelerate this workload, make use of NVIDIA hardware decoders.
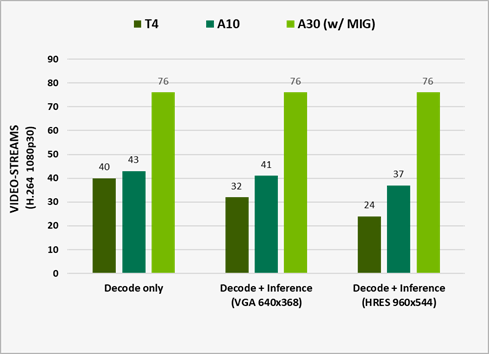
Figure 3. The number of streams being processed on different GPUs
Measured performance with DeepStream 5.1. It represents e2e performance with video capture and decode, preprocessing, batching, inference, and post-processing. Output rendering was turned off for optimal perf running ResNet10, ResNet18, and ResNet50 networks for inference on H.264 1080p30 video-streams.
A30 is designed to accelerate intelligent video analysis (IVA) by providing four video decoders, one JPEG decoder, and one optical flow decoder.
Representing the most powerful end-to-end AI and HPC platform for data centers, A30 enables researchers, engineers, and data scientists to deliver real-world results and deploy solutions into production at scale. For more information, see the NVIDIA A30 Tensor Core GPU datasheet and NVIDIA A30 GPU Accelerator product brief.
Surface clearing is a widely used accessory operation. This post covers best practices for clears on NVIDIA GPUs.
This post covers best practices for clears on NVIDIA GPUs. To get a high and consistent frame rate in your applications, see all Advanced API Performance tips.
Surface clearing is a widely used accessory operation.
Recommended
Use clear functions from the graphics API to clear resources.
Use any clear color to clear render targets.
Hardware optimizations improves the most clear operations.
Use a suitable clear value when clearing the depth buffer.
Prefer clear values within the range [0.0, 0.5) when using depth test functions D3D12_COMPARISON_FUNC_GREATER or D3D12_COMPARISON_FUNC_GREATER_EQUAL
Prefer clear values within the range [0.5, 1.0] when using depth test functions D3D12_COMPARISON_FUNC_LESS or D3D12_COMPARISON_FUNC_LESS_EQUAL.
Group clear operations into as few batches as possible.
Batching reduces the performance overhead of each clear.
Not recommended
Avoid using more than a few different clear colors for surface clearing.
Clearing optimization limited to 25 clear colors per frame on NVIDIA Ampere Architecture GPUs.
Clearing optimization limited to 10 clear colors per frame on NVIDIA Turing GPUs.
Avoid interleaving single clear calls with rendering work.
Group clears into batches whenever possible.
Never use clear-shaders as a replacement for API clears.
It disables hardware optimizations and negatively impacts both CPU and GPU performance.
Exception: Overlapping a compute clear with neighboring compute work may give better performance.
Acknowledgments
Thanks to Michael Murphy, Maurice Harris, Dmitry Zhdan, and Patric Neil for their advice and feedback.
Adepth map is an image channel in computer graphics and computer vision that provides information on the distance of the surface of objects as seen from a viewpoint for each pixel in that image. Because of its wide range of applications in augmented reality, portrait mode, and 3D reconstruction, ongoing research in the field of depth-sensing capabilities is being done to pave the way for the future (particularly with the release of the ARCore Depth API). Furthermore, the web community is increasing interest in merging the depth capabilities with JavaScript to enhance the existing web applications by integrating them with real-time AR effects. Despite these recent improvements, the number of photos connected with depth maps continues to be a source of worry.
To drive the next generation of web applications, Tensorflow released its first depth estimation API, called Depth API, and ARPortraitDepth, a model for estimating a depth map for portraiture. They also published 3D photo, a computational photography application that uses the anticipated depth and creates a 3D parallax effect on the given portrait image, further persuading people of the enormous possibilities of depth information. Tensorflow has also launched a live demo for people to try and convert their photographs into 3D versions.
The first open-source release of GPU kernel modules for the Linux community help improve NVIDIA GPU driver quality and security.
NVIDIA is now publishing Linux GPU kernel modules as open source with dual GPL/MIT license, starting with the R515 driver release. You can find the source code for these kernel modules in the NVIDIA Open GPU Kernel Modules repo on GitHub.
This release is a significant step toward improving the experience of using NVIDIA GPUs in Linux, for tighter integration with the OS and for developers to debug, integrate, and contribute back. For Linux distribution providers, the open-source modules increase ease of use. They also improve the out-of-the-box user experience to sign and distribute the NVIDIA GPU driver. Canonical and SUSE are able to immediately package the open kernel modules with Ubuntu and SUSE Linux Enterprise Distributions.
Developers can trace into code paths and see how kernel event scheduling is interacting with their workload for faster root cause debugging. In addition, enterprise software developers can now integrate the driver seamlessly into the customized Linux kernel configured for their project.
This will further help improve NVIDIA GPU driver quality and security with input and reviews from the Linux end-user community.
With each new driver release, NVIDIA publishes a snapshot of the source code on GitHub. Community submitted patches are reviewed and if approved, integrated into a future driver release.
The first release of the open GPU kernel modules is R515. Along with the source code, fully-built and packaged versions of the drivers are provided.
For data center GPUs in the NVIDIA Turing and NVIDIA Ampere architecture families, this code is production ready. This was made possible by the phased rollout of the GSP driver architecture over the past year, designed to make the transition easy for NVIDIA customers. We focused on testing across a wide variety of workloads to ensure feature and performance parity with the proprietary kernel-mode driver.
In this open-source release, support for GeForce and Workstation GPUs is alpha quality. GeForce and Workstation users can use this driver on Turing and NVIDIA Ampere architecture GPUs to run Linux desktops and use features such as multiple displays, G-SYNC, and NVIDIA RTX ray tracing in Vulkan and NVIDIA OptiX. Users can opt in using the kernel module parameter NVreg_EnableUnsupportedGpus as highlighted in the documentation. More robust and fully featured GeForce and Workstation support will follow in subsequent releases and the NVIDIA Open Kernel Modules will eventually supplant the closed-source driver.
Customers with Turing and Ampere GPUs can choose which modules to install. Pre-Turing customers will continue to run the closed source modules.
The open-source kernel-mode driver works with the same firmware and the same user-mode stacks such as CUDA, OpenGL, and Vulkan. However, all components of the driver stack must match versions within a release. For instance, you cannot take a release of the source code, build, and run it with the user-mode stack from a previous or future release.
Refer to the driver README document for instructions on installing the right versions and additional troubleshooting steps.
Installation opt in
The R515 release contains precompiled versions of both the closed-source driver and the open-source kernel modules. These versions are mutually exclusive, and the user can make the choice at install time. The default option ensures that silent installs will pick the optimal path for NVIDIA Volta and older GPUs versus Turing+ GPUs.
Users can build kernel modules from the source code and install them with the relevant user-mode drivers.
Figure 1: Illustration of installation options for the end user to opt-in to open GPU kernel modules and the default path of closed source modules.
Partner ecosystem
NVIDIA has been working with Canonical, Red Hat, and SUSE for better packaging, deployment, and support models for our mutual customers.
Canonical
“The new NVIDIA open-source GPU kernel modules will simplify installs and increase security for Ubuntu users, whether they’re AI/ML developers, gamers, or cloud users,” commented Cindy Goldberg, VP of Silicon alliances at Canonical. “As the makers of Ubuntu, the most popular Linux-based operating system for developers, we can now provide even better support to developers working at the cutting edge of AI and ML by enabling even closer integration with NVIDIA GPUs on Ubuntu.”
In the coming months, the NVIDIA Open GPU kernel modules will make their way into the recently launched Canonical Ubuntu 22.04 LTS.
SUSE
“We at SUSE are excited that NVIDIA is releasing their GPU kernel-mode driver as open source. This is a true milestone for the open-source community and accelerated computing. SUSE is proud to be the first major Linux distribution to deliver this breakthrough with SUSE Linux Enterprise 15 SP4 in June. Together, NVIDIA and SUSE power your GPU-accelerated computing needs across cloud, data center, and edge with a secure software supply chain and excellence in support.” — Markus Noga, General Manager, Business Critical Linux at SUSE
Red Hat
“Enterprise open source can spur innovation and improve customers’ experience, something that Red Hat has always championed. We applaud NVIDIA’s decision to open source its GPU kernel driver. Red Hat has collaborated with NVIDIA for many years, and we are excited to see them take this next step. We look forward to bringing these capabilities to our customers and to improve interoperability with NVIDIA hardware.” — Mike McGrath, Vice President, Linux Engineering at Red Hat
Upstream approach
NVIDIA GPU drivers have been designed over the years to share code across operating systems, GPUs and Jetson SOCs so that we can provide a consistent experience across all our supported platforms. The current codebase does not conform to the Linux kernel design conventions and is not a candidate for Linux upstream.
There are plans to work on an upstream approach with the Linux kernel community and partners such as Canonical, Red Hat, and SUSE.
In the meantime, published source code serves as a reference to help improve the Nouveau driver. Nouveau can leverage the same firmware used by the NVIDIA driver, exposing many GPU functionalities, such as clock management and thermal management, bringing new features to the in-tree Nouveau driver.
Stay tuned for more developments in future driver releases and collaboration on GitHub.
Frequently asked questions
Where can I download the R515 driver?
You can download the R515 development driver as part of CUDA Toolkit 11.7, or from the driver downloads page under “Beta” drivers. The R515 data center driver will follow in subsequent releases per our usual cadence.
Can open GPU Kernel Modules be distributed?
Yes, the NVIDIA open kernel modules are licensed under a dual GPL/MIT license; and the terms of licenses govern the distribution and repackaging grants.
Will the source for user-mode drivers such as CUDA be published?
These changes are for the kernel modules; while the user-mode components are untouched. So the user-mode will remain closed source and published with pre-built binaries in the driver and the CUDA toolkit.
Which GPUs are supported by Open GPU Kernel Modules?
Open kernel modules support all Ampere and Turing GPUs. Datacenter GPUs are supported for production, and support for GeForce and Workstation GPUs is alpha quality. Please refer to the Datacenter, NVIDIA RTX, and GeForce product tables for more details (Turing and above have compute capability of 7.5 or greater).
What is the process for patch submission and SLA/CLA for patches?
We encourage community submissions through pull requests on the GitHub page. The submitted patches will be reviewed and if approved, integrated with possible modifications into a future driver release. Please refer to the NVIDIA driver lifecycle document.
The published source code is a snapshot generated from a shared codebase, so contributions may not be reflected as separate Git commits in the GitHub repo. We are working on a process for acknowledging community contributions. We also advise against making significant reformatting of the code for the same reasons.
This feature-rich branch is fully compatible with Unreal Engine 5, and contains all of the latest developments from NVIDIA in the world of ray tracing.
The NVIDIA Branch of Unreal Engine 5 (NvRTX 5.0) is now available. This feature-rich branch is fully compatible with Unreal Engine 5 and has all of the latest developments in the world of ray tracing.
NVIDIA makes it easy for developers to add leading-edge technologies to their Unreal Engine games and applications through custom branches on GitHub. With NvRTX 5.0, developers can leverage RTXGI, RTXDI, and other improvements to ray tracing, such as shadow mismatching when using Nanite.
NvRTX is an engaging and interactive solution for developers to create stunning visuals and enhance ray tracing developments on any DirectX ray tracing (DXR) capable GPU. With these custom branches, developers are able to pick and choose which NVIDIA technologies they want to take advantage of in the games and applications.
RTXDI helps artists add unlimited shadow-casting and dynamic lights to game environments in real time without worrying about performance or resource constraints.
Join Microsoft Build 2022 to learn how NVIDIA AI technology solutions are transforming industries such as retail, manufacturing, automotive, and healthcare.
AI continues to transform global industries such as retail, manufacturing, automotive, and healthcare. The NVIDIA and Microsoft Azure partnership provides developers with global access to AI infrastructure on-demand, simplified infrastructure management, and solutions deploying AI-enabled applications.
Join the NVIDIA team virtually at Microsoft Build May 24-26, and learn more about the latest developer technologies, tools, and techniques for data scientists and developers to take AI to production faster. Connect live with subject matter experts from NVIDIA and Microsoft, get your technical questions answered, and hear how customers like BMW and Archer Daniels Midland (ADM) are harnessing the power of NVIDIA technologies on Azure.
Live Customer Interview | 5/25, 10:45-11:15 am Isaac Himanga and Archer Daniels Midland, ADM Watch the live interview. Registration is not required.
Many tools analyze equipment data to identify degraded performance or opportunities for improvement. What is not easy: finding relevant data for hundreds of thousands of assets to feed these models. ADM discusses how they’re organizing process data into a structure for quick deployment of AI to make data-based decisions. A new and better tool is needed to organize data and partnering with Sight Machine is helping move ADM closer to data-centric AI using NVIDIA GPU technology on Azure.
Join this session to see how Azure Cognitive Services uses the NVIDIA Triton Inference Server for inference at scale. We highlight two use cases: deploying the first-ever Mixture of Expert model for document translation and acoustic model for Microsoft Teams Live Captioning. Tune in to learn about serving models with NVIDIA Triton, ONNX Runtime, and custom backends.
Join experts from NVIDIA and Microsoft where you can ask questions about developing applications Graph Composer and new DeepStream features, deployment through IoT Hub, connecting to other Azure IoT Services, or transmitting inference results to the cloud.
Leaving performance on the table for AI inference deployments leads to poor cloud infrastructure utilization, high operational costs, and sluggish UX. Learn how to optimize the model configuration to maximize inference performance by using ONNX Runtime, OLive, Azure ML, NVIDIA Triton Inference Server, and NVIDIA Triton Model Analyzer.
Accelerate your ETL and ML Spark applications using Azure Synapse with NVIDIA RAPIDS.
Hands-on labs, tutorials, and resources
As a developer, you are a key contributor to the advancement of every field. We have created an online space devoted to your needs, with access to free SDKs, technical documentation, peer and domain expert help, and information on hardware to tackle the biggest challenges.
Join the NVIDIA Developer Program for free and exclusive access to SDKs, technical documentation, peer, and domain expert help. NVIDIA offers tools and training to accelerate AI, HPC, and graphics applications.



 A30 enables researchers, engineers, and data scientists to deliver real-world results and deploy solutions into production at scale.
A30 enables researchers, engineers, and data scientists to deliver real-world results and deploy solutions into production at scale. 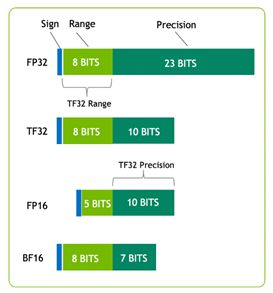
 Surface clearing is a widely used accessory operation. This post covers best practices for clears on NVIDIA GPUs.
Surface clearing is a widely used accessory operation. This post covers best practices for clears on NVIDIA GPUs.

 The first open-source release of GPU kernel modules for the Linux community help improve NVIDIA GPU driver quality and security.
The first open-source release of GPU kernel modules for the Linux community help improve NVIDIA GPU driver quality and security.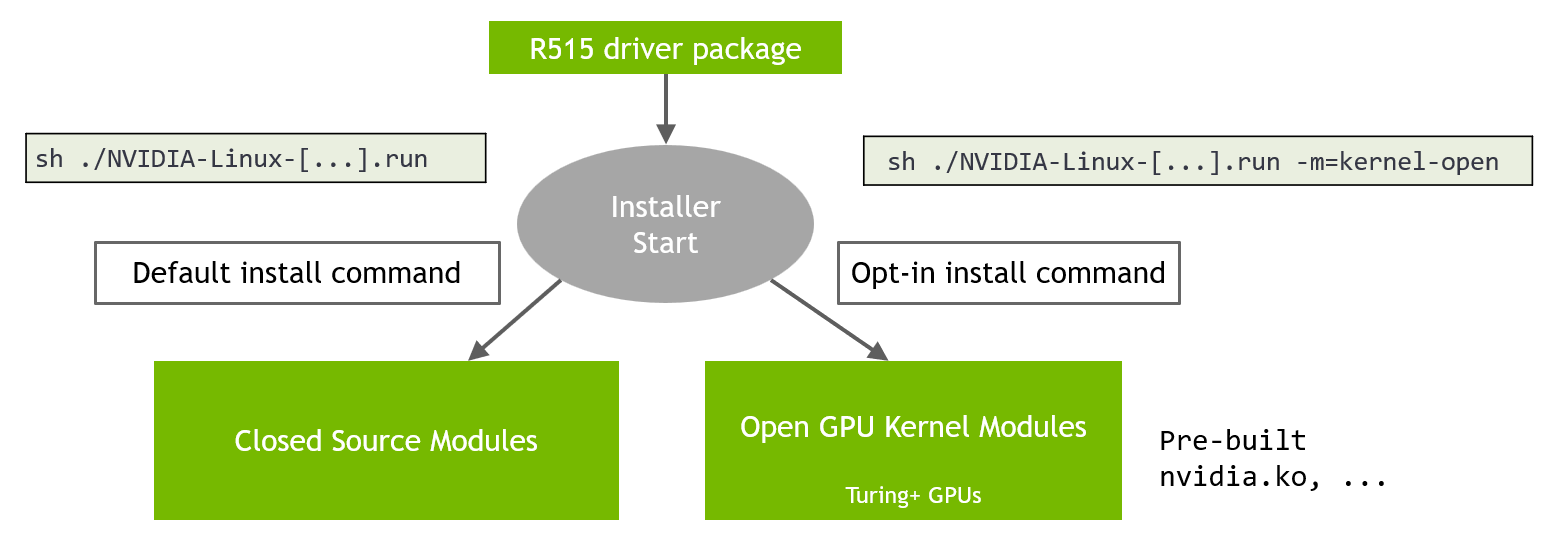
 This feature-rich branch is fully compatible with Unreal Engine 5, and contains all of the latest developments from NVIDIA in the world of ray tracing.
This feature-rich branch is fully compatible with Unreal Engine 5, and contains all of the latest developments from NVIDIA in the world of ray tracing. Join Microsoft Build 2022 to learn how NVIDIA AI technology solutions are transforming industries such as retail, manufacturing, automotive, and healthcare.
Join Microsoft Build 2022 to learn how NVIDIA AI technology solutions are transforming industries such as retail, manufacturing, automotive, and healthcare. {kind=link}