All of us recycle. Or, at least, all of us should. Now, AI is joining the effort. On the latest episode of the NVIDIA AI Podcast, host Noah Kravitz spoke with JD Ambadti, founder and CEO of EverestLabs, developer of RecycleOS, the first AI-enabled operating system for recycling. The company reports that an average of Read article >
Edge computing and edge AI are powering the digital transformation of business processes. But, as a growing field, there are still many questions about what…
Edge computing and edge AI are powering the digital transformation of business processes. But, as a growing field, there are still many questions about what exactly needs to be in an edge management platform.
The benefits of edge computing include low latency for real-time responses, using local area networks for higher bandwidth, and storage at lower costs compared to cloud computing.
However, the distributed nature of edge nodes can make managing edge AI complex and challenging. It can be time-consuming and costly when gathering insights from separate locations, installing hardware, deploying software, and maintaining upgrades at individual nodes.
Centralized management platforms are a critical component of a company’s edge AI solution. This enables organizations to deploy and manage industry applications at the edge, automate management tasks, allocate computing resources, update system software over the air, and monitor locations.
However, the entire stack that makes up an edge AI management solution is complicated, making the question of whether to build or buy an edge management platform exceedingly difficult.
In this post, I break down some of the most important factors to consider when evaluating an AI edge solution for your company.
Figure 1. Managing edge AI deployments from a central plane
To get started, consider asking the following questions:
What is the problem you’re solving? Clarify the requirements needed for your platform and prioritize them. No solution will be perfect.
What is your budget? Financial resources will inform your approach. Evaluate the cost of using vendor software compared to bringing in resources to your existing team. Management and maintenance costs are also a factor.
What is your timeline? Are there competitive reasons for you to move quickly? Remember to factor in integration and customization.
Benefits of building or buying
Similar to building a home, when building an edge management platform you are part of the entire process and maintain control of the design. This can be extremely beneficial to an enterprise, especially in terms of customization, data control, and security.
However, buying a solution can be a benefit, especially when it comes to ensuring quality and support from a vendor. Faster time-to-market and lower long-term costs are also significant advantages to buying. In the following, I lay out the top points for either option.
Benefits of building an edge management solution
Customization
Data control
Security risk
Customization
Understanding business needs is paramount to having a proper edge management solution. In doing your due diligence, you may find specific use cases or edge devices that require lots of customization. In this case, you are better off building the platform yourself.
Data control
Maintaining local storage and control of all critical data could be necessary depending on your business. It is important to ask how the third party will use your proprietary data. By building the platform, you ensure complete access and oversight to important data and business insights. If your data is a vital component of your competitive advantage, it becomes imperative to maintain this information internally.
Security risk
Enterprise-level software companies are the targets, and sometimes victims, of large-scale cyber attacks. These attacks compromise all users of their software, potentially leaking vitally important data or opening up pathways into your network. Building the entire platform in-house enables you to add security to places you deem the most important and limit exposure to any breach that a third party may have.
Benefits of buying an edge management solution
Ensured quality, expertise, and support
Faster time to market
Lower cost
Ensured quality, expertise, and support
Enterprise-edge AI management platforms are extremely complex with many layers. A solution provider is incentivized to ensure that the solution meets your needs. They have dedicated expert resources to build an optimal, enterprise-grade solution as well as provide enterprise support for all issues from low level to critical. This means that the platform not only resolves all your current needs but also solves future issues and has a dedicated resource to call upon when needed.
Faster time to market
Buying can help you deploy an edge computing solution faster. Enterprises across the world are working to find the best way to manage all their disparate edge nodes. It would be a competitive disadvantage to wait several months to build a quality solution.
Being an early adopter of edge AI management software can also give you a competitive advantage. You’re able to realize insights from your data in nearly real time and deploy or update new AI applications faster.
Lower cost
Enterprise software often has usage-based pricing, which can lower long-term expenses. Providers are able to spread maintenance and support costs, which is something you are unable to do in-house. Purchasing enterprise-grade software is a capital expenditure as opposed to an operating expense. In the long run, it tends to be cost-effective to purchase.
Risks of building or buying
There are also downsides to consider. There is some assumed risk with building your own solution. These risks—specifically around quality, opportunity cost, and support—can hinder development and slow down business growth.
But, nothing comes without risk, and buying a solution is no exception. These can be summarized into three main buckets: potential data leaks; a solution that doesn’t meet your needs; and trusting someone else to do the job. In the following section, I examine risks in detail.
Risks of building an edge management solution
Quality compromise
Technical debt
Opportunity cost
Quality compromise
A proper and complete solution must deploy AI workloads at scale, have layered security, and orchestrate containers, among other things. There is a tremendous amount of detail required to have a complete edge management platform. While this may seem simple to create, the many layers of complex software below the user interface could require an outside expert to solve your problem.
Technical debt
Another option is to extend your current solution to support edge computing and AI but that often brings more trouble than benefit. It could be costly, with additional licensing costs, and may not encompass all the benefits and features needed. A loop of continual repairs rather than rip and replace is not only costly but also time-consuming, leaving you with a platform that does not perform as needed.
Opportunity cost
Even in cases that do not require bringing in outside developers, the existing team may be of better value in building unique and custom AI applications for use cases rather than the platform. A solution provider can also offer expertise in edge computing and management, saving you time bringing the solution to market while meeting your all requirements.
Risks of buying an edge management solution
Long-term support
Access to private data
Unmet requirements
Market changes
Long-term support
By building your own solution, you also take on the cost of maintenance and support. Those costs rise as more applications and users come onto the platform. This can strain your IT personnel and end-users, while also growing operating expenses and lowering your net income.
Access to private data
The solution provider becomes a responsible owner for several components of the edge compute stack and could have access to some edge data. If there is data vital to your company’s competitive advantage, this is a risk you must consider.
Unmet requirements
The vendor’s solution may not meet the exact needs of your organization. You may have a niche or unique need that off-the-shelf products cannot solve. These could include specific connectivity, firewall, or provisioning issues limiting your ability to use a service provider.
Market changes
Using a third party could leave you vulnerable to any changes that the third party makes on their own. They could decide to leave the market or may struggle with market shifts leaving you exposed and without a trusted partner.
Choosing the right edge management solution
A lot goes into a quality edge AI management platform. While you still may be thinking through the best option, one approach to consider is a hybrid model; where you buy the primary solution but build out customizations for your organization’s needs.
This is only possible if the provider’s solution has APIs for integration. Be sure to ask if integration into other management tools and the wider ecosystem is possible. Also, when performing due diligence ask about local app data storage on-premises to minimize any data concerns.
The most important thing is to understand the capabilities of both the vendor and your own organization. Work closely with the vendor, ask for demos, ask questions about the flexibility of the pricing structure, and ensure it is a collaborative effort between all parties that are involved.
NVIDIA works with many customers who have chosen to build their own edge solutions and also offers the edge management platform NVIDIA Fleet Command. Fleet Command is a cloud service that enables the management of distributed edge computing environments at scale.
A proof-of-concept (POC) is the first step towards a successful edge AI deployment. Companies adopt edge AI to drive efficiency, automate workflows, reduce…
A proof-of-concept (POC) is the first step towards a successful edge AI deployment.
Companies adopt edge AI to drive efficiency, automate workflows, reduce cost, and improve overall customer experiences. As they do so, many realize that deploying AI at the edge is a new process that requires different tools and procedures than the traditional data center.
Without a clear understanding of what distinguishes a successful and unsuccessful edge AI solution, organizations often succumb to common pitfalls, starting in the POC process.
In fact, Gartner details that by 2025, 50% of edge computing solutions deployed without an enterprise edge computing strategy in place will fail to meet goals in deployment time, functionality, or cost.
As the leading AI infrastructure company, NVIDIA has helped countless organizations, customers, and partners successfully build their edge AI POCs. This post details the common edge AI POC challenges and solutions.
Before you start
The first decision that an organization makes before starting the process is to determine whether to buy a solution from an AI software vendor or to build their own.
Typically, companies that do not have in-house AI expertise partner with a software vendor. Vendors have insight into the best practices and can provide guidance to make the POC process as streamlined and cost-effective as possible.
Companies that have the technical capability can build a custom solution at a lower cost.
Defining the steps from development to production
Figure 1. Four steps from AI model development to production
While the process of developing and deploying an application may vary for different organizations, most organizations follow this process:
AI model development
Hands-on trial
Proof of concept
Production
AI model development
Your data requirements depend on whether you’re using pretrained models or building from scratch. Even when an AI application is purchased, most models must still be retrained on labeled data from your environment to achieve the desired accuracy.
Some data sources may include raw data from sensors at the edge, synthetic data, or crowdsourced data. Expect data collection to be the timeliest task of model development, followed by optimizing the training pipeline.
The purpose of this phase is to prove the feasibility of the project and model accuracy, not to get production-level performance. This phase is ongoing, as the model is continually retrained as new data is collected.
Hands-on trial
The more prepared organizations are for their POC, the smoother deployments will run. We highly recommend that you use free trials to test different software options before committing to them in the POC phase.
For example, free programs such as NVIDIA LaunchPad equip a curated experience with all of the hardware and software stacks necessary to test and prototype end-to-end solution workflows. The result is that the same stack can be deployed in production, enabling more confident software and infrastructure decisions.
Testing a solution before starting the POC streamlines the overall process and minimizes the common trap of entering a never-ending POC.
Proof of concept
The POC is a 1–3-month engagement where IT requirements are defined, hardware is acquired, and models are trained with company data and deployed in the company’s production environment to limited locations.
Unlike the hands-on trial, the key to this step is incorporating the company’s data rather than just testing standard software and hardware and generic data. The goal of a POC’s validation process is to verify the problem-solution fit, and that the solution can meet business requirements. It acts as the final test before a solution is fully scaled.
Production
In production, the AI model is deployed to every intended location and is fully functioning. Ongoing monitoring is expected.
What are the common challenges?
Following these four steps maximizes the chances of a smooth deployment. Unfortunately, most enterprises get stuck in the POC phase because they did not properly scope out the project, understand the requirements, define the measures of success, or have the correct tools and processes in place.
To get the most out of your POC program, have a solution in mind to combat the following common challenges that enterprises face when deploying AI at the edge:
Misalignment on POC design
Manual management of edge environments
POC creeps into production
Misalignment on POC design
When preparing for a POC project, first set expectations and then align on them. The steps should include identifying a high-value use case to solve, setting the project scope, determining measures of success, and ensuring stakeholder alignment.
High-value use case
Make sure that your problem statement is of high value and can be solved with AI. The key is to recognize which types of problems to hand off to the AI and which problems can be solved through managerial changes, or improved employee training.
Solving a problem that provides high value to your organization helps justify the resources and budget needed to prove the solution’s efficacy and enable scaling. Selecting a low-value use case runs the risk of the project losing focus before a full solution can be rolled out.
Examples of high-value use cases that solve a business problem include improving safety, efficiency, and customer experiences, and reducing costs and waste.
Measures of success
The purpose of a POC is to validate a solution quickly, so it’s important to run a focused POC with clear project goals.
If the success criteria are not properly defined, organizations typically experience the “moving goal post” phenomenon, where they find themselves constantly re-adjusting and re-designing the POC to meet ever-changing goals. A never-ending POC is costly and time-consuming.
The most common measures of success include:
Accuracy: Can the problem be solved with AI? Verify by testing whether the model can reach the desired accuracy. Accuracy is the first metric that should be tested. If model accuracy cannot be reached, then another solution should be put in place.
Latency: Does the solution add value to the overall system or process? It is not enough for a problem to be solvable with AI, it must provide value. For example, if a computer vision application at a manufacturing line works but requires the company to operate the line at 50% speed, the cost of slowing down the manufacturing line is not worth the benefit of using AI.
Efficiency: Is the solution cost-effective? Check whether the solution’s capital expenditures and operating expenditures are more favorable than other solutions. For example, if a network upgrade is necessary for the edge AI model to be effective, is it cheaper just to hire people to inspect products at your manufacturing line?
Defining the POC objectives, scope, and success criteria before executing the POC is the best way to understand whether the selected use case and solution can really achieve the intended benefits.
Stakeholder alignment
A POC requires a diverse team. To optimize your chances of success, identify and engage with both technical and business experts early on.
The involved stakeholders are usually business owners, AI developers, data scientists, IT, SecOps teams, and AI software providers. The AI software providers are particularly important because they have the knowledge, experience, and best practices. At this stage, identify the responsibilities of each stakeholder, including who owns the project after it scales.
Manual management of edge environments
Edge environments are unique because they are highly distributed, deployed in remote locations without trained IT staff, and often lack the physical security that a data center boasts.
These features present unique, often overlooked challenges when deploying, managing, and upgrading edge systems. It is extremely difficult and time-consuming for IT teams to troubleshoot issues manually at every remote edge site every time an upgrade is required or an issue arises.
Unfortunately, existing data center tools are not always applicable to edge AI environments. Moreover, because a POC is deployed to limited locations, organizations usually overlook a management tool during this phase and opt to update their models manually.
The POC is a highly iterative process, so implementing a management platform in this phase can help organizations save time. For customers who do not already have edge management tools in place, turnkey solutions like NVIDIA Fleet Command can help with the rollout of a POC as well as its transition to production.
Remote management
After setup, day 1, and day 2 operations begin, organizations must deploy and scale new applications, update existing applications, troubleshoot bugs, and validate new configurations.
Having remote management capabilities that are secure is critical because production deployments contain important data and insights that you want to keep safe.
Third-party access
Organizations should implement a management solution with advanced functionality for third-party access and security functions such as just-in-time (JIT) access, clearly defined access controls, and timed sessions.
Software vendors, system integrators, and hardware partners are just a few different parties that may need access to your systems. Coupled with remote management functionality, third parties can help make updates to your POC environment without gaining physical access to your edge location.
Monitoring
Tracking performance is important, even in the POC phase, because it can help with sizing and showing where bottlenecks may occur. These are important considerations to iron out before scaling.
POC creeps into production
A POC does not have to be fully production-ready for it to be successful. While it is true that the closer an organization can get to production specs in the POC phase, the easier it will be to scale, most POCs are not designed for production.
Many times, companies use whatever hardware or software they have on hand. This means that upon completion of a POC, businesses should go back and update their models and hardware before their final deployment. Many do not.
Here are some tips for transitioning from POC to production.
Measure efficacy
Track the efficacy of all software and hardware to help make decisions on what should be moved into production, and what must be upgraded.
Use enterprise-grade hardware and software
While it is okay to use existing systems that a business may already have during a POC, take extra time to understand what systems are needed for production and any implications of that change.
Only use software from a trusted source with a line of support to speak to when needed. Many organizations deploying edge applications download software online without researching whether it is from a trusted source and then they accidentally download malware.
Prepare for success
Ultimately, POCs are just the first step to a successful deployment. They are designed to help organizations determine whether a project should move forward and whether it is an effective use of their resources. Edge AI is a paradigm shift for most organizations. To avoid common pitfalls when deploying your solution, see An IT Manager’s Guide: How to Successfully Deploy an Edge AI Solution.
Nowadays, a huge number of implementations of state-of-the-art (SOTA) models and modeling solutions are present for different frameworks like TensorFlow, ONNX,…
Nowadays, a huge number of implementations of state-of-the-art (SOTA) models and modeling solutions are present for different frameworks like TensorFlow, ONNX, PyTorch, Keras, MXNet, and so on. These models can be used for out-of-the-box inference if you are interested in categories already in the datasets, or they can be embedded to custom business scenarios with minor fine-tuning.
This post gives you an overview of prevalent DL model categories and walks you through the end-to-end examples of deploying these models using NVIDIA Triton Inference Server. The client applications can be used as it is or can be modified according to the use case scenarios. I walk you through the deployment of image classification, object detection, and image segmentation public models using Triton Inference Server. The steps outlined in this post can also be applied to other open-source models with minor changes.
Deep learning inference challenges
Recent years have seen remarkable advancements in deep learning (DL). By resolving numerous complex and intricate problems that have hampered the AI community for years, it has completely revolutionized the future of AI. It is currently being used with rapidly growing applications in different industries, ranging from healthcare and aerospace engineering to autonomous driving and user authentications.
Deep learning, however, has various challenges when it comes to inference:
Support of multiple frameworks
Ease of use
Cost of deployment
Support of multiple frameworks
The first key challenge is around supporting multiple different types of model frameworks.
Developers and data scientists today are using various frameworks for their production models. For instance, there can be difficulties modifying the system for testing and deployment if a machine learning project is written in Keras, but a team member has more experience with TensorFlow.
Also, converting the models can be expensive and complicated, especially if new data is required for their training. They must have a server application to support each of those models.
Ease of use
The next key challenge is to have a serving application that can support different inference queries and use cases.
In some applications, you’re focused on real-time online inferencing where the priority is to minimize latency as much as possible. On the other hand, there might be use cases that require you to do offline batch inferencing where you’re focused on maximizing throughput.
It’s essential to have solutions that can support each type of query and use case and optimize for them.
Cost of deployment
The next challenge is managing the cost of deployment and lowering the cost of inference.
A key part of this is having one serving application that can support running on a mixed infrastructure. You might create a separate serving solution for running on CPU, another one for GPU, and a different one for deploying on the cloud in the data center and edge. That’s going to skyrocket costs and lead to a nonscalable implementation.
Triton Inference Server
Triton Inference Server is an open-source server inference application allowing inference on both CPU and GPU in different environments. It supports various backends, including TensorRT, PyTorch, TensorFlow, ONNX, and Python. To have maximum hardware utilization, NVIDIA Triton allows concurrent execution of different models. Further dynamic batching allows grouping together inference queries to maximize the throughput for different types of queries. For more information, see NVIDIA Triton Inference Server.
Figure 2. Triton Inference Server architecture
Quickstart with NVIDIA Triton
The easiest way to install and run NVIDIA Triton is to use the pre-built Docker image available from NGC.
Server: Pull the Docker image
Pull the image using the following command:
$ docker pull nvcr.io/nvidia/tritonserver:-py3
NVIDIA Triton is optimized to provide the best inferencing performance by using GPUs, but it can also work on CPU-only systems. In both cases, you can use the same Docker image.
Use the following command to run NVIDIA Triton with the example model repository that you just created:
In this command, is the version to pull. Run the client image.
To start the client, run the following command:
$ docker run -it --rm --net=host /path/to/the/repo/client/:/python_examples nvcr.io/nvidia/tritonserver:-py3-sdk
End-to-end model deployment
The NVIDIA Triton project provides several client libraries in C++ and Python to simplify communication. These APIs make communicating with NVIDIA Triton easy. With the help of these APIs, the client applications process the input and communicate with NVIDIA Triton to perform inferencing.
Figure 3. Workflow of client application interaction with Triton Inference Server
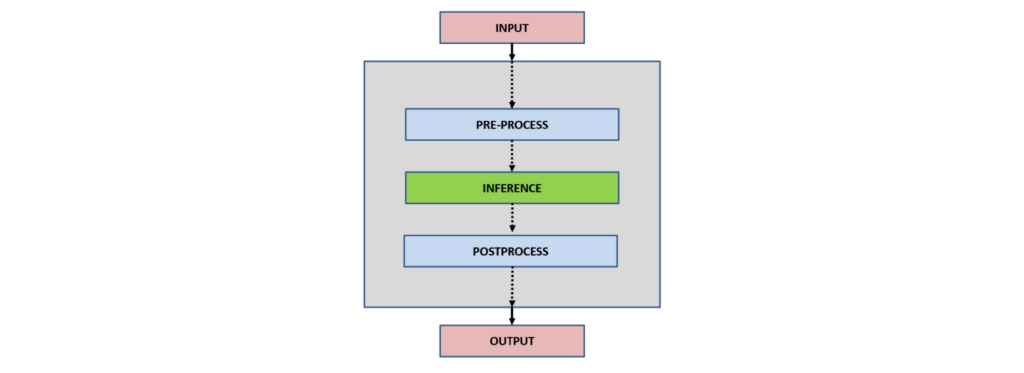
In general, the interaction of client applications with NVIDIA Triton can be summarized as follows:
Input
Preprocess
Inference
Postprocess
Output
Input: Depending upon the application type, one or more inputs are read to be inferred by the neural network.
Preprocess: Preprocessing data is a common first step in the deep learning workflow to prepare raw data in a format the network can accept, For example, image resizing, normalization, or noise removal from input data.
Inference: For the inference part, a client initially serializes the inference request into a message and sends it to Triton Inference Server. The message travels over the network from the client to the server and gets deserialized. The request is placed on the queue. The request is removed from the queue and computed. The completed request is serialized in a message and sent back to the client. The message travels over the network from the server to the client. The message arrives at the client and is deserialized.
Postprocess: When the message arrives at the client application, it is processed as a completed inference request. Depending upon the network type and application use case, post-processing is applied. For example, in object detection, postprocessing involves suppressing the superfluous boxes, aiding in selecting the best possible boxes, and mapping them back to the input image.
Output: After inference and processing, depending upon the application, the output can be stored, displayed, or passed to the network.
Image classification
Image classification is the task of comprehending an entire image and specifying a specific label for the image. Typically in image classification, a single object is present in the image, which is analyzed and comprehended. For more information, see image classification.
Server: Download the model
Download the ResNet-18 image classification model from the ONNX model zoo:
$ cd /path/to/the/repo/server/models/classification/1
$ wget https://github.com/onnx/models/raw/main/vision/classification/resnet/model/resnet18-v1-7.onnx && mv resnet18-v1-7.onnx model.onnx
The following code example shows the model configuration file:
The name property is optional. If the name of the model is not specified in the configuration, it is assumed to be the same as the model repository directory containing the model. The model is executed by the NVIDIA Triton backend, which is simply a wrapper around the DL frameworks like TensorFlow, PyTorch, TensorRT, and so on. For more information, see backend.
Maximum batch size
The maximum batch size that a model can support is indicated by the max_batch_size property. Zero size shows that bathing is not supported. For more information, see batch size.
Inputs and outputs
For each model, the expected input, output, and data types must be specified in the model configuration file. Based on the input and output tensors, different data types are allowed. For more information, see Datatypes.
The image classification model accepts a single input, and after the inference returns a single output.
In a separate console, launch the image_client example from the NGC NVIDIA Triton container.
Client: Run the image classification client
To run the image classification client, use the following command:
For the classification case, the model returns a single classification output that comprehends the input image. The class is decoded and printed in the console.
for results in output_array:
if not supports_batching:
results = [results]
for result in results:
if output_array.dtype.type == np.object_:
cls = "".join(chr(x) for x in result).split(':')
else:
cls = result.split(':')
print(" {} ({}) = {}".format(cls[0], cls[1], cls[2]))
For more information, see classification.py.
Figure 4 shows the sample output.
Figure 4. Classification label assigned to the image by the classification network
Object detection
The process of finding instances of objects of a particular class within an image is known as object detection. The problem of object detection combines classification with localization. It also examines more plausible scenarios in which an image might contain several objects. For more information, see object detection.
Server: Download the model
Download the faster_rcnn_inception_v2_coco object detection model:
$ cd /path/to/the/repo/server/models/detection/1
$ wget http://download.tensorflow.org/models/object_detection/faster_rcnn_inception_v2_coco_2018_01_28.tar.gz && tar xvf faster_rcnn_inception_v2_coco_2018_01_28.tar.gz && cp faster_rcnn_inception_v2_coco_2018_01_28/frozen_inference_graph.pb ./model.graphdef && rm -r faster_rcnn_inception_v2_coco_2018_01_28 faster_rcnn_inception_v2_coco_2018_01_28.tar.gz
The following code example shows the model configuration file for the object detection model:
Figure 5. Using object detection to identify and locate vehicles (source:MathWorks.com)
Image segmentation
The process of clustering parts of an image that correspond to the same object class is known as image segmentation. Image segmentation entails splitting images or video frames into multiple objects or segments. For more information, see image segmentation.
Server: Download the model
To download the model, use the following commands:
$ cd /path/to/the/repo/server/models/segmentation/1
$ wget https://github.com/onnx/models/raw/main/vision/object_detection_segmentation/fcn/model/fcn-resnet50-11.onnx && mv fcn-resnet50-11.onnx model.onnx
The following code example shows the model configuration file for the image segmentation model:
The segmentation model accepts a single input and returns a single output. After inferencing, the model returns the output based on which segmented and blended images are generated.
Learn how to write simple, portable, parallel-first GPU-accelerated applications using only C++ standard language features in this self-paced course from the…
Learn how to write simple, portable, parallel-first GPU-accelerated applications using only C++ standard language features in this self-paced course from the NVIDIA Deep Learning Institute
With the state of the world under constant flux in 2022, some technology trends were put on hold while others were accelerated. Supply chain challenges, labor shortages and economic uncertainty had companies reevaluating their budgets for new technology. For many organizations, AI is viewed as the solution to a lot of the uncertainty bringing improved Read article >
From taking your order and serving you food in a restaurant to playing poker with you, service robots are becoming increasingly prevalent. Globally, you can…
From taking your order and serving you food in a restaurant to playing poker with you, service robots are becoming increasingly prevalent. Globally, you can find these service robots at hospitals, airports, and retail stores.
According to Gartner, by 2030, 80% of humans will engage with smart robots daily, due to smart robot advancements in intelligence, social interactions, and human augmentation capabilities, up from less than 10% today.
An accurate speech AI or voice AI interface that can quickly understand humans and mimic human speech is critical to a service robot’s ease of use. Developers are integrating automatic speech recognition (ASR) and text-to-speech (TTS) with service robots to enable essential skills, such as understanding and responding to human questions in natural language. These voice-based technologies make up speech AI.
This post explains how ASR and TTS can be used in service robot applications. I provide a walkthrough on how to customize them using speech AI software tools for industry-specific jargon, languages, and dialects, depending on where the robot is deployed.
Why add speech AI to service robot applications?
Service robots are like digital humans in the metaverse except that they operate in the physical world. These service robots can help support warehouse workers, perform dangerous tasks while following human instructions, or even assist in activities that require contactless services. For instance, a service robot in the hospitality industry can greet guests, carry bags, and take orders.
For all these service robots to understand and respond in a human-like way, developers must incorporate highly accurate speech AI that runs in real time.
Examples of speech AI-enabled service robot applications
Today, service robots are used in a wide range of industries.
Restaurants
Online food delivery services are growing in popularity worldwide. To handle the increased customer demand without compromising quality, service robots can assist staff with tasks such as order taking or delivering food to in-person customers.
Hospitals
In hospitals, service robots can support and empower patient care teams by handling patient-related tasks. For example, a speech AI-enabled service robot can empathetically converse with patients to provide company or help improve their mental health state.
Ambient assisted living
In ambient assisted living environments, technology is primarily used to support the independence and safety of elderly or vulnerable adults. Service robots can assist with daily activities, such as transporting food trays from one location to another or using a smart robotic pill dispenser to manage medications in a timely manner. With speech AI skills, service robots can also provide emotional support.
Service robot reference architecture
Service robots help businesses improve quality assurance and boost productivity in several ways:
Assisting frontline workers with daily repetitive tasks in restaurants or manufacturing environments
Helping customers find desired items in retail stores
Supporting physicians and nurses with patient healthcare services in hospitals
In these settings, it’s imperative that robots can accurately process and understand what a user is relaying. This is especially true for situations where danger or serious harm is a possibility, such as a hospital. Service robots that can naturally converse with humans also contribute to a positive overall user experience for an application.
Figure 1. Service robot design review workflow architecture
Figure 1 shows that service robots use speech recognition to comprehend what users are saying and TTS to respond to users with a synthetic voice. Other components such as NLP and a dialog manager, are used to help service robots understand context and generate appropriate answers to users’ questions.
Also, the modules under robot tasks such as perception, navigation, and mapping help the robot understand its physical surroundings and move in the right direction.
Voice user interfaces to service robots
Voice user interfaces include two main components: automatic speech recognition and text-to-speech. Automatic speech recognition, also known as speech-to-text, is the process of converting raw speech into text. Text-to-speech, also known as speech synthesis, is the process of converting text into human-like speech.
Developing speech AI pipelines has its own challenges. For example, if a service robot is deployed in restaurants, it should be able to understand words like matcha, cappuccino, and ristretto. It should even transcribe in noisy environments as most people interacting with these applications are in open spaces.
Not only do the robots have to understand what is being said, but they should also be able to say these words correctly. Similarly, each industry has its own terminology that these robots must understand and respond to in real time.
Automatic speech recognition
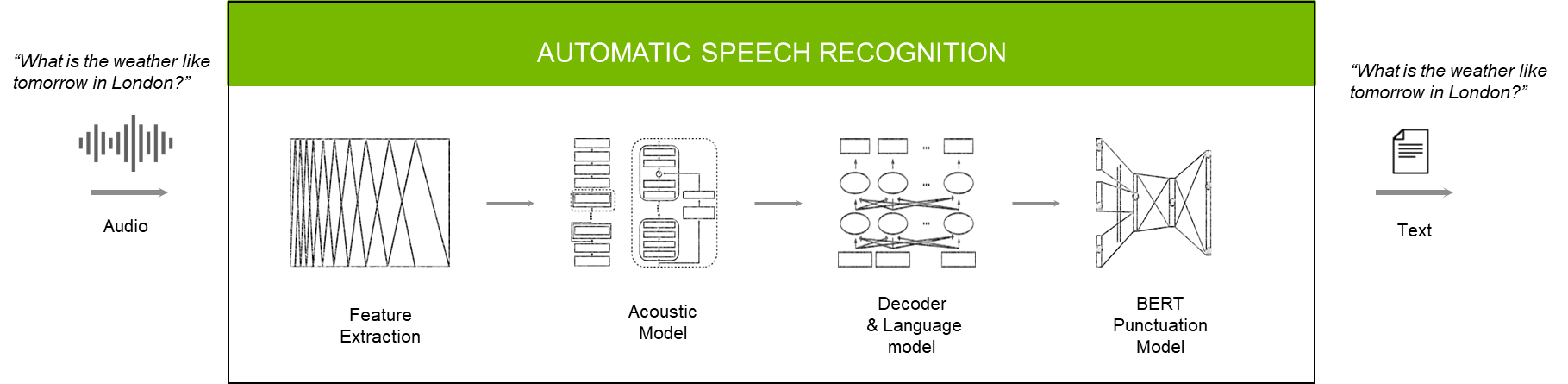
Figure 2. Speech-to-text pipeline
The roles of each model or module in the ASR pipeline are as follows:
The feature extractor converts raw audio into spectrograms or mel spectrograms.
The acoustic model takes these spectrograms and generates a matrix that has probabilities of characters or words over each time step.
The decoder and language model put together these characters/words into a transcript.
The punctuation and capitalization model applies things like commas, periods, and question marks in the right places for better readability.
Text-to-speech
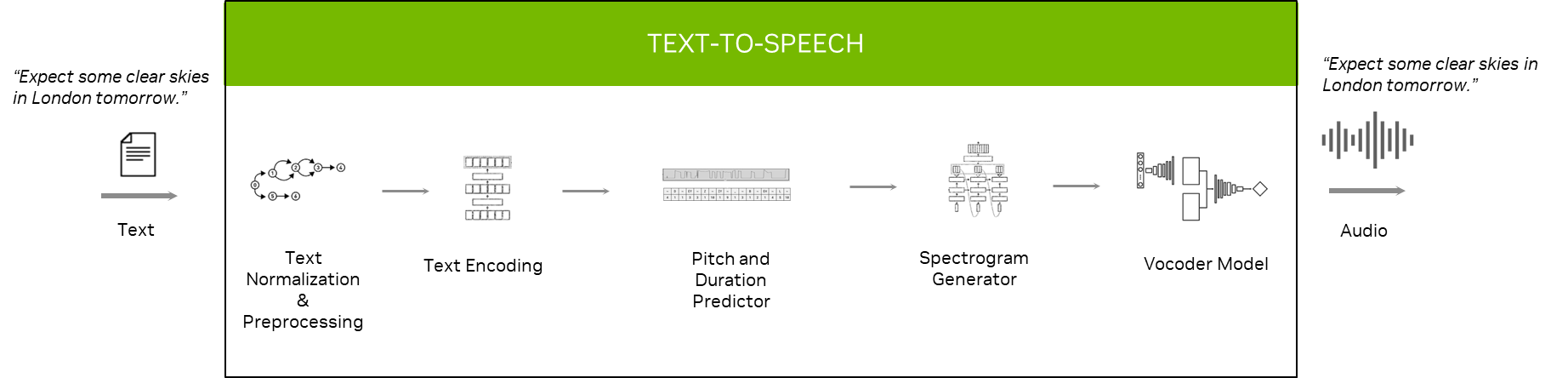
Figure 3: Text-to-speech pipeline
The roles of each model or module in the TTS pipeline are as follows:
In the text normalization and preprocessing stage, the text is converted into verbalized form. For instance: “at 10:00” -> “at ten o’clock.”
The text encoding module converts text into an encoded vector.
The pitch predictor predicts how much highness or lowness you have to give certain words, while the duration predictor predicts how long it takes to pronounce a character or word.
The spectrogram generator uses an encoded vector and other supporting vectors as input to generate a spectrogram.
The vocoder model takes spectrograms as input and produces a human-like voice as output.
Speech AI software suite
NVIDIA provides a variety of datasets, tools, and SDKs to help you build end-to-end speech AI pipelines. Customize the pipelines to your industry’s specific vocabulary, language, and dialects and run in milliseconds for natural and engaging interactions.
Datasets
To democratize and diversify speech AI technology, NVIDIA collaborated with Mozilla Common Voice (MCV). MCV is a crowd-sourced project in which volunteers contribute speech data to a public dataset that anyone can use to train voice-enabled technology. You can download various language audio datasets from MCV to develop ASR and TTS models.
NVIDIA also collaborated with Defined.ai, a one-stop shop for training data. You can download audio and speech training data in multiple domains, languages, and accents for use in speech AI models.
Pretrained models
NGC provides several pretrained models trained on a variety of open and proprietary datasets. All models have been optimized and trained on NVIDIA DGX servers for hundreds of thousands of hours.
You can fine-tune these highly accurate, pretrained models on a relevant dataset to improve accuracy even further.
Open-source tools
If you’re looking for open-source tools, NVIDIA offers NeMo, an open-source framework for building and training state-of-the-art AI speech and language models. NeMo is built on top of PyTorch and PyTorch Lightning, making it easy for you to develop and integrate modules that are already familiar.
Speech AI SDK
Use NVIDIA Riva, a free GPU-accelerated speech AI SDK, to build and deploy fully customizable, real-time AI pipelines. Riva offers state-of-the-art, highly accurate, pretrained models through NGC:
English
Spanish
Mandarin
Hindi
Russian
Korean
German
French
Portuguese
Japanese, Arabic, and Italian are coming soon.
With NeMo you can fine-tune these pretrained models on industry-specific jargon, languages, dialects, and accents, and optimized speech AI skills to run in real time.
You can deploy Riva skills in streaming or offline in all clouds, on-premises, at the edge, and on embedded devices.
Running Riva speech AI skills on embedded for robotics applications
In this section, I show you how to run out-of-the-box ASR and TTS skills with Riva on embedded devices. For better accuracy and performance, Riva also enables you to customize or fine-tune models on domain-specific datasets.
You can run Riva speech AI skills in both streaming and offline modes. First, set up and run the Riva server on embedded.
For more information about customizing Riva ASR models and pipelines for your industry-specific jargon, languages, dialects, and accents, see the instructions on the Model Overview in the Riva documentation.
Running C++ TTS client
For Riva TTS client on embedded, run the following command to synthesize audio files:
riva_tts_client --voice_name=English-US.Female-1 --text="Hello, this is a speech synthesizer." --audio_file=/opt/riva/wav/output.wav
For more information about customizing TTS models and pipelines on domain-specific datasets, see Model Overview in the Riva User Guide.
Resource for developing speech AI applications
Speech AI makes it possible for service robots and other interactive applications to comprehend nuanced human language and respond with ease.
It is empowering everything from real people in call centers to service robots in every industry. To understand how speech AI skills were integrated with a robotic dog that can fetch drinks in real life, see Low-code Building Blocks for Speech AI Robotics.
You can also access developer ebooks, such as End-To-End Speech AI pipelines to learn more about models and modules in speech AI pipelines and Building Speech AI Applications to gain insight on how to build and deploy real-time speech AI pipelines for your application.
Speech is one of the primary means to communicate with an AI-powered application. From virtual assistants to digital avatars, voice-based interfaces are…
Speech is one of the primary means to communicate with an AI-powered application. From virtual assistants to digital avatars, voice-based interfaces are changing how we typically interact with smart devices.
Deep learning techniques for speech recognition and speech synthesis are helping improve the user experience—think human-like responses and natural-sounding tones.
If you plan to build and deploy a speech AI-enabled application, this post provides an overview of how automatic speech recognition (ASR) and text-to-speech (TTS) technologies have evolved due to deep learning. I also mention some popular, state-of-the-art ASR and TTS architectures used in today’s modern applications.
Demystifying speech AI
Every day, hundreds of billions of audio minutes are generated, whether you are conversing with digital humans in the metaverse or actual humans in contact centers. Speech AI can assist in automating all these audio minutes.
Speech AI includes technologies like ASR, TTS, and related tasks. Interestingly, these technologies are not new and have existed for the last five decades.
Speech recognition evolution
Today, ASR algorithms developed using deep learning techniques can be customized for domain-specific jargon, languages, accents, and dialects, as well as transcribing in noisy environments.
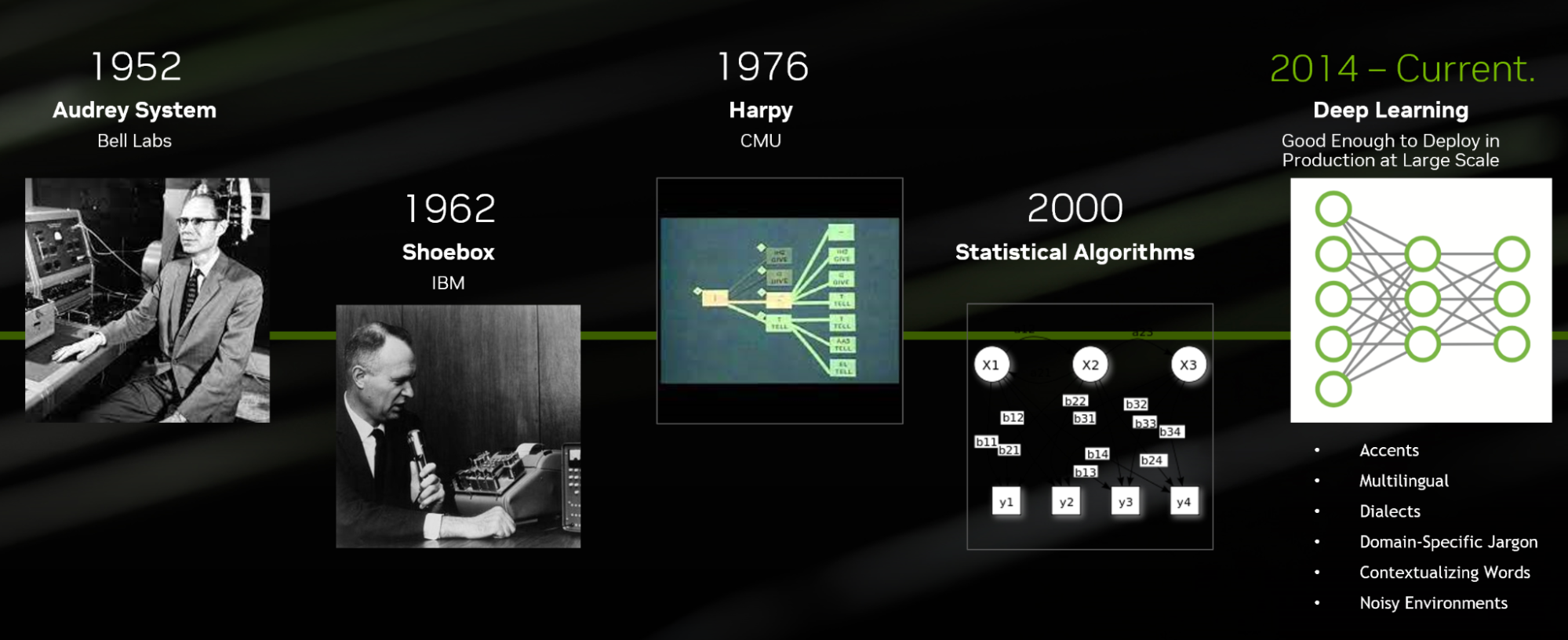
This level of technique differs significantly from the first ASR system, Audrey, which was invented by Bell Labs in 1952. At the time, Audrey could only transcribe numbers and was not developed using deep learning techniques.
Figure 1. Evolution of automatic speech recognition
ASR pipeline
A standard ASR deep learning pipeline consists of a feature extractor, acoustic model, decoder and language model, and BERT punctuation and capitalization model.
Text-to-speech evolution
TTS, or speech synthesis, systems that are developed using deep learning techniques sound like real humans and can run in real time to have natural and meaningful discussions. On the other hand, traditional systems like Voder, DECtalk commercial, and concatenative TTS sound robotic and are difficult to run in real time.
Deep learning TTS algorithms are flexible enough so that you can adjust the speed, pitch, and duration at the inference time to generate more expressive TTS voices.
TTS pipeline
A basic TTS pipeline includes the following components: text normalization, text encoding, pitch/duration predictor, spectrogram generator, and vocoder model.
You can learn more about how ASR and TTS have changed over the past few years and about each of the models and modules in ASR and TTS pipelines in the on-demand video, Speech AI Demystified.
Popular ASR and TTS architectures used today
Several state-of-the-art neural network architectures have been created. Some of the most popular ones in use today for ASR are CTC and transducer-based architecture models. For example, you can apply these architecture techniques to models such as CitriNet and Conformer.
For TTS, different types of architectures exist:
Autoregressive or non-autoregressive
Deterministic or generative
Explicit control or non-explicit control
Each of these TTS architectures offer varying capabilities. For example, deterministic models can predict the outcome exactly and don’t include randomness. Generative models include the data distribution itself and can capture different variations of the synthetic voice. To build an end-to-end text-to-speech pipeline, you must combine one architecture from each category.
You can get the latest architecture best practices to build an ASR and TTS pipeline for your voice-enabled application in the on-demand video, Speech AI Demystified.
NVIDIA Speech AI SDK
You can develop deep learning-based ASR and TTS algorithms by leveraging a GPU-accelerated speech AI SDK. NVIDIA Riva helps you build and deploy customizable AI pipelines that deliver world-class accuracy in all clouds, on-premises, at the edge, and on embedded devices.
Riva has state-of-the-art pretrained models on NGC that are trained on multiple open and proprietary datasets. You can use low-coding tools to customize these models to fit your industry and use case with optimized speech AI skills that can run in real time, without sacrificing accuracy.
Build your first speech AI application
Are you looking to add an interactive voice experience to applications? The following free ebooks will guide your journey:

 Edge computing and edge AI are powering the digital transformation of business processes. But, as a growing field, there are still many questions about what…
Edge computing and edge AI are powering the digital transformation of business processes. But, as a growing field, there are still many questions about what…
 A proof-of-concept (POC) is the first step towards a successful edge AI deployment. Companies adopt edge AI to drive efficiency, automate workflows, reduce…
A proof-of-concept (POC) is the first step towards a successful edge AI deployment. Companies adopt edge AI to drive efficiency, automate workflows, reduce…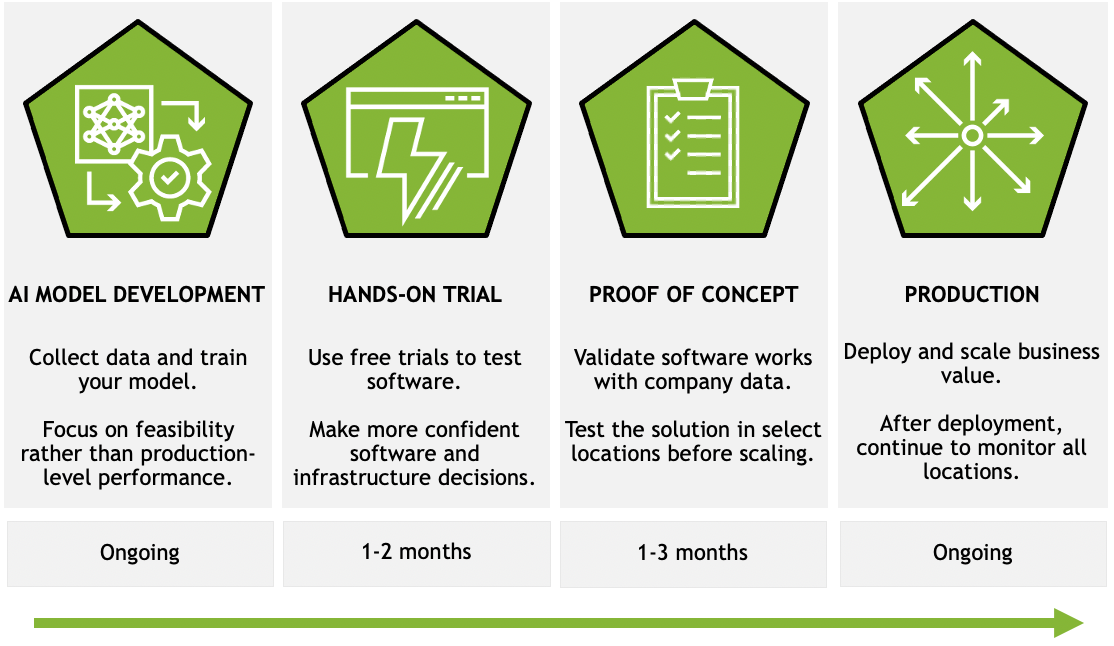
 Nowadays, a huge number of implementations of state-of-the-art (SOTA) models and modeling solutions are present for different frameworks like TensorFlow, ONNX,…
Nowadays, a huge number of implementations of state-of-the-art (SOTA) models and modeling solutions are present for different frameworks like TensorFlow, ONNX,…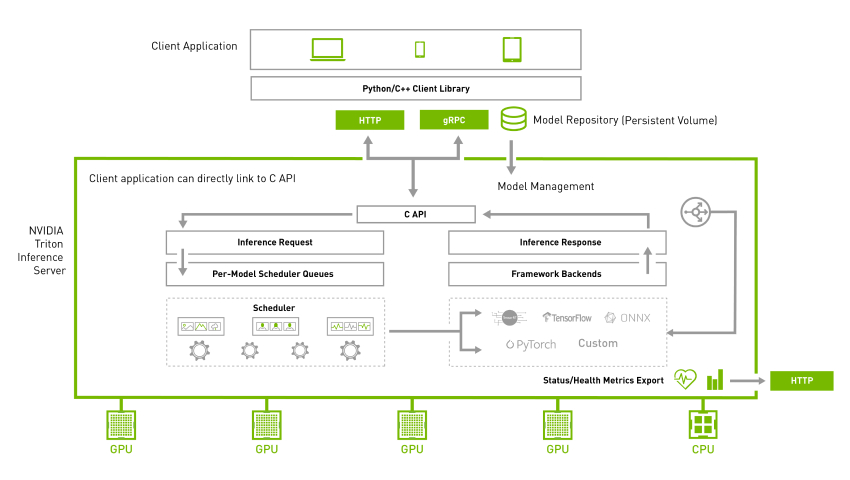



 Examples of what a smart city is can be found in metro IoT deployments from Singapore to Seat Pleasant, Maryland.
Examples of what a smart city is can be found in metro IoT deployments from Singapore to Seat Pleasant, Maryland. Learn how to write simple, portable, parallel-first GPU-accelerated applications using only C++ standard language features in this self-paced course from the…
Learn how to write simple, portable, parallel-first GPU-accelerated applications using only C++ standard language features in this self-paced course from the… From taking your order and serving you food in a restaurant to playing poker with you, service robots are becoming increasingly prevalent. Globally, you can…
From taking your order and serving you food in a restaurant to playing poker with you, service robots are becoming increasingly prevalent. Globally, you can…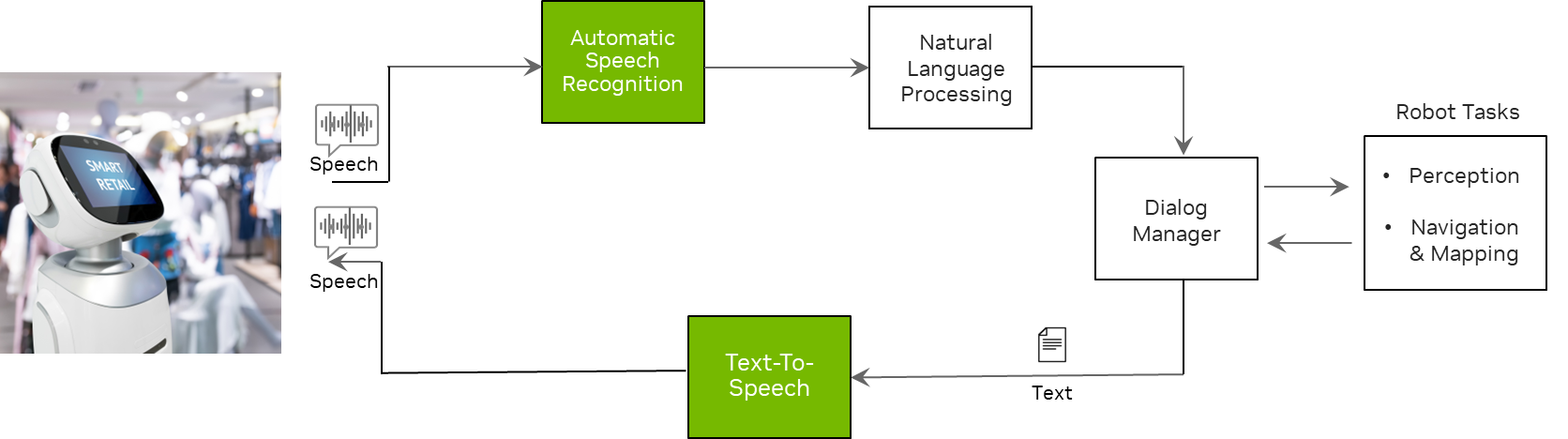
 Speech is one of the primary means to communicate with an AI-powered application. From virtual assistants to digital avatars, voice-based interfaces are…
Speech is one of the primary means to communicate with an AI-powered application. From virtual assistants to digital avatars, voice-based interfaces are…