I can’t seem to find any documentation on how to use this model.
I am trying to use it to print out the objects that appear in a video
any help would be greatly appreciated
submitted by /u/toushi100
[visit reddit] [comments]
 DataBloom
DataBloomI can’t seem to find any documentation on how to use this model.
I am trying to use it to print out the objects that appear in a video
any help would be greatly appreciated
submitted by /u/toushi100
[visit reddit] [comments]
Rearranging objects (such as organizing books on a bookshelf, moving utensils on a dinner table, or pushing piles of coffee beans) is a fundamental skill that can enable robots to physically interact with our diverse and unstructured world. While easy for people, accomplishing such tasks remains an open research challenge for embodied machine learning (ML) systems, as it requires both high-level and low-level perceptual reasoning. For example, when stacking a pile of books, one might consider where the books should be stacked, and in which order, while ensuring that the edges of the books align with each other to form a neat pile.
Across many application areas in ML, simple differences in model architecture can exhibit vastly different generalization properties. Therefore, one might ask whether there are certain deep network architectures that favor simple underlying elements of the rearrangement problem. Convolutional architectures, for example, are common in computer vision as they encode translational invariance, yielding the same response even if an image is shifted, while Transformer architectures are common in language processing because they exploit self-attention to capture long-range contextual dependencies. In robotics applications, one common architectural element is to use object-centric representations such as poses, keypoints, or object descriptors inside learned models, but these representations require additional training data (often manually annotated) and struggle to describe difficult scenarios such as deformables (e.g., playdough), fluids (honey), or piles of stuff (chopped onions).
Today, we present the Transporter Network, a simple model architecture for learning vision-based rearrangement tasks, which appeared as a publication and plenary talk during CoRL 2020. Transporter Nets use a novel approach to 3D spatial understanding that avoids reliance on object-centric representations, making them general for vision-based manipulation but far more sample efficient than benchmarked end-to-end alternatives. As a consequence, they are fast and practical to train on real robots. We are also releasing an accompanying open-source implementation of Transporter Nets together with Ravens, our new simulated benchmark suite of ten vision-based manipulation tasks.
Transporter Networks: Rearranging the Visual World for Robotic Manipulation
The key idea behind the Transporter Network architecture is that one can formulate the rearrangement problem as learning how to move a chunk of 3D space. Rather than relying on an explicit definition of objects (which is bound to struggle at capturing all edge cases), 3D space is a much broader definition for what could serve as the atomic units being rearranged, and can broadly encompass an object, part of an object, or multiple objects, etc. Transporter Nets leverage this structure by capturing a deep representation of the 3D visual world, then overlaying parts of it on itself to imagine various possible rearrangements of 3D space. It then chooses the rearrangements that best match those it has seen during training (e.g., from expert demonstrations), and uses them to parameterize robot actions. This formulation allows Transporter Nets to generalize to unseen objects and enables them to better exploit geometric symmetries in the data, so that they can extrapolate to new scene configurations. Transporter Nets are applicable to a wide variety of rearrangement tasks for robotic manipulation, expanding beyond our earlier models, such as affordance-based manipulation and TossingBot, that focus only on grasping and tossing.
| Transporter Nets capture a deep representation of the visual world, then overlay parts of it on itself to imagine various possible rearrangements of 3D space to find the best one and inform robot actions. |
Ravens Benchmark
To evaluate the performance of Transporter Nets in a consistent environment for fair comparisons to baselines and ablations, we developed Ravens, a benchmark suite of ten simulated vision-based rearrangement tasks. Ravens features a Gym API with a built-in stochastic oracle to evaluate the sample efficiency of imitation learning methods. Ravens avoids assumptions that cannot transfer to a real setup: observation data contains only RGB-D images and camera parameters; actions are end effector poses (transposed into joint positions with inverse kinematics).
Experiments on these ten tasks show that Transporter Nets are orders of magnitude more sample efficient than other end-to-end methods, and are capable of achieving over 90% success on many tasks with just 100 demonstrations, while the baselines struggle to generalize with the same amount of data. In practice, this makes collecting enough demonstrations a more viable option for training these models on real robots (which we show examples of below).
 |
| Our new Ravens benchmark includes ten simulated vision-based manipulation tasks, including pushing and pick-and-place, for which experiments show that Transporter Nets are orders of magnitude more sample efficient than other end-to-end methods. Ravens features a Gym API with a built-in stochastic oracle to evaluate the sample efficiency of imitation learning methods. |
Our new Ravens benchmark includes ten simulated vision-based manipulation tasks, including pushing and pick-and-place, for which experiments show that Transporter Nets are orders of magnitude more sample efficient than other end-to-end methods. Ravens features a Gym API with a built-in stochastic oracle to evaluate the sample efficiency of imitation learning methods.
Highlights
Given 10 example demonstrations, Transporter Nets can learn pick and place tasks such as stacking plates (surprisingly easy to misplace!), multimodal tasks like aligning any corner of a box to a marker on the tabletop, or building a pyramid of blocks.

By leveraging closed-loop visual feedback, Transporter Nets have the capacity to learn various multi-step sequential tasks with a modest number of demonstrations: such as moving disks for Tower of Hanoi, palletizing boxes, or assembling kits of new objects not seen during training. These tasks have considerably “long horizons”, meaning that to solve the task the model must correctly sequence many individual choices. Policies also tend to learn emergent recovery behaviors.

One surprising thing about these results was that beyond just perception, the models were starting to learn behaviors that resemble high-level planning. For example, to solve Towers of Hanoi, the models have to pick which disk to move next, which requires recognizing the state of the board based on the current visible disks and their positions. With a box-palletizing task, the models must locate the empty spaces of the pallet, and identify how new boxes can fit into those voids. Such behaviors are exciting because they suggest that with all the baked-in invariances, the model can focus its capacity on learning the more high-level patterns in manipulation.
Transporter Nets can also learn tasks that use any motion primitive defined by two end effector poses, such as pushing piles of small objects into a target set, or reconfiguring a deformable rope to connect the two end-points of a 3-sided square. This suggests that rigid spatial displacements can serve as useful priors for nonrigid ones.

Conclusion
Transporter Nets bring a promising approach to learning vision-based manipulation, but are not without limitations. For example, they can be susceptible to noisy 3D data, we have only demonstrated them for sparse waypoint-based control with motion primitives, and it remains unclear how to extend them beyond spatial action spaces to force or torque-based actions. But overall, we are excited about this direction of work, and we hope that it provides inspiration for extensions beyond the applications we’ve discussed. For more details, please check out our paper.
Acknowledgements
This research was done by Andy Zeng, Pete Florence, Jonathan Tompson, Stefan Welker, Jonathan Chien, Maria Attarian, Travis Armstrong, Ivan Krasin, Dan Duong, Vikas Sindhwani, and Johnny Lee, with special thanks to Ken Goldberg, Razvan Surdulescu, Daniel Seita, Ayzaan Wahid, Vincent Vanhoucke, Anelia Angelova, Kendra Byrne, for helpful feedback on writing; Sean Snyder, Jonathan Vela, Larry Bisares, Michael Villanueva, Brandon Hurd for operations and hardware support; Robert Baruch for software infrastructure, Jared Braun for UI contributions; Erwin Coumans for PyBullet advice; Laura Graesser for video narration.

I want to get a head combined with a body preserving art style. Or that head generating a body around it (image completion) using a trained model from a dataset.
In short:
Input 1: Single image of a head X in style A
Input 2: Single image of a body Y in style B
Data I have: a lot of same-size images of characters (with heads and bodies) in style B
Output: Single image of body Y with head X in style B (rather seamless, but no need to be perfect)
Couple of days ago I ran into a big list of Google collabs but most don’t describe properly what they do, and the few that do, won’t do what I need.
What application or project do you recommend for this? If it’s a project, will it run on CPU? I’ve got Windows and can install Anaconda.
Bottom line: is there in the very least an application or project that just gets head X into body Y regardless of style?
My experience so far:
In RunwayML I trained a StyleGAN model with art portraits of the same style and size, but after that, it does only image synthesis (creates new random portraits with the same style)😒 . It won’t take an input photo and turn it into a portrait in that style. At a fairly expensive subscription and machine-use fee, I think it offered very little bang for the buck.
Artbreeder portrait tools are better and fees are quite lower, and include using uploaded photos as inputs, mixing photos and creating new “genes” for the faces that may include an art style. However, its portrait tools are limited to heads only, from the neck up. It’s also terrible at preserving features such as piercings, tattoos, horns, elf ears etc.
Big thanks to anyone who might help.
submitted by /u/shadowrunelectric
[visit reddit] [comments]
I defined a model using tf.keras (v2.3.0) and I want to perfrom quantization aware training in this way:
import tensorflow as tf from tensorflow.keras import layers #i tried to replace with tf.python.keras.layers.VersionAwareLayers import tensorflow_model_optimization as tfmot def build_model(): inputs = tf.keras.Input() x = layers.Conv2D(24, 5, 2, 'relu')(inputs) x = layers.BatchNormalization()(x) # more layers... logits = layers.Softmax()(x) model = tf.keras.Model(inputs=inputs, outputs=logits) return model model = build_model() # training code q_aware_model = tfmot.quantization.keras.quantize_model(model)
I get this error:
RuntimeError: Layer batch_normalization_2:<class ‘tensorflow.python.keras.layers.normalization_v2.BatchNormalization’> is not supported. You can quantize this layer by passing a ‘tfmot.quantization.keras.QuantizeConfig’ instance to the ‘quantize_anotate_layer’ API
However, if I define the model as a keras MobilenetV2, which contains the same BatchNormalization layer, everything works fine. Where is the difference? How can I fix this problem?
submitted by /u/fralbalbero
[visit reddit] [comments]

|
I am training a model using tf.Keras. The code is the following.
class CustomCallback(tf.keras.callbacks.Callback): def __init__(self, val_dataset, **kwargs): self.val_dataset = val_dataset super().__init__(**kwargs) def on_train_batch_end(self, batch, logs=None): if batch%1000 == 0: val = self.model.evaluate(self.val_dataset, return_dict=True) print("*** Val accuracy: %.2f ***" % (val['sparse_categorical_accuracy'])) super().on_train_batch_end(batch, logs) ## DATASET ## # Create a dictionary describing the features. image_feature_description = { 'train/label' : tf.io.FixedLenFeature((), tf.int64), 'train/image' : tf.io.FixedLenFeature((), tf.string) } def _parse_image_function(example_proto): # Parse the input tf.train.Example proto using the dictionary above. parsed_features = tf.io.parse_single_example(example_proto, image_feature_description) image = tf.image.decode_jpeg(parsed_features['train/image']) image = tf.image.resize(image, [224,224]) # augmentation image = tf.image.random_flip_left_right(image) image = tf.image.random_brightness(image, 0.2) image = tf.image.random_jpeg_quality(image, 50, 95) image = image/255.0 label = tf.cast(parsed_features['train/label'], tf.int32) return image, label def load_dataset(filenames, labeled=True): ignore_order = tf.data.Options() ignore_order.experimental_deterministic = False # disable order, increase speed dataset = tf.data.TFRecordDataset(filenames) # automatically interleaves reads from multiple files dataset = dataset.with_options(ignore_order) # uses data as soon as it streams in, rather than in its original order dataset = dataset.map(partial(_parse_image_function), num_parallel_calls=AUTOTUNE) return dataset def get_datasets(filenames, labeled=True, BATCH=64): dataset = load_dataset(filenames, labeled=labeled) train_dataset = dataset.skip(2000) val_dataset = dataset.take(2000) train_dataset = train_dataset.shuffle(4096) train_dataset = train_dataset.prefetch(buffer_size=AUTOTUNE) train_dataset = train_dataset.batch(BATCH) val_dataset = val_dataset.batch(BATCH) return train_dataset, val_dataset train_dataset, val_dataset = get_datasets('data/train_224.tfrecords', BATCH=64) ## CALLBACKS ## log_path = './logs/' + datetime.datetime.now().strftime("%Y%m%d-%H%M%S") checkpoint_path = './checkpoints/' + datetime.datetime.now().strftime("%Y%m%d-%H%M%S") tb_callback = tf.keras.callbacks.TensorBoard( log_path, update_freq=100, profile_batch=0) model_checkpoint_callback = tf.keras.callbacks.ModelCheckpoint( filepath=checkpoint_path+'/weights.{epoch:02d}-{accuracy:.2f}.hdf5', save_weights_only=False, save_freq=200) custom_callback = CustomCallback(val_dataset=val_dataset) ## MODEL ## lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay( 0.005, decay_steps=300, decay_rate=0.98, staircase=True ) model = tf.keras.applications.MobileNetV2( include_top=True, weights=None, classes=2, alpha=0.25) model.compile( optimizer=tf.keras.optimizers.RMSprop(learning_rate=lr_schedule), loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False), metrics=['accuracy', 'sparse_categorical_accuracy']) model.fit(train_dataset, epochs=NUM_EPOCHS, shuffle=True, validation_data=val_dataset, validation_steps=None, callbacks=[model_checkpoint_callback, tb_callback, custom_callback]) model.save('model.hdf5')
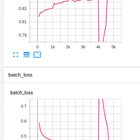
At the end of each epoch I can see a spike in the batch accuracy and loss, as you can see in the figure below. After the spike, the metrics gradually return to previous values and keep improving. What could be the reason for this strange behaviour? submitted by /u/fralbalbero |
I was working off some github code where I’m training a model to recognize laughter. This particular bit of code is giving me problems:
from keras.models import Sequential from keras.layers import Dense, BatchNormalization, Flatten lr_model = Sequential() # lr_model.add(keras.Input((None, 128))) lr_model.add(BatchNormalization(input_shape=(10, 128))) lr_model.add(Flatten()) lr_model.add(Dense(1, activation='sigmoid')) # try using different optimizers and different optimizer configs lr_model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) batch_size=32 CV_frac = 0.1 train_gen = data_generator(batch_size,'../Data/bal_laugh_speech_subset.tfrecord', 0, 1-CV_frac) val_gen = data_generator(128,'../Data/bal_laugh_speech_subset.tfrecord', 1-CV_frac, 1) rec_len = 18768 lr_h = lr_model.fit_generator(train_gen,steps_per_epoch=int(rec_len*(1-CV_frac))//batch_size, epochs=100, validation_data=val_gen, validation_steps=int(rec_len*CV_frac)//128, verbose=0, callbacks=[TQDMNotebookCallback()])
I get the following error:
--------------------------------------------------------------------------- KeyError Traceback (most recent call last) <ipython-input-15-9eced074de11> in <module> 7 rec_len = 18768 8 ----> 9 lr_h = lr_model.fit_generator(train_gen,steps_per_epoch=int(rec_len*(1-CV_frac))//batch_size, epochs=100, 10 validation_data=val_gen, validation_steps=int(rec_len*CV_frac)//128, 11 verbose=0, callbacks=[TQDMNotebookCallback()]) ~/.local/lib/python3.8/site-packages/tensorflow/python/keras/engine/training.py in fit_generator(self, generator, steps_per_epoch, epochs, verbose, callbacks, validation_data, validation_steps, validation_freq, class_weight, max_queue_size, workers, use_multiprocessing, shuffle, initial_epoch) 1845 'will be removed in a future version. ' 1846 'Please use `Model.fit`, which supports generators.') -> 1847 return self.fit( 1848 generator, 1849 steps_per_epoch=steps_per_epoch, ~/.local/lib/python3.8/site-packages/tensorflow/python/keras/engine/training.py in fit(self, x, y, batch_size, epochs, verbose, callbacks, validation_split, validation_data, shuffle, class_weight, sample_weight, initial_epoch, steps_per_epoch, validation_steps, validation_batch_size, validation_freq, max_queue_size, workers, use_multiprocessing) 1103 logs = tmp_logs # No error, now safe to assign to logs. 1104 end_step = step + data_handler.step_increment -> 1105 callbacks.on_train_batch_end(end_step, logs) 1106 if self.stop_training: 1107 break ~/.local/lib/python3.8/site-packages/tensorflow/python/keras/callbacks.py in on_train_batch_end(self, batch, logs) 452 """ 453 if self._should_call_train_batch_hooks: --> 454 self._call_batch_hook(ModeKeys.TRAIN, 'end', batch, logs=logs) 455 456 def on_test_batch_begin(self, batch, logs=None): ~/.local/lib/python3.8/site-packages/tensorflow/python/keras/callbacks.py in _call_batch_hook(self, mode, hook, batch, logs) 294 self._call_batch_begin_hook(mode, batch, logs) 295 elif hook == 'end': --> 296 self._call_batch_end_hook(mode, batch, logs) 297 else: 298 raise ValueError('Unrecognized hook: {}'.format(hook)) ~/.local/lib/python3.8/site-packages/tensorflow/python/keras/callbacks.py in _call_batch_end_hook(self, mode, batch, logs) 314 self._batch_times.append(batch_time) 315 --> 316 self._call_batch_hook_helper(hook_name, batch, logs) 317 318 if len(self._batch_times) >= self._num_batches_for_timing_check: ~/.local/lib/python3.8/site-packages/tensorflow/python/keras/callbacks.py in _call_batch_hook_helper(self, hook_name, batch, logs) 358 if numpy_logs is None: # Only convert once. 359 numpy_logs = tf_utils.to_numpy_or_python_type(logs) --> 360 hook(batch, numpy_logs) 361 362 if self._check_timing: ~/.local/lib/python3.8/site-packages/tensorflow/python/keras/callbacks.py in on_train_batch_end(self, batch, logs) 708 """ 709 # For backwards compatibility. --> 710 self.on_batch_end(batch, logs=logs) 711 712 @doc_controls.for_subclass_implementers ~/env/py385/lib/python3.8/site-packages/keras_tqdm/tqdm_callback.py in on_batch_end(self, batch, logs) 115 self.inner_count += update 116 if self.inner_count < self.inner_total: --> 117 self.append_logs(logs) 118 metrics = self.format_metrics(self.running_logs) 119 desc = self.inner_description_update.format(epoch=self.epoch, metrics=metrics) ~/env/py385/lib/python3.8/site-packages/keras_tqdm/tqdm_callback.py in append_logs(self, logs) 134 135 def append_logs(self, logs): --> 136 metrics = self.params['metrics'] 137 for metric, value in six.iteritems(logs): 138 if metric in metrics: KeyError: 'metrics'
All the other KeyError ‘metrics’ problems I’ve googled have to do with something else called livelossplot. Any help will be much appreciated!
submitted by /u/imstupidfeelbad
[visit reddit] [comments]
Hello there. I’m thinking of using Genetic Algorithm to tune Hyper-parameters of Neural Networks.
Apart form this paper and this blog blog, I don’t find anything that relates with the topic. However there are many GA libraries such as PyGAD etc, but they only apply GA onto weights to fine tune the model instead of finding the best hyper-parameters.
By any chance, anyone here tried anything like this before, as in using GA to find the best hyperparameter in a Tensorflow/Keras Model? Mind share your thoughts?
thanks!
submitted by /u/Obvious-Salad4973
[visit reddit] [comments]
I’m trying to create a DNN classifier and am running into the following error:
Invalid argument: assertion failed: [Labels must be <= n_classes – 1] [Condition x <= y did not hold element-wise:] [x (head/losses/labels:0) = ] [[3][2][4]…] [y (head/losses/check_label_range/Const:0) = ] [4]
I am following the general structure from https://www.tensorflow.org/tutorials/estimator/premade and am not sure what I’m doing wrong.
In my data, there are 255 columns and 4 possible classifications for each row.
I have excluded the imports
training_data = pd.read_csv(data_file)
target_data = pd.read_csv(target_file)
train_y = training_data.pop(‘StateCode’)
target_y = target_data.pop(‘StateCode’)
def input_fn(features, labels, training=True, batch_size=256):
# Convert the inputs to a Dataset.
dataset = tf.data.Dataset.from_tensor_slices((dict(features), labels))
# Shuffle and repeat if you are in training mode.
if training:
dataset = dataset.shuffle(1000).repeat()
return dataset.batch(batch_size)
my_feature_columns = []
for key in training_data.keys():
my_feature_columns.append(tf.feature_column.numeric_column(key=key))
labels = list(training_data.columns)
print(labels)
classifier = tf.estimator.DNNClassifier(
feature_columns=my_feature_columns,
# Two hidden layers of 30 and 10 nodes respectively.
hidden_units=[30, 10],
# The model must choose between 4 classes.
n_classes=4)
classifier.train(
input_fn=lambda: input_fn(training_data, train_y, training=True),
steps=5000)
Any help would be appreciated.
submitted by /u/rk2danker
[visit reddit] [comments]
Hi everyone,
I am trying to use a model saved in .h5 format to analyze a video stream and identify the speed in real time. How do I implement this in Python?
Thank you in advance!
submitted by /u/sleepingmousie
[visit reddit] [comments]
Hey!
I’m following this installation guide for object detection using tensorflow 2, my goal is to train a CNN using my GPU. Tensorflow seems to recognize it after the GPU support section and everything runs smoothly. However, after I install the Object Detection API, tensorflow just starts ignoring it and runs on CPU. Any help would be deeply apreciated, thanks!
submitted by /u/smcsb
[visit reddit] [comments]
{kind=link}