Since 2018, NVIDIA DLSS has leveraged AI to enable gamers and creators to increase performance and crank up their quality. Over time, this solution has evolved…
Since 2018, NVIDIA DLSS has leveraged AI to enable gamers and creators to increase performance and crank up their quality. Over time, this solution has evolved to include groundbreaking advancements in super resolution and frame generation.
Now, the AI neural rendering technology takes the next step forward with DLSS 3.5. This update includes an important new feature called Ray Reconstruction.
Video 1. Learn how DLSS 3.5 works with Bryan Catanzaro, NVIDIA VP of Applied Deep LearningResearch
Ray Reconstruction is a new neural network for all GeForce RTX GPUs that further improves the image quality of ray-traced images. Trained on 5x more data than DLSS 3, DLSS 3.5 replaces hand-tuned denoisers with an NVIDIA supercomputer-trained AI network that generates higher quality pixels in between sampled rays.
Figure 1. AI-powered Ray Reconstruction generates a high-quality ray-traced image in 4K from a 1080p source
Cyberpunk 2077, Cyberpunk 2077: Phantom Liberty, Alan Wake 2, and Portal with RTX, all coming this fall, will include Ray Reconstruction.
Video 2. Ray Reconstruction improves the performance of ray tracing in Cyberpunk 2077 Overdrive Mode
DLSS 3.5 also adds Auto Scene Change Detectionto Frame Generation. This feature aims to automatically prevent Frame Generation from producing difficult-to-create frames between a substantial scene change. It does this by analyzing the in-game camera orientation on every DLSS Frame Generation frame pair.
Auto Scene Change Detection eases integration of new DLSS 3 titles, is backwards compatible with all DLSS 3 integrations, and supports all rendering platforms. In SDK build variants, the scene change detector provides onscreen aids to indicate when a scene change is detected so the developer can pass in the reset flag.
Figure 2.Ray Reconstruction is trained to recognize different ray-traced effects and the quality of temporal and spatial pixels
With these new features, you can achieve even better results with ray tracing, and more effectively manage fast scene changes.
Integration into a custom engine is developer-friendly with the Streamline 2.2 SDK, an open-source cross-IHV framework. Simply identify which resources are required for the decided Streamline plug-in. In the game’s rendering pipeline, you can then trigger when to execute the plug-in.
For Unreal Engine titles, simply install the plug-in into your project and most of the work is done. For a step-by-step guide to integration, see How to Successfully Integrate NVIDIA DLSS 3.
Ray Reconstruction will soon be available to all game developers—sign up to be notified. Auto Scene Change Detection is available now in DLSS 3.5 through the Streamline 2.2 SDK and Unreal Engine plug-in.
Posted by Sergio Boixo and Vadim Smelyanskiy, Principal Scientists, Google Quantum AI Team
A full-scale error-corrected quantum computer will be able to solve some problems that are impossible for classical computers, but building such a device is a huge endeavor. We are proud of the milestones that we have achieved toward a fully error-corrected quantum computer, but that large-scale computer is still some number of years away. Meanwhile, we are using our current noisy quantum processors as flexible platforms for quantum experiments.
In contrast to an error-corrected quantum computer, experiments in noisy quantum processors are currently limited to a few thousand quantum operations or gates, before noise degrades the quantum state. In 2019 we implemented a specific computational task called random circuit sampling on our quantum processor and showed for the first time that it outperformed state-of-the-art classical supercomputing.
Although they have not yet reached beyond-classical capabilities, we have also used our processors to observe novel physical phenomena, such as time crystals and Majorana edge modes, and have made new experimental discoveries, such as robust bound states of interacting photons and the noise-resilience of Majorana edge modes of Floquet evolutions.
We expect that even in this intermediate, noisy regime, we will find applications for the quantum processors in which useful quantum experiments can be performed much faster than can be calculated on classical supercomputers — we call these “computational applications” of the quantum processors. No one has yet demonstrated such a beyond-classical computational application. So as we aim to achieve this milestone, the question is: What is the best way to compare a quantum experiment run on such a quantum processor to the computational cost of a classical application?
We already know how to compare an error-corrected quantum algorithm to a classical algorithm. In that case, the field of computational complexity tells us that we can compare their respective computational costs — that is, the number of operations required to accomplish the task. But with our current experimental quantum processors, the situation is not so well defined.
Plot of computational cost and impact of some recent quantum experiments. While some (e.g., QC-QMC 2022) have had high impact and others (e.g., RCS 2023) have had high computational cost, none have yet been both useful and hard enough to be considered a “computational application.” We hypothesize that our future OTOC experiment could be the first to pass this threshold. Other experiments plotted are referenced in the text.
Random circuit sampling: Evaluating the computational cost of a noisy circuit
When it comes to running a quantum circuit on a noisy quantum processor, there are two competing considerations. On one hand, we aim to do something that is difficult to achieve classically. The computational cost — the number of operations required to accomplish the task on a classical computer — depends on the quantum circuit’s effective quantum volume: the larger the volume, the higher the computational cost, and the more a quantum processor can outperform a classical one.
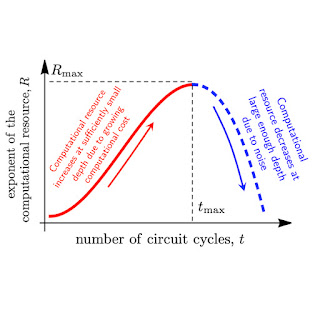
But on the other hand, on a noisy processor, each quantum gate can introduce an error to the calculation. The more operations, the higher the error, and the lower the fidelity of the quantum circuit in measuring a quantity of interest. Under this consideration, we might prefer simpler circuits with a smaller effective volume, but these are easily simulated by classical computers. The balance of these competing considerations, which we want to maximize, is called the “computational resource”, shown below.
Graph of the tradeoff between quantum volume and noise in a quantum circuit, captured in a quantity called the “computational resource.” For a noisy quantum circuit, this will initially increase with the computational cost, but eventually, noise will overrun the circuit and cause it to decrease.
We can see how these competing considerations play out in a simple “hello world” program for quantum processors, known as random circuit sampling (RCS), which was the first demonstration of a quantum processor outperforming a classical computer. Any error in any gate is likely to make this experiment fail. Inevitably, this is a hard experiment to achieve with significant fidelity, and thus it also serves as a benchmark of system fidelity. But it also corresponds to the highest known computational cost achievable by a quantum processor. We recently reported the most powerful RCS experiment performed to date, with a low measured experimental fidelity of 1.7×10-3, and a high theoretical computational cost of ~1023. These quantum circuits had 700 two-qubit gates. We estimate that this experiment would take ~47 years to simulate in the world’s largest supercomputer. While this checks one of the two boxes needed for a computational application — it outperforms a classical supercomputer — it is not a particularly useful application per se.
OTOCs and Floquet evolution: The effective quantum volume of a local observable
There are many open questions in quantum many-body physics that are classically intractable, so running some of these experiments on our quantum processor has great potential. We typically think of these experiments a bit differently than we do the RCS experiment. Rather than measuring the quantum state of all qubits at the end of the experiment, we are usually concerned with more specific, local physical observables. Because not every operation in the circuit necessarily impacts the observable, a local observable’s effective quantum volume might be smaller than that of the full circuit needed to run the experiment.
We can understand this by applying the concept of a light cone from relativity, which determines which events in space-time can be causally connected: some events cannot possibly influence one another because information takes time to propagate between them. We say that two such events are outside their respective light cones. In a quantum experiment, we replace the light cone with something called a “butterfly cone,” where the growth of the cone is determined by the butterfly speed — the speed with which information spreads throughout the system. (This speed is characterized by measuring OTOCs, discussed later.) The effective quantum volume of a local observable is essentially the volume of the butterfly cone, including only the quantum operations that are causally connected to the observable. So, the faster information spreads in a system, the larger the effective volume and therefore the harder it is to simulate classically.
A depiction of the effective volume Veff of the gates contributing to the local observable B. A related quantity called the effective area Aeff is represented by the cross-section of the plane and the cone. The perimeter of the base corresponds to the front of information travel that moves with the butterfly velocity vB.
We apply this framework to a recent experiment implementing a so-called Floquet Ising model, a physical model related to the time crystal and Majorana experiments. From the data of this experiment, one can directly estimate an effective fidelity of 0.37 for the largest circuits. With the measured gate error rate of ~1%, this gives an estimated effective volume of ~100. This is much smaller than the light cone, which included two thousand gates on 127 qubits. So, the butterfly velocity of this experiment is quite small. Indeed, we argue that the effective volume covers only ~28 qubits, not 127, using numerical simulations that obtain a larger precision than the experiment. This small effective volume has also been corroborated with the OTOC technique. Although this was a deep circuit, the estimated computational cost is 5×1011, almost one trillion times less than the recent RCS experiment. Correspondingly, this experiment can be simulated in less than a second per data point on a single A100 GPU. So, while this is certainly a useful application, it does not fulfill the second requirement of a computational application: substantially outperforming a classical simulation.
Information scrambling experiments with OTOCs are a promising avenue for a computational application. OTOCs can tell us important physical information about a system, such as the butterfly velocity, which is critical for precisely measuring the effective quantum volume of a circuit. OTOC experiments with fast entangling gates offer a potential path for a first beyond-classical demonstration of a computational application with a quantum processor. Indeed, in our experiment from 2021 we achieved an effective fidelity of Feff ~ 0.06 with an experimental signal-to-noise ratio of ~1, corresponding to an effective volume of ~250 gates and a computational cost of 2×1012.
While these early OTOC experiments are not sufficiently complex to outperform classical simulations, there is a deep physical reason why OTOC experiments are good candidates for the first demonstration of a computational application. Most of the interesting quantum phenomena accessible to near-term quantum processors that are hard to simulate classically correspond to a quantum circuit exploring many, many quantum energy levels. Such evolutions are typically chaotic and standard time-order correlators (TOC) decay very quickly to a purely random average in this regime. There is no experimental signal left. This does not happen for OTOC measurements, which allows us to grow complexity at will, only limited by the error per gate. We anticipate that a reduction of the error rate by half would double the computational cost, pushing this experiment to the beyond-classical regime.
Conclusion
Using the effective quantum volume framework we have developed, we have determined the computational cost of our RCS and OTOC experiments, as well as a recent Floquet evolution experiment. While none of these meet the requirements yet for a computational application, we expect that with improved error rates, an OTOC experiment will be the first beyond-classical, useful application of a quantum processor.
SANTA CLARA, Calif., Aug. 24, 2023 (GLOBE NEWSWIRE) — NVIDIA will present at the following events for the financial community: Goldman Sachs Communacopia & Technology ConferenceTuesday, Sept. …
Posted by Hattie Zhou, Graduate Student at MILA, Hanie Sedghi, Research Scientist, Google
Large language models (LLMs), such as GPT-3 and PaLM, have shown impressive progress in recent years, which have been driven by scaling up models and training data sizes. Nonetheless, a long standing debate has been whether LLMs can reason symbolically (i.e., manipulating symbols based on logical rules). For example, LLMs are able to perform simple arithmetic operations when numbers are small, but struggle to perform with large numbers. This suggests that LLMs have not learned the underlying rules needed to perform these arithmetic operations.
While neural networks have powerful pattern matching capabilities, they are prone to overfitting to spurious statistical patterns in the data. This does not hinder good performance when the training data is large and diverse and the evaluation is in-distribution. However, for tasks that require rule-based reasoning (such as addition), LLMs struggle with out-of-distribution generalization as spurious correlations in the training data are often much easier to exploit than the true rule-based solution. As a result, despite significant progress in a variety of natural language processing tasks, performance on simple arithmetic tasks like addition has remained a challenge. Even with modest improvement of GPT-4 on the MATH dataset, errors are still largely due to arithmetic and calculation mistakes. Thus, an important question is whether LLMs are capable of algorithmic reasoning, which involves solving a task by applying a set of abstract rules that define the algorithm.
In “Teaching Algorithmic Reasoning via In-Context Learning”, we describe an approach that leverages in-context learning to enable algorithmic reasoning capabilities in LLMs. In-context learning refers to a model’s ability to perform a task after seeing a few examples of it within the context of the model. The task is specified to the model using a prompt, without the need for weight updates. We also present a novel algorithmic prompting technique that enables general purpose language models to achieve strong generalization on arithmetic problems that are more difficult than those seen in the prompt. Finally, we demonstrate that a model can reliably execute algorithms on out-of-distribution examples with an appropriate choice of prompting strategy.
By providing algorithmic prompts, we can teach a model the rules of arithmetic via in-context learning. In this example, the LLM (word predictor) outputs the correct answer when prompted with an easy addition question (e.g., 267+197), but fails when asked a similar addition question with longer digits. However, when the more difficult question is appended with an algorithmic prompt for addition (blue box with white +shown below the word predictor), the model is able to answer correctly. Moreover, the model is capable of simulating the multiplication algorithm (X) by composing a series of addition calculations.
Teaching an algorithm as a skill
In order to teach a model an algorithm as a skill, we develop algorithmic prompting, which builds upon other rationale-augmented approaches (e.g., scratchpad and chain-of-thought). Algorithmic prompting extracts algorithmic reasoning abilities from LLMs, and has two notable distinctions compared to other prompting approaches: (1) it solves tasks by outputting the steps needed for an algorithmic solution, and (2) it explains each algorithmic step with sufficient detail so there is no room for misinterpretation by the LLM.
To gain intuition for algorithmic prompting, let’s consider the task of two-number addition. In a scratchpad-style prompt, we process each digit from right to left and keep track of the carry value (i.e., we add a 1 to the next digit if the current digit is greater than 9) at each step. However, the rule of carry is ambiguous after seeing only a few examples of carry values. We find that including explicit equations to describe the rule of carry helps the model focus on the relevant details and interpret the prompt more accurately. We use this insight to develop an algorithmic prompt for two-number addition, where we provide explicit equations for each step of computation and describe various indexing operations in non-ambiguous formats.
Illustration of various prompt strategies for addition.
Using only three prompt examples of addition with answer length up to five digits, we evaluate performance on additions of up to 19 digits. Accuracy is measured over 2,000 total examples sampled uniformly over the length of the answer. As shown below, the use of algorithmic prompts maintains high accuracy for questions significantly longer than what’s seen in the prompt, which demonstrates that the model is indeed solving the task by executing an input-agnostic algorithm.
Test accuracy on addition questions of increasing length for different prompting methods.
Leveraging algorithmic skills as tool use
To evaluate if the model can leverage algorithmic reasoning in a broader reasoning process, we evaluate performance using grade school math word problems (GSM8k). We specifically attempt to replace addition calculations from GSM8k with an algorithmic solution.
Motivated by context length limitations and possible interference between different algorithms, we explore a strategy where differently-prompted models interact with one another to solve complex tasks. In the context of GSM8k, we have one model that specializes in informal mathematical reasoning using chain-of-thought prompting, and a second model that specializes in addition using algorithmic prompting. The informal mathematical reasoning model is prompted to output specialized tokens in order to call on the addition-prompted model to perform the arithmetic steps. We extract the queries between tokens, send them to the addition-model and return the answer to the first model, after which the first model continues its output. We evaluate our approach using a difficult problem from the GSM8k (GSM8k-Hard), where we randomly select 50 addition-only questions and increase the numerical values in the questions.
An example from the GSM8k-Hard dataset. The chain-of-thought prompt is augmented with brackets to indicate when an algorithmic call should be performed.
We find that using separate contexts and models with specialized prompts is an effective way to tackle GSM8k-Hard. Below, we observe that the performance of the model with algorithmic call for addition is 2.3x the chain-of-thought baseline. Finally, this strategy presents an example of solving complex tasks by facilitating interactions between LLMs specialized to different skills via in-context learning.
Chain-of-thought (CoT) performance on GSM8k-Hard with or without algorithmic call.
Conclusion
We present an approach that leverages in-context learning and a novel algorithmic prompting technique to unlock algorithmic reasoning abilities in LLMs. Our results suggest that it may be possible to transform longer context into better reasoning performance by providing more detailed explanations. Thus, these findings point to the ability of using or otherwise simulating long contexts and generating more informative rationales as promising research directions.
Acknowledgements
We thank our co-authors Behnam Neyshabur, Azade Nova, Hugo Larochelle and Aaron Courville for their valuable contributions to the paper and great feedback on the blog. We thank Tom Small for creating the animations in this post. This work was done during Hattie Zhou’s internship at Google Research.
As part of NVIDIA and Microsoft’s collaboration to bring more choice to gamers, new Microsoft Store integration has been added to GeForce NOW that lets gamers stream select titles from the Xbox PC Game Pass catalog on GeForce NOW, starting today. With the Microsoft Store integration, members will see a brand-new Xbox button on supported Read article >
The NVIDIA DOCA framework aims to simplify the programming and application development for NVIDIA BlueField DPUs and ConnectX SmartNICs. It provides high-level…
The NVIDIA DOCA framework aims to simplify the programming and application development for NVIDIA BlueField DPUs and ConnectX SmartNICs. It provides high-level abstraction building blocks relevant to network applications through an SDK, runtime binaries, and high-level APIs that enable developers to rapidly create applications and services.
NVIDIA DOCA Flow is a newly updated set of software drivers and a steering library in the DOCA Framework. It runs in user space and enables offloading of networking-related operations from the CPU. This in turn enables applications to process high-packet throughput workloads with low latency, conserving CPU resources and reducing power usage.
DOCA Flow also efficiently optimizes the utilization of BlueField DPUs and ConnectX SmartNICs. DOCA is the key to unlocking the potential of BlueField’s acceleration engines, while DOCA Flow grants rapid access to the acceleration engine for packet-steering logic.
Simplify and expedite development
DOCA Flow offers C library APIs for defining hardware-based packet processing pipelines, abstracting the hardware capabilities of BlueField DPUs and ConnectX SmartNICs. This enables developers to construct high-performance and scalable applications for data center and cloud networks, programmatically defining and controlling network traffic flows, implementing network policies, and efficiently managing resources.
DOCA Flow complements and expands upon the core programming capabilities of DPDK, providing additional optimized features tailored specifically for NVIDIA DPUs and NICs. Further, DOCA Flow simplifies the complexities of the networking stack by offering building blocks for implementing basic packet processing pipelines for popular networking use cases, as well as for more sophisticated ones such as Longest Prefix Matching (LPM), Internet Protocol Security (IPsec) encryption or decryption, and creation or modification of entries in the Access Control List (ACL).
Using pre-created networking building blocks enables you to focus on creating your applications instead of writing low-level packet processing routines. This reduces TTM and frees you to focus on the core of your application, as the building blocks are already efficiently optimized for performance. DOCA Flow building blocks make software development easier, and can be used by developers of all experience levels.
Why DPUs are needed
Modern workloads and software-defined networking lead to significant networking overhead on CPU cores. Data centers and cloud networks now start at speeds of 25 or 100 Gbps and scale up to 200 and even 400 Gbps, requiring CPU cores to handle classification, tracking, processing, and steering of network traffic at immense speeds.
Compute virtualization amplifies networking requirements by generating more east/west traffic internally between host VMs and containers, and adding overlay network encapsulation plus microsegmentation to external communication with other servers or storage devices. As a result, much more networking demand is placed on the CPU.
CPU cores come with a significant cost and are not well-suited for efficient network packet processing. High-bandwidth tasks consume more CPU cores, placing unnecessary strain on the server’s valuable compute infrastructure, which could otherwise be utilized more productively for tenant workloads and application data processing.
In contrast, specialized hardware like SmartNICs and DPUs are specifically designed to efficiently handle fast data movement at scale, with reduced power consumption, heat, and overall cost compared to standard CPUs.
Execution pipes
The DOCA Flow library provides APIs that use hardware functions within the BlueField DPU and ConnectX SmartNICs to build generic and reusable execution pipes, where each pipe may consist of match criteria (packet classification) and a set of actions.
Classification enables identifying incoming packets to which logic should be applied, while actions vary and implement the logic that fits each packet’s classification. Using classifications and actions as building blocks provides a flexible method for developing hardware-accelerated network applications including gateways, firewalls, load-balancers, and others.
As mentioned, the actions in the DOCA Flow execution pipe vary and may include, as an example, packet manipulations such as applying Network Address Translation (NAT) logic on MAC addresses, changing source or destination IP addresses, applying overlay network encapsulation, changing header fields, incrementing a counter to measure traffic, and more. Actions may include monitoring traffic through the use of policies, forwarding traffic to different queues–either software queues or hairpin targets, port mirroring or packet sampling for debugging and lawful interception, and dropping packets to enforce policies or access control–all completely offloaded to the DPU or NIC hardware.
Pipes may be chained together through forwarding actions from one pipe to another to form a complete steering tree that defines paths for incoming packets. After executing a predefined action on a packet, the packet may be forwarded to another pipe for further action or inspection, to a software queue, to a hardware hairpin queue, or sent down the wire or dropped.
Figure 1. Pipe chaining constructs network logic, as each pipe handles unique criteria, actions, and forwarding, shaping a steering tree for packet control
Steering trees
A steering tree can be used to create hardware-based network applications on a DPU or NIC by implementing common network function logic. This enables packets to be effectively categorized so the appropriate action can be applied to each one. Using the steering tree concept provides multiple benefits, including:
Customized processing logic for each data flow
Versatility in directing packets to specific actions or destinations
Adaptable structure that’s easily resized for changing conditions
Flexible framework that allows adding new pipe types to meet evolving requirements
Optimized resource use, minimizing redundancy and enabling shared matches and actions
NVIDIA DOCA Flow use cases
When developing network pipelines for BlueField DPUs and ConnectX SmartNICs, DOCA Flow serves as a fundamental element in simplifying application development efforts. Use cases are applicable across enterprise data centers, telco, and cloud environments, particularly those that are focused on network infrastructure and security that require efficient packet processing.
Additionally, it is designed to handle scenarios involving establishing and removing pipelines at an extremely high rate, and can manage millions of packet exchanges per second. This accommodates software-defined networking applications, data analytics, virtual switching, AI inferencing, cybersecurity, and other packet processing applications. It enables operations like ingesting, examining headers and payloads, tracking connections, and inspecting, rerouting, copying, or dropping packets based on predetermined policies or other criteria.
Open vSwitch virtual switching
Open vSwitch (OVS) enables massive network automation through programmatic extension, and is designed to enable efficient network switching in virtualized environments such as virtual machines (VMs) and containers. Through DOCA Flow, a DPU-accelerated virtual switch (vSwitch) can be implemented in the user space data plane, allowing any server with a DPU to act as a network switch, router, or stateful load balancer.
This provides the flexibility of having a vSwitch available to multiple VNFs, while also significantly increasing small packet throughput and reducing latencies, thus expediting and accelerating communication through enhanced networking performance from the DPU and facilitating both north-south traffic for connecting to users, and east-west traffic for AI and distributed applications.
Next-generation firewall
Modern firewalls are required to inspect data at higher rates in order to combat new threats. However, with increased network speeds, more load is placed on the CPU. This can lead to increased latency, dropped packets, and reduced network throughput. To support higher speeds and more stringent security requirements without sacrificing latency is complex and deploying enough traditional firewalls capable of handling the increased traffic is cost-prohibitive.
DOCA Flow enables the development of an intelligent network filter for each server hosting a DPU. With this filter, the parsing and steering of traffic flows is based on predefined policies, with no CPU overhead. It can be used to create a distributed next-generation firewall (NGFW) that can achieve close to 100 Gbps throughput per server by using dedicated accelerators and Arm cores on the DPU to filter and forward packets based on their appropriate flow, as well as managing the data plane offloads and control plane of the NGFW.
Using DOCA Flow can provide a cost-effective solution to offload packet processing from the CPU to the DPU to increase performance and reduce costs beyond traditional hardware solutions. It offers advanced security features, like intrusion prevention, without sacrificing server performance. It also enables faster network flow inspection within the NIC/DPU.
Virtual network functions
DOCA Flow can accelerate virtualized network functions (VNFs), such as routers, load balancers, firewalls, content delivery network (CDN) services, and more. Telco vendors can replace proprietary hardware and execute virtualized workloads on commodity servers by developing VNFs that run on BlueField DPUs.
By using DPUs for VNF acceleration, a more efficient and flexible solution is achieved, leading to reduced equipment, space, heat, and power requirements compared with commodity servers. All this helps resolve limitations based on cooling and space constraints, enabling new opportunities with 5G, AI, IoT, and edge computing.
Edge applications
DOCA Flow is an ideal solution for edge workloads that require high network speeds and I/O processing capabilities, such as content delivery networks and video analytics systems. Host applications for the edge can be designed using DOCA Flow to run on DPUs installed within general-purpose servers, eliminating the need for expensive proprietary hardware appliances. By utilizing the DPUs acceleration and Arm cores, fewer server CPU cores are needed, allowing for smaller servers that consume less energy, require less cooling, and occupy less rack space. This approach offers cost savings in terms of both CapEx and OpEx.
Summary
The DOCA Flow library can be instrumental for developers by simplifying the development of modern applications that offer accelerated network throughput and latency improvements in packet processing. This is especially true for applications replacing proprietary bare-metal hardware solutions with virtualized applications hosted on commercial-off-the-shelf (COTS) server platforms.
The library consists of several building blocks for efficient networking offloads, including implementing basic packet processing pipelines, Longest Prefix Matching (LPM), and Internet Protocol Security (IPsec) encryption or decryption. Enhancements will be added soon to Connection Tracking (CT) and Access Control List (ACL) to create or modify access control entries. For a sampling of DOCA Flow reference applications, see the DOCA Reference Applications documentation.
By harnessing the capabilities of DOCA Flow, organizations can minimize cost, accelerate service deployment, and optimize hardware utilization within use cases that demand high throughput and low latency.
NVIDIA today reported revenue for the second quarter ended July 30, 2023, of $13.51 billion, up 101% from a year ago and up 88% from the previous quarter.
The advent of cloud computing has ushered in a paradigm shift in our data storage and utilization practices. Businesses can bypass the complexities of managing…
The advent of cloud computing has ushered in a paradigm shift in our data storage and utilization practices. Businesses can bypass the complexities of managing their own computing infrastructure by tapping into remote, on-demand resources deftly managed by cloud service providers. Yet, there exists a palpable apprehension about sharing sensitive information with the cloud.
While traditional cryptographic methods such as AES can help preserve data privacy, they stifle the cloud’s capacity to undertake meaningful operations on the data. In an encryption system, a message, also referred to as plaintext, is transformed using a key into a scrambled version known as ciphertext. The encryption methods in place assure that malicious entities can’t decrypt the message without the correct key and can’t gain access to its contents. Without decryption, a ciphertext is essentially nonsensical.
Fortunately, there is a solution: fully homomorphic encryption (FHE), a sophisticated and potent encryption technique. It serves as a comprehensive shield for data, whether in transit, at rest, or in use. Homomorphic encryption is a unique design that enables operations to be performed on the ciphertext while still preserving its security. This type of operation modifies a ciphertext in such a way that, after decryption, the result is the same as if the operation was carried out on the plaintext itself.
Frequently referred to as the ultimate goal of cryptography, FHE can carry out any computational function on the ciphertext. This remarkable technology has the capability to run thousands of algorithms directly on encrypted data, all without compromising the underlying plaintext. It confronts the pivotal privacy issues linked with cloud computing head-on, while simultaneously enabling intricate outsourced computations.
However, operations performed with FHE encryption tend to be slower than those conducted over standard unencrypted data. Also, the current applications of this technology can be somewhat challenging for non-specialists to set up and manage effectively.
ArctyrEX: Accelerated encrypted execution
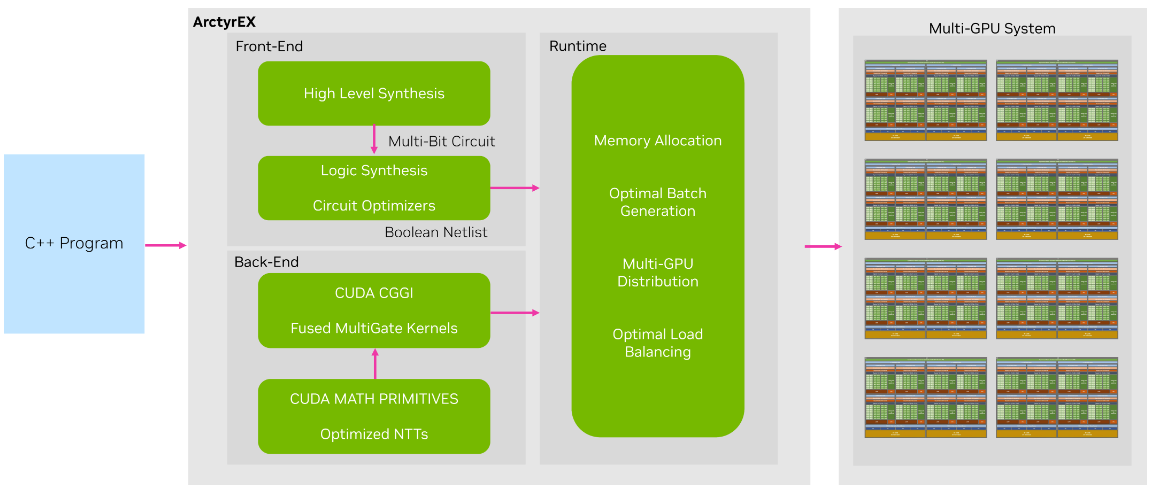
A recent effort by NVIDIA Research aims to address the efficiency problems associated with encrypted computing. The proposed solution, ArctyrEX, is an end-to-end framework that enables you to specify algorithms in C++ using standard data types and automatically convert this algorithm into an FHE representation that can be launched on arbitrary numbers of GPUs for efficient evaluation.
Figure 1. ArctyrEX system overview
ArctyrEX is composed of three parts:
A frontend responsible for converting input programs to the encrypted domain
A runtime library that sends encrypted workloads to GPU workers
A backend that consists of an implementation of the state-of-the-art CGGI cryptosystem.
The CGGI cryptosystem encrypts single bits of plaintext and enables encrypted Boolean operations between ciphertexts. Therefore, the programming model for CGGI is akin to constructing Boolean circuits composed of logic gates. For more information, see TFHE: Fast Fully Homomorphic Encryption over the Torus and TFHE.
The frontend takes advantage of decades of hardware development research to convert C++ programs to equivalent Verilog files, which provide a description of a circuit at a high level of abstraction. Then it converts the files to optimal Boolean circuits. This process uses well-established techniques in the form of high-level synthesis (HLS) and register-transfer level (RTL) or logic synthesis.
The ArctyrEX runtime library takes the generated Boolean circuit, divides it into distinct levels, and creates batches of approximately identical size to distribute to GPU workers. In some cases, the ciphertexts corresponding to an output wire of a gate at an intermediate level may have to serve as input to a workload assigned to a different GPU during the next level. ArctyrEX is capable of seamlessly coordinating these transfers efficiently.
Lastly, the ArctyrEX backend consists of an optimized CUDA kernel capable of executing batches of gates concurrently while minimizing CPU-GPU synchronizations. The output is composed of a set of ciphertexts that represent the output wires of the gates in the assigned batch.
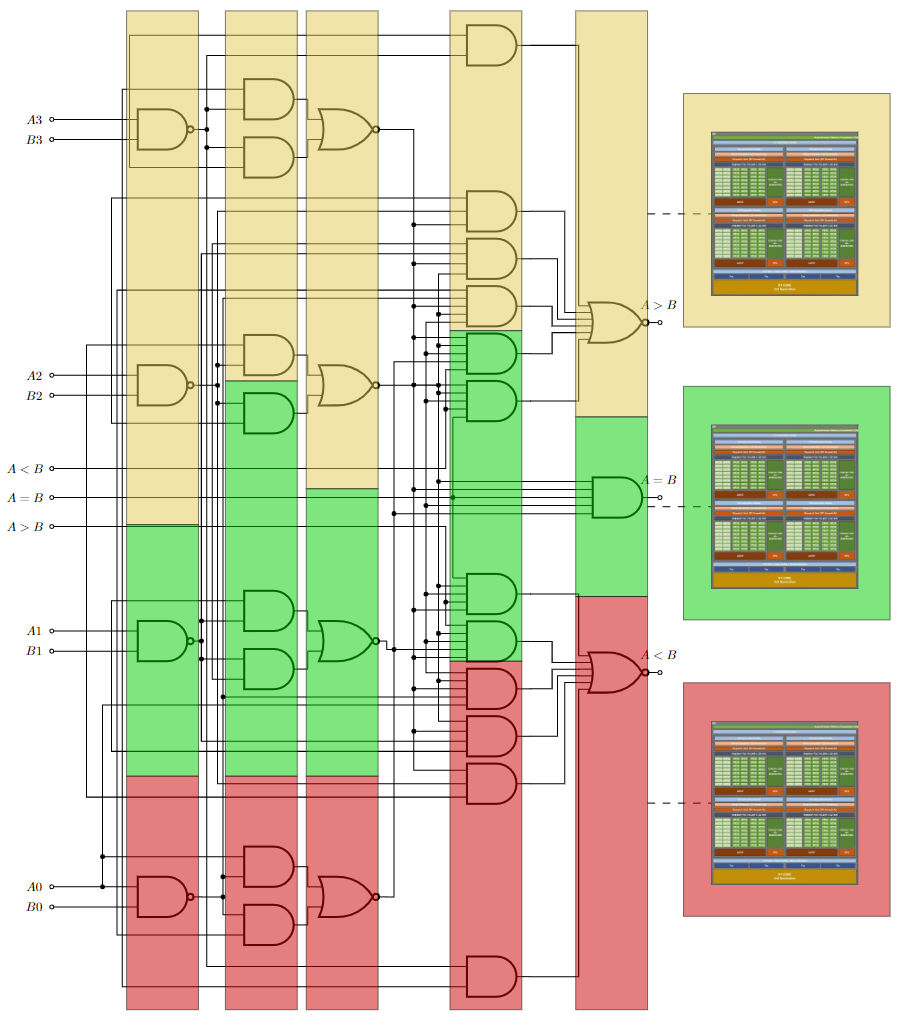
Figure 2. ArctyrEX runtime mapping gates to devices
Run programs with ArctyrEX up to 40x faster
ArctyrEX shows great scalability with the use of more GPUs for two key reasons:
Abundant primitive-level parallelism that is a natural trait of most FHE operations.
Circuit-level parallelism, which is a characteristic commonly displayed in Boolean circuits.
To attain speedy evaluation with Boolean FHE, the circuit must have wide levels, meaning that there should be many gates that can operate simultaneously, and it should have a minimal critical path. To show this, compare an encrypted dot product operation between two vectors with an encrypted vector addition operation.
To actualize these programs in ArctyrEX, you can write C++ code at a high level in an intuitive manner. Here, the pragma is necessary to unroll the loop before the HLS pass. You can employ HLS tools like Google XLS, which are designed to make digital design more approachable and efficient. XLS provides the means to specify digital logic at a higher level like C++ than traditional hardware description languages (like Verilog or VHDL), making the entire process simpler and more efficient.
As an example, observe the differences between an encrypted dot product between two vectors and an encrypted vector addition. To implement these programs in ArctyrEX, you can intuitively write high-level C++ code in the following way, where the pragma is required to unroll the loop before the HLS pass handled by Google XLS:
void vector_addition(int x[500], int y[500], int z[500]) {
#pragma hls_unroll yes
for (int i =0; i
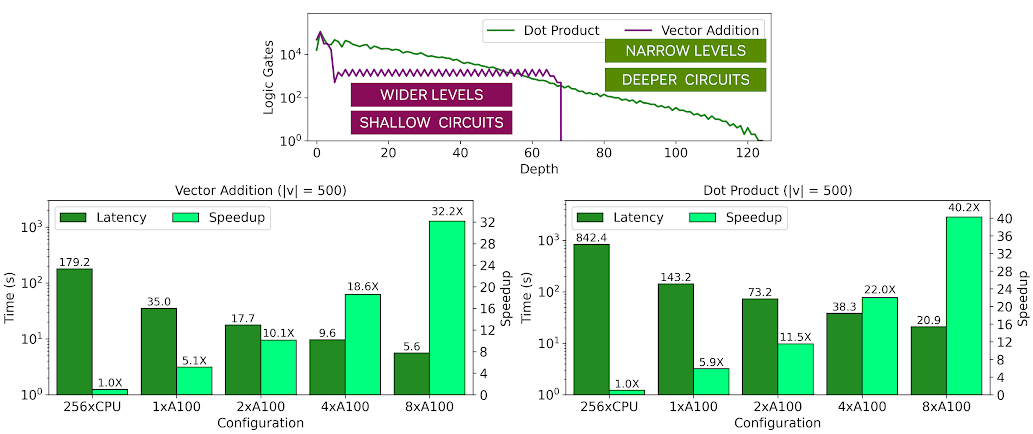
Figure 3. ArctyrEX vector algebra benchmarks
Figure 3 shows the characteristics of both circuits, specifically the number of logic gates at each level of the circuit. In the chart, |v| indicates the vector length and M refers to the dimensions of the matrices. You can see that a dot product of two vectors has a higher critical path with a depth of approximately 120 levels and the width of subsequent levels decreases gradually, limiting the parallelism possible to exploit in the later stages of the circuit.
On the other hand, vector addition has a critical path that is approximately 2x shorter than the dot product, and the width of each level remains relatively constant. As a result, the vector addition runs approximately 4x faster than the dot product, although both exhibit high speedups over a parallel CPU baseline with multiple GPUs. These interesting performance trends are shown in the topology graphs earlier. The light green bars show the speedup relative to a 256-threaded CPU baseline while the dark green bars show the execution time of the homomorphic application.
Summary
In summary, ArctyrEX represents a comprehensive solution for encrypted computation across various applications, harnessing the power of GPU acceleration and implementing innovative techniques for efficient FHE algorithm execution. Tasks like neural network inference demonstrate linear acceleration with the augmentation of GPUs, attributed to the inherent circuit-level parallelism, the newly introduced dispatch paradigm, and the extensive primitive-level parallelism harnessed by the CUDA-accelerated CGGI backend.
We thank all authors of ArctyrEX for their contributions, especially Charles Gouert (Ph.D. candidate) and Prof. Nektarios Georgios Tsoutsos from the University of Delaware. We’d also like to thank members of Zama, CryptoLab, Google, and Duality Tech for their insightful discussions, particularly Ilaria Chillotti, Jung Hee Cheon, Ahmad Al Badawi, Yuri Polyakov, David Cousins, Shruti Gorantala, and Eric Astor.
Posted by Wenhao Yu and Fei Xia, Research Scientists, Google
Empowering end-users to interactively teach robots to perform novel tasks is a crucial capability for their successful integration into real-world applications. For example, a user may want to teach a robot dog to perform a new trick, or teach a manipulator robot how to organize a lunch box based on user preferences. The recent advancements in large language models (LLMs) pre-trained on extensive internet data have shown a promising path towards achieving this goal. Indeed, researchers have explored diverse ways of leveraging LLMs for robotics, from step-by-step planning and goal-oriented dialogue to robot-code-writing agents.
While these methods impart new modes of compositional generalization, they focus on using language to link together new behaviors from an existing library of control primitives that are either manually engineered or learned a priori. Despite having internal knowledge about robot motions, LLMs struggle to directly output low-level robot commands due to the limited availability of relevant training data. As a result, the expression of these methods are bottlenecked by the breadth of the available primitives, the design of which often requires extensive expert knowledge or massive data collection.
In “Language to Rewards for Robotic Skill Synthesis”, we propose an approach to enable users to teach robots novel actions through natural language input. To do so, we leverage reward functions as an interface that bridges the gap between language and low-level robot actions. We posit that reward functions provide an ideal interface for such tasks given their richness in semantics, modularity, and interpretability. They also provide a direct connection to low-level policies through black-box optimization or reinforcement learning (RL). We developed a language-to-reward system that leverages LLMs to translate natural language user instructions into reward-specifying code and then applies MuJoCo MPC to find optimal low-level robot actions that maximize the generated reward function. We demonstrate our language-to-reward system on a variety of robotic control tasks in simulation using a quadruped robot and a dexterous manipulator robot. We further validate our method on a physical robot manipulator.
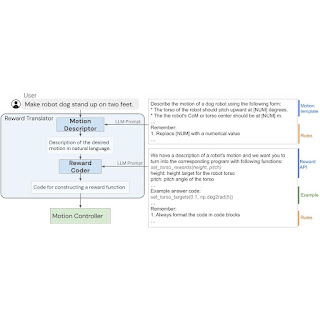
The language-to-reward system consists of two core components: (1) a Reward Translator, and (2) a Motion Controller. TheReward Translator maps natural language instruction from users to reward functions represented as python code. The Motion Controller optimizes the given reward function using receding horizon optimization to find the optimal low-level robot actions, such as the amount of torque that should be applied to each robot motor.
LLMs cannot directly generate low-level robotic actions due to lack of data in pre-training dataset. We propose to use reward functions to bridge the gap between language and low-level robot actions, and enable novel complex robot motions from natural language instructions.
Reward Translator: Translating user instructions to reward functions
The Reward Translator module was built with the goal of mapping natural language user instructions to reward functions. Reward tuning is highly domain-specific and requires expert knowledge, so it was not surprising to us when we found that LLMs trained on generic language datasets are unable to directly generate a reward function for a specific hardware. To address this, we apply the in-context learning ability of LLMs. Furthermore, we split the Reward Translator into two sub-modules: Motion Descriptor and Reward Coder.
Motion Descriptor
First, we design a Motion Descriptor that interprets input from a user and expands it into a natural language description of the desired robot motion following a predefined template. This Motion Descriptor turns potentially ambiguous or vague user instructions into more specific and descriptive robot motions, making the reward coding task more stable. Moreover, users interact with the system through the motion description field, so this also provides a more interpretable interface for users compared to directly showing the reward function.
To create the Motion Descriptor, we use an LLM to translate the user input into a detailed description of the desired robot motion. We design prompts that guide the LLMs to output the motion description with the right amount of details and format. By translating a vague user instruction into a more detailed description, we are able to more reliably generate the reward function with our system. This idea can also be potentially applied more generally beyond robotics tasks, and is relevant to Inner-Monologue and chain-of-thought prompting.
Reward Coder
In the second stage, we use the same LLM from Motion Descriptor for Reward Coder, which translates generated motion description into the reward function. Reward functions are represented using python code to benefit from the LLMs’ knowledge of reward, coding, and code structure.
Ideally, we would like to use an LLM to directly generate a reward function R (s, t) that maps the robot state s and time t into a scalar reward value. However, generating the correct reward function from scratch is still a challenging problem for LLMs and correcting the errors requires the user to understand the generated code to provide the right feedback. As such, we pre-define a set of reward terms that are commonly used for the robot of interest and allow LLMs to composite different reward terms to formulate the final reward function. To achieve this, we design a prompt that specifies the reward terms and guide the LLM to generate the correct reward function for the task.
The internal structure of the Reward Translator, which is tasked to map user inputs to reward functions.
Motion Controller: Translating reward functions to robot actions
The Motion Controller takes the reward function generated by the Reward Translator and synthesizes a controller that maps robot observation to low-level robot actions. To do this, we formulate the controller synthesis problem as a Markov decision process (MDP), which can be solved using different strategies, including RL, offline trajectory optimization, or model predictive control (MPC). Specifically, we use an open-source implementation based on the MuJoCo MPC (MJPC).
MJPC has demonstrated the interactive creation of diverse behaviors, such as legged locomotion, grasping, and finger-gaiting, while supporting multiple planning algorithms, such as iterative linear–quadratic–Gaussian (iLQG) and predictive sampling. More importantly, the frequent re-planning in MJPC empowers its robustness to uncertainties in the system and enables an interactive motion synthesis and correction system when combined with LLMs.
Examples
Robot dog
In the first example, we apply the language-to-reward system to a simulated quadruped robot and teach it to perform various skills. For each skill, the user will provide a concise instruction to the system, which will then synthesize the robot motion by using reward functions as an intermediate interface.
Dexterous manipulator
We then apply the language-to-reward system to a dexterous manipulator robot to perform a variety of manipulation tasks. The dexterous manipulator has 27 degrees of freedom, which is very challenging to control. Many of these tasks require manipulation skills beyond grasping, making it difficult for pre-designed primitives to work. We also include an example where the user can interactively instruct the robot to place an apple inside a drawer.
Validation on real robots
We also validate the language-to-reward method using a real-world manipulation robot to perform tasks such as picking up objects and opening a drawer. To perform the optimization in Motion Controller, we use AprilTag, a fiducial marker system, and F-VLM, an open-vocabulary object detection tool, to identify the position of the table and objects being manipulated.
Conclusion
In this work, we describe a new paradigm for interfacing an LLM with a robot through reward functions, powered by a low-level model predictive control tool, MuJoCo MPC. Using reward functions as the interface enables LLMs to work in a semantic-rich space that plays to the strengths of LLMs, while ensuring the expressiveness of the resulting controller. To further improve the performance of the system, we propose to use a structured motion description template to better extract internal knowledge about robot motions from LLMs. We demonstrate our proposed system on two simulated robot platforms and one real robot for both locomotion and manipulation tasks.
Acknowledgements
We would like to thank our co-authors Nimrod Gileadi, Chuyuan Fu, Sean Kirmani, Kuang-Huei Lee, Montse Gonzalez Arenas, Hao-Tien Lewis Chiang, Tom Erez, Leonard Hasenclever, Brian Ichter, Ted Xiao, Peng Xu, Andy Zeng, Tingnan Zhang, Nicolas Heess, Dorsa Sadigh, Jie Tan, and Yuval Tassa for their help and support in various aspects of the project. We would also like to acknowledge Ken Caluwaerts, Kristian Hartikainen, Steven Bohez, Carolina Parada, Marc Toussaint, and the greater teams at Google DeepMind for their feedback and contributions.

 Since 2018, NVIDIA DLSS has leveraged AI to enable gamers and creators to increase performance and crank up their quality. Over time, this solution has evolved…
Since 2018, NVIDIA DLSS has leveraged AI to enable gamers and creators to increase performance and crank up their quality. Over time, this solution has evolved…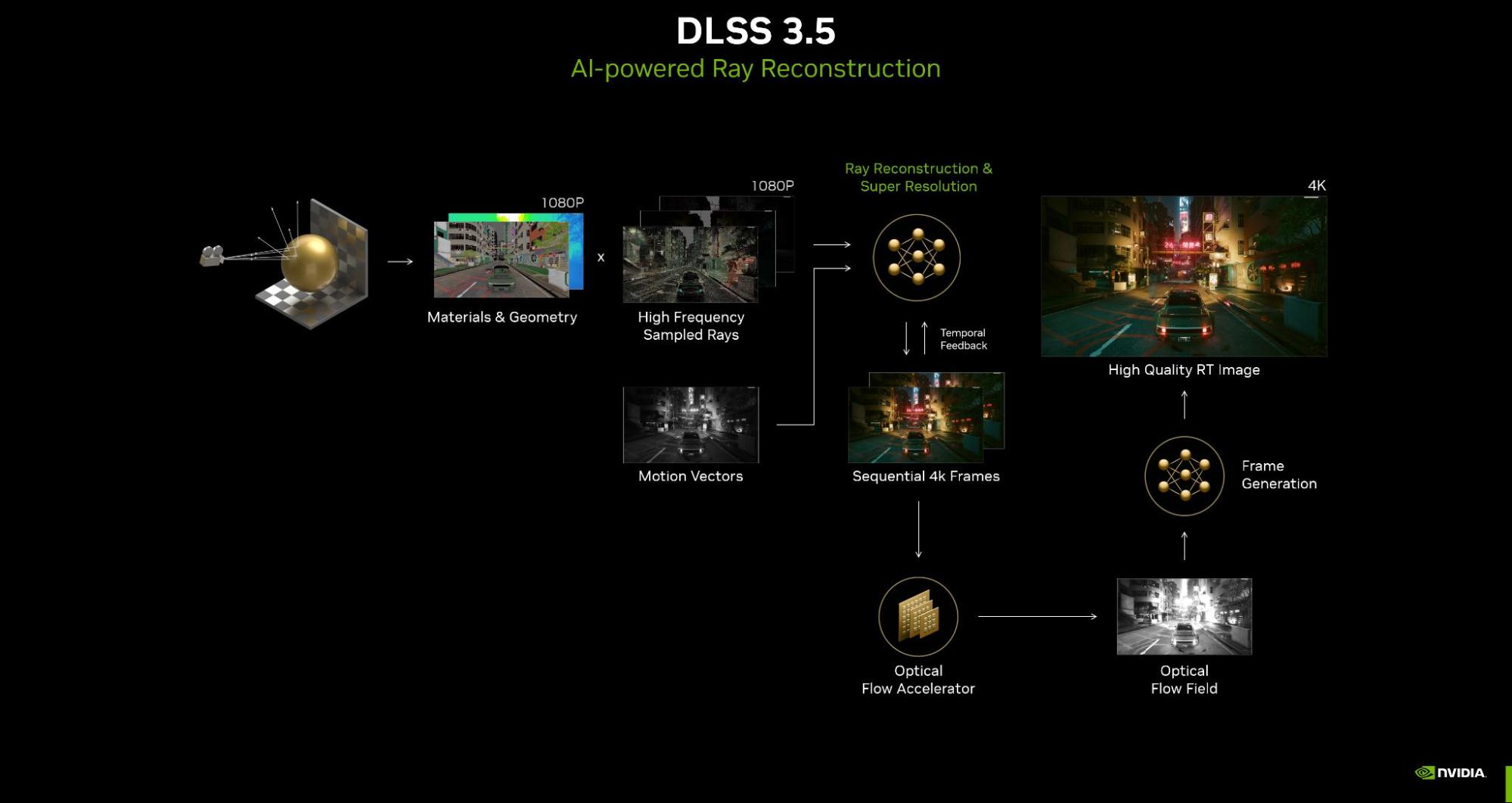









 The NVIDIA DOCA framework aims to simplify the programming and application development for NVIDIA BlueField DPUs and ConnectX SmartNICs. It provides high-level…
The NVIDIA DOCA framework aims to simplify the programming and application development for NVIDIA BlueField DPUs and ConnectX SmartNICs. It provides high-level…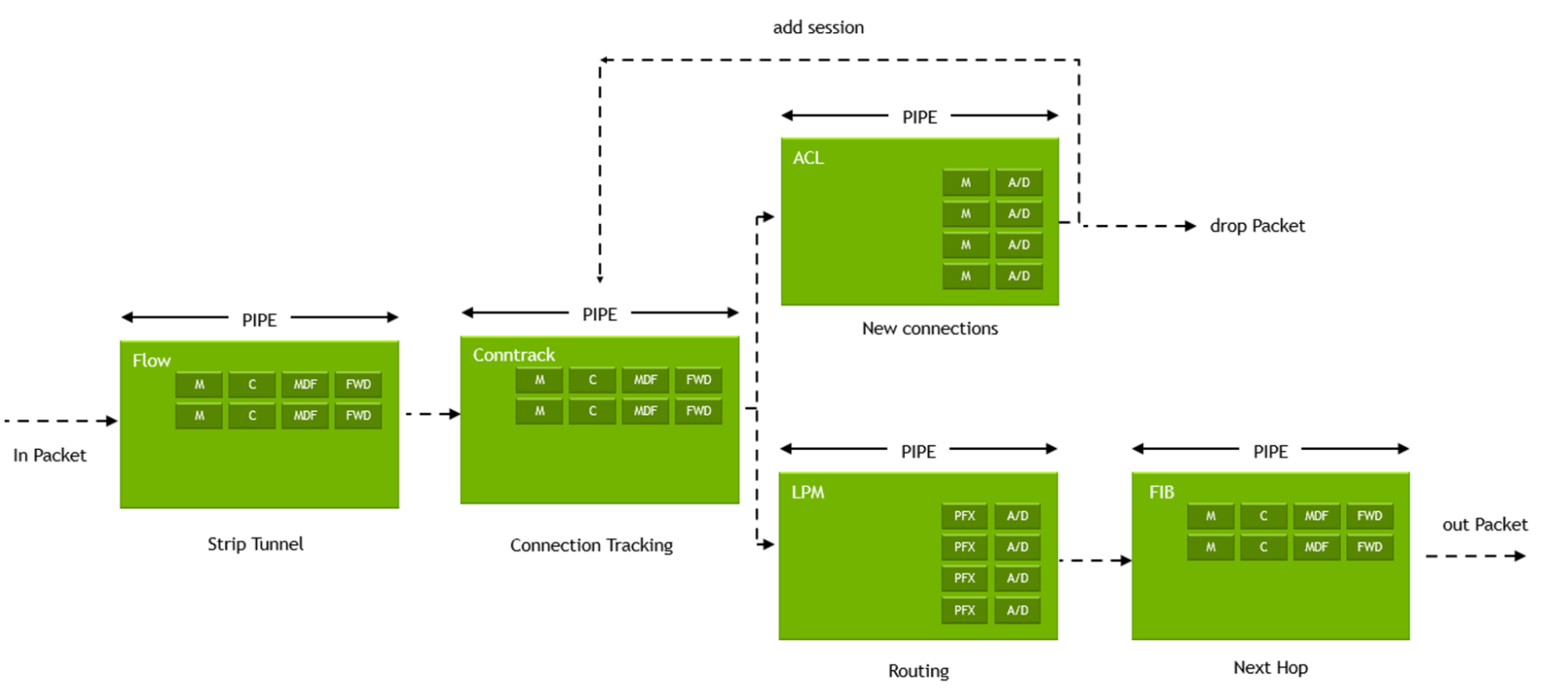
 Delve into how TMA Solutions is accelerating original ML and AI workflows with RAPIDS.
Delve into how TMA Solutions is accelerating original ML and AI workflows with RAPIDS. The advent of cloud computing has ushered in a paradigm shift in our data storage and utilization practices. Businesses can bypass the complexities of managing…
The advent of cloud computing has ushered in a paradigm shift in our data storage and utilization practices. Businesses can bypass the complexities of managing…