
OVX Servers Feature New NVIDIA GPUs to Accelerate Training and Inference, Graphics-Intensive Workloads; Coming Soon From Dell Technologies, Hewlett Packard Enterprise, Lenovo, Supermicro and …
New Platform Updates, Connections to Adobe Firefly, OpenUSD to RealityKit, Ada-Generation Systems Accelerate Interoperable 3D Workflows and Industrial DigitalizationLOS ANGELES, Aug. 08, 2023 …
 Generative AI has introduced a new era in computing, one promising to revolutionize human-computer interaction. At the forefront of this technological marvel…
Generative AI has introduced a new era in computing, one promising to revolutionize human-computer interaction. At the forefront of this technological marvel…
Generative AI has introduced a new era in computing, one promising to revolutionize human-computer interaction. At the forefront of this technological marvel are large language models (LLMs), empowering enterprises to recognize, summarize, translate, predict, and generate content using large datasets. However, the potential of generative AI for enterprises comes with its fair share of challenges.
Cloud services powered by general-purpose LLMs provide a quick way to get started with generative AI technology. However, these services are often focused on a broad set of tasks and are not trained on domain-specific data, limiting their value for certain enterprise applications. This leads many organizations to build their own solutions—a difficult task—as they must piece together various open-source tools, ensure compatibility, and provide their own support.
NVIDIA NeMo provides an end-to-end platform designed to streamline LLM development and deployment for enterprises, ushering in a transformative age of AI capabilities. NeMo equips you with the essential tools to create enterprise-grade, production-ready custom LLMs. The suite of NeMo tools simplifies the process of data curation, training, and deployment, facilitating the swift development of customized AI applications tailored to each organization’s specific requirements.
For enterprises banking on AI for their business operations, NVIDIA AI Enterprise presents a secure, end-to-end software platform. Combining NeMo with generative AI reference applications and enterprise support, NVIDIA AI Enterprise streamlines the adoption process, paving the way for seamless integration of AI capabilities.
End-to-end platform for production-ready generative AI
The NeMo framework simplifies the path to building customized, enterprise-grade generative AI models by providing end-to-end capabilities and containerized recipes for various model architectures.
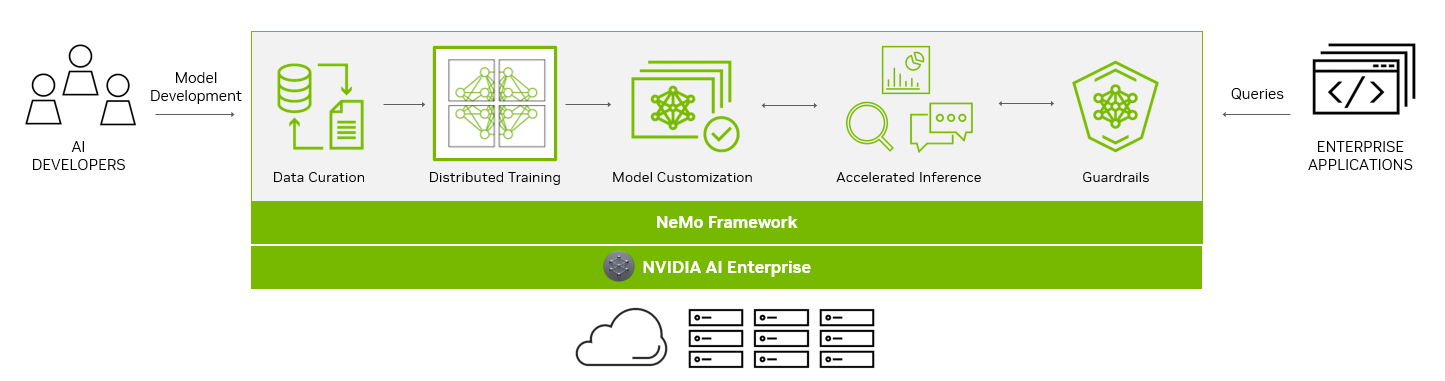
To aid you in creating LLMs, the NeMo framework provides powerful tools:
- Data curation
- Distributed training at scale
- Pretrained models for customization
- Accelerated inference
- Guardrails
Data curation
In the rapidly evolving landscape of AI, the demand for extensive datasets has become a critical factor in building robust LLMs.
The NeMo framework streamlines the often-complex process of data curation with NeMo Data Curator, which addresses the challenges of curating trillions of tokens in multilingual datasets. Through its scalability, this tool empowers you to effortlessly handle tasks like data download, text extraction, cleaning, filtering, and exact or fuzzy deduplication.
By harnessing the power of cutting-edge technologies, including Message-Passing Interface (MPI), Dask, and Redis Cluster, Data Curator can scale data-curation processes across thousands of compute cores, significantly reducing manual efforts and accelerating the development workflow.
One of the key benefits of Data Curator lies in its deduplication feature. By ensuring that LLMs are trained on unique documents, you can avoid redundant data and potentially achieve substantial cost savings during the pretraining phase. This not only streamlines the model development process but also optimizes AI investments for organizations, making AI development more accessible and cost-effective.
Data Curator comes packaged in the NeMo training container available through NGC.
Distributed training at scale
Training billion-parameter LLM models from scratch presents unique challenges of acceleration and scale. The process demands massive, distributed computing power, clusters of acceleration-based hardware and memory, reliable and scalable machine learning (ML) frameworks, and fault-tolerant systems.
At the heart of the NeMo framework lies the unification of distributed training and advanced parallelism. NeMo expertly uses GPU resources and memory across nodes, leading to groundbreaking efficiency gains. By dividing the model and training data, NeMo enables seamless multi-node and multi-GPU training, significantly reducing training time and enhancing overall productivity.
A standout feature of NeMo is its incorporation of various parallelism techniques:
- Data parallelism
- Tensor parallelism
- Pipeline parallelism
- Sequence parallelism
- Sparse attention reduction (SAR).
These techniques work in tandem to optimize the training process, thereby maximizing resource usage and bolstering performance.
NeMo also offers an array of precision options:
- FP32/TF32
- BF16
- FP8
Groundbreaking innovations like FlashAttention and Rotary Positional Embedding (RoPE) cater to long sequence-length tasks. Attention with Linear Biases (ALiBi), gradient and partial checkpointing, and the Distributed Adam Optimizer further elevate model performance and speed.
Pretrained models for customization
While some generative AI use cases require training from scratch, more and more organizations are using pretrained models to jump-start their effort when building customized LLMs.
One of the most significant benefits of pretrained models is the savings in time and resources. By skipping the data collection and cleaning phases required to pre-train the generic LLM, you can focus on fine-tuning models to their specific needs, accelerating the time to the final solution. Moreover, the burden of infrastructure setup and model training is greatly reduced, as pretrained models come with pre-existing knowledge, ready to be customized.
Thousands of open-source models are also available on hubs like GitHub, Hugging Face, and others, so you have choices when it comes to which model to start with. Accuracy is one of the more common measurements to evaluate pretrained models, but there are also other considerations:
- Size
- Cost to fine-tune
- Latency
- Memory constraints
- Commercial licensing options
With NeMo, you can now access a wide range of pretrained models, from NVIDIA and popular open-source repositories like Falcon AI, Llama-2, and MPT 7B.
NeMo models are optimized for inference, making them ideal for production use cases. With the ability to deploy these models in real-world applications, you can drive transformative outcomes and unlock the full potential of AI for your organizations.
Model customization
Customization of ML models is rapidly evolving to accommodate the unique needs of businesses and industries. The NeMo framework offers an array of techniques to refine generic, pretrained LLMs for specialized use cases. Through these diverse customization options, NeMo offers wide-ranging flexibility that is crucial in meeting varying business requirements.
Prompt engineering is an efficient customization method that makes it possible to use pretrained LLMs on many downstream tasks without needing to tune the pretrained models’ parameters. The goal of prompt engineering is to design and optimize prompts that are specific and clear enough to elicit the desired output from the model.
P-tuning and prompt tuning are parameter-efficient fine-tuning (PETF) techniques that use clever optimizations to selectively update only a few parameters of the LLM. As implemented in NeMo, new tasks can be added to a model without overwriting or disrupting previous tasks for which the model has already been tuned.
NeMo has optimized its p-tuning methods for use on multi-GPU and multi-node environments enabling accelerated training. NeMo p-tuning also supports an ‘early stop’ mechanism that identifies when a model has converged to the point when further training won’t improve accuracy much. It then stops the training job. This technique reduces the time and resources needed to customize models.
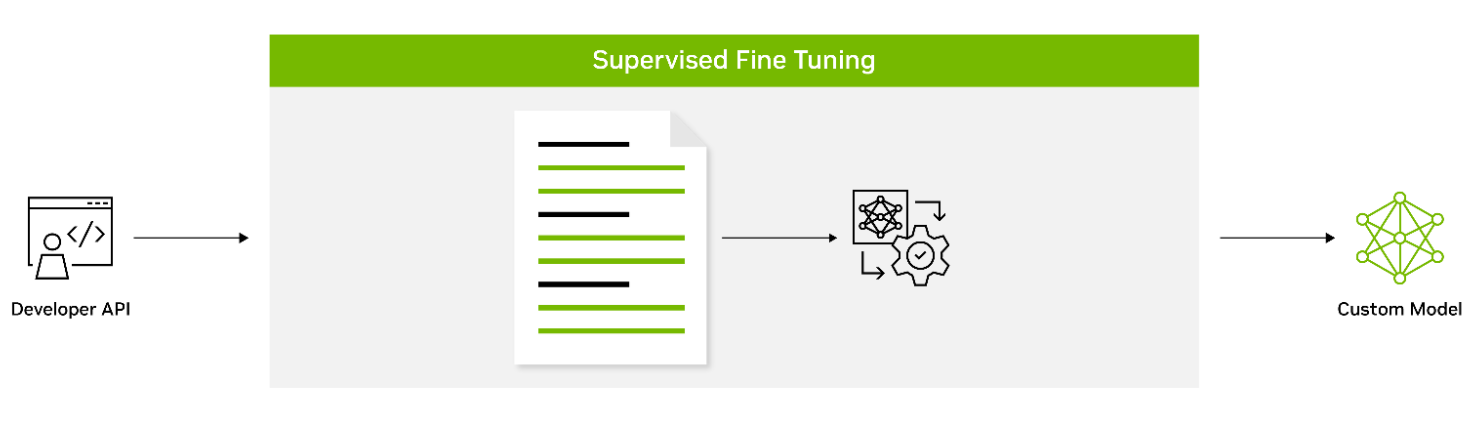
Supervised fine-tuning (SFT) involves fine-tuning a model’s parameters using labeled data. Also known as instruction tuning, this form of customization is typically conducted post-pretraining. It provides the advantage of using state-of-the-art models without the need for initial training, thus lowering computational costs and reducing data collection requirements.
Adapters introduce small feedforward layers in between the model’s core layers. These adapter layers are then fine-tuned for specific downstream tasks, providing a level of customization that is unique to the requirements of the task at hand.
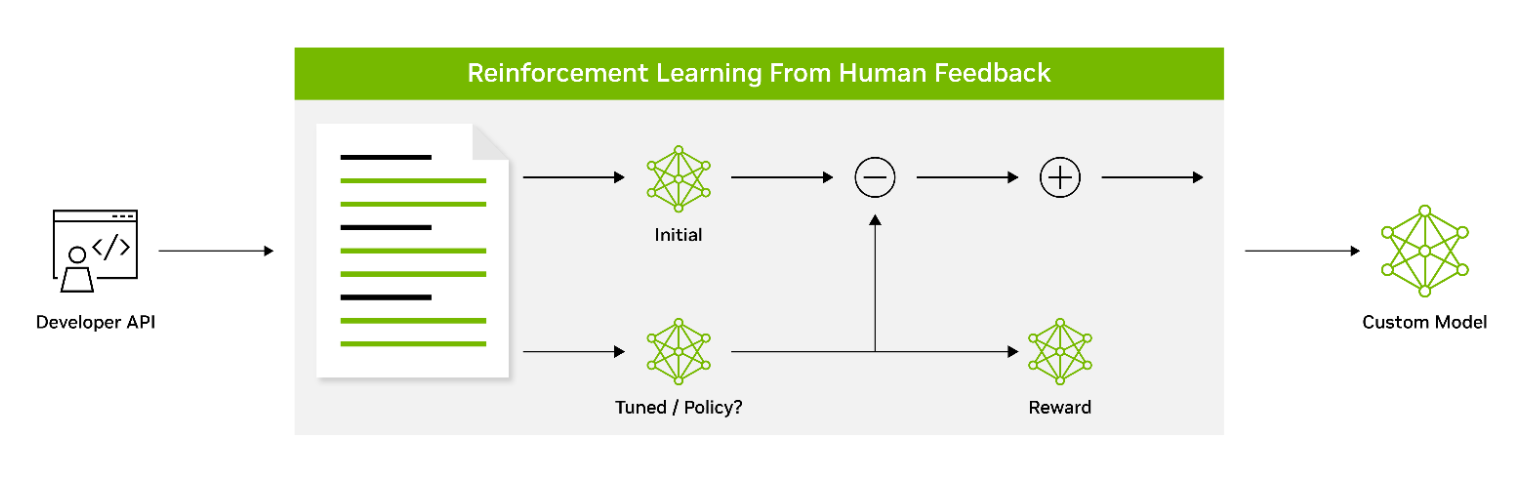
Reinforcement learning from human feedback (RLHF) employs a three-stage fine-tuning process. The model adapts its behavior based on feedback, encouraging a better alignment with human values and preferences. This makes RLHF a powerful tool for creating models that resonate with human users.
AliBi enables transformer models to process longer sequences at inference time than they were trained on. This is particularly useful in scenarios where the information to be processed is lengthy or complex.
NeMo Guardrails helps ensure that smart applications powered by LLMs are accurate, appropriate, on-topic, and secure. NeMo Guardrails is available as open source and includes all the code, examples, and documentation businesses need for adding safety to AI apps that generate text. NeMo Guardrails works with NeMo as well as all LLMs, including OpenAI’s ChatGPT.
Accelerated inference
Seamlessly integrating with NVIDIA Triton Inference Server, NeMo significantly accelerates the inference process, delivering exceptional accuracy, low latency, and high throughput. This integration facilitates secure and efficient deployments ranging from a single GPU to large-scale, multi-node GPUs, while adhering to stringent safety and security requirements.
NVIDIA Triton empowers NeMo to streamline and standardize generative AI inference. This enables teams to deploy, run, and scale trained ML or deep learning (DL) models from any framework on any GPU- or CPU-based infrastructure. This high level of flexibility provides you with the freedom to choose the most suitable framework for your AI research and data science projects without compromising production deployment flexibility.
Guardrails
As part of the NVIDIA AI Enterprise software suite, NeMo enables organizations to deploy production-ready generative AI with confidence. Organizations can take advantage of long-term branch support for up to 3 years, ensuring seamless operations and stability. Regular Common Vulnerabilities and Exposures (CVE) scans, security notifications, and timely patches enhance security, while API stability simplifies updates.
NVIDIA AI Enterprise support services are included with the purchase of the NVIDIA AI Enterprise software suite. We provide direct access to NVIDIA AI experts, defined service-level agreements, and control of upgrade and maintenance schedules with long-term support options.
Powering enterprise-grade generative AI
As part of NVIDIA AI Enterprise 4.0, NeMo offers seamless compatibility across multiple platforms, including the cloud, data centers, and now, NVIDIA RTX-powered workstations and PCs. This enables a true develop-once-and-deploy-anywhere experience, eliminates the complexities of integration, and maximizes operational efficiency.
NeMo has already gained significant traction among forward-thinking organizations looking to build custom LLMs. Writer and Korea Telecom have embraced NeMo, leveraging its capabilities to drive their AI-driven initiatives.
The unparalleled flexibility and support provided by NeMo opens a world of possibilities for businesses, enabling them to design, train, and deploy sophisticated LLM solutions tailored to their specific needs and industry verticals. By partnering with NVIDIA AI Enterprise and integrating NeMo into their workflows, your organizations can unlock new avenues of growth, derive valuable insights, and deliver cutting-edge AI-powered applications to customers, clients, and employees alike.
Get started with NVIDIA NeMo
NVIDIA NeMo has emerged as a game-changing solution, bridging the gap between the immense potential of generative AI and the practical realities faced by enterprises. A comprehensive platform for LLM development and deployment, NeMo empowers businesses to leverage AI technology efficiently and cost-effectively.
With these powerful capabilities, enterprises can integrate AI into their operations, streamlining processes, enhancing decision-making capabilities, and unlocking new avenues for growth and success.
Learn more about NVIDIA NeMo and how it helps enterprises build production-ready generative AI.
 The latest developments in large language model (LLM) scaling laws have shown that when scaling the number of model parameters, the number of tokens used for…
The latest developments in large language model (LLM) scaling laws have shown that when scaling the number of model parameters, the number of tokens used for…
The latest developments in large language model (LLM) scaling laws have shown that when scaling the number of model parameters, the number of tokens used for training should be scaled at the same rate. The Chinchilla and LLaMA models have validated these empirically derived laws and suggest that previous state-of-the-art models have been under-trained regarding the total number of tokens used during pretraining.
Considering these recent developments, it’s apparent that LLMs need larger datasets, more than ever.
However, despite this need, most software and tools developed to create massive datasets for training LLMs are not publicly released or scalable. This requires LLM developers to build their own tools to curate large language datasets.
To meet this growing need for large datasets, we have developed and released the NeMo Data Curator: a scalable data-curation tool that enables you to curate trillion-token multilingual datasets for pretraining LLMs.
Data Curator is a set of Python modules that use Message-Passing Interface (MPI), Dask, and Redis Cluster to scale the following tasks to thousands of compute cores:
- Data download
- Text extraction
- Text reformatting and cleaning
- Quality filtering
- Exact or fuzzy deduplication
Applying these modules to your datasets helps reduce the burden of combing through unstructured data sources. Through document-level deduplication, you can ensure that models are trained on unique documents, potentially leading to greatly reduced pretraining costs.
In this post, we provide an overview of each module in Data Curator and demonstrate that they offer linear scaling to more than 1000 CPU cores. To validate the data curated, we also show that using documents it processes from Common Crawl for pretraining provides significant downstream task improvement over using raw downloaded documents.
Data-curation pipeline
This tool enables you to download data and extract, clean, deduplicate, and filter documents at scale. Figure 1 shows a typical LLM data-curation pipeline that can be implemented. In the following sections, we briefly describe the implementation of each of these modules available.
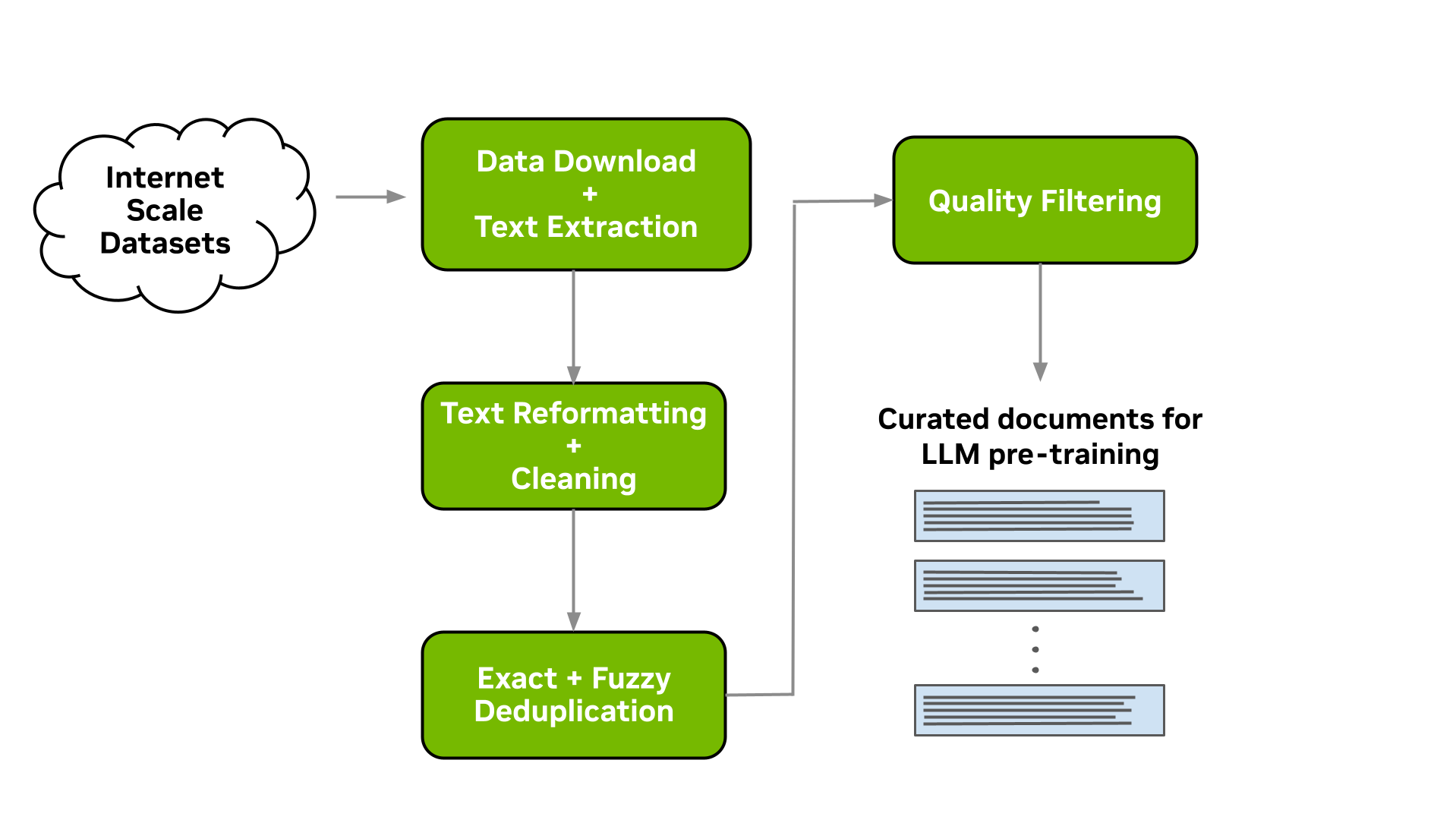
Download and text extraction
The starting point for preparing custom pretraining datasets for many LLM practitioners is a list of URLs that point to data files or websites that contain content of interest for LLM pretraining.
Data Curator enables you to download pre-crawled web pages from data repositories such as Common Crawl, Wikidumps, and ArXiv and to extract the relevant text to JSONL files at scale. Data Curator also provides you with the flexibility of supplying your own download and extraction functions to process datasets from a variety of sources. Using a combination of MPI and Python Multiprocessing, thousands of asynchronous download and extraction workers can be launched at runtime across many compute nodes.
Text reformatting and cleaning
Upon downloading and extracting text from documents, a common step is to fix all Unicode-related errors that can be introduced when text data are not properly decoded during extraction. Data Curator uses the Fixes Text For You library (ftfy) to fix all Unicode-related errors. Cleaning also helps to normalize the text, which results in a higher recall when performing document deduplication.
Document-level deduplication
When downloading data from massive web-crawl sources such as Common Crawl, it’s common to encounter both documents that are exact duplicates and documents with high similarity (that is, near duplicates). Pretraining LLMs with repeated documents can lead to poor generalization and a lack of diversity during text generation.
We provide exact and fuzzy deduplication utilities to remove duplicates from text data. The exact deduplication utility computes a 128-bit hash of each document, groups documents by their hashes into buckets, selects one document per bucket, and removes the remaining exact duplicates within the bucket.
The fuzzy-deduplication utility uses a MinHashLSH-based approach where MinHashes are computed for each document, and then documents are grouped using the locality-sensitive property of min-wise hashing. After documents are grouped into buckets, similarities are computed between documents within each bucket to check for potential false positives created during MinHashLSH.
For both deduplication utilities, Data Curator uses a Redis Cluster distributed across compute nodes to implement a distributed dictionary for clustering documents into buckets. The scalable design and gossip protocol implemented by the Redis Cluster enables efficient scaling of deduplication workloads to many compute nodes.
Document-level quality filtering
In addition to containing a significant fraction of duplicate documents, data from web-crawl sources such as Common Crawl often tend to include many documents with informal prose. This includes, for example, many URLs, symbols, boilerplate content, ellipses, or repeating substrings. They can be considered low-quality content from a language-modeling perspective.
While it’s been shown that diverse LLM pretraining datasets lead to improved downstream performance, a significant quantity of low-quality documents can hinder performance. Data Curator provides you with a highly configurable document-filtering utility that enables you to apply custom heuristic filters at scale to your corpora. The tool also includes implementations of language-data filters (both classifier and heuristic-based) that have been shown to improve overall data quality and downstream task performance when applied to web-crawl data.
Scaling to many compute cores
To demonstrate the scaling capabilities of the different modules available within Data Curator, we used them to prepare a small dataset consisting of approximately 40B tokens. This involved running the previously described data-curation pipeline on 5 TB of Common Crawl WARC files.
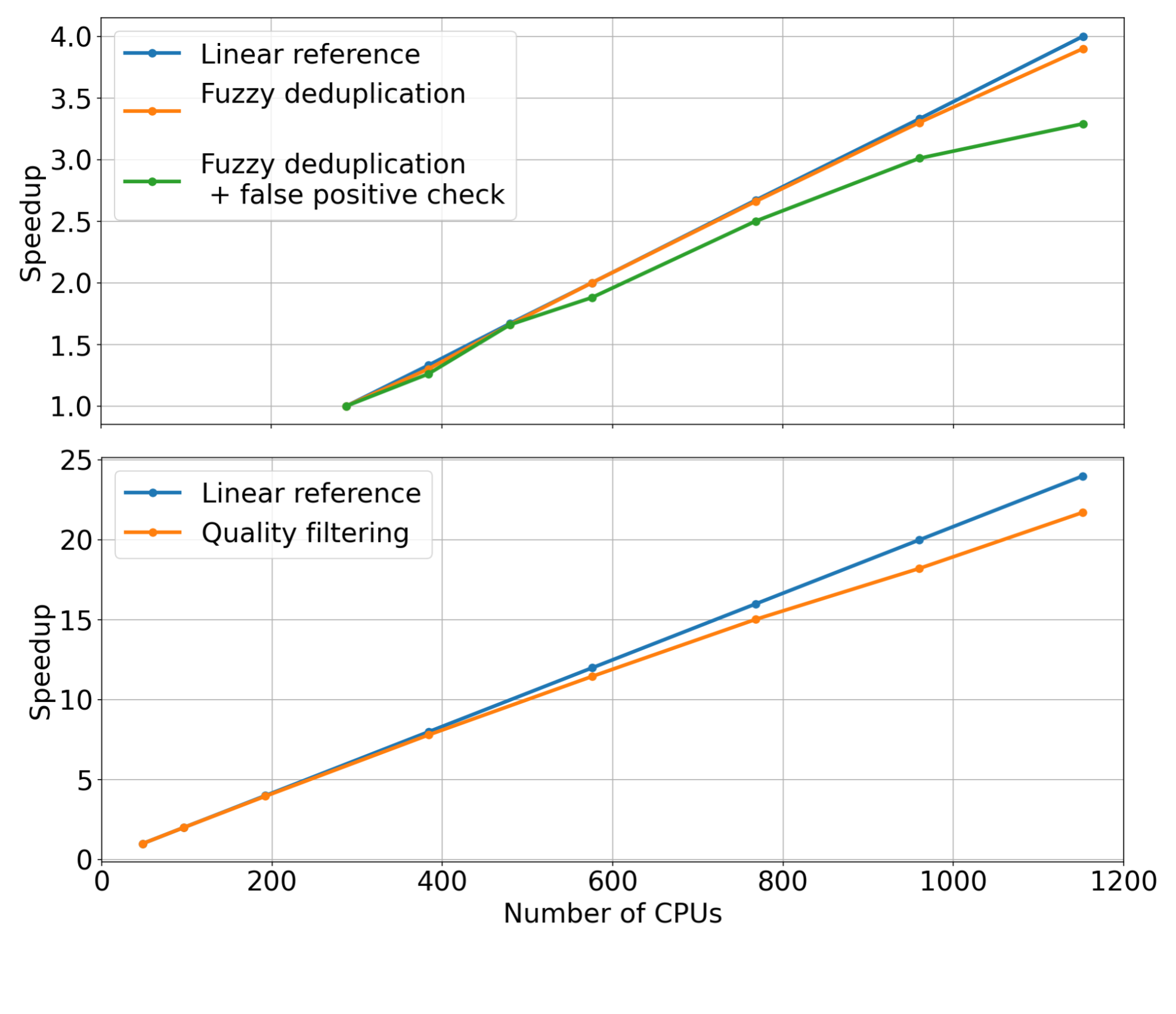
For each pipeline stage, we fixed the input dataset size while linearly increasing the number of CPU cores used to scale the data curation modules (that is, strong scaling). We then measured the speedup for each module. The measured speedups for the quality-filtering and fuzzy-deduplication modules are shown in Figure 2.
Examining the trends of the measurements, it’s apparent that these modules can reach substantial speedups when increasing the number of CPU cores used for distributing the data curation workloads. Compared to the linear reference (orange curve), we observe that both modules are able to achieve considerable speedup when using up to 1,000 CPUs or more.
Curated pretraining data results in improved model downstream performance
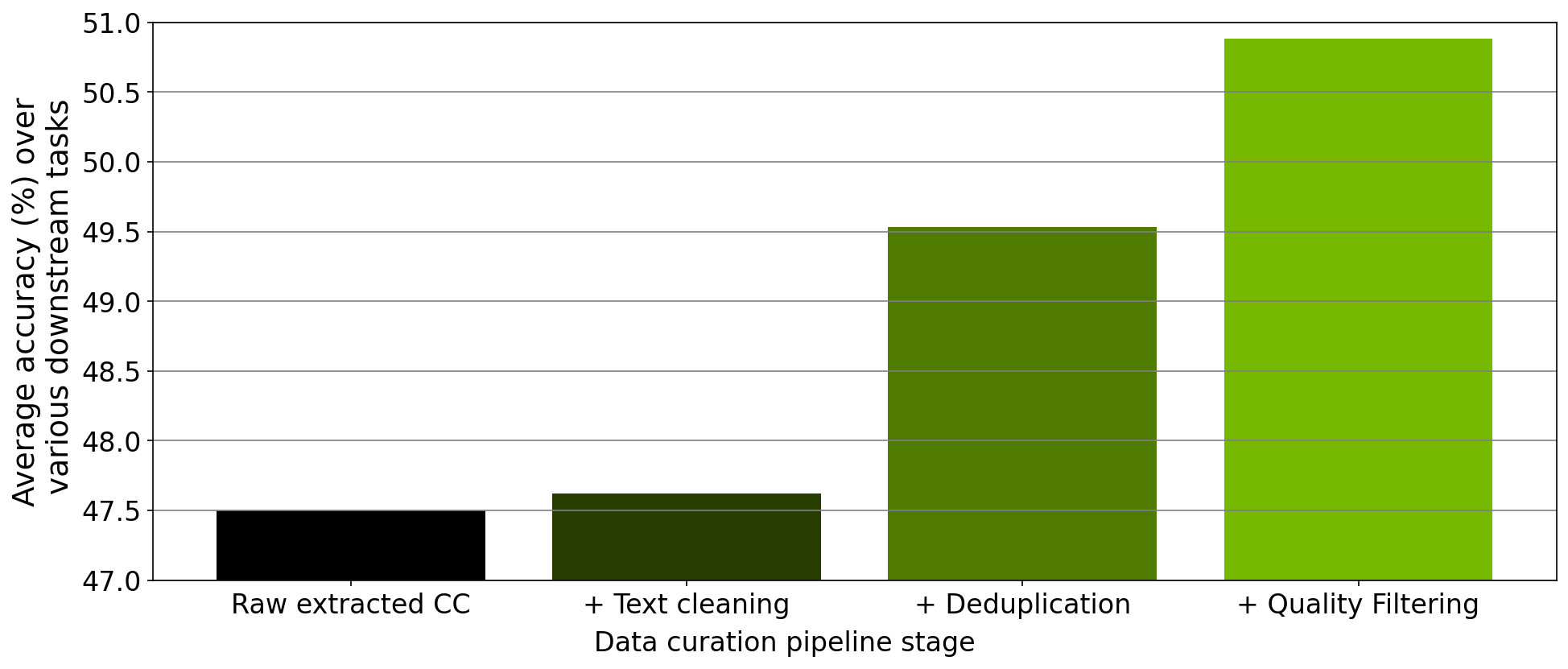
In addition to verifying the scaling of each module, we also performed an ablation study on the data curated from each step of the data-curation pipeline implemented within the tool. Starting from a downloaded Common Crawl snapshot, we trained a 357M parameter GPT model on 78M tokens curated from this snapshot after extraction, cleaning, deduplication, and filtering.
After each pretraining experiment, we evaluated the model across the RACE-High, PiQA, Winogrande, and Hellaswag tasks in a zero-shot setting. Figure 3 shows that the results of our ablation experiments averaged over all four tasks. As the data progresses through the different stages of the pipeline, the average over all four tasks increases significantly, indicating improved data quality.
Curating a 2T token dataset with NeMo Data Curator
Recently, the NVIDIA NeMo service started providing early-access users with the opportunity to customize an NVIDIA-trained 43B-parameter multilingual large foundation model. To pretrain this foundation model, we prepared a dataset consisting of 2T tokens that included 53 natural languages originating from a variety of diverse domains as well as 37 different programming languages.
Curating this large dataset required applying our data-curation pipeline implemented within Data Curator to a total of 8.7 TB of text data on a CPU cluster of more than 6K CPUs. Pretraining the 43B foundation model on 1.1T of these tokens resulted in a state-of-the-art LLM that’s currently being used by NVIDIA customers for their LLM needs.
Conclusion
To meet the growing demands for curating pretraining datasets for LLMs, we have released Data Curator as part of the NeMo framework. We have demonstrated that the tool curates high-quality data that leads to improved LLM downstream performance. Further, we have shown that each data-curation module available within Data Curator can scale to use thousands of CPU cores. We anticipate that this tool will significantly benefit LLM developers attempting to build pretraining datasets.
 Developing extended reality (XR) applications can be extremely challenging. Users typically start with a template project and adhere to pre-existing packaging…
Developing extended reality (XR) applications can be extremely challenging. Users typically start with a template project and adhere to pre-existing packaging…
Developing extended reality (XR) applications can be extremely challenging. Users typically start with a template project and adhere to pre-existing packaging templates for deploying an app to a headset. This approach creates a distinct bottleneck in the asset iteration pipeline. Updating assets inside an XR experience becomes completely dependent on how fast the developer can build, package, and deploy a new executable.
The new spatial framework in NVIDIA Omniverse helps tackle these challenges with Universal Scene Description, known as OpenUSD, and NVIDIA RTX-enabled ray tracing. This marks the world’s first fully ray-traced XR experience, enabling you to view every reflection, soft shadow, limitless light, and dynamic change to geometry in your scene.
You can now fully ray trace massive, complex, full fidelity design data sets with millions of polygons, physical materials, and accurate lighting. Experience the data sets in an immersive environment without requiring additional time for data preparation.
Enabling immersive workflows with OpenUSD
OpenUSD ensures that scene editing remains nondestructive, enabling seamless interactions between different tools and ecosystems. Omniverse renders and presents the USD data on disk, so users can iterate on that data at any cadence and see the XR view of the asset updated in real time.
As a result, users can experience applications immersively at any point in the pipeline, drastically reducing friction and increasing iteration speeds. Users can even integrate XR in existing pipelines—it is no longer time-intensive to implement.
Key features of the spatial framework include:
- New tools for adding immersive experiences and basic XR functionality. This streamlines workflows for design reviews and factory planning.
- Connects RTX ray tracing and Omniverse to SteamVR, OpenXR, and NVIDIA CloudXR.
- Support for spatial computing platforms and headsets. Omniverse users can build USD stages that are compatible with other OpenUSD-based spatial computing platforms such as AR Kit and RealityKit. Plus, new support for the Khronos Group OpenXR open standard expands Omniverse-developer experiences to more headsets from manufacturers such as HTC Vive, Magic Leap, and Varjo.
“The NVIDIA release of Omniverse Kit with OpenXR and Magic Leap 2 support is an important milestone for enterprise AR,” said Jade Meskill, VP Product at Magic Leap. “Enterprise users can now render and stream immersive, full-scale digital twins from Omniverse to Magic Leap 2 with groundbreaking visual quality.”
Placing photorealistic digital twins based on full fidelity design data in the real world with accurate lighting and reflections is a must-have for demanding enterprise applications, added Meskill. “We are delighted by the strong partnership between the NVIDIA and Magic Leap engineering teams that pioneered key technical advancements in visual quality.”
Integrating XR into existing 3D workflows
Omniverse application developers can now easily integrate XR into 3D workflows. The new spatial framework in Omniverse enables real-time, immersive visualization for 3D scenes. You can also incorporate XR functionalities, such as teleporting, manipulating, and navigating, into existing pipelines.
Using the spatial framework, you can view working assets in mixed reality, or totally immersively, across devices. NVIDIA CloudXR enables a completely untethered experience with the same level of fidelity that only desktop compute can provide.
You can also use specific extensions without downloading an entire application, enabling simpler and more modular workflows. Automatic user interface optimizations improve the speed and productivity of applications to provide smoother playbacks.
In addition, you can deploy custom XR applications and design user interfaces for specific workflows, such as collaborative product design review and factory planning.
RTX-powered immersive experiences on industry-leading headsets
With Omniverse Kit 105, you can create assets with ultimate immersion and realism and build apps that are incredibly realistic, with full fidelity, geometry, and materials.
For example, Kit 105 can drive the retinal resolution Quad View rendering for the Varjo XR-3, the industry’s highest resolution mixed-reality headset. The renderer produces two high-resolution views and two lower resolution views, which are then composited by the device to provide an unparalleled level of fidelity and immersion within the VR experience.
“Real-time ray tracing is the holy grail of 3D visualization,” explains Marcus Olsson, director of Software Partnerships at Varjo. “The graphical and computing demands made it impossible to render true-to-life immersive scenes like these—until now. With NVIDIA Omniverse and Varjo XR-3, users can unlock real-time ray tracing for mixed reality environments due to the combination of a powerful multi-GPU setups and Varjo’s photorealistic visual fidelity.”
The Quad View renders a staggering 15 million pixels, unlocking new levels of visual fidelity in XR. Teams seeking to leverage retinal resolution Quad View rendering should use a multi-GPU setup powered by the latest NVIDIA RTX 6000 Ada Generation graphics cards to provide seamless rendering and optimal performance for the Varjo XR-3 headset.
Start building immersive experiences and applications with Omniverse
Ready to start building XR into applications and creating immersive experiences using Omniverse Kit 105? The spatial framework is available now in the Omniverse Extension Library under VR Experience. Add the extension to your Kit app and the Tablet AR and VR panels will be ready to use. Omni.UI is also implemented in the framework, so tools and interfaces you develop for desktop can be used while in a headset.
USD Composer provides a good place to test immersive experiences in Omniverse. USD Composer is a reference application in Omniverse where you can easily open and craft a USD stage. To get started, install USD Composer from the Omniverse Launcher. In the Window -> Rendering menu, find VR and Tablet AR. If you’re working with another user, you can leverage the USD Composer multi-user workflow to work immersively together in real time. Get started building your own XR experience in Omniverse.
To learn more about USD, attend the OpenUSD Day at SIGGRAPH 2023 on August 9. And remember to join the NVIDIA OpenUSD Developer Program.
Get started with NVIDIA Omniverse by downloading the standard license free, or learn how Omniverse Enterprise can connect your team. If you’re a developer, get started with Omniverse resources. Stay up-to-date on the platform by subscribing to the newsletter, and following NVIDIA Omniverse on Instagram, Medium, and Twitter. For resources, check out our forums, Discord server, Twitch, and YouTube channels.
 The latest release of NVIDIA Omniverse delivers an exciting collection of new features based on Omniverse Kit 105, making it easier than ever for developers to…
The latest release of NVIDIA Omniverse delivers an exciting collection of new features based on Omniverse Kit 105, making it easier than ever for developers to…
The latest release of NVIDIA Omniverse delivers an exciting collection of new features based on Omniverse Kit 105, making it easier than ever for developers to get started building 3D simulation tools and workflows.
Built on Universal Scene Description, known as OpenUSD, and NVIDIA RTX and AI technologies, Omniverse enables you to create advanced, real-time 3D simulation applications for industrial digitalization and perception AI use cases. The fully composable platform scales from workstation to cloud, so you can build advanced, scalable solutions with minimal coding.
During the NVIDIA keynote at SIGGRAPH 2023, CEO Jensen Huang announced ChatUSD and RunUSD.
ChatUSD is a large language model (LLM) agent for generating Python-USD code scripts from text and answering USD knowledge questions, helping to simplify and accelerate USD development tasks directly in Omniverse.
RunUSD is a cloud API that translates OpenUSD files into fully path-traced rendered images by checking compatibility of the uploaded files against versions of OpenUSD releases, and generating renders with Omniverse Cloud. A demo of the API is currently available for developers in the NVIDIA OpenUSD Developer Program.
These investments in OpenUSD expand on NVIDIA co-founding the Alliance for OpenUSD (AOUSD)—an organization announced last week that will standardize OpenUSD specifications—along with Pixar, Adobe, Apple and Autodesk. To learn more about OpenUSD and how developers across enterprises, startups, and 3D solution providers are using Omniverse to build tools for the metaverse, see Developers Look to OpenUSD in Era of AI and Industrial Digitalization.
Building OpenUSD-based applications with Omniverse Kit
Omniverse Kit is the development toolkit and engine for building OpenUSD-based applications and extensions on Omniverse. This powerful, extensible SDK is the foundation for every application, Connector, and extension built with Omniverse.
Convai recently developed an extension with Omniverse Kit that allows creators to add characters in their digital twin environments that can provide relevant information about the environment and objects, be a tour guide, or a virtual robot. Cesium for Omniverse, an extension built with Kit, enables 3D Tiles, an open standard for streaming massive geospatial datasets in virtual worlds, including those supported by OpenUSD.
echo3D, a cloud platform for 3D asset management that helps developers and companies build and deploy 3D apps, has developed an extension with Kit that enables you to add 3D assets remotely to an Omniverse project and update them through the cloud.
And Alpha3D is a generative AI-powered platform that transforms 2D images and text prompts into 3D models in a matter of minutes. With the Alpha3D extension developed using Omniverse Kit, the 3D models can be automatically imported into the creator’s Omniverse panel once they are rendered.
Better efficiency and user experience
Get started building on Omniverse with the new Kit Extension Registry, which serves as a centralized repository for accessing, sharing, and managing extensions. From here, you can browse over 500 core extensions. Download instantly once and use anywhere. Extensions can be assembled together in many combinations to build workflows and experiences that deliver new possibilities.
Kit 105 introduces the new Welcome Window, which delivers a significantly improved application launch experience. Quickly access recent files, samples, and learning resources from the customizable welcome window, and jump-start your projects with on-demand extension loading.
After launching your desired experience in Omniverse Kit 105, you’ll notice significant improvements in user interface rendering. New rendering optimizations take full advantage of the NVIDIA Ada Lovelace architecture enhancements in NVIDIA RTX GPUs with DLSS 3.0 technology fully integrated into the Omniverse RTX Renderer. Additionally, a new AI denoiser enables real-time 4K path tracing of massive industrial scenes.
The rendering optimizations have been implemented at the framework level, automatically providing performance enhancements without any changes to existing code. With the introduction of Raster mode for widgets, render costs are reduced by up to 20x.
Enhanced modularity and performance
Developers using Omniverse Kit have always appreciated its extreme modularity, where the Kernel provides the foundation, extensions add specific functionalities, and apps and services combine extensions into complete solutions. With Kit 105, this modularity extends to consumption as well.
The Kit Kernel is now available through Omniverse Launcher, making it easy to access the Kit executable, Python, and other essential core components.
Kit Extensions are now hosted in the Omniverse Extension Registry. You can download these modules on demand into a shared location, which significantly reduces package size. When multiple apps use the same version of an extension, only one download is required, both during development and for the end user. This enables NVIDIA and the developer community to update extensions frequently without requiring new app versions, providing a seamless experience.
Build immersive workflows with new spatial framework
Developers of Kit-based applications can now easily integrate extended reality (XR) into 3D workflows with the new Omniverse spatial framework. XR functionalities, such as teleporting, manipulating, and navigating are easy to incorporate into existing pipelines with the framework.
Key features of the spatial framework include:
- New tools for adding immersive experiences and basic XR functionality, streamlining workflows for design reviews and factory planning.
- Connects NVIDIA RTX Renderer and NVIDIA Omniverse to SteamVR, OpenXR, and NVIDIA CloudXR.
- Support for spatial computing platforms and headsets. Build content, experiences, and applications for OpenUSD-based spatial computing platforms.
To learn more about the spatial framework and supported platforms and headsets, see RTX-Powered Spatial Framework Delivers Full Ray Tracing with USD for XR Pipelines.
Experience Omniverse Kit in action
Experience all the new functionalities and performance improvements of Omniverse Kit 105 in updated Omniverse foundation applications. These are fully customizable reference applications that you can copy, extend, or enhance.
- Omniverse USD Composer enables 3D users to assemble large-scale, OpenUSD-based scenes. CGI.Backgrounds, developer of premium 360° ready HDRi environments, now has several ultra-high definition HDRi maps available to leverage in USD Composer.
- Omniverse Audio2Face provides access to generative AI APIs that create realistic facial animations and gestures from only an audio file. It now includes multi-language support and a new female base model.
These applications can be used as a template for building your own Kit-based app. You can deconstruct and add on functionalities from the sample application to build your own custom application.
Get started building on Omniverse
If you are an independent or enterprise developer, you can easily build and sell your own extensions, apps, connectors, and microservices on the Omniverse platform. Explore the broad variety of tools and code samples. To get started building, download Omniverse for free and navigate to Omniverse Developer Resources.
Join the NVIDIA OpenUSD Developer Program, and attend OpenUSD Day at SIGGRAPH 2023 on August 9.
Get started with NVIDIA Omniverse by downloading the standard license free, or learn how Omniverse Enterprise can connect your team. If you’re a developer, get started with Omniverse resources. Stay up-to-date on the platform by subscribing to the newsletter, and following NVIDIA Omniverse on Instagram, Medium, and Twitter. For resources, check out our forums, Discord server, Twitch, and YouTube channels.
 Developing custom generative AI models and applications is a journey, not a destination. It begins with selecting a pretrained model, such as a Large Language…
Developing custom generative AI models and applications is a journey, not a destination. It begins with selecting a pretrained model, such as a Large Language…
Developing custom generative AI models and applications is a journey, not a destination. It begins with selecting a pretrained model, such as a Large Language Model, for exploratory purposes—then developers often want to tune that model for their specific use case. This first step typically requires using accessible compute infrastructure, such as a PC or workstation. But as training jobs get larger, developers are forced to expand into additional compute infrastructure in the data center or cloud.
The process can become incredibly complex and time consuming, especially when trying to collaborate and deploy across multiple environments and platforms. NVIDIA AI Workbench helps simplify the process by providing a single platform for managing data, models, resources, and compute needs. This enables seamless collaboration and deployment for developers to develop cost-effective scalable generative AI models quickly.
What’s NVIDIA AI Workbench?
NVIDIA AI Workbench is a unified, easy-to-use developer toolkit to create, test, and customize pretrained AI models on a PC or workstation. Then users can scale the models to virtually any data center, public cloud, or NVIDIA DGX Cloud. It enables developers of all levels to generate and deploy cost-effective and scalable generative AI models quickly and easily.
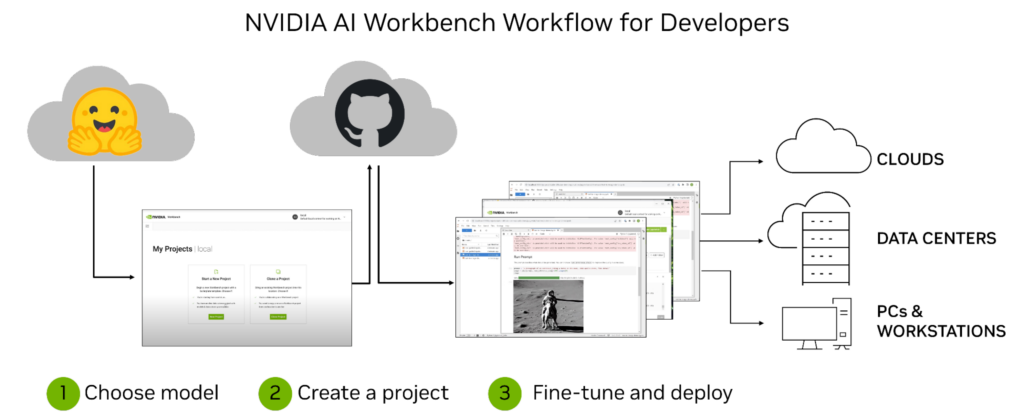
After installation, the platform provides management and deployment for containerized development environments to make sure everything works, regardless of a user’s machine. AI Workbench integrates with platforms like GitHub, Hugging Face, and NVIDIA NGC, as well as with self-hosted registries and Git servers.
Users can develop naturally in both JupyterLab and VS Code while managing work across a variety of machines with a high degree of reproducibility and transparency. Developers with an NVIDIA RTX PC or workstation can also launch, test, and fine-tune enterprise-grade generative AI projects on their local systems, and access data center and cloud computing resources when scaling up.
Enterprises can connect AI Workbench to NVIDIA AI Enterprise, accelerating the adoption of generative AI and paving the way for seamless integration in production. Sign up to get notified when AI Workbench is available for early access.
Enterprise AI development workflow challenges
While generative AI models offer incredible potential for businesses, the development process can be complex and time consuming.
Some of the challenges faced by enterprises as they begin their journey developing custom generative AI include the following.
Technical expertise: having the right technical skills is key when working on generative AI models. Developers must have a deep understanding of machine learning algorithms, data manipulation techniques, languages such as Python, and frameworks like TensorFlow.
Data access and security: the proliferation of sensitive customer data means it’s important to make sure proper security measures are taken during such projects. Additionally, businesses must consider how they’ll access the necessary datasets for training their models, which may involve dealing with large amounts of unstructured or semi-structured data from multiple sources.
Moving workflows and applications: development and deployment across machines and environments can be complex due to dependencies between components. Keeping track of different versions of the same application or workflow can be difficult, especially in more distributed environments such as cloud computing platforms like Amazon AWS, Google Cloud Platform, or Microsoft Azure. Additionally, managing credentials and confidential information is essential for protecting secure access to resources across machines and environments.
These challenges underscore the importance of having a comprehensive platform like NVIDIA AI Workbench that simplifies the entire generative AI development process. This makes it easier to manage data, models, compute resources, dependencies between components, and versions. All while providing seamless collaboration and deployment capabilities across machines and environments.
Key benefits of NVIDIA AI Workbench
Developing generative AI models is a complex process, and AI Workbench streamlines it. With its unified platform for managing data, models, and compute resources, developers of all skill levels can quickly and easily create and deploy cost-effective, scalable AI models.
Some of the key benefits of using AI Workbench include the following:
Easy-to-use development platform: AI Workbench simplifies the development process by providing a single platform for managing data, models, and compute resources that supports collaboration across machines and environments.
Integration with AI development tools and repositories: AI Workbench integrates with services such as GitHub, NVIDIA NGC, and Hugging Face, self-hosted registries, and Git servers. Users can develop using tools like JupyterLab and VS Code, across platforms and infrastructure with a high degree of reproducibility and transparency.
Enhanced collaboration: AI Workbench uses an architecture focused around a project, which is a Git repository with metadata files describing the contents and their relationships, instructions for configuration, and execution. Location or user-dependent data is handled by AI Workbench transparently and injected at runtime so that such information isn’t hard coded into projects. The project structure helps to automate complex tasks around versioning, container management, and handling confidential information while also enabling collaboration across teams.
Access to accelerated compute: AI Workbench deployment is a client-server model. The Workbench user interface runs on a local system and communicates with the Workbench Service remotely. Both the user interface and service run locally on a user’s primary resource, such as a work laptop. The service can be installed on remote machines accessible through SSH connections. This enables teams to begin development on local compute resources in their workstations and shift to data center or cloud resources as the training jobs get larger.
NVIDIA AI Workbench in action
At SIGGRAPH 2023, we demonstrated the power of AI Workbench for generative AI customization across both text and image workflows.
Custom image generation with Stable Diffusion XL
While Gradio apps on services like Hugging Face Spaces provide one-click interaction with models like StableDiffusion XL, getting those models and apps to run locally can be tough.
Users must get the local environment set up with the appropriate NVIDIA software, such as NVIDIA TensorRT and NVIDIA Triton. Then, they need models from Hugging Face, code from GitHub, and containers from NVIDIA NGC. Finally, they must configure the container, handle apps like JupyterLab, and make sure their GPUs support the model size.
Only then are they ready to get to work. It is a lot to do, even for experts.
AI Workbench makes it easy to accomplish the entire process by cloning a Workbench project from GitHub. The following example outlines the steps that our team took when creating a Toy Jensen image.
We started by opening AI Workbench on a PC and cloning a repo with the URL. Instead of running Jupyter Notebook locally, we opened it on a remote workstation with more GPUs. In AI Workbench, you can select your workstation and open the Jupyter Notebook.
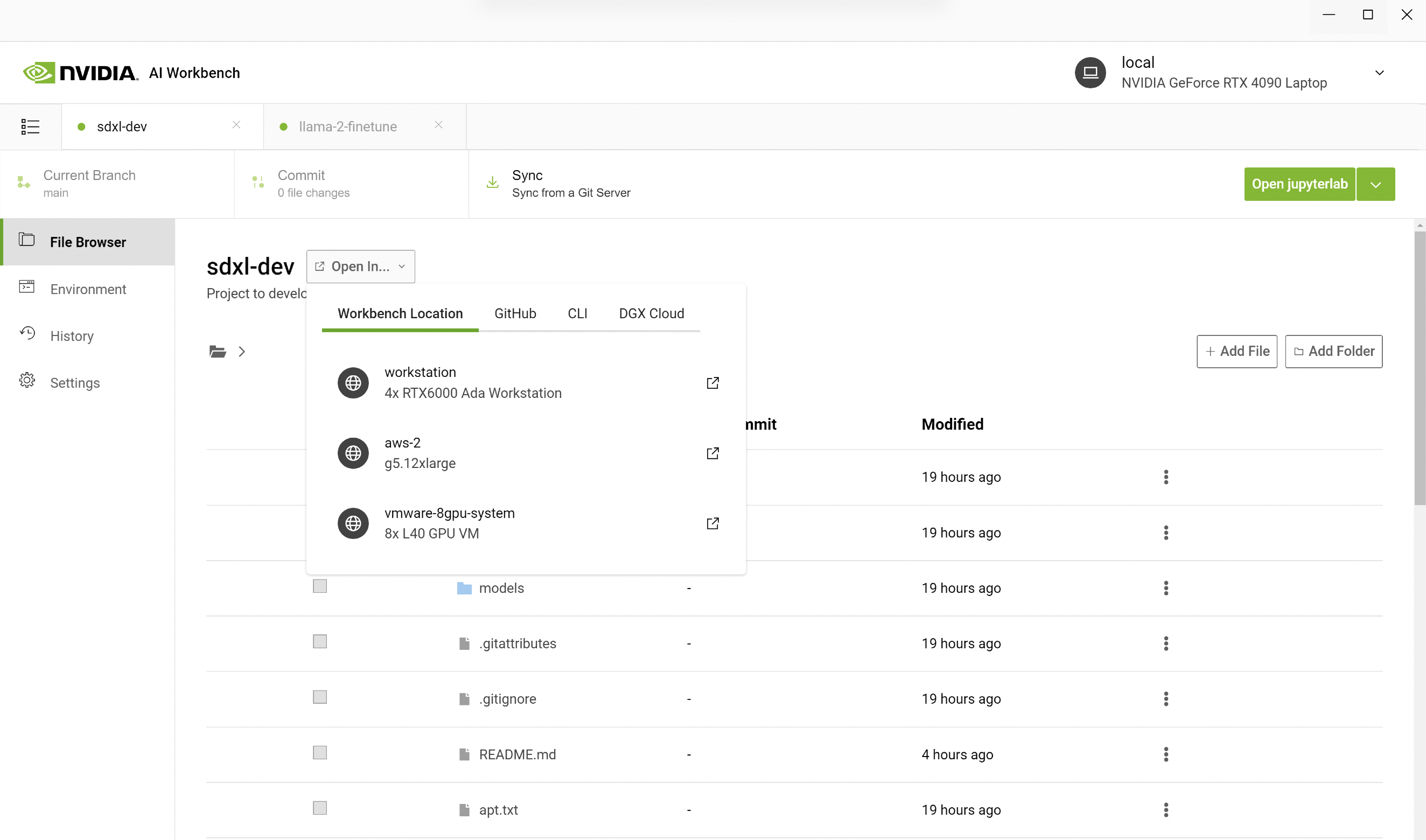
In the Jupyter Notebook, we loaded the pretrained Stable Diffusion XL model from Hugging Face and asked it to generate an image of “Toy Jensen in space.” However, based on the output image, the model doesn’t know who Toy Jensen is.
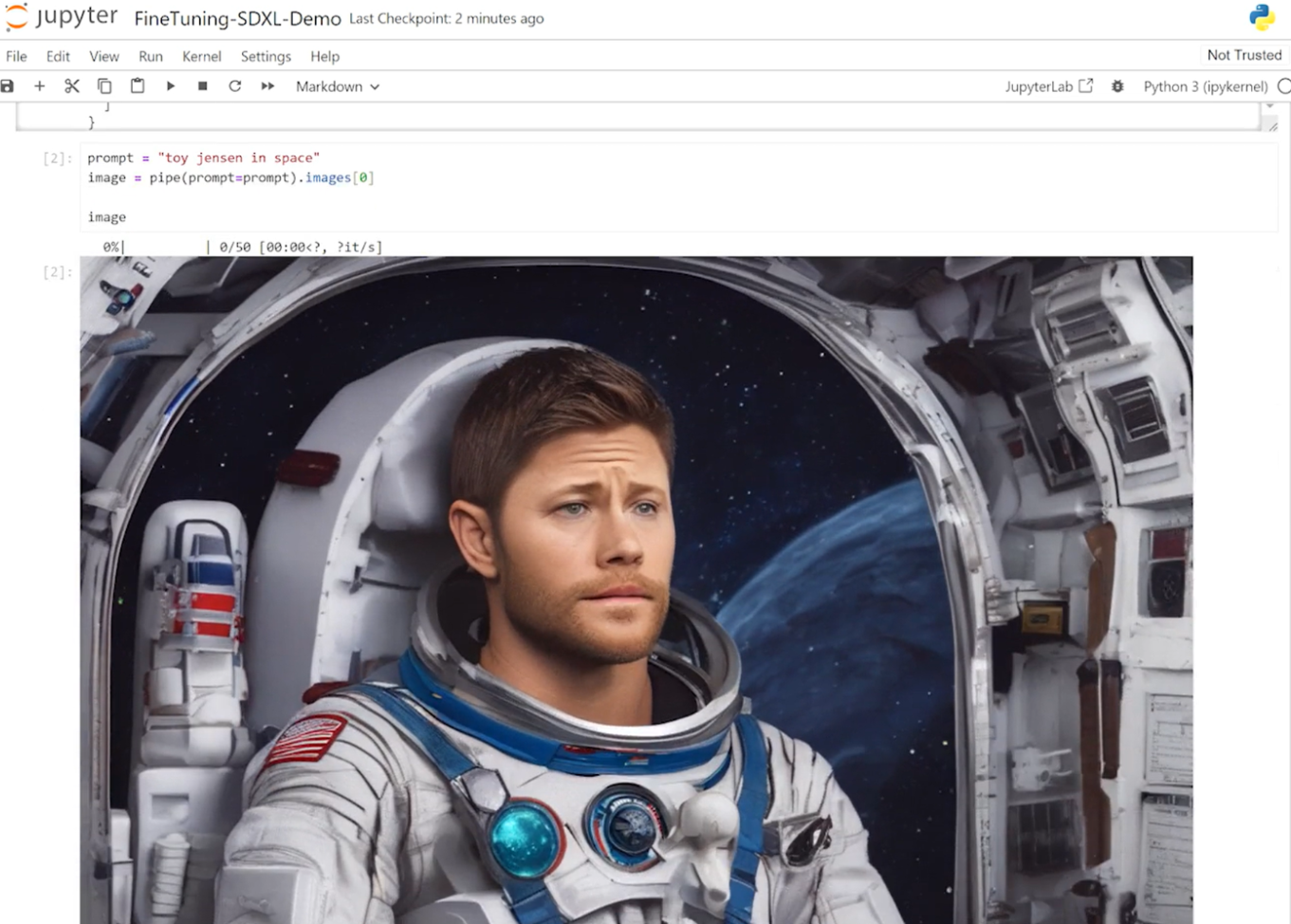
Using DreamBooth to fine-tune the model enabled us to personalize it to a specific subject of interest. In the case of Toy Jensen, we used eight photos of Toy Jensen to fine-tune the model and get good results. Now we’re ready to rerun inference with the user interface. The model now knows what Toy Jensen looks like and can produce better pictures, as shown in Figure 4.
Fine-tuning Llama 2 for medical reasoning
Larger models like Llama 2 70B require a bit more accelerated compute power for both fine-tuning and inference. In this demo, we needed to set up GPUs in the data center to be able to customize the model.
Normally, the work that goes into setting up environments, connecting services, downloading resources, configuring containers, and so on is done on a remote resource. With AI Workbench, we only have to clone a project from GitHub and click Start JupyterLab.
The goal of this demo is to use the Llama-2 model to build a specialized chatbot for a medical use case. Out of the box, the Llama-2 model does not respond well to medical questions about research papers, so we must customize the model.
Starting on a laptop, we connect to eight NVIDIA L40 GPUs running in either the data center or the cloud. The local project is migrated to a remote machine using AI Workbench.
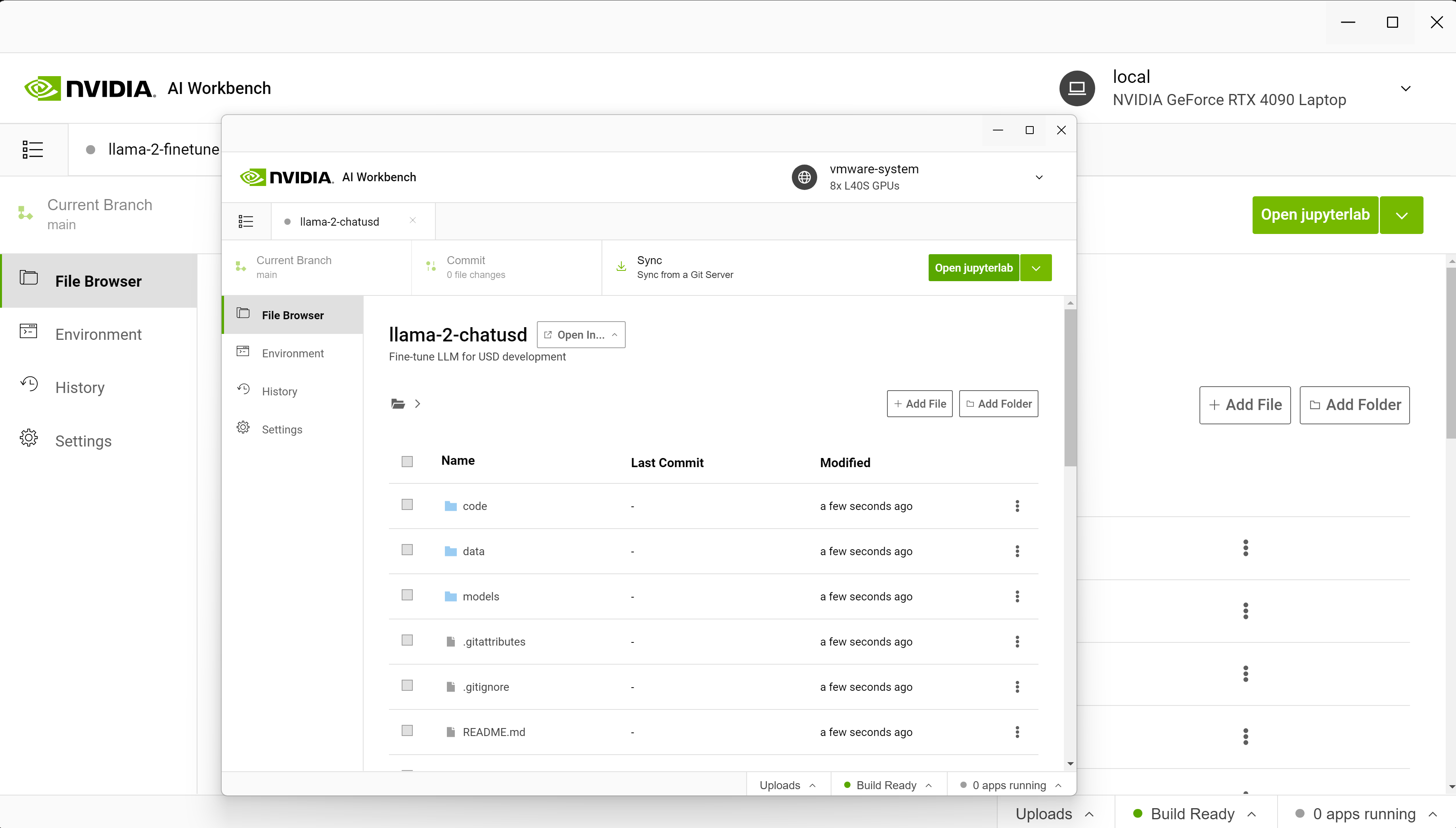
From AI Workbench, a Jupyter environment is launched and includes the P-tuning notebook where we load the pretrained Llama-2 model.
Next, we use NeMo to P-tune it with the open-source PubMedQA dataset. Then, we open the user interface to run inference again, and now our model more accurately answers questions about previously unknown ailments based on given medical context.
In this example, we provided the following prompt to guide the tuned model on how to respond.
| OBJECTIVE: To determine the ability of early sonograms to predict the presentation of twin A at birth.
METHODS: Sonogram records were reviewed for the presentation of twin A at seven gestational age intervals and inpatient medical records were reviewed for the presentation of twin A at delivery. RESULTS: The positive predictive value of cephalic presentation of twin A as determined by ultrasound for the persistence of cephalic presentation at delivery reached 95% after 28 weeks gestation. The positive predictive value for noncephalic presentation as established by sonogram for noncephalic at delivery was >90% after 32 weeks gestation. QUESTION: Can third-trimester ultrasound predict the presentation of the first twin at delivery? |
The p-tuned model was able to respond to the prompt correctly with information that it learned from the PubMedQA dataset.
| ANSWER: Yes, third-trimester ultrasound can predict the presentation of the first twin at delivery with a high degree of accuracy. According to the study you provided, the positive predictive value of cephalic presentation of twin A as determined by ultrasound for the persistence of cephalic presentation at delivery reached 95% after 28 weeks gestation.
Similarly, the positive predictive value for noncephalic presentation as established by sonogram for noncephalic presentation at delivery was >90% after 32 weeks gestation. These findings suggest that ultrasound in the third trimester can provide a reliable prediction of the presentation of the first twin at birth. However, it’s important to note that ultrasound is not always 100% accurate and other factors such as fetal movement and positioning can affect the accuracy of the prediction. |
With AI Workbench users can quickly create or clone existing generative AI projects to get started. Developers can go from early exploration on local machines, all the way up to model tuning on workstations and push into scalable resources in the cloud and data center for large-scale training.
Cost-effective scalability of generative AI using NVIDIA AI Workbench
As AI models become increasingly complex and computationally intensive, it’s essential for developers to have cost-effective tools that enable them to scale up quickly and efficiently. AI Workbench provides a single platform for managing data, models, and compute resources, for seamless collaboration and deployment across machines and environments. With this platform, developers of all skill levels can quickly create and deploy cost-effective, scalable generative AI models.
To learn more about AI Workbench, or to sign up to be notified about the availability of early access, visit the AI Workbench page.
Microsoft Azure users can now turn to the latest NVIDIA accelerated computing technology to train and deploy their generative AI applications. Available today, the Microsoft Azure ND H100 v5 VMs using NVIDIA H100 Tensor Core GPUs and NVIDIA Quantum-2 InfiniBand networking — enables scaling generative AI, high performance computing (HPC) and other applications with a Read article >
 In the realm of computer graphics, achieving photorealistic visuals has been a long-sought goal. NVIDIA OptiX is a powerful and flexible ray-tracing framework,…
In the realm of computer graphics, achieving photorealistic visuals has been a long-sought goal. NVIDIA OptiX is a powerful and flexible ray-tracing framework,…
In the realm of computer graphics, achieving photorealistic visuals has been a long-sought goal. NVIDIA OptiX is a powerful and flexible ray-tracing framework, enabling you to harness the potential of ray tracing. NVIDIA OptiX is a GPU-accelerated, ray-casting API based on the CUDA parallel programming model. It gives you all the tools required to implement ray tracing, enabling you to define and execute complex ray tracing algorithms efficiently on NVIDIA GPUs. Used with a graphics API like OpenGL or DirectX, NVIDIA OptiX permits you to create a renderer that enables faster and more cost-effective product development cycles.
NVIDIA OptiX is widely used across various Media and Entertainment verticals like product design and visualization. It empowers designers to render high-quality images and animations of their products, helping them visualize and iterate on designs more effectively. Realistic lighting and materials can be accurately simulated, providing a more realistic representation of the final product.

Figure 1 is a 3D character rendered by artist Ian Spriggs. The workflow used NVIDIA RTX rendering with two NVIDIA RTX 6000 graphic cards.
NVIDIA OptiX has also found its place in the film and animation industry, where accurate and realistic rendering is crucial. It enables artists to create striking visual effects, simulate complex lighting scenarios, and achieve cinematic realism.
This release adds support for Shader Execution Reordering (SER). SER is a performance optimization that enables reordering the execution of ray tracing workloads for better thread and memory coherency. It minimizes divergence by sorting the rays making sure they’re more coherent when being executed. This optimization helps reduce both execution and data divergence in rendering workloads. Here are some key benefits and features of NVIDIA OptiX.
Key benefits
Here are some of the key benefits of NVIDIA OptiX:
- Programmable shading: Enables you to create highly customizable shading algorithms by providing a programmable pipeline. This flexibility enables advanced rendering techniques, including global illumination, shadows, reflections, and refractions.
- High performance: Uses the immense computational power of NVIDIA GPUs to achieve ray tracing performance. By using hardware acceleration, NVIDIA OptiX efficiently processes complex scenes with large numbers of geometric objects, textures, and lights.
- Ray-tracing acceleration structures: Offers built-in acceleration structures, such as bounding volume hierarchies (BVH) and kd-trees, which optimize ray-object intersection calculations. These acceleration structures reduce the computational complexity of ray-object intersection tests, resulting in faster rendering times.
- Dynamic scene updates: Enables interactive applications where objects, lights, or camera positions can change in real time.
- CUDA integration: Built on top of the CUDA platform, which provides direct access to the underlying GPU hardware. This integration enables you to leverage the full power of CUDA, including low-level memory management, parallel computation, and access to advanced GPU features.
- Motion blur: Enables better performance, especially with hardware-accelerated motion blur, which is available only in NVIDIA OptiX.
- Multi-level instancing: Helps you scale your project, especially when working with large scenes.
- NVIDIA OptiX denoiser: Provides support for many denoising modes including HDR, temporal, AOV, and upscaling.
- NVIDIA OptiX primitives: Offers many supported primitive types, such as triangles, curves, and spheres. Also, opacity micromaps (OMMs) and displacement micromaps (DMMs) have recently been added for greater flexibility and complexity in your scene.
Key features
Here are some of the key features of NVIDIA OptiX:
- Shader execution reordering (SER)
- Programmable, GPU-accelerated ray tracing pipeline
- Single-ray shader programming model using C++
- Optimized for current and future NVIDIA GPU architectures
- Transparently scales across multiple GPUs
- Automatically combines GPU memory over NVLink for large scenes
- AI-accelerated rendering using NVIDIA Tensor Cores
- Ray-tracing acceleration using NVIDIA RT Cores
- Free for commercial use
- Arm support
NVIDIA OptiX accelerates ray tracing, providing you with a powerful framework to create visually stunning graphics and simulations. Its programmable shading, high performance, and dynamic scene updates make it a versatile tool across various industries, particularly film production. With NVIDIA OptiX, you can unlock the full potential of ray tracing and deliver compelling immersive experiences.
Next steps
Learn more about NVIDIA OptiX or get started with an NVIDIA OptiX download. NVIDIA OptiX is free to use within any application, including commercial and educational applications. To download, you must be a member of the NVIDIA Developer Program.
Categories
NVIDIA CEO Jensen Huang Returns to SIGGRAPH
One pandemic and one generative AI revolution later, NVIDIA founder and CEO Jensen Huang returns to the SIGGRAPH stage next week to deliver a live keynote at the world’s largest professional graphics conference. The address, slated for Tuesday, Aug. 8, at 8 a.m. PT in Los Angeles, will feature an exclusive look at some of Read article >