
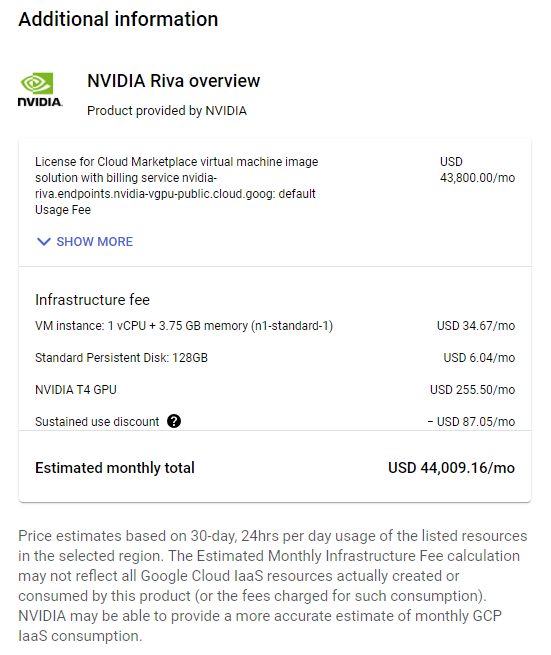
As generative AI and large language models (LLMs) continue to drive innovations, compute requirements for training and inference have grown at an astonishing pace. To meet that need, Google Cloud today announced the general availability of its new A3 instances, powered by NVIDIA H100 Tensor Core GPUs. These GPUs bring unprecedented performance to all kinds Read article >
 From start-ups to large enterprises, businesses use cloud marketplaces to find the new solutions needed to quickly transform their businesses. Cloud…
From start-ups to large enterprises, businesses use cloud marketplaces to find the new solutions needed to quickly transform their businesses. Cloud…
From start-ups to large enterprises, businesses use cloud marketplaces to find the new solutions needed to quickly transform their businesses. Cloud marketplaces are online storefronts where customers can purchase software and services with flexible billing models, including pay-as-you-go, subscriptions, and privately negotiated offers. Businesses further benefit from committed spending at discount prices and a single source of billing and invoicing that saves time and resources.
NVIDIA Riva state-of-the-art speech and translation AI services are on the largest cloud service providers (CSP) marketplaces:
Companies can quickly find high-performance speech and translation AI that can be fully customized to best fit conversational pipelines such as question and answering services, intelligent virtual assistants, digital avatars, and agent assists for contact centers in different languages.
Organizations can quickly run Riva on the public cloud or integrate it with cloud provider services with greater confidence and a better return on their investment. With NVIDIA Riva in the cloud, you can now get instant access to Riva speech and translation AI through your browser—even if you don’t currently have your own on-premises GPU-accelerated infrastructure.
Purchase NVIDIA Riva from the marketplace, or use existing cloud credits. Contact NVIDIA for discounted private pricing through a Amazon Web Services, Google Cloud Platform, or Microsoft Azure private offer.
In this post and the associated videos, using Spanish-to-English speech-to-speech (S2S) translation as an example, you learn how to prototype and test Riva on a single CSP node. This post also covers deploying Riva in production at scale on a managed Kubernetes cluster.
Prototype and test Riva on a single node
Before launching and scaling a conversational application with Riva, prototype and test on a single node to find defects and improvement areas and ensure perfect production performance.
- Select and launch the Riva virtual machine image (VMI) on the public CSPs
- Access the Riva container on the NVIDIA GPU Cloud (NGC) catalog
- Configure the NGC CLI
- Edit the Riva Skills Quick Start configuration script and deploy the Riva server
- Get started with Riva with tutorial Jupyter notebooks
- Run speech-to-speech (S2S) translation inference
Video 1 explains how to launch a GCP virtual machine instance from the Riva VMI and connect to it from a terminal.
Video 2 shows how to start the Riva Server and run Spanish-to-English speech-to-speech translation in the virtual machine instance.
Select and launch the Riva VMI on a public CSP
The Riva VMI provides a self-contained environment that enables you to run Riva on single nodes in public cloud services. You can quickly launch with the following steps.
Go to your chosen CSP:
Choose the appropriate button to begin configuring the VM instance.
- Set the compute zone, GPU and CPU types, and network security rules. The S2S translation demo should only take 13-14 GB of GPU memory and should be able to run on a 16 GB T4 GPU.
- If necessary, generate an SSH key pair.
Deploy the VM instance and edit it further, if necessary. Connect to the VM instance using SSH and a key file in your local terminal (this is the safest way).
Connecting to a GCP VM instance with SSH and a key file requires the gcloud CLI rather than the built-in SSH tool. Use the following command format:
gcloud compute ssh --project= --zone= -- -L 8888:localhost:8888
If you’ve already added the Project_ID and compute-zone values to your gcloud config, you can omit those flags in the command. The -L flag enables port forwarding, which enables you to launch Jupyter on the VM instance and access it in your local browser as though the Jupyter server were running locally.
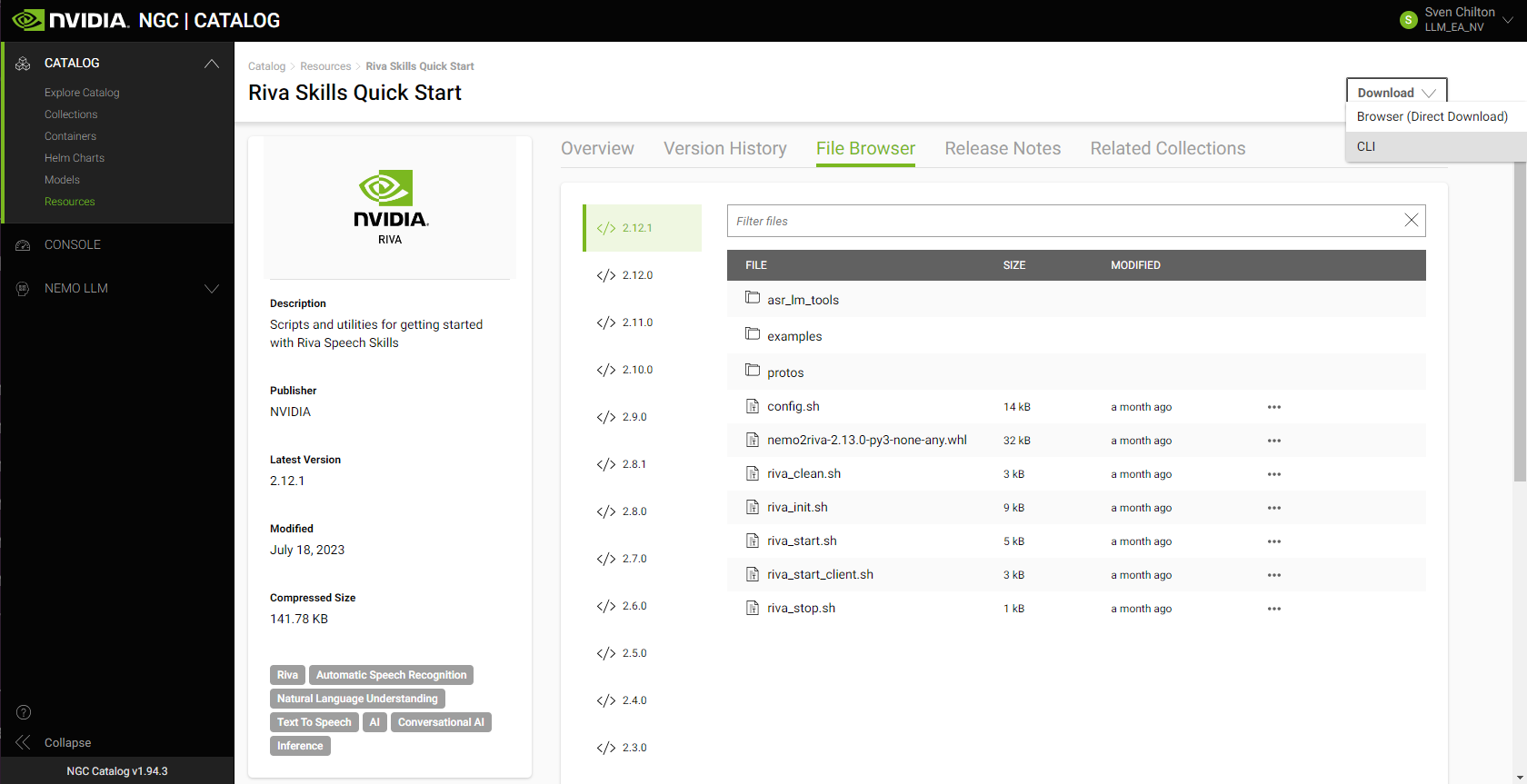
Access the Riva container on NGC
The NGC catalog is a curated set of GPU-accelerated AI models and SDKs to help you quickly infuse AI into your applications.
The easiest way to download the Riva containers and desired models into the VM instance is to download the Riva Skills Quick Start resource folder with the appropriate ngc command, edit the provided config.sh script, and run the riva_init.sh and riva_start.sh scripts.
An additional perk for Riva VMI subscribers is access to the NVIDIA AI Enterprise Catalog on NGC.
Configure the NGC CLI to access resources
Your NGC CLI configuration ensures that you can access NVIDIA software resources. The configuration also determines which container registry space you can access.
The Riva VMI already provides the NGC CLI, so you don’t have to download or install it. You do still need to configure it.
Generate an NGC API key, if necessary. At the top right, choose your name and org. Choose Setup, Get API Key, and Generate API Key. Make sure to copy and save your newly generated API key someplace safe.
Run ngc config set and paste in your API key. Set the output format for the results of calls to the NGC CLI and set your org, team, and ACE.
Edit the Riva Skills Quick Start configuration script and deploy the Riva Server
Riva includes Quick Start scripts to help you get started with Riva speech and translation AI services:
- Automatic speech recognition (ASR)
- Text-to-speech (TTS)
- Several natural language processing (NLP) tasks
- Neural machine translation (NMT)
On the asset’s NGC overview page, choose Download. To copy the appropriate NGC CLI command into your VM instance’s terminal, choose CLI:
ngc registry resource download-version "nvidia/riva/riva_quickstart:2.12.1"
At publication time, 2.12.1 is the most recent version of Riva. Check the NGC catalog or the Riva documentation page for the latest version number.
After downloading the Riva Skills Quick Start resource folder in your VM instance’s terminal, implement a Spanish-to-English speech-to-speech (S2S) translation pipeline.
In the Riva Skills Quick Start home directory, edit the config.sh script to tell Riva which services to enable and which model files in the .rmir format to download.
Set service_enabled_nlp=false but leave the other services as true. You need Spanish ASR, Spanish-to-English NMT, and English TTS. There is no need for NLP.
To enable Spanish ASR, change language_code=("en-US") to language_code=("es-US").
Uncomment the line containing rmir_megatronnmt_any_en_500m to enable NMT from Spanish (and any of over 30 additional languages) to English.
To download the desired .rmir files and deploy them, run the following command. riva_init.sh wraps around the riva-deploy command.
bash riva_init.sh config.sh
To start the Riva server, run the following command:
bash riva_start.sh config.sh
If the server doesn’t start, output the relevant Docker logs to a file:
docker logs riva-speech &> docker-logs-riva-speech.txt
Inspect the file. If you see any CUDA out-of-memory errors, your model pipeline is too big for your GPU.
Get started with Riva through Jupyter notebook tutorials
One of the best ways to get started with Riva is to work through the Jupyter notebook tutorials in the /nvidia-riva/tutorials GitHub repo:
git clone https://github.com/nvidia-riva/tutorials.git
The VMI already contains a miniconda Python distribution, which includes Jupyter. Create a new conda environment from the base (default) environment in which to install dependencies, then launch Jupyter.
Clone the base (default) environment:
conda create --name conda-riva-tutorials --clone base
Activate the new environment:
conda activate conda-riva-tutorials
Install an iPython kernel for the new environment:
ipython kernel install --user --name=conda-riva-tutorials
Launch Jupyter Lab:
jupyter lab --allow-root --ip 0.0.0.0 --port 8888
If you set up port forwarding when connecting to the VM instance with gcloud compute ssh, choose the link containing 127.0.0.1 to run Jupyter Lab in your local browser. If not, enter the following into your browser bar to run Jupyter Lab:
- Your VM instance’s external IP address
- A colon (:)
- The port number (presumably
8888) /lab?token=
If you don’t want to copy and paste the token in the browser bar, the browser asks you to enter the token in a dialog box instead.
Run the speech-to-speech translation demo
This speech-to-speech (S2S) demonstration consists of a modified version of the nmt-python-basics.ipynb tutorial notebook. To carry it out, perform the following steps.
Import the necessary modules:
import IPython.display as ipd
import numpy as np
import riva.client
Create a Riva client and connect to the Riva server:
auth = riva.client.Auth(uri="localhost:50051")
riva_nmt_client = riva.client.NeuralMachineTranslationClient(auth)
Load the audio file:
my_wav_file = "ASR-Demo-2-Spanish-Non-Native-Elena.wav"
The audio file contains a clip of a colleague reading a line from Miguel de Cervantes’ celebrated novel Don Quixote, “Cuando la vida misma parece lunática, ¿quién sabe dónde está la locura?”
This can be translated into English as, “When life itself seems lunatic, who knows where madness lies?”
Set up an audio chunk iterator, that is, divide the audio file into chunks no larger than a given number of frames:
audio_chunk_iterator = riva.client.AudioChunkFileIterator(my_wav_file, chunk_n_frames=4800)
Define an S2S config, composed of a sequence of ASR, NMT, and TTS configs:
s2s_config = riva.client.StreamingTranslateSpeechToSpeechConfig(
asr_config = riva.client.StreamingRecognitionConfig(
config=riva.client.RecognitionConfig(
encoding=riva.client.AudioEncoding.LINEAR_PCM,
language_code='es-US', # Spanish ASR model
max_alternatives=1,
profanity_filter=False,
enable_automatic_punctuation=True,
verbatim_transcripts=not True,
sample_rate_hertz=16000,
audio_channel_count=1,
),
interim_results=True,
),
translation_config = riva.client.TranslationConfig(
source_language_code="es-US", # Source language is Spanish
target_language_code='en-US', # Target language is English
model_name='megatronnmt_any_en_500m',
),
tts_config = riva.client.SynthesizeSpeechConfig(
encoding=1,
sample_rate_hz=44100,
voice_name="English-US.Female-1", # Default EN female voice
language_code="en-US",
),
)
Make gRPC requests to the Riva Speech API server:
responses = riva_nmt_client.streaming_s2s_response_generator(
audio_chunks=audio_chunk_iterator,
streaming_config=s2s_config)
Listen to the streaming response:
# Create an empty array to store the receiving audio buffer
empty = np.array([])
# Send requests and listen to streaming response from the S2S service
for i, rep in enumerate(responses):
audio_samples = np.frombuffer(rep.speech.audio, dtype=np.int16) / (2**15)
print("Chunk: ",i)
try:
ipd.display(ipd.Audio(audio_samples, rate=44100))
except:
print("Empty response")
empty = np.concatenate((empty, audio_samples))
# Full translated synthesized speech
print("Final synthesis:")
ipd.display(ipd.Audio(empty, rate=44100))
This yields clips of synthesized speech in chunks and a final, fully assembled clip. The synthesized voice in the final clip should say, “When life itself seems lunatic, who knows where madness lies?”
Deploy Riva on a managed Kubernetes platform
After launching a Riva VMI and gaining access to the enterprise catalog, you can also deploy Riva to the various supported managed Kubernetes platforms like AKS, Amazon EKS, and GKE. These managed Kubernetes platforms are ideal for production-grade deployments because they enable seamless automated deployment, easy scalability, and efficient operability.
To help you get started, this post guides you through an example deployment for Riva on a GKE cluster. By combining the power of Terraform and Helm, you can quickly stand up production-grade deployments.
- Set up a Kubernetes cluster on a managed Kubernetes platform with the NVIDIA Terraform modules
- Deploy the Riva server on the Kubernetes cluster with a Helm chart
- Interact with Riva on the Kubernetes cluster
Video 3 explains how to set up and run Riva on Google Kubernetes Engine (GKE) with Terraform.
Video 4 shows how to scale up and out speech AI inference by deploying Riva on the Kubernetes cluster with Helm.
Set up the GKE cluster with the NVIDIA Terraform modules
The NVIDIA Terraform modules make it easy to deploy a Riva-ready GKE cluster. For more information, see the /nvidia-terraform-modules GitHub repo.
To get started, clone the repo and install the prerequisites on a machine:
- kubectl
- gcloud CLI
- Make sure that you also install the GKE authentication plugin by running
gcloud components install gke-gcloud-auth-plugin
- Make sure that you also install the GKE authentication plugin by running
- GCP account where you have Kubernetes Engine Admin permissions
- Terraform (CLI)
From within the nvidia-terraform-modules/gke directory, ensure that you have active credentials set with the gcloud CLI.
Update terraform.tfvars by uncommenting cluster_name and region and filling out the values specific to your project. By default, this module deploys the cluster into a new VPC. To deploy the cluster into an existing VPC, you must also uncomment and set the existing_vpc_details variable.
Alternatively, you can change any variable names or parameters in any of the following ways:
- Add them directly to
variables.tf. - Pass them in from the command line with the
-varflag. - Pass them in as environment variables.
- Pass them in from the command line when prompted.
In variables.tf, update the following variables for use by Riva: GPU type and region.
Select a supported GPU type:
variable "gpu_type" {
default = "nvidia-tesla-t4"
description = "GPU SKU To attach to Holoscan GPU Node (eg. nvidia-tesla-k80)"
}
(Optional) Select your region:
variable "region" {
default = "us-west1"
description = "The Region resources (VPC, GKE, Compute Nodes) will be created in"
}
Run gcloud auth application-default login to make your Google credentials available to the terraform executable. For more information, see Assigning values to root module variables in the Terraform documentation.
terraform init: Initialize the configuration.terraform plan: See what will be applied.terraform apply: Apply the code against your GKE environment.
Connect to the cluster with kubectl by running the following command after the cluster is created:
gcloud container clusters get-credentials --region=
To delete cloud infrastructure provisioned by Terraform, run terraform destroy.
The NVIDIA Terraform modules can also be used for deployments in other CSPs and follow a similar pattern. For more information about deploying AKS and EKS clusters, see the /nvidia-terraform-modules GitHub repo.
Deploy the Riva Speech Skills API with a Helm chart
The Riva speech skills Helm chart is designed to automate deployment to a Kubernetes cluster. After downloading the Helm chart, minor adjustments adapt the chart to the way Riva is used in the rest of this post.
Start by downloading and untarring the Riva API Helm chart. The 2.12.1 version is the most recent as of this post. To download a different version of the Helm chart, replace VERSION_TAG with the specific version needed in the following code example:
export NGC_CLI_API_KEY=
export VERSION_TAG="2.12.1"
helm fetch https://helm.ngc.nvidia.com/nvidia/riva/charts/riva-api-${VERSION_TAG}.tgz --username='$oauthtoken' --password=$NGC_CLI_API_KEY
tar -xvzf riva-api-${VERSION_TAG}.tgz
In the riva-api folder, modify the following files as noted.
In the values.yaml file, in modelRepoGenerator.ngcModelConfigs.tritonGroup0, comment or uncomment specific models or change language codes as needed.
For the S2S pipeline used earlier:
- Change the language code in the ASR model from US English to Latin American Spanish, so that
rmir_asr_conformer_en_us_str_thrbecomesrmir_asr_conformer_es_us_str_thr. - Uncomment the line containing
rmir_megatronnmt_any_en_500m. - Ensure that
service.typeis set toClusterIPrather thanLoadBalancer. This exposes the service only to other services within the cluster, such as the proxy service installed later in this post.
In the templates/deployment.yaml file, follow up by adding a node selector constraint to ensure that Riva is only deployed on the correct GPU resources. Attach it to a node pool (called a node group in Amazon EKS). You can get this from the GCP console or by running the appropriate gcloud commands in your terminal:
$ gcloud container clusters list
NAME LOCATION MASTER_VERSION MASTER_IP MACHINE_TYPE NODE_VERSION NUM_NODES STATUS
riva-in-the-cloud-blog-demo us-west1 1.27.3-gke.100 35.247.68.177 n1-standard-4 1.27.3-gke.100 3 RUNNING
$ gcloud container node-pools list --cluster=riva-in-the-cloud-blog-demo --location=us-west1
NAME MACHINE_TYPE DISK_SIZE_GB NODE_VERSION
tf-riva-in-the-cloud-blog-demo-cpu-pool n1-standard-4 100 1.27.3-gke.100
tf-riva-in-the-cloud-blog-demo-gpu-pool n1-standard-4 100 1.27.3-gke.100
In spec.template.spec, add the following with your node pool name from earlier:
nodeSelector:
cloud.google.com/gke-nodepool: tf-riva-in-the-cloud-blog-demo-gpu-pool
Ensure that you are in a working directory with /riva-api as a subdirectory, then install the Riva Helm chart. You can explicitly override variables from the values.yaml file.
helm install riva-api riva-api/
--set ngcCredentials.password=`echo -n $NGC_CLI_API_KEY | base64 -w0`
--set modelRepoGenerator.modelDeployKey=`echo -n tlt_encode | base64 -w0`
The Helm chart runs two containers in order:
- A
riva-model-initcontainer that downloads and deploys the models. - A
riva-speech-apicontainer to start the speech service API.
Depending on the number of models, the initial model deployment could take an hour or more. To monitor the deployment, use kubectl to describe the riva-api Pod and to watch the container logs.
export pod=`kubectl get pods | cut -d " " -f 1 | grep riva-api`
kubectl describe pod $pod
kubectl logs -f $pod -c riva-model-init
kubectl logs -f $pod -c riva-speech-api
The Riva server is now deployed.
Interact with Riva on the GKE cluster
While this method of interacting with the server is probably not ideally suited to production environments, you can run the S2S translation demo from anywhere outside the GKE cluster by changing the URI in the call to riva.client.Auth so that the Riva Python client sends inference requests to the riva-api service on the GKE cluster rather than the local host. Obtain the appropriate URI with kubectl:
$ kubectl get services
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.155.240.1 443/TCP 1h
riva-api LoadBalancer 10.155.243.119 34.127.90.22 8000:30623/TCP,8001:30542/TCP,8002:32113/TCP,50051:30842/TCP 1h
No port forwarding is taking place here. To run the Spanish-to-English S2S translation pipeline on the GKE cluster from a Jupyter notebook outside the cluster, change the following line:
auth = riva.client.Auth(uri="localhost:50051")
Here’s the desired line:
auth = riva.client.Auth(uri=":50051")
There are multiple ways to interact with the server. One method involves deploying IngressRoute through a Traefik Edge router deployable through Helm. For more information, see Deploying the Traefik edge router.
NVIDIA also provides an opinionated production deployment recipe through the Speech AI Workflows, Audio Transcription, Intelligent Virtual Assistant. For more information, see the Technical Brief.
Summary
NVIDIA Riva is available on the Amazon Web Services, Google Cloud, and Microsoft Azure marketplaces. Get started with prototyping and testing Riva in the cloud on a single node through quickly deployable VMIs. For more information, see the NVIDIA Riva on GCP videos.
Production-grade Riva deployments on Managed Kubernetes are easy with NVIDIA Terraform modules. For more information, see the NVIDIA Riva on GKE videos.
Deploy Riva on CSP compute resources with cloud credits by purchasing a license from a CSP marketplace:
You can also reach out to NVIDIA through the Amazon Web Services, Google Cloud, or Microsoft Azure forms for discount pricing with private offers.
 Generative AI has become a transformative force of our era, empowering organizations spanning every industry to achieve unparalleled levels of productivity,…
Generative AI has become a transformative force of our era, empowering organizations spanning every industry to achieve unparalleled levels of productivity,…
Generative AI has become a transformative force of our era, empowering organizations spanning every industry to achieve unparalleled levels of productivity, elevate customer experiences, and deliver superior operational efficiencies.
Large language models (LLMs) are the brains behind generative AI. Access to incredibly powerful and knowledgeable foundation models, like Llama and Falcon, has opened the door to amazing opportunities. However, these models lack the domain-specific knowledge required to serve enterprise use cases.
Developers have three choices for powering their generative AI applications:
- Pretrained LLMs: the easiest lift is to use foundation models, which work very well for use cases that rely on general-purpose knowledge.
- Custom LLMs: pretrained models customized with domain-specific knowledge, and task-specific skills, connected to enterprises’ knowledge bases perform tasks and provide responses based on the latest proprietary information.
- Develop LLMs: organizations with specialized data (for example, models catering to regional languages) cannot use pretrained foundation models and must build their models from scratch.
NVIDIA NeMo is an end-to-end, cloud-native framework for building, customizing, and deploying generative AI models. It includes training and inferencing frameworks, guardrails, and data curation tools, for an easy, cost-effective, and fast way to adopt generative AI.
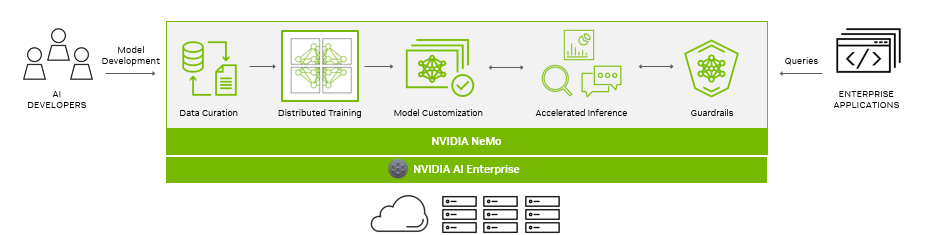
As generative AI models and their development continue to progress, the AI stack and its dependencies become increasingly complex. For enterprises running their business on AI, NVIDIA provides a production-grade, secure, end-to-end software solution with NVIDIA AI Enterprise.
Organizations are running their mission-critical enterprise applications on Google Cloud, a leading provider of GPU-accelerated cloud platforms. NVIDIA AI Enterprise, which includes NeMo and is available on Google Cloud, helps organizations adopt generative AI faster.
Building a generative AI solution requires that the full stack, from compute to networking, systems, management software, training, and inference SDKs work in harmony.
At Google Cloud Next 2023, Google Cloud announced the general availability of their A3 instances powered by NVIDIA H100 Tensor Core GPUs. Engineering teams from both companies are collaborating to bring NeMo to the A3 instances for faster training and inference.
In this post, we cover training and inference optimizations developers can enjoy while building and running their custom generative AI models on NVIDIA H100 GPUs.
Data curation at scale
The potential of a single LLM achieving exceptional outcomes across diverse tasks is due to training on an immense volume of Internet-scale data.
NVIDIA NeMo Data Curator facilitates the handling of trillion-token multilingual training data for LLMs. It consists of a collection of Python modules leveraging MPI, Dask, and a Redis cluster to scale tasks involved in data curation efficiently. These tasks include data downloads, text extractions, text reformatting, quality filtering, and removal of exact or fuzzy duplicate data. This tool can distribute these tasks across thousands of computational cores.
Using these modules aids developers in swiftly sifting through unstructured data sources. This technology accelerates model training, reduces costs through efficient data preparation, and yields more precise results.
Accelerated model training
NeMo employs distributed training using sophisticated parallelism methods to use GPU resources and memory across multiple nodes on a large scale. By breaking down the model and training data, NeMo enables optimal throughput and significantly reduces the time required for training, which also speeds up TTM.
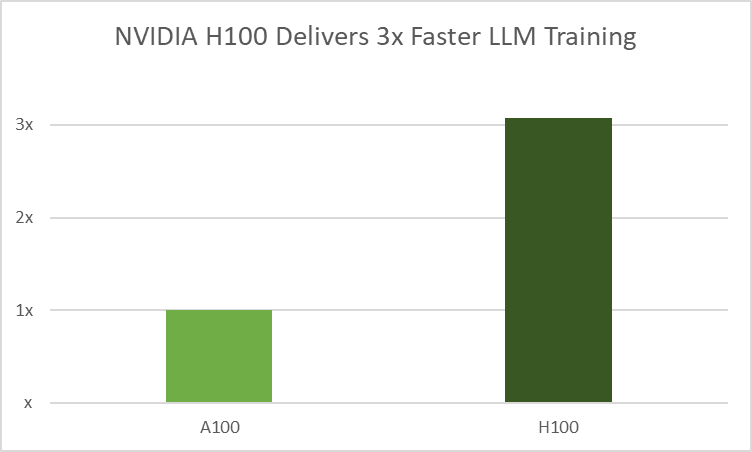
H100 GPUs employ NVIDIA Transformer Engine (TE), a library that enhances AI performance by combining 16-bit and 8-bit floating-point formats with advanced algorithms. It achieves faster LLM training without losing accuracy by reducing math operations to FP8 from the typical FP16 and FP32 formats used in AI workloads. This optimization uses per-layer statistical analysis to increase precision for each model layer, resulting in optimal performance and accuracy.
AutoConfigurator delivers developer productivity
Finding model configurations for LLMs across distributed infrastructure is a time-consuming process. NeMo provides AutoConfigurator, a hyperparameter tool to find optimal training configurations automatically, enabling high throughput LLMs to train faster. This saves developers time searching for efficient model configurations.
It applies heuristics and grid search techniques to various parameters, such as tensor parallelism, pipeline parallelism, micro-batch size, and activation checkpointing layers, aimed at determining configurations with the highest throughputs.
AutoConfigurator can also find model configurations that achieve the highest throughput or lowest latency during inference. Latency and throughput constraints can be provided to deploy the model, and the tool will recommend suitable configurations.
Review the recipes for building generative AI models of various sizes for GPT, MT5, T5, and BERT architectures.
Model customization
In the realm of LLMs, one size rarely fits all, especially in enterprise applications. Off-the-shelf LLMs often fall short in catering to the distinct requirements of the organizations, whether it’s the intricacies of specialized domain knowledge, industry jargon, or unique operational scenarios.
This is precisely where the significance of custom LLMs comes into play. Enterprises must fine-tune models that support the capabilities for specific use cases and domain expertise. These customized models provide enterprises with the means to create solutions personalized to match their brand voice and streamline workflows, for more accurate insights, and rich user experiences.
NeMo supports a variety of customization techniques, for developers to use NVIDIA-built models by adding functional skills, focusing on specific domains, and implementing guardrails to prevent inappropriate responses.
Additionally, the framework supports community-built pretrain LLMs including Llama 2, BLOOM, and Bart, and supports GPT, T5, mT5, T5-MoE, and Bert architectures.
- P-Tuning trains a small helper model to set the context for the frozen LLM to generate a relevant and accurate response.
- Adapters/IA3 introduce small, task-specific feedforward layers within the core transformer architecture, adding minimal trainable parameters per task. This makes for easy integration of new tasks without reworking existing ones.
- Low-Rank Adaption uses compact additional modules to enhance model performance on specific tasks without substantial changes to the original model.
- Supervised Fine-tuning calibrates model parameters on labeled data of inputs and outputs, teaching the model domain-specific terms and how to follow user-specified instructions.
- Reinforcement Learning with Human Feedback enables LLMs to achieve better alignment with human values and preferences.
Learn more about various LLM customization techniques.
Accelerated inference
Community LLMs are growing at an explosive rate, with increased demand from companies to deploy these models into production. The size of these LLMs is driving the cost and complexity of deployment higher, requiring optimized inference performance for production applications. Higher performance not only helps decrease costs but also improves user experiences.
LLMs such as LLaMa, BLOOM, ChatGLM, Falcon, MPT, and Starcoder have demonstrated the potential of advanced architectures and operators. This has created a challenge in producing a solution that can efficiently optimize these models for inference, something that is highly desirable in the ecosystem.
NeMo employs MHA and KV cache optimizations, flash attention, quantized KV cache, and paged attention, among other techniques to solve the large set of LLM optimization challenges. It enables developers to try new LLM and customize foundation models for peak performance without requiring deep knowledge of C++ or NVIDIA CUDA optimization.
NeMo also leverages NVIDIA TensorRT deep learning compiler, pre- and post-processing optimizations, and multi-GPU multi-node communication. In an open-source Python API, it defines, optimizes, and executes LLMs for inference in production applications.
NeMo Guardrails
LLMs can be biased, provide inappropriate responses, and hallucinate. NeMo Guardrails is an open-source, programmable toolkit for addressing these challenges. It sits between the user and the LLM, screening and filtering inappropriate user prompts as well as LLM responses.
Building guardrails for various scenarios is straightforward. First, define a guardrail by providing a few examples in natural language. Then, define a response when a question on that topic is generated. Lastly, define a flow, which dictates the set of actions to be taken when the topic or the flow is triggered.
NeMo Guardrails can help the LLM stay focused on topics, prevent toxic responses, and make sure that replies are generated from credible sources before they are presented to users. Read about building trustworthy, safe, and secure LLM conversational systems.
Simplify deployment with ecosystem tools
NeMo works with MLOps ecosystem technologies such as Weights & Biases (W&B) providing powerful capabilities for accelerating the development, tuning, and adoption of LLMs.
Developers can debug, fine-tune, compare, and reproduce models with the W&B MLOps platform. W&B Prompts help organizations understand, tune, and analyze LLM performance. W&B integrates with Google Cloud products commonly used in ML development.
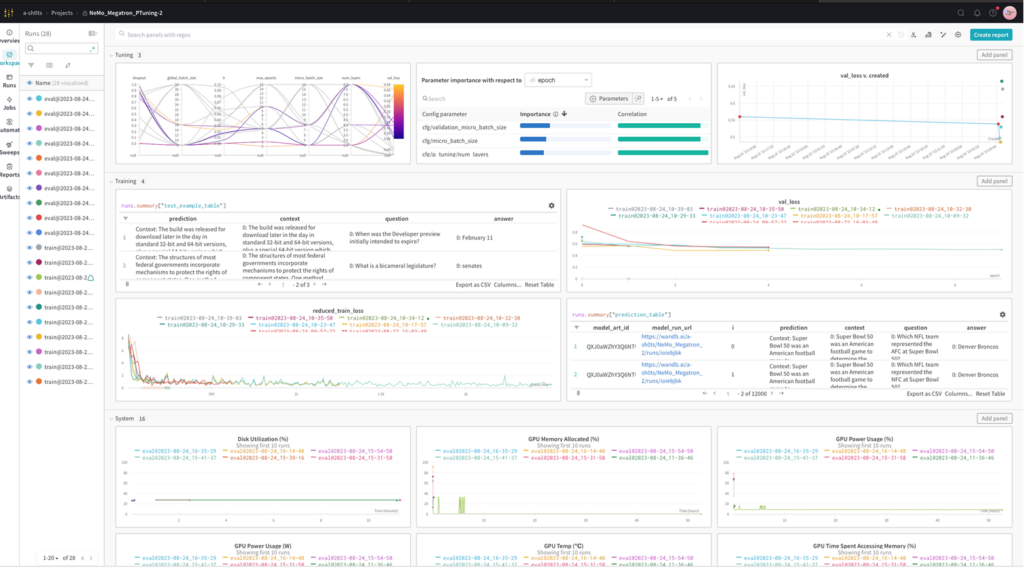
The combination of NeMo, W&B, and Google Cloud is on display at the NVIDIA booth at Google Cloud Next.
Fuel generative AI applications
Writer, a leading generative AI-based content creation service, is harnessing NeMo capabilities and accelerated compute on Google Cloud. They’ve built up to 40B parameter language models that now cater to hundreds of customers, revolutionizing content generation.
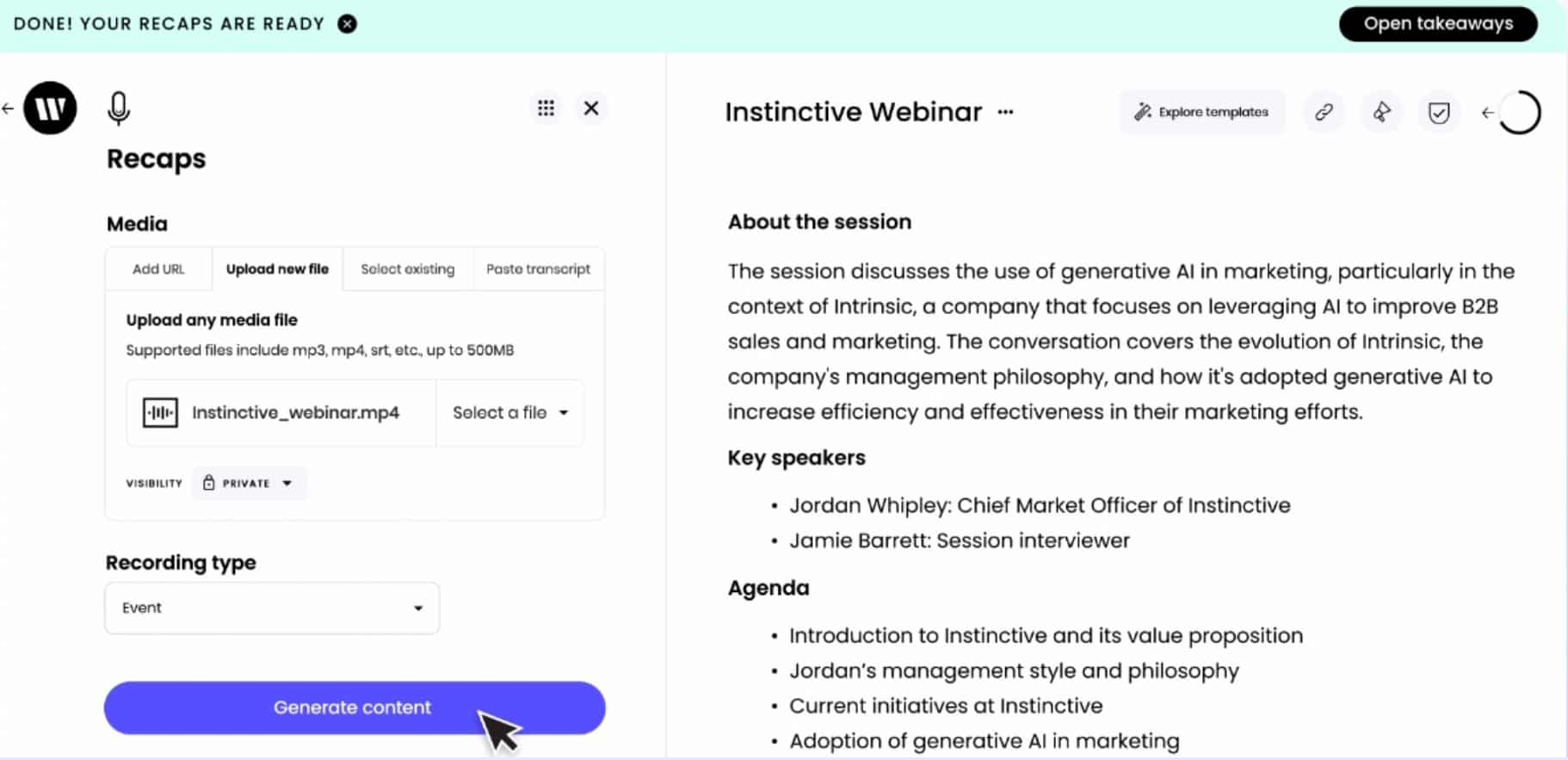
Figure 4. The Writer Recap tool creates written summaries from audio recordings of an interview or event
APMIC is another success story with NeMo at its core. With a dual focus, they leverage NeMo for two distinct use cases. They’ve supercharged their contract verification and verdict summarization processes through entity linking, extracting vital information from documents quickly. They are also using NeMo to customize GPT models, offering customer service and digital human interaction solutions by powering question-answering systems.
Start building your generative AI application
Using AI playground, you can experience the full potential of community and NVIDIA-built generative AI models, optimized for the NVIDIA accelerated stack, directly through your web browser.
Customize GPT, mT5, or BERT-based pretrained LLMs from Hugging Face using NeMo on Google Cloud:
- Access NeMo from GitHub.
- Pull the NeMo container from NGC to run across GPU-accelerated platforms.
- Access NeMo from NVIDIA AI Enterprise available on Google Cloud Marketplace with enterprise-grade support and security.
Get started with NVIDIA NeMo today.
NVIDIA Generative AI Technology Used by Google DeepMind and Google Research Teams Now Optimized and Available to Google Cloud Customers WorldwideSAN FRANCISCO, Aug. 29, 2023 (GLOBE NEWSWIRE) …
Janice K. Lee, a.k.a Janice.Journal — the subject of this week’s In the NVIDIA Studio installment — is a TikTok sensation using AI to accelerate her creative process, find inspiration and automate repetitive tasks.
The ability to detect objects in the visual world is crucial for computer vision and machine intelligence, enabling applications like adaptive autonomous agents and versatile shopping systems. However, modern object detectors are limited by the manual annotations of their training data, resulting in a vocabulary size significantly smaller than the vast array of objects encountered in reality. To overcome this, the open-vocabulary detection task (OVD) has emerged, utilizing image-text pairs for training and incorporating new category names at test time by associating them with the image content. By treating categories as text embeddings, open-vocabulary detectors can predict a wide range of unseen objects. Various techniques such as image-text pre-training, knowledge distillation, pseudo labeling, and frozen models, often employing convolutional neural network (CNN) backbones, have been proposed. With the growing popularity of vision transformers (ViTs), it is important to explore their potential for building proficient open-vocabulary detectors.
The existing approaches assume the availability of pre-trained vision-language models (VLMs) and focus on fine-tuning or distillation from these models to address the disparity between image-level pre-training and object-level fine-tuning. However, as VLMs are primarily designed for image-level tasks like classification and retrieval, they do not fully leverage the concept of objects or regions during the pre-training phase. Thus, it could be beneficial for open-vocabulary detection if we build locality information into the image-text pre-training.
In “RO-ViT: Region-Aware Pretraining for Open-Vocabulary Object Detection with Vision Transformers”, presented at CVPR 2023, we introduce a simple method to pre-train vision transformers in a region-aware manner to improve open-vocabulary detection. In vision transformers, positional embeddings are added to image patches to encode information about the spatial position of each patch within the image. Standard pre-training typically uses full-image positional embeddings, which does not generalize well to detection tasks. Thus, we propose a new positional embedding scheme, called “cropped positional embedding”, that better aligns with the use of region crops in detection fine-tuning. In addition, we replace the softmax cross entropy loss with focal loss in contrastive image-text learning, allowing us to learn from more challenging and informative examples. Finally, we leverage recent advances in novel object proposals to enhance open-vocabulary detection fine-tuning, which is motivated by the observation that existing methods often miss novel objects during the proposal stage due to overfitting to foreground categories. We are also releasing the code here.
Region-aware image-text pre-training
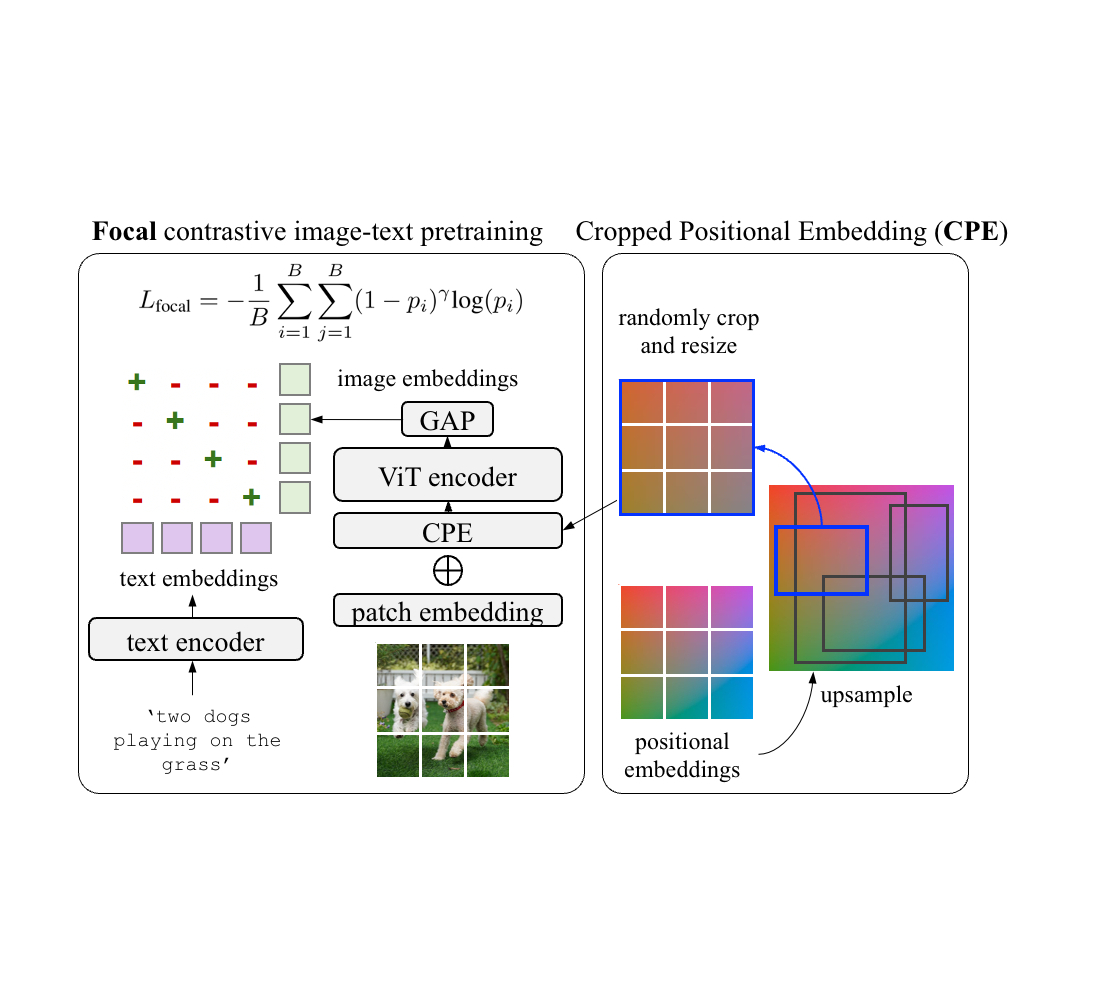
Existing VLMs are trained to match an image as a whole to a text description. However, we observe there is a mismatch between the way the positional embeddings are used in the existing contrastive pre-training approaches and open-vocabulary detection. The positional embeddings are important to transformers as they provide the information of where each element in the set comes from. This information is often useful for downstream recognition and localization tasks. Pre-training approaches typically apply full-image positional embeddings during training, and use the same positional embeddings for downstream tasks, e.g., zero-shot recognition. However, the recognition occurs at region-level for open-vocabulary detection fine-tuning, which requires the full-image positional embeddings to generalize to regions that they never see during the pre-training.
To address this, we propose cropped positional embeddings (CPE). With CPE, we upsample positional embeddings from the image size typical for pre-training, e.g., 224×224 pixels, to that typical for detection tasks, e.g., 1024×1024 pixels. Then we randomly crop and resize a region, and use it as the image-level positional embeddings during pre-training. The position, scale, and aspect ratio of the crop is randomly sampled. Intuitively, this causes the model to view an image not as a full image in itself, but as a region crop from some larger unknown image. This better matches the downstream use case of detection where recognition occurs at region- rather than image-level.
 |
| For the pre-training, we propose cropped positional embedding (CPE) which randomly crops and resizes a region of positional embeddings instead of using the whole-image positional embedding (PE). In addition, we use focal loss instead of the common softmax cross entropy loss for contrastive learning. |
We also find it beneficial to learn from hard examples with a focal loss. Focal loss enables finer control over how hard examples are weighted than what the softmax cross entropy loss can provide. We adopt the focal loss and replace it with the softmax cross entropy loss in both image-to-text and text-to-image losses. Both CPE and focal loss introduce no extra parameters and minimal computation costs.
Open-vocabulary detector fine-tuning
An open-vocabulary detector is trained with the detection labels of ‘base’ categories, but needs to detect the union of ‘base’ and ‘novel’ (unlabeled) categories at test time. Despite the backbone features pre-trained from the vast open-vocabulary data, the added detector layers (neck and heads) are newly trained with the downstream detection dataset. Existing approaches often miss novel/unlabeled objects in the object proposal stage because the proposals tend to classify them as background. To remedy this, we leverage recent advances in a novel object proposal method and adopt the localization quality-based objectness (i.e., centerness score) instead of object-or-not binary classification score, which is combined with the detection score. During training, we compute the detection scores for each detected region as the cosine similarity between the region’s embedding (computed via RoI-Align operation) and the text embeddings of the base categories. At test time, we append the text embeddings of novel categories, and the detection score is now computed with the union of the base and novel categories.
 |
| The pre-trained ViT backbone is transferred to the downstream open-vocabulary detection by replacing the global average pooling with detector heads. The RoI-Align embeddings are matched with the cached category embeddings to obtain the VLM score, which is combined with the detection score into the open-vocabulary detection score. |
Results
We evaluate RO-ViT on the LVIS open-vocabulary detection benchmark. At the system-level, our best model achieves 33.6 box average precision on rare categories (APr) and 32.1 mask APr, which outperforms the best existing ViT-based approach OWL-ViT by 8.0 APr and the best CNN-based approach ViLD-Ens by 5.8 mask APr. It also exceeds the performance of many other approaches based on knowledge distillation, pre-training, or joint training with weak supervision.
 |
| RO-ViT outperforms both the state-of-the-art (SOTA) ViT-based and CNN-based methods on LVIS open-vocabulary detection benchmark. We show mask AP on rare categories (APr) , except for SOTA ViT-based (OwL-ViT) where we show box AP. |
Apart from evaluating region-level representation through open-vocabulary detection, we evaluate the image-level representation of RO-ViT in image-text retrieval through the MS-COCO and Flickr30K benchmarks. Our model with 303M ViT outperforms the state-of-the-art CoCa model with 1B ViT on MS COCO, and is on par on Flickr30K. This shows that our pre-training method not only improves the region-level representation but also the global image-level representation for retrieval.
 |
| We show zero-shot image-text retrieval on MS COCO and Flickr30K benchmarks, and compare with dual-encoder methods. We report recall@1 (top-1 recall) on image-to-text (I2T) and text-to-image (T2I) retrieval tasks. RO-ViT outperforms the state-of-the-art CoCa with the same backbone. |
 |
| RO-ViT open-vocabulary detection on LVIS. We only show the novel categories for clarity. RO-ViT detects many novel categories that it has never seen during detection training: “fishbowl”, “sombrero”, “persimmon”, “gargoyle”. |
Visualization of positional embeddings
We visualize and compare the learned positional embeddings of RO-ViT with the baseline. Each tile is the cosine similarity between positional embeddings of one patch and all other patches. For example, the tile in the top-left corner (marked in red) visualizes the similarity between the positional embedding of the location (row=1, column=1) and those positional embeddings of all other locations in 2D. The brightness of the patch indicates how close the learned positional embeddings of different locations are. RO-ViT forms more distinct clusters at different patch locations showing symmetrical global patterns around the center patch.
 |
| Each tile shows the cosine similarity between the positional embedding of the patch (at the indicated row-column position) and the positional embeddings of all other patches. ViT-B/16 backbone is used. |
Conclusion
We present RO-ViT, a contrastive image-text pre-training framework to bridge the gap between image-level pre-training and open-vocabulary detection fine-tuning. Our methods are simple, scalable, and easy to apply to any contrastive backbones with minimal computation overhead and no increase in parameters. RO-ViT achieves the state-of-the-art on LVIS open-vocabulary detection benchmark and on the image-text retrieval benchmarks, showing the learned representation is not only beneficial at region-level but also highly effective at the image-level. We hope this study can help the research on open-vocabulary detection from the perspective of image-text pre-training which can benefit both region-level and image-level tasks.
Acknowledgements
Dahun Kim, Anelia Angelova, and Weicheng Kuo conducted this work and are now at Google DeepMind. We would like to thank our colleagues at Google Research for their advice and helpful discussions.
Companies are discovering how accelerated computing can boost their bottom lines while making a positive impact on the planet. The NVIDIA RAPIDS Accelerator for Apache Spark, software that speeds data analytics, not only raises performance and lowers costs, it increases energy efficiency, too. That means it can help companies meet goals for net-zero emissions of Read article >
Google’s Responsible AI research is built on a foundation of collaboration — between teams with diverse backgrounds and expertise, between researchers and product developers, and ultimately with the community at large. The Perception Fairness team drives progress by combining deep subject-matter expertise in both computer vision and machine learning (ML) fairness with direct connections to the researchers building the perception systems that power products across Google and beyond. Together, we are working to intentionally design our systems to be inclusive from the ground up, guided by Google’s AI Principles.
 |
| Perception Fairness research spans the design, development, and deployment of advanced multimodal models including the latest foundation and generative models powering Google’s products. |
Our team’s mission is to advance the frontiers of fairness and inclusion in multimodal ML systems, especially related to foundation models and generative AI. This encompasses core technology components including classification, localization, captioning, retrieval, visual question answering, text-to-image or text-to-video generation, and generative image and video editing. We believe that fairness and inclusion can and should be top-line performance goals for these applications. Our research is focused on unlocking novel analyses and mitigations that enable us to proactively design for these objectives throughout the development cycle. We answer core questions, such as: How can we use ML to responsibly and faithfully model human perception of demographic, cultural, and social identities in order to promote fairness and inclusion? What kinds of system biases (e.g., underperforming on images of people with certain skin tones) can we measure and how can we use these metrics to design better algorithms? How can we build more inclusive algorithms and systems and react quickly when failures occur?
Measuring representation of people in media
ML systems that can edit, curate or create images or videos can affect anyone exposed to their outputs, shaping or reinforcing the beliefs of viewers around the world. Research to reduce representational harms, such as reinforcing stereotypes or denigrating or erasing groups of people, requires a deep understanding of both the content and the societal context. It hinges on how different observers perceive themselves, their communities, or how others are represented. There’s considerable debate in the field regarding which social categories should be studied with computational tools and how to do so responsibly. Our research focuses on working toward scalable solutions that are informed by sociology and social psychology, are aligned with human perception, embrace the subjective nature of the problem, and enable nuanced measurement and mitigation. One example is our research on differences in human perception and annotation of skin tone in images using the Monk Skin Tone scale.
Our tools are also used to study representation in large-scale content collections. Through our Media Understanding for Social Exploration (MUSE) project, we’ve partnered with academic researchers, nonprofit organizations, and major consumer brands to understand patterns in mainstream media and advertising content. We first published this work in 2017, with a co-authored study analyzing gender equity in Hollywood movies. Since then, we’ve increased the scale and depth of our analyses. In 2019, we released findings based on over 2.7 million YouTube advertisements. In the latest study, we examine representation across intersections of perceived gender presentation, perceived age, and skin tone in over twelve years of popular U.S. television shows. These studies provide insights for content creators and advertisers and further inform our own research.
 |
| An illustration (not actual data) of computational signals that can be analyzed at scale to reveal representational patterns in media collections. [Video Collection / Getty Images] |
Moving forward, we’re expanding the ML fairness concepts on which we focus and the domains in which they are responsibly applied. Looking beyond photorealistic images of people, we are working to develop tools that model the representation of communities and cultures in illustrations, abstract depictions of humanoid characters, and even images with no people in them at all. Finally, we need to reason about not just who is depicted, but how they are portrayed — what narrative is communicated through the surrounding image content, the accompanying text, and the broader cultural context.
Analyzing bias properties of perceptual systems
Building advanced ML systems is complex, with multiple stakeholders informing various criteria that decide product behavior. Overall quality has historically been defined and measured using summary statistics (like overall accuracy) over a test dataset as a proxy for user experience. But not all users experience products in the same way.
Perception Fairness enables practical measurement of nuanced system behavior beyond summary statistics, and makes these metrics core to the system quality that directly informs product behaviors and launch decisions. This is often much harder than it seems. Distilling complex bias issues (e.g., disparities in performance across intersectional subgroups or instances of stereotype reinforcement) to a small number of metrics without losing important nuance is extremely challenging. Another challenge is balancing the interplay between fairness metrics and other product metrics (e.g., user satisfaction, accuracy, latency), which are often phrased as conflicting despite being compatible. It is common for researchers to describe their work as optimizing an “accuracy-fairness” tradeoff when in reality widespread user satisfaction is aligned with meeting fairness and inclusion objectives.
 |
| We built and released the MIAP dataset as part of Open Images, leveraging our research on perception of socially relevant concepts and detection of biased behavior in complex systems to create a resource that furthers ML fairness research in computer vision. Original photo credits — left: Boston Public Library; middle: jen robinson; right: Garin Fons; all used with permission under the CC- BY 2.0 license. |
To these ends, our team focuses on two broad research directions. First, democratizing access to well-understood and widely-applicable fairness analysis tooling, engaging partner organizations in adopting them into product workflows, and informing leadership across the company in interpreting results. This work includes developing broad benchmarks, curating widely-useful high-quality test datasets and tooling centered around techniques such as sliced analysis and counterfactual testing — often building on the core representation signals work described earlier. Second, advancing novel approaches towards fairness analytics — including partnering with product efforts that may result in breakthrough findings or inform launch strategy.
Advancing AI responsibly
Our work does not stop with analyzing model behavior. Rather, we use this as a jumping-off point for identifying algorithmic improvements in collaboration with other researchers and engineers on product teams. Over the past year we’ve launched upgraded components that power Search and Memories features in Google Photos, leading to more consistent performance and drastically improving robustness through added layers that keep mistakes from cascading through the system. We are working on improving ranking algorithms in Google Images to diversify representation. We updated algorithms that may reinforce historical stereotypes, using additional signals responsibly, such that it’s more likely for everyone to see themselves reflected in Search results and find what they’re looking for.
This work naturally carries over to the world of generative AI, where models can create collections of images or videos seeded from image and text prompts and can answer questions about images and videos. We’re excited about the potential of these technologies to deliver new experiences to users and as tools to further our own research. To enable this, we’re collaborating across the research and responsible AI communities to develop guardrails that mitigate failure modes. We’re leveraging our tools for understanding representation to power scalable benchmarks that can be combined with human feedback, and investing in research from pre-training through deployment to steer the models to generate higher quality, more inclusive, and more controllable output. We want these models to inspire people, producing diverse outputs, translating concepts without relying on tropes or stereotypes, and providing consistent behaviors and responses across counterfactual variations of prompts.
Opportunities and ongoing work
Despite over a decade of focused work, the field of perception fairness technologies still seems like a nascent and fast-growing space, rife with opportunities for breakthrough techniques. We continue to see opportunities to contribute technical advances backed by interdisciplinary scholarship. The gap between what we can measure in images versus the underlying aspects of human identity and expression is large — closing this gap will require increasingly complex media analytics solutions. Data metrics that indicate true representation, situated in the appropriate context and heeding a diversity of viewpoints, remains an open challenge for us. Can we reach a point where we can reliably identify depictions of nuanced stereotypes, continually update them to reflect an ever-changing society, and discern situations in which they could be offensive? Algorithmic advances driven by human feedback point a promising path forward.
Recent focus on AI safety and ethics in the context of modern large model development has spurred new ways of thinking about measuring systemic biases. We are exploring multiple avenues to use these models — along with recent developments in concept-based explainability methods, causal inference methods, and cutting-edge UX research — to quantify and minimize undesired biased behaviors. We look forward to tackling the challenges ahead and developing technology that is built for everybody.
Acknowledgements
We would like to thank every member of the Perception Fairness team, and all of our collaborators.
 Since 2018, NVIDIA DLSS has leveraged AI to enable gamers and creators to increase performance and crank up their quality. Over time, this solution has evolved…
Since 2018, NVIDIA DLSS has leveraged AI to enable gamers and creators to increase performance and crank up their quality. Over time, this solution has evolved…
Since 2018, NVIDIA DLSS has leveraged AI to enable gamers and creators to increase performance and crank up their quality. Over time, this solution has evolved to include groundbreaking advancements in super resolution and frame generation.
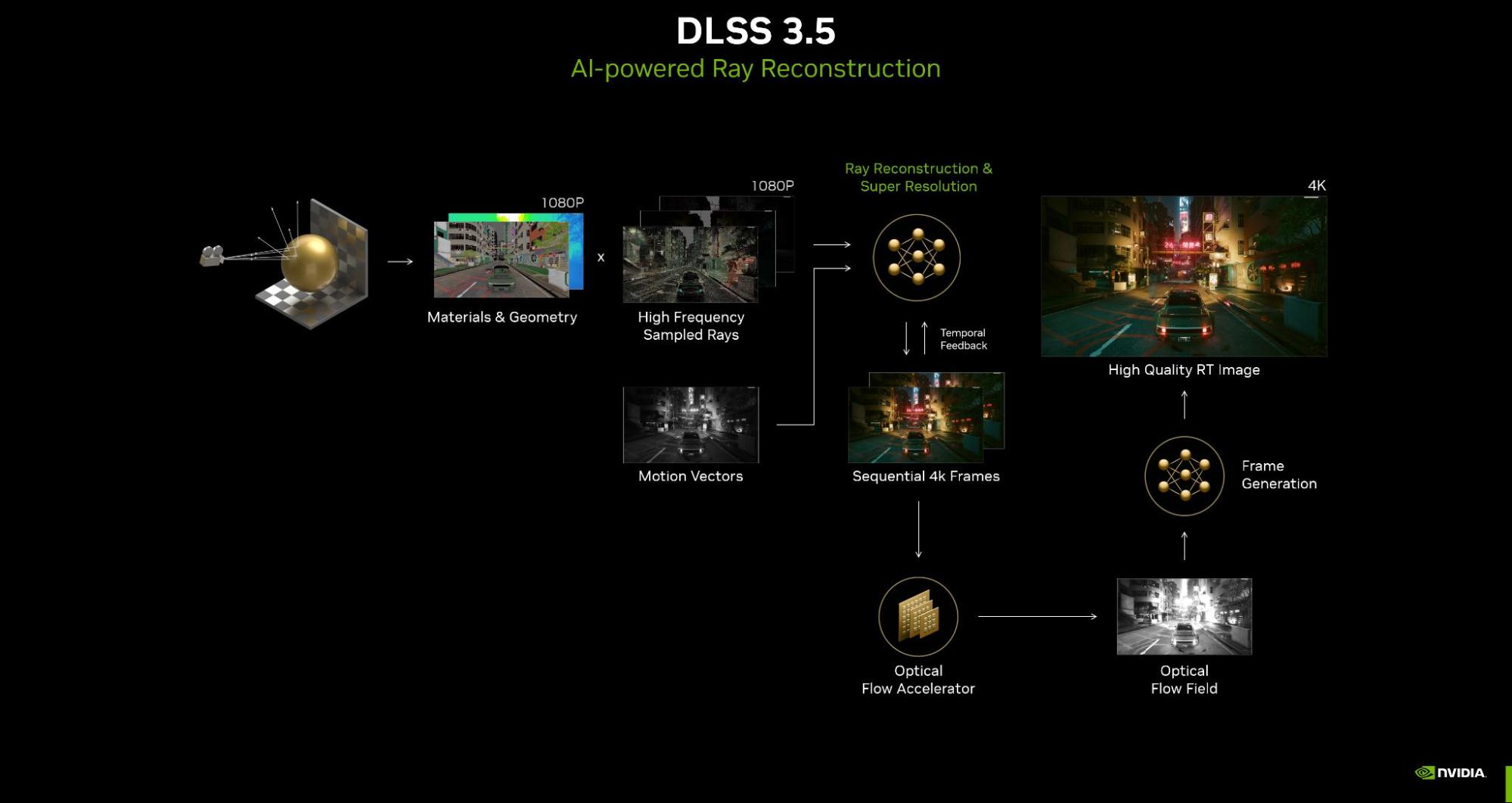
Now, the AI neural rendering technology takes the next step forward with DLSS 3.5. This update includes an important new feature called Ray Reconstruction.
Ray Reconstruction is a new neural network for all GeForce RTX GPUs that further improves the image quality of ray-traced images. Trained on 5x more data than DLSS 3, DLSS 3.5 replaces hand-tuned denoisers with an NVIDIA supercomputer-trained AI network that generates higher quality pixels in between sampled rays.
Cyberpunk 2077, Cyberpunk 2077: Phantom Liberty, Alan Wake 2, and Portal with RTX, all coming this fall, will include Ray Reconstruction.
DLSS 3.5 also adds Auto Scene Change Detection to Frame Generation. This feature aims to automatically prevent Frame Generation from producing difficult-to-create frames between a substantial scene change. It does this by analyzing the in-game camera orientation on every DLSS Frame Generation frame pair.
Auto Scene Change Detection eases integration of new DLSS 3 titles, is backwards compatible with all DLSS 3 integrations, and supports all rendering platforms. In SDK build variants, the scene change detector provides onscreen aids to indicate when a scene change is detected so the developer can pass in the reset flag.

With these new features, you can achieve even better results with ray tracing, and more effectively manage fast scene changes.
Integration into a custom engine is developer-friendly with the Streamline 2.2 SDK, an open-source cross-IHV framework. Simply identify which resources are required for the decided Streamline plug-in. In the game’s rendering pipeline, you can then trigger when to execute the plug-in.
For Unreal Engine titles, simply install the plug-in into your project and most of the work is done. For a step-by-step guide to integration, see How to Successfully Integrate NVIDIA DLSS 3.
Ray Reconstruction will soon be available to all game developers—sign up to be notified. Auto Scene Change Detection is available now in DLSS 3.5 through the Streamline 2.2 SDK and Unreal Engine plug-in.
A full-scale error-corrected quantum computer will be able to solve some problems that are impossible for classical computers, but building such a device is a huge endeavor. We are proud of the milestones that we have achieved toward a fully error-corrected quantum computer, but that large-scale computer is still some number of years away. Meanwhile, we are using our current noisy quantum processors as flexible platforms for quantum experiments.
In contrast to an error-corrected quantum computer, experiments in noisy quantum processors are currently limited to a few thousand quantum operations or gates, before noise degrades the quantum state. In 2019 we implemented a specific computational task called random circuit sampling on our quantum processor and showed for the first time that it outperformed state-of-the-art classical supercomputing.
Although they have not yet reached beyond-classical capabilities, we have also used our processors to observe novel physical phenomena, such as time crystals and Majorana edge modes, and have made new experimental discoveries, such as robust bound states of interacting photons and the noise-resilience of Majorana edge modes of Floquet evolutions.
We expect that even in this intermediate, noisy regime, we will find applications for the quantum processors in which useful quantum experiments can be performed much faster than can be calculated on classical supercomputers — we call these “computational applications” of the quantum processors. No one has yet demonstrated such a beyond-classical computational application. So as we aim to achieve this milestone, the question is: What is the best way to compare a quantum experiment run on such a quantum processor to the computational cost of a classical application?
We already know how to compare an error-corrected quantum algorithm to a classical algorithm. In that case, the field of computational complexity tells us that we can compare their respective computational costs — that is, the number of operations required to accomplish the task. But with our current experimental quantum processors, the situation is not so well defined.
In “Effective quantum volume, fidelity and computational cost of noisy quantum processing experiments”, we provide a framework for measuring the computational cost of a quantum experiment, introducing the experiment’s “effective quantum volume”, which is the number of quantum operations or gates that contribute to a measurement outcome. We apply this framework to evaluate the computational cost of three recent experiments: our random circuit sampling experiment, our experiment measuring quantities known as “out of time order correlators” (OTOCs), and a recent experiment on a Floquet evolution related to the Ising model. We are particularly excited about OTOCs because they provide a direct way to experimentally measure the effective quantum volume of a circuit (a sequence of quantum gates or operations), which is itself a computationally difficult task for a classical computer to estimate precisely. OTOCs are also important in nuclear magnetic resonance and electron spin resonance spectroscopy. Therefore, we believe that OTOC experiments are a promising candidate for a first-ever computational application of quantum processors.
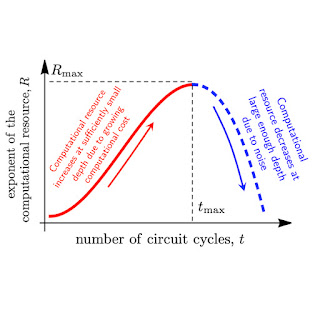
 |
| Plot of computational cost and impact of some recent quantum experiments. While some (e.g., QC-QMC 2022) have had high impact and others (e.g., RCS 2023) have had high computational cost, none have yet been both useful and hard enough to be considered a “computational application.” We hypothesize that our future OTOC experiment could be the first to pass this threshold. Other experiments plotted are referenced in the text. |
Random circuit sampling: Evaluating the computational cost of a noisy circuit
When it comes to running a quantum circuit on a noisy quantum processor, there are two competing considerations. On one hand, we aim to do something that is difficult to achieve classically. The computational cost — the number of operations required to accomplish the task on a classical computer — depends on the quantum circuit’s effective quantum volume: the larger the volume, the higher the computational cost, and the more a quantum processor can outperform a classical one.
But on the other hand, on a noisy processor, each quantum gate can introduce an error to the calculation. The more operations, the higher the error, and the lower the fidelity of the quantum circuit in measuring a quantity of interest. Under this consideration, we might prefer simpler circuits with a smaller effective volume, but these are easily simulated by classical computers. The balance of these competing considerations, which we want to maximize, is called the “computational resource”, shown below.
 |
| Graph of the tradeoff between quantum volume and noise in a quantum circuit, captured in a quantity called the “computational resource.” For a noisy quantum circuit, this will initially increase with the computational cost, but eventually, noise will overrun the circuit and cause it to decrease. |
We can see how these competing considerations play out in a simple “hello world” program for quantum processors, known as random circuit sampling (RCS), which was the first demonstration of a quantum processor outperforming a classical computer. Any error in any gate is likely to make this experiment fail. Inevitably, this is a hard experiment to achieve with significant fidelity, and thus it also serves as a benchmark of system fidelity. But it also corresponds to the highest known computational cost achievable by a quantum processor. We recently reported the most powerful RCS experiment performed to date, with a low measured experimental fidelity of 1.7×10-3, and a high theoretical computational cost of ~1023. These quantum circuits had 700 two-qubit gates. We estimate that this experiment would take ~47 years to simulate in the world’s largest supercomputer. While this checks one of the two boxes needed for a computational application — it outperforms a classical supercomputer — it is not a particularly useful application per se.
OTOCs and Floquet evolution: The effective quantum volume of a local observable
There are many open questions in quantum many-body physics that are classically intractable, so running some of these experiments on our quantum processor has great potential. We typically think of these experiments a bit differently than we do the RCS experiment. Rather than measuring the quantum state of all qubits at the end of the experiment, we are usually concerned with more specific, local physical observables. Because not every operation in the circuit necessarily impacts the observable, a local observable’s effective quantum volume might be smaller than that of the full circuit needed to run the experiment.
We can understand this by applying the concept of a light cone from relativity, which determines which events in space-time can be causally connected: some events cannot possibly influence one another because information takes time to propagate between them. We say that two such events are outside their respective light cones. In a quantum experiment, we replace the light cone with something called a “butterfly cone,” where the growth of the cone is determined by the butterfly speed — the speed with which information spreads throughout the system. (This speed is characterized by measuring OTOCs, discussed later.) The effective quantum volume of a local observable is essentially the volume of the butterfly cone, including only the quantum operations that are causally connected to the observable. So, the faster information spreads in a system, the larger the effective volume and therefore the harder it is to simulate classically.
 |
| A depiction of the effective volume Veff of the gates contributing to the local observable B. A related quantity called the effective area Aeff is represented by the cross-section of the plane and the cone. The perimeter of the base corresponds to the front of information travel that moves with the butterfly velocity vB. |
We apply this framework to a recent experiment implementing a so-called Floquet Ising model, a physical model related to the time crystal and Majorana experiments. From the data of this experiment, one can directly estimate an effective fidelity of 0.37 for the largest circuits. With the measured gate error rate of ~1%, this gives an estimated effective volume of ~100. This is much smaller than the light cone, which included two thousand gates on 127 qubits. So, the butterfly velocity of this experiment is quite small. Indeed, we argue that the effective volume covers only ~28 qubits, not 127, using numerical simulations that obtain a larger precision than the experiment. This small effective volume has also been corroborated with the OTOC technique. Although this was a deep circuit, the estimated computational cost is 5×1011, almost one trillion times less than the recent RCS experiment. Correspondingly, this experiment can be simulated in less than a second per data point on a single A100 GPU. So, while this is certainly a useful application, it does not fulfill the second requirement of a computational application: substantially outperforming a classical simulation.
Information scrambling experiments with OTOCs are a promising avenue for a computational application. OTOCs can tell us important physical information about a system, such as the butterfly velocity, which is critical for precisely measuring the effective quantum volume of a circuit. OTOC experiments with fast entangling gates offer a potential path for a first beyond-classical demonstration of a computational application with a quantum processor. Indeed, in our experiment from 2021 we achieved an effective fidelity of Feff ~ 0.06 with an experimental signal-to-noise ratio of ~1, corresponding to an effective volume of ~250 gates and a computational cost of 2×1012.
While these early OTOC experiments are not sufficiently complex to outperform classical simulations, there is a deep physical reason why OTOC experiments are good candidates for the first demonstration of a computational application. Most of the interesting quantum phenomena accessible to near-term quantum processors that are hard to simulate classically correspond to a quantum circuit exploring many, many quantum energy levels. Such evolutions are typically chaotic and standard time-order correlators (TOC) decay very quickly to a purely random average in this regime. There is no experimental signal left. This does not happen for OTOC measurements, which allows us to grow complexity at will, only limited by the error per gate. We anticipate that a reduction of the error rate by half would double the computational cost, pushing this experiment to the beyond-classical regime.
Conclusion
Using the effective quantum volume framework we have developed, we have determined the computational cost of our RCS and OTOC experiments, as well as a recent Floquet evolution experiment. While none of these meet the requirements yet for a computational application, we expect that with improved error rates, an OTOC experiment will be the first beyond-classical, useful application of a quantum processor.