 A new paradigm for data modeling and interchange is unlocking possibilities for 3D workflows and virtual worlds.
A new paradigm for data modeling and interchange is unlocking possibilities for 3D workflows and virtual worlds.
A new paradigm for data modeling and interchange is unlocking possibilities for 3D workflows and virtual worlds.
 DataBloom
DataBloomA new paradigm for data modeling and interchange is unlocking possibilities for 3D workflows and virtual worlds.
A new paradigm for data modeling and interchange is unlocking possibilities for 3D workflows and virtual worlds.
 Smart cities are the future of urban living. Yet they can present various challenges for city planners, most notably in the realm of transportation. To be…
Smart cities are the future of urban living. Yet they can present various challenges for city planners, most notably in the realm of transportation. To be…
Smart cities are the future of urban living. Yet they can present various challenges for city planners, most notably in the realm of transportation. To be successful, various aspects of the city—from environment and infrastructure to business and education—must be functionally integrated.
This can be difficult, as managing traffic flow alone is a complex problem full of challenges such as congestion, emergency response to accidents, and emissions.
To address these challenges, developers are creating AI software with field programmability and flexibility. These software-defined IoT solutions can provide scalable, ready-to-deploy products for real-time environments like traffic management, number plate recognition, smart parking, and accident detection.
Still, building effective AI models is easier said than done. Omitted values, duplicate examples, bad labels, and bad feature values are common problems with training data that can lead to inaccurate models. The results of inaccuracy can be dangerous in the case of self-driving cars, and can also lead to inefficient transportation systems or poor urban planning.
End-to-end AI engineering company SmartCow, an NVIDIA Metropolis partner, has created digital twins of traffic scenarios on NVIDIA Omniverse. These digital twins generate synthetic data sets and validate AI model performance.
The team resolved common challenges due to a lack of adequate data for building optimized AI training pipelines by generating synthetic data with NVIDIA Omniverse Replicator.
The foundation for all Omniverse Extensions is Universal Scene Description, known as OpenUSD. USD is a powerful interchange with highly extensible properties on which virtual worlds are built. Digital twins for smart cities rely on highly scalable and interoperable USD features for large, high-fidelity scenes that accurately simulate the real world.
Omniverse Replicator, a core extension of the Omniverse platform, enables developers to programmatically generate annotated synthetic data to bootstrap the training of perception of AI models. Synthetic data is particularly useful when real data sets are limited or hard to obtain.
By using a digital twin, the SmartCow team generated synthetic data that accurately represents real-world traffic scenarios and violations. These synthetic datasets help validate AI models and optimize AI training pipelines.
One of the most significant challenges for intelligent traffic management systems is license plate recognition. Developing a model that will work in a variety of countries and municipalities with different rules, regulations, and environments requires diverse and robust training data. To provide adequate and diverse training data for the model, SmartCow developed an extension in Omniverse to generate synthetic data.
Extensions in Omniverse are reusable components or tools that deliver powerful functionalities to augment pipelines and workflows. After building an extension in Omniverse Kit, developers can easily distribute it to customers to use in Omniverse USD Composer, Omniverse USD Presenter, and other apps.
SmartCow’s extension, which is called License Plate Synthetic Generator (LP-SDG), uses an environmental randomizer and a physics randomizer to make synthetic datasets more diverse and realistic.
The environmental randomizer simulates variations in lighting, weather, and other factors in the digital twin environment such as rain, snow, fog, or dust. The physics randomizer simulates scratches, dirt, dents, and discoloration that could affect the ability of the model to recognize the number on the license plate.
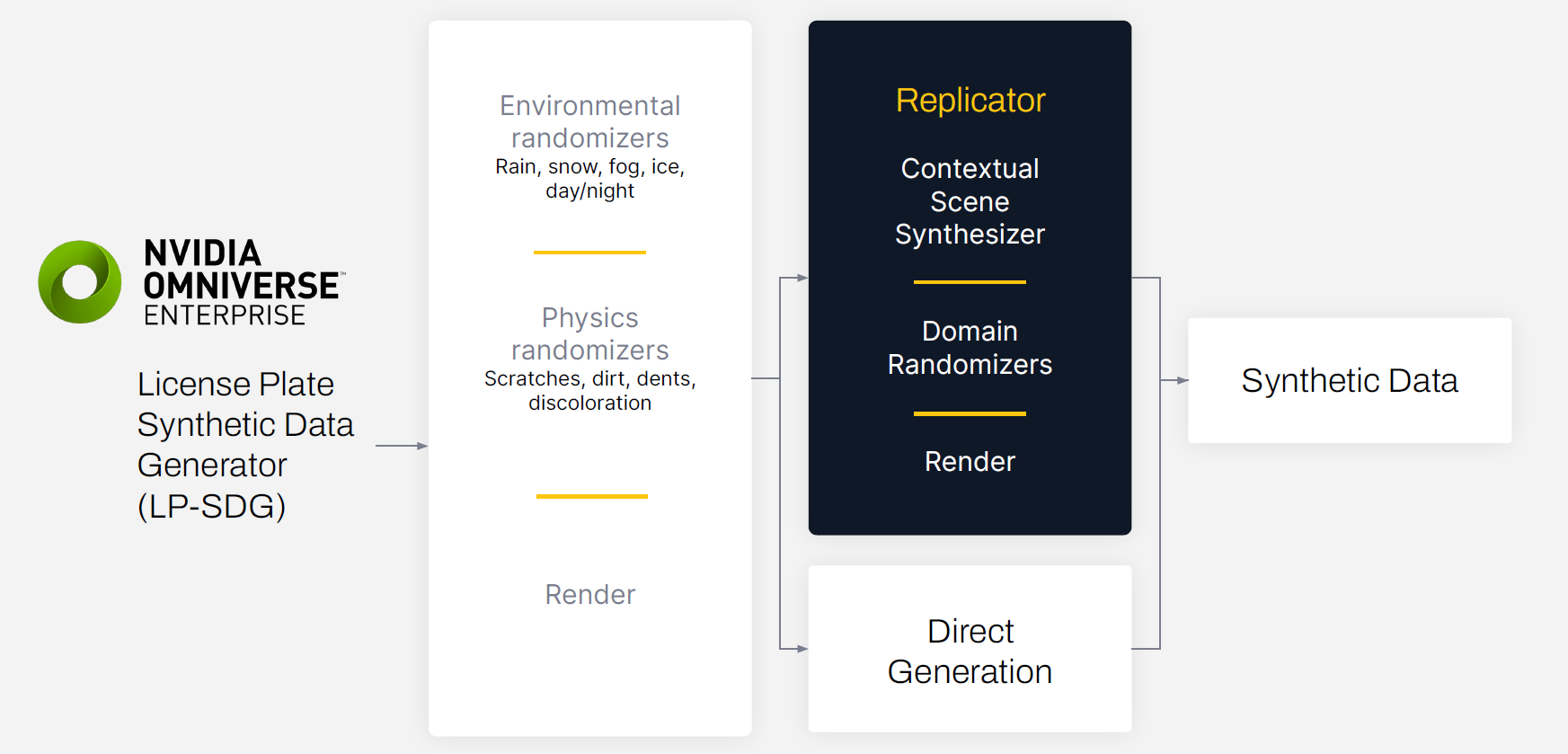
The data generation process starts with creating a 3D environment in Omniverse. The digital twin in Omniverse can be used for many simulation scenarios, including generating synthetic data. The initial 3D scene was built by SmartCow’s in-house technical artists, ensuring that the digital twin matched reality as best as possible.

Once the scene was generated, domain randomization was used to vary the light sources, textures, camera positions, and materials. This entire process was accomplished programmatically using the built-in Omniverse Replicator APIs.
The generated data was exported with bounding box annotations and additional output variables needed for training.
The initial model was trained on 3,000 real images. The goal was to understand the baseline model performance and validate aspects such as correct bounding box dimensions and light variation.
Next, the team staged experiments to compare benchmarks on synthetically generated datasets of 3,000 samples, 30,000 samples, and 300,000 samples.

“With the realism obtained through Omniverse, the model trained on synthetic data occasionally outperformed the model trained on real data,” said Natalia Mallia, software engineer at SmartCow. “Using synthetic data actually removes the bias, which is naturally present in the real image training dataset.”
To provide accurate benchmarking and comparisons, the team randomized the data across consistent parameters such as time of day, scratches, and viewing angle when training on the three sizes of synthetically generated data sets. Real-world data was not mixed with synthetic data for training, to preserve comparative accuracy. Each model was validated against a dataset of approximately 1,000 real images.
SmartCow’s team integrated the training data from the Omniverse LP-SDG extension with NVIDIA TAO, a low-code AI model training toolkit that leverages the power of transfer learning for fine-tuning models.
The team used the pretrained license plate detection model available in the NGC catalog and fine-tuned it using TAO and NVIDIA DGX A100 systems.
The AI models were then deployed onto custom edge devices using NVIDIA DeepStream SDK.
They then implemented a continuous learning loop that involved collecting drift data from edge devices, feeding the data back into Omniverse Replicator, and synthesizing retrainable datasets that were passed through automated labeling tools and fed back into TAO for training.
This closed-loop pipeline helped to create accurate and effective AI models for automatically detecting the direction of traffic in each lane and any vehicles that are stalled for an unusual amount of time.
Digital twin workflows for generating synthetic data sets and validating AI model performance are a significant step towards building more effective AI models for transportation in smart cities. Using synthetic datasets helps overcome the challenge of limited data sets, and provides accurate and effective AI models that can lead to efficient transportation systems and better urban planning.
If you’re looking to implement this solution directly, check out the SmartCow RoadMaster and SmartCow PlateReader solutions.
If you’re a developer interested in building your own synthetic data generation solution, download NVIDIA Omniverse for free and try the Replicator API in Omniverse Code. Join the conversation in the NVIDIA Developer Forums.
Join NVIDIA at SIGGRAPH 2023 to learn about the latest breakthroughs in graphics, OpenUSD, and AI. Save the date for the session, Accelerating Self-Driving Car and Robotics Development with Universal Scene Description.
Get started with NVIDIA Omniverse by downloading the standard license free, or learn how Omniverse Enterprise can connect your team. If you’re a developer, get started with Omniverse resources. Stay up to date on the platform by subscribing to the newsletter, Twitch, and YouTube channels.
Pixar, Adobe, Apple, Autodesk, and NVIDIA, together with the Joint Development Foundation (JDF), an affiliate of the Linux Foundation, today announced the Alliance for OpenUSD (AOUSD) to promote the standardization, development, evolution, and growth of Pixar’s Universal Scene Description technology.
NVIDIA joined Pixar, Adobe, Apple and Autodesk today to found the Alliance for OpenUSD, a major leap toward unlocking the next era of 3D graphics, design and simulation. The group will standardize and extend OpenUSD, the open-source Universal Scene Description framework that’s the foundation of interoperable 3D applications and projects ranging from visual effects to Read article >
Principal NVIDIA artist and 3D expert Michael Johnson creates highly detailed art that’s both technically impressive and emotionally resonant.
 Synchronization in graphics programming refers to the coordination and control of concurrent operations to ensure the correct and predictable execution of…
Synchronization in graphics programming refers to the coordination and control of concurrent operations to ensure the correct and predictable execution of…
Synchronization in graphics programming refers to the coordination and control of concurrent operations to ensure the correct and predictable execution of rendering tasks. Improper synchronization across the CPU and GPU can lead to slow performance, race conditions, and visual artifacts.
 NVIDIA HPC SDK version 23.7 is now available and provides minor updates and enhancements.
NVIDIA HPC SDK version 23.7 is now available and provides minor updates and enhancements.
NVIDIA HPC SDK version 23.7 is now available and provides minor updates and enhancements.
 Precisely reproducing VR experiences is critical to many workflows, yet it is extremely challenging. But VR testing is critical for many teams, especially when…
Precisely reproducing VR experiences is critical to many workflows, yet it is extremely challenging. But VR testing is critical for many teams, especially when…
Precisely reproducing VR experiences is critical to many workflows, yet it is extremely challenging. But VR testing is critical for many teams, especially when they’re looking to troubleshoot a VR experience, or want to gain more insights into what customers see when they put on the headset.
Chaos Enscape is using NVIDIA VR Capture and Replay (VCR) to streamline their VR build tests by playing back recorded VR sessions using NVIDIA VCR to confirm that new Enscape builds perform as expected.
Enscape is a real-time visualization tool used predominantly in the AECO space that has VR capabilities. The team at Chaos is responsible for developing the VR functionalities of the app. Before using VCR, a large part of Chaos Enscape’s VR menu and movement testing relied on manual testing: a hands-on process that was time-consuming and labor-intensive.
To test VR scenes, a user must navigate a VR scene and press the VR controller buttons in a sequence. For every test, the user must do the same VR headset motions and press the same button sequences to get consistent results. But, it’s impossible to always repeat every movement with identical position and timing.
NVIDIA VCR helps address these challenges by providing an easy-to-use solution for VR recording, editing, analysis, and replay. This enables the engineering team to streamline the VR testing process.
“With NVIDIA VCR, our testing has improved because its capture and replay capabilities enable us to run automated tests simulating complex VR interactions as part of our continuous integration,” said Josua Meier, rendering engineer at Chaos.
Previously, testing VR features and software builds were only performed manually and periodically for Chaos Enscape. This meant that it often took longer to find issues within their VR.
Now, in addition to manual testing, the Chaos Enscape team uses NVIDIA VCR to run automated tests every day to ensure that their VR implementation works as expected.
Here’s how NVIDIA VCR works:
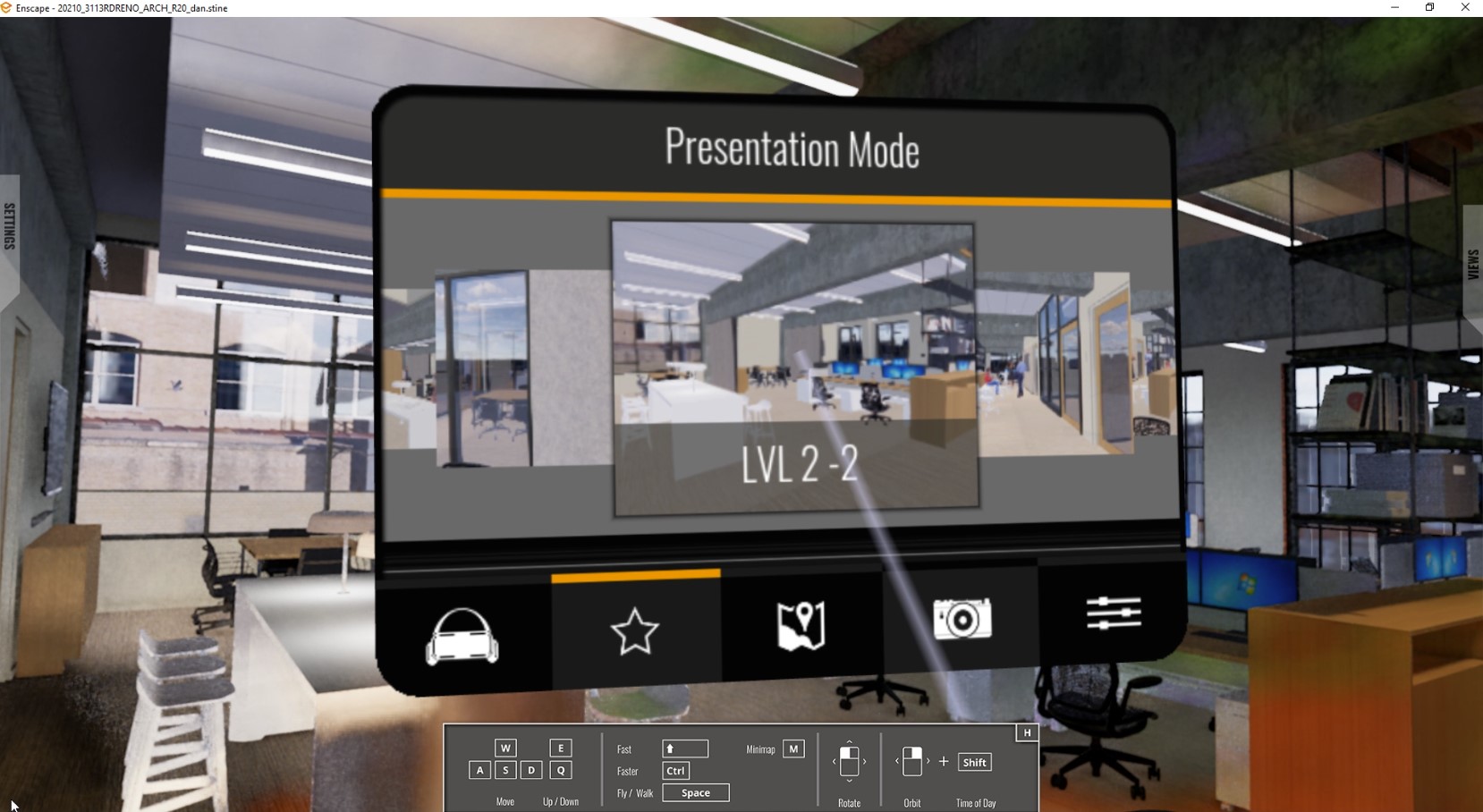
NVIDIA VCR playback is precise and enables engineers at Chaos to test controller inputs and teleport through a scene using automated playback scripts.
“NVIDIA VCR helps us find issues in our VR implementation faster, potentially saving us days in the test cycle before a release,” said Meier. “It’s a great solution for running stable, reproducible VR tests, which is also easy to integrate into existing systems.”
Based on previous testing across multiple ISVs, developers have experienced reduced times for VR testing, an average of 2.5 hours per week.
In addition to streamlining VR application testing, you can use NVIDIA VCR as a developer tool for filtering NVIDIA VCR-recorded sessions. Using the included C++ API, you can create scripts for editing, re-timing, and filtering to smooth out user inputs.
NVIDIA VCR can also help marketing and analytics teams, as it enables VR sessions to be replayed to objectively review where VR users look to target optimal product placement in VR retail experiences.
For more information, see the following resources:
You can see more of the latest NVIDIA XR technologies at SIGGRAPH, which runs August 6–10.
From smart factories to next-generation railway systems, developers and enterprises across the world are racing to fuel industrial digitalization opportunities at every scale. Key to this is the open-source Universal Scene Description (USD) framework, or OpenUSD, along with metaverse applications powered by AI. OpenUSD, originally developed by Pixar for large-scale feature film pipelines for animation Read article >
 Autonomous vehicle (AV) development requires massive amounts of sensor data for perception development. Developers typically get this data from two…
Autonomous vehicle (AV) development requires massive amounts of sensor data for perception development. Developers typically get this data from two…
Autonomous vehicle (AV) development requires massive amounts of sensor data for perception development.
Developers typically get this data from two sources—replay streams of real-world drives or simulation. However, real-world datasets offer limited flexibility, as the data is fixed to only the objects, events, and view angles captured by the physical sensors. It is also difficult to simulate the detail and imperfection of real-world conditions—such as sensor noise or occlusions—at scale.
Neural fields have gained significant traction in recent years. These AI tools capture real-world content and simulate it from novel viewpoints with high levels of realism, achieving the fidelity and diversity required for AV simulation.
At NVIDIA GTC 2022, we showed how we use neural reconstruction to build a 3D scene from recorded camera sensor data in simulation, which can then be rendered from novel views. A paper we published for ICCV 2023—which runs Oct. 2 to Oct.6—details how we applied a similar approach to address these challenges in synthesizing lidar data.

The method, called neural lidar fields, optimizes a neural radiance field (NeRF)-like representation from lidar measurements that enables synthesizing realistic lidar scans from entirely new viewpoints. It combines neural rendering with a physically based lidar model to accurately reproduce sensor behaviors—such as beam divergence, secondary returns, and ray dropping.
With neural lidar fields, we can achieve improved realism of novel views, narrowing the domain gap with real lidar data recordings. In doing so, we can improve the scalability of lidar sensor simulation and accelerate AV development.
By applying neural rendering techniques such as neural lidar fields in NVIDIA Omniverse, AV developers can bypass the time– and cost-intensive process of rebuilding real-world scenes by hand. They can bring physical sensors into a scalable and repeatable simulation.
While replaying recorded data is a key component of testing and validation, it is critical to also simulate new scenarios for the AV system to experience.
These scenarios make it possible to test situations where the vehicle deviates from the original trajectory. It will view the world from novel views. This benefit also extends to testing a sensor suite on a different vehicle type, where the rig may be positioned differently (for example, switching from a sedan to an SUV).
With the ability to modify sensor properties such as beam divergence and ray pattern, we can also use a different lidar type in simulation than the sensor that originally recorded the data.
However, previous explicit approaches to simulating novel views have proven cumbersome and often inaccurate. First, surface representation—such as surfels or a triangular mesh—must be extracted from scanned lidar point clouds. Then, lidar measurements are simulated from a novel viewpoint by casting rays and intersecting them with the surface model.
These methods—known as explicit reconstruction—introduce noticeable errors in the rendering as well as assuming a perfect lidar model with no divergence of beams.
Rather than rely on an error-prone reconstruction pipeline, the neural lidar fields method takes a NeRF-style approach. It is based on neural scene representation and sensor modeling, which is directly optimized to render sensor measurements. This results in a more realistic output.
Specifically, we used an improved, lidar-specific volume rendering procedure, which creates range and intensity measurements from the 3D scene. Then, we added beam divergence for improved realism. We took into account that lidar works as an active sensor—rather than a passive one like a camera. This, along with characteristics such as beam divergence, enabled us to reproduce sensor properties, including dropped rays and multiple returns.
To test the accuracy of the neural lidar fields, we ran the scenes in a lidar simulator, comparing results with a variety of viewpoints taken at different distances from the original scan.
These scans were then compared with real data from the Waymo Open dataset, using metrics such as real-world intensities, ray drop, and secondary returns to evaluate fidelity. We also used real data to validate the accuracy of the neural lidar fields’ view synthesis in challenging scenes.
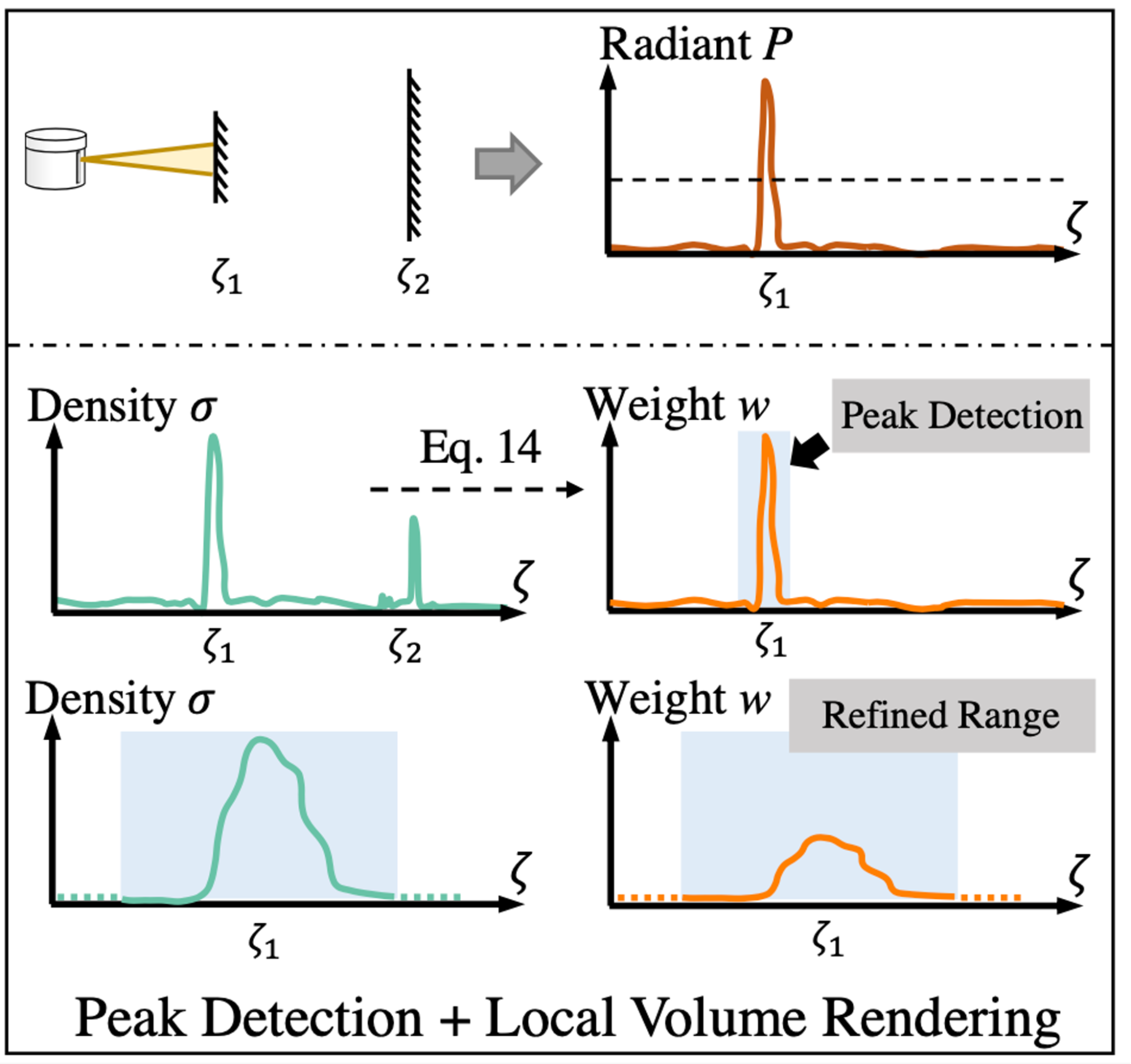
In Figure 2, the neural lidar fields accurately reproduce the waveform properties. The top row shows that the first surface fully scatters the lidar energy. The other rows shows that neural lidar fields estimate range through peak detection on the computed weights followed by volume rendering-based range refinement.
Using these evaluation methods, we compared neural lidar field-synthesized lidar views with traditional reconstruction processes.
By accounting for real-world lidar characteristics, neural lidar field views reduced range errors and improved performance compared with explicit reconstruction. We also found the implicit method synthesized challenging scenes with high accuracy.
After we established performance, we then validated the neural lidar field-generated scans using two low-level perception tasks: point cloud registration and semantic segmentation.
We applied the same model to both real-world lidar scans and various synthesized scans to evaluate how well the scans maintained accuracy. We found that neural lidar fields outperformed the baseline methods on datasets with complex geometry and high noise levels.

For semantic segmentation, we applied the same pretrained model to both real and synthetic lidar scans. Neural lidar fields achieved the highest recall for vehicles, which are especially difficult to render due to sensor noise such as dual returns and ray drops.
While neural lidar fields are still an active research method, it is a critical tool for scalable AV simulation. Next, we plan to focus on generalizing the networks across scenes and handling dynamic environments. Eventually, developers on Omniverse and the NVIDIA DRIVE Sim AV simulator will be able to tap into these AI-powered approaches for accelerated and physically based simulation.
For more information about neural lidar fields and our development and evaluation methods, see the Neural LiDAR Fields for Novel View Synthesis paper.
We would like to thank our collaborators at ETH Zurich, Shengyu Huang and Konrad Schindler, as well as Zan Gojcic, Zian Wang, Francis Williams, Yoni Kasten, Sanja Fidler, and Or Litany from the NVIDIA Research team.