
The ability to classify images into categories has been transformed by deep learning. It has also been significantly accelerated by transfer learning, whereby models are first pre-trained on large datasets, like ImageNet, to learn visual representations that are then transferred via fine-tuning to a new task with less data (e.g., classifying animals). Previous works such as BiT and ViT employed these methods to achieve state-of-the-art performance on a wide range of classification tasks, such as the VTAB benchmark.
However, fine-tuning has some downsides: though pre-training is done only once, fine-tuning is necessary on every new dataset for which task-specific data is needed. Multimodal contrastive learning is an alternative, recently popularized paradigm (e.g., CLIP, ALIGN) that overcomes these issues by instead learning how to match free-form text with images. These models can then solve new tasks by reformulating them as image-text matching problems, without extra data (referred to as “zero-shot” learning). Contrastive learning is flexible and easy to adapt to new tasks, but has its own limitations, namely the need for a lot of paired image-text data and weaker performance than transfer learning approaches.
With those limitations in mind, we propose “LiT: Zero-Shot Transfer with Locked-image Text Tuning”, to appear at CVPR 2022. LiT models learn to match text to an already pre-trained image encoder. This simple yet effective setup provides the best of both worlds: strong image representations from pre-training, plus flexible zero-shot transfer to new tasks via contrastive learning. LiT achieves state-of-the-art zero-shot classification accuracy, significantly closing the gap between the two styles of learning. We think the best way to understand is to try it yourself, so we’ve included a demo of LiT models at the end of this post.
 |
| Fine-tuning (left) requires task-specific data and training to adapt a pre-trained model to a new task. An LiT model (right) can be used with any task, without further data or adaptation. |
Contrastive Learning on Image-Text Data
Contrastive learning models learn representations from “positive” and “negative” examples, such that representations for “positive” examples are similar to each other but different from “negative” examples.
Multimodal contrastive learning applies this to pairs of images and associated texts. An image encoder computes representations from images, and a text encoder does the same for texts. Each image representation is encouraged to be close to the representation of its associated text (“positive”), but distinct from the representation of other texts (“negatives”) in the data, and vice versa. This has typically been done with randomly initialized models (“from scratch”), meaning the encoders have to simultaneously learn representations and how to match them.
 |
| Multimodal contrastive learning trains models to produce similar representations for closely matched images and texts. |
This training can be done on noisy, loosely aligned pairs of image and text, which naturally occur on the web. This circumvents the need for manual labeling, and makes data scaling easy. Furthermore, the model learns much richer visual concepts — it’s not constrained to what’s defined in the classification label space. Instead of classifying an image as “coffee”, it can understand whether it’s “a small espresso in a white mug” or “a large latte in a red flask”.
Once trained, a model that aligns image and text can be used in many ways. For zero-shot classification, we compare image representations to text representations of the class names. For example, a “wombat vs jaguar” classifier can be built by computing the representations of the texts “jaguar” and “wombat”, and classifying an image as a jaguar if its representation better matches the former. This approach scales to thousands of classes and makes it very easy to solve classification tasks without the extra data necessary for fine-tuning. Another application of contrastive models is image search (a.k.a. image-text retrieval), by finding the image whose representation best matches that of a given text, or vice versa.
The Best of Both Worlds with Locked-image Tuning
As mentioned earlier, transfer learning achieves state-of-the-art accuracy, but requires per-task labels, datasets, and training. On the other hand, contrastive models are flexible, scalable, and easily adaptable to new tasks, but fall short in performance. To compare, at the time of writing, the state of the art on ImageNet classification using transfer learning is 90.94%, but the best contrastive zero-shot models achieve 76.4%.
LiT tuning bridges this gap: we contrastively train a text model to compute representations well aligned with the powerful ones available from a pre-trained image encoder. Importantly, for this to work well, the image encoder should be “locked“, that is: it should not be updated during training. This may be unintuitive since one usually expects the additional information from further training to increase performance, but we find that locking the image encoder consistently leads to better results.
 |
| LiT-tuning contrastively trains a text encoder to match a pre-trained image encoder. The text encoder learns to compute representations that align to those from the image encoder. |
This can be considered an alternative to the classic fine-tuning stage, where the image encoder is separately adapted to every new classification task; instead we have one stage of LiT-tuning, after which the model can classify any data. LiT-tuned models achieve 84.5% zero-shot accuracy on ImageNet classification, showing significant improvements over previous methods that train models from scratch, and halving the performance gap between fine-tuning and contrastive learning.
 |
| Left: LiT-tuning significantly closes the gap between the best contrastive models and the best models fine-tuned with labels. Right: Using a pre-trained image encoder is always helpful, but locking it is surprisingly a key part of the recipe to success; unlocked image models (dashed) yield significantly worse performance. |
An impressive benefit of contrastive models is increased robustness — they retain high accuracy on datasets that typically fool fine-tuned models, such as ObjectNet and ImageNet-C. Similarly, LiT-tuned models have high performance across various challenging versions of ImageNet, for example achieving a state-of-the-art 81.1% accuracy on ObjectNet.
LiT-tuning has other advantages. While prior contrastive works require large amounts of data and train for a very long time, the LiT approach is much less data hungry. LiT models trained on 24M publicly available image-text pairs rival the zero-shot classification performance of prior models trained on 400M image-text pairs of private data. The locked image encoder also leads to faster training with a smaller memory footprint. On larger datasets, image representations can be pre-computed; not running the image model during training further improves efficiency and also unlocks much larger batch sizes, which increases the number of “negatives” the model sees and is key to high-performance contrastive learning. The method works well with varied forms of image pre-training (e.g., including self-supervised learning), and with many publicly available image models. We hope that these benefits make LiT a great testbed for researchers.
Conclusion
We present Locked-image Tuning (LiT), which contrastively trains a text encoder to match image representations from a powerful pre-trained image encoder. This simple method is data and compute efficient, and substantially improves zero-shot classification performance compared to existing contrastive learning approaches.
Want to try it yourself?
.gif) |
| A preview of the demo: use it to match free-form text descriptions to images and build your own zero-shot classifier! |
We have prepared a small interactive demo to try some LiT-tuned models. We also provide a Colab with more advanced use cases and larger models, which are a great way to get started.
Acknowledgments
We would like to thank Xiaohua Zhai, Xiao Wang, Daniel Keysers, Alexander Kolesnikov, and Lucas Beyer who have co-authored the LiT paper and been involved in all aspects of its development, as well as the Brain team in Zürich. We also would like to thank Tom Small for creating the animations used in this blogpost.

 Cities now have access to real-time, multimodal traffic data that improves road safety and reduces traffic congestion.
Cities now have access to real-time, multimodal traffic data that improves road safety and reduces traffic congestion.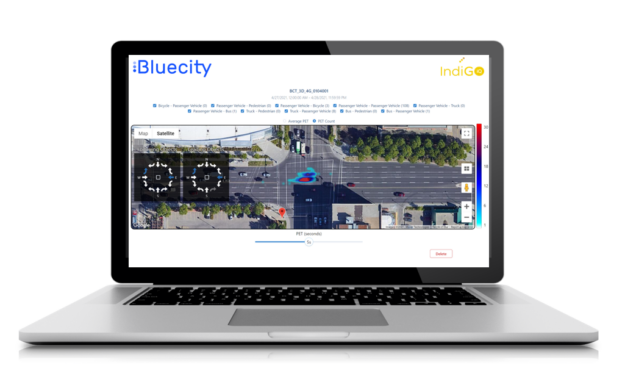


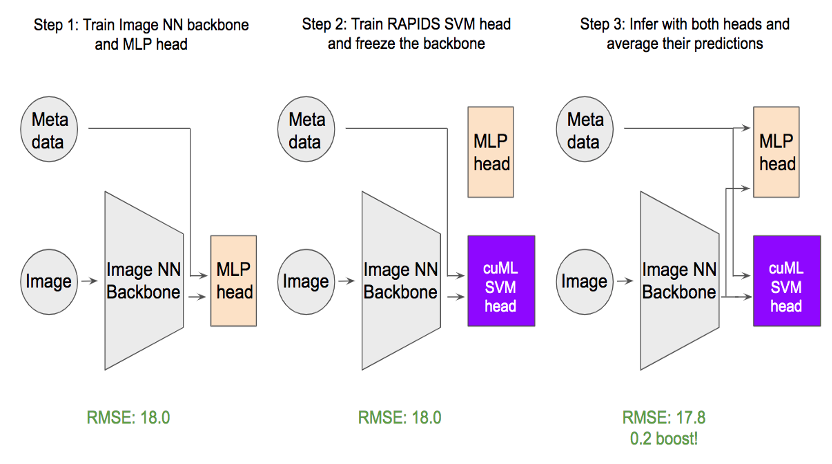
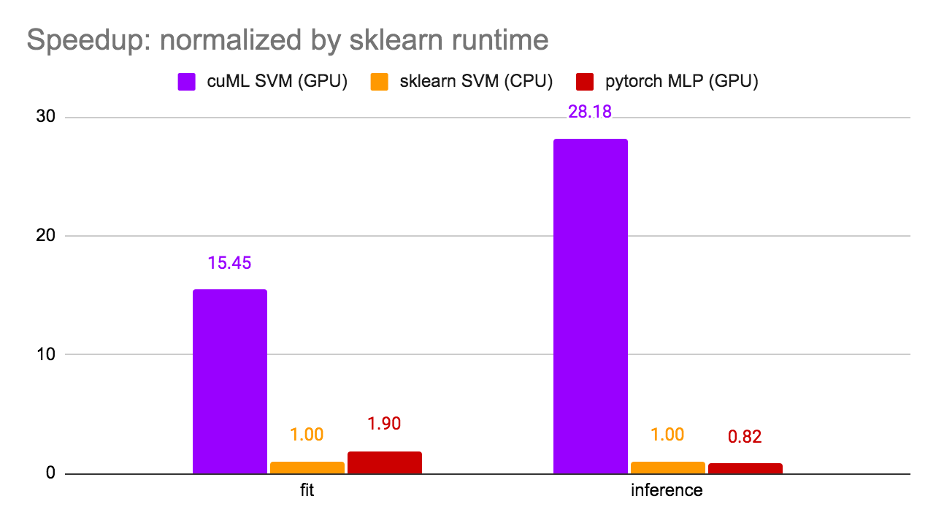
 Find out how RAPIDS and the cuML support vector machine can achieve faster training time and maximum accuracy when fine-tuning transformers.
Find out how RAPIDS and the cuML support vector machine can achieve faster training time and maximum accuracy when fine-tuning transformers.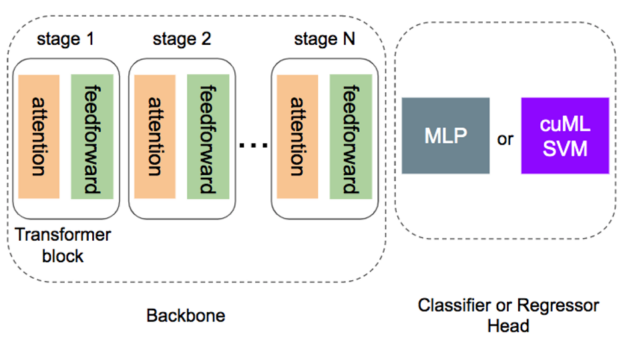












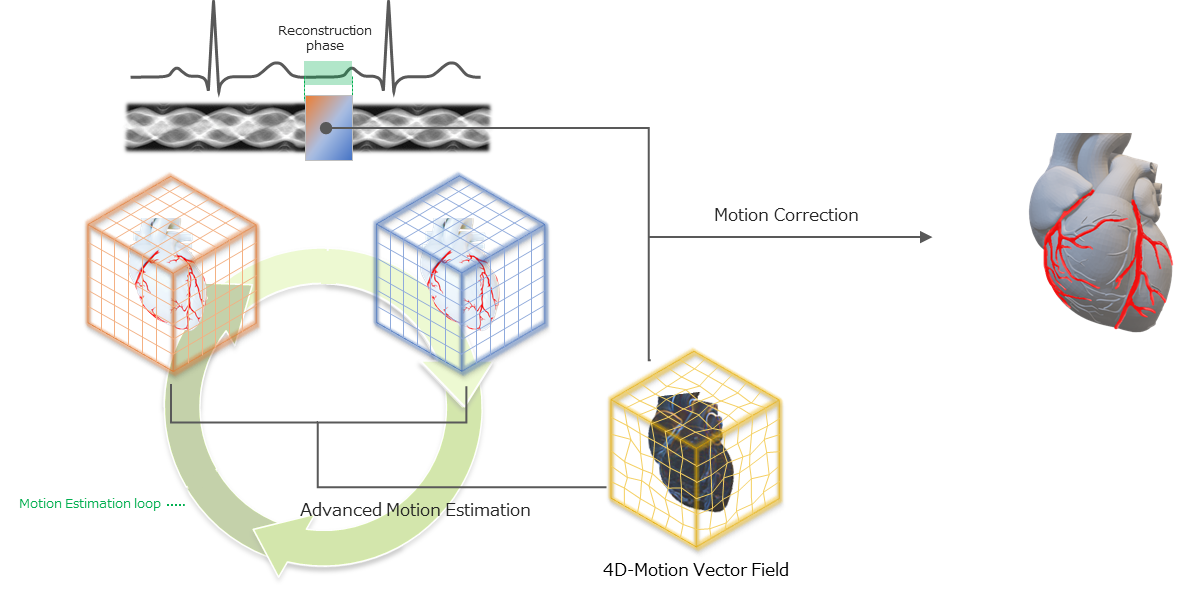
 Using NVIDIA GPUs, Fujifilm Healthcare developed Cardio StillShot to capture cardiac imaging at any heart rate, with 6x better temporal resolution of cardiac CT images.
Using NVIDIA GPUs, Fujifilm Healthcare developed Cardio StillShot to capture cardiac imaging at any heart rate, with 6x better temporal resolution of cardiac CT images.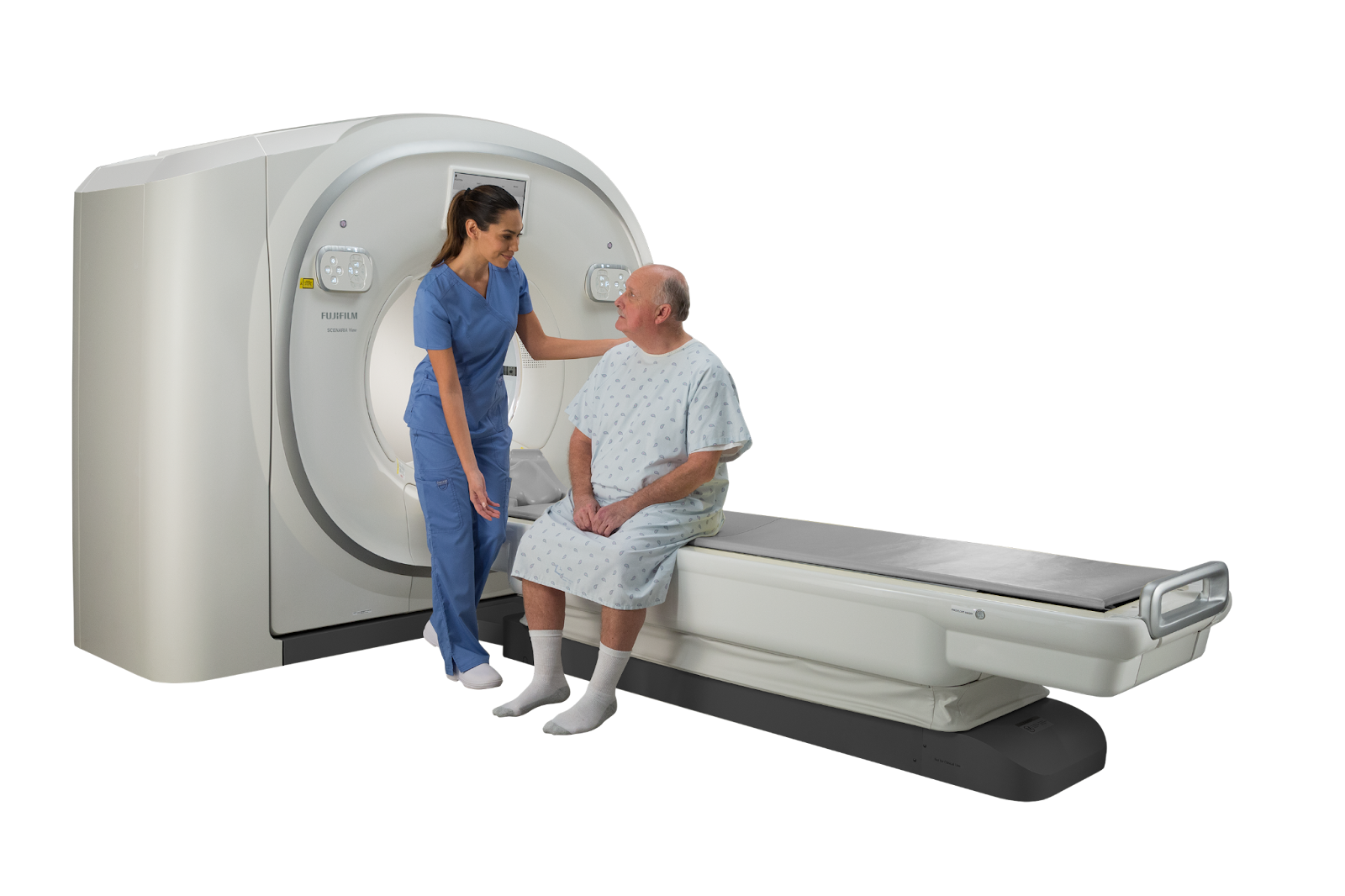
{kind=link}