![[TFLite] Mozilla + Coqui Speech Technology Hackathon](https://external-preview.redd.it/0IhuCddswwQwHgjUJG1-YaPDo2h7-CotPqTohC9E64U.jpg?width=108&crop=smart&auto=webp&s=c7b69b157af7fe7767436bf82accc36b8c09ac30 "[TFLite] Mozilla + Coqui Speech Technology Hackathon")
|
submitted by /u/josh-r-meyer [visit reddit] [comments] |

 DataBloom
DataBloom
|
|
submitted by /u/josh-r-meyer [visit reddit] [comments] |
I have a problem, which I could not solve yet.
I need to create a conda environment with tensorflow=2.6.0, python=3.8 and cudatoolkit>=11 (using ampere GPU)
I cannot use conda default channel. Until now I tried using conda-forge and nvidia channel.
I have not succeeded in creating a conda environment with the above requirements. Anyone got a hint?
The machine got centos with Nvidia driver 495 and cuda 11.5
submitted by /u/alex_bababu
[visit reddit] [comments]
I am using Dataspell and have a jupyter notebook set up inside dataspell, I’ve done simple imports such as
import TensorFlow as tf
import tensorflow_hub as hub
import tensorflow_text as text
but its has been like 2 hours and it still hasn’t finished loading, I’ve made sure that i already installed the packages using terminal pip install TensorFlow etc
submitted by /u/ratmanreturns265
[visit reddit] [comments]
I am trying to build a sorting system to sort parts by taking a picture of the part, identifying the part, and then telling a robot to move the part into the appropriate bucket. 99% of the parts are known and can be trained for. 1% of the parts are not known. I would like the known parts to be put in their buckets, and all of the unknown parts to be rejected into a single bucket called unknown.
I naively thought I would be able to do this with Resnet50 by looking at the weights returned in the prediction array. I thought the predictor would have uncertainty when presented with an unknown part. However, I have discovered that Resnet50 (and perhaps all image classifiers) will force any image to be in one of it’s trained for buckets with a high level of confidence.
Because only 1% of the parts are unknown, I can’t realistically gather enough of them to train for. Furthermore, I don’t know when and where they will show up.
Does anyone know of a technique I could use to sort images of known parts into their buckets, and reject unknown parts?
submitted by /u/marlon1492
[visit reddit] [comments]
 The greater performance delivered by current-generation NVIDIA GPU-accelerated instances more than outweighs the per-hour pricing differences of prior-generation GPUs.
The greater performance delivered by current-generation NVIDIA GPU-accelerated instances more than outweighs the per-hour pricing differences of prior-generation GPUs.
AI is transforming every industry, enabling powerful new applications and use cases that simply weren’t possible with traditional software. As AI continues to proliferate, and with the size and complexity of AI models on the rise, significant advances in AI compute performance are required to keep up.
That’s where the NVIDIA platform comes in.
With a full-stack approach spanning chips, systems, software, and even the entire data center, NVIDIA delivers both the highest performance and the greatest versatility for all AI workloads, including AI training. NVIDIA demonstrated this in the MLPerf Training v1.1, the latest edition of an industry-standard, peer-reviewed benchmark suite that measures ML training performance across a wide range of networks. Systems powered by the NVIDIA A100 Tensor Core GPU, including the Azure NDm A100 v4 cloud instance, delivered chart-topping results, set new records, and were the only ones to complete all eight MLPerf Training tests.
All major cloud service providers offer NVIDIA GPU-accelerated instances powered by the A100, making the public cloud a great place to tap into the performance and capabilities of the NVIDIA platform. In this post, I show how a strategy of selecting current-generation instances based on the A100 not only delivers the fastest time to train AI models in the cloud but is also the most cost-effective.
The NVIDIA A100 is based on the Ampere architecture, which incorporates a host of innovations that speed up AI training compared to the prior-generation NVIDIA V100, such as third-generation Tensor Cores, a new generation of NVLink, and much greater memory bandwidth. These enhancements deliver a giant performance leap, enabling the reduction in the time to train a wide range of AI networks.
In this post, I use ResNet-50 to represent image classification, BERT Large for natural language processing, and DLRM for recommender systems.

GPU Server: Dual socket AMD EPYC 7742 @ 2.25GHz w/ 8x NVIDIA A100 SXM4-40GB and Dual socket Intel Xeon E5-2698 v4 @ 2.2GHz w/ 8x NVIDIA V100 SXM2-32GB. Frameworks: TensorFlow for ResNet-50 v1.5, PyTorch for BERT-Large and DLRM; Precision: Mixed+XLA for ResNet-50 v1.5, Mixed for BERT-Large and DLRM. NVIDIA Driver: 465.19.01; Dataset: ImageNet2012 for ResNet-50 v1.5, SQuaD v1.1 for BERT Large Fine Tuning, Criteo Terabyte Dataset for DLRM, Batch sizes for ResNet-50: A100, V100 = 256; Batch sizes for BERT Large: A100 = 32, V100 = 10; Batch sizes for DLRM: A100, V100 = 65536.
Faster training times speed time to insight, maximizing the productivity of an organization’s data science teams and getting the trained network deployed sooner. There’s also another important benefit: lower costs!
Cloud instances are commonly priced per unit of time, with hourly pricing typical for on-demand usage. The cost to train a model is the product of both hourly instance pricing and the time required to train a model.
Although it can be tempting to select the instances with the lowest hourly price, this might not lead to the lowest cost to train. An instance might be slightly cheaper on a per-hour basis but take significantly longer to train a model. The total cost to train is higher than it would be with the higher-priced instance that gets the job done more quickly. In addition, there’s the time lost waiting for the slower instance to complete the training run.
In the performance numbers shown earlier, the NVIDIA A100 can train models much more quickly than NVIDIA V100. That’s almost 3x as fast in the case of BERT Large Fine Tuning. At the same time, A100-based instances from major cloud providers are often only priced at modest premiums to their prior-generation, V100-based counterparts.
In this post, I discuss how using A100-based cloud instances enables you to save time and money while training AI models, compared to V100-based cloud instances.
Given the immense computational demands of AI training, it is common to train models using multiple GPUs working in concert to reduce training times significantly.
The NVIDIA platform has been designed to deliver industry-leading per-accelerator performance and achieve the best performance and highest ROI at scale, thanks to technologies like NVLink and NVSwitch. That’s why, in this post, I estimate the cost savings that instances with eight NVIDIA A100 GPUs can deliver compared to instances with eight NVIDIA V100 GPUs.
For this analysis, I estimate the relative costs to train ResNet-50, fine tune BERT Large, and train DLRM on V100- and A100-based instances from three major cloud service providers: Amazon Web Services, Google Cloud Platform, and Microsoft Azure.
| CSP | Instance | GPU Configuration |
| Amazon Web Services | p4d.24xlarge | 8x NVIDIA A100 40GB |
| p3dn.24xlarge | 8x NVIDIA V100 32GB | |
| p3.16xlarge | 8x NVIDIA V100 16GB | |
| Google Cloud Platform | a2-highgpu-8g | 8x NVIDIA A100 40GB |
| n1-highmem-96 | 8x NVIDIA V100 16GB | |
| Microsoft Azure | Standard_ND96asr_v4 | 8x NVIDIA A100 40GB |
| ND40rs v2 | 8x NVIDIA V100 32GB |
To estimate the training performance of the cloud instances, I used measured time to train data on NVIDIA DGX systems with GPU configurations that correspond to those in the instances. As a result of the deep engineering collaboration with these cloud partners, the performance of NVIDIA-powered cloud instances should be similar to the performance achievable on the DGX systems.
Then, with the measured time-to-train data, I used on-demand, per-hour instance pricing to estimate the cost to train ResNet-50, fine tune BERT Large, and train DLRM.
The following charts all tell a similar story: no matter which cloud service provider you choose, selecting instances based on the latest NVIDIA A100 GPUs can translate into significant cost savings when training a range of AI models. This is even though, on a per-hour basis, instances based on the NVIDIA A100 are more expensive than instances using prior-generation V100 GPUs.
Amazon Web Services:
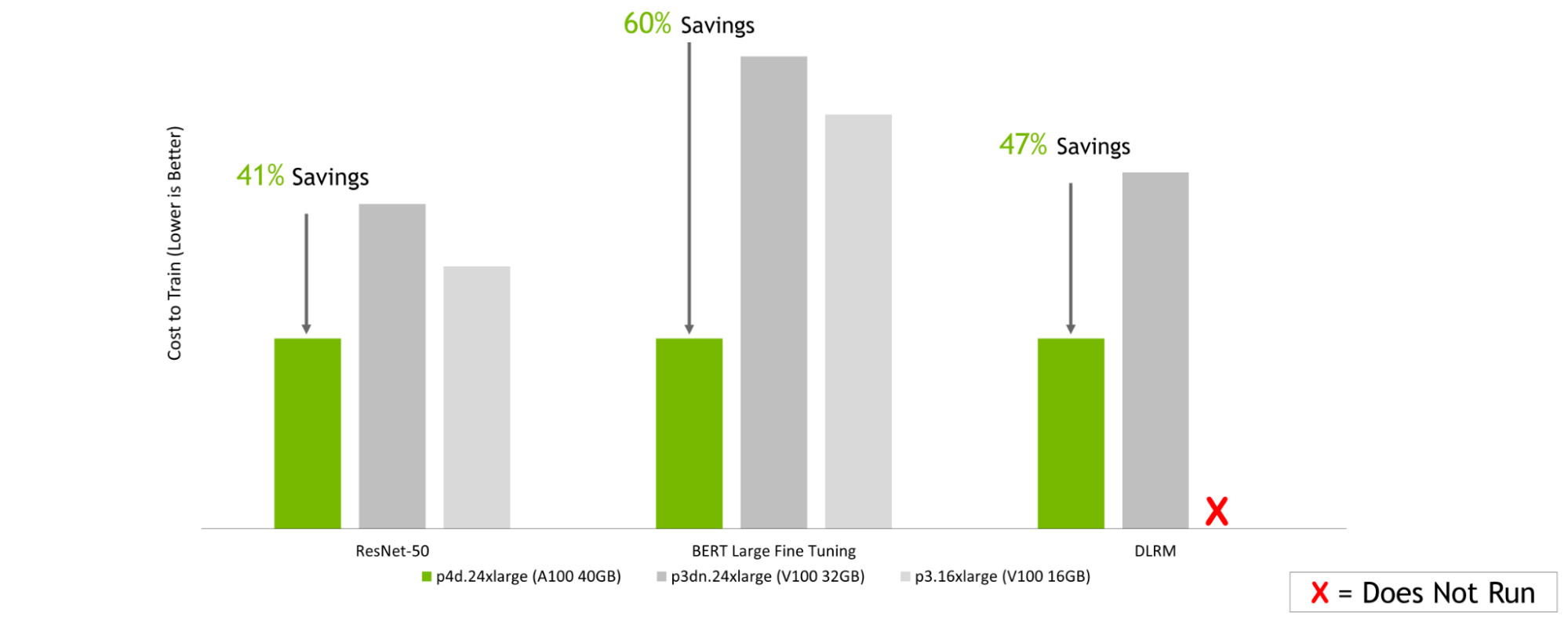
GPU Server: Dual socket AMD EPYC 7742 @ 2.25GHz w/ 8x NVIDIA A100 SXM4-40GB, Dual socket Intel Xeon E5-2698 v4 @ 2.2GHz w/ 8x NVIDIA V100 SXM2-32GB, and Dual socket Intel Xeon E5-2698 v4 @ 2.2GHz w/ 8x NVIDIA V100 SXM2-16GB. Frameworks: TensorFlow for ResNet-50 v1.5, PyTorch for BERT-Large and DLRM; Precision: Mixed+XLA for ResNet-50 v1.5, Mixed for BERT-Large and DLRM. NVIDIA Driver: 465.19.01; Dataset: Imagenet2012 for ResNet-50 v1.5, SQuaD v1.1 for BERT Large Fine Tuning, Criteo Terabyte Dataset for DLRM, Batch sizes for ResNet-50: A100, V100 = 256; Batch sizes for BERT Large: A100 = 32, V100 = 10; Batch sizes for DLRM: A100, V100 = 65536; Cost estimated using performance data run on the earlier configurations as well as on-demand instance pricing as of 2/8/2022.
Google Cloud Platform:
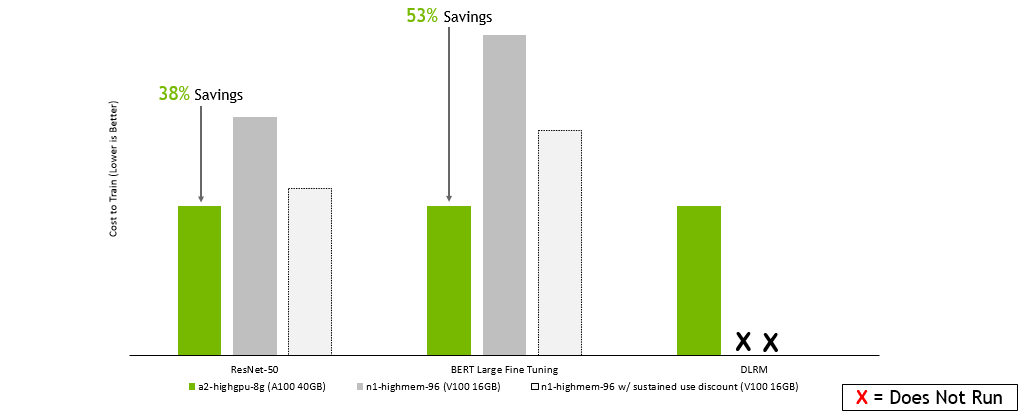
GPU Server: Dual socket AMD EPYC 7742 @ 2.25GHz w/ 8x NVIDIA A100 SXM4-40GB, Dual socket Intel Xeon E5-2698 v4 @ 2.2GHz w/ 8x NVIDIA V100 SXM2-32GB, and Dual socket Intel Xeon E5-2698 v4 @ 2.2GHz w/ 8x NVIDIA V100 SXM2-16GB. Frameworks: TensorFlow for ResNet-50 v1.5, PyTorch for BERT-Large and DLRM; Precision: Mixed+XLA for ResNet-50 v1.5, Mixed for BERT-Large and DLRM. NVIDIA Driver: 465.19.01; Dataset: ImageNet2012 for ResNet-50 v1.5, SQuaD v1.1 for BERT Large Fine Tuning, Criteo Terabyte Dataset for DLRM, Batch sizes for ResNet-50: A100, V100 = 256; Batch sizes for BERT Large: A100 = 32, V100 = 10; Batch sizes for DLRM: A100, V100 = 65536; Cost estimated using performance data run on the earlier configurations as well as on-demand instance pricing as of 2/8/2022.
Microsoft Azure:
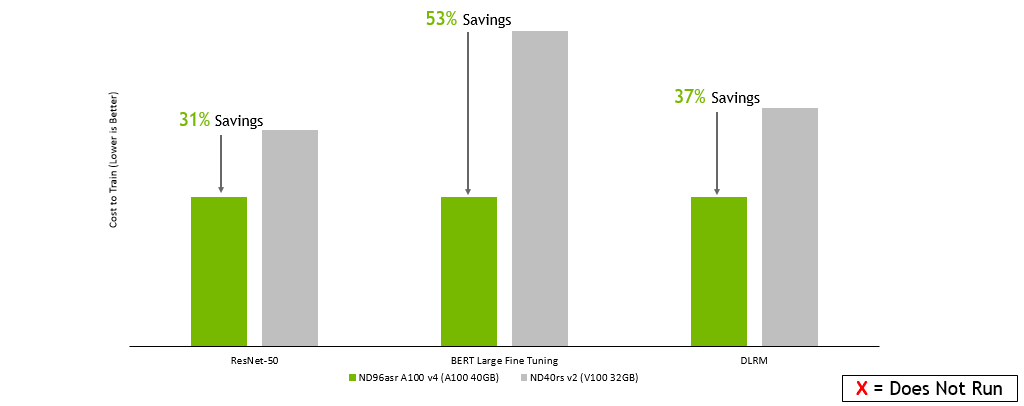
GPU Server: Dual socket AMD EPYC 7742 @ 2.25GHz w/ 8x NVIDIA A100 SXM4-40GB, Dual socket Intel Xeon E5-2698 v4 @ 2.2GHz w/ 8x NVIDIA V100 SXM2-32GB, and Dual socket Intel Xeon E5-2698 v4 @ 2.2GHz w/ 8x NVIDIA V100 SXM2-16GB. Frameworks: TensorFlow for ResNet-50 v1.5, PyTorch for BERT-Large and DLRM; Precision: Mixed+XLA for ResNet-50 v1.5, Mixed for BERT-Large and DLRM. NVIDIA Driver: 465.19.01; Dataset: ImageNet2012 for ResNet-50 v1.5, SQuaD v1.1 for BERT Large Fine Tuning, Criteo Terabyte Dataset for DLRM, Batch sizes for ResNet-50: A100, V100 = 256; Batch sizes for BERT Large: A100 = 32, V100 = 10; Batch sizes for DLRM: A100, V100 = 65536; Costs estimated using performance data run on the earlier configurations as well as on-demand instance pricing as of 2/8/2022.
In addition to delivering lower training costs and saving users a significant amount of time, there’s another benefit to using current-generation instances: they enable fundamentally new AI use cases. For example, AI-based recommendation engines are becoming increasingly popular and NVIDIA GPUs are commonly used to train them. Figure 5 summarizes the cost and time savings that A100-instances deliver across different cloud providers:
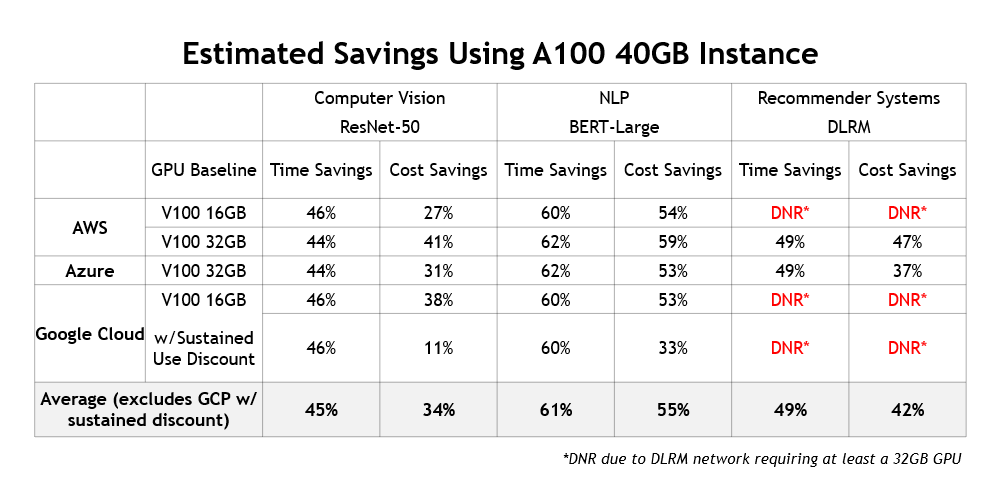
These results presented here show that the much greater performance delivered by current-generation NVIDIA GPU-accelerated instances more than outweighs the per-hour pricing differences compared to older instances that use prior-generation GPUs.
Instances based on the latest NVIDIA A100 GPUs not only maximize the productivity of your data science teams by minimizing training time, but they’re also the most cost-effective way to train your models in the cloud.
To learn more about the many options for using NVIDIA acceleration in the cloud, see Cloud Computing.
Action recognition has become a major focus area for the research community because many applications can benefit from improved modeling, such as video retrieval, video captioning, video question-answering, etc. Transformer-based approaches have recently demonstrated state-of-the-art performance on several benchmarks. While Transformer models require data to learn better visual priors compared to ConvNets, action recognition datasets are relatively small in scale. Large Transformer models are typically first trained on image datasets and later fine-tuned on a target action recognition dataset.
While the current pre-training and fine-tuning action recognition paradigm is straightforward and manifests strong empirical results, it may be overly restrictive for building general-purpose action-recognition models. Compared to a dataset like ImageNet that covers a large range of object recognition classes, action recognition datasets like Kinetics and Something-Something-v2 (SSv2) pertain to limited topics. For example, Kinetics include object-centric actions like “cliff diving” and “ice climbing’ while SSv2 contains object-agnostic activities like ’pretending to put something onto something else.’ As a result, we observed poor performance adapting an action recognition model that has been fine-tuned on one dataset to another disparate dataset.
Differences in objects and video backgrounds among datasets further exacerbate learning a general-purpose action recognition classification model. Despite the fact that video datasets may be increasing in size, prior work suggests significant data augmentation and regularization is necessary to achieve strong performance. This latter finding may indicate the model quickly overfits on the target dataset, and as a result, hinders its capacity to generalize to other action recognition tasks.
In “Co-training Transformer with Videos and Images Improves Action Recognition”, we propose a training strategy, named CoVeR, that leverages both image and video data to jointly learn a single general-purpose action recognition model. Our approach is buttressed by two main findings. First, disparate video datasets cover a diverse set of activities, and training them together in a single model could lead to a model that excels at a wide range of activities. Second, video is a perfect source for learning motion information, while images are great for exploiting structural appearance. Leveraging a diverse distribution of image examples may be beneficial in building robust spatial representations in video models. Concretely, CoVeR first pre-trains the model on an image dataset, and during fine-tuning, it simultaneously trains a single model on multiple video and image datasets to build robust spatial and temporal representations for a general-purpose video understanding model.
Architecture and Training Strategy
We applied the CoVeR approach to the recently proposed spatial-temporal video transformer, called TimeSFormer, that contains 24 layers of transformer blocks. Each block contains one temporal attention, one spatial attention, and one multilayer perceptron (MLP) layer. To learn from multiple video and image datasets, we adopt a multi-task learning paradigm and equip the action recognition model with multiple classification heads. We pre-train all non-temporal parameters on the large-scale JFT dataset. During fine-tuning, a batch of videos and images are sampled from multiple video and image datasets. The sampling rate is proportional to the size of the datasets. Each sample within the batch is processed by the TimeSFormer and then distributed to the corresponding classifier to get the predictions.
Compared with the standard training strategy, CoVeR has two advantages. First, as the model is directly trained on multiple datasets, the learned video representations are more general and can be directly evaluated on those datasets without additional fine-tuning. Second, Transformer-based models may easily overfit to a smaller video distribution, thus degrading the generalization of the learned representations. Training on multiple datasets mitigates this challenge by reducing the risk of overfitting.
 |
| CoVeR adopts a multi-task learning strategy trained on multiple datasets, each with their own classifier. |
Benchmark Results
We evaluate the CoVeR approach to train on Kinetics-400 (K400), Kinetics-600 (K600), Kinetics-700 (K700), SomethingSomething-V2 (SSv2), and Moments-in-Time (MiT) datasets. Compared with other approaches — such as TimeSFormer, Video SwinTransformer, TokenLearner, ViViT, MoViNet, VATT, VidTr, and OmniSource — CoVeR established the new state-of-the-art on multiple datasets (shown below). Unlike previous approaches that train a dedicated model for one single dataset, a model trained by CoVeR can be directly applied to multiple datasets without further fine-tuning.
| Model | Pretrain | Finetune | K400 Accuracy |
| VATT | AudioSet+Videos | K400 | 82.1 |
| Omnisource | IG-Kinetics-65M | K400 | 83.6 |
| ViViT | JFT-300M | K400 | 85.4 |
| Video SwinTrans | ImageNet21K+external | K400 | 86.8 |
| CoVeR | JFT-3B | K400+SSv2+MiT+ImNet | 87.2 |
| Accuracy comparison on Kinetics-400 (K400) dataset. |
| Model | Pretrain | Finetune | SSv2 Accuracy |
| TimeSFormer | ImageNet21k | SSv2 | 62.4 |
| VidTr | ImageNet21k | SSv2 | 63.0 |
| ViViT | ImageNet21k | SSv2 | 65.9 |
| Video SwinTrans | ImageNet21K+external | SSv2 | 69.6 |
| CoVeR | JFT-3B | K400+SSv2+MiT+ImNet | 70.9 |
| Accuracy comparison on SomethingSomething-V2 (SSv2) dataset. |
| Model | Pretrain | Finetune | MiT Accuracy |
| ViViT | ImageNet21k | MiT | 38.5 |
| VidTr | ImageNet21k | SSv2 | 41.1 |
| CoVeR | JFT-3B | K400+SSv2+MiT+ImNet | 46.1 |
| Accuracy comparison on Moments-in-Time (MiT) dataset. |
Transfer Learning
We use transfer learning to further verify the video action recognition performance and compare with co-training on multiple datasets, results are summarized below. Specifically, we train on the source datasets, then fine-tune and evaluate on the target dataset.
We first consider K400 as the target dataset. CoVeR co-trained on SSv2 and MiT improves the top-1 accuracy on K400→K400 (where the model is trained on K400 and then fine-tuned on K400) by 1.3%, SSv2→K400 by 1.7%, and MiT→K400 by 0.4%. Similarly, we observe that by transferring to SSv2, CoVeR achieves 2%, 1.8%, and 1.1% improvement over SSv2→SSv2, K400→SSv2, and MiT→SSv2, respectively. The 1.2% and 2% performance improvement on K400 and SSv2 indicates that CoVeR co-trained on multiple datasets could learn better visual representations than the standard training paradigm, which is useful for downstream tasks.
 |
| Comparison of transfer learning the representation learned by CoVeR and standard training paradigm. A→B means the model is trained on dataset A and then fine-tuned on dataset B. |
Conclusion
In this work, we present CoVeR, a training paradigm that jointly learns action recognition and object recognition tasks in a single model for the purpose of constructing a general-purpose action recognition framework. Our analysis indicates that it may be beneficial to integrate many video datasets into one multi-task learning paradigm. We highlight the importance of continuing to learn on image data during fine-tuning to maintain robust spatial representations. Our empirical findings suggest CoVeR can learn a single general-purpose video understanding model which achieves impressive performance across many action recognition datasets without an additional stage of fine-tuning on each downstream application.
Acknowledgements
We would like to thank Christopher Fifty, Wei Han, Andrew M. Dai, Ruoming Pang, and Fei Sha for preparation of the CoVeR paper, Yue Zhao, Hexiang Hu, Zirui Wang, Zitian Chen, Qingqing Huang, Claire Cui and Yonghui Wu for helpful discussions and feedbacks, and others on the Brain Team for support throughout this project.

I can load text data using: tf.keras.utils.text_dataset_from_directory but to use that, each of my “rows” need to be in individual files in their own directory and the label is determined by the directory name.
For the life of me, I can’t figure out how to convert a pandas dataframe into a DataSet.
The dataframe would have some structure like this:
index label unstructured_text 1 1 i like ice cream 2 0 i don't like ice cream 3 1 i'm a little teapot and i'm happy
etc.
Thank you for any hints.
submitted by /u/1-800-AVOGADRO
[visit reddit] [comments]
Is there a practical limit on the size of graph Tensorflow can handle? We are looking at large computation problems that could expand to hundreds of million or billions of nodes in the graph, am wondering if Tensorflow can automatically handle the construction and distributed execution of such large graphs over multiple computers using CPUs? Or we have to manually break the graph into smaller ones before sending to Tensorflow?
Any first-hand experience in handling large graphs are great appreciated, such as the maximum graph size you were able to run in Tensorflow, and any potential pitfalls etc,
submitted by /u/amazingraph
[visit reddit] [comments]
GauGAN, an AI demo for photorealistic image generation, allows anyone to create stunning landscapes using generative adversarial networks. Named after post-Impressionist painter Paul Gauguin, it was created by NVIDIA Research and can be experienced free through NVIDIA AI Demos. How to Create With GauGAN The latest version of the demo, GauGAN2, turns any combination of Read article >
The post What Is GauGAN? How AI Turns Your Words and Pictures Into Stunning Art appeared first on NVIDIA Blog.
Since months I want to implement a VERY basic RNN layer for a project. Its kinda frustrating because 99% of the rest of the project is done. Its only the RNN layer and its a major point of the project.
So I beg you to just have a quick look to my stackoverflow post: https://stackoverflow.com/questions/71308645/warning-variables-were-used-in-a-lambda-layers-call-results-in-not-trainable
I would be VERY thankful if someone can give me the right hint to overcome this last obstacle! Thanks!
submitted by /u/Rindsroulade
[visit reddit] [comments]