In my model I have a keras.layers.Lambda layer as the output layer. I use the layer to do some post-processing and return either a 0 or a 1. The problem arises when I run the predict function, the lambda layer only returns a small portion of the last batch data.
Like imagine you have a lambda function that returns the same constant no matter the input given, then the layer won’t give predictions on all data that was passed to it.
For example:
def output_function(x): # Return 1 no matter the input return 1 model = keras.Sequential([ keras.layers.Dense(1, activation='sigmoid'), keras.layers.Lambda(output_function) ]) test_data = tf.random.uniform(shape=(79, 1)) model.predict(test_data, batch_size=32) # Returns an array of only 3 predictions
I suspect that it is because I don’t return a tensor of the shape (None, 1), but rather just (1). But I don’t know how to rewrite the output_function to return a tensor of shape (None, 1).
Researchers create a new AI algorithm that can analyze mammography scans, identify whether a lesion is malignant, and show how it reached its conclusion.
A recently developed AI platform is giving medical professionals screening for breast cancer a new, transparent tool for evaluating mammography scans. The research, creates an AI model that evaluates the scans and highlights parts of an image the algorithm finds relevant. The work could help medical professionals determine whether a patient needs an invasive—and often nerve-wracking—biopsy.
“If a computer is going to help make important medical decisions, physicians need to trust that the AI is basing its conclusions on something that makes sense,” Joseph Lo, professor of radiology at Duke and study coauthor said in a press release. “We need algorithms that not only work, but explain themselves and show examples of what they’re basing their conclusions on. That way, whether a physician agrees with the outcome or not, the AI is helping to make better decisions.”
One in every eight women in the US will develop invasive breast cancer during their lifetime. When detected early, a woman has a 93 percent or higher survival rate in the first 5 years.
Mammography, which uses low-energy X-rays to examine breast tissue for diagnosis and screening, is an effective tool for early detection, but requires a highly skilled radiologist to interpret the scans. However, false negatives and positives do occur, resulting in missed diagnosis and up to 40% of biopsied lesions being benign.
Using AI for medical imaging analysis has grown significantly in recent years and offers advantages in interpreting data. Implementing AI models also carries risks, especially when an algorithm fails.
“Our idea was to instead build a system to say that this specific part of a potential cancerous lesion looks a lot like this other one that I’ve seen before,” said study lead and Duke computer science Ph.D. candidate Alina Barnett. “Without these explicit details, medical practitioners will lose time and faith in the system if there’s no way to understand why it sometimes makes mistakes.”
Using 1,136 images from 484 patients within the Duke University Health System, researchers trained the algorithm to locate and evaluate potentially cancerous areas. This was accomplished by training the models to identify unhealthy tissue, or lesions, which often appear as bright or irregular shapes with fuzzy edges on a scan.
Radiologists then labeled these images, teaching the algorithm to focus on the fuzzy edges, also known as margins. Often associated with quick-growing cancerous breast tumor cells, margins are a strong indicator of cancerous lesions. With these carefully labeled images, the AI can compare cancerous and benign edges, and learn to distinguish between them.
The AI model uses the cuDNN-accelerated PyTorch deep learning framework and can be run on two NVIDIA P100 or V100 GPUs.
Figure 1. Top image shows an AI model for spotting pre-cancerous lesions in mammography without revealing the decision-making process. Bottom image shows the IAIA-BL model that tells doctors where it’s looking and how its drawing its conclusions. Credit: Alina Barnett, Duke University.
The researchers found the AI to be as effective as other machine learning-based mammography models, but it holds the advantage of having transparency in its decision-making. When the model is wrong, a radiologist can see how the mistake was made.
According to the study, the model could also be a useful tool when teaching medical students how to read mammogram scans and for resource-constrained areas of the world lacking cancer specialists.
The code from the study is available through GitHub.
Deep learning models require a lot of data to produce accurate predictions. Here’s how to solve the data processing problem for the medical domain with NVIDIA DALI.
Deep learning models require vast amounts of data to produce accurate predictions, and this need becomes more acute every day as models grow in size and complexity. Even large datasets, such as the well-known ImageNet with more than a million images, are not sufficient to achieve state-of-the-art results in modern computer vision tasks.
For this purpose, data augmentation techniques are required to artificially increase the size of a dataset by introducing random disturbances to the data, such as geometric deformations, color transforms, noise addition, and so on. These disturbances help produce models that are more robust in their predictions, avoid overfitting, and deliver better accuracy.
In medical imaging tasks, data augmentation is critical because datasets contain mere hundreds or thousands of samples at best. Models, on the other hand, tend to produce large activations that require a lot of GPU memory, especially when dealing with volumetric data such as CT and MRI scans. This typically results in training with small batch sizes on a small dataset. To avoid overfitting, more elaborate data preprocessing and augmentation techniques are required.
Preprocessing, however, often has a significant impact on the overall performance of the system. This is especially true in applications dealing with large inputs, such as volumetric images. These preprocessing tasks are typically run on the CPU due to simplicity, flexibility, and availability of libraries such as NumPy.
In some applications, such as segmentation or detection in medical images, the GPU utilization during training is usually suboptimal as data preprocessing is usually performed in the CPU. One of the solutions is to attempt to overlap data processing and training fully, but it is not always that simple.
Such a performance bottleneck leads to a chicken and egg problem. Researchers avoid introducing more advanced augmentations into their models due to performance reasons, and libraries don’t put the effort into optimizing preprocessing primitives due to low adoption.
GPU acceleration solution
You can improve the performance of applications with heavy data preprocessing pipelines significantly by offloading data preprocessing to the GPU. The GPU is typically underutilized in such scenarios but can be used to do the work that the CPU cannot complete in time. The result is better hardware utilization, and ultimately faster training.
Figure 1. U-Net3D BraTS21 training performance comparison
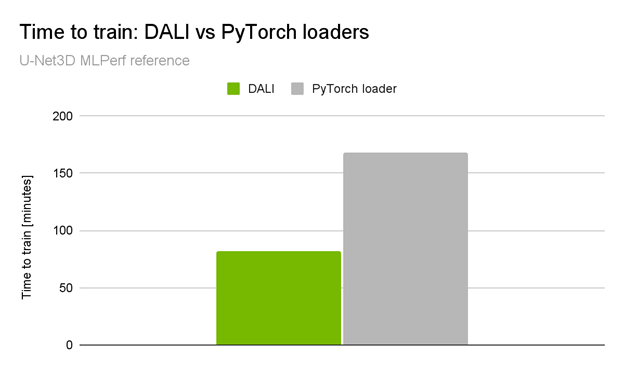
This difference becomes more significant when you look at the NVIDIA submission for the MLPerf UNet3D benchmark. It used the same network architecture as in the BraTS21 winning solution but with a more complex data loading pipeline and larger input volumes (KITS19 dataset). The performance boost is an impressive 2x end-to-end training speedup when compared with the native pipeline (Figure 2).
Figure 2. U-Net3D MLPerf Training 1.1 training performance comparison
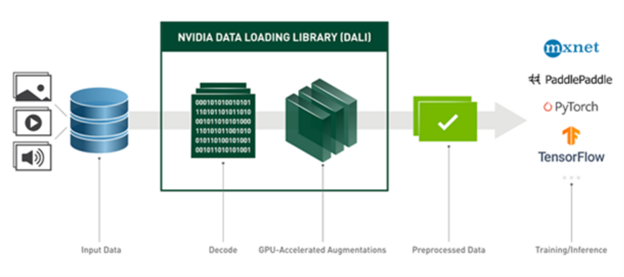
This was made possible by NVIDIA Data Loading Library (DALI). DALI provides a set of GPU-accelerated building blocks, enabling you to build a complete data processing pipeline that includes data loading, decoding, and augmentation, and to integrate it with a deep learning framework of choice (Figure 3).
Figure 3. DALI overview and its usage as a tool for accelerated data loading and preprocessing in DL applications
Volumetric image operations
Originally, DALI was developed as a solution for images classification and detection workflows. Later, it was extended to cover other data domains, such as audio, video, or volumetric images. For more information about volumetric data processing, see 3D Transforms or Numpy Reader.
DALI supports a wide range of image-processing operators. Some can also be applied to volumetric images. Here are some examples worth mentioning:
Resize
Warp affine
Rotate
Random object bounding box
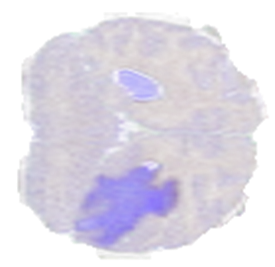
To showcase some of the mentioned operations, we use a sample from the BraTS19 dataset, consisting of MRI scans labeled for brain tumor segmentation. Figure 4 shows a two-dimensional slice extracted from a brain MRI scan volume, where the darker region represents a region labeled as an abnormality.
Figure 4. A slice from a BraTS19 dataset sample
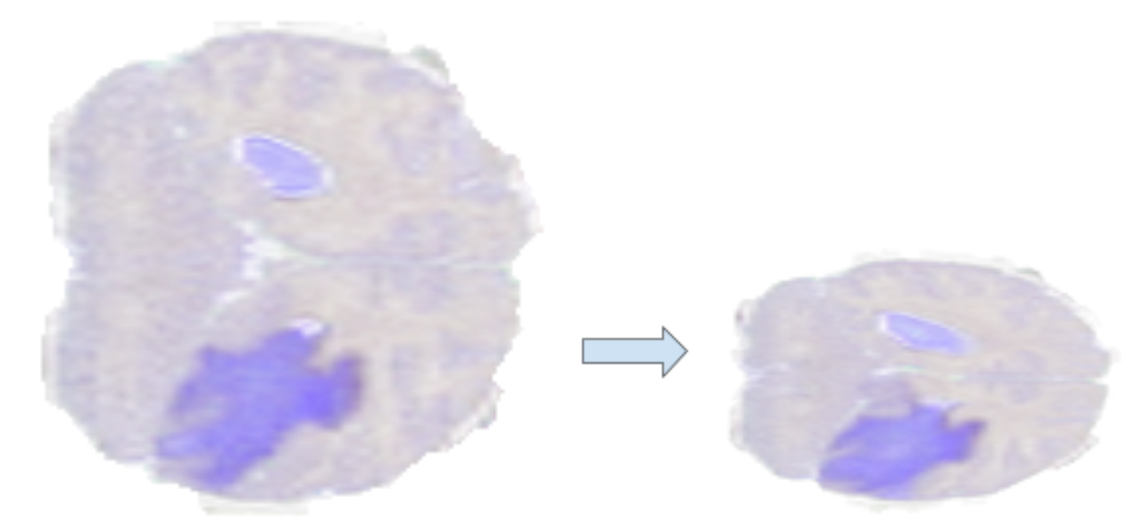
Resize operator
Resize upscales or downscales the image to a desired shape by interpolating the input pixels. The upscale or downscale is configurable for each dimension separately, including the selection of the interpolation method.
Figure 5. Reference slice from BraTS19 dataset sample (left) compared with resizedsample (right)
Warp affine operator
Warp affine applies a geometric transformation by mapping pixel coordinates from source to destination with a linear transformation.
Warp affine can be used to perform multiple transformations (rotation, flip, shear, scale) in one go.
Figure 6. A slice of a volume transformed with WarpAffine
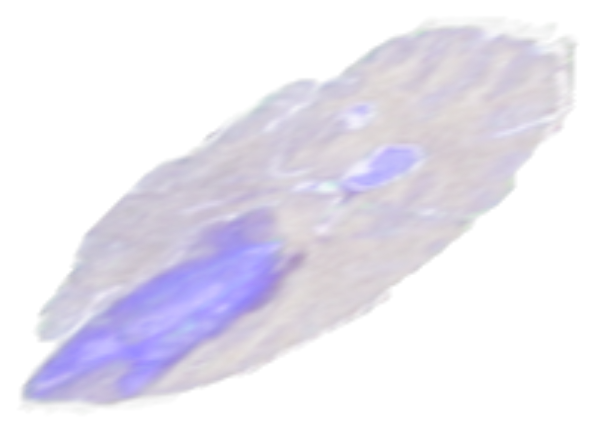
Rotate operator
Rotate allows you to rotate a volume around an arbitrary axis, provided as a vector, and an angle. It can also optionally extend the canvas so that the entire rotated image is contained in it. Figure 7 shows an example of a rotated volume.
Figure 7. A slice from a rotated volume
Random object bounding box operator
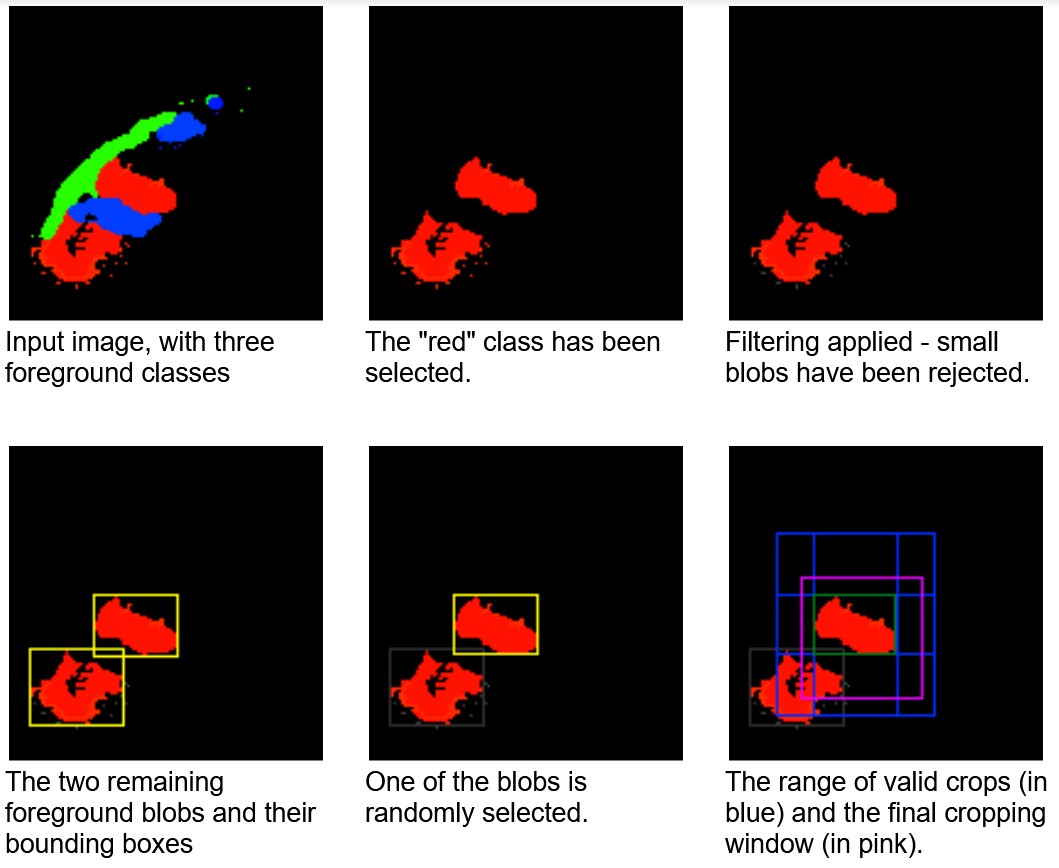
Random object bounding box is an operator suited for detection and segmentation tasks. As mentioned earlier, medical datasets tend to be rather small, with target classes (such as abnormalities) occupying a comparatively small area. Furthermore, in many cases the input volume is much larger than the volume expected by the network. If you were to use random cropping windows for training, then the majority would not contain the target. This could cause the training convergence to slow down or bias the network towards false-negative results.
This operator selects pseudo-random crops that can be biased towards sampling a particular label. Connected component analysis is performed on the label map as a pre-step. Then, a connected blob is selected at random, with equal probability. By doing that, the operator avoids overrepresenting larger blobs.
You can also select to restrict the selection to the largest K blobs or specify a minimum blob size. When a particular blob is selected, a random cropping window is generated, within the range containing the given blob. Figure 8 shows this cropping window selection process.
Figure 8. A visualization of the Random object bounding box operation on an artificial 2D image with a set of objects belonging to three different classes (each highlighted with different color)
The gain in learning speed can be significant. On the KITS19 dataset, nnU-Net achieves the same accuracy in 2134 in the test run epochs with the Random object bounding box operator as in 3,222 epochs with random crop.
Typically, the process of finding connected components is slow, but the number of samples in the data set can be small. The operator can be configured to cache the connected component information, so that it’s only calculated during the first epoch of the training.
Accelerate on your own
You can download the latest version of the prebuilt and tested DALI pip packages. The NGC containers for TensorFlow, PyTorch, and MXNet have DALI integrated. You can review the many examples and read the latest release notes for a detailed list of new features and enhancements.
See how DALI can help you accelerate data preprocessing for your deep learning applications. The best place to access is the NVIDIA DALI Documentation, including numerous examples and tutorials. You can also watch our GTC 2021 talk about DALI. DALI is an open-source project, and our code is available on the /NVIDIA/DALI GitHub repo. We welcome your feedback and contributions.
I have trained a model using tf1.15, converted it to tflite and compiled it for the edgetpu, which is all working. However, my confidence values for all bounding boxes is 50%. It seems to recognise what is what somewhat well, such as putting many boxes over and around the object it’s trying to detect, but they’re all 50% confidence so it is difficult to get a clean output. I believe the issue was not caused by any conversions, but during training, as tensorboard also shows this.
Browse through MORF Gallery — virtually or at an in-person exhibition — and you’ll find robots that paint, digital dreamscape experiences, and fine art brought to life by visual effects. The gallery showcases cutting-edge, one-of-a-kind artwork from award-winning artists who fuse their creative skills with AI, machine learning, robotics and neuroscience. Scott Birnbaum, CEO and Read article >
With a new year underway, NVIDIA is helping enterprises worldwide add modern workloads to their mainstream servers using the latest release of the NVIDIA AI Enterprise software suite. NVIDIA AI Enterprise 1.1 is now generally available. Optimized, certified and supported by NVIDIA, the latest version of the software suite brings new updates including production support Read article >
How much would it take to train a model which consists of about 2000 pictures on my laptop (I am a beginner but I need to train it for a project) Specs: Ryzen 5 3500u 10gb of ram vega 8 gpu
I was going to do it on the cpu, because I think its more powerful (correct me if I am wrong)
Posted by Oran Lang and Inbar Mosseri, Software Engineers, Google Research
Neural networks can perform certain tasks remarkably well, but understanding how they reach their decisions — e.g., identifying which signals in an image cause a model to determine it to be of one class and not another — is often a mystery. Explaining a neural model’s decision process may have high social impact in certain areas, such as analysis of medical images and autonomous driving, where human oversight is critical. These insights can also be helpful in guiding health care providers, revealing model biases, providing support for downstream decision makers, and even aiding scientific discovery.
Previous approaches for visual explanations of classifiers, such as attention maps (e.g., Grad-CAM), highlight which regions in an image affect the classification, but they do not explain what attributes within those regions determine the classification outcome: For example, is it their color? Their shape? Another family of methods provides an explanation by smoothly transforming the image between one class and another (e.g., GANalyze). However, these methods tend to change all attributes at once, thus making it difficult to isolate the individual affecting attributes.
In “Explaining in Style: Training a GAN to explain a classifier in StyleSpace”, presented at ICCV 2021, we propose a new approach for a visual explanation of classifiers. Our approach, StylEx, automatically discovers and visualizes disentangled attributes that affect a classifier. It allows exploring the effect of individual attributes by manipulating those attributes separately (changing one attribute does not affect others). StylEx is applicable to a wide range of domains, including animals, leaves, faces, and retinal images. Our results show that StylEx finds attributes that align well with semantic ones, generate meaningful image-specific explanations, and are interpretable by people as measured in user studies.
Explaining a Cat vs. Dog Classifier: StylEx provides the top-K discovered disentangled attributes which explain the classification. Moving each knob manipulates only the corresponding attribute in the image, keeping other attributes of the subject fixed.
For instance, to understand a cat vs. dog classifier on a given image, StylEx can automatically detect disentangled attributes and visualize how manipulating each attribute can affect the classifier probability. The user can then view these attributes and make semantic interpretations for what they represent. For example, in the figure above, one can draw conclusions such as “dogs are more likely to have their mouth open than cats” (attribute #4 in the GIF above), “cats’ pupils are more slit-like” (attribute #5), “cats’ ears do not tend to be folded” (attribute #1), and so on.
The video below provides a short explanation of the method:
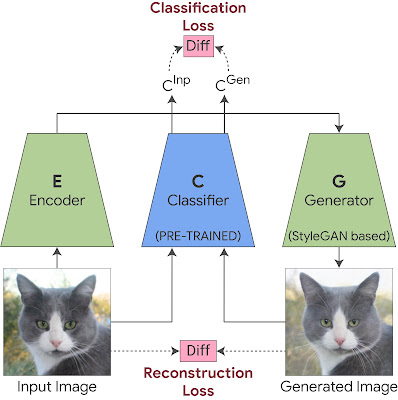
How StylEx Works: Training StyleGAN to Explain a Classifier Given a classifier and an input image, we want to find and visualize the individual attributes that affect its classification. For that, we utilize the StyleGAN2 architecture, which is known to generate high quality images. Our method consists of two phases:
Phase 1: Training StylEx
A recent work showed that StyleGAN2 contains a disentangled latent space called “StyleSpace”, which contains individual semantically meaningful attributes of the images in the training dataset. However, because StyleGAN training is not dependent on the classifier, it may not represent those attributes that are important for the decision of the specific classifier we want to explain. Therefore, we train a StyleGAN-like generator to satisfy the classifier, thus encouraging its StyleSpace to accommodate classifier-specific attributes.
This is achieved by training the StyleGAN generator with two additional components. The first is an encoder, trained together with the GAN with a reconstruction-loss, which forces the generated output image to be visually similar to the input. This allows us to apply the generator on any given input image. However, visual similarity of the image is not enough, as it may not necessarily capture subtle visual details important for a particular classifier (such as medical pathologies). To ensure this, we add a classification-loss to the StyleGAN training, which forces the classifier probability of the generated image to be the same as the classifier probability of the input image. This guarantees that subtle visual details important for the classifier (such as medical pathologies) will be included in the generated image.
Training StyleEx: We jointly train the generator and the encoder. A reconstruction-loss is applied between the generated image and the original image to preserve visual similarity. A classification-loss is applied between the classifier output of the generated image and the classifier output of the original image to ensure the generator captures subtle visual details important for the classification.
Phase 2: Extracting Disentangled Attributes
Once trained, we search the StyleSpace of the trained Generator for attributes that significantly affect the classifier. To do so, we manipulate each StyleSpace coordinate and measure its effect on the classification probability. We seek the top attributes that maximize the change in classification probability for the given image. This provides the top-K image-specific attributes. By repeating this process for a large number of images per class, we can further discover the top-K class-specific attributes, which teaches us what the classifier has learned about the specific class. We call our end-to-end system “StylEx”.
A visual illustration of image-specific attribute extraction: once trained, we search for the StyleSpace coordinates that have the highest effect on the classification probability of a given image.
StylEx is Applicable to a Wide Range of Domains and Classifiers Our method works on a wide variety of domains and classifiers (binary and multi-class). Below are some examples of class-specific explanations. In all the domains tested, the top attributes detected by our method correspond to coherent semantic notions when interpreted by humans, as verified by human evaluation.
For perceived gender and age classifiers, below are the top four detected attributes per classifier. Our method exemplifies each attribute on multiple images that are automatically selected to best demonstrate that attribute. For each attribute we flicker between the source and attribute-manipulated image. The degree to which manipulating the attribute affects the classifier probability is shown at the top-left corner of each image.
Top-4 automatically detected attributes for a perceived-gender classifier.
Top-4 automatically detected attributes for a perceived-age classifier.
Note that our method explains a classifier, not reality. That is, the method is designed to reveal image attributes that a given classifier has learned to utilize from data; those attributes may not necessarily characterize actual physical differences between class labels (e.g., a younger or older age) in reality. In particular, these detected attributes may reveal biases in the classifier training or dataset, which is another key benefit of our method. It can further be used to improve fairness of neural networks, for example, by augmenting the training dataset with examples that compensate for the biases our method reveals.
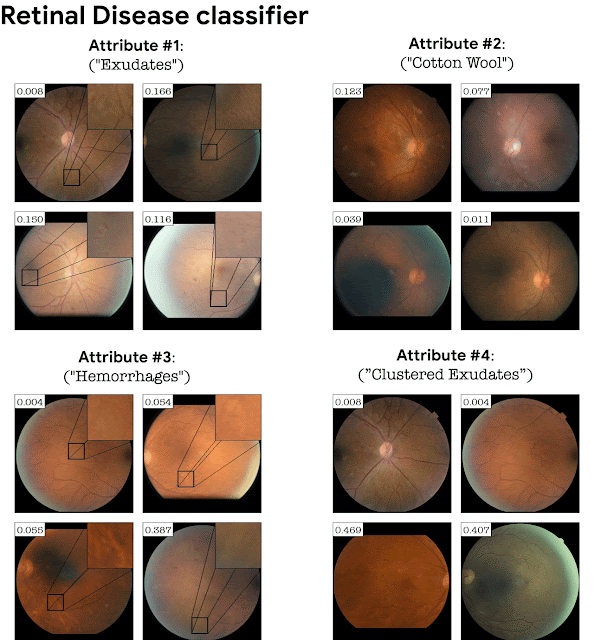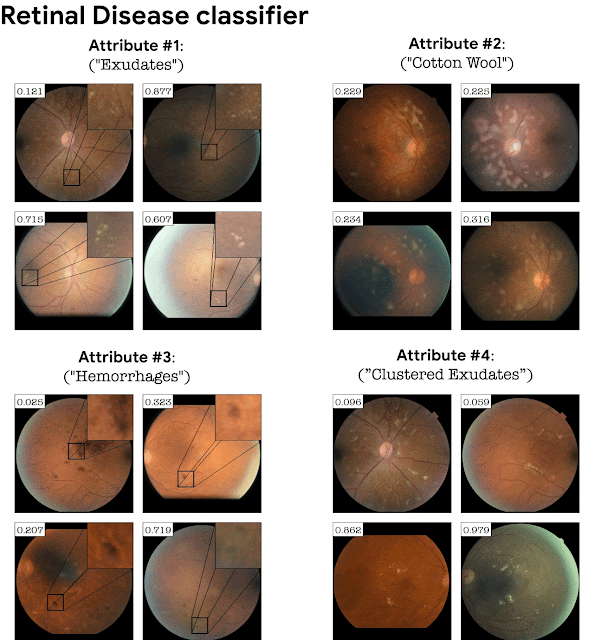
Adding the classifier loss into StyleGAN training turns out to be crucial in domains where the classification depends on fine details. For example, a GAN trained on retinal images without a classifier loss will not necessarily generate fine pathological details corresponding to a particular disease. Adding the classification loss causes the GAN to generate these subtle pathologies as an explanation of the classifier. This is exemplified below for a retinal image classifier (DME disease) and a sick/healthy leaf classifier. StylEx is able to discover attributes that are aligned with disease indicators, for instance “hard exudates”, which is a well known marker for retinal DME, and rot for leaf diseases.
Top-4 automatically detected attributes for a DME classifier of retina images.
Top-4 automatically detected attributes for a classifier of sick/healthy leaf images.
Finally, this method is also applicable to multi-class problems, as demonstrated on a 200-way bird species classifier.
Top-4 automatically detected attributes in a 200-way classifier trained on CUB-2011 for(a) the class “brewer blackbird”, and (b) the class “yellow bellied flycatcher”. Indeed we observe that StylEx detects attributes that correspond to attributes in CUB taxonomy.
Broader Impact and Next Steps Overall, we have introduced a new technique that enables the generation of meaningful explanations for a given classifier on a given image or class. We believe that our technique is a promising step towards detection and mitigation of previously unknown biases in classifiers and/or datasets, in line with Google’s AI Principles. Additionally, our focus on multiple-attribute based explanation is key to providing new insights about previously opaque classification processes and aiding in the process of scientific discovery. Finally, our GitHub repository includes a Colab and model weights for the GANs used in our paper.
Acknowledgements The research described in this post was done by Oran Lang, Yossi Gandelsman, Michal Yarom, Yoav Wald (as an intern), Gal Elidan, Avinatan Hassidim, William T. Freeman, Phillip Isola, Amir Globerson, Michal Irani and Inbar Mosseri. We would like to thank Jenny Huang and Marilyn Zhang for leading the writing process for this blogpost, and Reena Jana, Paul Nicholas, and Johnny Soraker for ethics reviews of our research paper and this post.
GANcraft is a hybrid neural rendering pipeline to represent large and complex scenes using Minecraft.
Scientists at NVIDIA and Cornell University introduced a hybrid unsupervised neural rendering pipeline to represent large and complex scenes efficiently in voxel worlds. Essentially, a 3D artist only needs to build the bare minimum, and the algorithm will do the rest to build a photorealistic world. The researchers applied this hybrid neural rendering pipeline to Minecraft block worlds to generate a far more realistic version of the Minecraft scenery.
Previous works from NVIDIA and the broader research community (pix2pix, pix2pixHD, MUNIT, SPADE) have tackled the problem of image-to-image translation (im2im)—translating an image from one domain to another. At first glance, these methods might seem to offer a simple solution to the task of transforming one world to another—translating one image at a time. However, im2im methods do not preserve viewpoint consistency, as they have no knowledge of the 3D geometry, and each 2D frame is generated independently. As can be seen in the images that follow, the results from these methods produce jitter and abrupt color and texture changes.
MUNIT SPADE wc-vid2vid NSVF-W GANcraft
Figure 1. A comparison of prior works and GANcraft.
Enter GANcraft, a new method that directly operates on the 3D input world.
“As the ground truth photorealistic renderings for a user-created block world simply doesn’t exist, we have to train models with indirect supervision,” the researchers explained in the study.
The method works by randomly sampling camera views in the input block world and then imagining what a photorealistic version of that view would look like. This is done with the help of SPADE, prior work from NVIDIA on image-to-image translation, and was the key component in the popular GauGAN demo. GANcraft overcomes the view inconsistency of these generated “pseudo-groundtruths” through the use of a style-conditioning network that can disambiguate the world structure from the rendering style. This enables GANcraft to generate output videos that are view consistent, as well as with different styles as shown in this image!
Figure 2. GANcraft’s methodology enables view consistency in a variety of different styles.
While the results of the research are demonstrated in Minecraft, the method works with other 3D block worlds such as voxels. The potential to shorten the amount of time and expertise needed to build high-definition worlds increases the value of this research. It could help game developers, CGI artists, and the animation industry cut down on the time it takes to build these large and impressive worlds.
If you would like a further breakdown of the potential of this technology, Károly Zsolnai-Fehér highlights the research in his YouTube series: Two Minute Papers:
Figure 3. The YouTube series, Two Minute Papers, covers significant developments in AI as they come onto the scene.
GANcraft was implemented in the Imaginaire library. This library is optimized for the training of generative models and generative adversarial networks, with support for multi-GPU, multi-node, and automatic mixed-precision training. Implementations of over 10 different research works produced by NVIDIA, as well as pretrained models have been released. This library will continue to be updated with newer works over time.

 Researchers create a new AI algorithm that can analyze mammography scans, identify whether a lesion is malignant, and show how it reached its conclusion.
Researchers create a new AI algorithm that can analyze mammography scans, identify whether a lesion is malignant, and show how it reached its conclusion.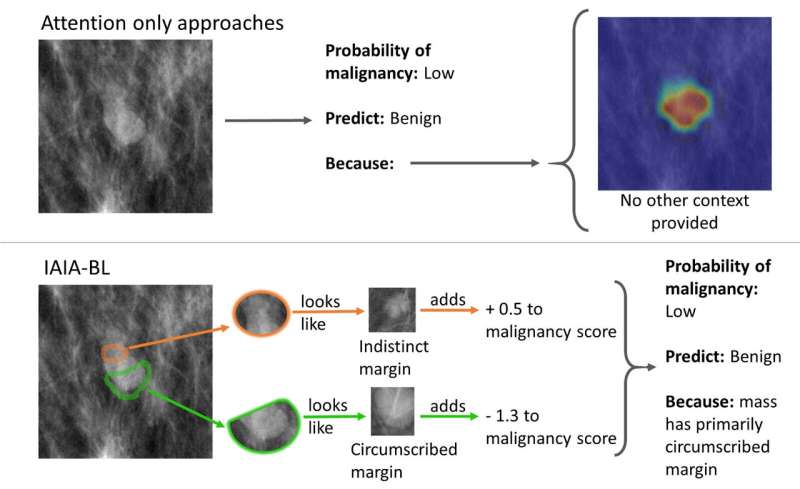
 Deep learning models require a lot of data to produce accurate predictions. Here’s how to solve the data processing problem for the medical domain with NVIDIA DALI.
Deep learning models require a lot of data to produce accurate predictions. Here’s how to solve the data processing problem for the medical domain with NVIDIA DALI.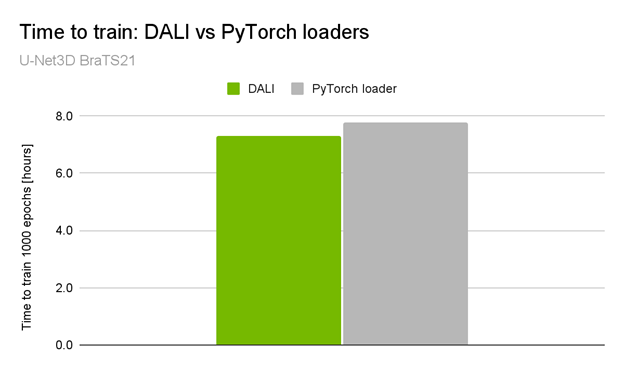
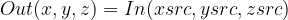







 GANcraft is a hybrid neural rendering pipeline to represent large and complex scenes using Minecraft.
GANcraft is a hybrid neural rendering pipeline to represent large and complex scenes using Minecraft.



