Game and professional visualization developers need the best tools to create the best games and real-time interactive content. Read this article to find out what NVIDIA technologies will provide developers optimal real time ray tracing within their workflows.
Game and professional visualization developers need the best tools to create the best games and real-time interactive content.
To help them achieve this goal, NVIDIA has pioneered real-time ray tracing hardware with the launch of the RTX 20 series.
Today, we continue to develop and expand powerful tools for developers by creating SDKs that run on RTX GPUs.
The following NVIDIA technologies will provide developers optimal real time ray tracing within their workflows:
RTXDI offers realistic lighting and shadows of dynamic scenes involving millions of lights which, until now, would have been prohibitively expensive for real-time applications. Traditionally, most lighting is baked offline, computing just a handful of “hero” dynamic lights at runtime. RTXDI pushes past those limits and allows developers to elevate the visual fidelity in their games.
RTXGI provides developers with a scalable solution for multi-bounce indirect lighting without light leakage, time-intensive offline lightmap baking, or expensive per-frame costs. RTXGI’s dynamic, real-time global illumination is not only beautiful in action, but it streamlines the content creation process by removing barriers that previously prevented artists from rapidly iterating. With a low performance cost and massive productivity gains, RTXGI is an ideal starting point to bring the benefits of ray tracing to your content.
Get the optimal real-time ray tracing performance with NRD, a library of spatial and spatio-temporal API-agnostic denoisers. From the beginning, NRD was specifically designed to work well with low ray budgets. With NRD, developers can create visuals that rival ground-truth images with as little as a half of a ray cast per pixel.
Get the latest news and updates about these SDKs at next month’s GPU Technology Conference. Registration is free — join us and hear from experts who worked on popular game titles, including Minecraft, Cyberpunk 2077, Overwatch and LEGO Builder’s Journey.
Explore the sessions for game developers and learn how you can integrate NVIDIA tools and technologies into games.
When freak lightning ignited massive wildfires across Northern California last year, it also sparked efforts from data scientists to improve predictions for blazes. One effort came from SpaceML, an initiative of the Frontier Development Lab, which is an AI research lab for NASA in partnership with the SETI Institute. Dedicated to open-source research, the SpaceML Read article >
Hey, just wanted to fine tune some data with GPT-2 155M to create some simple Discord or Twitter bots with my RTX 3080. What’s the best way to currently use the small GPT-2 with Tensorflow 2.0 currently? Looked around online, but doesn’t seem like there’s a lot of interest due to people interested in GPT moving onto 3 or Neo.
I have RTX 3070. I have Visual Studio installed, the appropriate driver installed along with cudnn and the appropriate CUDA toolkit. I have copied the bin, lib and include files into my C:Program FilesNVIDIA GPU Computing ToolkitCUDAv11.2 directory. I have python 3.8.5 installed and Tensorflow 2.4.1.
Is there another step I am missing? I am running tf.test.is_built_with_cuda() and getting True, while tf.test.is_gpu_available(cuda_only = False) returns false.
Thanks to smartphones you can now point, click, and share your way to superstardom. Smartphones have made creating—and consuming—digital photos and video on social media a pastime for billions. But the content those phones can create can’t compare to the quality of those made with a good camera. British entrepreneur Vishal Kumar’s startup Photogram wants Read article >
Spring. Rejuvenation. Everything’s blooming. And GeForce NOW adds even more games. Nature is amazing. For today’s GFN Thursday, we’re taking a look at all the exciting games coming to GeForce NOW in April. Starting with today’s launches: OUTRIDERS (day-and-date release on Epic Games Store and Steam) As mankind bleeds out in the trenches of Enoch, Read article >
This post is the eighth installment of the series of articles on the RAPIDS ecosystem. The series explores and discusses various aspects of RAPIDS that allow its users solve ETL (Extract, Transform, Load) problems, build ML (Machine Learning) and DL (Deep Learning) models, explore expansive graphs, process signal and system log, or use SQL language … Continued
This post is the eighth installment of the series of articles on the RAPIDS ecosystem. The series explores and discusses various aspects of RAPIDS that allow its users solve ETL (Extract, Transform, Load) problems, build ML (Machine Learning) and DL (Deep Learning) models, explore expansive graphs, process signal and system log, or use SQL language via BlazingSQL to process data.
You may or may not be aware that every bit of information your computer has received from a server miles away, every pixel your screen has shown, or every tune your speakers has produced was some form of a signal that was sent over a ‘wire’. That signal was most likely encoded by the sender end so it could carry the information and the receiver side decoded it for further usage.
Signals are abundant: audio, radio or other electromagnetic waves (like gamma, infrared or visible light), wireless communications, ocean wave, and so on. Some of these waves are man-made, many are produced naturally. Even images or stock market time series can be seen and processed as signals.
cuSignal is a newer addition to the RAPIDS ecosystem of libraries. It is aimed at analyzing and processing signals in any form and is modeled closely after the scikit-learn signal library. However, unlike scikit-learn, cuSignal brings the power of NVIDIA GPUs to signal processing resulting in orders-of-magnitude increase in speed of computations.
Previous posts showcased:
In the first post, python pandas tutorialwe introduced cuDF, the RAPIDS DataFrame framework for processing large amounts of data on an NVIDIA GPU.
In this post, we will introduce and showcase the most common functionality of RAPIDS cuSignal. As with the other libraries we already discussed, to help with getting familiar with cuSignal, we provide a cheat sheet that can be downloaded here: cuSignal cheatsheet, and an interactive notebook with all the current functionality of cuSignal showcased.
Frequency
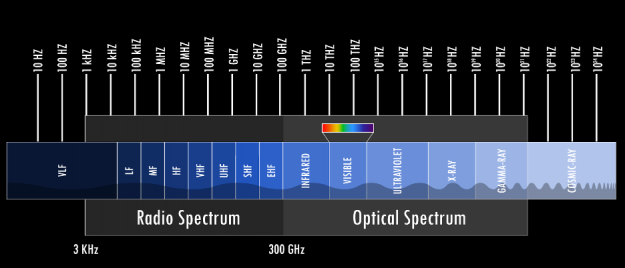
One of the most fundamental properties of signals is frequency. Hertz (abbreviated Hz) is a fundamental unit of frequency defined as a single cycle per second; it was named after Heindrich Rudolf Hertz who provided conclusive proof of the existence of electromagnetic waves. Any signal we detect or store is closely related to time: you could probably safely argue that any signal is a time series with ‘slightly’ different tools to analyze it.
The Alternating Current (AC) supplied to each home is an electric current that oscillates at either 50Hz or 60Hz, audio signals normally cover roughly the spectrum between 20Hz – 20,000Hz (or 20kHz), mobile bands cover some narrow bands in 850-900MHz, 1800Mhz (1.8GHz) and 1900MHz, Wifi signals oscillate at some predefined frequencies around either 2.4GHz or 5GHz. And these are but a few examples of signals that surround us. Ever heard of radio telescopes? The Wilkinson Microwave Anisotropy Probe is capable of scanning the night sky and detecting signals centered around 5 high-frequency bands: 23 GHz, 33 GHz, 41 GHz, 61 GHz, and 94 GHz, helping us to understand the beginnings of our universe. However, this is still just in the middle of the spectrum of electromagnetic waves.
In the early 20th century, almost all signals we dealt with were analog. Amplifying or recording speech or music was done on tapes and through fully analog signal paths using vacuum tubes, transistors, or, nowadays, operational amplifiers. However, the storage and reproduction of signals (music or else) have changed with the advent of Digital Signal Processing (or DSP). Still, remember CDs? Even if not, the music today is stored as a string of zeros and ones. However, when you play a song, the signal that drives the speaker is analog. In order to play an MP3, the signal needs to be converted from digital to analog and this can be achieved by passing it through the Digital-to-Analog converter (DAC): then the signal can be amplified and played through the speaker. The reverse process happens when you want to save the signal in a digital format: an analog signal is passed through an Analog-to-Digital converter (ADC) that digitizes the signal.
With the emergence of the high-speed Internet and 5th Generation mobile networks, signal analysis and processing has become a vital tool in many domains. cuSignal brings the processing power of NVIDIA GPUs into this domain to help with the current and emerging demands of the field.
Convolution
One of the most fundamental tools to analyze signals and extract meaningful information is convolution. Convolution is a mathematical operation that takes two signals and produces a third one, filtered. In the signal processing domain, convolution can be used to filter some frequencies from the spectrum of the signal to better isolate or detect some interesting properties. Just like in Convolutional Neural Networks, where the network learns different kernels to sharpen, blur or otherwise extract interesting features from an image to, for example, detect objects, the signal convolutions use different windows that help to refine the signal.
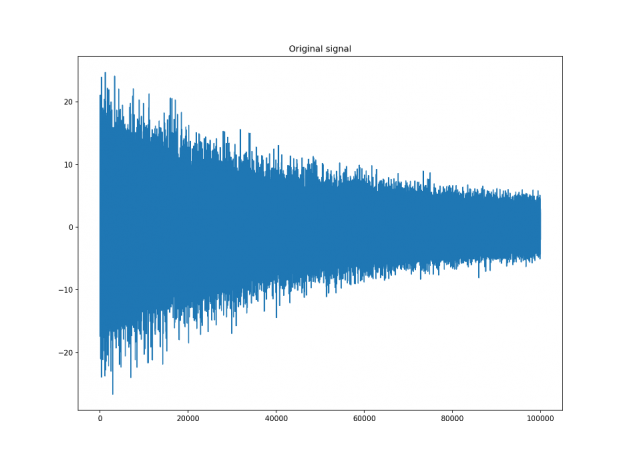
Let’s assume that we have a digital signal that looks as below.
Figure 2: Sample signal with an exponentially decaying noise component.
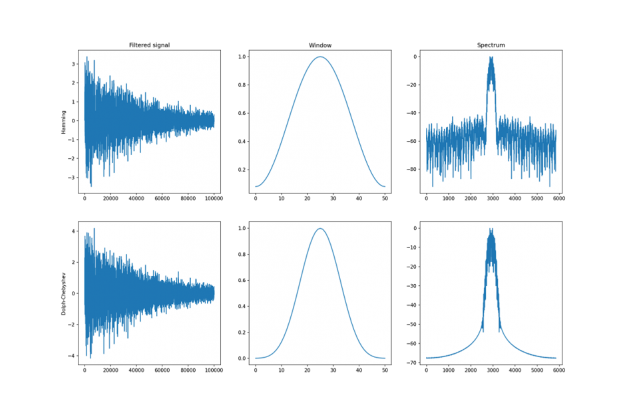
The signal above is a 2 Vrms (Root Mean Squared) a sine wave with its frequency slowly modulated around 3kHz, corrupted by the white noise of exponentially decreasing magnitude sampled at 10 kHz. To see the effect different windows would have on this signal, we will use Hamming and Dolph-Chebyshev windows.
Figure 3: Effects of applying Hamming and Dolph-Chebyshev windows on the original signal.
On the right, you can see the difference between the two windows. They are of similar shape but the Dolph-Chebyshev window is narrower and is effectively a more narrow band-pass filter compared to the Hamming window. Both of these methods can definitely help to find the fundamental frequency in the data.
For a full list of all the windows supported in cuSignal, refer to the cheat sheet you can download cuSignal cheatsheet, or try any of them in an interactive cuSignal notebookhere.
Spectral analysis
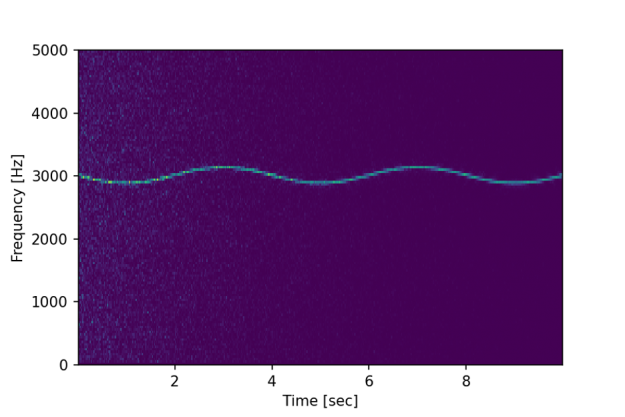
While filtering the signal using convolution might help to find the fundamental frequency of 3KHz, it does not show if (and how) that frequency might change over time. However, spectral analysis should allow us to do just that.
Figure 4: Spectrogram of slowly 3Hz signal with a compound 0.25Hz oscillation.
We can now clearly see not only the fundamental frequency of 3kHz is slowly, at 0.25Hz, modulated slightly over time, but we can also observe the initial influence of the white noise shown as lighter blue dots.
With the introduction of cuSignal, the RAPIDS ecosystem gained another great package with a vast array of signal processing tools that can be applied in many domains. You can try the above examples and more for yourself atapp.blazingsql.com, and download thecuSignal cheat sheethere!
Join speakers and panelists considered to be pioneers of AI, technologists, and creators who are re-imagining what is possible in higher education and research.
This year at GTC, you will join speakers and panelists considered to be pioneers of AI, technologists, and creators who are re-imagining what is possible in higher education and research.
By registering for this free event you’ll get access to these top sessions, and more:
NVIDIA’s Deep Learning Institute (DLI) University Ambassador Program facilitates free hands-on training in AI and accelerated computing in academia to solve real-world problems. The program provides educators the opportunity to get certified to teach instructor-led DLI workshops, at no cost, across campuses and academic conferences. DLI workshop topics span from the fundamentals of deep learning, accelerated computing, and accelerated data science to more advanced workshops on NLP, intelligent recommender systems, and health-care imaging analysis. Select courses offer a DLI certificate to demonstrate subject matter competency and support career growth. Join NVIDIA’s higher education leadership and Professor Manuel Ujaldon from the University of Malaga, Spain to learn more about the program and how to apply. Manuel will also discuss how he leverages the program for his students and how these resources have helped him improve the quality of online learning during the COVID-19 pandemic.
Joe Bungo, DLI Program Manager, NVIDIA Manuel Ujaldón, Professor, Computer Architecture Department, University of Malaga
This talk will give some highlights from NVIDIA Research over the past year. Topics will include high-performance optical signaling, deep learning accelerators, applying AI to video coding, and the latest in computer graphics.
Bill Dally, Chief Scientist and SVP Research, NVIDIA
Learn how a state-of-the-art model for time series classification was used for severe weather (tornadoes and severe hail thunderstorms) prediction using lightning data from the Geostationary Lightning Mapper (GLM) device aboard the NOAA GOES-16 satellite. These results are the outcome of NASA Frontier Development Lab (FDL) 2020: Lightning and Extreme Weather, and were accepted to oral presentations in two NeurIPS 2020 workshops and are currently submitted for publication. According to our tests, the GPU implementation of the convolutional time series approach was 27x faster than a CPU implementation. This dramatic gain in speed allowed rapid iteration to build more and better models. Find out how leveraged by NVIDIA V100 GPUs, our results suggest that, with a 15 minute lead time, false alarms for warned thunderstorms could be decreased by 70% and that tornadoes and large hail could be correctly identified approximately 3 out of 4 times using lightning data only.
Ivan Venzor, Data Science Deputy Director, Banregio
NVIDIA’s Jetson AI Ambassador will show you how to implement fundamental deep learning and robotics in high schools with Jetson Nano developer kit. If you’re interested in AI education, you’ll learn how to get the most from NVIDIA Jetson Nano developer kit and DLI courses. This AI curriculum includes deep learning fundamental concepts, Python programming skills, an image processing algorithm, and an integrated robotics project (Jetbot). Students can evaluate what they’ve learned and have an instant response on the robot’s behavior.
Get an introduction to NVIDIA’s Kaolin library for accelerating 3D deep learning research, as well as a demonstration of APIs for Kaolin’s GPU-optimized operations such as modular differentiable rendering, fast conversions between representations, data loading, 3D checkpoints, and more. In this session, we’ll also demonstrate using the Omniverse Kaolin application to visualize training datasets, generate new ones, and to observe the progress of ongoing training of models.
Jean-Francois Lafleche, Deep Learning Engineer, NVIDIA Clement Fuji Tsang, Research Scientist, NVIDIA
Visit the GTC website to view more recommended sessions and to register for the free conference.
Got a conflict with your 2pm appointment? Just spin up a quick assistant that takes good notes and when your boss asks about you even identifies itself and explains why you aren’t there. Nice fantasy? No, it’s one of many use cases a team of some 50 ninja programmers, AI experts and 20 beta testers Read article >

 Game and professional visualization developers need the best tools to create the best games and real-time interactive content. Read this article to find out what NVIDIA technologies will provide developers optimal real time ray tracing within their workflows.
Game and professional visualization developers need the best tools to create the best games and real-time interactive content. Read this article to find out what NVIDIA technologies will provide developers optimal real time ray tracing within their workflows. 
 This post is the eighth installment of the series of articles on the RAPIDS ecosystem. The series explores and discusses various aspects of RAPIDS that allow its users solve ETL (Extract, Transform, Load) problems, build ML (Machine Learning) and DL (Deep Learning) models, explore expansive graphs, process signal and system log, or use SQL language …
This post is the eighth installment of the series of articles on the RAPIDS ecosystem. The series explores and discusses various aspects of RAPIDS that allow its users solve ETL (Extract, Transform, Load) problems, build ML (Machine Learning) and DL (Deep Learning) models, explore expansive graphs, process signal and system log, or use SQL language … 
 Join speakers and panelists considered to be pioneers of AI, technologists, and creators who are re-imagining what is possible in higher education and research.
Join speakers and panelists considered to be pioneers of AI, technologists, and creators who are re-imagining what is possible in higher education and research. 



