Developers and users can capture and replay VR sessions for performance testing and scene troubleshooting with early access to NVIDIA Virtual Reality Capture and Replay.
Developers and users can capture and replay VR sessions for performance testing and scene troubleshooting with early access to NVIDIA Virtual Reality Capture and Replay.
Developers and early access users can now accurately capture and replay VR sessions for performance testing, scene troubleshooting, and more with NVIDIA Virtual Reality Capture and Replay (VCR.)
The potentials of virtual worlds are limitless, but working with VR content poses challenges, especially when it comes to recording or recreating a virtual experience. Unlike the real world, capturing an immersive scene isn’t as easy as taking a video on your phone or hitting the record button on your computer.
It’s impossible to repeat an identical experience in VR, and immersive demos are often jittery and difficult to watch due to excessive camera motion. Creating VR applications can also be cumbersome, as developers have to jump in and out of their headsets to code, test, and refine their work. Plus, all of these tasks require a 1:1 device connection, in order to launch and run a VR application.
All of this makes recording anything in VR an extremely time-consuming and tedious process.
“We often find ourselves spending more time getting the hardware ready and navigating to a location within VR than we actually do testing or troubleshooting an issue,” explains Lukas Faeth, Senior Product Manager at Autodesk. “The NVIDIA VCR SDK should help us test performance between builds without having to put someone in VR for hours at a time.”
“The NVIDIA VCR SDK seems at first promising and rather cool, and when I tried it out it left my head spinning! With a little creative thought, this tool can be very powerful. I am still trying to get my head around the myriad of ways I can use it in my day-to-day workflows. It has opened up quite a few use cases for me in terms of automatic testing, training potential VR users, and creating high-quality GI renders of an OpenGL VR session,” said Danny Tierney, Automotive Design Solution Specialist at Autodesk
Easier, faster VR video production
NVIDIA VCR started as an internal project for VR performance testing across NVIDIA GPUs. The NVIDIA XR team continued to expand the feature set as they recognized new use cases. The team is making it available to select partners to help evaluate, test, and identify additional applications for the project.
With NVIDIA VCR, developers and creators can more easily develop VR applications, assist end users with QA and troubleshooting, and generate quality VR videos.
NVIDIA VCR features include:
- Accurate and painless VR session playback. This is especially useful for performance testing and QC.
- Less time in a headset. With a reduced number of development steps users spend less time jumping in and out of VR.
- Multirole recordings from a single headset in the same VR scene using one HMD. Replay the recordings simultaneously to simulate collaboration.
Early partners like ESI Group imagine promising opportunities to leverage the SDK. “NVIDIA VCR opens up infinite possibilities for immersive experiences,” says Eric Kam, Solutions Marketing Manager at ESI Group.
“Recording and playback of virtuality add a temporal dimension to VR sessions,” Kam adds, pointing out that VCR could be developed to serve downstream workflows in addition to addressing challenges with performance testing.
Getting started with NVIDIA VCR
NVIDIA VCR records time-stamped HMD and controller inputs during an immersive VR session. Users can then replay the recording, without an HMD attached, to reproduce the session. It’s also possible to filter the recorded session through an optional processing step, cleaning up the data and removing excessive camera motion.
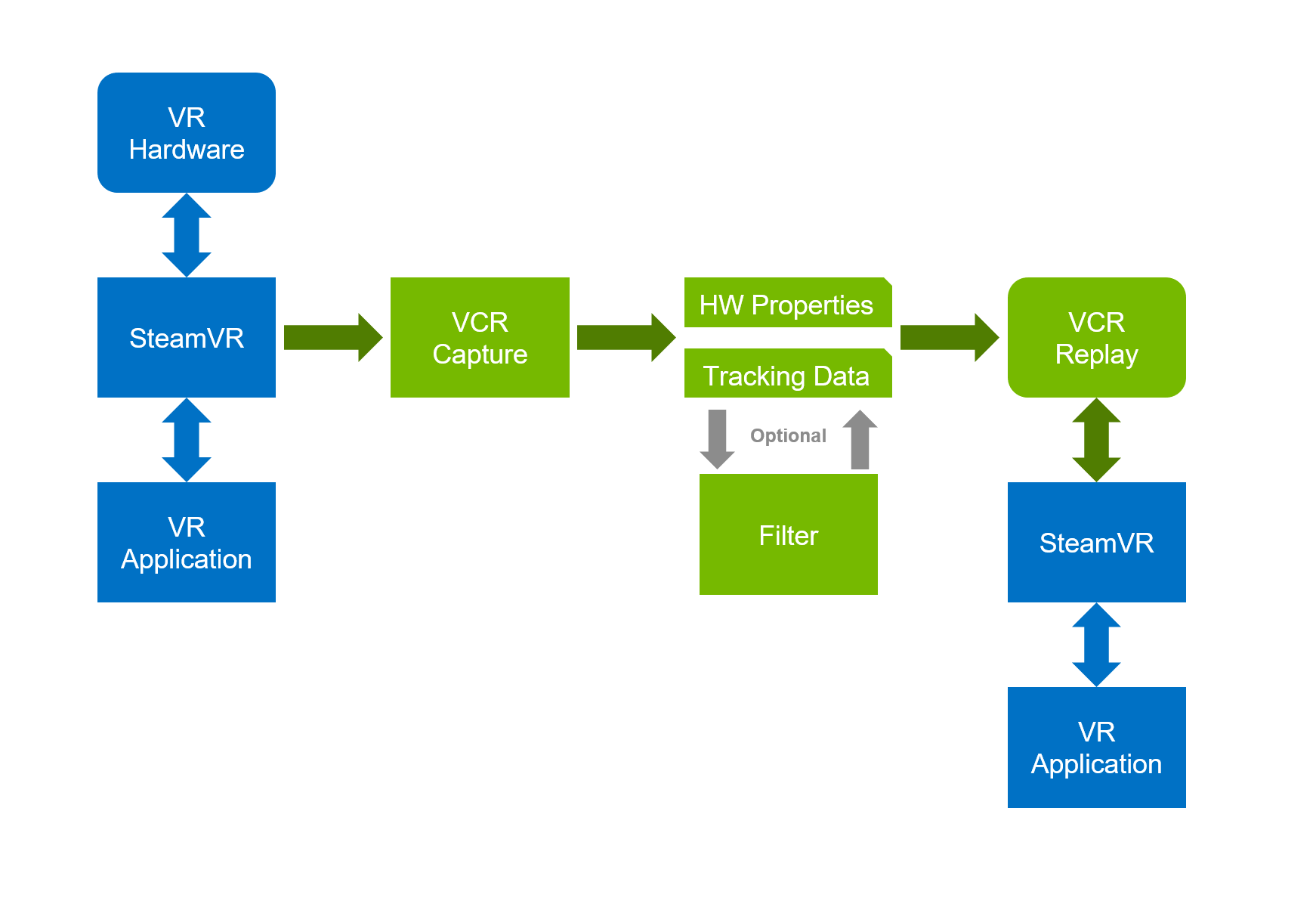
Components of NVIDIA VCR:
- Capture is an OpenVR background application that stores HMD and controller properties and logs motion and button presses into tracking data.
- Filter is an optional processing step to read and write recorded sessions. Using the VCR C++ API, developers can analyze a session, clean up data, or retime HMD motion paths.
- Replay uses an OpenVR driver to emulate an HMD and controllers, read tracking data, and replay motion and button presses in the scene. Hardware properties such as display resolution and refresh rate can be edited as a JSON file.
Four NVIDIA VCR Use Cases
- Use a simple capture and replay workflow to record tracking data and replay it an infinite number of times. This is ideal for verifying scene correctness, such as in performance testing or QC use cases.
- In a filtering workflow, apply motion data smoothing to minimize jitter and produce a more professional-looking VR demo video or tutorial.
- Repeat and mix segments captured in VCR to generate an entirely new sequence. In the video below, the same set of segments (the letters “H,” “o,” “l,” and “e” in addition to movement and interaction data) were reordered to spell a completely new word.
- Use NVIDIA VCR within the Autodesk VRED application to capture an example of single-user collaboration. In this workflow, one user generates four separate VCR captures with a single HMD system. These were then replayed simultaneously on multiple systems to simulate multiuser collaboration.
Apply to become an early access partner
NVIDIA VCR is available to a limited number of early access partners. If you have an innovative use case and are willing to provide feedback on VCR apply for early access.
 This GTC focused roundup features updates to the HPC SDK, cuQuantum SDK, Nsight Graphics and Systems 2022.2, CUDA 11.6, Update 1, cuNumeric, and Warp.
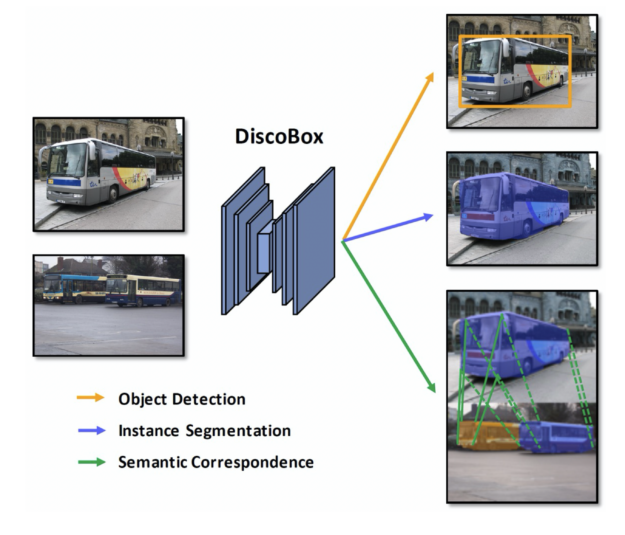
This GTC focused roundup features updates to the HPC SDK, cuQuantum SDK, Nsight Graphics and Systems 2022.2, CUDA 11.6, Update 1, cuNumeric, and Warp. Discobox is a weakly supervised learning algorithm to identify objects without costly mask annotations during training.
Discobox is a weakly supervised learning algorithm to identify objects without costly mask annotations during training.