The NVIDIA NGC catalog is a hub of highly performant software containers, pre-trained models, industry specific SDKs and Helm charts you can simplify and accelerate your end-to-end workflows.
The NVIDIA NGC catalog is a hub of GPU-optimized deep learning, machine learning and HPC applications. With highly performant software containers, pre-trained models, industry specific SDKs and Helm charts you can simplify and accelerate your end-to-end workflows.
The NVIDIA NGC team works closely with our internal and external partners to update the content in the catalog on a regular basis. Below are some of the highlights:
NVIDIA Maxine
NVIDIA Maxine is a GPU-accelerated SDK with state-of-the-art AI features for developers to build virtual collaboration and content creation solutions, including video conferencing and streaming applications. You can add any of Maxine’s AI effects – Video,Audio, and Augmented Reality – into your existing application or develop a new pipeline from scratch.
Maxine’s Video Effects SDK and Audio Effects SDK are now available through the Maxine collection on the NGC catalog that includes a container for each SDK:
Video Effects SDK container enables video quality enhancement such as super resolution, reducing compression artifacts and video degradation caused by low light conditions or lower-quality cameras.
Audio Effects SDK container removes reverberations due to talking in low sound absorption spaces and reduces over 25 different unwanted background noise profiles such as keyboard typing, mouse-clicking, and fan noise.
Clara Train SDK 4.0
Clara Train v4.0 is now powered by MONAI, a domain-specialized open-source PyTorch framework, accelerating deep learning in Healthcare imaging.
The latest version also expands into Digital Pathology and introduces homomorphic encryption for server side aggregation in federated learning.
Transfer Learning Toolkit (TLT)
The NVIDIA Transfer Learning Toolkit (TLT) is the AI toolkit that abstracts away the AI/DL framework complexity and leverages high quality pre-trained models to enable you to build production quality models faster with only a fraction of data required.
Version 3.0 of TLT is now available for computer vision and conversational AI use cases. Get started today by exploring the TLT collections for:
PyTorch Lightning, developed by Grid.AI, allows you to leverage multiple GPUs and state-of-the-art training features such as 16-bit precision, early stopping, logging, pruning and quantization, while enabling faster iteration and reproducibility for your AI research.
Vyasa’s suite of biomedical analytics allows users to derive insights from analytical modules including question answering, named entity recognition, PDF table extraction and image classification, irrespective of where that data resides.
The Game Developer Conference (GDC) is here, and NVIDIA will be showcasing how our latest technologies are driving the future of game development and graphics. Check out our list of sessions now.
The Game Developer Conference (GDC) is here, and NVIDIA will be showcasing how our latest technologies are driving the future of game development and graphics.
From NVIDIA Deep Learning Super Sampling (DLSS) to RTX Global Illumination (RTXGI), our latest tools and technologies are helping game developers create realistic and stunning virtual worlds for gamers. Attendees will also get an exclusive look at how NVIDIA Omniverse, the open platform for virtual collaboration and simulation, is helping developers accelerate production workflows.
Get an inside look at all the collaboration tools available in Omniverse. Explore the platform’s ability to connect popular tools and applications, including Epic Games’ Unreal Engine 4, Autodesk Maya and 3ds Max, and Substance by Adobe.
Learn more about the NVIDIA RTX Unreal Engine Branch (NvRTX), and discover technologies such as RTXDI, RTXGI, new denoisers like Relax, ray-traced volumetrics and tools like the BVH viewer. See demonstrations on how complex settings like a jungle or museum can be built with NvRTX, and get a better understanding of how AAA real-time ray tracing visuals are created.
This session will cover the technology that makes DLSS possible. Learn how to integrate DLSS into a new game engine. Graphic programmers, technical artists and technical directors are encouraged to join this session so they can learn more about the engine requirements for DLSS and pick up general DLSS debugging tools.
Game developers can dive into the NvRTX family of branches, and learn how to bring enhanced ray tracing support to Unreal Engine 4. This session will cover several challenges developers can encounter when working to deploy ray tracing in a game environment. Join us and explore how NVIDIA has crafted solutions for these challenges within the context of a curated branch of UE4.
Students, technical artists, programmers and developers can experience ray tracing at interactive framerates with DXR and Vulkan Ray Tracing. Join this session to check out some of the available tools and features that developers can use to take advantage of NVIDIA GPUs and improve the graphics in games.
Enter for a Chance to Win Some Gems
Attendees can win a limited-edition hard copy ofRay Tracing Gems II, the follow up to 2019’s Ray Tracing Gems.
Ray Tracing Gems II brings the community of rendering experts back together to share their knowledge. The book covers everything in ray tracing and rendering, from basic concepts geared toward beginners to full ray tracing deployment in shipping AAA games.
Wake up, wake up, wake up, it’s the first of the month. This first of the month is a GFN Thursday celebration. The Steam Summer Sale now has over 700 PC games on sale that are playable on GeForce NOW. And since it’s also the first GFN Thursday of the month, it’s time to check Read article >
After pulling the Tensorflow object detection api image and run the container, I then try to run the api package test but I keeps failing and returning this error message “Traceback (most recent call last): File “objectdetection/builders/model_builder_tf2_test.py”, line 21, in <module> import tensorflow.compat.v1 as tf File “/home/tensorflow/.local/lib/python3.6/site-packages/tensorflow/init_.py”, line 444, in <module> _ll.load_library(_main_dir) File “/home/tensorflow/.local/lib/python3.6/site-packages/tensorflow/python/framework/load_library.py”, line 154, in load_library py_tf.TF_LoadLibrary(lib) tensorflow.python.framework.errors_impl.NotFoundError: /usr/local/lib/python3.6/dist-packages/tensorflow/core/kernels/libtfkernel_sobol_op.so: undefined symbol: _ZN10tensorflow8OpKernel11TraceStringEPNS_15OpKernelContextEb”
Recommendation systems must constantly evolve through the digestion of new data or algorithmic improvements of the model for its recommendations to stay effective and relevant. In this post, we focus on how NVIDIA Merlin components fit into a complete MLOps pipeline to operationalize a recommendation system, and continuously deliver improvements in production
Recommender systems are a critical resource for enterprises that are relentlessly striving to improve customer engagement. They work by suggesting potentially relevant products and services amongst an overwhelmingly large and ever-increasing number of offerings. NVIDIA Merlin is an application framework that accelerates all phases of recommender system development on NVIDIA GPUs, from experimentation (data processing, data loading, and model training) to production deployment either on-premises or in-cloud.
The term recommender systems implies that they are not just a mere model but an entire pipeline. It is important that all pieces work together like a well-oiled machine. More importantly, these are dynamic systems that need to constantly evolve and adapt (through digestion of new data or algorithmic improvement of the model). The ability to quickly and continuously integrate and deliver these improvements into production is critical for the recommendation system to stay effective.
According to Google Cloud, MLOps is an ML engineering culture and practice that aims at unifying ML system development (Dev) and ML system operation (Ops). MLOps takes both its name as well as some of the core principles and tooling from DevOps. This makes sense as the goals of MLOps and DevOps are practically the same: to reduce the time and effort required to develop, deploy, and maintain high-quality ML software in production.
In this post, we focus on how Merlin components fit into a complete MLOps pipeline and demonstrate with a hands-on example deployed with KubeFlow Pipelines on Google Kubernetes Engine (GKE). When we use the term Merlin MLOps in this post, we mean the act of operationalizing Merlin with MLOps tools and practices.
Reference architecture: MLOps for Merlin
Here’s a quick review of the Merlin components, as well as different levels of MLOps. The Merlin application framework supports all phases of recommender system development on the GPUs.
Data preprocessing and feature engineering: Merlin NVTabular is a high-performance library designed for processing terabyte-scale tabular datasets. It scales seamlessly from single to multi-GPU systems.
Model training: Merlin HugeCTR is a recommender system framework for training state-of-the-art deep learning recommendation models such as DLRM, Wide and Deep, Deep Cross Network (DCN), and so on. It scales seamlessly on multiple GPUs and multi-GPU nodes.
Production inference: The NVIDIA Triton Inference Server coupled with a HugeCTR inference backend provides a robust high-throughput and low-latency production environment. NVIDIA Triton can be deployed either on-premises or in-cloud, and it is fully compatible with the Kubernetes ecosystem.
Given the capabilities of Merlin, we now review the three levels of MLOps according to Google Cloud’s definition:
Level 0: Manual process and pipeline.
Level 1: Pipeline with some automation, such as monitoring and triggers, automated retraining, and redeployment of ML models (continuous retraining).
Level 2: Fully automated pipeline with continuous integration and delivery (CI/CD).
Figure 1. A high-level overview of Merlin MLOps.
Figure 1 shows a Level 1 Merlin MLOps workflow, with a fully automated pipeline and continuous retraining. Look deeper into this architecture:
Data pipeline: Every recommender system starts with data about users, items, and their interactions. Data is collected and stored in a data lake. From the data lake, a subset of data (based on time range and number of features) is extracted and prepared for model training (preprocessing, feature engineering). A data validation module ensures that the test data is as expected while also detecting data drift.
Continuous re-training: At first, the recommendation model is trained on a large amount of available data and deployed. Continuous incremental retraining ensures that the model stays up-to-date and captures the latest trends and user preferences. A model validation module ensures that the model meets a specified quality threshold.
Deployment and serving: An automated redeployment pipeline puts the new qualified model into production in a seamless manner. The number of GPU inference servers automatically scales up and down as needed.
Logging and monitoring: Monitoring modules continuously monitor the quality of the recommendation in real-time through a range of KPIs, such as hit rate and conversion rate. The modules trigger full retraining should model drift happen, that is, if certain KPIs fall below known established baselines.
Merlin MLOps with Kubeflow Pipelines on Google Kubernetes Engine
In this section, we walk through a concrete example of realizing the workflow with Kubeflow pipelines and GKE.
GKE provides a managed environment for deploying, managing, and scaling containerized applications using Google Cloud infrastructure. Kubeflow Pipelines is a platform for building and deploying portable, scalable machine learning (ML) workflows based on Docker containers. With an existing GKE cluster, Kubeflow pipelines can be installed easily with a push of a button. We selected Kubeflow Pipelines as the orchestrator that wields together the components of a Merlin MLOps pipeline.
In the Kubernetes world, applications are containerized. Merlin Docker containers are available on NGC, including the Merlin training and inference containers. These containers can be pulled, and then pushed to Google Cloud Container Registry, ready to be used with GKE.
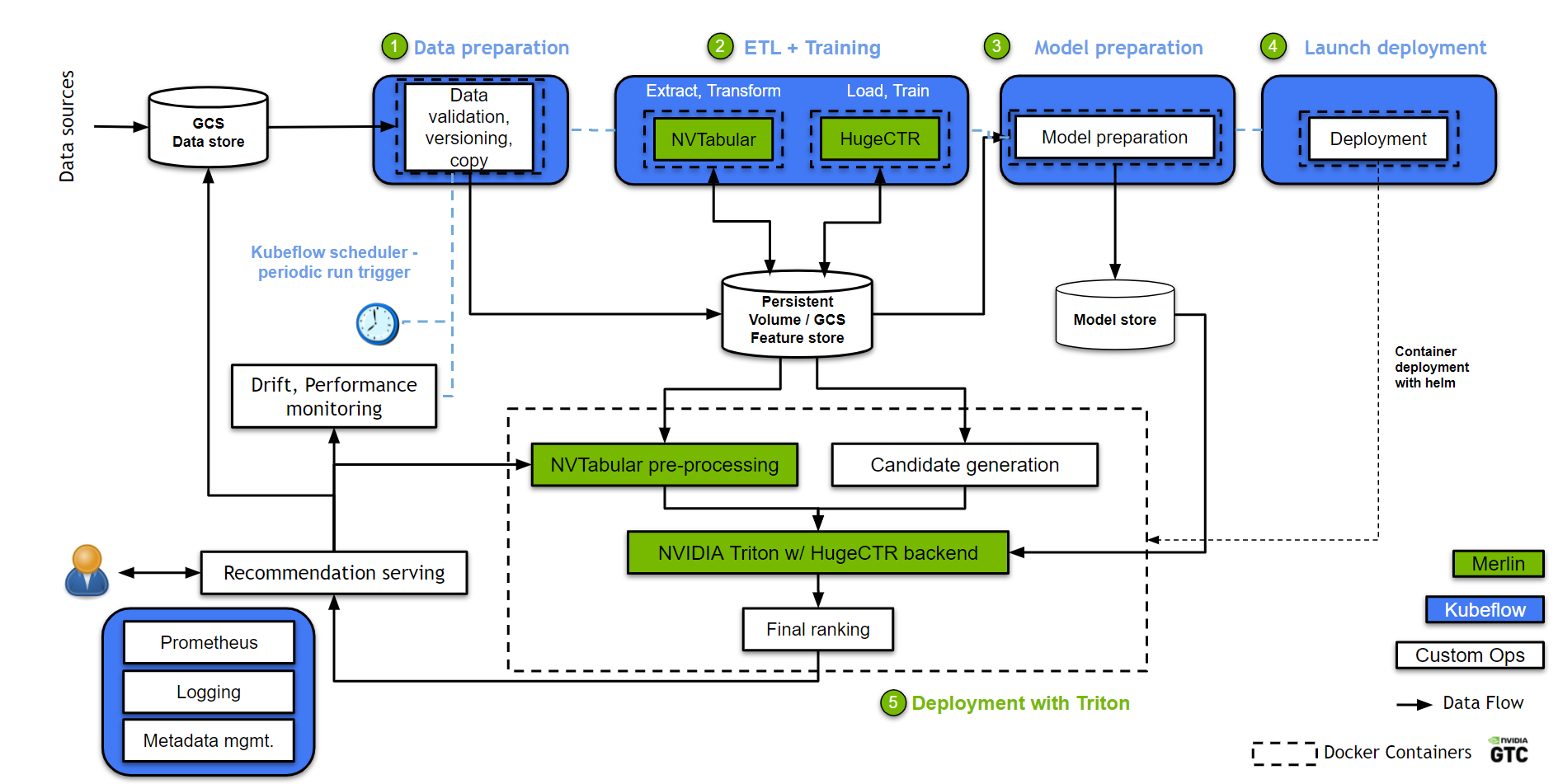
Figure 2. Merlin Kubeflow pipelines architecture on GCP and GKE.
In Figure 2, we mapped the conceptual workflow components in Figure 1 to concrete GCP and GKE components:
Data pipeline: Data is collected and stored in a data store, which in this case is a Google Cloud Storage (GCS) bucket. A data extraction module extracts and copies the relevant data to a high-speed active working space. In this example, it is a GKE-persistent volume for preprocessing and model training. A data validation module based on TensorFlow Data Validation analyzes the training data to detect data drift.
Continuous re-training: A Merlin training pod is used for data preprocessing and model training.
NVTabular is responsible for data preprocessing, feature engineering, and persisting the preprocessed dataset into the pipeline-shared persistent volume.
Next, HugeCTR picks up the preprocessed data and trains a DCN model. The model can be updated either using incremental data or trained from scratch using all or a large amount of available data.
Deployment and serving: The deployment module prepares the HugeCTR trained model for production. Prepared models are then stored in a model store in GCS. Depending on the application domains, model serving can involve two steps:
Candidate generation reduces the number of candidates from a space potentially as large as millions of items to a computationally manageable amount, for example, thousands of items.
The Merlin inference pod picks up and serves the latest HugeCTR trained model from the model store. This inference container contains the Triton Inference Server with a HugeCTR inference backend. The model re-ranks the generated candidates and serves the top scoring ones.
Logging and monitoring: The monitoring pod continuously monitors the quality of the recommendation in real-time (hit rate, conversion rate) and automatically triggers full retraining upon detecting significant model drift. NVIDIA Triton and the monitoring module log statistics into Prometheus and Grafana.
Criteo Terabyte click log dataset case study
In this example, we demonstrate the Merlin MLOps pipeline on Kubeflow pipelines and GKE using the Criteo Terabyte click log dataset, which is one of the largest public datasets in the recommendation domain. It contains ~1.3 TB of uncompressed click logs containing over four billion samples spanning 24 days, and can be used to train recommender system models that predict the ad clickthrough rate. Features are anonymized and categorical values are hashed to ensure privacy. Each record in this dataset contains 40 values:
A label indicating a click (value 1) or no click (value 0)
13 values for numerical features
26 values for categorical features
Because this data set contains only interaction data and no data on users, items, and their attributes, we skipped the candidate generation and final ranking parts and only implemented the deep learning scoring model to predict whether users will click on the ad.
Technical highlights
In this section, we discuss some of the major highlights pertaining to our implementation.
Multi-instance GPU on GKE
To maximize GPU usage, NVIDIA Triton is deployed on a GKE A100 MIG instance. NVIDIA Multi-instance GPU (MIG) technology partitions a single NVIDIA A100 GPU into as many as seven independent GPU instances. They run simultaneously, each with its own memory, cache, and streaming multiprocessors. That enables the A100 GPU to deliver guaranteed quality-of-service (QoS) at up to 7x higher utilization compared to prior GPUs. Small recommendation models that fit into the memory of a MIG instance can be deployed onto a GKE MIG instance of the appropriate size. That being said, we are working on relaxing this memory requirement through embedding table caching. Stay tuned!
GPU autoscaling
NVIDIA Triton deployment can be scaled using default metrics like CPU/GPU utilization, memory usage, and so on, and also using custom metrics. For this example, we use a custom metric exported to the Prometheus operator based on the average time spent by the incoming request in the inference queue. If the inference load on NVIDIA Triton increases, then the time spent by the incoming requests in the inference queue goes up as well.
To balance the increase in load, the Horizontal Pod Autoscaler (HPA) can schedule another NVIDIA Triton Pod on freely available GPU nodes. If no nodes are available in the GPU node pool, then the HPA kicks in the GKE node autoscaler that assigns a new GPU node to the GPU node pool. After a new node is available in the cluster, the Kubernetes Pod scheduler schedules a new instance of the NVIDIA Triton Pod on that GPU node. The load balancer can then route the pending incoming requests in the queue to the newly created NVIDIA Triton Pod. Subsequently, if the load decreases, the autoscaler can scale down the nodes.
Sending inference requests
An end user interacts with the inference server indirectly through a client application or recommendation API, which translates user requests and responses to inference requests. To this end, we include a test inference client app that can be used to read Criteo .parquet files and send inference gRPC requests to the NVIDIA Triton endpoint.
Monitoring
In an ML system, the relationship between the independent and the target variables can change over time. As a result, the model predictions can gradually become erroneous. In this example pipeline, we have a monitoring module that is tasked with tracking the performance (in this case, AUC score) and triggering another run of the pipeline if AUC drifts below a certain threshold. The monitoring module runs as a separate pod in the GKE cluster.
How does it get access to the request data? In the reference design, the test inference client is responsible for logging the inference requests using Cloud Pub/Sub, where the inference client publishes the requests and corresponding inference results to the Pub/Sub broker, and the monitoring module subscribes to it. Using this asynchronous mechanism, monitoring can assess the performance and take appropriate action like triggering the Kubeflow pipeline for retraining if required. It also writes these requests periodically to a volume, which a daemon job pushes to the GCS bucket for use in the next round of continuous training. This data collection closes the loop in the system, and allows the new incoming requests as fresh data that the pipeline can use for incremental training from the previous checkpoint.
Scope for improvement
The high-level goal of this post was to show an example of a recommender system, built using Merlin components, running in the form of a Kubeflow pipeline. There are several pieces of this example that could be designed in an alternative way or further improved. For instance:
Cloud Pub/Sub is used for communicating request data from the inference client to the monitoring module. This gives you high scalability, reliability, and advantages of asynchronous behavior. However, this does add an additional dependency on GCP infrastructure. Alternatively, you could use other message queues, like Kafka.
Data drift could be monitored live, especially in cases where there is no user feedback for served recommendations to estimate model performance. You could plug in a solution similar to the data validation component in monitoring. Additionally, you should first filter outliers out from out-of-distribution samples.
The data validation component using TensorFlow Data Validation is a simple example showing where such a component could be plugged into the pipeline. There could be other appropriate actions on detecting drift, like notifications to users or taking corrective measures other than logging. There may be other libraries more suitable to your use case, like Great Expectations or Alibi Detect.
Conclusion
This example with Merlin components on a Kubeflow pipeline follows the reference architecture as described earlier. Most ML systems would follow a similar architecture, with components for data acquisition and cleaning, preprocessing, training, model serving, monitoring, and so on. As such, these blocks could be replaced with custom containers and code in the pipeline. Any additional modules could be either added to the pipeline itself (like data validation and training), or deployed as a separate pod in the cluster (like inference, and monitoring). This Merlin MLOps example serves as a reference on how you can create, compile, and run your pipelines.
The code and step-by-step instructions to run this Merlin MLOps example are available at the NVIDIA-Merlin/gcp-ml-ops GitHub repo. We’d love to hear about how this project relates to what you’re working on, especially if you have any questions or feedback! You can reach us through the repo or by leaving a comment here.
Can anyone help me fix the error OSError: SavedModel file does not exist at: /mnt/Archive/Google_T5/11B/{saved_model.pbtxt|saved_model.pb} in this code:
import tensorflow.compat.v1 as tf import tensorflow_text as tf_text tf.reset_default_graph() sess = tf.Session() meta_graph_def = tf.saved_model.loader.load(sess, ["serve"], "/mnt/Archive/Google_T5/11B") signature_def = meta_graph_def.signature_def["serving_default"]
Hey, I’m using python 3.9.4 on Windows 10 and am trying to run an ML program in VScode, but despite all of the available resources I just can’t seem to get my GPU to run the program
When I run the following code:
import tensorflow as tf from tensorflow import keras print("Num GPUs Available: ", len(tf.config.experimental.list_physical_devices('GPU')))
It says:
Num GPUs Available: 0
Cannot dlopen some GPU libraries. Please make sure the missing libraries mentioned above are installed properly if you would like to use
So I checked the site and added the necessary Cuda folders to the environment path and still no luck. If someone could give some guidance as to how they achieved this I’d be grateful
For the uninitiated, Cornhole is a lawn game popular in the United States where players take turns using their aim and motor skills to throw bags of corn kernels at a raised platform which has a hole on the far side. Dave’s setup pairs the Jetson with a Kuka KR20 robot (fondly called ‘Susan’). A 1080p webcam serves as the eyes of Susan and a 2020 extrusion bar mimics the throwing arm of a player. The platform’s hole is colored red to make it easier for Susan to spot it from the background.
For the software, Dave used several OpenCV functions such as inRange to pick out the red hole from the scene, and findContours to establish the ring around the hole. Using the relative positions of the camera and the center of the hole, the angle and power for the throw are calculated on Jetson. Lastly, Jetson communicates these calculations to Susan through the network via the KUKA.ethernetKRL software package.
In the demo video, Dave mentions that he enjoyed working on Jetson and added,“This [Jetson AGX Xavier] is an awesome computer — think of it like if a video card had a baby with a Raspberry Pi. It has a lot of parallel compute on it, so you can do neural networks, deep learning, machine vision, but it doesn’t actually draw all that much power and with a little mount, you can strap it directly onto Susan.”
This project demonstrates how Jetson AGX Xavier could be used as an intelligent robot controller and can be paired with robot arms for industrial applications. Summer is here in North America and we’ll take some inspiration from Susan for our next cornhole game.
If you’re interested in learning more about the winning duo of Susan and Jetson, check out Dave’s code on GitHub.
All roads to the future of autonomous, electric and connected transportation run through one key innovation: software-defined, centralized computing. Today at Volvo Cars’ Tech Moment event, Ali Kani, NVIDIA vice president and general manager of Automotive, joined executives from Volvo Cars to outline the centralized compute architecture that will power these software-defined vehicles. This architecture, Read article >
NVIDIA’s partners are delivering GPU-accelerated systems that train AI models faster than anyone on the planet, according to the latest MLPerf results released today. Seven companies put at least a dozen commercially available systems, the majority NVIDIA-Certified, to the test in the industry benchmarks. Dell, Fujitsu, GIGABYTE, Inspur, Lenovo, Nettrix and Supermicro joined NVIDIA to Read article >

 The NVIDIA NGC catalog is a hub of highly performant software containers, pre-trained models, industry specific SDKs and Helm charts you can simplify and accelerate your end-to-end workflows.
The NVIDIA NGC catalog is a hub of highly performant software containers, pre-trained models, industry specific SDKs and Helm charts you can simplify and accelerate your end-to-end workflows.  The Game Developer Conference (GDC) is here, and NVIDIA will be showcasing how our latest technologies are driving the future of game development and graphics. Check out our list of sessions now.
The Game Developer Conference (GDC) is here, and NVIDIA will be showcasing how our latest technologies are driving the future of game development and graphics. Check out our list of sessions now. 
 Recommendation systems must constantly evolve through the digestion of new data or algorithmic improvements of the model for its recommendations to stay effective and relevant. In this post, we focus on how NVIDIA Merlin components fit into a complete MLOps pipeline to operationalize a recommendation system, and continuously deliver improvements in production
Recommendation systems must constantly evolve through the digestion of new data or algorithmic improvements of the model for its recommendations to stay effective and relevant. In this post, we focus on how NVIDIA Merlin components fit into a complete MLOps pipeline to operationalize a recommendation system, and continuously deliver improvements in production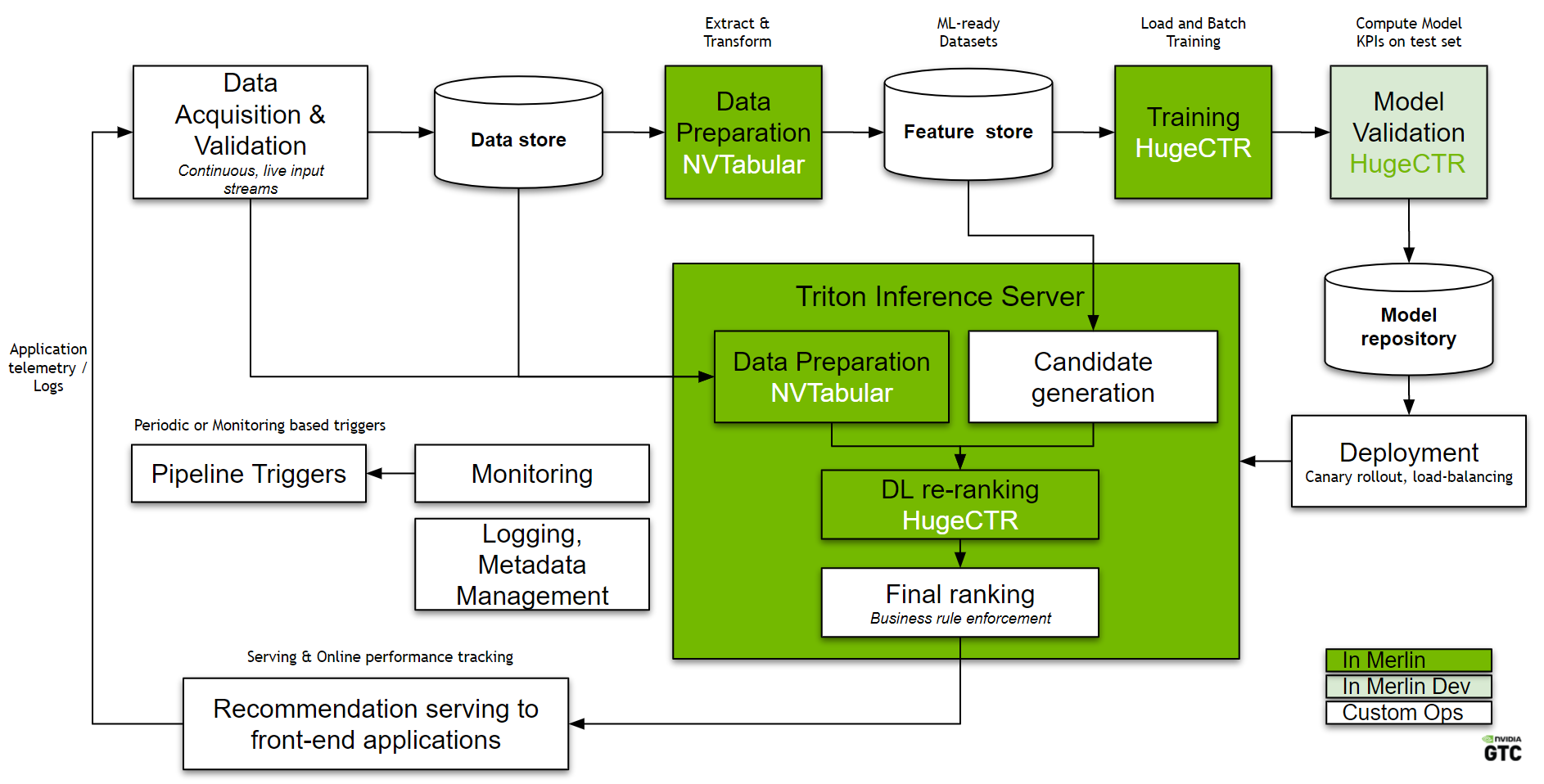

 David Niewinski of Dave’s Armoury won the ‘Jetson Project of the Month’ for building a robot arm capable of playing a perfect game of cornhole.
David Niewinski of Dave’s Armoury won the ‘Jetson Project of the Month’ for building a robot arm capable of playing a perfect game of cornhole.