
Thanks to smartphones you can now point, click, and share your way to superstardom. Smartphones have made creating—and consuming—digital photos and video on social media a pastime for billions. But the content those phones can create can’t compare to the quality of those made with a good camera. British entrepreneur Vishal Kumar’s startup Photogram wants Read article >
The post All for the ‘Gram: The Next Big Thing on Social Media Could Be a Smarter Camera appeared first on The Official NVIDIA Blog.
Spring. Rejuvenation. Everything’s blooming. And GeForce NOW adds even more games. Nature is amazing. For today’s GFN Thursday, we’re taking a look at all the exciting games coming to GeForce NOW in April. Starting with today’s launches: OUTRIDERS (day-and-date release on Epic Games Store and Steam) As mankind bleeds out in the trenches of Enoch, Read article >
The post GFN Thursday: All My Friends Know the Outriders appeared first on The Official NVIDIA Blog.
 This post is the eighth installment of the series of articles on the RAPIDS ecosystem. The series explores and discusses various aspects of RAPIDS that allow its users solve ETL (Extract, Transform, Load) problems, build ML (Machine Learning) and DL (Deep Learning) models, explore expansive graphs, process signal and system log, or use SQL language … Continued
This post is the eighth installment of the series of articles on the RAPIDS ecosystem. The series explores and discusses various aspects of RAPIDS that allow its users solve ETL (Extract, Transform, Load) problems, build ML (Machine Learning) and DL (Deep Learning) models, explore expansive graphs, process signal and system log, or use SQL language … Continued
This post is the eighth installment of the series of articles on the RAPIDS ecosystem. The series explores and discusses various aspects of RAPIDS that allow its users solve ETL (Extract, Transform, Load) problems, build ML (Machine Learning) and DL (Deep Learning) models, explore expansive graphs, process signal and system log, or use SQL language via BlazingSQL to process data.
You may or may not be aware that every bit of information your computer has received from a server miles away, every pixel your screen has shown, or every tune your speakers has produced was some form of a signal that was sent over a ‘wire’. That signal was most likely encoded by the sender end so it could carry the information and the receiver side decoded it for further usage.

Signals are abundant: audio, radio or other electromagnetic waves (like gamma, infrared or visible light), wireless communications, ocean wave, and so on. Some of these waves are man-made, many are produced naturally. Even images or stock market time series can be seen and processed as signals.
cuSignal is a newer addition to the RAPIDS ecosystem of libraries. It is aimed at analyzing and processing signals in any form and is modeled closely after the scikit-learn signal library. However, unlike scikit-learn, cuSignal brings the power of NVIDIA GPUs to signal processing resulting in orders-of-magnitude increase in speed of computations.
Previous posts showcased:
- In the first post, python pandas tutorial we introduced cuDF, the RAPIDS DataFrame framework for processing large amounts of data on an NVIDIA GPU.
- The second post compared similarities between cuDF DataFrame and pandas DataFrame.
- In the third post, querying data using SQL we introduced BlazingSQL, a SQL engine that runs on GPU.
- In the fourth post, data processing with Dask we introduced a Python distributed framework that helps to run distributed workloads on GPUs.
- In the fifth post, the functionality of cuML, we introduced the Machine Learning library of RAPIDS.
- In the sixth post, the use of RAPIDS cuGraph, we introduced a GPU framework for processing and analyzing cyber logs.
- In the seventh post, the functionality of cuStreamz, we introduced how GPUs can be used to process streaming data.
In this post, we will introduce and showcase the most common functionality of RAPIDS cuSignal. As with the other libraries we already discussed, to help with getting familiar with cuSignal, we provide a cheat sheet that can be downloaded here: cuSignal cheatsheet, and an interactive notebook with all the current functionality of cuSignal showcased.
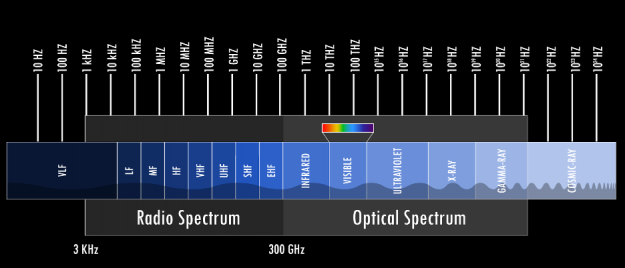
Frequency
One of the most fundamental properties of signals is frequency. Hertz (abbreviated Hz) is a fundamental unit of frequency defined as a single cycle per second; it was named after Heindrich Rudolf Hertz who provided conclusive proof of the existence of electromagnetic waves. Any signal we detect or store is closely related to time: you could probably safely argue that any signal is a time series with ‘slightly’ different tools to analyze it.
The Alternating Current (AC) supplied to each home is an electric current that oscillates at either 50Hz or 60Hz, audio signals normally cover roughly the spectrum between 20Hz – 20,000Hz (or 20kHz), mobile bands cover some narrow bands in 850-900MHz, 1800Mhz (1.8GHz) and 1900MHz, Wifi signals oscillate at some predefined frequencies around either 2.4GHz or 5GHz. And these are but a few examples of signals that surround us. Ever heard of radio telescopes? The Wilkinson Microwave Anisotropy Probe is capable of scanning the night sky and detecting signals centered around 5 high-frequency bands: 23 GHz, 33 GHz, 41 GHz, 61 GHz, and 94 GHz, helping us to understand the beginnings of our universe. However, this is still just in the middle of the spectrum of electromagnetic waves.
Digital or analog
In the early 20th century, almost all signals we dealt with were analog. Amplifying or recording speech or music was done on tapes and through fully analog signal paths using vacuum tubes, transistors, or, nowadays, operational amplifiers. However, the storage and reproduction of signals (music or else) have changed with the advent of Digital Signal Processing (or DSP). Still, remember CDs? Even if not, the music today is stored as a string of zeros and ones. However, when you play a song, the signal that drives the speaker is analog. In order to play an MP3, the signal needs to be converted from digital to analog and this can be achieved by passing it through the Digital-to-Analog converter (DAC): then the signal can be amplified and played through the speaker. The reverse process happens when you want to save the signal in a digital format: an analog signal is passed through an Analog-to-Digital converter (ADC) that digitizes the signal.
With the emergence of the high-speed Internet and 5th Generation mobile networks, signal analysis and processing has become a vital tool in many domains. cuSignal brings the processing power of NVIDIA GPUs into this domain to help with the current and emerging demands of the field.
Convolution
One of the most fundamental tools to analyze signals and extract meaningful information is convolution. Convolution is a mathematical operation that takes two signals and produces a third one, filtered. In the signal processing domain, convolution can be used to filter some frequencies from the spectrum of the signal to better isolate or detect some interesting properties. Just like in Convolutional Neural Networks, where the network learns different kernels to sharpen, blur or otherwise extract interesting features from an image to, for example, detect objects, the signal convolutions use different windows that help to refine the signal.
Let’s assume that we have a digital signal that looks as below.
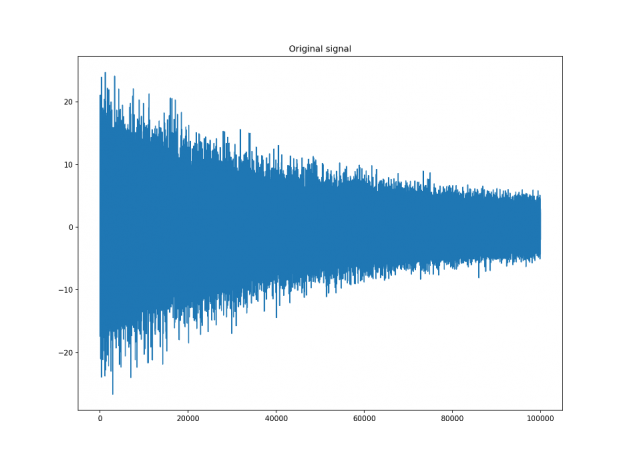
The signal above is a 2 Vrms (Root Mean Squared) a sine wave with its frequency slowly modulated around 3kHz, corrupted by the white noise of exponentially decreasing magnitude sampled at 10 kHz. To see the effect different windows would have on this signal, we will use Hamming and Dolph-Chebyshev windows.
window_hamming = cusignal.hamming(51) window_chebwin = cusignal.chebwin(51, at=100) filtered_hamming = cusignal.convolve( data , window_hamming , method='direct' ) / cp.sum(window_hamming) filtered_chebwin = cusignal.convolve( data , window_chebwin , method='direct' ) / cp.sum(window_chebwin)
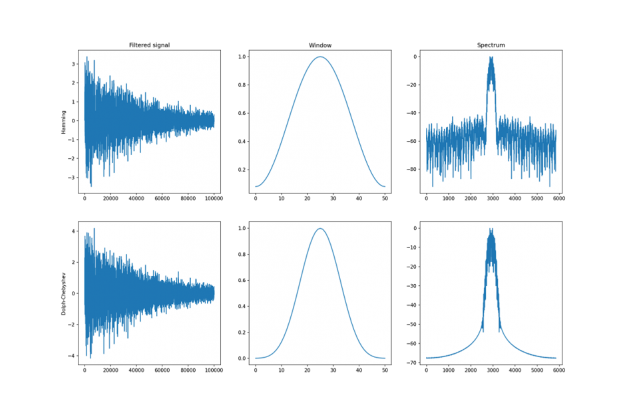
On the right, you can see the difference between the two windows. They are of similar shape but the Dolph-Chebyshev window is narrower and is effectively a more narrow band-pass filter compared to the Hamming window. Both of these methods can definitely help to find the fundamental frequency in the data.
For a full list of all the windows supported in cuSignal, refer to the cheat sheet you can download cuSignal cheatsheet, or try any of them in an interactive cuSignal notebook here.
Spectral analysis
While filtering the signal using convolution might help to find the fundamental frequency of 3KHz, it does not show if (and how) that frequency might change over time. However, spectral analysis should allow us to do just that.
f, t, Sxx = cusignal.spectrogram(x, fs)
plt.pcolormesh(
cp.asnumpy(t),
cp.asnumpy(f),
cp.asnumpy(Sxx)
)
plt.ylabel('Frequency [Hz]') plt.xlabel('Time [sec]')The above code produces the following chart:
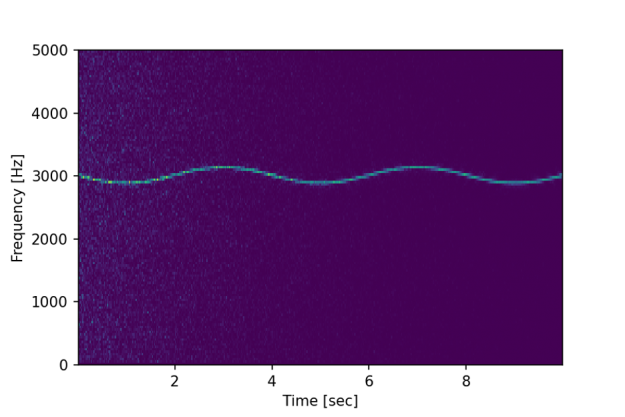
We can now clearly see not only the fundamental frequency of 3kHz is slowly, at 0.25Hz, modulated slightly over time, but we can also observe the initial influence of the white noise shown as lighter blue dots.
With the introduction of cuSignal, the RAPIDS ecosystem gained another great package with a vast array of signal processing tools that can be applied in many domains. You can try the above examples and more for yourself at app.blazingsql.com, and download the cuSignal cheat sheet here!
 Join speakers and panelists considered to be pioneers of AI, technologists, and creators who are re-imagining what is possible in higher education and research.
Join speakers and panelists considered to be pioneers of AI, technologists, and creators who are re-imagining what is possible in higher education and research.
This year at GTC, you will join speakers and panelists considered to be pioneers of AI, technologists, and creators who are re-imagining what is possible in higher education and research.
By registering for this free event you’ll get access to these top sessions, and more:

- The DLI University Ambassador Program: Preparing Today’s Students and Researchers for Tomorrow’s AI and Accelerated Computing Challenges
NVIDIA’s Deep Learning Institute (DLI) University Ambassador Program facilitates free hands-on training in AI and accelerated computing in academia to solve real-world problems. The program provides educators the opportunity to get certified to teach instructor-led DLI workshops, at no cost, across campuses and academic conferences. DLI workshop topics span from the fundamentals of deep learning, accelerated computing, and accelerated data science to more advanced workshops on NLP, intelligent recommender systems, and health-care imaging analysis. Select courses offer a DLI certificate to demonstrate subject matter competency and support career growth. Join NVIDIA’s higher education leadership and Professor Manuel Ujaldon from the University of Malaga, Spain to learn more about the program and how to apply. Manuel will also discuss how he leverages the program for his students and how these resources have helped him improve the quality of online learning during the COVID-19 pandemic.
Joe Bungo, DLI Program Manager, NVIDIA
Manuel Ujaldón, Professor, Computer Architecture Department, University of Malaga

- Insights From NVIDIA Research
This talk will give some highlights from NVIDIA Research over the past year. Topics will include high-performance optical signaling, deep learning accelerators, applying AI to video coding, and the latest in computer graphics.
Bill Dally, Chief Scientist and SVP Research, NVIDIA

- NASA Frontier Development Lab: Severe Weather Prediction Using Lightning Data
Learn how a state-of-the-art model for time series classification was used for severe weather (tornadoes and severe hail thunderstorms) prediction using lightning data from the Geostationary Lightning Mapper (GLM) device aboard the NOAA GOES-16 satellite. These results are the outcome of NASA Frontier Development Lab (FDL) 2020: Lightning and Extreme Weather, and were accepted to oral presentations in two NeurIPS 2020 workshops and are currently submitted for publication. According to our tests, the GPU implementation of the convolutional time series approach was 27x faster than a CPU implementation. This dramatic gain in speed allowed rapid iteration to build more and better models. Find out how leveraged by NVIDIA V100 GPUs, our results suggest that, with a 15 minute lead time, false alarms for warned thunderstorms could be decreased by 70% and that tornadoes and large hail could be correctly identified approximately 3 out of 4 times using lightning data only.
Ivan Venzor, Data Science Deputy Director, Banregio

- Hands-On Deep Learning Robotics Curriculum in High Schools with Jetson Nano
NVIDIA’s Jetson AI Ambassador will show you how to implement fundamental deep learning and robotics in high schools with Jetson Nano developer kit. If you’re interested in AI education, you’ll learn how to get the most from NVIDIA Jetson Nano developer kit and DLI courses. This AI curriculum includes deep learning fundamental concepts, Python programming skills, an image processing algorithm, and an integrated robotics project (Jetbot). Students can evaluate what they’ve learned and have an instant response on the robot’s behavior.
David Tseng, Manager, CAVEDU Education

- NVIDIA Kaolin and Omniverse for 3D Deep Learning Research
Get an introduction to NVIDIA’s Kaolin library for accelerating 3D deep learning research, as well as a demonstration of APIs for Kaolin’s GPU-optimized operations such as modular differentiable rendering, fast conversions between representations, data loading, 3D checkpoints, and more. In this session, we’ll also demonstrate using the Omniverse Kaolin application to visualize training datasets, generate new ones, and to observe the progress of ongoing training of models.
Jean-Francois Lafleche, Deep Learning Engineer, NVIDIA
Clement Fuji Tsang, Research Scientist, NVIDIA
Visit the GTC website to view more recommended sessions and to register for the free conference.
Got a conflict with your 2pm appointment? Just spin up a quick assistant that takes good notes and when your boss asks about you even identifies itself and explains why you aren’t there. Nice fantasy? No, it’s one of many use cases a team of some 50 ninja programmers, AI experts and 20 beta testers Read article >
The post Now Hear This: Startup Gives Businesses a New Voice appeared first on The Official NVIDIA Blog.
Drawing on his trifecta of degrees in math, music and music technology, Tlacael Esparza, co-founder and CTO of Sunhouse, is revolutionizing electronic drumming. Esparza has created Sensory Percussion, a combination of hardware and software that uses sensors and AI to allow a single drum to produce a complex range of sounds depending on where and Read article >
The post Drum Roll, Please: AI Startup Sunhouse Founder Tlacael Esparza Finds His Rhythm appeared first on The Official NVIDIA Blog.
Categories
Art and Music in Light of AI
In the sea of virtual exhibitions that have popped up over the last year, the NVIDIA AI Art Gallery offers a fresh combination of incredible visual art, musical experiences and poetry, highlighting the narrative of an emerging art form based on AI technology. The online exhibit — part of NVIDIA’s GTC event — will feature Read article >
The post Art and Music in Light of AI appeared first on The Official NVIDIA Blog.
 Containers have quickly gained strong adoption in the software development and deployment process and has truly enabled us to manage software complexity. It is not surprising that, by a recent Gartner report, more than 70% of global organizations will be running containerized applications in production by 2023. That’s up from less than 20% in 2019. … Continued
Containers have quickly gained strong adoption in the software development and deployment process and has truly enabled us to manage software complexity. It is not surprising that, by a recent Gartner report, more than 70% of global organizations will be running containerized applications in production by 2023. That’s up from less than 20% in 2019. … Continued
Containers have quickly gained strong adoption in the software development and deployment process and has truly enabled us to manage software complexity. It is not surprising that, by a recent Gartner report, more than 70% of global organizations will be running containerized applications in production by 2023. That’s up from less than 20% in 2019.
However, containers also bring security challenges to IT and security practitioners. Shipping containers can be a potential hiding place for illegal contraband. You may not be fully aware of the contents of a software container. That’s why it’s critical to have a comprehensive understanding of the contents of the containers that you deploy. Security is no longer an afterthought for IT and security admins, but there is a need to adopt security best practices early in the software building process.
Today, there are numerous software marketplaces from which to pull a variety of containerized software tools to help you speed up software development. However, this speedup in the development process is counterproductive if the DevSecOps or IT team flags the software for security lapses, preventing deployment to production. This can lead to delays in production and, eventually, revenue loss.
To speed up development in a repeated and an automated format, the most common starting point is to download a publicly available image and build on top of it. Unknowingly, you might expose your new application code or service to the risk of vulnerabilities, which are inherited from base images. Some of the most common threats include images that have unpatched vulnerabilities or mistakenly granting many privileges that can have potential escalation in production environments, related to exposed insecure ports, private keys, or secrets. Relying on software images from trusted sources, like NVIDIA NGC, can play a key role in accelerating the software development cycle.
When you layer your own application code with NGC images as base images, you may only have to worry about the code layers that you add on top of it. Secondly, every time a CVE is identified in any layer, you must build an image from scratch, which may take several hours and may be time-consuming. Using NGC images to build production applications or services helps you reduce time to deployments.
Container security at the core of the NGC catalog
The software from NGC provides a high level of security assurance required by enterprises. Curated containers on NGC can enable rapid application development with minimal investment as the NGC containers undergo performance regression testing, and functional and security checks ahead of a release.
The NGC container publication process has container image scanning by Anchore at its core. Image scanning refers to the process of analyzing the contents of a container image to detect security issues, vulnerabilities, or bad practices.
NGC registry integrates security scanning as an SaaS offering where images are retrieved and scanned with the Anchore solution. The security scans include checks like the following:
- Vulnerability, such as CVE-mapping
- Metadata scans such as Dockerfiles
- Data or key leaks such as crypto keys
- Open ports
The scanning policy for CVEs measures severity into critical, high, medium, and low vulnerabilities using the Common Vulnerability Scoring System (CVSS). Known CVEs are patched before publishing an image to NGC. The scan results may vary in time as new CVEs are published each hour and the new CVEs may not be known at the time of publishing. The scan results allow publishers to identify any red flags early in the development process, saving development time using Anchore’s best-in-class, high signal-to-noise ratio scanning technology, which means fewer false positives.
Figure 1 shows a sample results of an image scanned in NGC, with two high vulnerabilities found in OS packages. It also provides CVE links to detailed descriptions on the security threats exposed and if it was patched in upstream versions. Developers and security can analyze the risk further to triage it.
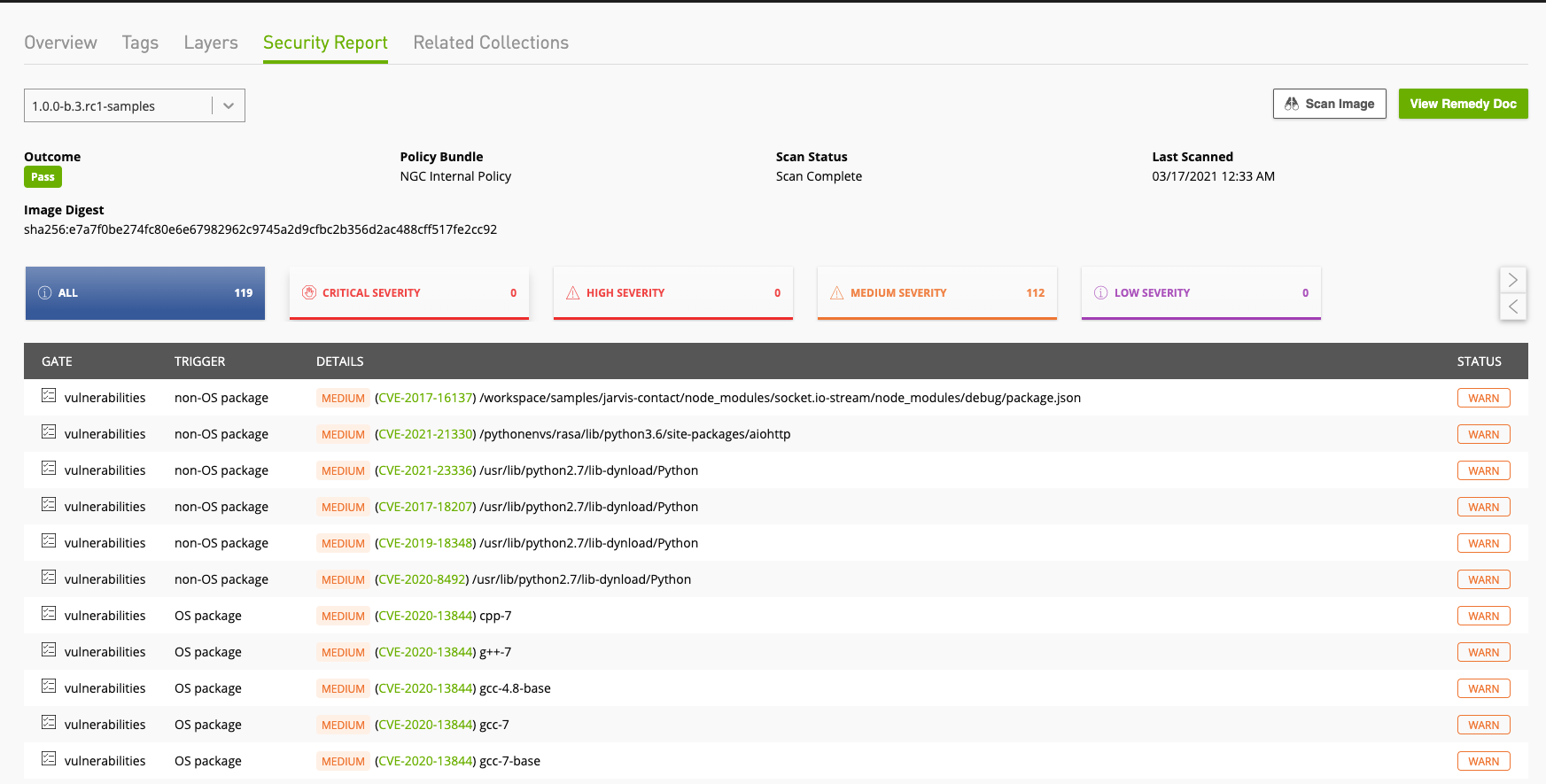
The most popular products like PyTorch, TensorFlow, Triton, TensorRT, MXNet, RAPIDS, CUDA, and nv-HPC SDK update their NGC images on a monthly release cadence, assuring that the latest security patches are applied.
As software complexity increases with the need for additional capabilities, you rely on additional packages and software layers, which in turn increases security risks and exposures. Our security development practices drive to a minimal memory footprint as we provide thinner images in flavors of development and deployment images. For example, the CUDA base is used to build applications but the CUDA runtime image is used for deployments. This leads to a smaller attack surface, where unused packages or debug tools are eliminated.
Thus, NGC aims to provide a strong foundation for enterprises by adapting to security best practices such as scanning and other approaches. As upgrading, testing, and deploying gets easier with containers, you are encouraged to upgrade to the latest NGC image versions. This not only reduces security risks from recently found CVEs, but also allows you to get maximum performance delivered on NVIDIA GPUs.
GTC 21
To learn more about container security, join us for the Industry Experts Discuss Container Security and Best Practices for Software Development Stakeholders GTC panel session on April 14, 1PM (registration required to view). During the session, security industry experts discuss the best practices that data scientists and developers can follow to be more vigilant in identifying and pulling secure software images. Register today!
 Back in 2012, NVIDIAN Mark Harris wrote Six Ways to Saxpy, demonstrating how to perform the SAXPY operation on a GPU in multiple ways, using different languages and libraries. Since then, programming paradigms have evolved and so has the NVIDIA HPC SDK. In this post, I demonstrate five ways to implement a simple SAXPY computation … Continued
Back in 2012, NVIDIAN Mark Harris wrote Six Ways to Saxpy, demonstrating how to perform the SAXPY operation on a GPU in multiple ways, using different languages and libraries. Since then, programming paradigms have evolved and so has the NVIDIA HPC SDK. In this post, I demonstrate five ways to implement a simple SAXPY computation … Continued
Back in 2012, NVIDIAN Mark Harris wrote Six Ways to Saxpy, demonstrating how to perform the SAXPY operation on a GPU in multiple ways, using different languages and libraries. Since then, programming paradigms have evolved and so has the NVIDIA HPC SDK.
In this post, I demonstrate five ways to implement a simple SAXPY computation using NVIDIA GPUs. Why is this interesting? Because it demonstrates the breadth of options that you have today for programming NVIDIA GPUs. It also covers the four main approaches to GPU computing:
- GPU-accelerated libraries
- Compiler directives
- Standard language parallelism
- GPU programming languages
SAXPY stands for Single-Precision A·X Plus Y, a function in the standard Basic Linear Algebra Subroutines (BLAS) library. SAXPY is a combination of scalar multiplication and vector addition, and it’s simple: it takes as input two vectors of 32-bit floats X and Y with N elements each, and a scalar value A. It multiplies each element X[i] by A and adds the result to Y[i]. A simple C implementation looks like the following:
void saxpy_cpu(int n, float a, float *x, float *y)
{
for (int i = 0; i Given this basic example code, I can now show you five ways to SAXPY on GPUs. I chose SAXPY because it is a short and simple code, but it shows enough of the syntax of each programming approach to compare them. Because it does relatively little computation, SAXPY isn’t that useful for demonstrating the difference in performance between the different programming models, but that’s not my intent here. My goal is to demonstrate multiple ways to program on the NVIDIA platform today, rather than to recommend one over another. That would require taking other factors into account and is beyond the scope of this post.
I discuss implementations of SAXPY in the following models:
- CUDA C++—A C++ language extension to support the CUDA programming model and allow C++ code to be executed on NVIDIA GPUs.
- cuBLAS—A GPU-accelerated implementation of the basic linear algebra subroutines (BLAS) optimized for NVIDIA GPUs.
- OpenACC—Using compiler directives to tell the compiler that a given portion of the code can be parallelized and letting the compiler figure out how to do it.
- Standard C++—Using the NVC++ compiler and parallel execution policies added to the standard library with C++11 and 17.
- Thrust—A high-level, GPU-accelerated parallel algorithms library.
After going through all the implementations, I show what performance looks like when SAXPY is accelerated through these approaches.
CUDA C++ SAXPY
__global__ void saxpy_cuda(int n, float a, float *x, float *y)
{
unsigned int t_id = threadIdx.x + blockDim.x * blockIdx.x;
unsigned int stride = blockDim.x * gridDim.x;
for (int i = t_id; i >>(n, 2.0, dev_x, dev_y);
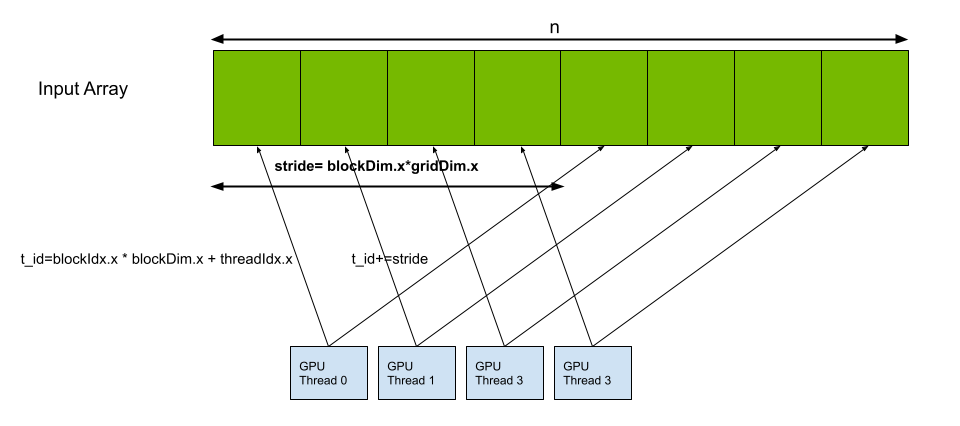
cudaDeviceSynchronize();CUDA C++ is a GPU programming language that provides extensions to the C/C++ language for expressing parallel computation. Device functions, called kernels, are declared with the __global__ specifier to show that they can be called either from host code or device code. Device memory to hold the float vector is allocated using cudaMalloc. Then, the kernel defined is called with an execution configuration:
>>
Each thread launched executes the kernel, using built-in variables like threadIdx, blockDim, and blockIdx. The variables are assigned by the device for each thread and block and are used to calculate the index of the elements in the vector for which it is responsible. In doing so, each thread does the multiply-add operation on a limited number of elements of the vector. In the case where the number of threads is less than the size of the vector, each thread computes a stride to operate on multiple elements so that the entire vector is taken care of (Figure 1).
cuBLAS SAXPY
cublasHandle_t handle;
cublasCreate(&handle);
unsigned int n = 1UL SAXPY, being a BLAS operation, has an implementation in the NVIDIA cuBLAS library. It involves initializing a cuBLAS library context by passing a handle to cublasCreate, allocating memory for the vectors, and then calling the library function cublasSaxpy while passing in the vector and scalar values. Finally, cublasDestroy and cudaFree are used to release the resources associated with the cuBLAS library context and device memory allocated for the vectors, respectively.
OpenACC C++ SAXPY
void saxpy(int n, float a, float *restrict x, float *restrict y)
{
#pragma acc kernels
for (int i = 0; i OpenACC is a directive-based programming model that uses compiler directives through #pragma to tell the compiler that a portion of the code can be parallelized. The compiler then analyzes the instruction and automatically generates code for the GPU. OpenACC provides options for fine-tuning launch configurations in those instances where the automatically generated code may not be optimal.
Compilers with support for NVIDIA GPUs like nvc++ can offload computation to the GPU using unified memory to seamlessly copy data between the host and device. Adding #pragma acc kernels tells the compiler to generate a kernel for the following for loop. Because you allocated x and y on the host using the malloc instruction, the compiler uses unified memory to move the vector to the device before computation and back to the host afterward. The compiler generates instructions to move the vectors x and y into device memory and do a fused multiply-add for each element.
std::par C++ SAXPY
void saxpy(int N, float a, float *restrict x, float *restrict y)
{
std::transform(std::execution::par_unseq, x, x + N, y, y,[=](float xi, float yi) { return a * xi + yi; });
}
float alpha = 2.0;
unsigned int n = 1UL With the NVIDIA NVC++ compiler, you can use GPU acceleration in standard C++ with no language extensions, pragmas, directives, or libraries, other than the C++ standard library. The code, being standard C++, is portable to other compilers and systems and can be accelerated on NVIDIA GPUs or multicore CPUs using NVC++.
With the new features for parallel execution and execution policies introduced with C++11 and 17, algorithms in the standard library like std::transform and std::reduce added an execution policy as the first parameter to any algorithm that supports execution policies. You can thus pass std::execution::par_unseq to std::transform, defining a lambda that captures by value and performs the saxpy operation. When compiled using the -stdpar command line option, the compiler compiles standard algorithms that are called with a parallel execution policy for execution on NVIDIA GPUs.
Thrust SAXPY
struct saxpy_functor
{
const float a;
saxpy_functor(float _a) : a(_a) {}
__global__ float operator()(const float &x, const float &y)
{
return a * x + y;
}
};
float alpha = 2.0;
unsigned int n = 1UL x(n);
thrust::device_vector y(n);
thrust::fill(x.begin(), x.end(), 1.0);
thrust::fill(y.begin(), y.end(), 1.0);
thrust::transform(x.begin(), x.end(), y.begin(), y.begin(), saxpy_functor(alpha));Thrust is a parallel algorithms library that resembles the C++ Standard Template Library (STL). It provides parallel building blocks to develop fast, portable algorithms. Interoperability with established technologies like CUDA and TBB, along with its modular design, allows you to focus on the algorithms instead of the platform-specific implementations.
Here, you allocate memory on the device, in this case the NVIDIA GPU for x and y. You then use the fill function to initialize them. Finally, you use the Thrust transform algorithm along with the defined functor saxpy_functor to apply the y=a*x+y operation to each element of x and y.
SAXPY performance
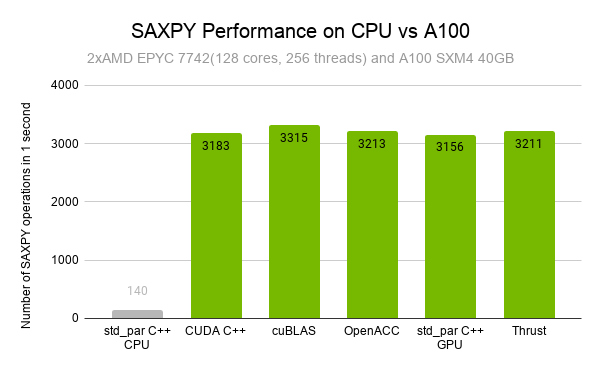
While SAXPY is a bandwidth-bound operation and not computationally complex, its highly parallel nature means that it still benefits from GPU acceleration if the problem size is large enough. When compared to a dual socket AMD EPYC 7742 system with 128 cores and 256 threads, an NVIDIA A100 GPU was 23x faster, executing more than 3000 SAXPY operations in the time that the CPU took to do 140. Furthermore, all the GPU-accelerated implementations gave a similar performance, with cuBLAS edging out the rest by a slight margin (Figure 2).
Accelerating your code with NVIDIA GPUs
The NVIDIA HPC SDK is a comprehensive suite of compilers, libraries, and tools enabling you to choose the programming model that works best for you and still get excellent performance by accelerating your code using NVIDIA GPUs. Learn more and get started today:
Try NVIDIA GPU acceleration for your code from any major cloud service provider. Try A100 in the cloud at Google Cloud Platform, Amazon Web Services, or Alibaba Cloud.