Posted by Hattie Zhou, Graduate Student at MILA, Hanie Sedghi, Research Scientist, Google
Large language models (LLMs), such as GPT-3 and PaLM, have shown impressive progress in recent years, which have been driven by scaling up models and training data sizes. Nonetheless, a long standing debate has been whether LLMs can reason symbolically (i.e., manipulating symbols based on logical rules). For example, LLMs are able to perform simple arithmetic operations when numbers are small, but struggle to perform with large numbers. This suggests that LLMs have not learned the underlying rules needed to perform these arithmetic operations.
While neural networks have powerful pattern matching capabilities, they are prone to overfitting to spurious statistical patterns in the data. This does not hinder good performance when the training data is large and diverse and the evaluation is in-distribution. However, for tasks that require rule-based reasoning (such as addition), LLMs struggle with out-of-distribution generalization as spurious correlations in the training data are often much easier to exploit than the true rule-based solution. As a result, despite significant progress in a variety of natural language processing tasks, performance on simple arithmetic tasks like addition has remained a challenge. Even with modest improvement of GPT-4 on the MATH dataset, errors are still largely due to arithmetic and calculation mistakes. Thus, an important question is whether LLMs are capable of algorithmic reasoning, which involves solving a task by applying a set of abstract rules that define the algorithm.
In “Teaching Algorithmic Reasoning via In-Context Learning”, we describe an approach that leverages in-context learning to enable algorithmic reasoning capabilities in LLMs. In-context learning refers to a model’s ability to perform a task after seeing a few examples of it within the context of the model. The task is specified to the model using a prompt, without the need for weight updates. We also present a novel algorithmic prompting technique that enables general purpose language models to achieve strong generalization on arithmetic problems that are more difficult than those seen in the prompt. Finally, we demonstrate that a model can reliably execute algorithms on out-of-distribution examples with an appropriate choice of prompting strategy.
By providing algorithmic prompts, we can teach a model the rules of arithmetic via in-context learning. In this example, the LLM (word predictor) outputs the correct answer when prompted with an easy addition question (e.g., 267+197), but fails when asked a similar addition question with longer digits. However, when the more difficult question is appended with an algorithmic prompt for addition (blue box with white +shown below the word predictor), the model is able to answer correctly. Moreover, the model is capable of simulating the multiplication algorithm (X) by composing a series of addition calculations.
Teaching an algorithm as a skill
In order to teach a model an algorithm as a skill, we develop algorithmic prompting, which builds upon other rationale-augmented approaches (e.g., scratchpad and chain-of-thought). Algorithmic prompting extracts algorithmic reasoning abilities from LLMs, and has two notable distinctions compared to other prompting approaches: (1) it solves tasks by outputting the steps needed for an algorithmic solution, and (2) it explains each algorithmic step with sufficient detail so there is no room for misinterpretation by the LLM.
To gain intuition for algorithmic prompting, let’s consider the task of two-number addition. In a scratchpad-style prompt, we process each digit from right to left and keep track of the carry value (i.e., we add a 1 to the next digit if the current digit is greater than 9) at each step. However, the rule of carry is ambiguous after seeing only a few examples of carry values. We find that including explicit equations to describe the rule of carry helps the model focus on the relevant details and interpret the prompt more accurately. We use this insight to develop an algorithmic prompt for two-number addition, where we provide explicit equations for each step of computation and describe various indexing operations in non-ambiguous formats.
Illustration of various prompt strategies for addition.
Using only three prompt examples of addition with answer length up to five digits, we evaluate performance on additions of up to 19 digits. Accuracy is measured over 2,000 total examples sampled uniformly over the length of the answer. As shown below, the use of algorithmic prompts maintains high accuracy for questions significantly longer than what’s seen in the prompt, which demonstrates that the model is indeed solving the task by executing an input-agnostic algorithm.
Test accuracy on addition questions of increasing length for different prompting methods.
Leveraging algorithmic skills as tool use
To evaluate if the model can leverage algorithmic reasoning in a broader reasoning process, we evaluate performance using grade school math word problems (GSM8k). We specifically attempt to replace addition calculations from GSM8k with an algorithmic solution.
Motivated by context length limitations and possible interference between different algorithms, we explore a strategy where differently-prompted models interact with one another to solve complex tasks. In the context of GSM8k, we have one model that specializes in informal mathematical reasoning using chain-of-thought prompting, and a second model that specializes in addition using algorithmic prompting. The informal mathematical reasoning model is prompted to output specialized tokens in order to call on the addition-prompted model to perform the arithmetic steps. We extract the queries between tokens, send them to the addition-model and return the answer to the first model, after which the first model continues its output. We evaluate our approach using a difficult problem from the GSM8k (GSM8k-Hard), where we randomly select 50 addition-only questions and increase the numerical values in the questions.
An example from the GSM8k-Hard dataset. The chain-of-thought prompt is augmented with brackets to indicate when an algorithmic call should be performed.
We find that using separate contexts and models with specialized prompts is an effective way to tackle GSM8k-Hard. Below, we observe that the performance of the model with algorithmic call for addition is 2.3x the chain-of-thought baseline. Finally, this strategy presents an example of solving complex tasks by facilitating interactions between LLMs specialized to different skills via in-context learning.
Chain-of-thought (CoT) performance on GSM8k-Hard with or without algorithmic call.
Conclusion
We present an approach that leverages in-context learning and a novel algorithmic prompting technique to unlock algorithmic reasoning abilities in LLMs. Our results suggest that it may be possible to transform longer context into better reasoning performance by providing more detailed explanations. Thus, these findings point to the ability of using or otherwise simulating long contexts and generating more informative rationales as promising research directions.
Acknowledgements
We thank our co-authors Behnam Neyshabur, Azade Nova, Hugo Larochelle and Aaron Courville for their valuable contributions to the paper and great feedback on the blog. We thank Tom Small for creating the animations in this post. This work was done during Hattie Zhou’s internship at Google Research.
As part of NVIDIA and Microsoft’s collaboration to bring more choice to gamers, new Microsoft Store integration has been added to GeForce NOW that lets gamers stream select titles from the Xbox PC Game Pass catalog on GeForce NOW, starting today. With the Microsoft Store integration, members will see a brand-new Xbox button on supported Read article >
The NVIDIA DOCA framework aims to simplify the programming and application development for NVIDIA BlueField DPUs and ConnectX SmartNICs. It provides high-level…
The NVIDIA DOCA framework aims to simplify the programming and application development for NVIDIA BlueField DPUs and ConnectX SmartNICs. It provides high-level abstraction building blocks relevant to network applications through an SDK, runtime binaries, and high-level APIs that enable developers to rapidly create applications and services.
NVIDIA DOCA Flow is a newly updated set of software drivers and a steering library in the DOCA Framework. It runs in user space and enables offloading of networking-related operations from the CPU. This in turn enables applications to process high-packet throughput workloads with low latency, conserving CPU resources and reducing power usage.
DOCA Flow also efficiently optimizes the utilization of BlueField DPUs and ConnectX SmartNICs. DOCA is the key to unlocking the potential of BlueField’s acceleration engines, while DOCA Flow grants rapid access to the acceleration engine for packet-steering logic.
Simplify and expedite development
DOCA Flow offers C library APIs for defining hardware-based packet processing pipelines, abstracting the hardware capabilities of BlueField DPUs and ConnectX SmartNICs. This enables developers to construct high-performance and scalable applications for data center and cloud networks, programmatically defining and controlling network traffic flows, implementing network policies, and efficiently managing resources.
DOCA Flow complements and expands upon the core programming capabilities of DPDK, providing additional optimized features tailored specifically for NVIDIA DPUs and NICs. Further, DOCA Flow simplifies the complexities of the networking stack by offering building blocks for implementing basic packet processing pipelines for popular networking use cases, as well as for more sophisticated ones such as Longest Prefix Matching (LPM), Internet Protocol Security (IPsec) encryption or decryption, and creation or modification of entries in the Access Control List (ACL).
Using pre-created networking building blocks enables you to focus on creating your applications instead of writing low-level packet processing routines. This reduces TTM and frees you to focus on the core of your application, as the building blocks are already efficiently optimized for performance. DOCA Flow building blocks make software development easier, and can be used by developers of all experience levels.
Why DPUs are needed
Modern workloads and software-defined networking lead to significant networking overhead on CPU cores. Data centers and cloud networks now start at speeds of 25 or 100 Gbps and scale up to 200 and even 400 Gbps, requiring CPU cores to handle classification, tracking, processing, and steering of network traffic at immense speeds.
Compute virtualization amplifies networking requirements by generating more east/west traffic internally between host VMs and containers, and adding overlay network encapsulation plus microsegmentation to external communication with other servers or storage devices. As a result, much more networking demand is placed on the CPU.
CPU cores come with a significant cost and are not well-suited for efficient network packet processing. High-bandwidth tasks consume more CPU cores, placing unnecessary strain on the server’s valuable compute infrastructure, which could otherwise be utilized more productively for tenant workloads and application data processing.
In contrast, specialized hardware like SmartNICs and DPUs are specifically designed to efficiently handle fast data movement at scale, with reduced power consumption, heat, and overall cost compared to standard CPUs.
Execution pipes
The DOCA Flow library provides APIs that use hardware functions within the BlueField DPU and ConnectX SmartNICs to build generic and reusable execution pipes, where each pipe may consist of match criteria (packet classification) and a set of actions.
Classification enables identifying incoming packets to which logic should be applied, while actions vary and implement the logic that fits each packet’s classification. Using classifications and actions as building blocks provides a flexible method for developing hardware-accelerated network applications including gateways, firewalls, load-balancers, and others.
As mentioned, the actions in the DOCA Flow execution pipe vary and may include, as an example, packet manipulations such as applying Network Address Translation (NAT) logic on MAC addresses, changing source or destination IP addresses, applying overlay network encapsulation, changing header fields, incrementing a counter to measure traffic, and more. Actions may include monitoring traffic through the use of policies, forwarding traffic to different queues–either software queues or hairpin targets, port mirroring or packet sampling for debugging and lawful interception, and dropping packets to enforce policies or access control–all completely offloaded to the DPU or NIC hardware.
Pipes may be chained together through forwarding actions from one pipe to another to form a complete steering tree that defines paths for incoming packets. After executing a predefined action on a packet, the packet may be forwarded to another pipe for further action or inspection, to a software queue, to a hardware hairpin queue, or sent down the wire or dropped.
Figure 1. Pipe chaining constructs network logic, as each pipe handles unique criteria, actions, and forwarding, shaping a steering tree for packet control
Steering trees
A steering tree can be used to create hardware-based network applications on a DPU or NIC by implementing common network function logic. This enables packets to be effectively categorized so the appropriate action can be applied to each one. Using the steering tree concept provides multiple benefits, including:
Customized processing logic for each data flow
Versatility in directing packets to specific actions or destinations
Adaptable structure that’s easily resized for changing conditions
Flexible framework that allows adding new pipe types to meet evolving requirements
Optimized resource use, minimizing redundancy and enabling shared matches and actions
NVIDIA DOCA Flow use cases
When developing network pipelines for BlueField DPUs and ConnectX SmartNICs, DOCA Flow serves as a fundamental element in simplifying application development efforts. Use cases are applicable across enterprise data centers, telco, and cloud environments, particularly those that are focused on network infrastructure and security that require efficient packet processing.
Additionally, it is designed to handle scenarios involving establishing and removing pipelines at an extremely high rate, and can manage millions of packet exchanges per second. This accommodates software-defined networking applications, data analytics, virtual switching, AI inferencing, cybersecurity, and other packet processing applications. It enables operations like ingesting, examining headers and payloads, tracking connections, and inspecting, rerouting, copying, or dropping packets based on predetermined policies or other criteria.
Open vSwitch virtual switching
Open vSwitch (OVS) enables massive network automation through programmatic extension, and is designed to enable efficient network switching in virtualized environments such as virtual machines (VMs) and containers. Through DOCA Flow, a DPU-accelerated virtual switch (vSwitch) can be implemented in the user space data plane, allowing any server with a DPU to act as a network switch, router, or stateful load balancer.
This provides the flexibility of having a vSwitch available to multiple VNFs, while also significantly increasing small packet throughput and reducing latencies, thus expediting and accelerating communication through enhanced networking performance from the DPU and facilitating both north-south traffic for connecting to users, and east-west traffic for AI and distributed applications.
Next-generation firewall
Modern firewalls are required to inspect data at higher rates in order to combat new threats. However, with increased network speeds, more load is placed on the CPU. This can lead to increased latency, dropped packets, and reduced network throughput. To support higher speeds and more stringent security requirements without sacrificing latency is complex and deploying enough traditional firewalls capable of handling the increased traffic is cost-prohibitive.
DOCA Flow enables the development of an intelligent network filter for each server hosting a DPU. With this filter, the parsing and steering of traffic flows is based on predefined policies, with no CPU overhead. It can be used to create a distributed next-generation firewall (NGFW) that can achieve close to 100 Gbps throughput per server by using dedicated accelerators and Arm cores on the DPU to filter and forward packets based on their appropriate flow, as well as managing the data plane offloads and control plane of the NGFW.
Using DOCA Flow can provide a cost-effective solution to offload packet processing from the CPU to the DPU to increase performance and reduce costs beyond traditional hardware solutions. It offers advanced security features, like intrusion prevention, without sacrificing server performance. It also enables faster network flow inspection within the NIC/DPU.
Virtual network functions
DOCA Flow can accelerate virtualized network functions (VNFs), such as routers, load balancers, firewalls, content delivery network (CDN) services, and more. Telco vendors can replace proprietary hardware and execute virtualized workloads on commodity servers by developing VNFs that run on BlueField DPUs.
By using DPUs for VNF acceleration, a more efficient and flexible solution is achieved, leading to reduced equipment, space, heat, and power requirements compared with commodity servers. All this helps resolve limitations based on cooling and space constraints, enabling new opportunities with 5G, AI, IoT, and edge computing.
Edge applications
DOCA Flow is an ideal solution for edge workloads that require high network speeds and I/O processing capabilities, such as content delivery networks and video analytics systems. Host applications for the edge can be designed using DOCA Flow to run on DPUs installed within general-purpose servers, eliminating the need for expensive proprietary hardware appliances. By utilizing the DPUs acceleration and Arm cores, fewer server CPU cores are needed, allowing for smaller servers that consume less energy, require less cooling, and occupy less rack space. This approach offers cost savings in terms of both CapEx and OpEx.
Summary
The DOCA Flow library can be instrumental for developers by simplifying the development of modern applications that offer accelerated network throughput and latency improvements in packet processing. This is especially true for applications replacing proprietary bare-metal hardware solutions with virtualized applications hosted on commercial-off-the-shelf (COTS) server platforms.
The library consists of several building blocks for efficient networking offloads, including implementing basic packet processing pipelines, Longest Prefix Matching (LPM), and Internet Protocol Security (IPsec) encryption or decryption. Enhancements will be added soon to Connection Tracking (CT) and Access Control List (ACL) to create or modify access control entries. For a sampling of DOCA Flow reference applications, see the DOCA Reference Applications documentation.
By harnessing the capabilities of DOCA Flow, organizations can minimize cost, accelerate service deployment, and optimize hardware utilization within use cases that demand high throughput and low latency.
NVIDIA today reported revenue for the second quarter ended July 30, 2023, of $13.51 billion, up 101% from a year ago and up 88% from the previous quarter.
The advent of cloud computing has ushered in a paradigm shift in our data storage and utilization practices. Businesses can bypass the complexities of managing…
The advent of cloud computing has ushered in a paradigm shift in our data storage and utilization practices. Businesses can bypass the complexities of managing their own computing infrastructure by tapping into remote, on-demand resources deftly managed by cloud service providers. Yet, there exists a palpable apprehension about sharing sensitive information with the cloud.
While traditional cryptographic methods such as AES can help preserve data privacy, they stifle the cloud’s capacity to undertake meaningful operations on the data. In an encryption system, a message, also referred to as plaintext, is transformed using a key into a scrambled version known as ciphertext. The encryption methods in place assure that malicious entities can’t decrypt the message without the correct key and can’t gain access to its contents. Without decryption, a ciphertext is essentially nonsensical.
Fortunately, there is a solution: fully homomorphic encryption (FHE), a sophisticated and potent encryption technique. It serves as a comprehensive shield for data, whether in transit, at rest, or in use. Homomorphic encryption is a unique design that enables operations to be performed on the ciphertext while still preserving its security. This type of operation modifies a ciphertext in such a way that, after decryption, the result is the same as if the operation was carried out on the plaintext itself.
Frequently referred to as the ultimate goal of cryptography, FHE can carry out any computational function on the ciphertext. This remarkable technology has the capability to run thousands of algorithms directly on encrypted data, all without compromising the underlying plaintext. It confronts the pivotal privacy issues linked with cloud computing head-on, while simultaneously enabling intricate outsourced computations.
However, operations performed with FHE encryption tend to be slower than those conducted over standard unencrypted data. Also, the current applications of this technology can be somewhat challenging for non-specialists to set up and manage effectively.
ArctyrEX: Accelerated encrypted execution
A recent effort by NVIDIA Research aims to address the efficiency problems associated with encrypted computing. The proposed solution, ArctyrEX, is an end-to-end framework that enables you to specify algorithms in C++ using standard data types and automatically convert this algorithm into an FHE representation that can be launched on arbitrary numbers of GPUs for efficient evaluation.
Figure 1. ArctyrEX system overview
ArctyrEX is composed of three parts:
A frontend responsible for converting input programs to the encrypted domain
A runtime library that sends encrypted workloads to GPU workers
A backend that consists of an implementation of the state-of-the-art CGGI cryptosystem.
The CGGI cryptosystem encrypts single bits of plaintext and enables encrypted Boolean operations between ciphertexts. Therefore, the programming model for CGGI is akin to constructing Boolean circuits composed of logic gates. For more information, see TFHE: Fast Fully Homomorphic Encryption over the Torus and TFHE.
The frontend takes advantage of decades of hardware development research to convert C++ programs to equivalent Verilog files, which provide a description of a circuit at a high level of abstraction. Then it converts the files to optimal Boolean circuits. This process uses well-established techniques in the form of high-level synthesis (HLS) and register-transfer level (RTL) or logic synthesis.
The ArctyrEX runtime library takes the generated Boolean circuit, divides it into distinct levels, and creates batches of approximately identical size to distribute to GPU workers. In some cases, the ciphertexts corresponding to an output wire of a gate at an intermediate level may have to serve as input to a workload assigned to a different GPU during the next level. ArctyrEX is capable of seamlessly coordinating these transfers efficiently.
Lastly, the ArctyrEX backend consists of an optimized CUDA kernel capable of executing batches of gates concurrently while minimizing CPU-GPU synchronizations. The output is composed of a set of ciphertexts that represent the output wires of the gates in the assigned batch.
Figure 2. ArctyrEX runtime mapping gates to devices
Run programs with ArctyrEX up to 40x faster
ArctyrEX shows great scalability with the use of more GPUs for two key reasons:
Abundant primitive-level parallelism that is a natural trait of most FHE operations.
Circuit-level parallelism, which is a characteristic commonly displayed in Boolean circuits.
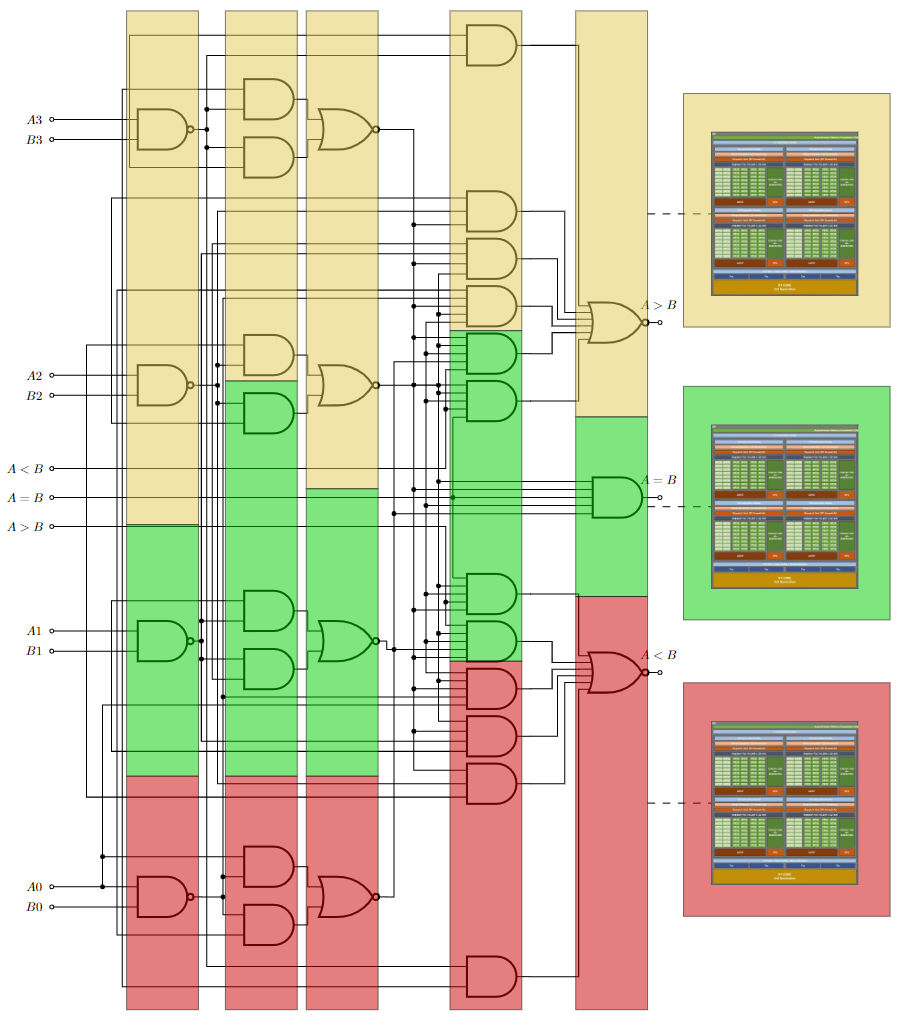
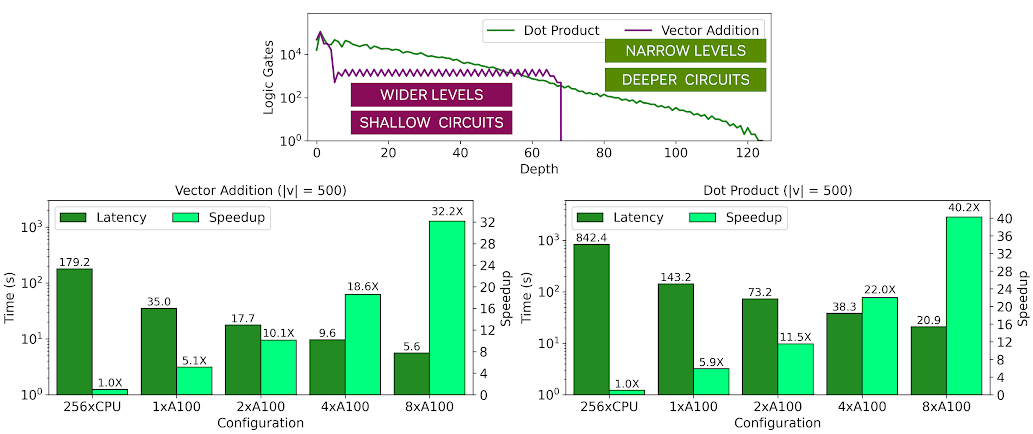
To attain speedy evaluation with Boolean FHE, the circuit must have wide levels, meaning that there should be many gates that can operate simultaneously, and it should have a minimal critical path. To show this, compare an encrypted dot product operation between two vectors with an encrypted vector addition operation.
To actualize these programs in ArctyrEX, you can write C++ code at a high level in an intuitive manner. Here, the pragma is necessary to unroll the loop before the HLS pass. You can employ HLS tools like Google XLS, which are designed to make digital design more approachable and efficient. XLS provides the means to specify digital logic at a higher level like C++ than traditional hardware description languages (like Verilog or VHDL), making the entire process simpler and more efficient.
As an example, observe the differences between an encrypted dot product between two vectors and an encrypted vector addition. To implement these programs in ArctyrEX, you can intuitively write high-level C++ code in the following way, where the pragma is required to unroll the loop before the HLS pass handled by Google XLS:
void vector_addition(int x[500], int y[500], int z[500]) {
#pragma hls_unroll yes
for (int i =0; i
Figure 3. ArctyrEX vector algebra benchmarks
Figure 3 shows the characteristics of both circuits, specifically the number of logic gates at each level of the circuit. In the chart, |v| indicates the vector length and M refers to the dimensions of the matrices. You can see that a dot product of two vectors has a higher critical path with a depth of approximately 120 levels and the width of subsequent levels decreases gradually, limiting the parallelism possible to exploit in the later stages of the circuit.
On the other hand, vector addition has a critical path that is approximately 2x shorter than the dot product, and the width of each level remains relatively constant. As a result, the vector addition runs approximately 4x faster than the dot product, although both exhibit high speedups over a parallel CPU baseline with multiple GPUs. These interesting performance trends are shown in the topology graphs earlier. The light green bars show the speedup relative to a 256-threaded CPU baseline while the dark green bars show the execution time of the homomorphic application.
Summary
In summary, ArctyrEX represents a comprehensive solution for encrypted computation across various applications, harnessing the power of GPU acceleration and implementing innovative techniques for efficient FHE algorithm execution. Tasks like neural network inference demonstrate linear acceleration with the augmentation of GPUs, attributed to the inherent circuit-level parallelism, the newly introduced dispatch paradigm, and the extensive primitive-level parallelism harnessed by the CUDA-accelerated CGGI backend.
We thank all authors of ArctyrEX for their contributions, especially Charles Gouert (Ph.D. candidate) and Prof. Nektarios Georgios Tsoutsos from the University of Delaware. We’d also like to thank members of Zama, CryptoLab, Google, and Duality Tech for their insightful discussions, particularly Ilaria Chillotti, Jung Hee Cheon, Ahmad Al Badawi, Yuri Polyakov, David Cousins, Shruti Gorantala, and Eric Astor.
Posted by Wenhao Yu and Fei Xia, Research Scientists, Google
Empowering end-users to interactively teach robots to perform novel tasks is a crucial capability for their successful integration into real-world applications. For example, a user may want to teach a robot dog to perform a new trick, or teach a manipulator robot how to organize a lunch box based on user preferences. The recent advancements in large language models (LLMs) pre-trained on extensive internet data have shown a promising path towards achieving this goal. Indeed, researchers have explored diverse ways of leveraging LLMs for robotics, from step-by-step planning and goal-oriented dialogue to robot-code-writing agents.
While these methods impart new modes of compositional generalization, they focus on using language to link together new behaviors from an existing library of control primitives that are either manually engineered or learned a priori. Despite having internal knowledge about robot motions, LLMs struggle to directly output low-level robot commands due to the limited availability of relevant training data. As a result, the expression of these methods are bottlenecked by the breadth of the available primitives, the design of which often requires extensive expert knowledge or massive data collection.
In “Language to Rewards for Robotic Skill Synthesis”, we propose an approach to enable users to teach robots novel actions through natural language input. To do so, we leverage reward functions as an interface that bridges the gap between language and low-level robot actions. We posit that reward functions provide an ideal interface for such tasks given their richness in semantics, modularity, and interpretability. They also provide a direct connection to low-level policies through black-box optimization or reinforcement learning (RL). We developed a language-to-reward system that leverages LLMs to translate natural language user instructions into reward-specifying code and then applies MuJoCo MPC to find optimal low-level robot actions that maximize the generated reward function. We demonstrate our language-to-reward system on a variety of robotic control tasks in simulation using a quadruped robot and a dexterous manipulator robot. We further validate our method on a physical robot manipulator.
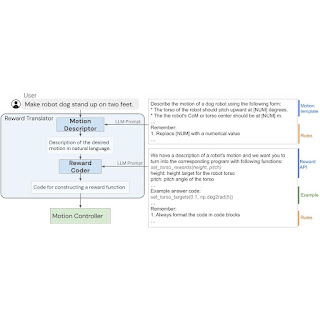
The language-to-reward system consists of two core components: (1) a Reward Translator, and (2) a Motion Controller. TheReward Translator maps natural language instruction from users to reward functions represented as python code. The Motion Controller optimizes the given reward function using receding horizon optimization to find the optimal low-level robot actions, such as the amount of torque that should be applied to each robot motor.
LLMs cannot directly generate low-level robotic actions due to lack of data in pre-training dataset. We propose to use reward functions to bridge the gap between language and low-level robot actions, and enable novel complex robot motions from natural language instructions.
Reward Translator: Translating user instructions to reward functions
The Reward Translator module was built with the goal of mapping natural language user instructions to reward functions. Reward tuning is highly domain-specific and requires expert knowledge, so it was not surprising to us when we found that LLMs trained on generic language datasets are unable to directly generate a reward function for a specific hardware. To address this, we apply the in-context learning ability of LLMs. Furthermore, we split the Reward Translator into two sub-modules: Motion Descriptor and Reward Coder.
Motion Descriptor
First, we design a Motion Descriptor that interprets input from a user and expands it into a natural language description of the desired robot motion following a predefined template. This Motion Descriptor turns potentially ambiguous or vague user instructions into more specific and descriptive robot motions, making the reward coding task more stable. Moreover, users interact with the system through the motion description field, so this also provides a more interpretable interface for users compared to directly showing the reward function.
To create the Motion Descriptor, we use an LLM to translate the user input into a detailed description of the desired robot motion. We design prompts that guide the LLMs to output the motion description with the right amount of details and format. By translating a vague user instruction into a more detailed description, we are able to more reliably generate the reward function with our system. This idea can also be potentially applied more generally beyond robotics tasks, and is relevant to Inner-Monologue and chain-of-thought prompting.
Reward Coder
In the second stage, we use the same LLM from Motion Descriptor for Reward Coder, which translates generated motion description into the reward function. Reward functions are represented using python code to benefit from the LLMs’ knowledge of reward, coding, and code structure.
Ideally, we would like to use an LLM to directly generate a reward function R (s, t) that maps the robot state s and time t into a scalar reward value. However, generating the correct reward function from scratch is still a challenging problem for LLMs and correcting the errors requires the user to understand the generated code to provide the right feedback. As such, we pre-define a set of reward terms that are commonly used for the robot of interest and allow LLMs to composite different reward terms to formulate the final reward function. To achieve this, we design a prompt that specifies the reward terms and guide the LLM to generate the correct reward function for the task.
The internal structure of the Reward Translator, which is tasked to map user inputs to reward functions.
Motion Controller: Translating reward functions to robot actions
The Motion Controller takes the reward function generated by the Reward Translator and synthesizes a controller that maps robot observation to low-level robot actions. To do this, we formulate the controller synthesis problem as a Markov decision process (MDP), which can be solved using different strategies, including RL, offline trajectory optimization, or model predictive control (MPC). Specifically, we use an open-source implementation based on the MuJoCo MPC (MJPC).
MJPC has demonstrated the interactive creation of diverse behaviors, such as legged locomotion, grasping, and finger-gaiting, while supporting multiple planning algorithms, such as iterative linear–quadratic–Gaussian (iLQG) and predictive sampling. More importantly, the frequent re-planning in MJPC empowers its robustness to uncertainties in the system and enables an interactive motion synthesis and correction system when combined with LLMs.
Examples
Robot dog
In the first example, we apply the language-to-reward system to a simulated quadruped robot and teach it to perform various skills. For each skill, the user will provide a concise instruction to the system, which will then synthesize the robot motion by using reward functions as an intermediate interface.
Dexterous manipulator
We then apply the language-to-reward system to a dexterous manipulator robot to perform a variety of manipulation tasks. The dexterous manipulator has 27 degrees of freedom, which is very challenging to control. Many of these tasks require manipulation skills beyond grasping, making it difficult for pre-designed primitives to work. We also include an example where the user can interactively instruct the robot to place an apple inside a drawer.
Validation on real robots
We also validate the language-to-reward method using a real-world manipulation robot to perform tasks such as picking up objects and opening a drawer. To perform the optimization in Motion Controller, we use AprilTag, a fiducial marker system, and F-VLM, an open-vocabulary object detection tool, to identify the position of the table and objects being manipulated.
Conclusion
In this work, we describe a new paradigm for interfacing an LLM with a robot through reward functions, powered by a low-level model predictive control tool, MuJoCo MPC. Using reward functions as the interface enables LLMs to work in a semantic-rich space that plays to the strengths of LLMs, while ensuring the expressiveness of the resulting controller. To further improve the performance of the system, we propose to use a structured motion description template to better extract internal knowledge about robot motions from LLMs. We demonstrate our proposed system on two simulated robot platforms and one real robot for both locomotion and manipulation tasks.
Acknowledgements
We would like to thank our co-authors Nimrod Gileadi, Chuyuan Fu, Sean Kirmani, Kuang-Huei Lee, Montse Gonzalez Arenas, Hao-Tien Lewis Chiang, Tom Erez, Leonard Hasenclever, Brian Ichter, Ted Xiao, Peng Xu, Andy Zeng, Tingnan Zhang, Nicolas Heess, Dorsa Sadigh, Jie Tan, and Yuval Tassa for their help and support in various aspects of the project. We would also like to acknowledge Ken Caluwaerts, Kristian Hartikainen, Steven Bohez, Carolina Parada, Marc Toussaint, and the greater teams at Google DeepMind for their feedback and contributions.
Heterogeneous Memory Management (HMM) is a CUDA memory management feature that extends the simplicity and productivity of the CUDA Unified Memory programming…
Heterogeneous Memory Management (HMM) is a CUDA memory management feature that extends the simplicity and productivity of the CUDA Unified Memory programming model to include system allocated memory on systems with PCIe-connected NVIDIA GPUs. System allocated memory refers to memory that is ultimately allocated by the operating system; for example, through malloc, mmap, the C++ new operator (which of course uses the preceding mechanisms), or related system routines that set up CPU-accessible memory for the application.
Previously, on PCIe-based machines, system allocated memory was not directly accessible by the GPU. The GPU could only access memory that came from special allocators such as cudaMalloc or cudaMallocManaged.
With HMM enabled, all application threads (GPU or CPU) can directly access all of the application’s system allocated memory. As with Unified Memory (which can be thought of as a subset of, or precursor to HMM), there is no need to manually copy system allocated memory between processors. This is because it is automatically placed on the CPU or GPU, based on processor usage.
Within the CUDA driver stack, CPU and GPU page faults are typically used to discover where the memory should be placed. Again, this automatic placement already happens with Unified Memory—HMM simply extends the behavior to cover system allocated memory as well as cudaMallocManaged memory.
This new ability to directly read or write to the full application memory address space will significantly improve programmer productivity for all programming models built on top of CUDA: CUDA C++, Fortran, standard parallelism in Python, ISO C++, ISO Fortran, OpenACC, OpenMP, and many others.
In fact, as the upcoming examples demonstrate, HMM simplifies GPU programming to the point that GPU programming is nearly as accessible as CPU programming. Some highlights:
Explicit memory management is not required for functionality when writing a GPU program; therefore, an initial “first draft” program can be small and simple. Explicit memory management (for performance tuning) can be deferred to a later phase of development.
GPU programming is now practical for programming languages that do not distinguish between CPU and GPU memory.
Large applications can be GPU-accelerated without requiring large memory management refactoring, or changes to third-party libraries (for which source code is not always available).
As an aside, new hardware platforms such as NVIDIA Grace Hopper natively support the Unified Memory programming model through hardware-based memory coherence among all CPUs and GPUs. For such systems, HMM is not required, and in fact, HMM is automatically disabled there. One way to think about this is to observe that HMM is effectively a software-based way of providing the same programming model as an NVIDIA Grace Hopper Superchip.
To learn more about CUDA Unified Memory, see the resources section at the end of this post.
Unified Memory before HMM
The original CUDA Unified Memory feature introduced in 2013 enables you to accelerate a CPU program with only a few changes, as shown below:
Before HMM CPU only
void sortfile(FILE* fp, int N) {
char* data;
data = (char*)malloc(N);
fread(data, 1, N, fp);
qsort(data, N, 1, cmp);
use_data(data);
free(data);
}
After HMM CUDA Unified Memory (2013)
void sortfile(FILE* fp, int N) {
char* data;
cudaMallocManaged(&data, N);
fread(data, 1, N, fp);
qsort>>(data, N, 1, cmp);
cudaDeviceSynchronize();
use_data(data);
cudaFree(data);
}
This programming model is simple, clear, and powerful. Over the past 10 years, this approach has enabled countless applications to easily benefit from GPU acceleration. And yet, there is still room for improvement: note the need for a special allocator: cudaMallocManaged, and the corresponding cudaFree.
What if we could go even further, and get rid of those? That’s exactly what HMM does.
Unified Memory after HMM
On systems with HMM (detailed below), continue using malloc and free:
Before HMM CPU only
void sortfile(FILE* fp, int N) {
char* data;
data = (char*)malloc(N);
fread(data, 1, N, fp);
qsort(data, N, 1, cmp);
use_data(data);
free(data);
}
After HMM CUDA Unified Memory + HMM (2023)
void sortfile(FILE* fp, int N) {
char* data;
data = (char*)malloc(N);
fread(data, 1, N, fp);
qsort>>(data, N, 1, cmp);
cudaDeviceSynchronize();
use_data(data);
free(data)
}
With HMM, the memory management is now identical between the two.
System allocated memory and CUDA allocators
GPU applications using CUDA memory allocators work “as is” on systems with HMM. The main difference in these systems is that system allocation APIs like malloc, C++ new, or mmap now create allocations that may be accessed from GPU threads, without having to call any CUDA APIs to tell CUDA about the existence of these allocations. Table 1 captures the differences between the most common CUDA memory allocators on systems with HMM:
Memory allocatorson systems with HMM
Placement
Migratable
Accessible from:
CPU
GPU
RDMA
System allocated malloc, mmap, …
First-touch GPU or CPU
Y
Y
Y
Y
CUDA managed cudaMallocManaged
Y
Y
Y
N
CUDA device-only cudaMalloc, …
GPU
N
N
Y
Y
CUDA host-pinned cudaMallocHost, …
CPU
N
Y
Y
Y
Table 1. Overview of system and CUDA memory allocators on systems with HMM
In general, selecting the allocator that better expresses the application intent may enable CUDA to deliver better performance. With HMM, these choices become performance optimizations that do not need to be done upfront, before accessing the memory from the GPU for the first time. HMM enables developers to focus on parallelizing algorithms first, and performing memory allocator-related optimizations later, when their overhead improves performance.
Seamless GPU acceleration for C++, Fortran, and Python
HMM makes it significantly easier to program NVIDIA GPUs with standardized and portable programming languages like Python that do not distinguish between CPU and GPU memory and assume all threads may access all memory, as well as programming languages described by international standards like ISO Fortran and ISO C++.
These languages provide concurrency and parallelism facilities that enable implementations to automatically dispatch computations to GPUs and other devices. For example, since C++ 2017, the standard library algorithms from the header accept execution policies that enable implementations to run them in parallel.
Sorting a file in place from the GPU
For example, before HMM, sorting a file larger than CPU memory in-place was complicated, requiring sorting smaller parts of the file first, and merging them into a fully-sorted file afterwards. With HMM, the application may map the file on disk into memory using mmap, and read and write to it directly from the GPU. For more details, see the HMM sample code file_before.cpp and file_after.cpp on GitHub.
Before HMM Dynamic Allocation
void sortfile(FILE* fp, int N) {
std::vector buffer;
buffer.resize(N);
fread(buffer.data(), 1, N, fp);
// std::sort runs on the GPU:
std::sort(std::execution::par,
buffer.begin(), buffer.end(),
std::greater{});
use_data(std::span{buffer});
}
After HMM CUDA Unified Memory + HMM (2023)
void sortfile(int fd, int N) {
auto buffer = (char*)mmap(NULL, N,
PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
// std::sort runs on the GPU:
std::sort(std::execution::par,
buffer, buffer + N,
std::greater{});
use_data(std::span{buffer});
}
The NVIDIA C++ Compiler (NVC++) implementation of the parallel std::sort algorithm sorts the file on the GPU when using the -stdpar=gpu option. There are many restrictions on the use of this option, as detailed in the HPC SDK documentation.
Before HMM: GPU may only access dynamically allocated memory on the heap within code compiled by NVC++. That is, automatic variables on CPU thread stacks, global variables, and memory-mapped files are not accessible from the GPU (see examples below).
After HMM: GPU may access all system allocated memory, including data dynamically allocated on the heap in CPU code compiled by other compilers and third-party libraries, automatic variables on CPU thread stacks, global variables in CPU memory, memory-mapped files, and so on
Atomic memory operations and synchronization primitives
HMM supports all memory operations, which includes atomic memory operations. That is, programmers may use atomic memory operations to synchronize GPU and CPU threads with flags. While certain parts of the C++ std::atomic APIs use system calls that are not available on the GPU yet, such as std::atomic::wait and std::atomic::notify_all/_one APIs, most of the C++ concurrency primitive APIs are available and readily useful to perform message passing between GPU and CPU threads.
void main() {
// Variables allocated with cudaMallocManaged
std::atomic* flag;
int* msg;
cudaMallocManaged(&flag, sizeof(std::atomic));
cudaMallocManaged(&msg, sizeof(int));
new (flag) std::atomic(0);
*msg = 0;
// Start a different CPU thread…
auto t = std::jthread([&] {
// … that launches and waits
// on a GPU kernel completing
std::for_each_n(
std::execution::par,
&msg, 1, [&](int& msg) {
// GPU thread writes message…
*msg = 42; // all accesses via ptrs
// …and signals completion…
flag->store(1); // all accesses via ptrs
});
});
// CPU thread waits on GPU thread
while (flag->load() == 0); // all accesses via ptrs
// …and reads the message:
std::cout
After HMM CPU←→GPU message passing
void main() {
// Variables on CPU thread stack:
std::atomic flag = 0; // Atomic
int msg = 0; // Message
// Start a different CPU thread…
auto t = std::jthread([&] {
// … that launches and waits
// on a GPU kernel completing
std::for_each_n(
std::execution::par,
&msg, 1, [&](int& msg) {
// GPU thread writes message…
msg = 42;
// …and signals completion…
flag.store(1);
});
});
// CPU thread waits on GPU thread
while (flag.load() == 0);
// …and reads the message:
std::cout
Before HMM CPU←→GPU locks
void main() {
// Variables allocated with cudaMallocManaged
ticket_lock* lock; // Lock
int* msg; // Message
cudaMallocManaged(&lock, sizeof(ticket_lock));
cudaMallocManaged(&msg, sizeof(int));
new (lock) ticket_lock();
*msg = 0;
// Start a different CPU thread…
auto t = std::jthread([&] {
// … that launches and waits
// on a GPU kernel completing
std::for_each_n(
std::execution::par,
&msg, 1, [&](int& msg) {
// GPU thread takes lock…
auto g = lock->guard();
// … and sets message (no atomics)
msg += 1;
}); // GPU thread releases lock here
});
{ // Concurrently with GPU thread
// … CPU thread takes lock…
auto g = lock->guard();
// … and sets message (no atomics)
msg += 1;
} // CPU thread releases lock here
t.join(); // Wait on GPU kernel completion
std::cout
After HMM CPU←→GPU locks
void main() {
// Variables on CPU thread stack:
ticket_lock lock; // Lock
int msg = 0; // Message
// Start a different CPU thread…
auto t = std::jthread([&] {
// … that launches and waits
// on a GPU kernel completing
std::for_each_n(
std::execution::par,
&msg, 1, [&](int& msg) {
// GPU thread takes lock…
auto g = lock.guard();
// … and sets message (no atomics)
msg += 1;
}); // GPU thread releases lock here
});
{ // Concurrently with GPU thread
// … CPU thread takes lock…
auto g = lock.guard();
// … and sets message (no atomics)
msg += 1;
} // CPU thread releases lock here
t.join(); // Wait on GPU kernel completion
std::cout
Accelerate complex HPC workloads with HMM
Research groups working on large and long-lived HPC applications have yearned for years for more productive and portable programming models for heterogeneous platforms. m-AIA is a multi-physics solver spanning almost 300,000 lines of code developed at the Institute of Aerodynamics at RWTH Aachen, Germany. See Accelerating a C++ CFD Code with OpenACC for more information. Instead of using OpenACC for the initial prototype, it is now partially accelerated on GPUs using the ISO C++ programming model described above, which was not available when the prototype work was done.
HMM enabled our team to accelerate new m-AIA workloads that interface with GPU-agnostic third-party libraries such as FFTW and pnetcdf, which are used for initial conditions and I/O and are oblivious to the GPU directly accessing the same memory.
Leverage memory-mapped I/O for fast development
One of the interesting features that HMM provides is memory-mapped file I/O directly from the GPU. It enables developers to directly read files from supported storage or /disk without staging them in system memory and without copying the data to the high bandwidth GPU memory. This also enables application developers to easily process input data larger than the available physical system memory, without constructing an iterative data ingestion and computation workflow.
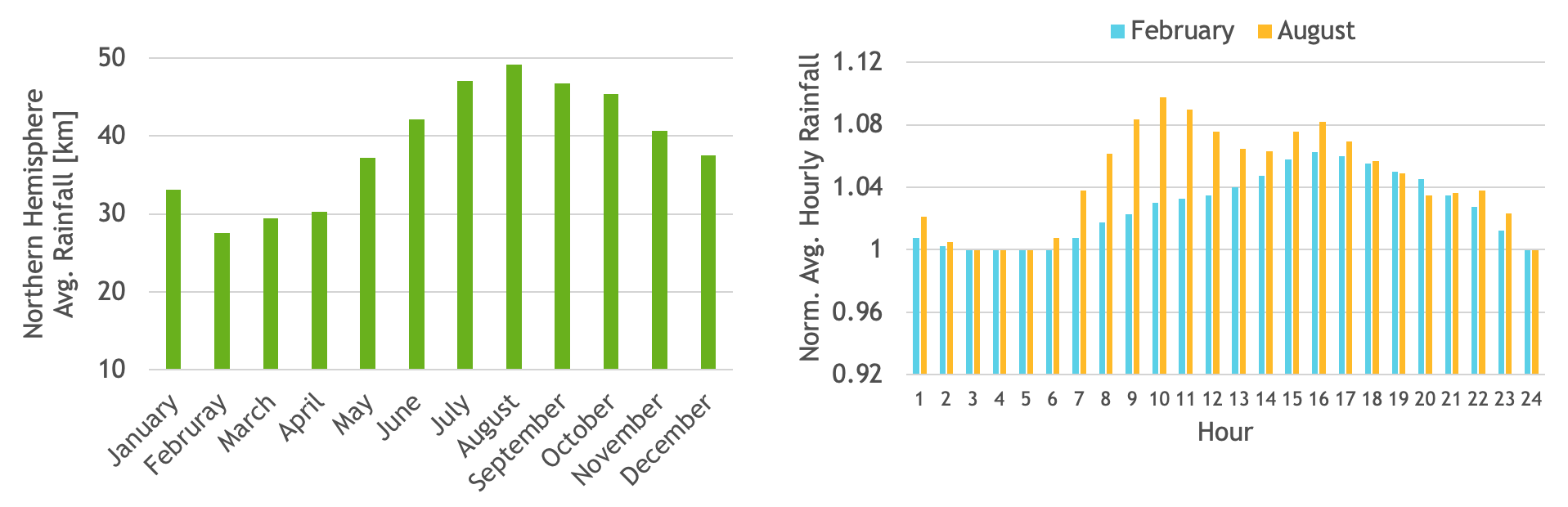
To demonstrate this functionality, our team wrote a sample application that builds a histogram of hourly total precipitation for every day of the year from the ERA5 reanalysis dataset. For more details, see The ERA5 global reanalysis.
The ERA5 dataset consists of hourly estimates of several atmospheric variables. In the dataset, total precipitation data for each month is stored in a separate file. We used 40 years of total precipitation data from 1981–2020, which sum to 480 input files aggregating to ~1.3 TB total input data size. See Figure 1 for example results.
Figure 1.Average monthly rainfall over the northern hemisphere (left) and normalized average hourly rainfall for the months of February and August (right)
Using the Unix mmap API, input files can be mapped to a contiguous virtual address space. With HMM, this virtual address can be passed as input to a CUDA kernel which can then directly access the values to build a histogram of total precipitation for each hour for all the days in a year.
The resulting histogram will reside in GPU memory and can be used to easily compute interesting statistics such as average monthly precipitation over the northern hemisphere. As an example, we also computed average hourly precipitation for the months of February and August. To see the code for this application, visit HMM_sample_code on GitHub.
Before HMM Batch and pipeline memory transfers
size_t chunk_sz = 70_gb;
std::vector buffer(chunk_sz);
for (fp : files)
for (size_t off = 0; off
histogram>>(dev, N, out);
cudaDeviceSynchronize();
}
The CUDA Toolkit and driver will automatically enable HMM whenever it detects that your system can handle it. The requirements are documented in detail in the CUDA 12.2 Release Notes: General CUDA. You’ll need:
To detect systems in which GPUs may access system allocated memory, query the cudaDevAttrPageableMemoryAccess.
In addition, systems such as the NVIDIA Grace Hopper Superchip support ATS, which has similar behavior to HMM. In fact, the programming model for HMM and ATS systems is the same, so merely checking for cudaDevAttrPageableMemoryAccess suffices for most programs.
However, for performance tuning and other advanced programming, it is possible to discern between HMM and ATS by also querying for cudaDevAttrPageableMemoryAccessUsesHostPageTables. Table 2 shows how to interpret the results.
Attribute
HMM
ATS
cudaDevAttrPageableMemoryAccess
1
1
cudaDevAttrPageableMemoryAccessUsesHostPageTables
0
1
Table 2. CUDA device attributes to query HMM and ATS support
For portable applications that are only interested in querying whether the programming model exposed by HMM or ATS is available, querying the ‘pageable memory access’ property usually suffices.
Unified Memory performance hints
There are no changes to the semantics of pre-existing Unified Memory performance hints. For applications that are already using CUDA Unified Memory on hardware-coherent systems like NVIDIA Grace Hopper, the main change is that HMM enables them to run “as is” on more systems within the limitations mentioned above.
The pre-existing Unified Memory hints also work with system allocated memory on HMM systems:
A preferred location for the memory: cudaMemAdviseSetPreferredLocation, or
A device that will access the memory: cudaMemAdviseSetAccessedBy, or
A device that will be mostly reading the memory that will be infrequently modified: cudaMemAdviseSetReadMostly.
A little more advanced: there is a new CUDA 12.2 API, cudaMemAdvise_v2, that enables applications to choose which NUMA node a given memory range should prefer. This comes into play when HMM places the memory contents on the CPU side.
As always, memory management hints may either improve or degrade performance. Behavior is application and workload dependent, but none of the hints impacts the correctness of the application.
Limitations of HMM in CUDA 12.2
The initial HMM implementation in CUDA 12.2 delivers new features without regressing the performance of any pre-existing applications. The limitations of HMM in CUDA 12.2 are documented in detail in the CUDA 12.2 Release Notes: General CUDA. The main limitations are:
HMM is only available for x86_64, and other CPU architectures are not yet supported.
GPU atomic operations on file-backed memory and HugeTLBfs memory are not supported.
fork(2) without a following exec(3) is not fully supported.
Page migrations are handled in chunks of 4 KB-page size.
Stay tuned for future CUDA driver updates that will address HMM limitations and improve performance.
Summary
HMM simplifies the programming model by removing the need for explicit memory management for GPU programs that run on common PCIe-based (x86, typically) computers. Programmers can simply use malloc, C++ new, and mmap calls directly, just as they already do for CPU programming.
HMM further boosts programmer productivity by enabling a wide variety of standard programming language features to be safely used within CUDA programs. There is no need to worry about accidentally exposing system allocated memory to a CUDA kernel.
HMM enables a seamless transition to and from the new NVIDIA Grace Hopper Superchip, and similar machines. On PCIe-based machines, HMM provides the same simplified programming model as that used on the NVIDIA Grace Hopper Superchip.
VMware Inc. and NVIDIA today announced the expansion of their strategic partnership to ready the hundreds of thousands of enterprises that run on VMware’s cloud infrastructure for the era of generative AI.
Servers Featuring NVIDIA L40S GPUs and NVIDIA BlueField Coming Soon From Dell Technologies, Hewlett Packard Enterprise and Lenovo to Support VMware Private AI Foundation with NVIDIALAS VEGAS, …






 The NVIDIA DOCA framework aims to simplify the programming and application development for NVIDIA BlueField DPUs and ConnectX SmartNICs. It provides high-level…
The NVIDIA DOCA framework aims to simplify the programming and application development for NVIDIA BlueField DPUs and ConnectX SmartNICs. It provides high-level…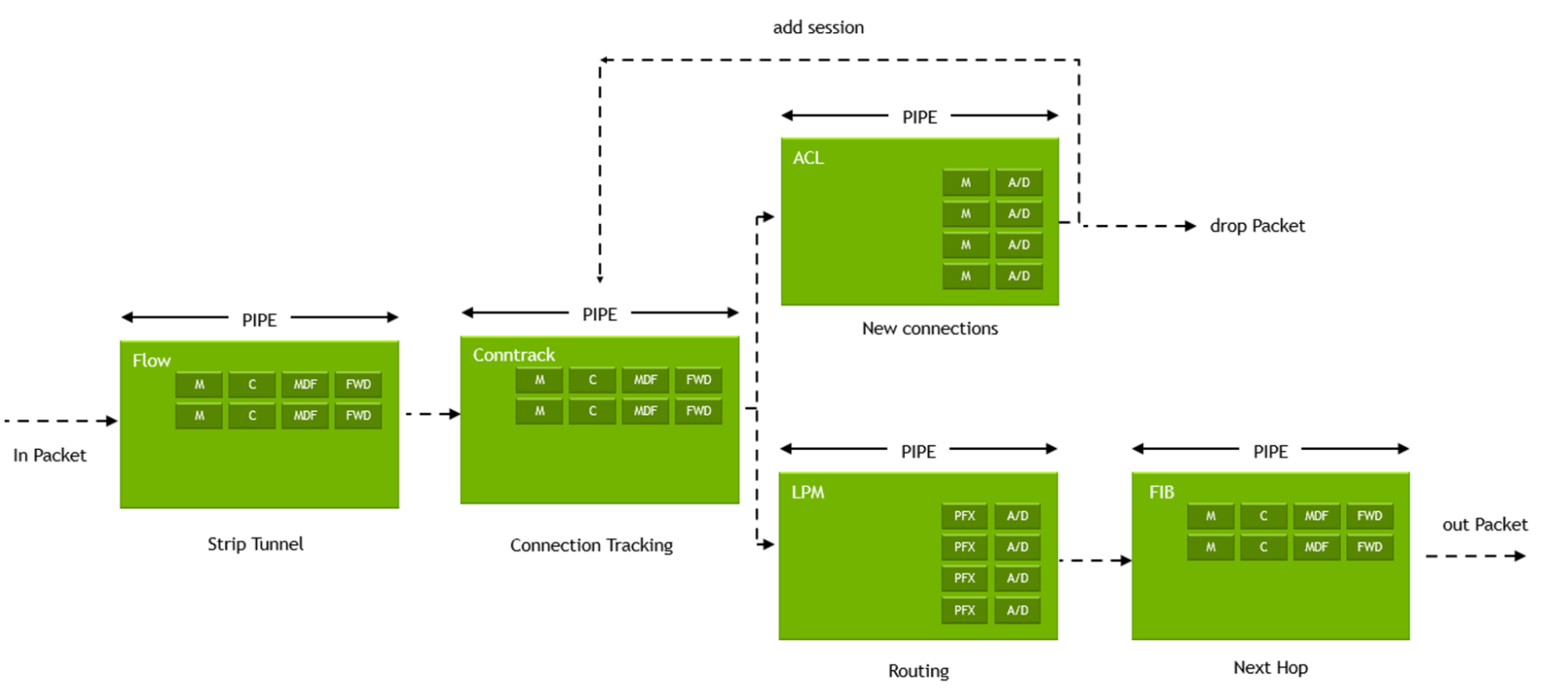
 Delve into how TMA Solutions is accelerating original ML and AI workflows with RAPIDS.
Delve into how TMA Solutions is accelerating original ML and AI workflows with RAPIDS. The advent of cloud computing has ushered in a paradigm shift in our data storage and utilization practices. Businesses can bypass the complexities of managing…
The advent of cloud computing has ushered in a paradigm shift in our data storage and utilization practices. Businesses can bypass the complexities of managing…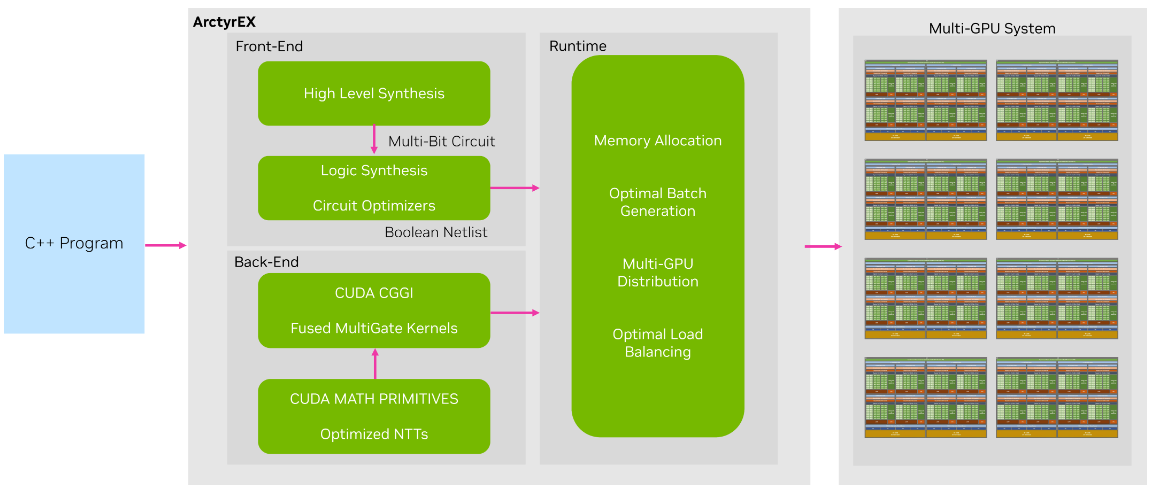


 Heterogeneous Memory Management (HMM) is a CUDA memory management feature that extends the simplicity and productivity of the CUDA Unified Memory programming…
Heterogeneous Memory Management (HMM) is a CUDA memory management feature that extends the simplicity and productivity of the CUDA Unified Memory programming…