![]() According to Gartner,® “Nearly half of digital workers struggle to find the data they need to do their jobs, and close to one-third have made a wrong business…
According to Gartner,® “Nearly half of digital workers struggle to find the data they need to do their jobs, and close to one-third have made a wrong business…![]()
According to Gartner,® “Nearly half of digital workers struggle to find the data they need to do their jobs, and close to one-third have made a wrong business decision due to lack of information awareness.”1 To address this challenge, more and more enterprises are deploying AI in customer service, as it helps to provide more efficient and information-based personalized services.
Technologies such as speech-to-text, text-to-speech, translation, deep learning, transformer models, and generative AI have changed how businesses interact with customers. These technologies enable:
- Real-time analysis of customer feedback
- Automation of customer interactions
- Accurate and personalized AI-based recommendations to assist human agents handle customer inquiries
AI algorithms can process and analyze vast amounts of data, identify customer needs and behavior patterns, and empower the creation of engaging and satisfying customer experiences. Overall, the use of AI in customer service has significantly improved the quality and efficiency of customer interactions, benefiting both businesses and customers.
Language barrier challenges in contact centers
In the global economy, businesses operate across countries and serve customers with diverse linguistic and cultural backgrounds. This global language diversity presents a unique challenge for contact centers.
Effective communication is critical to providing excellent customer service, and language barriers can lead to miscommunication, misunderstandings, and frustration. This can result in dissatisfied customers and missed business opportunities.
Traditional approaches to multilingual support, such as hiring native speakers, training agents in different languages, and providing language-specific scripts are not scalable, cost effective, or efficient.
However, advances in speech AI and translation AI technology are helping contact centers overcome language barriers through language neutralization. This innovation has been crucial for contact centers catering to diverse customers.
What is language neutralization?
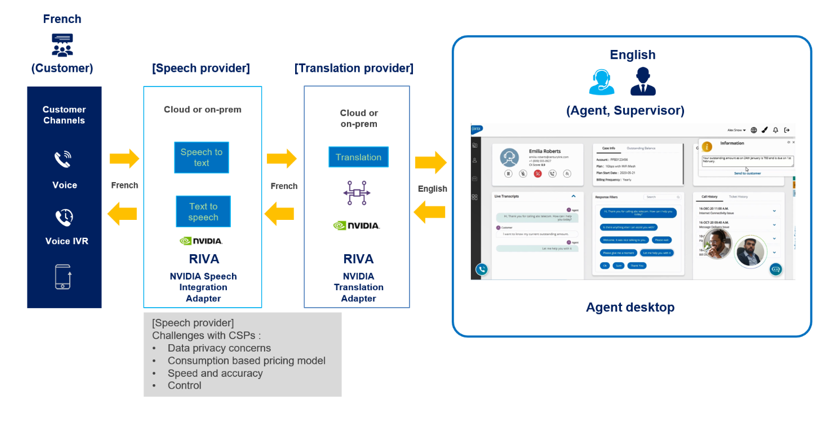
In the context of contact centers, language neutralization refers to the process of using transcription, translation, and speech synthesis (TTS) technologies to convert communication from a customer’s natural language to a language that an agent can understand. The agent then responds in their own language, which is again converted through transcription, translation, and speech synthesis, or a combination based on the scenario.
Language neutralization enables effective communication between parties who may not speak the same language, removing language barriers and facilitating smooth interaction. This technique involves advanced AI technologies to equip contact center agents with tools to help them understand customer queries and respond effectively.
Overcoming language barriers
Language neutralization is particularly important for contact centers that provide support services to customers from diverse linguistic and cultural backgrounds. Using language neutralization techniques, contact centers can effectively communicate with non-native speakers and provide them with the same level of service as native speakers.
Infosys Cortex language neutralization powered by NVIDIA Riva
Infosys Cortex, an AI-driven customer engagement platform, transforms contact center operations through purposeful communication and smart decision-making capabilities. With greater brain power and continuous coaching, Infosys Cortex helps employees make better and faster decisions on their journey from new hire to experienced agent.
Infosys Cortex leverages NVIDIA Riva, a cutting-edge speech and translation AI SDK, to power language neutralization capabilities. The world-class accuracy of Riva automatic speech recognition (ASR), neural machine translation (NMT), and engaging speech synthesis empower accurate and natural communication. Based on NVIDIA GPUs for model fine-tuning and processing, Riva enables a high-performance solution for contact centers.
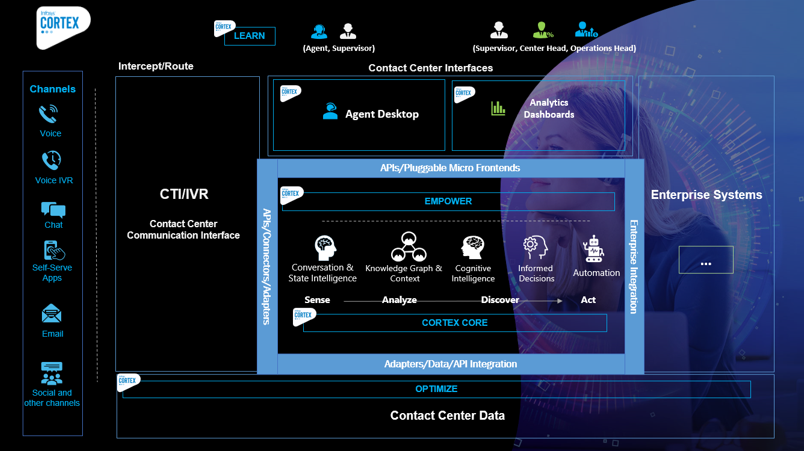
Cortex platform features
The microservices-based architecture of Infosys Cortex includes five key modules that offer the following features (Figure 1):
- Cortex Core: Sense, analyze, and generate actionable insights from data, and build new customer contexts along the way.
- Learn: Enable agent training with simulated learning features; based on historical call pipelines, training bank creations, learn-and-practice models, and follow-up actions.
- Empower: Provide proactive assistance to customers and agents using intelligent nudges based on transaction details, compliance, and real-time sentiment analysis to suggest the next best action.
- Experience: Integrate with CTI/IVR to create contact flows for self-service, virtual assistance, and intelligent routing to enhance the customer experience.
- Optimize: Generate insights through analyzing customer sentiment and interaction as well as agent behavior and performance.
Benefits and advantages
Riva services have been instrumental in addressing the key challenges Infosys has faced in relying on contact centers for customer service (Figure 2). The following are some key areas Riva addresses:
- Accuracy: Domain-specific language and product name customizations and fine-tuning different accents and pronunciation enable future-proof solutions.
- Language barrier: Support for 12 languages—Arabic, Chinese, English (US/UK), French, German, Italian, Japanese, Korean, Portuguese, Russian, and Spanish (LATAM/Spain)—with consistent addition of support for new languages.
- Data privacy: On-premises deployment enables mitigation of data privacy issues, helping to ensure that sensitive data is kept secure.
- Cost reduction: High-performance, efficient Riva models, along with flexible licensing, enable creation of cost-effective solutions as volumes increase.
- Control: Better means of improving Riva models with phonetic boosting and transfer learning for specific domains.
Overall, the advantages Riva models offer over managed services on the cloud include data privacy, predictable pricing, and better performance. In addition, the fine-tuning capabilities of Riva models enable further improvement of the model performance.
Language neutralization requires real-time integration with the CTI audio streams, and latency negatively impacts the experience. Riva on-premises models’ low latency is crucial, as every response must deal with transcription, translation, and synthesis flows at least once.
Key takeaways
Language neutralization is a transformative approach for contact centers, providing a scalable, cost-effective, and efficient solution for multilingual support.
The powerful language neutralization offered by Infosys Cortex and based on NVIDIA Riva speech and translation enables contact center agents to communicate effectively with customers and prevent misunderstandings and ambiguities.
Smoother customer-agent interaction leads to faster handling of issues and a reduction in wait time and backlog. Overall, the reduction in communication-based barriers results in contact centers reducing costs and increasing consistency, thus leading to greater customer satisfaction.
Developers can try Riva containers and pretrained models with a 90-day free trial through NGC. For production deployments, get unlimited usage on all clouds, enterprise-grade support, security, and API stability with the purchase of Riva, a premium edition of the NVIDIA AI Enterprise platform. Learn more.
1Gartner, Quick Answer: How Should Organizations Prepare for the Addition of Generative AI to the Microsoft Stack?, G00790185, 3/16/2023. GARTNER is a registered trademark and service mark of Gartner, Inc. and/or its affiliates in the U.S. and internationally and is used herein with permission. All rights reserved.






















.gif)
.gif)