Autonomous vehicle (AV) development requires massive amounts of sensor data for perception development. Developers typically get this data from two…
Autonomous vehicle (AV) development requires massive amounts of sensor data for perception development.
Developers typically get this data from two sources—replay streams of real-world drives or simulation. However, real-world datasets offer limited flexibility, as the data is fixed to only the objects, events, and view angles captured by the physical sensors. It is also difficult to simulate the detail and imperfection of real-world conditions—such as sensor noise or occlusions—at scale.
Neural fields have gained significant traction in recent years. These AI tools capture real-world content and simulate it from novel viewpoints with high levels of realism, achieving the fidelity and diversity required for AV simulation.
At NVIDIA GTC 2022, we showed how we use neural reconstruction to build a 3D scene from recorded camera sensor data in simulation, which can then be rendered from novel views. A paper we published for ICCV 2023—which runs Oct. 2 to Oct.6—details how we applied a similar approach to address these challenges in synthesizing lidar data.
Figure 1. An example novel viewpoint rendered by neural lidar fields
The method, called neural lidar fields, optimizes a neural radiance field (NeRF)-like representation from lidar measurements that enables synthesizing realistic lidar scans from entirely new viewpoints. It combines neural rendering with a physically based lidar model to accurately reproduce sensor behaviors—such as beam divergence, secondary returns, and ray dropping.
With neural lidar fields, we can achieve improved realism of novel views, narrowing the domain gap with real lidar data recordings. In doing so, we can improve the scalability of lidar sensor simulation and accelerate AV development.
By applying neural rendering techniques such as neural lidar fields in NVIDIA Omniverse, AV developers can bypass the time– and cost-intensive process of rebuilding real-world scenes by hand. They can bring physical sensors into a scalable and repeatable simulation.
Novel view synthesis
While replaying recorded data is a key component of testing and validation, it is critical to also simulate new scenarios for the AV system to experience.
These scenarios make it possible to test situations where the vehicle deviates from the original trajectory. It will view the world from novel views. This benefit also extends to testing a sensor suite on a different vehicle type, where the rig may be positioned differently (for example, switching from a sedan to an SUV).
With the ability to modify sensor properties such as beam divergence and ray pattern, we can also use a different lidar type in simulation than the sensor that originally recorded the data.
However, previous explicit approaches to simulating novel views have proven cumbersome and often inaccurate. First, surface representation—such as surfels or a triangular mesh—must be extracted from scanned lidar point clouds. Then, lidar measurements are simulated from a novel viewpoint by casting rays and intersecting them with the surface model.
These methods—known as explicit reconstruction—introduce noticeable errors in the rendering as well as assuming a perfect lidar model with no divergence of beams.
Neural lidar fields method
Rather than rely on an error-prone reconstruction pipeline, the neural lidar fields method takes a NeRF-style approach. It is based on neural scene representation and sensor modeling, which is directly optimized to render sensor measurements. This results in a more realistic output.
Specifically, we used an improved, lidar-specific volume rendering procedure, which creates range and intensity measurements from the 3D scene. Then, we added beam divergence for improved realism. We took into account that lidar works as an active sensor—rather than a passive one like a camera. This, along with characteristics such as beam divergence, enabled us to reproduce sensor properties, including dropped rays and multiple returns.
To test the accuracy of the neural lidar fields, we ran the scenes in a lidar simulator, comparing results with a variety of viewpoints taken at different distances from the original scan.
These scans were then compared with real data from the Waymo Open dataset, using metrics such as real-world intensities, ray drop, and secondary returns to evaluate fidelity. We also used real data to validate the accuracy of the neural lidar fields’ view synthesis in challenging scenes.
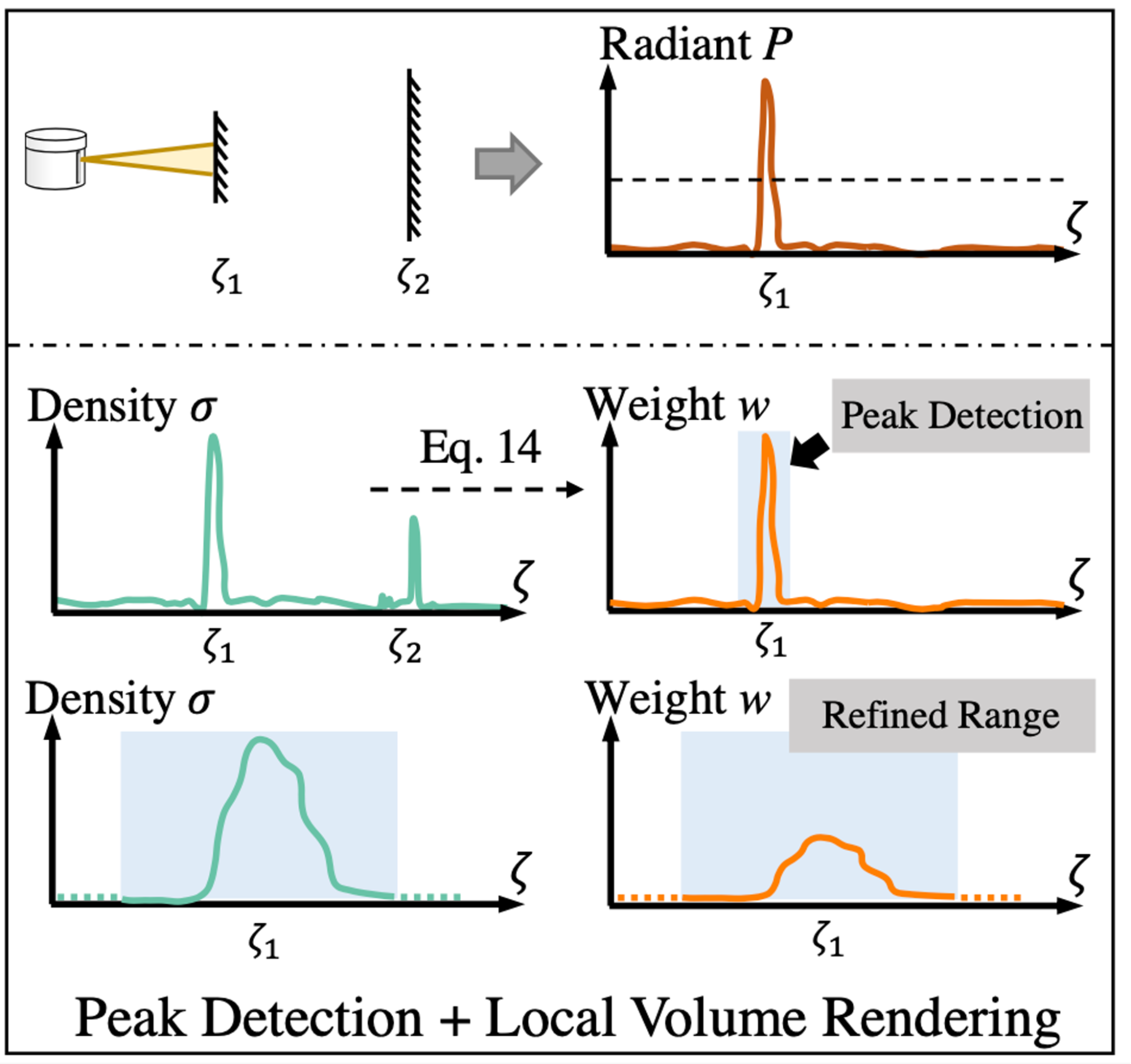
Figure 2. Neural lidar fields model the waveform
In Figure 2, the neural lidar fields accurately reproduce the waveform properties. The top row shows that the first surface fully scatters the lidar energy. The other rows shows that neural lidar fields estimate range through peak detection on the computed weights followed by volume rendering-based range refinement.
Results
Using these evaluation methods, we compared neural lidar field-synthesized lidar views with traditional reconstruction processes.
By accounting for real-world lidar characteristics, neural lidar field views reduced range errors and improved performance compared with explicit reconstruction. We also found the implicit method synthesized challenging scenes with high accuracy.
After we established performance, we then validated the neural lidar field-generated scans using two low-level perception tasks: point cloud registration and semantic segmentation.
We applied the same model to both real-world lidar scans and various synthesized scans to evaluate how well the scans maintained accuracy. We found that neural lidar fields outperformed the baseline methods on datasets with complex geometry and high noise levels.
Figure 3. Qualitative visualization of lidar novel view synthesis on the Waymo dataset.
For semantic segmentation, we applied the same pretrained model to both real and synthetic lidar scans. Neural lidar fields achieved the highest recall for vehicles, which are especially difficult to render due to sensor noise such as dual returns and ray drops.
While neural lidar fields are still an active research method, it is a critical tool for scalable AV simulation. Next, we plan to focus on generalizing the networks across scenes and handling dynamic environments. Eventually, developers on Omniverse and the NVIDIA DRIVE Sim AV simulator will be able to tap into these AI-powered approaches for accelerated and physically based simulation.
We would like to thank our collaborators at ETH Zurich, Shengyu Huang and Konrad Schindler, as well as Zan Gojcic, Zian Wang, Francis Williams, Yoni Kasten, Sanja Fidler, and Or Litany from the NVIDIA Research team.
Machine learning-based weather prediction has emerged as a promising complement to traditional numerical weather prediction (NWP) models. Models such as NVIDIA…
Machine learning-based weather prediction has emerged as a promising complement to traditional numerical weather prediction (NWP) models. Models such as NVIDIA FourCastNet have demonstrated that the computational time for generating weather forecasts can be reduced from hours to mere seconds, a significant improvement to current NWP-based workflows.
Traditional methods are formulated from first principles and typically require a timestep restriction to guarantee the accuracy of the underlying numerical method. ML-based approaches do not come with such restrictions, and their uniform memory access patterns are ideally suited for GPUs.
However, these methods are purely data-driven, and you may rightfully ask:
How can we trust these models?
How well do they generalize?
How can we further increase their skill, trustworthiness, and explainability, if they are not formulated from first principles?
Figure 1: 5-month-long rollout of SFNO. Surface windspeed predictions with SFNO and ground truth data are compared to each other.
A potential approach to creating principled and trustworthy models involves formulating them in a manner akin to the formulation of physical laws.
Physical laws are typically formulated from symmetry considerations:
We do not expect physics to depend on the frame of reference.
We further expect underlying physical laws to remain unchanged if the frame of reference is altered.
In the context of physical systems on the sphere, changes in the frame of reference are accomplished through rotations. Thus, we strive to establish a formulation that remains equivariant under rotations.
Current ML-based weather prediction models treat the state of the atmosphere as a discrete series of vectors representing physical quantities of interest at various spatial locations over time. Any of these vectors are updated by a learned function, which maps the current state to the next state in the sequence.
In plain terms, we ask a neural network to consecutively predict the weather in the next time step when showing it the weather of today. This is comparable to the integration of a physical system using traditional methods, with the caveat of having learned the dynamics in a purely data-driven manner, as opposed to deriving them from physical laws. This approach enables significantly larger time steps as opposed to traditional methods.
The task at hand can thus be understood as learning image-to-image mappings between finite-dimensional vector spaces.
While a broad variety of neural network topologies such as U-Nets are applicable to this task, such approaches ignore the functional nature of the problem. Both input and output are functions and their evolution is governed by partial differential equations.
Traditional ML approaches such as U-Nets ignore this, as they learn a map at a fixed resolution. Neural operators generalize neural networks to solve this problem. Rather than learning maps between finite-dimensional spaces, they learn an operator that can directly map one function to another.
As such, Fourier neural operators (FNOs) provide a powerful framework for learning maps between function spaces and approximating the solution operator of PDEs, which maps one state to the next.
However, classical FNOs are defined in Cartesian space, whose associated symmetries differ from those of the sphere. In practice, ignoring the geometry and pretending that Earth is a periodic rectangle leads to artifacts, which accumulate on long rollouts, due to the autoregressive nature of the model. Such artifacts typically occur around the poles and lead to a breakdown of the model (Figure 2).
You may now wonder, what would an FNO on a sphere look like?
Figure 2. Temperature predictions using AFNO vs. SFNO
Figure 2 shows temperature predictions using adaptive Fourier neural operators (AFNO) as compared to spherical Fourier neural operators (SFNO). Respecting the spherical geometry and associated symmetries avoids artifacts and enables a stable rollout.
Spherical Fourier neural operators
To respect the spherical geometry of Earth, we implemented spherical Fourier neural operators (SFNOs), a Fourier neural operator that is directly formulated in spherical coordinates. To achieve this, we made use of a convolution theorem formulated on the sphere.
Global convolutions are the central building blocks of FNOs. Their computation through FFTs is enabled by the convolution theorem: a powerful mathematical tool that connects convolutions to the Fourier transform.
Similarly, a convolution theorem on the sphere connects spherical convolutions to the generalization of the Fourier transform on the sphere: the spherical harmonic transform (SHT).
To enable the implementation of SFNOs, we required a differentiable SHT. To this end, we implemented torch-harmonics, a PyTorch library for differentiable SHTs. The library natively supports the computation of SHTs on single and multiple GPUs as well as CPUs, to enable scalable model parallelism. torch-harmonics can be installed easily by running the following command:
pip install torch-harmonics
torch-harmonics seamlessly integrates with PyTorch. The differentiable SHT can be easily integrated into any existing ML architecture as a module. To compute the SHT of a random function, run the following code example:
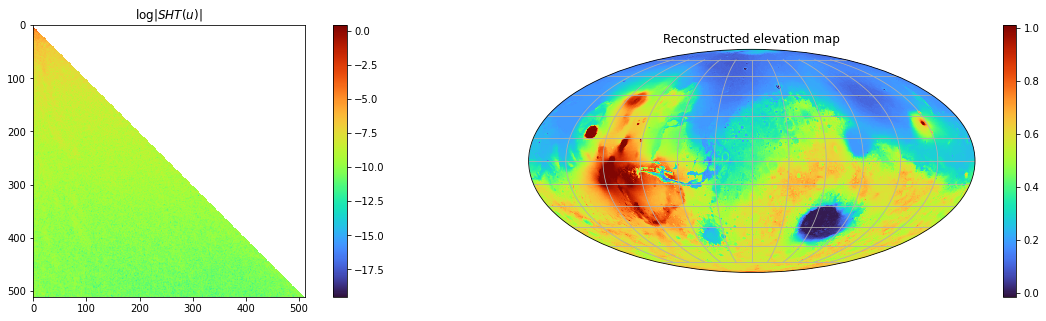
To get started with torch-harmonics, we recommend the getting-started notebook, which guides you through the computation of the spherical harmonic coefficients of Mars’ elevation map (Figure 3). The example showcases the computation of the coefficients using both the SHT and the differentiability of the ISHT.
Figure 3. Spherical harmonic coefficients of the elevation map of Mars, computed with torch-harmonics (left). Reconstructed signal computed with the inverse spherical harmonic transform (right).
Implications for ML-based weather forecasting
We trained SFNOs on the ERA5 dataset, provided by the European Centre for Medium-range Weather Forecasts (ECMWF). This dataset represents our best understanding of the state of Earth’s atmosphere over the past 44 years. Figure 2 shows that SFNO shows no signs of artifacts over the poles and rollouts remain remarkably stable, over thousands of autoregressive steps, for up to a year (Figure 1).
These results pave the way for the deployment of ML-based weather prediction methods. They offer a glimpse of how ML-based methods may hold the key to bridging the gap between weather forecasting and climate prediction, in the holy grail of sub-seasonal-to-seasonal forecasting.
A single rollout of SFNOs for a year, which involves 1460 autoregressive steps, is computed in 13 minutes on a single NVIDIA RTX A6000. That is over a thousand times faster than traditional numerical weather prediction methods.
Such substantially faster forecasting tools open the door to the computation of thousands of possible scenarios in the same time that it took to do a single one using traditional NWP, enabling higher confidence predictions of the risk of rare but high-impact extreme weather events.
More about SFNOs and the NVIDIA Earth-2 initiative
To see how SFNOs were used to generate thousands of ensemble members and predict the 2018 Algerian heat wave, watch the following video:
Video 1. Predicting Extreme Weather Risk Three Weeks in Advance with FourCastNet
For more information about SFNOs, see the following resources:
AI is improving ways to power the world by tapping the sun and the wind, along with cutting-edge technologies. The latest episode in the I AM AI video series showcases how artificial intelligence can help optimize solar and wind farms, simulate climate and weather, enhance power grid reliability and resilience, advance carbon capture and power Read article >
Get ready for Gunfire Games and Gearbox Publishing’s highly anticipated Remnant II, available for members to stream on GeForce NOW at launch. It leads eight new games coming to the cloud gaming platform. Ultimate and Priority members, make sure to grab the Guild Wars 2 rewards, available now through Thursday, Aug. 31. Visit the GeForce Read article >
ServiceNow (NYSE: NOW), NVIDIA (NASDAQ: NVDA), and Accenture (NYSE: ACN) today announced the launch of AI Lighthouse, a first-of-its-kind program designed to fast-track the development and adoption of enterprise generative AI capabilities.
AWS users can now access the leading performance demonstrated in industry benchmarks of AI training and inference. The cloud giant officially switched on a new Amazon EC2 P5 instance powered by NVIDIA H100 Tensor Core GPUs. The service lets users scale generative AI, high performance computing (HPC) and other applications with a click from a Read article >
Posted by Eleni Triantafillou, Research Scientist, and Malik Boudiaf, Student Researcher, Google
Deep learning has recently made tremendous progress in a wide range of problems and applications, but models often fail unpredictably when deployed in unseen domains or distributions. Source-free domain adaptation (SFDA) is an area of research that aims to design methods for adapting a pre-trained model (trained on a “source domain”) to a new “target domain”, using only unlabeled data from the latter.
Designing adaptation methods for deep models is an important area of research. While the increasing scale of models and training datasets has been a key ingredient to their success, a negative consequence of this trend is that training such models is increasingly computationally expensive, out of reach for certain practitioners and also harmful for the environment. One avenue to mitigate this issue is through designing techniques that can leverage and reuse already trained models for tackling new tasks or generalizing to new domains. Indeed, adapting models to new tasks is widely studied under the umbrella of transfer learning.
SFDA is a particularly practical area of this research because several real-world applications where adaptation is desired suffer from the unavailability of labeled examples from the target domain. In fact, SFDA is enjoying increasing attention [1, 2, 3, 4]. However, albeit motivated by ambitious goals, most SFDA research is grounded in a very narrow framework, considering simple distribution shifts in image classification tasks.
In a significant departure from that trend, we turn our attention to the field of bioacoustics, where naturally-occurring distribution shifts are ubiquitous, often characterized by insufficient target labeled data, and represent an obstacle for practitioners. Studying SFDA in this application can, therefore, not only inform the academic community about the generalizability of existing methods and identify open research directions, but can also directly benefit practitioners in the field and aid in addressing one of the biggest challenges of our century: biodiversity preservation.
In this post, we announce “In Search for a Generalizable Method for Source-Free Domain Adaptation”, appearing at ICML 2023. We show that state-of-the-art SFDA methods can underperform or even collapse when confronted with realistic distribution shifts in bioacoustics. Furthermore, existing methods perform differently relative to each other than observed in vision benchmarks, and surprisingly, sometimes perform worse than no adaptation at all. We also propose NOTELA, a new simple method that outperforms existing methods on these shifts while exhibiting strong performance on a range of vision datasets. Overall, we conclude that evaluating SFDA methods (only) on the commonly-used datasets and distribution shifts leaves us with a myopic view of their relative performance and generalizability. To live up to their promise, SFDA methods need to be tested on a wider range of distribution shifts, and we advocate for considering naturally-occurring ones that can benefit high-impact applications.
Distribution shifts in bioacoustics
Naturally-occurring distribution shifts are ubiquitous in bioacoustics. The largest labeled dataset for bird songs is Xeno-Canto (XC), a collection of user-contributed recordings of wild birds from across the world. Recordings in XC are “focal”: they target an individual captured in natural conditions, where the song of the identified bird is at the foreground. For continuous monitoring and tracking purposes, though, practitioners are often more interested in identifying birds in passive recordings (“soundscapes”), obtained through omnidirectional microphones. This is a well-documented problem that recentwork shows is very challenging. Inspired by this realistic application, we study SFDA in bioacoustics using a bird species classifier that was pre-trained on XC as the source model, and several “soundscapes” coming from different geographical locations — Sierra Nevada (S. Nevada); Powdermill Nature Reserve, Pennsylvania, USA; Hawai’i; Caples Watershed, California, USA; Sapsucker Woods, New York, USA (SSW); and Colombia — as our target domains.
This shift from the focalized to the passive domain is substantial: the recordings in the latter often feature much lower signal-to-noise ratio, several birds vocalizing at once, and significant distractors and environmental noise, like rain or wind. In addition, different soundscapes originate from different geographical locations, inducing extreme label shifts since a very small portion of the species in XC will appear in a given location. Moreover, as is common in real-world data, both the source and target domains are significantly class imbalanced, because some species are significantly more common than others. In addition, we consider a multi-label classification problem since there may be several birds identified within each recording, a significant departure from the standard single-label image classification scenario where SFDA is typically studied.
Illustration of the “focal → soundscapes” shift. In the focalized domain, recordings are typically composed of a single bird vocalization in the foreground, captured with high signal-to-noise ratio (SNR), though there may be other birds vocalizing in the background.On the other hand, soundscapes contain recordings from omnidirectional microphones and can be composed of multiple birds vocalizing simultaneously, as well as environmental noises from insects, rain, cars, planes, etc.
Illustration of the distribution shift from the focal domain (left) to the soundscape domain (right), in terms of the audio files (top) and spectrogram images (bottom) of a representative recording from each dataset. Note that in the second audio clip, the bird song is very faint; a common property in soundscape recordings where bird calls aren’t at the “foreground”. Credits: Left: XC recording by Sue Riffe (CC-BY-NC license). Right: Excerpt from a recording made available by Kahl, Charif, & Klinck. (2022) “A collection of fully-annotated soundscape recordings from the Northeastern United States” [link] from the SSW soundscape dataset (CC-BY license).
State-of-the-art SFDA models perform poorly on bioacoustics shifts
As a starting point, we benchmark six state-of-the-art SFDA methods on our bioacoustics benchmark, and compare them to the non-adapted baseline (the source model). Our findings are surprising: without exception, existing methods are unable to consistently outperform the source model on all target domains. In fact, they often underperform it significantly.
As an example, Tent, a recent method, aims to make models produce confident predictions for each example by reducing the uncertainty of the model’s output probabilities. While Tent performs well in various tasks, it doesn’t work effectively for our bioacoustics task. In the single-label scenario, minimizing entropy forces the model to choose a single class for each example confidently. However, in our multi-label scenario, there’s no such constraint that any class should be selected as being present. Combined with significant distribution shifts, this can cause the model to collapse, leading to zero probabilities for all classes. Other benchmarked methods like SHOT, AdaBN, Tent, NRC, DUST and Pseudo-Labelling, which are strong baselines for standard SFDA benchmarks, also struggle with this bioacoustics task.
Evolution of the test mean average precision (mAP), a standard metric for multilabel classification, throughout the adaptation procedure on the six soundscape datasets. We benchmark our proposed NOTELA and Dropout Student (see below), as well as SHOT, AdaBN, Tent, NRC, DUST and Pseudo-Labelling. Aside from NOTELA, all other methods fail to consistently improve the source model.
Introducing NOisy student TEacher with Laplacian Adjustment (NOTELA)
Nonetheless, a surprisingly positive result stands out: the less celebrated Noisy Student principle appears promising. This unsupervised approach encourages the model to reconstruct its own predictions on some target dataset, but under the application of random noise. While noise may be introduced through various channels, we strive for simplicity and use model dropout as the only noise source: we therefore refer to this approach as Dropout Student (DS). In a nutshell, it encourages the model to limit the influence of individual neurons (or filters) when making predictions on a specific target dataset.
DS, while effective, faces a model collapse issue on various target domains. We hypothesize this happens because the source model initially lacks confidence in those target domains. We propose improving DS stability by using the feature space directly as an auxiliary source of truth. NOTELA does this by encouraging similar pseudo-labels for nearby points in the feature space, inspired by NRC’s method and Laplacian regularization. This simple approach is visualized below, and consistently and significantly outperforms the source model in both audio and visual tasks.
NOTELA in action. The audio recordings are forwarded through the full model to obtain a first set of predictions, which are then refined through Laplacian regularization, a form of post-processing based on clustering nearby points. Finally, the refined predictions are used as targets for the noisy model to reconstruct.
Conclusion
The standard artificial image classification benchmarks have inadvertently limited our understanding of the true generalizability and robustness of SFDA methods. We advocate for broadening the scope and adopt a new assessment framework that incorporates naturally-occurring distribution shifts from bioacoustics. We also hope that NOTELA serves as a robust baseline to facilitate research in that direction. NOTELA’s strong performance perhaps points to two factors that can lead to developing more generalizable models: first, developing methods with an eye towards harder problems and second, favoring simple modeling principles. However, there is still future work to be done to pinpoint and comprehend existing methods’ failure modes on harder problems. We believe that our research represents a significant step in this direction, serving as a foundation for designing SFDA methods with greater generalizability.
Acknowledgements
One of the authors of this post, Eleni Triantafillou, is now at Google DeepMind. We are posting this blog post on behalf of the authors of the NOTELA paper: Malik Boudiaf, Tom Denton, Bart van Merriënboer, Vincent Dumoulin*, Eleni Triantafillou* (where * denotes equal contribution). We thank our co-authors for the hard work on this paper and the rest of the Perch team for their support and feedback.
1Note that in this audio clip, the bird song is very faint; a common property in soundscape recordings where bird calls aren’t at the “foreground”. ↩
The world increasingly runs on code. Accelerating the work of those who create that code will boost their productivity — and that’s just what AI startup Codeium, a member of NVIDIA’s Inception program for startups, aims to do. On the latest episode of NVIDIA’s AI Podcast, host Noah Kravitz interviewed Codeium founder and CEO Varun Read article >
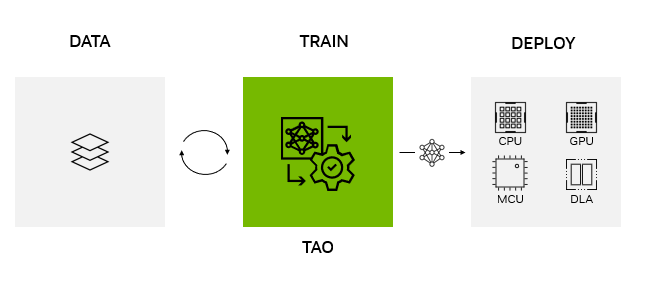
NVIDIA TAO Toolkit provides a low-code AI framework to accelerate vision AI model development suitable for all skill levels, from novice beginners to expert…
NVIDIA TAO Toolkit provides a low-code AI framework to accelerate vision AI model development suitable for all skill levels, from novice beginners to expert data scientists. With the TAO Toolkit, developers can use the power and efficiency of transfer learning to achieve state-of-the-art accuracy and production-class throughput in record time with adaptation and optimization.
NVIDIA released TAO Toolkit 5.0, bringing groundbreaking features to enhance any AI model development. The new features include source-open architecture, transformer-based pretrained models, AI-assisted data annotation, and the capability to deploy models on any platform.
Release highlights include:
Model export in open ONNX format to support deployment on GPUs, CPUs, MCUs, neural accelerators, and more.
Advanced Vision Transformer training for better accuracy and robustness against image corruption and noise.
New AI-assisted data annotation, accelerating labeling tasks for segmentation masks.
Support for new computer vision tasks and pretrained models for optical inspection, such as optical character detection and Siamese Network models.
Open source availability for customizable solutions, faster development, and integration.
This post has been revised from its original version to provide accurate information reflecting the TAO Toolkit 5.0 release.
Figure 1. NVIDIA TAO Toolkit workflow diagram
Deploy NVIDIA TAO models on any platform, anywhere
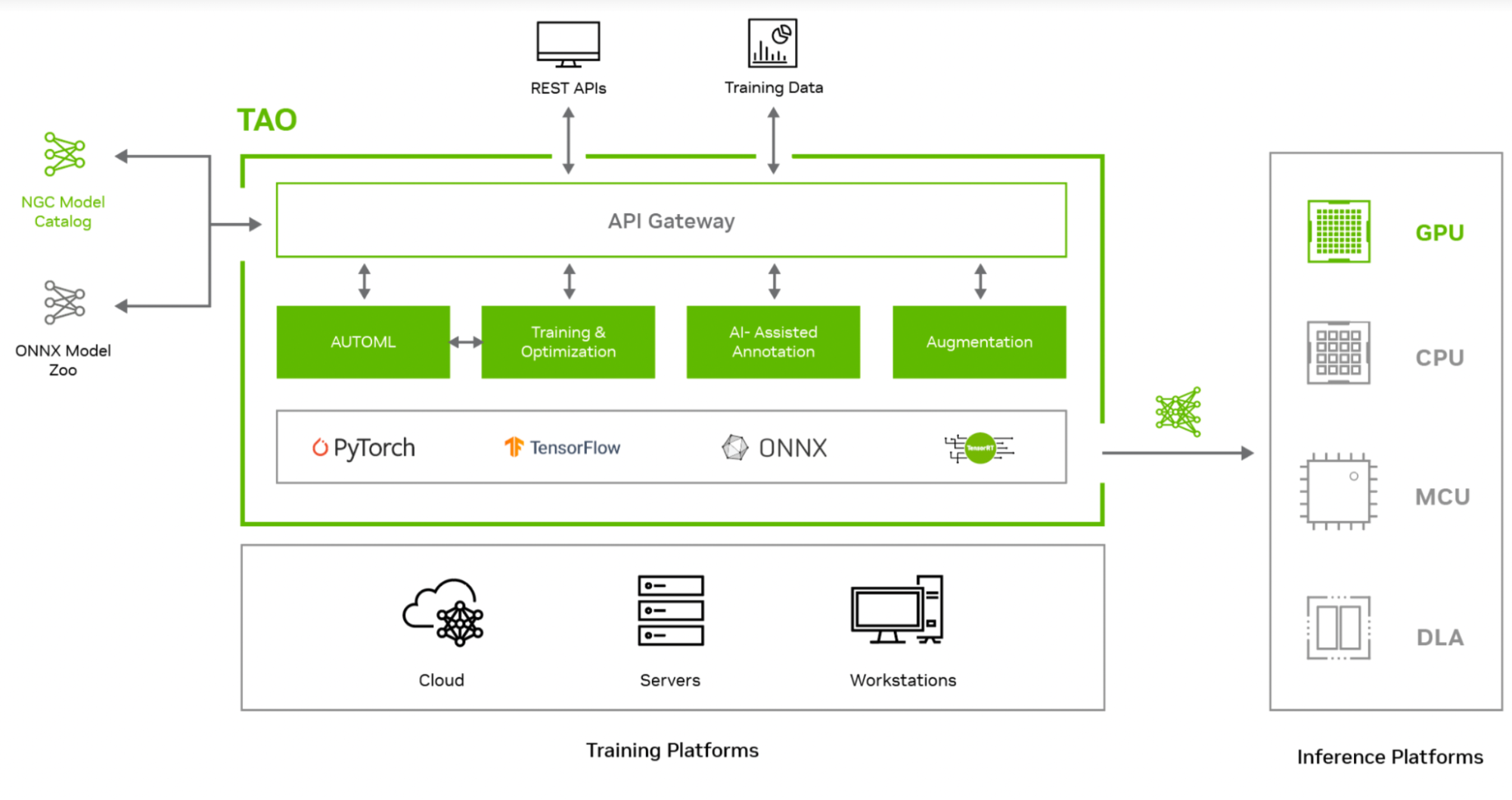
NVIDIA TAO Toolkit 5.0 supports model export in ONNX. This makes it possible to deploy a model trained with NVIDIA TAO Toolkit on any computing platform—GPUs, CPUs, MCUs, DLAs, FPGAs—at the edge or in the cloud. NVIDIA TAO Toolkit simplifies the model training process and optimizes the model for inference throughput, powering AI across hundreds of billions of devices.
Figure 2. NVIDIA TAO Toolkit architecture
Edge Impulse, a platform for building, refining, and deploying machine learning models and algorithms, integrated TAO Toolkit into their edge AI platform. With this integration, Edge Impulse now offers advanced vision AI capabilities and models that complement its current offerings. Developers can use the platform to build production AI with TAO for any edge device. Learn more about the integration in a blog post from Edge Impulse.
Video 1. Training an AI model with the Edge Impulse platform leveraging NVIDIA TAO and deployed on a Cortex-M7 MCU
STMicroelectronics, a global leader in embedded microcontrollers, integrated NVIDIA TAO Toolkit into its STM32Cube AI developer workflow. This puts the latest AI capabilities into the hands of millions of STMicroelectronics developers. It provides, for the first time, the ability to integrate sophisticated AI into widespread IoT and edge use cases powered by the STM32Cube.
Now, with NVIDIA TAO Toolkit, even the most novice AI developers can optimize and quantize AI models to run on STM32 MCU within the microcontroller’s compute and memory budget. Developers can also bring their own models and fine-tune using TAO Toolkit. More information about this work is captured in the following demo. Learn more about the project on the STMicroelectronics GitHub page.
Video 2. Learn how to deploy a model optimized with TAO Toolkit on an STM microcontroller
While TAO Toolkit models can run on any platform, these models achieve the highest throughput on NVIDIA GPUs using TensorRT for inference. On CPUs, these models use ONNX-RT for inference. The script and recipe to replicate these numbers will be provided once the software becomes available.
NVIDIA Jetson Orin Nano 8 GB
NVIDIA Jetson AGX Orin 64 GB
T4
A2
A100
L4
H100
PeopleNet
112
679
429
242
3,264
797
7,062
DINO – FAN-S
3.1
11.2
20.4
11.7
121
44
213
SegFormer – MiT
1.3
4.8
9.4
5.8
62.2
17.8
108
OCRNet
935
3,876
3,649
2,094
28,300
8,036
55,700
EfficientDet
61
227
303
184
1,521
522
2,428
2D Body Pose
136
557
593
295
4,140
1,010
7,812
3D Action Recognition
52
212
269
148
1,658
529
2,708
Table 1. Performance comparison (in FPS) of several NVIDIA TAO Toolkit vision models, including new Vision Transformer models on NVIDIA GPUs
AI-assisted data annotation and management
Data annotation remains an expensive and time-consuming process for all AI projects. This is especially true for CV tasks like segmentation that require generating a segmentation mask at pixel level around the object. Generally, segmentation masks cost 10x more than object detection or classification.
It is faster and less expensive to annotate segmentation masks with new AI-assisted annotation capabilities using TAO Toolkit 5.0. Now you can use the weakly supervised segmentation architecture, Mask Auto Labeler (MAL) to aid in segmentation annotation and in fixing and tightening bounding boxes for object detection. Loose bounding boxes around an object in ground truth data can lead to suboptimal detection results. But, with AI-assisted annotation, you can tighten your bounding boxes over objects, leading to more accurate models.
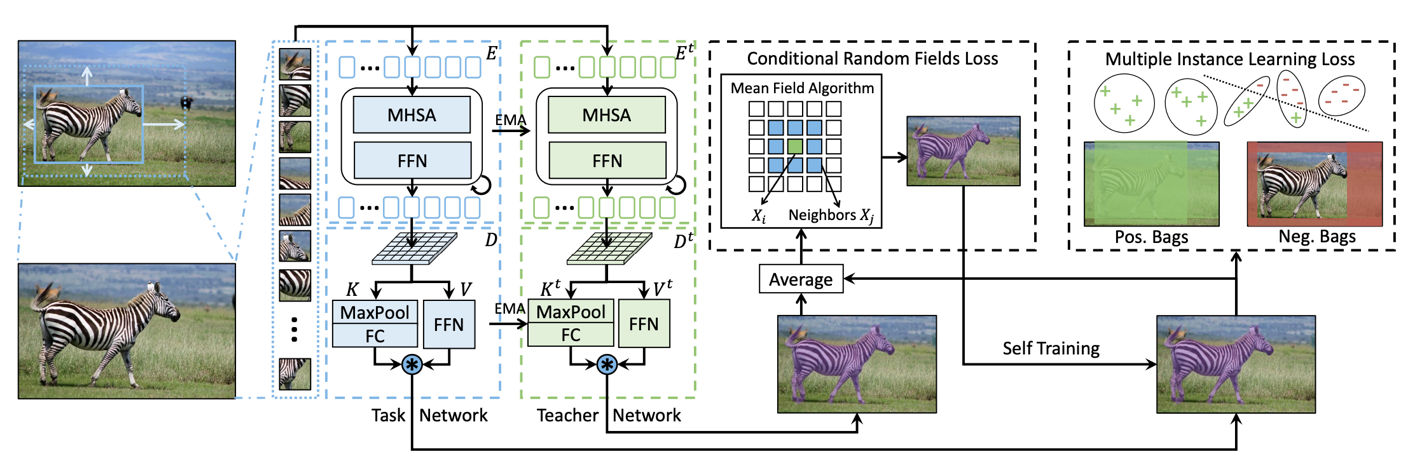
Figure 3. TAO Toolkit auto labeling
MAL is a transformer-based, mask auto-labeling framework for instance segmentation using only box annotations. MAL takes box-cropped images as inputs and conditionally generates the mask pseudo-labels. It uses COCO annotation format for both input and output labels.
MAL significantly reduces the gap between auto labeling and human annotation for mask quality. Instance segmentation models trained using the MAL-generated masks can nearly match the performance of the fully supervised counterparts, retaining up to 97.4% performance of fully supervised models.
Figure 4. MAL network architecture
When training the MAL network, a task network and a teacher network (sharing the same transformer structure) work together to achieve class-agnostic self-training. This enables refining the prediction masks with conditional random field (CRF) loss and multi-instance learning (MIL) loss.
TAO Toolkit uses MAL in both the auto-labeling pipeline and data augmentation pipeline. Specifically, users can generate pseudo-masks on the spatially augmented images (sheared or rotated, for example), and refine and tighten the corresponding bounding boxes using the generated masks.
State-of-the-art Vision Transformers
Transformers have become the standard architecture in NLP, largely because of self-attention. They have also gained popularity for a range of vision AI tasks. In general, transformer-based models can outperform traditional CNN-based models due to their robustness, generalizability, and ability to perform parallelized processing of large-scale inputs. All of this increases training efficiency, provides better robustness against image corruption and noise, and generalizes better on unseen objects.
TAO Toolkit 5.0 features several state-of-the-art (SOTA) Vision Transformers for popular CV tasks, as detailed below.
Fully Attentional Network
Fully Attentional Network (FAN) is a transformer-based family of backbones from NVIDIA Research that achieves SOTA in robustness against various corruptions. This family of backbones can easily generalize to new domains and be more robust to noise, blur, and more.
A key design behind the FAN block is the attentional channel processing module that leads to robust representation learning. FAN can be used for image classification tasks as well as downstream tasks such as object detection and segmentation.
Figure 5. An activation heat map on a corrupted image for ResNet50 (center) compared to FAN-Small (right)
The FAN family supports four backbones, as shown in Table 2.
Model
# of parameters/FLOPs
Accuracy
FAN-Tiny
7 M/3.5 G
71.7
FAN-Small
26 M/6.7
77.5
FAN-Base
50 M/11.3 G
79.1
FAN-Large
77 M/16.9 G
81.0
Table 2. FAN backbones with size and accuracy
Global Context Vision Transformer
Global Context Vision Transformer (GC-ViT) is a novel architecture from NVIDIA Research that achieves very high accuracy and compute efficiency. GC-ViT addresses the lack of inductive bias in Vision Transformers. It achieves better results on ImageNet with a smaller number of parameters through the use of local self-attention.
Local self-attention paired with global context self-attention can effectively and efficiently model both long and short-range spatial interactions. Figure 6 shows the GC-ViT model architecture. For more details, see Global Context Vision Transformers.
Figure 6. GC-ViT model architecture
As shown in Table 3, the GC-ViT family contains six backbones, ranging from GC-ViT-xxTiny (compute efficient) to GC-ViT-Large (very accurate). GC-ViT-Large models can achieve Top-1 accuracy of 85.6 on the ImageNet-1K dataset for image classification tasks. This architecture can also be used as the backbone for other CV tasks like object detection and semantic and instance segmentation.
Model
# of parameters/FLOPs
Accuracy
GC-ViT-xxTiny
12 M/2.1 G
79.6
GC-ViT-xTiny
20 M/2.6 G
81.9
GC-ViT-Tiny
28 M/4.7 G
83.2
GC-ViT-Small
51 M/8.5 G
83.9
GC-ViT-Base
90 M/14.8 G
84.4
GC-ViT-Large
201 M/32.6 G
85.6
Table 3. GC-ViT backbones with size and accuracy
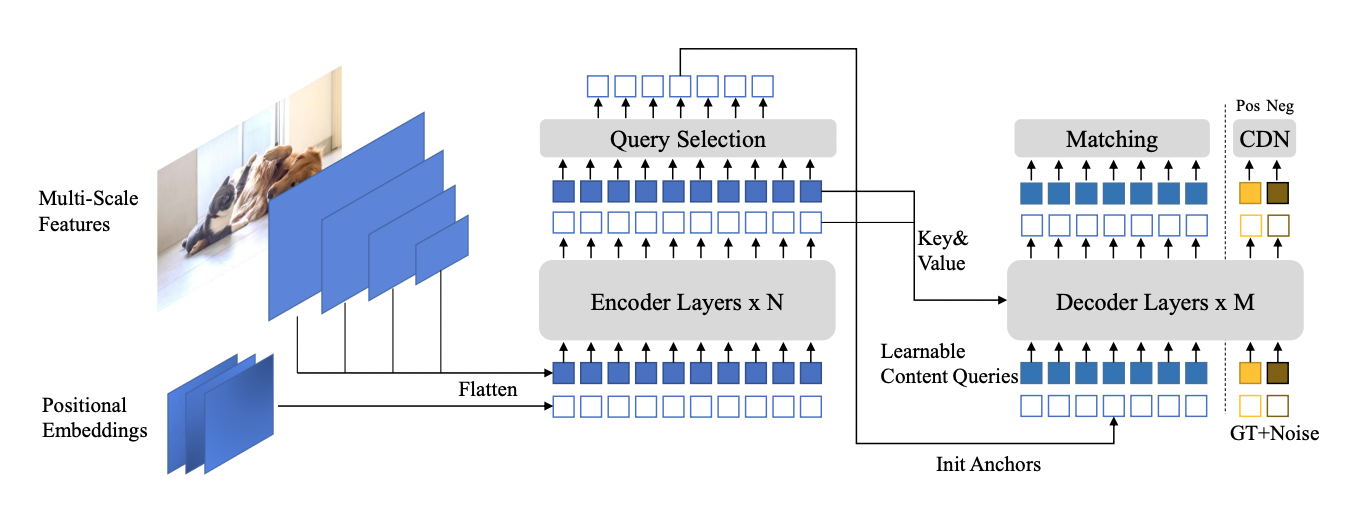
DINO
DINO (detectiontransformer with improved denoising anchor) is the newest generation of detection transformers (DETR). It achieves a faster training convergence time than its predecessor. Deformable-DETR (D-DETR) requires at least 50 epochs to converge, while DINO can converge in 12 epochs on the COCO dataset. It also achieves higher accuracy when compared with D-DETR.
DINO achieves faster convergence through the use of denoising during training, which helps the bipartite matching process at the proposal generation stage. The training convergence of DETR-like models is slow due to the instability of bipartite matching. Bipartite matching removed the need for handcrafted and compute-heavy NMS operations. However, it often required much more training because incorrect ground truths were matched to the predictions during bipartite matching.
DINO in TAO Toolkit is flexible and can be combined with various backbones from traditional CNNs, such as ResNets, and transformer-based backbones like FAN and GC-ViT. Table 4 shows the accuracy of the COCO dataset on various versions of DINO with popular YOLOv7. For more details, see YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors.
Model
Backbone
AP
AP50
AP75
APS
APM
APL
Param
YOLOv7
N/A
51.2
69.7
55.5
35.2
56.0
66.7
36.9M
DINO
ResNet50
48.8
66.9
53.4
31.8
51.8
63.4
46.7M
FAN-Small
53.1
71.6
57.8
35.2
56.4
68.9
48.3M
GCViT-Tiny
50.7
68.9
55.3
33.2
54.1
65.8
46.9M
Table 4. DINO and D-DETR accuracy on the COCO dataset
SegFormer
SegFormer is a lightweight transformer-based semantic segmentation. The decoder is made of lightweight MLP layers. It avoids using positional encoding (mostly used by transformers), which makes the inference efficient at different resolutions.
Adding FAN backbone to SegFormer MLP decoder results in a highly robust and efficient semantic segmentation model. FAN base hybrid + SegFormer was the winning architecture at the Robust Vision Challenge 2022 for semantic segmentation.
Figure 8. SegFormer with FAN prediction (right) on a noisy input image (left)
Model
Dataset
Mean IOU (%)
Retention rate (robustness) (%)
PSPNet
Cityscapes Validation
78.8
43.8
SegFormer – FAN-S-Hybrid
Cityscapes validation
81.5
81.5
Table 5. Robustness of SegFormer compared to PSPNet
See how SegFormer generates robust semantic segmentation while maintaining high efficiency for accelerated autonomous vehicle development in the following video.
Video 3. NVIDIA DRIVE Labs episode, Enhancing AI Segmentation Models for Autonomous Vehicle Safety
CV tasks beyond object detection and segmentation
NVIDIA TAO Toolkit accelerates a wide range of CV tasks beyond traditional object detection and segmentation. The new character detection and recognition models in TAO Toolkit 5.0 enable developers to extract text from images and documents. This automates document conversion and accelerates use cases in industries like insurance and finance.
Detecting anomalies in images is useful when the object being classified varies greatly, such that training with all the variations is impossible. In industrial inspection, for example, a defect can come in any form. Using a simple classifier could result in many missed defects if the defect has not been previously seen by the training data.
For such use cases, comparing the test object directly against a golden reference would result in better accuracy. TAO Toolkit 5.0 features a Siamese neural network in which the model calculates the difference between the object under test and a golden reference to classify if the object is defective.
Automate training using AutoML for hyperparameter optimization
Automated machine learning (autoML) automates the manual task of finding the best models and hyperparameters for the desired KPI on a given dataset. It can algorithmically derive the best model and abstract away much of the complexity of AI model creation and optimization.
AutoML in TAO Toolkit is fully configurable for automatically optimizing the hyperparameters of a model. It caters to both AI experts and nonexperts. For nonexperts, the guided Jupyter Notebook provides a simple, efficient way to create an accurate AI model.
For experts, TAO Toolkit gives you full control of which hyperparameters to tune and which algorithm to use for sweeps. TAO Toolkit currently supports two optimization algorithms: Bayesian and Hyperband optimization. These algorithms can sweep across a range of hyperparameters to find the best combination for a given dataset.
AutoML is supported for a wide range of CV tasks, including several new Vision Transformers such as DINO, D-DETR, SegFormer, and more. Table 6 shows the full list of supported networks (bold items are new to TAO Toolkit 5.0).
Image classification
Object detection
Segmentation
Other
FAN
DINO
SegFormer
LPRNet
GC-ViT
D-DETR
UNET
ResNet
YoloV3/V4/V4-Tiny
MaskRCNN
EfficientNet
EfficientDet
DarkNet
RetinaNet
MobileNet
FasterRCNN
DetectNet_v2
SSD/DSSD
Table 6. Models supported by AutoML in TAO Toolkit, including several new Vision Transformer models (bold items are new to TAO Toolkit 5.0)
REST APIs for workflow integration
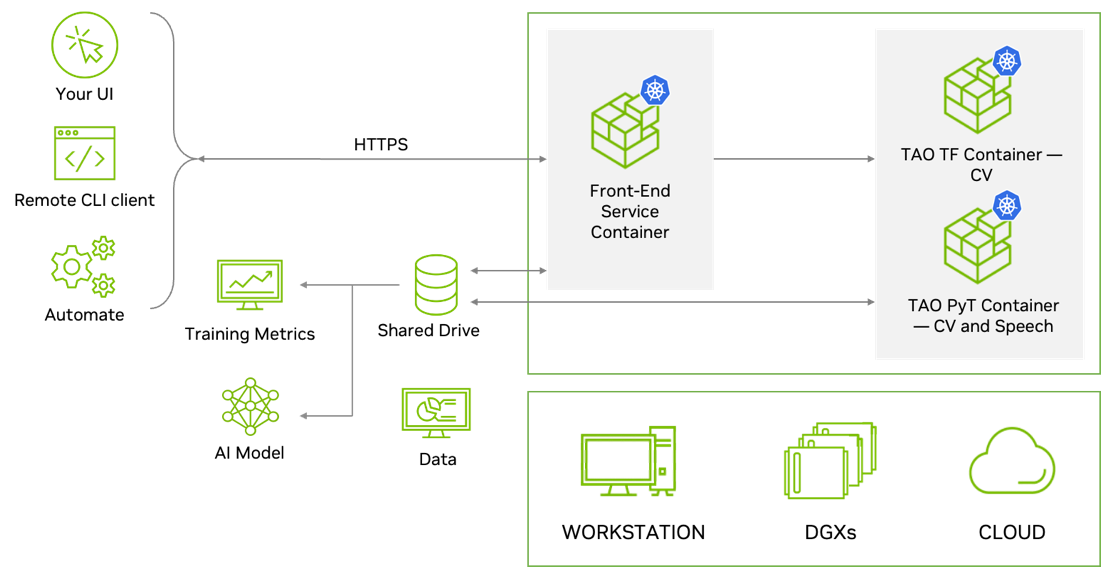
TAO Toolkit is modular and cloud-native, meaning it is available as containers and can be deployed and managed using Kubernetes. TAO Toolkit can be deployed as a self-managed service on any public or private cloud, DGX, or workstation. TAO Toolkit provides well-defined REST APIs, making it easy to integrate into your development workflow. Developers can call the API endpoints for all training and optimization tasks. These API endpoints can be called from any application or user interface, which can trigger training jobs remotely.
Figure 9. TAO Toolkit architecture for cloud native deployment
Better inference optimization
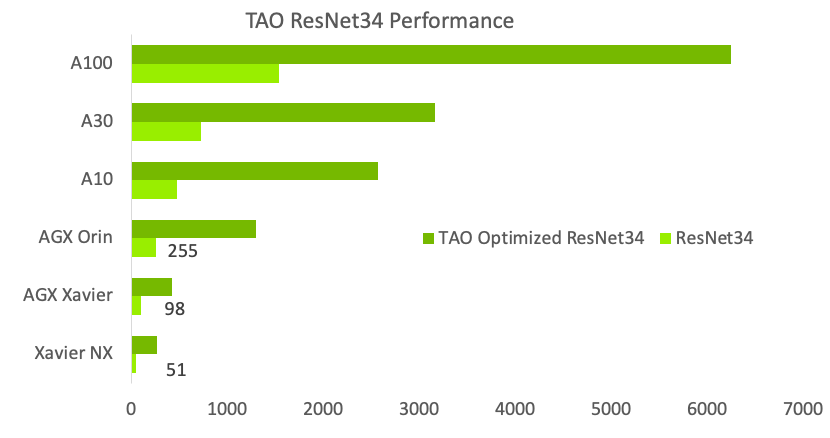
To simplify productization and increase inference throughput, TAO Toolkit provides several turnkey performance optimization techniques. These include model pruning, lower precision quantization, and TensorRT optimization, which can combine to deliver a 4x to 8x performance boost, compared to a comparable model from public model zoos.
Figure 10. Performance comparison between TAO Toolkit optimized and public models on a wide range of GPUs
Open and flexible, with better support
An AI model predicts output based on complex algorithms. This can make it difficult to understand how the system arrived at its decision and challenging to debug, diagnose, and fix errors. Explainable AI (XAI) aims to address these challenges by providing insights into how AI models arrive at their decisions. This helps humans understand the reasoning behind the AI output and makes it easier to diagnose and fix errors. This transparency can help to build trust in AI systems.
To help with transparency and explainability, TAO Toolkit will now be available as source-open. Developers will be able to view feature maps from internal layers, as well as plot activation heat maps to better understand the reasoning behind AI predictions. In addition, having access to the source code will give developers the flexibility to create customized AI, improve debug capability, and increase trust in their models.
NVIDIA TAO Toolkit is enterprise-ready and available through NVIDIA AI Enterprise (NVAIE). NVAIE provides companies with business-critical support, access to NVIDIA AI experts, and priority security fixes. Join NVAIE to get support from AI experts.
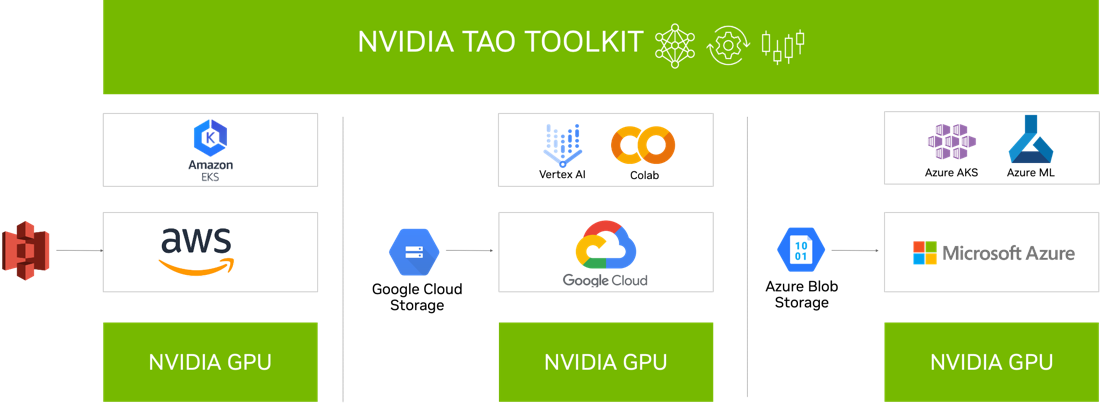
Integration with cloud services
NVIDIA TAO Toolkit 5.0 is integrated into various AI services that you might already use, such as Google Vertex AI, AzureML, Azure Kubernetes service, Google GKE, and Amazon EKS.
Figure 11. TAO Toolkit 5.0 is integrated with various AI services
Summary
TAO Toolkit offers a platform for any developer, in any service, and on any device to easily transfer-learn their custom models, perform quantization and pruning, manage complex training workflows, and perform AI-assisted annotation with no coding requirements.

 Autonomous vehicle (AV) development requires massive amounts of sensor data for perception development. Developers typically get this data from two…
Autonomous vehicle (AV) development requires massive amounts of sensor data for perception development. Developers typically get this data from two…

 Machine learning-based weather prediction has emerged as a promising complement to traditional numerical weather prediction (NWP) models. Models such as NVIDIA…
Machine learning-based weather prediction has emerged as a promising complement to traditional numerical weather prediction (NWP) models. Models such as NVIDIA…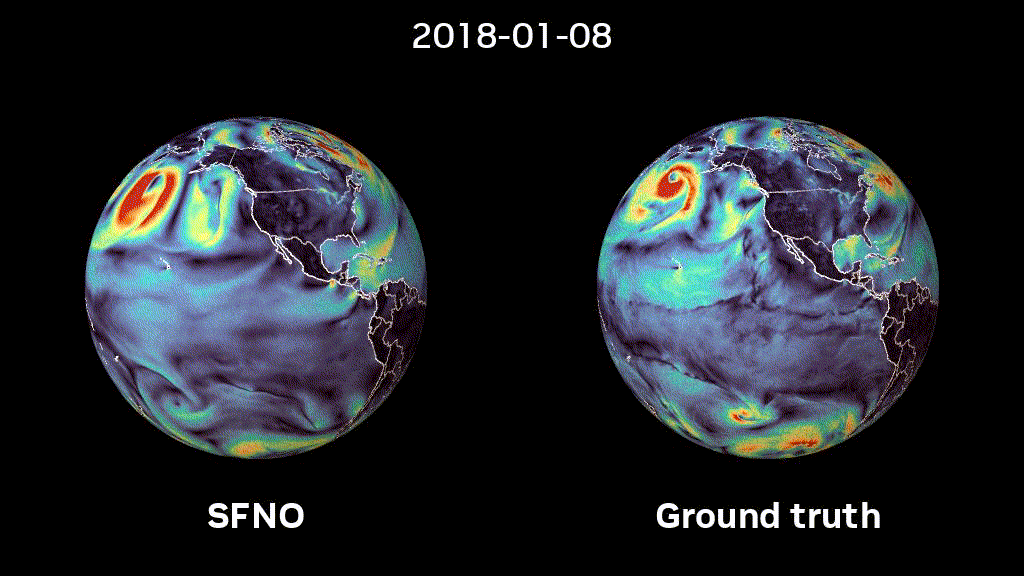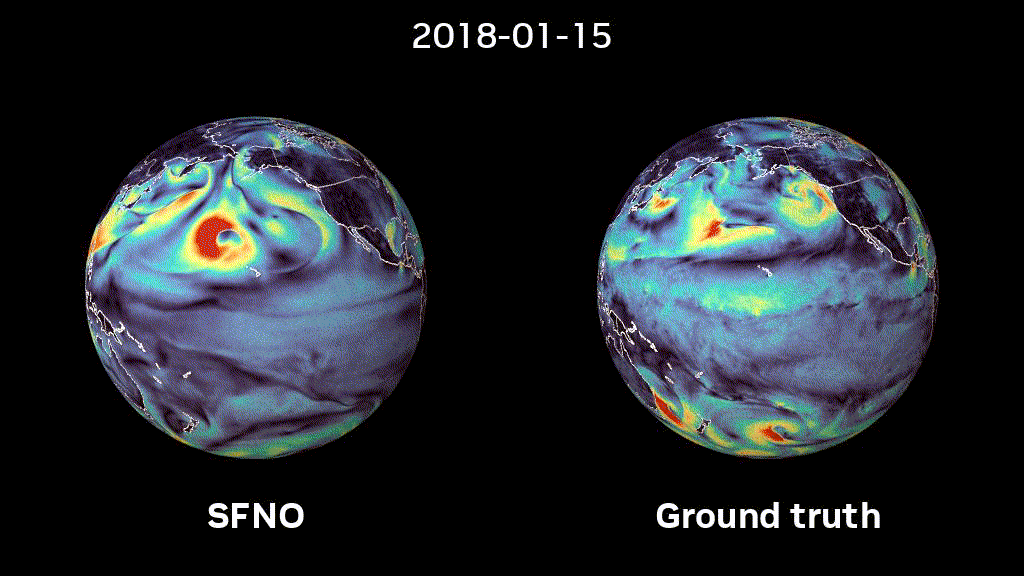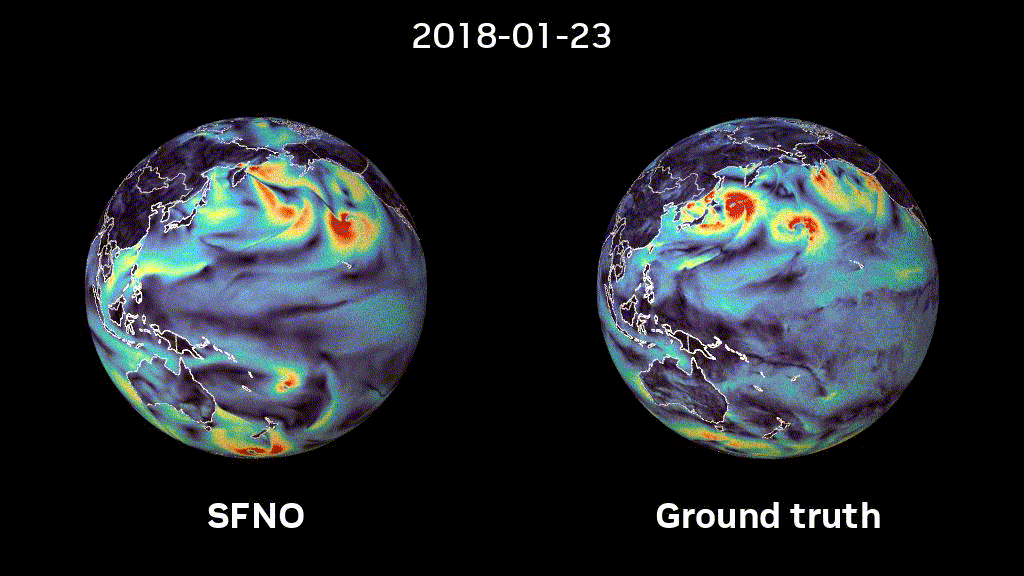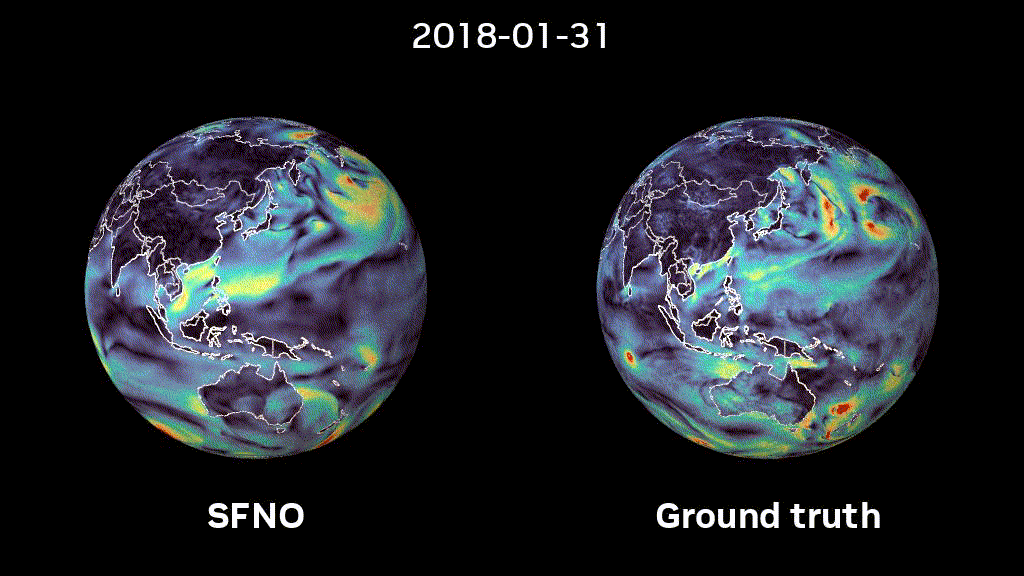








 On July 26, connect with CUDA product team experts on the latest NVIDIA CUDA Toolkit 12.
On July 26, connect with CUDA product team experts on the latest NVIDIA CUDA Toolkit 12.  NVIDIA TAO Toolkit provides a low-code AI framework to accelerate vision AI model development suitable for all skill levels, from novice beginners to expert…
NVIDIA TAO Toolkit provides a low-code AI framework to accelerate vision AI model development suitable for all skill levels, from novice beginners to expert…