Posted by Jason Wei and Yi Tay, Research Scientists, Google Research, Brain Team
The field of natural language processing (NLP) has been revolutionized by language models trained on large amounts of text data. Scaling up the size of language models often leads to improved performance and sample efficiency on a range of downstream NLP tasks. In many cases, the performance of a large language model can be predicted by extrapolating the performance trend of smaller models. For instance, the effect of scale on language model perplexity has been empirically shown to span more than seven orders of magnitude.
On the other hand, performance for certain other tasks does not improve in a predictable fashion. For example, the GPT-3 paper showed that the ability of language models to perform multi-digit addition has a flat scaling curve (approximately random performance) for models from 100M to 13B parameters, at which point the performance jumped substantially. Given the growing use of language models in NLP research and applications, it is important to better understand abilities such as these that can arise unexpectedly.
In “Emergent Abilities of Large Language Models,” recently published in the Transactions on Machine Learning Research (TMLR), we discuss the phenomena of emergent abilities, which we define as abilities that are not present in small models but are present in larger models. More specifically, we study emergence by analyzing the performance of language models as a function of language model scale, as measured by total floating point operations (FLOPs), or how much compute was used to train the language model. However, we also explore emergence as a function of other variables, such as dataset size or number of model parameters (see the paper for full details). Overall, we present dozens of examples of emergent abilities that result from scaling up language models. The existence of such emergent abilities raises the question of whether additional scaling could potentially further expand the range of capabilities of language models.
Emergent Prompted Tasks
First we discuss emergent abilities that may arise in prompted tasks. In such tasks, a pre-trained language model is given a prompt for a task framed as next word prediction, and it performs the task by completing the response. Without any further fine-tuning, language models can often perform tasks that were not seen during training.
Example of few-shot prompting on movie review sentiment classification. The model is given one example of a task (classifying a movie review as positive or negative) and then performs the task on an unseen example.
We call a prompted task emergent when it unpredictably surges from random performance to above-random at a specific scale threshold. Below we show three examples of prompted tasks with emergent performance: multi-step arithmetic, taking college-level exams, and identifying the intended meaning of a word. In each case, language models perform poorly with very little dependence on model size up to a threshold at which point their performance suddenly begins to excel.
The ability to perform multi-step arithmetic (left), succeed on college-level exams (middle), and identify the intended meaning of a word in context (right) all emerge only for models of sufficiently large scale. The models shown include LaMDA, GPT-3, Gopher, Chinchilla, and PaLM.
Performance on these tasks only becomes non-random for models of sufficient scale — for instance, above 1022 training FLOPs for the arithmetic and multi-task NLU tasks, and above 1024 training FLOPs for the word in context tasks. Note that although the scale at which emergence occurs can be different for different tasks and models, no model showed smooth improvement in behavior on any of these tasks. Dozens of other emergent prompted tasks are listed in our paper.
Emergent Prompting Strategies
The second class of emergent abilities encompasses prompting strategies that augment the capabilities of language models. Prompting strategies are broad paradigms for prompting that can be applied to a range of different tasks. They are considered emergent when they fail for small models and can only be used by a sufficiently-large model.
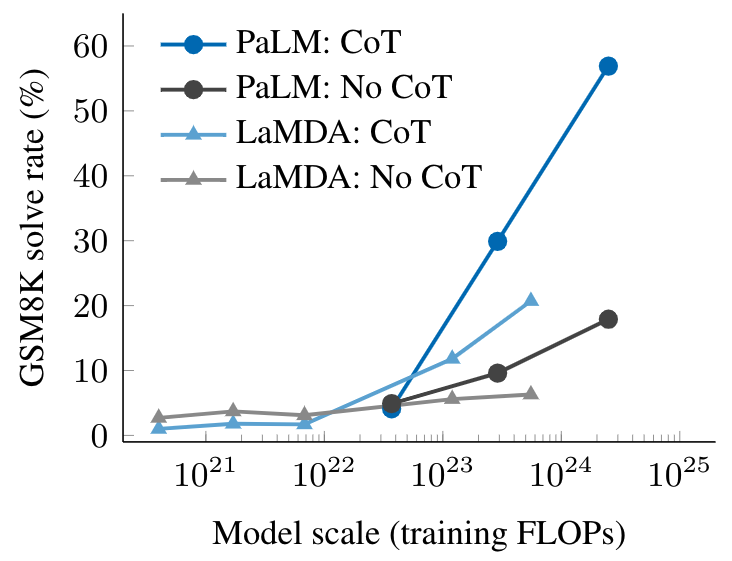
One example of an emergent prompting strategy is called “chain-of-thought prompting”, for which the model is prompted to generate a series of intermediate steps before giving the final answer. Chain-of-thought prompting enables language models to perform tasks requiring complex reasoning, such as a multi-step math word problem. Notably, models acquire the ability to do chain-of-thought reasoning without being explicitly trained to do so. An example of chain-of-thought prompting is shown in the figure below.
Chain of thought prompting enables sufficiently large models to solve multi-step reasoning problems.
The empirical results of chain-of-thought prompting are shown below. For smaller models, applying chain-of-thought prompting does not outperform standard prompting, for example, when applied to GSM8K, a challenging benchmark of math word problems. However, for large models (1024 FLOPs), chain-of-thought prompting substantially improves performance in our tests, reaching a 57% solve rate on GSM8K.
Chain-of-thought prompting is an emergent ability — it fails to improve performance for small language models, but substantially improves performance for large models. Here we illustrate the difference between standard and chain-of-thought prompting at different scales for two language models, LaMDA and PaLM.
Implications of Emergent Abilities
The existence of emergent abilities has a range of implications. For example, because emergent few-shot prompted abilities and strategies are not explicitly encoded in pre-training, researchers may not know the full scope of few-shot prompted abilities of current language models. Moreover, the emergence of new abilities as a function of model scale raises the question of whether further scaling will potentially endow even larger models with new emergent abilities.
Identifying emergent abilities in large language models is a first step in understanding such phenomena and their potential impact on future model capabilities. Why does scaling unlock emergent abilities? Because computational resources are expensive, can emergent abilities be unlocked via other methods without increased scaling (e.g., better model architectures or training techniques)? Will new real-world applications of language models become unlocked when certain abilities emerge? Analyzing and understanding the behaviors of language models, including emergent behaviors that arise from scaling, is an important research question as the field of NLP continues to grow.
Acknowledgements
It was an honor and privilege to work with Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Metzler, Ed H. Chi, Tatsunori Hashimoto, Oriol Vinyals, Percy Liang, Jeff Dean, and William Fedus.
The NVIDIA Grace Hopper Superchip Architecture is the first true heterogeneous accelerated platform for high-performance computing (HPC) and AI workloads. It…
The NVIDIA Grace Hopper Superchip Architecture is the first true heterogeneous accelerated platform forhigh-performance computing (HPC) and AI workloads. It accelerates applications with the strengths of both GPUs and CPUs while providing the simplest and most productive distributed heterogeneous programming model to date. Scientists and engineers can focus on solving the world’s most important problems.
In this post, you learn all about the Grace Hopper Superchip and highlight the performance breakthroughs that NVIDIA Grace Hopper delivers. For more information about the speedups that Grace Hopper achieves over the most powerful PCIe-based accelerated platforms using NVIDIA Hopper H100 GPUs, see the NVIDIA Grace Hopper Superchip Architecture whitepaper.
Performance and productivity for strong-scaling HPC and giant AI workloads
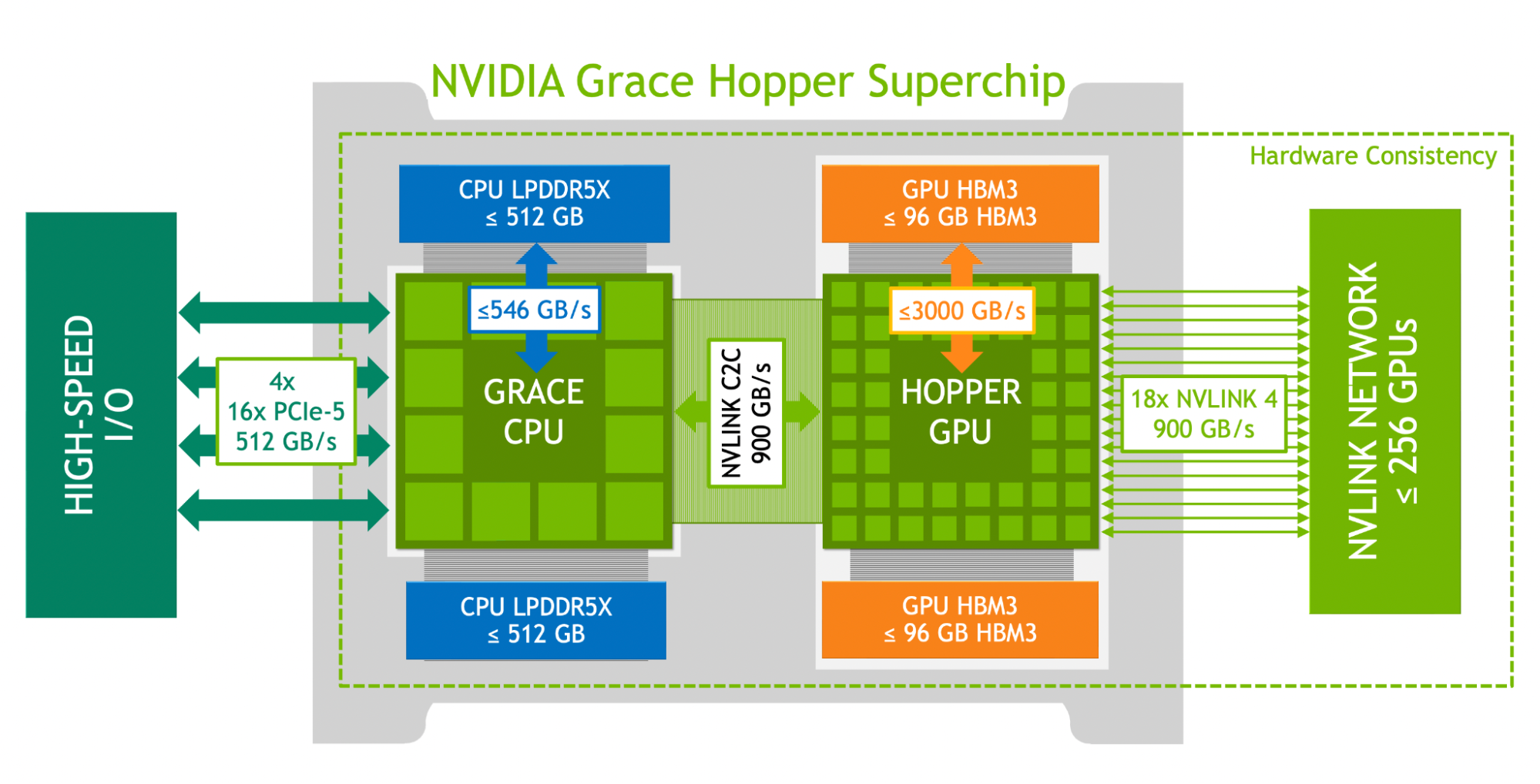
NVIDIA NVLink-C2C is an NVIDIA memory coherent, high-bandwidth, and low-latency superchip interconnect. It is the heart of the Grace Hopper Superchip and delivers up to 900 GB/s total bandwidth. This is 7x higher bandwidth than x16 PCIe Gen5 lanes commonly used in accelerated systems.
NVLink-C2C memory coherency increases developer productivity and performance and enables GPUs to access large amounts of memory.CPU and GPU threads can now concurrently and transparently access both CPU– and GPU-resident memory, enabling you to focus on algorithms instead of explicit memory management.
Memory coherency enables you to transfer only the data you need, and not migrate entire pages to and from the GPU. It also enables lightweight synchronization primitives across GPU and CPU threads by enabling native atomic operations from both the CPU and GPU. NVLink-C2C with Address Translation Services (ATS) leverages the NVIDIA Hopper Direct Memory Access (DMA) copy engines for accelerating bulk transfers of pageable memory across host and device.
NVLink-C2C enables applications to oversubscribe the GPU’s memory and directly utilize NVIDIA Grace CPU’s memory at high bandwidth. With up to 512 GB of LPDDR5X CPU memory per Grace Hopper Superchip, the GPU has direct high-bandwidth access to 4x more memory than what is available with HBM. Combined with the NVIDIA NVLink Switch System, all GPU threads running on up to 256 NVLink-connected GPUs can now access up to 150 TB of memory at high bandwidth. Fourth-generation NVLink enables accessing peer memory using direct loads, stores, and atomic operations, enabling accelerated applications to solve larger problems more easily than ever.
Together with NVIDIA networking technologies, Grace Hopper Superchips provide the recipe for the next generation of HPC supercomputers and AI factories. Customers can take on larger datasets, more complex models, and new workloads, solving them more quickly than before.
The main innovations of the NVIDIA Grace Hopper Superchip are as follows:
NVIDIA Grace CPU:
Up to 72x Arm Neoverse V2 cores with Armv9.0-A ISA and 4×128-bit SIMD units per core.
Up to 117 MB of L3 Cache.
Up to 512 GB of LPDDR5X memory delivering up to 546 GB/s of memory bandwidth.
Up to 64x PCIe Gen5 lanes.
NVIDIA Scalable Coherency Fabric (SCF) mesh and distributed cache with up to 3.2 TB/s memory bandwidth.
High developer productivity with a single CPU NUMA node.
NVIDIA Hopper GPU:
Up to 144 SMs with fourth-generation Tensor Cores, Transformer Engine, DPX, and 3x higher FP32 and FP64 throughout compared to the NVIDIA A100 GPU.
Up to 96 GB of HBM3 memory delivering up to 3000 GB/s.
60 MB L2 Cache.
NVLink 4 and PCIe 5.
NVIDIA NVLink-C2C:
Hardware-coherent interconnect between the Grace CPU and Hopper GPU.
Up to 900 GB/s total bandwidth, 450 GB/s/dir.
The Extended GPU Memory feature enables the Hopper GPU to address all CPU memory as GPU memory. Each Hopper GPU can address up to 608 GB of memory within a superchip.
NVIDIA NVLink Switch System:
Connects up to 256x NVIDIA Grace Hopper Superchips using NVLink 4.
Each NVLink-connected Hopper GPU can address all HBM3 and LPDDR5X memory of all superchips in the network, for up to 150 TB of GPU addressable memory.
Programming model for performance, portability, and productivity
Traditional heterogeneous platforms with PCIe-connected accelerators require users to follow a complex programming model that involves manually managing device memory allocations and data transfer to and from the host.
The NVIDIA Grace Hopper Superchip platform is heterogeneous and easy to program, and NVIDIA is committed to making it accessible to all developers and applications, independent of the programming language of choice.
Both the Grace Hopper Superchip and the platform are built to enable you to pick the right language for the task at hand, and the NVIDIA CUDA LLVM Compiler APIs enable you to bring your preferred programming language to the CUDA platform with the same level of code-generation quality and optimizations as NVIDIA compilers and tools.
The languages provided by NVIDIA for the CUDA platform (Figure 3) include accelerated standard languages like ISO C++, ISO Fortran, and Python. The platform also supports directive-based programming models like OpenACC, OpenMP, CUDA C++, and CUDA Fortran. The NVIDIA HPC SDK supports all these approaches, along with a rich set of accelerated libraries and tools for profiling and debugging.
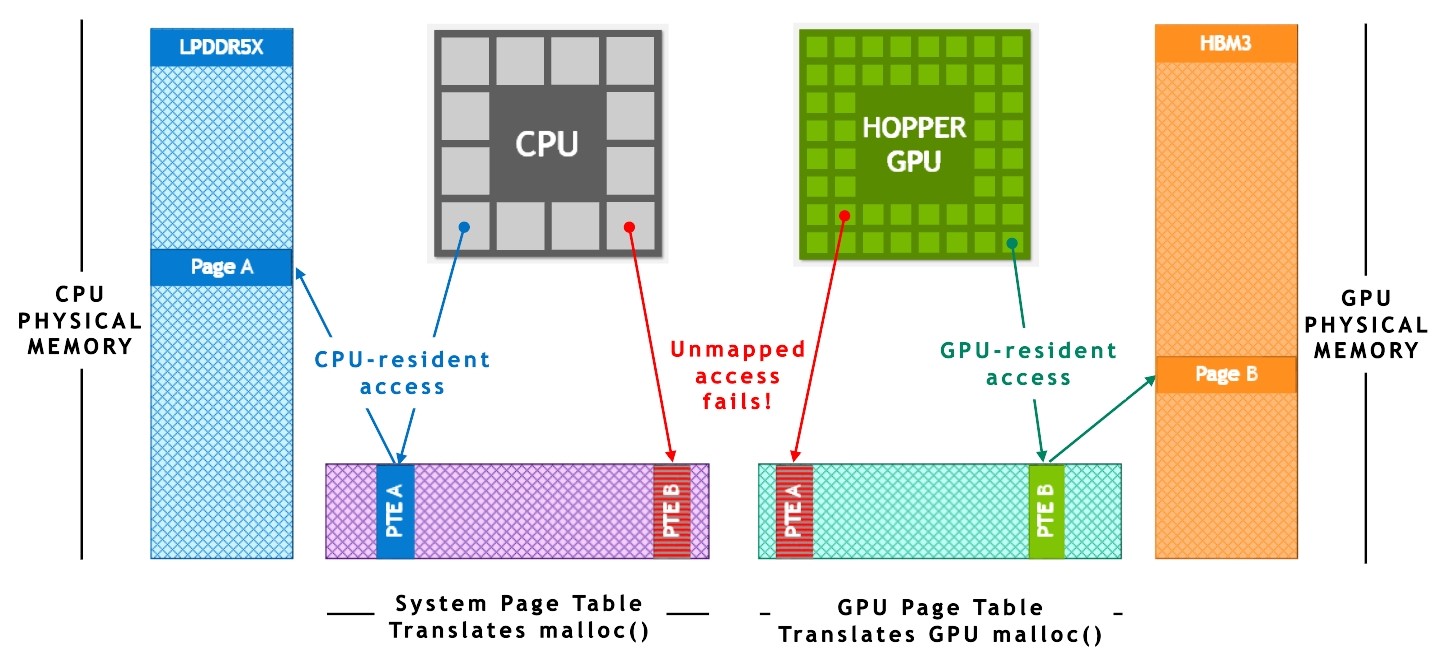
This technology relies heavily on the hardware-accelerated memory coherency provided by NVIDIA NVLink-C2C and NVIDIA Unified Virtual Memory. As shown in Figure 4, in traditional PCIe-connected x86+Hopper systems without ATS, the CPU and the GPU have independent per-process page tables, and system-allocated memory is not directly accessible from the GPU. When a program allocates memory with the system allocator but the page entry is not available in the GPU’s page table, then accessing the memory from a GPU thread fails.
Figure 4. NVIDIA Hopper System with disjoint page tables
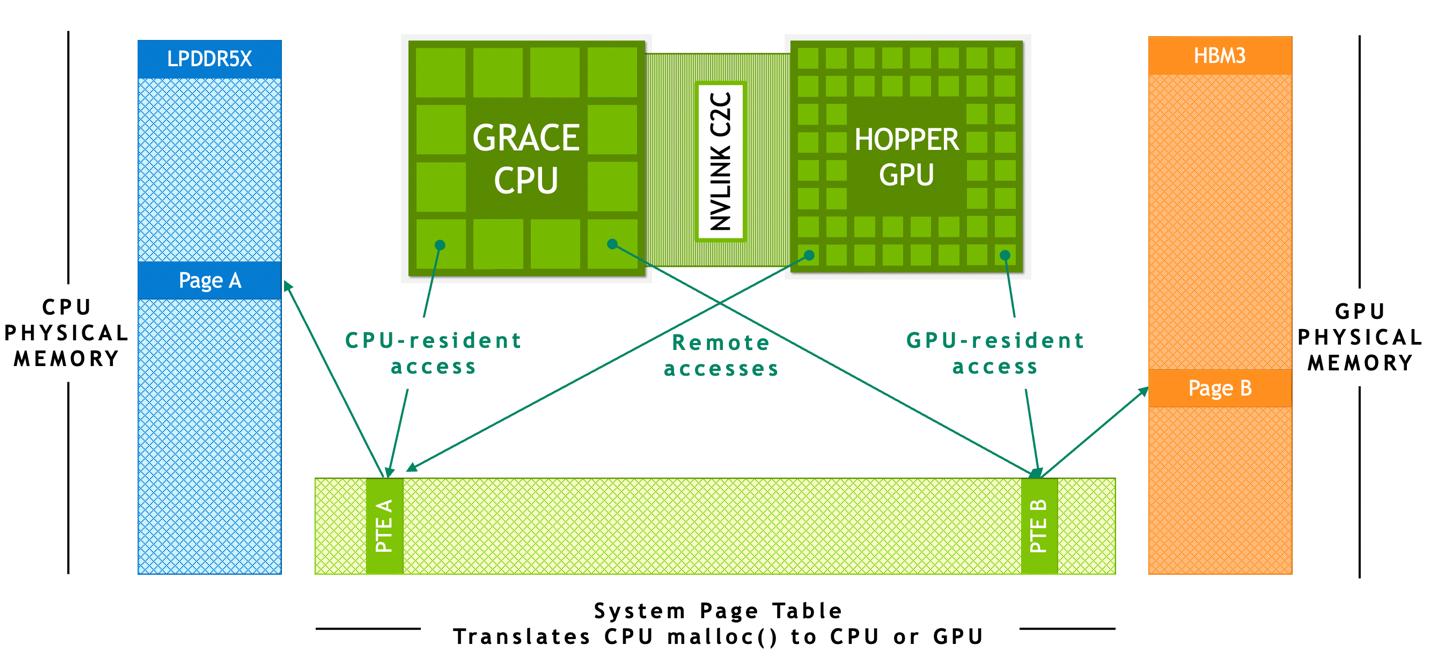
In NVIDIA Grace Hopper Superchip-based systems, ATS enables the CPU and GPU to share a single per-process page table, enabling all CPU and GPU threads to access all system-allocated memory, which can reside on physical CPU or GPU memory. The CPU heap, CPU thread stack, global variables, memory-mapped files, and interprocess memory are accessible to all CPU and GPU threads.
Figure 5. Address Translation Services in an NVIDIA Grace Hopper Superchip system
NVIDIA NVLink-C2C hardware-coherency enables the Grace CPU to cache GPU memory at cache-line granularity and for the GPU and CPU to access each other’s memory without page-migrations.
NVLink-C2C also accelerates all atomic operations supported by the CPU and GPU on system-allocated memory. Scoped atomic operations are fully supported and enable fine-grained and scalable synchronization across all threads in the system.
The runtime backs system-allocated memory with physical memory on first touch, either on LPDDR5X or HBM3, depending on whether a CPU or a GPU thread accesses it first. From an OS perspective, the Grace CPU and Hopper GPU are just two separate NUMA nodes. System-allocated memory is migratable so the runtime can change its physical memory backing to improve application performance or deal with memory pressure.
For PCIe-based platforms such as x86 or Arm, you can use the same Unified Memory programming model as the NVIDIA Grace Hopper model. That is possible through the Heterogeneous Memory Management (HMM) feature, which is a combination of Linux kernel features and NVIDIA driver features that use software to emulate memory coherence between CPUs and GPUs.
On NVIDIA Grace Hopper, these applications transparently benefit from the higher-bandwidth, lower-latency, higher atomic throughput, and hardware acceleration for memory coherency provided by NVLink-C2C, without any software changes.
Superchip architectural features
Here’s a look at the main innovations of the NVIDIA Grace Hopper architecture:
NVIDIA Grace CPU
NVIDIA Hopper GPU
NVLink-C2C
NVLink Switch System
Extended GPU memory
NVIDIA Grace CPU
As the parallel compute capabilities of GPUs continue to triple every generation, a fast and efficient CPU is critical to prevent the serial and CPU-only fractions of modern workloads from dominating performance.
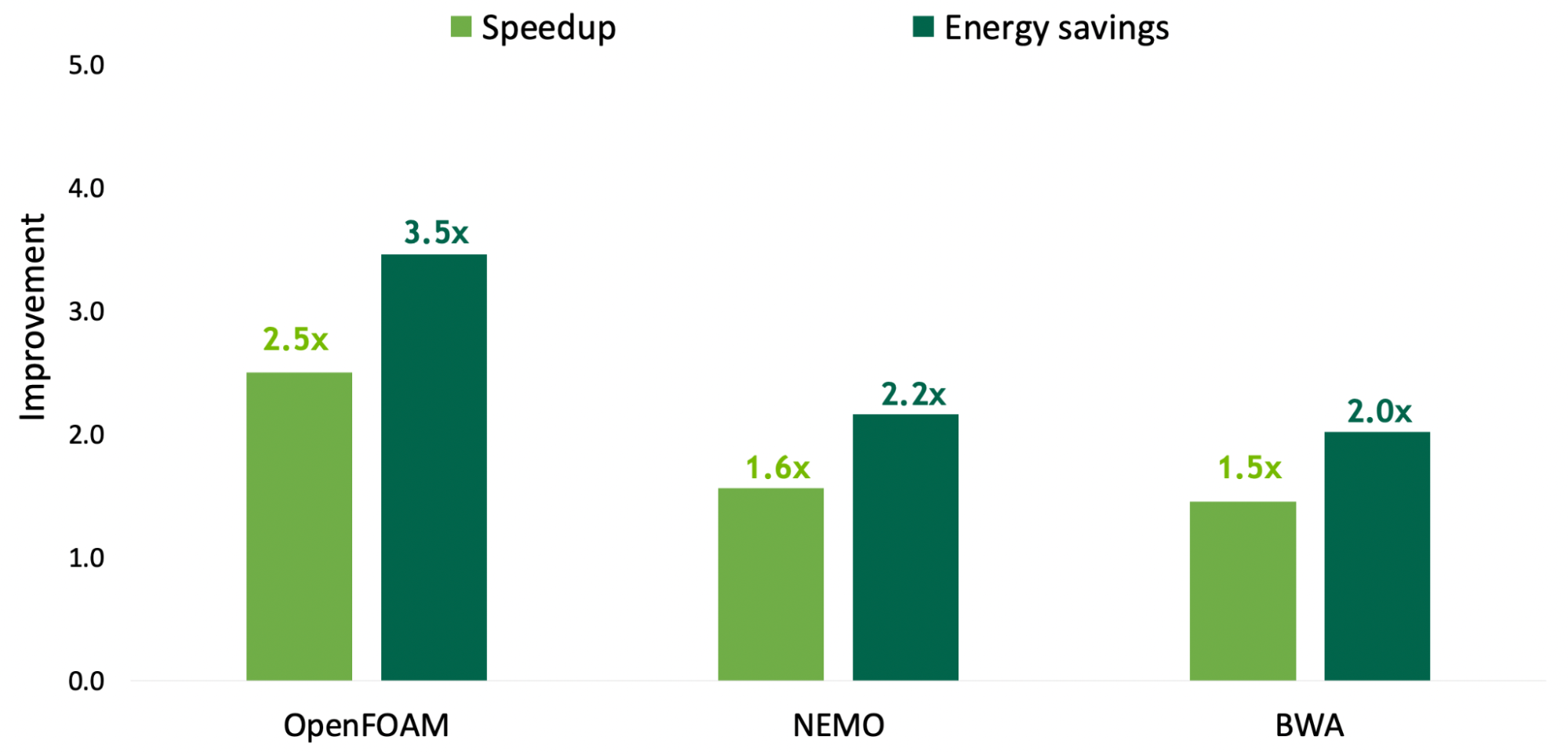
NVIDIA Grace delivers leading per-thread performance, while providing higher energy efficiency than traditional CPUs. The 72 CPU cores deliver up to a 370 (estimated) score on SPECrate 2017_int_base, ensuring high-performance to satisfy the demands of both HPC and AI heterogeneous workloads.
Figure 6. End-user application performance and energy saving simulations of the NVIDIA Grace CPU in the Grace Hopper Superchip vs AMD Milan 7763 shows that the Grace CPU is up to 2.5x faster while using 4x less energy
Modern GPU workloads in machine learning and data science need access to huge amounts of memory. Typically, these workloads would have to use multiple GPUs to store the dataset in HBM memory.
The NVIDIA Grace CPU provides up to 512 GB of LPDDR5X memory, which delivers the optimal balance between memory capacity, energy efficiency, and performance. It supplies up to 546 GB/s of LPDDR5X memory bandwidth, which NVLink-C2C makes accessible to the GPU at 900 GB/s total bandwidth.
A single NVIDIA Grace Hopper Superchip provides the Hopper GPU with a total of 608 GB of fast-accessible memory, almost the total amount of slow memory available in a DGX-A100-80; an eight-GPU system of the previous generation.
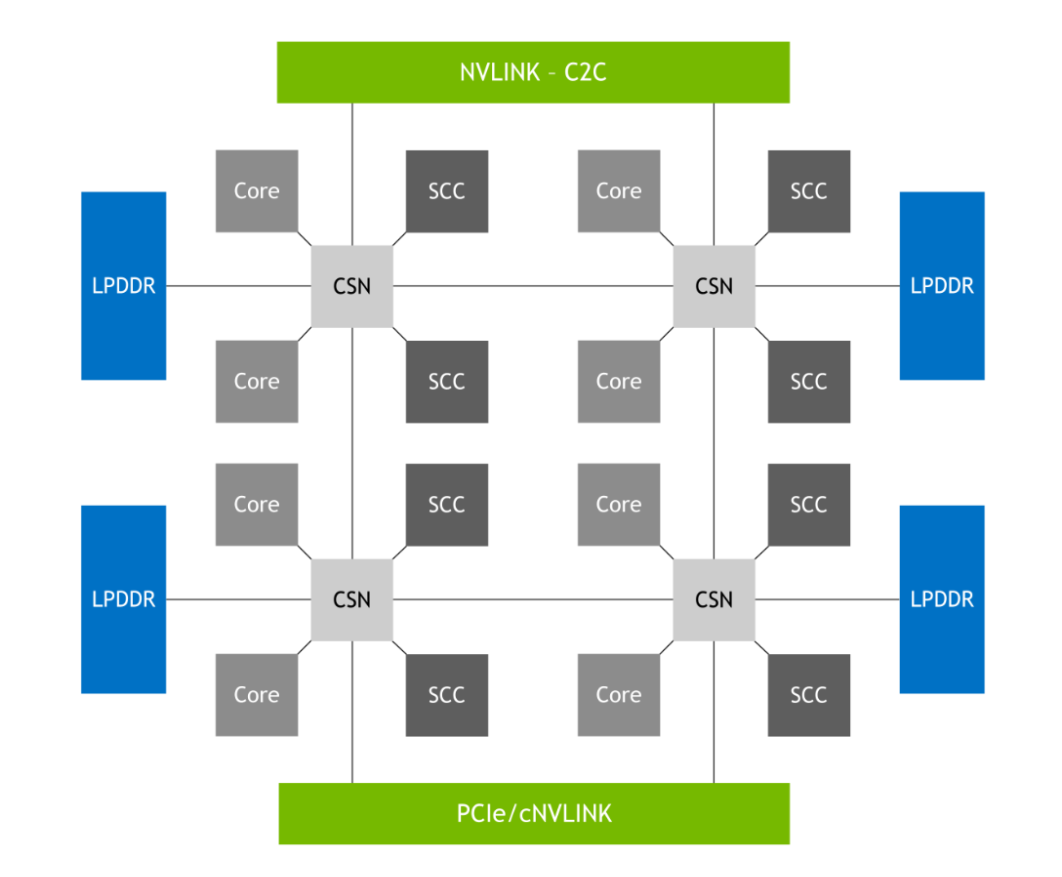
This is made possible by the NVIDIA SCF shown in Figure 7, a mesh fabric and distributed cache that provides up to 3.2 TB/s of total bisection bandwidth to realize the full performance of CPU cores, memory, system I/Os, and NVLink-C2C. The CPU cores and SCF Cache partitions (SCCs) are distributed throughout the mesh, while Cache Switch Nodes (CSNs) route data through the fabric and serve as interfaces between the CPU cores, cache memory, and the rest of the system.
Figure 7. SCF logical overview
NVIDIA Hopper GPU
The NVIDIA Hopper GPU is the ninth-generation NVIDIA data center GPU. It is designed to deliver orders-of-magnitude improvements for large-scale AI and HPC applications compared to previous NVIDIA Ampere GPU generations. The Hopper GPU also features multiple innovations:
New fourth-generation Tensor Cores perform faster matrix computations than ever before on an even broader array of AI and HPC tasks.
A new transformer engine enables H100 to deliver up to 9x faster AI training and up to 30x faster AI inference speedups on large language models compared to the prior generation NVIDIA A100 GPU.
Improved features for spatial and temporal data locality and asynchronous execution enable applications to always keep all units busy and maximize power efficiency.
Secure Multi-Instance GPU (MIG) partitions the GPU into isolated, right-sized instances to maximize quality of service (QoS) for smaller workloads.
Figure 8. NVIDIA Hopper GPU enables next-generation AI and HPC breakthroughs
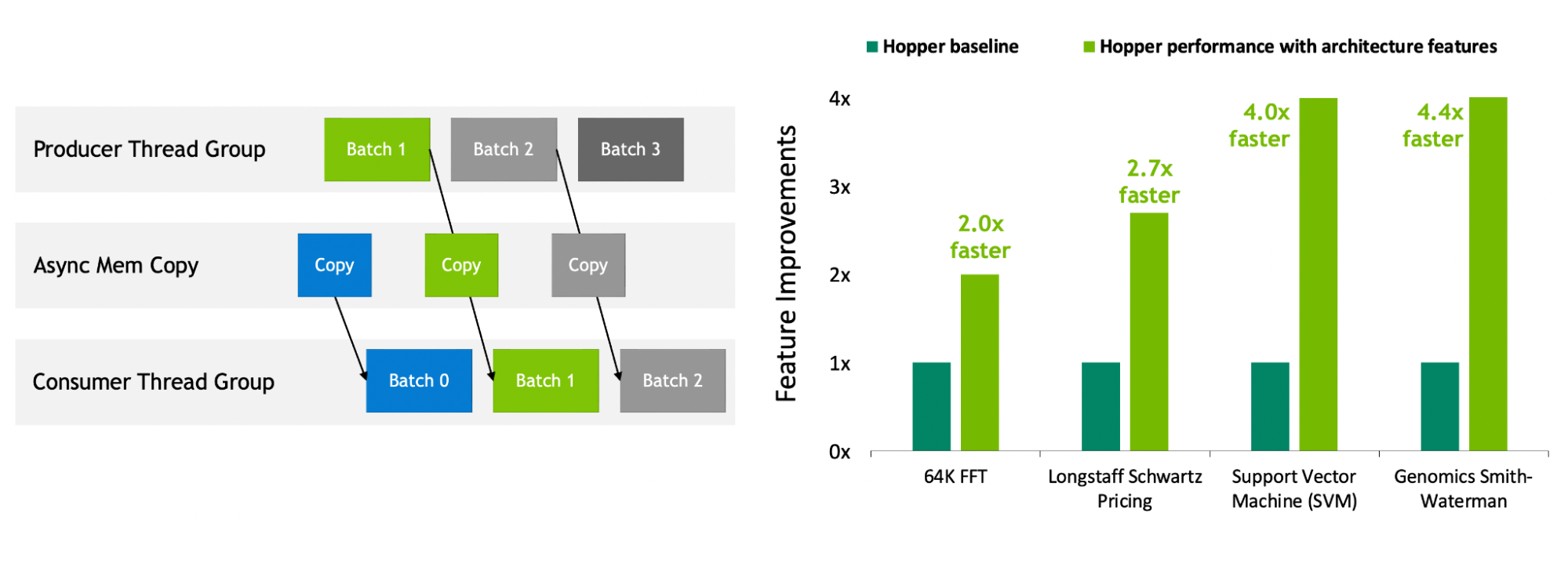
NVIDIA Hopper is the first truly asynchronous GPU. Its Tensor Memory Accelerator (TMA) and asynchronous transaction barrier enable threads to overlap and pipeline independent data movement and data processing, enabling applications to fully utilize all units.
New spatial and temporal locality features like thread block clusters, distributed shared memory, and thread block reconfiguration provide applications with fast access to larger amounts of shared memory and tools. This enables applications to better reuse data while it’s on-chip, further improving application performance.
Figure 9. NVIDIA Hopper GPU asynchronous execution enables overlapping independent data-movement with computation (left). New spatial and temporal locality features improve application performance (right).
NVLink-C2C: A high-bandwidth, chip-to-chip interconnect for superchips
NVIDIA Grace Hopper fuses an NVIDIA Grace CPU and NVIDIA Hopper GPU into a single superchip through the NVIDIA NVLink-C2C, a 900 GB/s chip-to-chip coherent interconnect that enables programming the Grace Hopper Superchip with a unified programming model.
The NVLink Chip-2-Chip (C2C) interconnect provides a high-bandwidth direct connection between a Grace CPU and a Hopper GPU to create the Grace Hopper Superchip, which is designed for drop-in acceleration of AI and HPC applications.
With 900 GB/s of bidirectional bandwidth, NVLink-C2C provides 7x the bandwidth of x16 PCIe Gen links at lower latency. NVLink-C2C also only uses 1.3 picojoules per bit transferred, which is greater than 5x more energy-efficient than PCIe Gen 5.
Furthermore, NVLink-C2C is a coherent memory interconnect with native hardware support for system-wide atomic operations. This improves the performance of memory accesses to non-local memory, such as CPU and GPU threads accessing memory resident in the other device. Hardware coherency also improves the performance of synchronization primitives, reducing the time the GPU or CPU wait on each other and increasing total system utilization.
Finally, hardware coherency also simplifies the development of heterogeneous computing applications using popular programming languages and frameworks. For more information, see the NVIDIA Grace Hopper Programming Model section.
NVLink Switch System
The NVIDIA NVLink Switch System combines fourth-generation NVIDIA NVLink technology with the new third-generation NVIDIA NVSwitch. A single level of the NVSwitch connects up to eight Grace Hopper Superchips, and a second level in a fat-tree topology enables networking up to 256 Grace Hopper Superchips with NVLink. A Grace Hopper Superchip pair exchanges data at up to 900 GB/s.
With up to 256 Grace Hopper Superchips, the network delivers up to 115.2 TB/s all-to-all bandwidth. This is 9x the all-to-all bandwidth of the NVIDIA InfiniBand NDR400.
Figure 10. Logical overview of NVIDIA NVLink 4 NVSwitch
The fourth-generation NVIDIA NVLink technology enables GPU threads to address up to 150 TB of memory provided by all superchips in the NVLink network using normal memory operations, atomic operations, and bulk transfers. Communication libraries like MPI, NCCL, or NVSHMEM transparently leverage the NVLink Switch System when available.
Extended GPU memory
The NVIDIA Grace Hopper Superchip is designed to accelerate applications with exceptionally large memory footprints, larger than the capacity of the HBM3 and LPDDR5X memory of a single superchip. For more information, see the NVIDIA Grace Hopper Accelerated Applications section.
The Extended GPU Memory (EGM) feature over the high-bandwidth NVLink-C2C enables GPUs to access all the system memory efficiently. EGM provides up to 150 TBs of system memory in a multi-node NVSwitch-connected system. With EGM, physical memory can be allocated to be accessible from any GPU thread in the multi-node system. All GPUs can access EGM at the minimum of GPU-GPU NVLink or NVLink-C2C speed.
Memory accesses within a Grace Hopper Superchip configuration go through the local high-bandwidth NVLink-C2C at 900 GB/s total. Remote memory accesses are performed through GPU NVLink and, depending on the memory being accessed, also NVLink-C2C (Figure 11). With EGM, GPU threads can now access all memory resources available over the NVSwitch fabric, both LPDDR5X and HBM3, at 450 GB/s.
Figure 11. Memory accesses across NVLink-connected Grace Hopper Superchips
NVIDIA HGX Grace Hopper
Figure 12. NVIDIA HGX Grace Hopper with InfiniBand
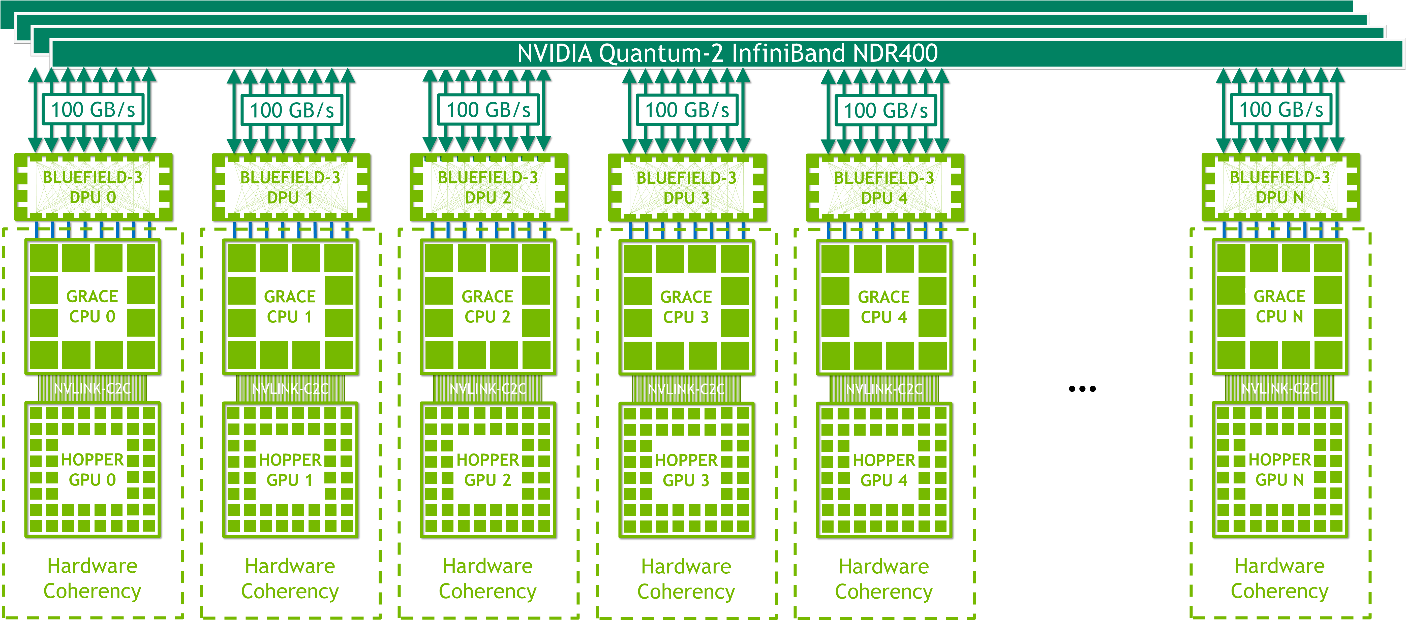
NVIDIA HGX Grace Hopper has a single Grace Hopper Superchip per node, paired with BlueField-3 NICs or OEM-Defined I/O and optionally an NVLink Switch System. It can be air– or liquid-cooled and has up to 1,000W TDP.
NVIDIA HGX Grace Hopper with InfiniBand
NVIDIA HGX Grace Hopper with Infiniband (Figure 13) is ideal for the scale-out of traditional machine learning (ML) and HPC workloads that are not bottlenecked by network communication overheads of InfiniBand, which is one of the fastest interconnects available.
Each node contains one Grace Hopper Superchip and one or more PCIe devices like NVMe solid-state drives and BlueField-3 DPUs, NVIDIA ConnectX-7 NICs, or OEM-defined I/O. With 16x PCIe Gen 5 lanes, an NDR400 InfiniBand NIC provides up to 100 GB/s of total bandwidth across the superchips. Combined with NVIDIA BlueField-3 DPUs, this platform is easy to manage and deploy and uses a traditional HPC and AI cluster networking architecture.
Figure 13. NVIDIA HGX Grace Hopper with InfiniBand for scale-out ML and HPC workloads
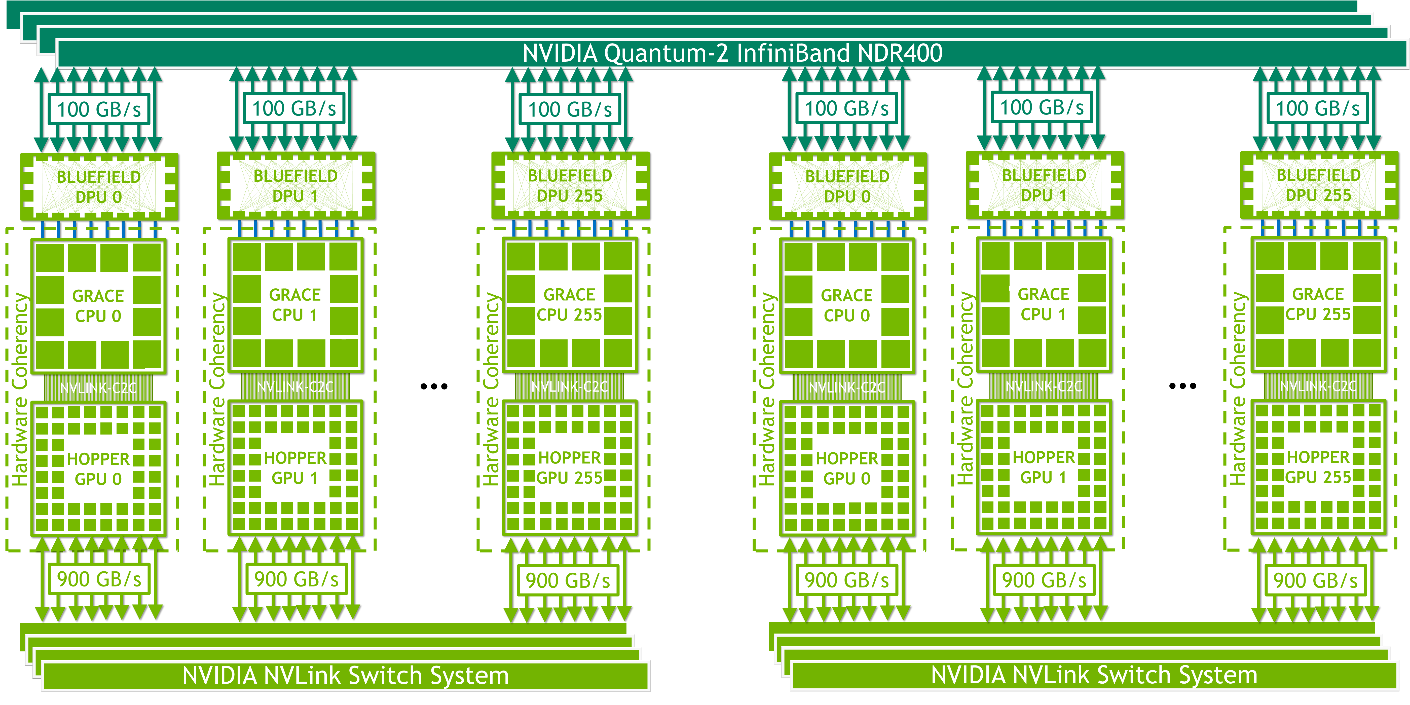
NVIDIA HGX Grace Hopper with NVLink Switch
NVIDIA HGX Grace Hopper with NVLink Switch is ideal for strong scaling giant machine learning and HPC workloads. It enables all GPU threads in the NVLink-connected domain to address up to 150 TB of memory at up to 900 GB/s total bandwidth per superchip in a 256-GPU NVLink-connected system. The a simple programming model uses pointer load, store, and atomic operations. Its 450 GB/s all-reduce bandwidth and up to 115.2 TB/s bisection bandwidth make this platform ideal for strong-scaling the world’s largest and most challenging AI training and HPC workloads.
NVLink-connected domains are networked with NVIDIA InfiniBand networking, for example, NVIDIA ConnectX-7 NICs or NVIDIA BlueField-3 data processing units (DPUs) paired with NVIDIA Quantum 2 NDR switches or OEM-defined I/O solutions.
Figure 14. NVIDIA HGX Grace Hopper with NVLink Switch System for strong-scaling giant ML and HPC workloads
Delivering performance breakthroughs
The NVIDIA Grace Hopper Superchip Architecture whitepaper expands on the details covered in this post. It walks you through how Grace Hopper delivers the performance breakthroughs shown on Figure 1 over what is currently the most powerful PCIe-based accelerated platforms powered by NVIDIA Hopper H100 PCIe GPUs.
Do you have any applications that would be perfect for the NVIDIA Grace Hopper Superchip? Let us know in the comments!
Acknowledgments
We would like to thank Jack Choquette, Ronny Krashinsky, John Hubbard, Mark Hummel, Greg Palmer, Ryan Wells, Alex Ishii, Jonah Alben, and the many NVIDIA architects and engineers who contributed to this post.
“Before NVIDIA Instant NeRF, creating 3D scenes required specialized equipment, expertise, and lots of time and money. Now it just takes a few photos and a few minutes,” TIME writes in their release.
The 3D rendering tool was introduced at SIGGRAPH 2022, the world’s largest conference for computer graphics and interactive techniques.
Accumulating tens of thousands of downloads and achieving over 9,700 stars on the Instant NeRF GitHub page, developers and 3D content creators are embracing the ability to create stunning 3D scenes with the tool.
What is a NeRF?
Neural Radiance Fields (NeRF) are neural networks capable of generating 3D images or scenes from a set of 2D images. Using spatial location and volumetric rendering, the model uses the camera pose from the images to render the 3D space of the scene.
NeRFs are computationally intensive and historically required many hours for rendering. However, Instant NeRFs give users the power to render an image or scene quickly and accurately with a small number of images. You can generate a scene in seconds and the longer the model trains the more details of a scene are rendered.
Video 1. Amalfi Coast created with Instant NeRF. Credit: Jonathan Stephens
Exploring NeRFs
To support developers adopting Instant NeRF, NVIDIA hosted an Instant NeRF Sweepstakes over the summer. The event encouraged contestants to explore their creative abilities while using InstantNeRF and the chance to win a GeForce RTX 3090. The sweepstakes reached over 2.7 million people on Twitter.
Since the code release, a large community of creators ranging from AI researchers to photographers have demonstrated their Instant NGP skills by making their own NeRFs.
“NeRF is a way to freeze a moment in time that is more immersive than a photograph or a video. It’s a way to recreate a moment – the whole moment. NeRF is the natural extension of photogrammetry and the evolution of modern photography,” said Michael Rubloff of Franc Lucent, an early explorer in NeRF technology.
Video 2. NERF of Zeus. Credit: Hugues Bruyère
“Museums are great exploration fields for interactive and immersive experiences. Volumetric scenes like this one can also directly contribute to historical heritage conservation, with a modern and immersive twist,” said Hugues Bruyère, partner and chief of innovation at the Montreal-based creative studio Dpt.
The community has taken NeRFs to another level by expressing themselves and their art through this new form of photography. Some have even found ways to make NeRFs impactful in how they work.
Video 3. A NeRF scene of a woman meditating. Credit: Franc Lucent
Make your own NeRFs
This remarkable technology is available for anyone to try out!
The holiday season is approaching, and GeForce NOW has everyone covered. This GFN Thursday brings an easy way to give the gift of gaming with GeForce NOW gift cards, for yourself or for a gamer in your life. Plus, stream 10 new games from the cloud this week, including the first story downloadable content (DLC) Read article >
As enterprises continue to shift workloads to the cloud, some applications need to remain on-premises to maximize latency performance and meet security, data…
As enterprises continue to shift workloads to the cloud, some applications need to remain on-premises to maximize latency performance and meet security, data sovereignty, and compliance policies. Microsoft Azure Stack HCI is a hyperconverged infrastructure (HCI) stack delivered as an Azure service. Providing built-in security and manageability, Azure Stack HCI is ideally positioned to run production workloads and cloud-native apps in core and edge data centers.
NVIDIA BlueField data processing unit (DPU) is an accelerated data center infrastructure platform that unleashes application performance and system efficiency. BlueField DPUs help cloud-minded enterprises overcome performance and scalability bottlenecks in modern IT environments. This is achieved by offloading, accelerating, and isolating software-defined infrastructure workloads.
Marking a major leap forward in performance and productivity, Microsoft has demonstrated a prototype of the Azure Stack HCI platform accelerated on NVIDIA BlueField-2 DPUs, delivering 12x CPU resource efficiency and 60% higher throughput. The DPU-accelerated HCI platform enables significant total cost of ownership (TCO) savings by requiring fewer servers and lower power and space to operate a given workload.
Performance and efficiency gains
Azure Stack HCI is a software-defined platform that runs the Azure networking stack for connecting virtual machines (VMs) and containers together. Software-defined networks deliver rich functionality and great flexibility and enable enterprises to easily scale from a single on-premises data center to hybrid and multi-cloud environments.
Despite the many benefits of software-defined networks, those that run exclusively on CPUs are resource constrained. They’re known for stealing away expensive cores that would otherwise be used for running business applications, taking a toll on performance and scalability. In addition, software-defined network (SDN) technologies have had a longstanding conflict with hardware-accelerated networking (namely SR-IOV). This forces cloud architects to prioritize one over the other, often at the cost of poor application performance or higher TCO.
NVIDIA BlueField DPUs are designed to deliver the best of both worlds: the functionality and agility of SDNs with the performance and efficiency of hardware-accelerated networking (SR-IOV). BlueField offloads the entire SDN workload from the host CPU, freeing up CPU cores for line-of-business applications and creating major TCO savings.
Running in the BlueField Arm processor, the SDN pipeline is mapped to the BlueField-accelerated programmable pipeline to increase throughput and packet processing performance and reduce latency. By offloading and accelerating functions of the Azure Stack HCI SDN on NVIDIA BlueField-2 DPUs, the Microsoft team is able to achieve massive performance and efficiency gains (Figure 1).
Figure 1. Accelerating the Azure Stack HCI on NVIDIA BlueField-2 DPUs results in network throughput gains (left) and CPU core savings (right)
The test results indicate that BlueField-2 delivers line-rate, software-defined networking at 96 Gb/s with practically zero CPU utilization compared to only 60 Gb/s that were utilized over 8 CPU cores. Those 8 cores are now freed up to run business workloads with 60% faster networking.
To show an apples-to-apples comparison and because the x86 CPU was not able to reach ~100 Gb/s in the test, the number of CPU cores that would have been required to support 96 Gb/s have been extrapolated. Figure 1 shows that 12 CPU cores would have been required to support 96 Gb/s, which means BlueField-2 saves 12 CPU cores to support the same throughput.
This savings enables enterprises to design, deploy, and operate fewer servers to deliver the same business outcomes, or alternatively, achieve better outcomes based on the same number of servers.
From a functional standpoint, the Microsoft Azure Stack HCI platform supports a wide range of SDN policies: VXLAN network encapsulation and decapsulation (encap/decap), access-control list (ACL), quality-of-service (QoS), IP-in-IP encapsulation, network address translation (NAT), IPsec encryption/decryption, and more. The traditional configuration of accelerated networking (SR-IOV) for a VM would require bypassing this rich set of policies for the benefit of achieving higher performance.
The Azure Stack HCI solution prototype, now offloaded and accelerated on the BlueField DPU, delivers both advanced SDN policies without sacrificing performance and efficiency. See Evolving Networking with a DPU-Powered Edge for more details.
Summary
While shifting workloads to the cloud, enterprises continue to prioritize on-premises and edge data centers to meet stringent performance and security requirements. Next-generation applications including machine learning and artificial intelligence increasingly rely on accelerated networking to realize their full potential. The Microsoft Azure Stack HCI on NVIDIA BlueField DPUs prototype delivers on the promise of hybrid cloud and accelerated networking for businesses at every scale.
Just like many businesses, the world of industrial scientific computing has a data problem. Solving seemingly intractable challenges — from developing new energy sources and creating new modes of transportation, to addressing mission-critical issues such as driving operational efficiencies and improving customer support — requires massive amounts of high performance computing. Instead of having to Read article >
Anyone who’s taken a photo with a digital camera is likely familiar with a “noisy” image: discolored spots that make the photo lose clarity and sharpness. Many photographers have tips and tricks to reduce noise in images, including fixing the settings on the camera lens or taking photos in different lighting. But it isn’t just Read article >
Two months after their debut sweeping MLPerf inference benchmarks, NVIDIA H100 Tensor Core GPUs set world records across enterprise AI workloads in the industry group’s latest tests of AI training. Together, the results show H100 is the best choice for users who demand utmost performance when creating and deploying advanced AI models. MLPerf is the Read article >
As AI becomes increasingly capable and pervasive in high performance computing (HPC), MLPerf benchmarks have emerged as an invaluable tool. Developed by…
As AI becomes increasingly capable and pervasive in high performance computing (HPC), MLPerf benchmarks have emerged as an invaluable tool. Developed by MLCommons, MLPerf benchmarks enable organizations to evaluate the performance of AI infrastructure across a set of important workloads traditionally performed on supercomputers.
Peer-reviewed industry-standard benchmarks are a critical tool for evaluating HPC platforms, and NVIDIA believes access to reliable performance data will help guide HPC architects of the future in their design decisions.
MLPerf HPC benchmarks measure training time and throughput for three types of high-performance simulations that have adopted machine learning techniques.
Figure 1. MLPerf HPC v2.0 all submitted results
This post walks through the steps the NVIDIA MLPerf team took to optimize each benchmark and measurement to extract the maximum performance. We will focus on the optimizations in MLPerf HPC v2.0 in addition to those in MLPerf HPC v1.0.
CosmoFlow
Each instance of the CosmoFlow training application benchmark loads ~8 TB of training data and ~1 TB of validation data. These consist of 512K training samples and 64K validation samples. Each sample has a 16 MB data file and a tiny 144-character label file. In total, there are over 1 million small files that need to be loaded into node-local Nonvolatile Memory Express (NVMe) before training can begin.
In MLPerf HPC v1.0, this resulted in data staging taking a significant amount of time both for strong-scale and weak-scale cases. For the weak-scale case, having many instances—each loading over 1 million files from the file system—puts additional strain on the shared disk system.
For the number of instances used for weak-scale submission, this causes a non-linear degradation of staging performance with respect to number of instances. These problems were addressed in several ways and are outlined below.
Data staging on NVMe
For a single strong training instance analysis of the NVIDIA MLPerf HPC v1.0 submission showed that only a small fraction of the maximum theoretical read bandwidth of the Selene Lustre file system was used. This was also the case for storage network interface cards (NICs) on the nodes when staging the input dataset.
During the staging phase of training, the CPU resources allocated are dedicated entirely to sourcing data from the shared file system to node-local NVMe storage. Increasing the threads dedicated to staging, and staging the training and validation data in parallel, reduced the staging time by ~75%. This equates to a ~4x speedup in staging and resulted in a 40% end-to-end reduction in total time for strong-scale.
Data compression
Loading many tiny files is inherently inefficient. In the case of CosmoFlow, there are more than 1 million files, each with 144 bytes. To further improve staging performance, the associated data and label were combined into one compressed file offline ahead of time.
In parallel with the data being staged from disk, the files are uncompressed locally onto the compute node disk. This reduces the number of files to be read from disk by 50% and the total data transferred from disk by ~85%, at the end giving an additional 13% staging speedup for strong-scale scenarios. This results in a 7% end-to-end performance improvement in overall training time for strong-scale submission.
This approach achieved over 900 GB/s read bandwidth for data staging of a strong-scale scenario.
Increasing effective bandwidth when running multiple instances
When running multiple instances at the same time, for weak scaling, every instance must stage a copy of the training and validation data on its local nodes. This year, the NVIDIA submission implemented the distributed staging mechanism for CosmoFlow.
All of the nodes, regardless of which instance they are associated with, load a fraction of total data (1/N where N is the total number of nodes, which is 512 in this case) from the shared file system. Given the optimizations already discussed, this takes only a few seconds.
Then, every node uses MPI_Allgather to distribute the data loaded from remote storage to the other nodes that need the data. This distribution takes place over the higher bandwidth InfiniBand Fabric. In other words, a large portion of data transfer that was previously happening over the storage network is offloaded to InfiniBand Fabric with this optimization. As a result of distributing staging, staging time scales linearly with the number of instances (at least up to 128 instances) for weak-scale scenarios.
For the v1.0 submission, 32 instances were run, each staging ~9 TB of data. This took 10.76 minutes for an effective bandwidth of ~460 GB/s.
For this year’s submission, 128 instances were run, each staging ~9 TB of data, for which the total staging time takes 6.7 minutes. This means staging input data for 4x the number of instances in 1.6x less time, resulting in an effective bandwidth of ~2,900 GB/s, a 6.5x increase in effective bandwidth. Effective bandwidth assumes the amount of total data staged from the file system is the same as that of a non-distributed algorithm for a given number of instances.
Smaller instance sizes for weak-scale training
All the staging improvements enabled the size of the individual instances to be reduced for weak scaling (hence a larger number of parallel instances), which would not have been possible with the storage access bottlenecks that existed before the optimizations were implemented. In v1.0, 32 instances, each with 128 GPUs, caused the staging time to scale non-linearly. Increasing the number of instances caused a superlinear increase in staging time.
Without the improvements to efficiently stage for many instances, the staging time would have continued to grow superlinearly with the number of instances, resulting in more time being spent for data staging than the actual training.
With the optimizations described above, the number of instances were increased from 32 to 128 for the weak-scale submission, each instance using four nodes instead of 16 nodes as done in MLPerf HPC v1.0. In v2.0, staging was completed in less time, while increasing the number of models running simultaneously by 4x for weak-scale submission.
CUDA graphs and graph capture
CUDA graphs allow a single graph that consists of a sequence of kernels to be launched, instead of individually launching each of the kernels from CPU to GPU. This feature minimizes CPU involvement in each iteration, substantially improving performance by minimizing latencies—especially for strong scaling scenarios.
CUDA graphs support was recently added to PyTorch. See Accelerating PyTorch with CUDA Graphs for more details. CUDA graphs support in PyTorch resulted in around a 15% end-to-end performance gain in CosmoFlow for the strong scaling scenario, which is most sensitive to latency and jitter.
OpenCatalyst
Load balancing across GPUs
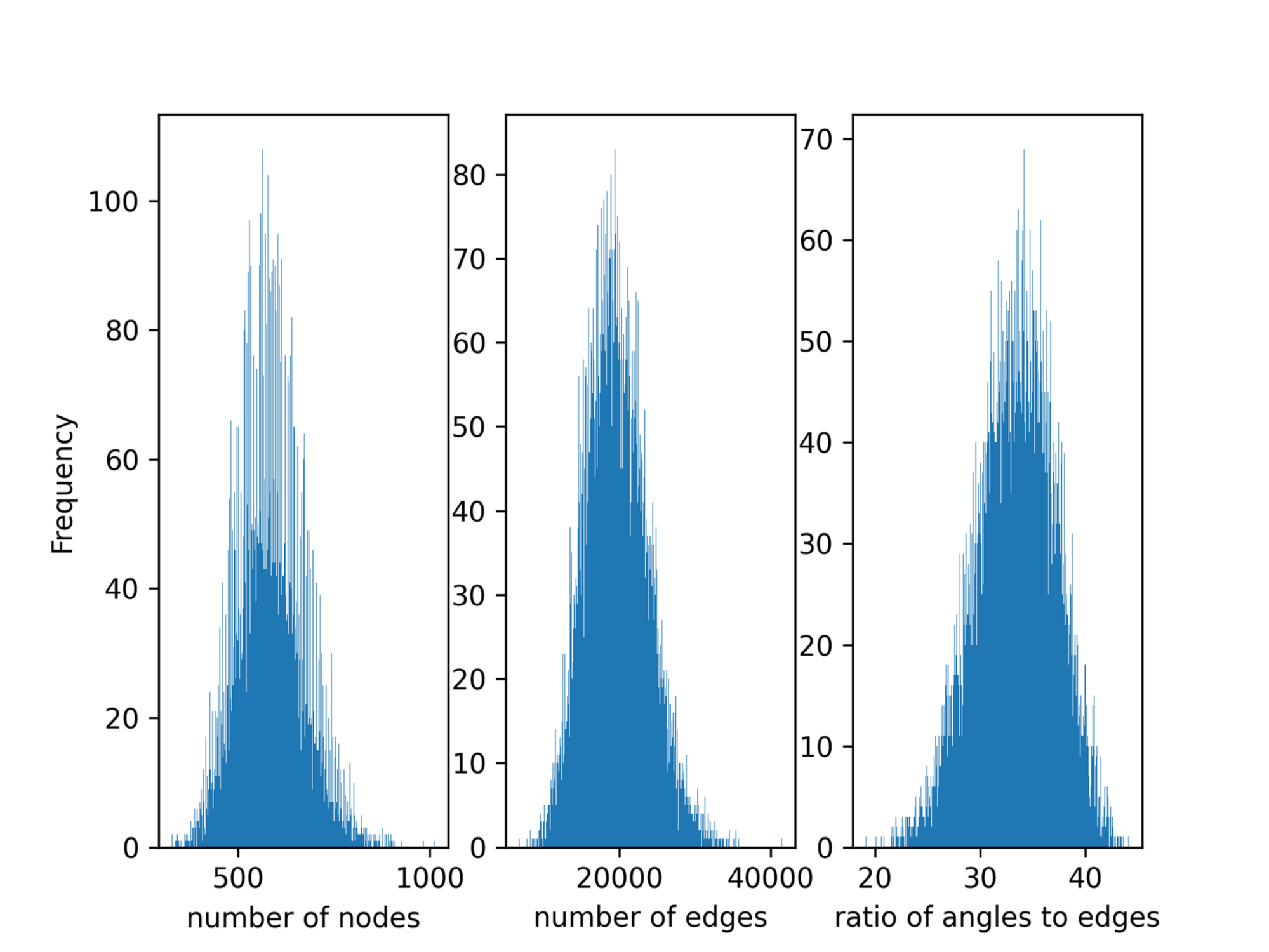
Data parallelism splits the global batch equally between each GPU. However, data-parallel task partitioning, by default, does not consider load imbalance within the batch. Load imbalance exists in Open Catalyst between the samples in a batch since the number of atoms of different molecules, the number of edges, and triplets in the graph obtained from molecules vary substantially (Figure 2).
This imbalance results in a large synchronization overhead in the multi-GPU setting. For the strong-scaling scenario, this results in 32% of the computation time being wasted. Lawrence Berkeley National Laboratory (LBNL) introduced an algorithm to balance the load across GPUs in MLPerf HPC v1.0, and this was adopted in the NVIDIA submission this round.
This algorithm first preprocesses the training data to obtain the number of edges for each sample. In the sampling stage, each GPU is given the indices of the local samples and performs a global ALLgather to get the indices of global samples.
Then the global samples are sorted by the number of edges and distributed across workers, so that each GPU processes as close to an equal number of edges as possible. This algorithm balances the workload well but introduces a large communication overhead especially as the application scales to more GPUs. This is the same algorithm used in the Open Catalyst submission from LBNL in v1.0.
NVIDIA also improved the sampling function in v2.0. The load balancing sampler avoids global (inter-GPU) communication by fetching the indices of all the samples in the global batch to all workers at the beginning. As before, samples are sorted by the number of edges, and partitioned into different buckets such that each bucket has the same approximate number of edges. Finally, each worker gets its bucket containing the indices of the samples that correspond to its global rank.
Figure 2. Load imbalance in Open Catalyst, showing the number of atoms, number of edges, and ratio of angles to edges all varying significantly across iterations
Kernel fusion using nvFuser and cuGraph-ops
There are more than 10K kernels in the original OpenCatalyst model as downloaded from MLCommons GitHub. The deep learning compiler for PyTorch, nvFuser, is a common optimization methodology that uses just-in-time (JIT) compilation to fuse multiple operations into a single kernel. The approach decreases both the number of kernels and global memory transactions.
To achieve this, NVIDIA modified the model script to enable JIT in PyTorch. Optimized fused kernels were also implemented in cuGraph-ops that were exposed through the RAPIDS framework. With the help of nvFuser and cuGraph-ops, the total number of kernels can be reduced by more than 90%.
Fusing small GEMMs to improve GPU utilization
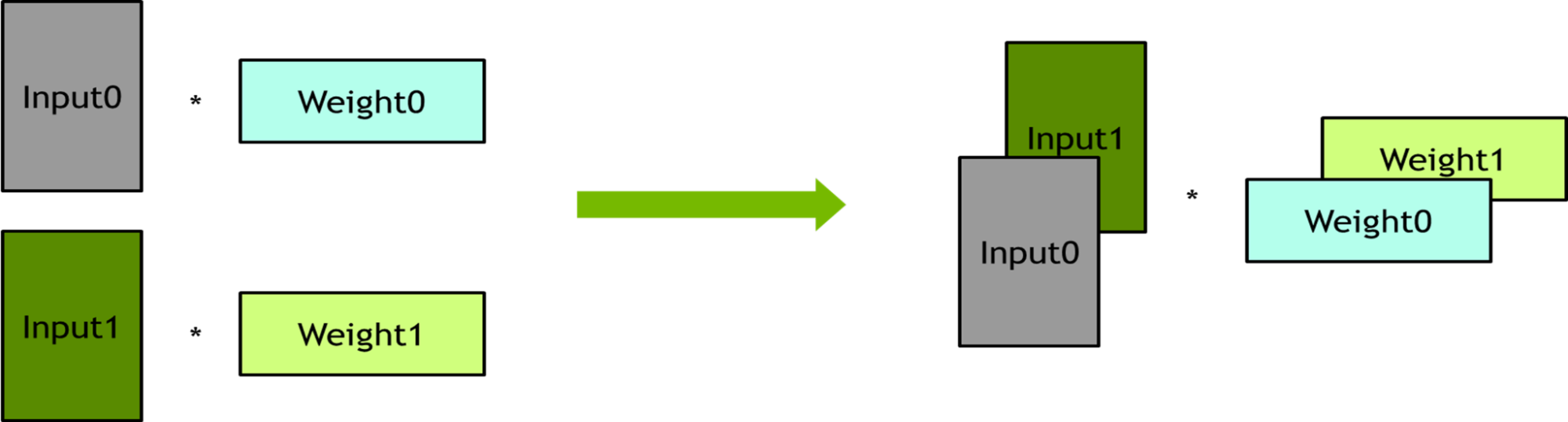
In the original computation graph, there are many small general matrix multiplications (GEMMs) which are executed sequentially and cannot saturate the GPU. These small GEMM operations can be fused to reduce the number of kernels and improve GPU utilization. Three kinds of GEMM fusions were applied–packing, batching, and horizontal fusion–as explained below. The only change was made to the model script to implement these fusions.
Packing – Several linear layers share the same input. One large GEMM was used to replace a set of several small GEMMs.
Figure 3. Linear layers sharing input
Batching – Several linear layers have no dependency on each other. These linear layers were bundled into batch operations to improve the degree of parallelism.
Figure 4. Linear layers computed independently
Horizontal fusion –The formula of the output reduction can be expressed as w1 x 01 + w2 x 02 + w3 x 03 + w4 x 04 + w5 x 05, which just matches the block multiplication of matrices and they can be packed together.
Figure 5. Matrix multiplication reduction
Eliminating redundant computation on triplets
In the original computation graph, each edge feature is expanded to triplets and then each triplet performs an elementwise multiplication. The number of triplets is about 30x the number of edges, which results in a large number of redundant computations. To remove the redundant computations, elementwise multiplication was performed on edge features first and then expanded to perform edge features to triplets.
Pipeline optimization
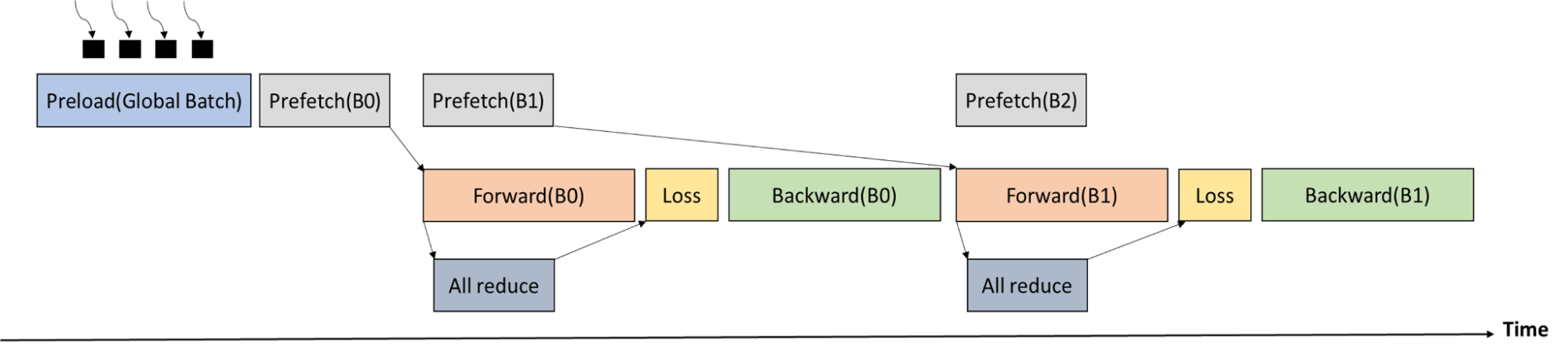
An ALLReduce communication across all the workers is required before the loss stage to obtain the total number of atoms in the current global batch. As the execution time of forward pass is longer than the execution time of ALLReduce, the communication can be well overlapped.
Figure 6 shows the training process timeline. The global batch is first loaded by multiple processes into CPU memory. Memcpy from CPU memory to GPU memory and ALLReduce (to get the number of atoms in the global batch) are overlapped with forward pass.
Figure 6. Training process timeline
Data staging
The training data of the Open Catalyst benchmark is 300 GB, and one DGXA100 node has a system memory of 2,048 GB and 256 threads (128 threads per socket, with two sockets per node). As a result, the whole training data can be preloaded into the CPU memory at the beginning. There is no need to load the minibatch from disk to CPU memory in every training step.
To accelerate data preload, NVIDIA launched 256 processes, each loading 300/256 (~1.2) GB of the training dataset. It took about 10s~15s to finish the preload, which is negligible with respect to the end-to-end training time.
DeepCam
Loading data
Previously, the transparent in-memory data loader utilized background processes to cache data locally in dynamic random-access memory (DRAM). This causes a large overhead, and thus the loader was reimplemented to employ threads instead.
Performance was previously limited by the Python Global Interpreter Lock (GIL). This time, the C++ based IO helper class was optimized to release the GIL. This approach allows the background loading to overlap with other CPU work. The same optimization was applied to the distributed data stager for the weak scaling score, improving end-to-end performance by about 15%.
Full iteration CUDA graph capture
Compared to MLPerf HPC v1.0, the scope of CUDA graph capture was extended to the full iteration, forward and backward pass, optimizer, and learning rate scheduler step. For this purpose, the sync-free optimizer FusedMixedPrecisionLAMB and DistributedLAMB from the NVIDIA APEX packages were employed for weak and strong scaling benchmarks.
Additionally, all DeepCAM learning rate schedulers were ported to GPU. By increasing the fraction of the computation that is executed inside the CUDA graph, performance variability across devices that stems from CPU execution variability is reduced. Scale-out performance improves as a result.
Distributed optimizer
For improving strong scaling performance, the DistributedLAMB optimizer was used. This optimizer is especially suited for small per-GPU local batch sizes and large scales, since optimizer cost is more pronounced in such settings. The performance gain at scale is about 3% end-to-end for DeepCAM.
cuDNN kernel optimizations
DeepCAM features a large number of computing kernels with different performance characteristics. While NVIDIA improved the performance of grouped convolutions in v1.0, the performance of pointwise convolutions was also improved in v2.0. They are used together with the grouped convolutions to form depth-wise separable convolutions.
MLPerf HPC v2.0 final results
AI is changing how science is done with high performance computing. Each year, new and more accurate surrogate models are built and shown to vastly outpace physics-based simulations with sufficient accuracy to be useful. Protein folding and the advent of OpenFold, RoseTTAFold, and AlphaFold 2 have been revolutionized by this AI-based approach, bringing protein structure-based drug discovery within reach.
MLPerf HPC reflects the supercomputing industry’s need for an objective, peer-reviewed method to measure and compare AI training performance for use cases relevant to HPC.
NVIDIA has made significant progress since the MLPerf HPC v1.0 submission in 2021. The Selene supercomputer shows that the NVIDIA A100 Tensor Core GPU and the NVIDIA DGX-A100 SuperPOD, though nearly three years old, are still the best system for AI training for HPC use cases and beyond.
As AI becomes increasingly capable and pervasive, MLPerf benchmarks, developed by MLCommons, have emerged as an invaluable tool for organizations to evaluate…
As AI becomes increasingly capable and pervasive, MLPerf benchmarks, developed by MLCommons, have emerged as an invaluable tool for organizations to evaluate the performance of AI infrastructure across a wide range of popular AI-based workloads.
MLPerf Training v2.1—the seventh iteration of this AI training-focused benchmark suite—tested performance across a breadth of popular AI use cases, including the follwoing:
Image classification
Object detection
Medical imaging
Speech recognition
Natural language processing
Recommendation
Reinforcement learning
Many AI applications take advantage of multiple AI models deployed in a pipeline. This means that it is critical for an AI platform to be able to run the full range of models available today as well as provide both the performance and flexibility to support new model innovations.
The NVIDIA AI platform submitted results on all workloads in this round and it continues to be the only platform to have submitted results on all MLPerf Training workloads.
Figure 1. Real-world AI example showing the use of many AI models
NVIDIA Hopper delivers a big performance boost
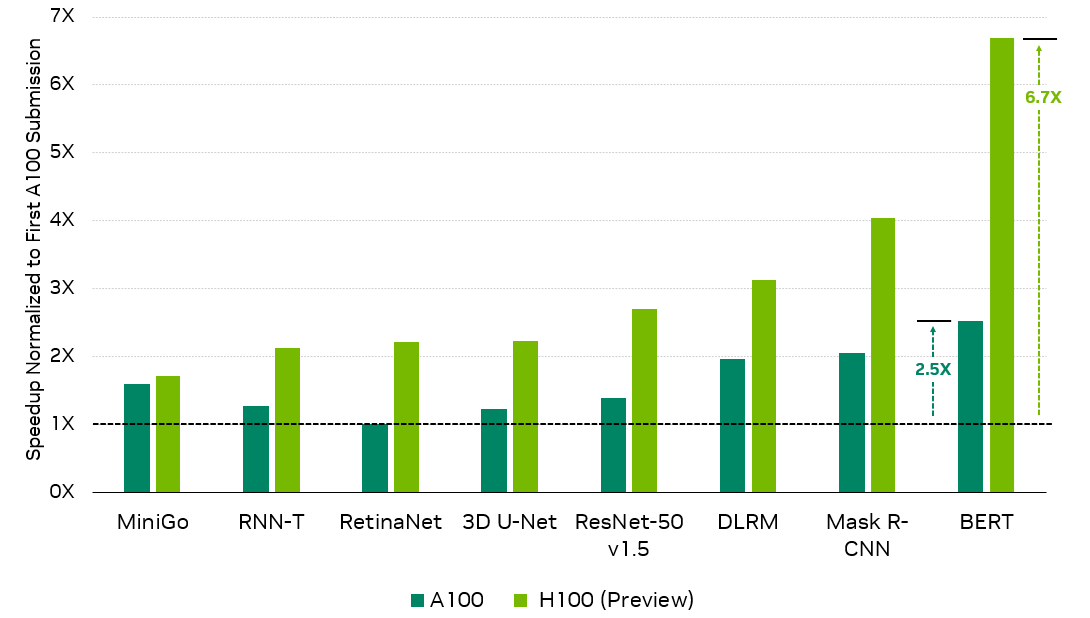
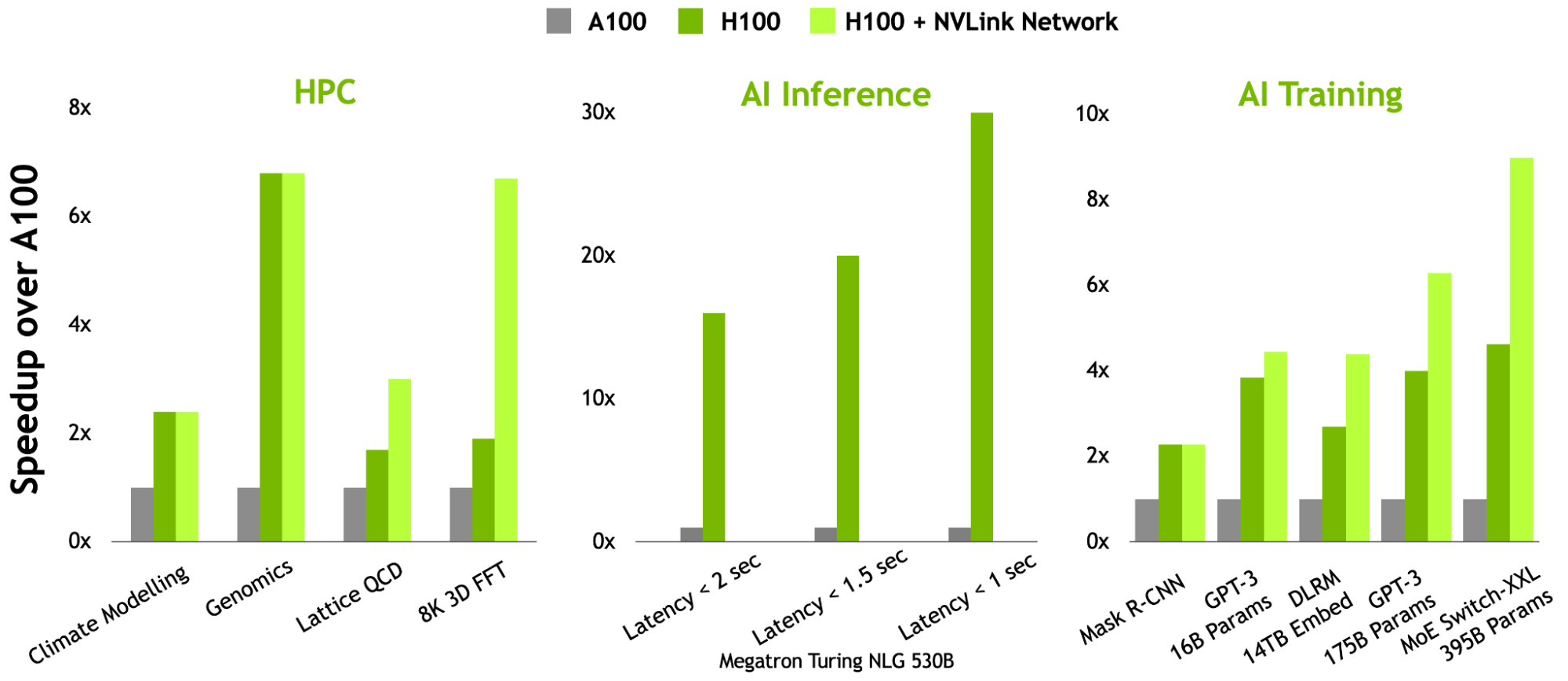
In this round, NVIDIA submitted its first MLPerf Training results using the new H100 Tensor Core GPU, demonstrating up to 6.7x higher performance compared to the first A100 Tensor Core GPU submission and up to 2.6x more performance compared to the latest A100 results.
Figure 2. Performance improvements of the latest H100 and A100 submissions compared to the first A100 submission on each MLPerf Training workload
ResNet-50 v1.5: 8x NVIDIA 0.7-18, 8x NVIDIA2.1-2060,8x NVIDIA 2.1-2091 | BERT: 8x NVIDIA 0.7-19, 8x NVIDIA2.1-2062,8x NVIDIA 2.1-2091 | DLRM: 8x NVIDIA 0.7-17, 8x NVIDIA2.1-2059,8x NVIDIA 2.1-2091 | Mask R-CNN: 8x NVIDIA 0.7-19, 8x NVIDIA2.1-2062,8x NVIDIA 2.1-2091 | RetinaNet: 8x NVIDIA 2.0-2091, 8x NVIDIA2.1-2061,8x NVIDIA 2.1-2091 | RNN-T: 8x NVIDIA 1.0-1060, 8x NVIDIA2.1-2061,8x NVIDIA 2.1-2091 | Mini Go: 8x NVIDIA 0.7-20, 8x NVIDIA2.1-2063,8x NVIDIA 2.1-2091 | 3D U-Net: 8x NVIDIA 1.0-1059, 8x NVIDIA2.1-2060,8x NVIDIA 2.1-2091 First NVIDIA A100 Tensor Core GPU results normalized for throughput due to higher accuracy requirements introduced in MLPerf Training 2.0 where applicable. The MLPerf name and logo are trademarks. For more information, seewww.mlperf.org.
In addition, in its fifth MLPerf Training, A100 continued to deliver excellent performance across the full suite of workloads, delivering up to 2.5x more performance compared to its first submission, as a result of extensive software optimizations.
This post offers a closer look at the work done by NVIDIA to deliver these results.
BERT
For this round of MLPerf, several optimizations were implemented for our BERT submission, including the use of the FP8 format and the implementation of optimizations for FP8 operations, a reduction in CPU overhead, and the application of sequence packing for small scales.
Integration with NVIDIA Transformer Engine
One of thekey optimizations employed in our BERT submission in MLPerf Training v2.1 was the use of the NVIDIA Transformer Engine library. The library accelerates transformer models on NVIDIA GPUs and takes advantage of the FP8 data format supported by the NVIDIA Hopper fourth-generation Tensor Cores.
BERT FP8 inputs were used for fully connected layers, as well as for the fused multihead attention kernel that implements multihead attention in a single kernel. Using the FP8 format improves memory access times by reducing the amount of data transferred between memory and streaming multiprocessors (SMs) compared to the FP16 format.
Using the FP8 format for the inputs of matrix multiplications also takes advantage of the higher computational rates of FP8 format compared to the FP16 format on NVIDIA Hopper architecture GPUs. By taking advantage of the FP8 format, Transformer Engine accelerates the end-to-end training time by 37% compared to not using the Transformer Engine on the same hardware.
Transformer Engine abstracts away the FP8 tensor type from the user. As a result, the tensor format at the input and output of the encoder layers remains as FP16. The details of FP8 usage are handled by the Transformer Engine library inside the encoder layer.
Both E4M3 and E5M2 formats are employed for FP8, referred to as a hybrid recipe in Transformer Engine. For more information about FP8 format and recipes, see Using FP8 with Transformer Engine.
FP8 general matrix multiply layers
The Transformer Engine library features custom fused kernel implementations to accelerate commonly used NLP and data transformation operations.
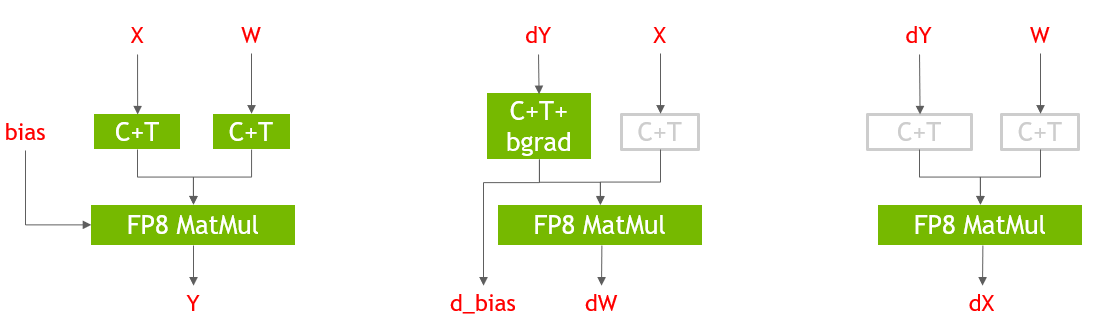
Figure 3 shows the FP8 implementation of the forward and backward passes for the Linear layer in PyTorch. The inputs to the GEMM layers are converted to FP8 using the Cast+Transpose (C+T) fused kernel provided by the Transformer Engine library and the GEMM outputs are saved in FP16 precision. FP8 GEMM layers result in a 29% improvement in end-to-end training time. In Figure 3, the C+T operations in gray are redundant and are shown for illustrative purposes only. FP8 GEMM layers use the cuBLAS library in the backend of the Transformer Engine library.
Figure 3. FP8 GEMM patterns employed in BERT through Transformer Engine
Higher-efficiency, fused multihead attention for FP8
In this round, we implemented a different version of fused multihead attention that is more efficient for BERT use case, inspired by the FlashAttention algorithm.
This implementation does not write out the softmax output or dropout mask in the forward pass to be used in the backward pass. Instead, it recomputes the softmax output in the backward pass and uses the random number generator states directly from the forward pass to regenerate the dropout mask in the backward pass.
This approach is much more efficient, particularly when FP8 inputs and outputs are used due to reduced register pressure. It results in an 8% improvement in end-to-end time-to-train.
Minimize overhead using dataset packing
Previously, for small scales, we used an unpadding strategy to minimize the overhead that stems from varying sequence lengths and additional padding.
An alternative approach is to pack the sequences in a way such that they almost completely fill the batch matrix, making the additional padding negligible while keeping the buffer sizes static across iterations.
In our latest submission, we used a sequence packing algorithm to preprocess training data for small and medium-scale (64 GPUs or less) NVIDIA Hopper submissions. This is similar to the technique employed in previous rounds for larger scales with 1,024 GPUs and more.
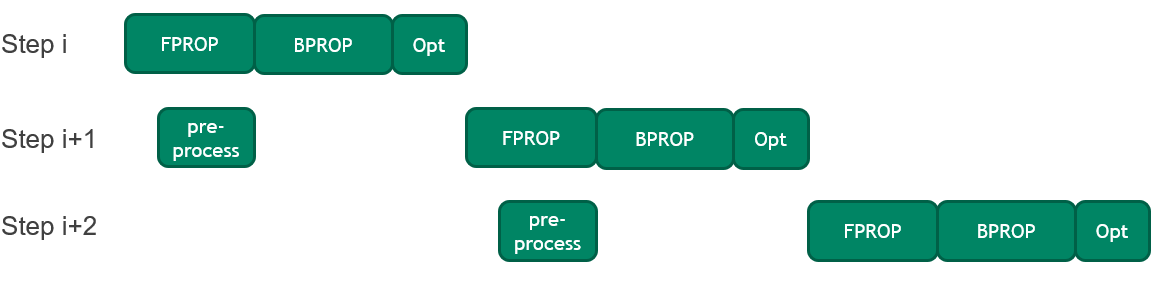
Overlap CPU preprocessing with GPU operations to improve training time
Each training step in BERT involves preprocessing the input sequences (also known as mini-batches) on the CPU before copying them to the GPU.
In this round, an optimization was introduced to pipeline the forward pass execution of the current mini-batch with preprocessing of the next mini-batch. This optimization reduces idle GPU time, which is especially important as GPU execution gets faster. It resulted in a 2% improvement in end-to-end training time.
Figure 4. Pipelining of data preprocessing and forward pass
New hyperparameter and batch sizes optimized for H100
With the new H100 Tensor Core GPUs based on the NVIDIA Hopper architecture, throughput scales extremely well with growing local batch sizes. As a result, we increased per-accelerator batch sizes and optimized the training hyperparameters accordingly.
ResNet-50
In this round of MLPerf, we extended the fusion of convolution and memory-bound operations beyond epilog fusions and improved the performance of the pooling operation.
Conv-BN fprop Fusion
The ResNet-50 model consists of a Conv->BN->Relu->Conv->BN->ReLu pattern, resulting in idle Tensor Cores when memory-bound normalization layers are being executed.
In MLPerf Training 2.1, BatchNorm was split into BatchNorm Stats calculation and BatchNorm Apply.
The programmability of NVIDIA GPUs enabled us to fuse the stats calculation in the epilog of the previous convolution, and fuse Apply in the mainloop of the next convolution.
For weight gradients calculation, however, this means the input must be recomputed by fusing BatchNorm Apply and ReLu in the wgrad. With new, high-performance kernels in cuDNN, this feature yielded a 4.2% end-to-end speedup for small scales.
Faster pooling operations
The ResNet-50 model employs maxPool and AvgPool operations in the stem and classifier blocks. By using the new graph API in cuDNN and taking advantage of the higher DRAM bandwidth in the NVIDIA H100 Tensor Core GPU, we sped up the pooling operations by over 3x. This resulted in a speedup of over 3% in MLPerf Training v2.1.
RetinaNet
The major optimization for RetinaNet in this round of MLPerf was improving score computation in the NVCOCO library to remove CPU bottlenecks for the max-scale submission. Additional optimizations include new fusions, extending the reach of CUDA Graphs for reducing CPU overheads, and using the DALI library to improve data preprocessing in the evaluation phase.
NVCOCO: Accelerating scoring
As GPU execution gets faster, the portions of the code that execute on the CPU can bottleneck performance. This is especially true at large scales where the amount of work executed per GPU is smaller.
Currently, the mAP metric computation during the evaluation phase runs on the CPU, and it was the performance bottleneck in our previous max-scale submission.
In this MLPerf round, we optimized this evaluation computation to eliminate CPU bottlenecks and enable our GPU optimizations to shine. This has particularly helped with the max-scale submission.
The C++ extensions were also further optimized in NVIDIA cocoapi. For its mAP metric computation, we improved COCO’s performance by 3x and overall 20x over the original cocoapi implementation. These optimizations mostly are focused on file I/O, memory access, and load balancing.
We replaced pybind11 with native CPython PyModules as the interface between Python and C++. By reading JSON files directly on the C++ side and interacting with the CPython pointers of NumPy objects, we eliminated deep copies that might have existed before.
Also, loop transformations, such as loop fusion and loop reordering, have significantly improved cache locality and memory access efficiency for multithreading.
We added more parallel regions in OpenMP to exploit additional parallelism and adjusted tasking schedules to better load balance across the threads.
These optimizations in the metric computation have overall resulted in a ~60% end-to-end performance improvement at the 160-node scale. Removing CPU bottlenecks from the critical path also enabled us to increase our maximum scale to 256 nodes from 160 nodes. This yields an additional ~30% reduction in the total time-to-train, despite an increase in the number of epochs required to achieve the target accuracy.
The total end-to-end speedup from the COCO optimization is 2.3x.
Extending CUDA graphs: Sync-free Adam optimizer
CUDA Graphs provides a mechanism to launch multiple GPU kernels without CPU intervention, mitigating CPU overheads.
In MLPerf Training v2.0, CUDA Graphs was used extensively in our RetinaNet submission. However, gradient scaling and the Adam optimizer step were left out of the region that was graph-captured, due to CPU-GPU synchronization in the optimizer implementation.
In this MLPerf Training v2.1 submission, the Adam optimizer was modified to achieve a sync-free operation. This enabled us to further extend the reach of CUDA graphs and reduce CPU overhead.
Additional cuDNN runtime fusion
In addition to the conv-bias-relu fusion used in the previous MLPerf submission, a conv-scale-bias-relu fusion was employed in the RetinaNet backbone by using cuDNN runtime fusion. This enabled us to avoid kernel launch latency and data movements, resulting in a 1.5% end-to-end speedup.
Using NVIDIA DALI during evaluation
The significant speedups achieved in the training passes have resulted in an increase in the proportion of the time spent on the evaluation stages.
NVIDIA DALI was previously employed during training but not during evaluation. To address the relatively slow evaluation iteration times, we used DALI to efficiently load and preprocess data.
Mask R-CNN
In this round of MLPerf, beyond improving the parallelization of different blocks of Mask R-CNN, we enabled the use of new kernel fusions and reduced the CPU overhead in training iterations.
Faster JSON interpreter
Switching from ujson to orjson reduced the loading time of the COCO 2017 annotations file by approximately 1.5 seconds.
Faster evaluation and NVCOCO optimizations
We used the NVCOCO improvements explained for RetinaNet to reduce the end-to-end time for all Mask R-CNN configurations by about 2 seconds. On average, these optimizations reduce evaluation time by approximately 2 seconds per epoch, but only the last evaluation is exposed in end-to-end time.
The optimized NVCOCO library is a drop-in replacement, making the optimizations directly available to end users.
Vectorized batched ROI Align
Region of Interest (ROI) Align performs bilinear interpolation, which requires a fair bit of math work. As this work is the same for all channels, vectorizing across the channel dimension reduced the amount of work needed by about 4x.
The way launch configurations are calculated were also changed to avoid launching more CUDA threads than needed.
Combined, these efforts improved performance for ROI Align forward propagation by about 5x.
Exposing more parallelism in model code
Mask R-CNN, like most models, incorporates many sections of code that can be executed in parallel. For example, mask-head loss calculation involves calculating a loss for multiple proposals, where each proposal loss can be calculated independently.
We achieved a 3-5% speedup by identifying such sections that can be parallelized and placing them on separate CUDA streams.
Removing more CPU-GPU syncs
In sections of the code where CUDA Graphs is not employed, the GPU kernels are launched from the CPU code. CPU code primarily performs bookkeeping tasks, such as managing memory, keeping track of pointers and indices, and so on.
If the CPU code is not fast enough, the GPU kernel finishes and sits idle before the next kernel is launched. Improving CPU performance to the point where the CPU portion of the code runs faster than the GPU portion is critical to maximizing training performance. This requires some amount of CPU run-ahead.
CPU-GPU synchronizations prevent this because they keep the CPU idle until the current GPU work completes, so removing CPU-GPU synchronizations is also critical for training performance.
We have done this in past rounds for submissions using the NVIDIA A100 Tensor Core GPU. However, the significant performance increase provided by the NVIDIA H100 Tensor Core GPU necessitated that more of these CPU-GPU synchronizations be removed.
This had a small impact on the NVIDIA A100 Tensor Core GPU results, as CPU overhead is not as pronounced for that GPU on Mask R-CNN. However, it improved performance on the H100 Tensor Core GPU by 25-30% for the 32-GPU configuration.
Runtime fusions in RPN and FPN
In previous rounds, we sped up the code by using the cudnn v8 API to perform runtime fusions for the ResNet-50 backbone of Mask R-CNN.
In this round, previous work was leveraged for RetinaNet to extend run time fusions to the RPN and FPN modules, further improving end-to-end performance by about 2%.
Boosting AI performance by 6.7x
The NVIDIA H100 GPU based on the NVIDIA Hopper architecture delivers the next large performance leap for the NVIDIA AI platform. It boosts performance by up to 6.7x compared to the first submission using the A100 GPU.
With software improvements alone, the A100 GPU demonstrated up to 2.5x more performance in this latest round compared to its debut submission, showcasing the continuous full-stack innovation delivered by the NVIDIA AI platform.
All software used for NVIDIA MLPerf submissions is available from the MLPerf repository, enabling you to reproduce our benchmark results. We constantly incorporate these cutting-edge MLPerf improvements to our deep learning framework containers. These containers are available on NGC, our software hub for GPU-optimized applications.




 The NVIDIA Grace Hopper Superchip Architecture is the first true heterogeneous accelerated platform for high-performance computing (HPC) and AI workloads. It…
The NVIDIA Grace Hopper Superchip Architecture is the first true heterogeneous accelerated platform for high-performance computing (HPC) and AI workloads. It…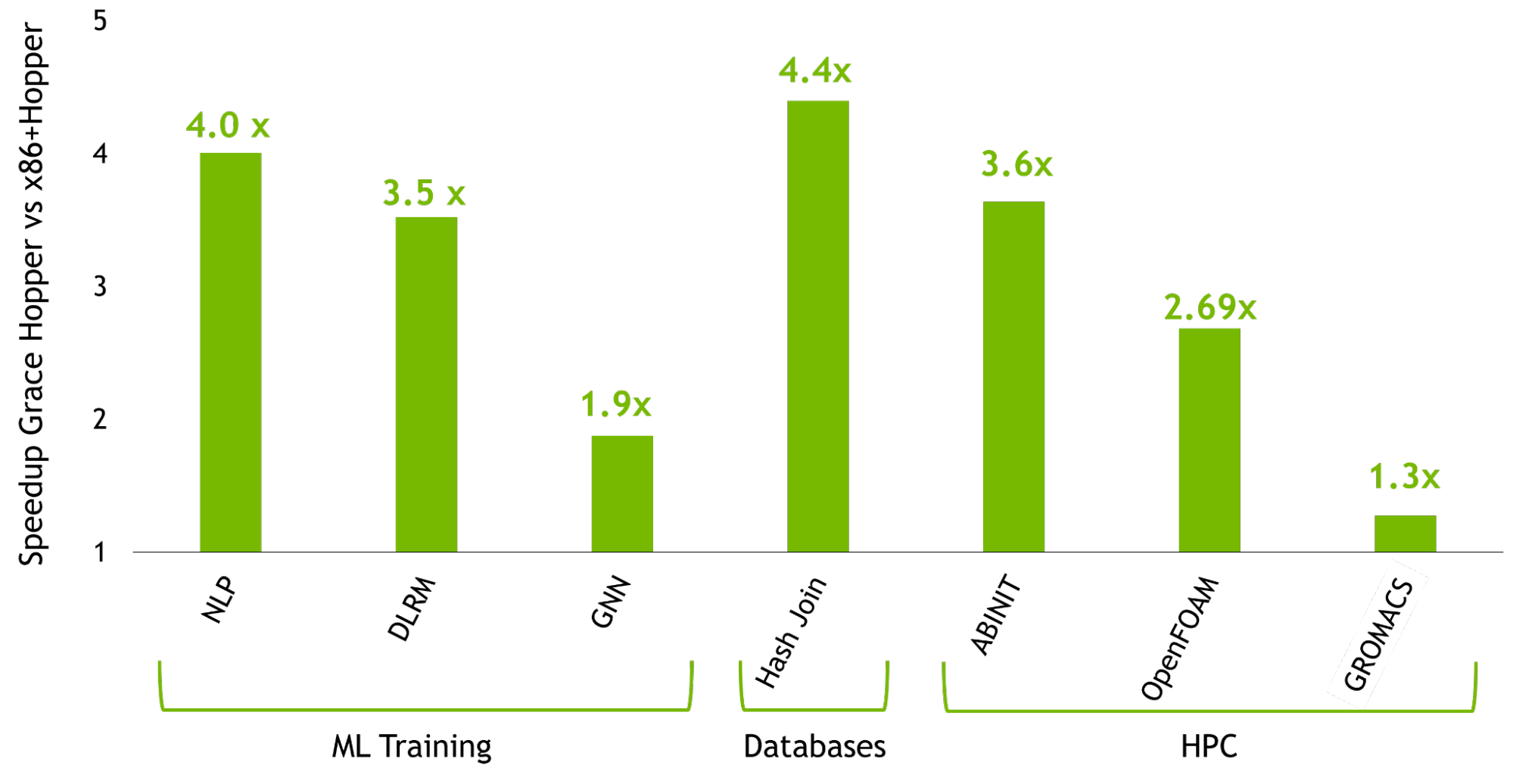




 TIME Magazine named NVIDIA Instant NeRF, a technology capable of transforming 2D images into 3D scenes, one of the Best Inventions of 2022. “Before…
TIME Magazine named NVIDIA Instant NeRF, a technology capable of transforming 2D images into 3D scenes, one of the Best Inventions of 2022. “Before… As enterprises continue to shift workloads to the cloud, some applications need to remain on-premises to maximize latency performance and meet security, data…
As enterprises continue to shift workloads to the cloud, some applications need to remain on-premises to maximize latency performance and meet security, data…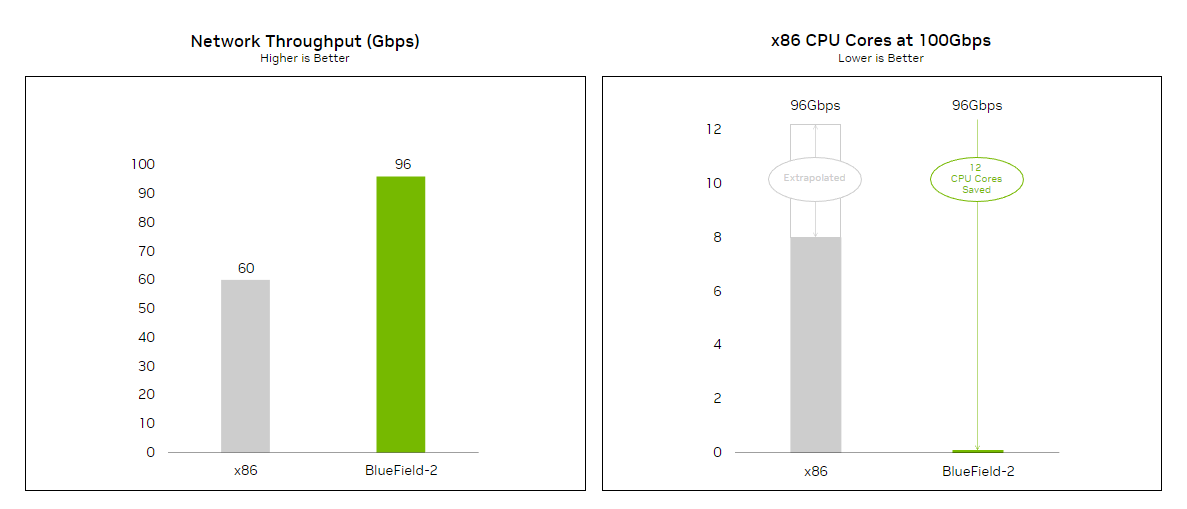
 As AI becomes increasingly capable and pervasive in high performance computing (HPC), MLPerf benchmarks have emerged as an invaluable tool. Developed by…
As AI becomes increasingly capable and pervasive in high performance computing (HPC), MLPerf benchmarks have emerged as an invaluable tool. Developed by…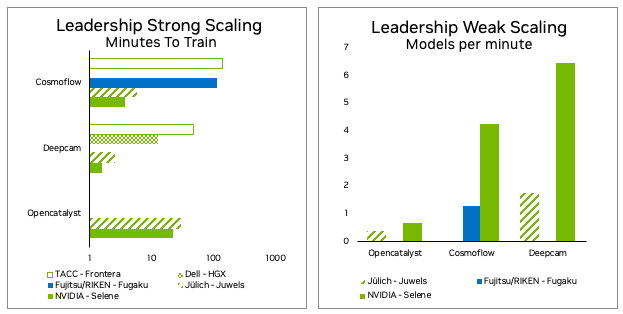


![Diagram shows a user asking their phone to identify the type of flower in an image and the many AI models that may be used to perform this identification task across several domains[SBE1] : audio, vision, recommendation, and TTS.](https://developer-blogs.nvidia.com/wp-content/uploads/2022/11/model-use-case.png)