The Acceleration Agency, a digital innovation and product design firm, is working on an active digital twin framework and toolkit called Project Gemini….
The Acceleration Agency, a digital innovation and product design firm, is working on an active digital twin framework and toolkit called Project Gemini. Inspired by the United States space program of the same name, Project Gemini uses active sensor fabric data and a wide range of data from sources like Google Sheets and Customer Relationship Management (CRM) platforms to replicate real-world settings in the virtual world.
The project launched with a digital replication of The Acceleration Agency’s main office located in Austin, Texas. Instrumented with a dense sensor fabric for real-time and historical spatial computation, the digital twin of the office includes employees and employee information (job title, ID#, gender, and date of birth) provided by Salesforce. It also tracks inventory items on site and can display information such as quantity, date of last interaction, temperature, and orientation.
With NVIDIA Omniverse real time, true-to-reality physics from PhysX, and physically accurate RTX rendering capabilities, the team anticipates that the Gemini active digital twin can be simulated with an unprecedented level of visual and physical fidelity and with complex simulations.
Leveraging USD and Omniverse Nucleus, users of the Project Gemini digital twin platform will be able to update content in a variety of tools in real time collaboratively instead of having to wait for new builds.
Connecting Google Sheets to NVIDIA Omniverse with a Kit Extension
Multiple abstraction layers and a sensor fabric layer allow a variety of sensors, databases, CRMs and object integration tools to connect to Omniverse. The connection allows real-time updates to inventory objects and information like temperature, humidity, and location.
To accomplish this, the team created a simple Omniverse Kit Extension enabled by a Python script that reads data from a Google Sheet and attaches the data to an object in Omniverse Kit. It allows someone to control the location, scale, and rotation of any selected object in Omniverse applications like Omniverse Code or Omniverse Create using the metadata in the spreadsheet. You can access the AccelerationAgency/omniverse-extensions through GitHub.
Using database and CRM tools with the extension makes the task of manipulating object data more scalable. When building digital twins at the scale of factories, stadiums, warehouses, and even cities, hundreds, thousands, and even millions of objects may need to be manipulated rapidly.
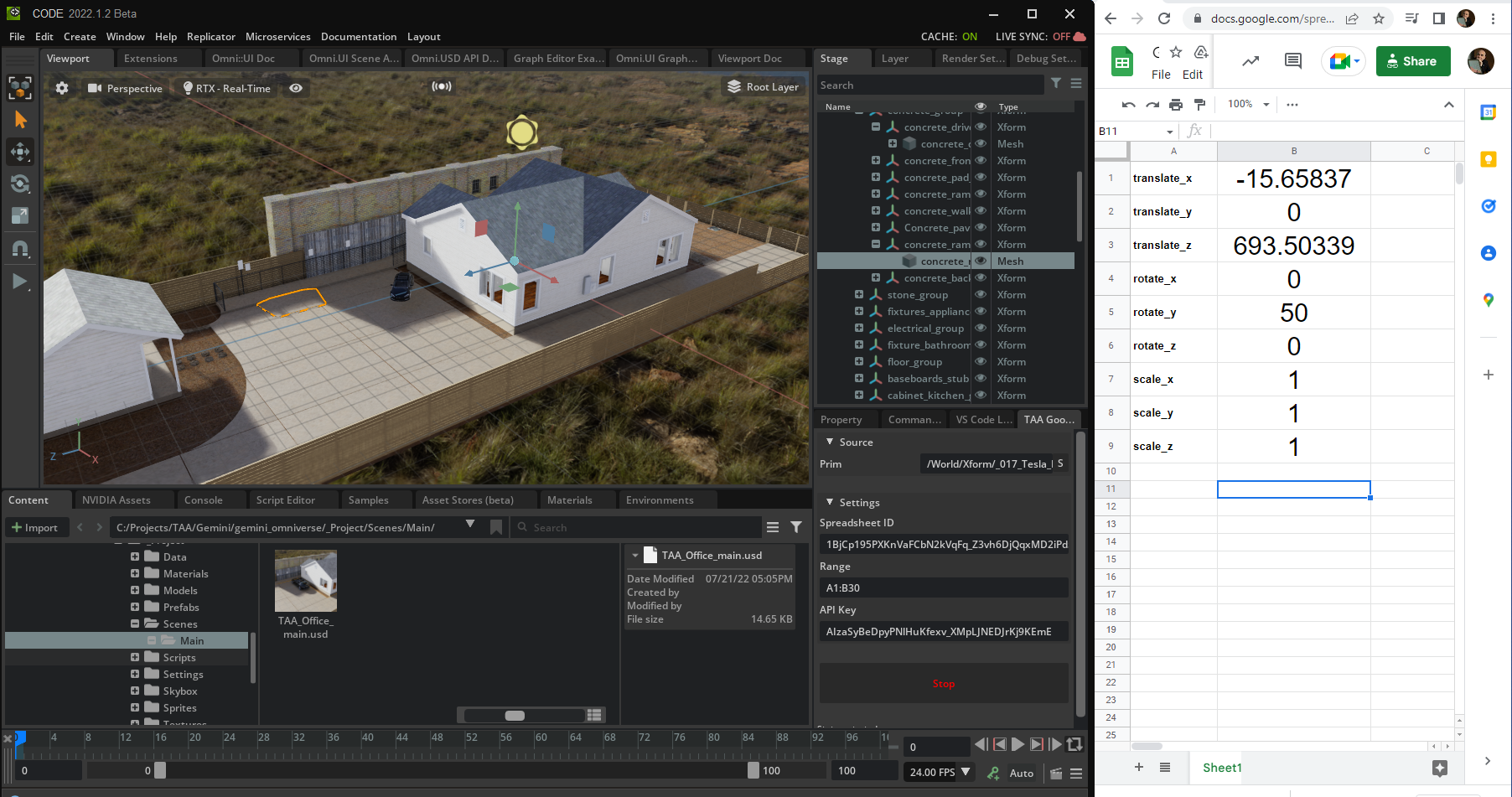
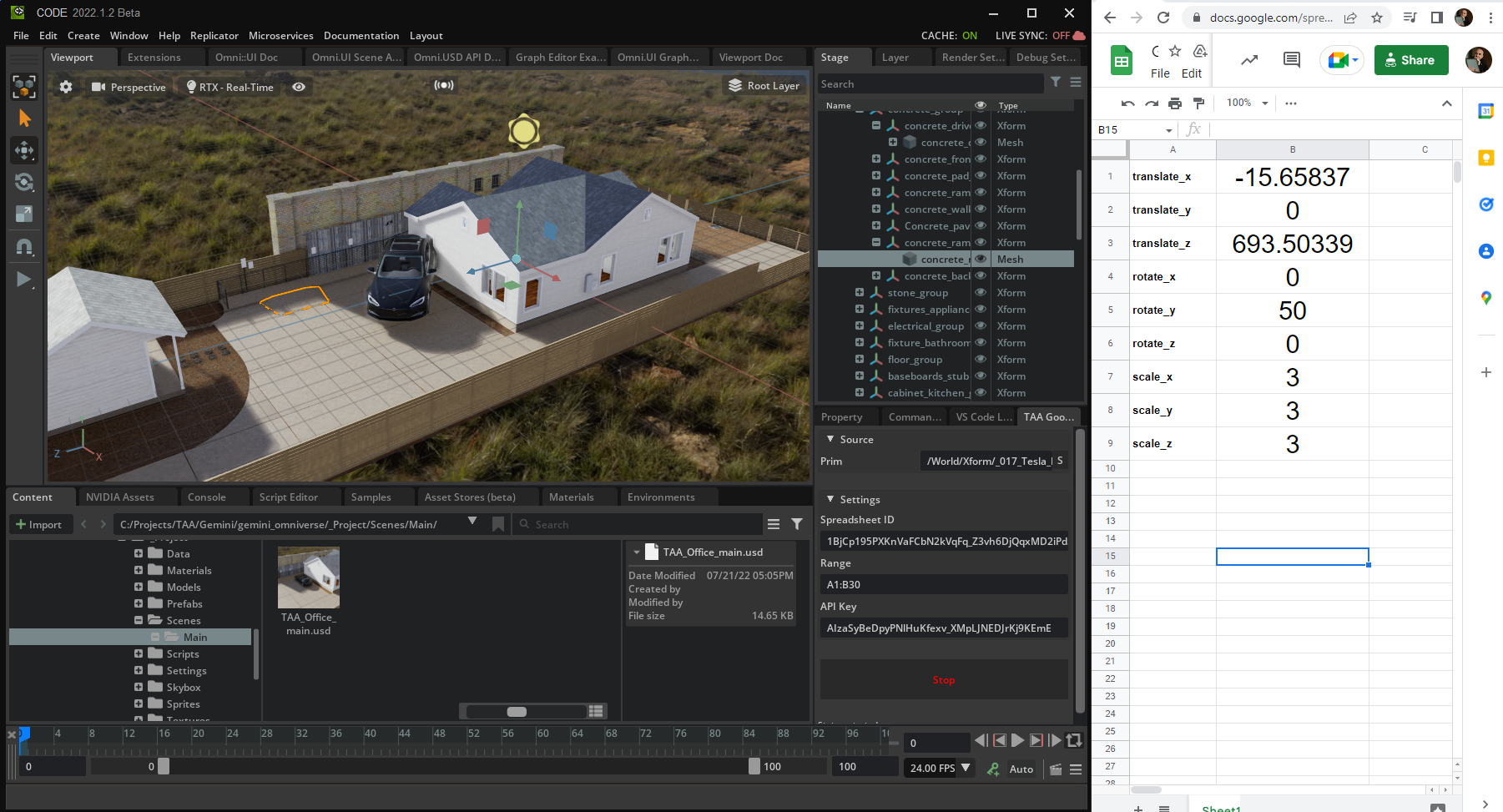
The Acceleration Agency loaded the USD version of their office digital twin into the Omniverse stage and used the extension to select and manipulate object data.
The images below show an example of how this process was done for a Tesla in the parking lot outside the agency office. Building this was fairly straightforward and only took a few days for a single developer to create. It can be extended to any data source.
Figure 1. Google Sheet with object location, scale, and rotation information
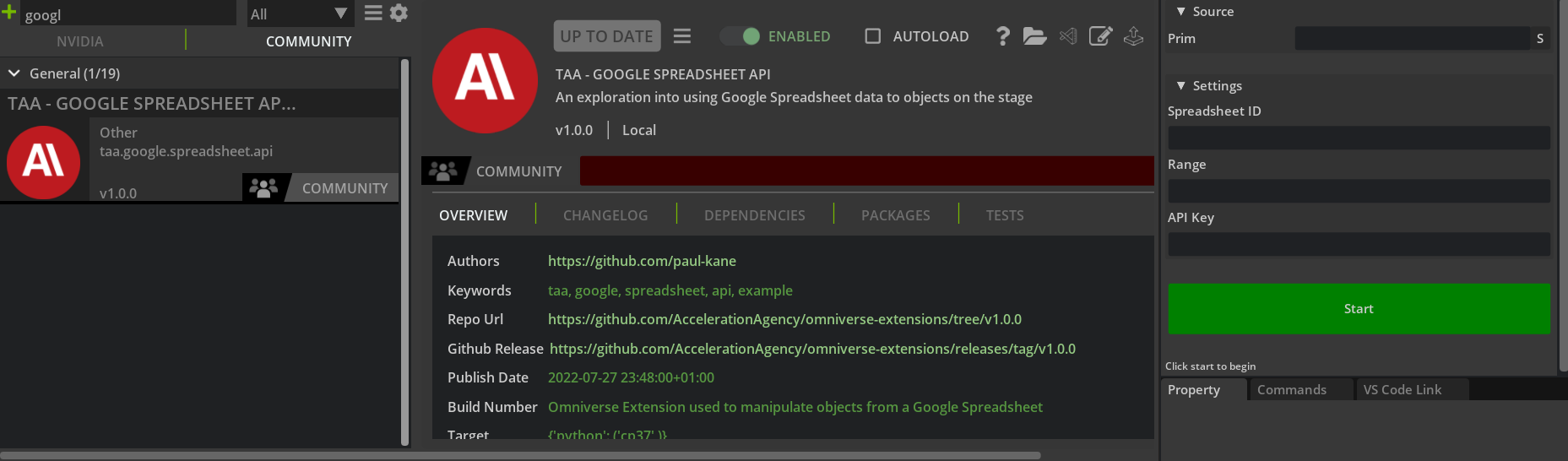
Figure 2. Selecting the Project Gemini-enabled extension from the extensions tab in Omniverse Code
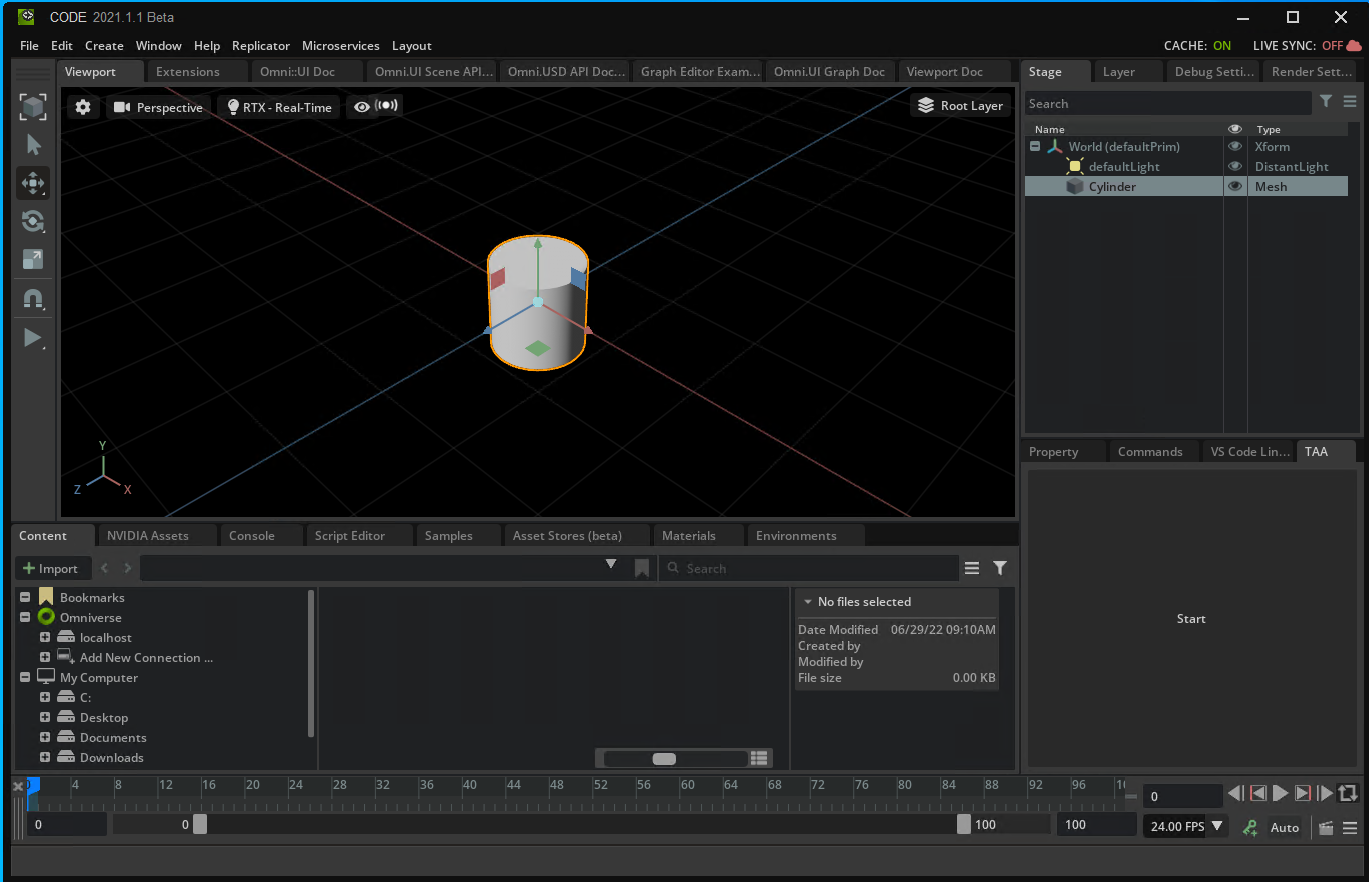
Figure 3. The object before running the extension to pull in the data from the Google Sheet
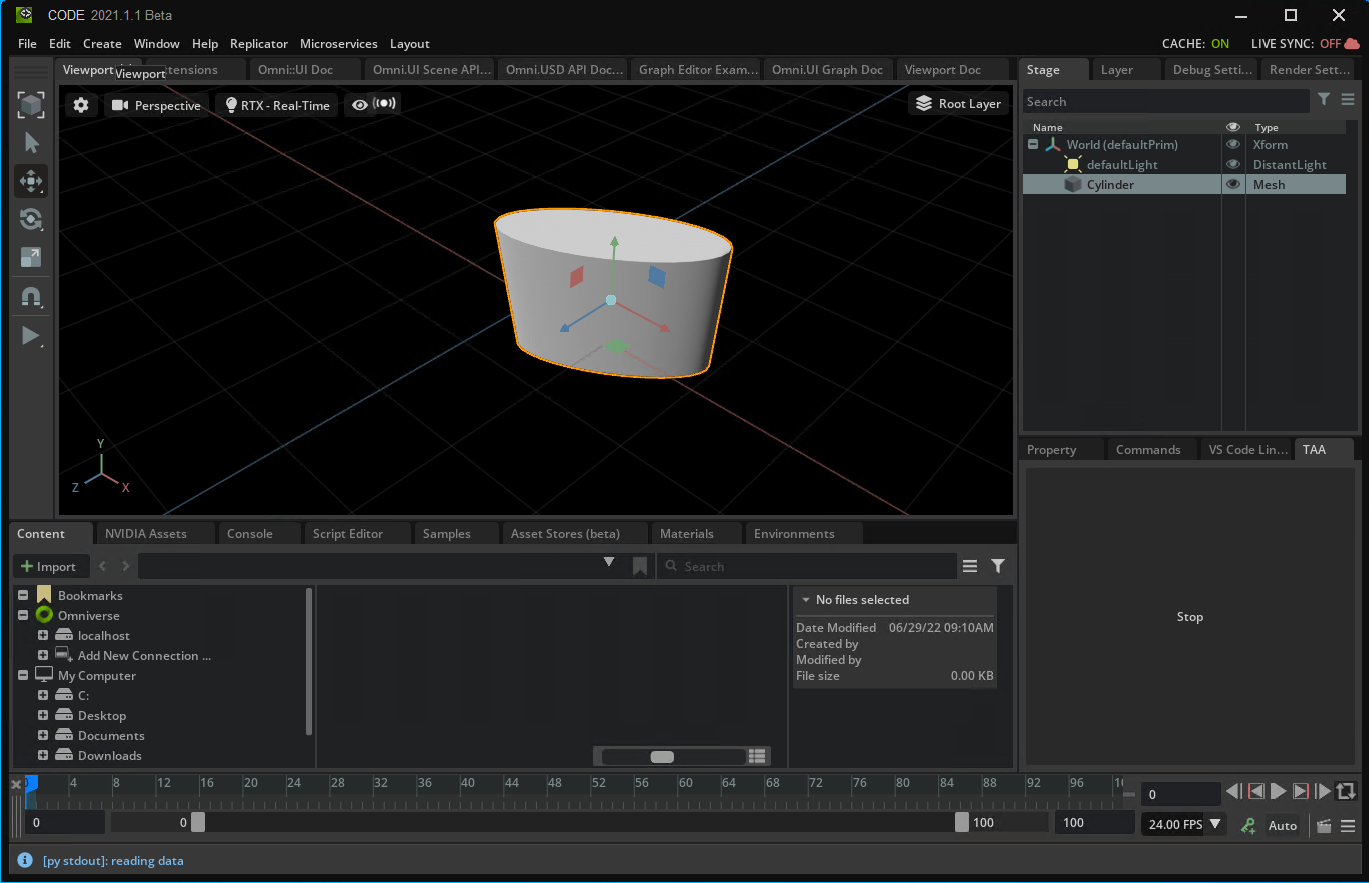
Figure 4. After running the extension to pull in the data from the Google Sheet, the object now has different parameters
Figure 5. Running the extension using the USD version of the office digital twin as the data source, then selecting the Tesla as the data object to manipulate
Figure 6. Tripling the scale factors of the Tesla in the Google Sheet updates through the extension and then propagates into the stage
Watch the extension in action with Starr Long, Executive Producer at The Acceleration Agency:
Adding RTX Renderer and Nucleus Collaboration
The next step for Project Gemini is to render in real time with the NVIDIA RTX Renderer and allow for real-time modifications through Nucleus. The real-time modifications are one of the advantages of working with the powerful USD 3D framework and composition engine. This will be coupled with historical recordings of real data which when played back can be mixed with these modifications to try different scenarios. Some of the use cases the team is targeting include construction sites, hospitals, and live event venues. To learn more, visit the Project Gemini website.
Figure 7. Digital twin of The Acceleration Agency office running in the NVIDIA RTX Renderer
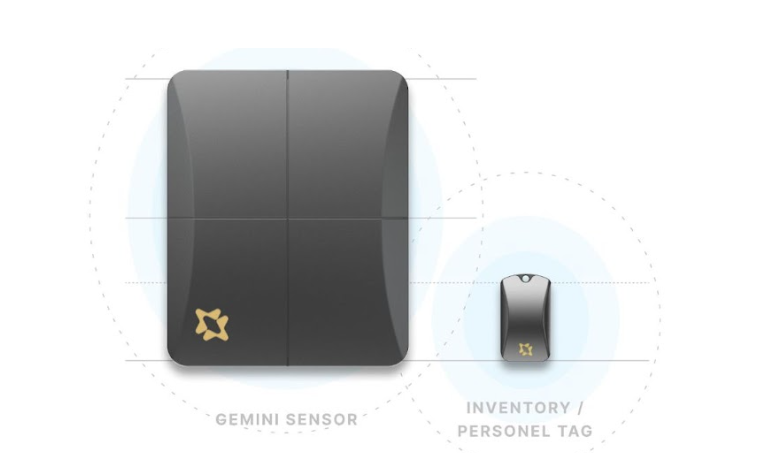
Figure 8. Sensors and tags that send real-time data about location, temperature, and other factors to the digital twin
You’re also invited to enter the inaugural #ExtendOmniverse developer contest, open through August 19, 2022. Create an Omniverse Extension using Omniverse Code for a chance to win an NVIDIA RTX GPU.
Innovative technologies in AI, virtual worlds and digital humans are shaping the future of design and content creation across every industry. Experience the latest advances from NVIDIA in all these areas at SIGGRAPH, the world’s largest gathering of computer graphics experts, running Aug. 8-11. At the conference, creators, developers, engineers, researchers and students will see Read article >
Posted by Bingyi Cao, Software Engineer, Google Research, and Mário Lipovský, Software Engineer, Google Lens
Computer vision models see daily application for a wide variety of tasks, ranging from object recognition to image-based 3D object reconstruction. One challenging type of computer vision problem is instance-level recognition (ILR) — given an image of an object, the task is to not only determine the generic category of an object (e.g., an arch), but also the specific instance of the object (”Arc de Triomphe de l’Étoile, Paris, France”).
Previously, ILR was tackled using deep learning approaches. First, a large set of images was collected. Then a deep model was trained to embed each image into a high-dimensional space where similar images have similar representations. Finally, the representation was used to solve the ILR tasks related to classification (e.g., with a shallow classifier trained on top of the embedding) or retrieval (e.g., with a nearest neighbor search in the embedding space).
Since there are many different object domains in the world, e.g., landmarks, products, or artworks, capturing all of them in a single dataset and training a model that can distinguish between them is quite a challenging task. To decrease the complexity of the problem to a manageable level, the focus of research so far has been to solve ILR for a single domain at a time. To advance the research in this area, we hosted multiple Kaggle competitions focused on the recognition and retrieval of landmark images. In 2020, Amazon joined the effort and we moved beyond the landmark domain and expanded to the domains of artwork and product instance recognition. The next step is to generalize the ILR task to multiple domains.
To this end, we’re excited to announce the Google Universal Image Embedding Challenge, hosted by Kaggle in collaboration with Google Research and Google Lens. In this challenge, we ask participants to build a single universal image embedding model capable of representing objects from multiple domains at the instance level. We believe that this is the key for real-world visual search applications, such as augmenting cultural exhibits in a museum, organizing photo collections, visual commerce and more.
Images1 of object instances coming from multiple domains, which are represented in our dataset: apparel and accessories, packaged goods, furniture and home goods, toys, cars, landmarks, storefronts, dishes, artwork, memes and illustrations.
Degrees of Variation in Different Domains To represent objects from a large number of domains, we require one model to learn many domain-specific subtasks (e.g., filtering different kinds of noise or focusing on a specific detail), which can only be learned from a semantically and visually diverse collection of images. Addressing each degree of variation proposes a new challenge for both image collection and model training.
The first sort of variation comes from the fact that while some domains contain unique objects in the world (landmarks, artwork, etc.), others contain objects that may have many copies (clothing, furniture, packaged goods, food, etc.). Because a landmark is always placed at the same location, the surrounding context may be useful for recognition. In contrast, a product, say a phone, even of a specific model and color, may have millions of physical instances and thus appear in many surrounding contexts.
Another challenge comes from the fact that a single object may appear different depending on the point of view, lighting conditions, occlusion or deformations (e.g., a dress worn on a person may look very different than on a hanger). In order for a model to learn invariance to all of these visual modes, all of them should be captured by the training data.
Additionally, similarities between objects differ across domains. For example, in order for a representation to be useful in the product domain, it must be able to distinguish very fine-grained details between similarly looking products belonging to two different brands. In the domain of food, however, the same dish (e.g., spaghetti bolognese) cooked by two chefs may look quite different, but the ability of the model to distinguish spaghetti bolognese from other dishes may be sufficient for the model to be useful. Additionally, a vision model of high quality should assign similar representations to more visually similar renditions of a dish.
Which physical objects belong to the instance class?
Single instance in the world
Many physical instances; may differ in size or pattern (e.g., a patterned cloth cut differently)
What are the possible views of the object?
Appearance variation only based on capture conditions (e.g., illumination or viewpoint); limited number of common external views; possibility of many internal views
Deformable appearance (e.g., worn or not); limited number of common views: front, back, side
What are the surroundings and are they useful for recognition?
Surrounding context does not vary much other than daily and yearly cycles; may be useful for verifying the object of interest
Surrounding context can change dramatically due to difference in environment, additional pieces of clothing, or accessories partially occluding clothing of interest (e.g., a jacket or a scarf)
What may be tricky cases that do not belong to the instance class?
Replicas of landmarks (e.g., Eiffel Tower in Las Vegas), souvenirs
Same piece of apparel of different material or different color; visually very similar pieces with a small distinguishing detail (e.g., a small brand logo); different pieces of apparel worn by the same model
Variation among domains for landmark and apparel examples.
Learning Multi-domain Representations After a collection of images covering a variety of domains is created, the next challenge is to train a single, universal model. Some features and tasks, such as representing color, are useful across many domains, and thus adding training data from any domain will likely help the model improve at distinguishing colors. Other features may be more specific to selected domains, thus adding more training data from other domains may deteriorate the model’s performance. For example, while for 2D artwork it may be very useful for the model to learn to find near duplicates, this may deteriorate the performance on clothing, where deformed and occluded instances need to be recognized.
The large variety of possible input objects and tasks that need to be learned require novel approaches for selecting, augmenting, cleaning and weighing the training data. New approaches for model training and tuning, and even novel architectures may be required.
Universal Image Embedding Challenge To help motivate the research community to address these challenges, we are hosting the Google Universal Image Embedding Challenge. The challenge was launched on Kaggle in July and will be open until October, with cash prizes totaling $50k. The winning teams will be invited to present their methods at the Instance-Level Recognition workshop at ECCV 2022.
Participants will be evaluated on a retrieval task on a dataset of ~5,000 test query images and ~200,000 index images, from which similar images are retrieved. In contrast to ImageNet, which includes categorical labels, the images in this dataset are labeled at the instance level.
The evaluation data for the challenge is composed of images from the following domains: apparel and accessories, packaged goods, furniture and home goods, toys, cars, landmarks, storefronts, dishes, artwork, memes and illustrations.
Acknowledgement The core contributors to this project are Andre Araujo, Boris Bluntschli, Bingyi Cao, Kaifeng Chen, Mário Lipovský, Grzegorz Makosa, Mojtaba Seyedhosseini and Pelin Dogan Schönberger. We would like to thank Sohier Dane, Will Cukierski and Maggie Demkin for their help organizing the Kaggle challenge, as well as our ECCV workshop co-organizers Tobias Weyand, Bohyung Han, Shih-Fu Chang, Ondrej Chum, Torsten Sattler, Giorgos Tolias, Xu Zhang, Noa Garcia, Guangxing Han, Pradeep Natarajan and Sanqiang Zhao. Furthermore we are thankful to Igor Bonaci, Tom Duerig, Vittorio Ferrari, Victor Gomes, Futang Peng and Howard Zhou who gave us feedback, ideas and support at various points of this project.
Pinterest has engineered a way to serve its photo-sharing community more of the images they love. The social-image service, with more than 400 million monthly active users, has trained bigger recommender models for improved accuracy at predicting people’s interests. Pinterest handles hundreds of millions of user requests an hour on any given day. And it Read article >
Imagine hiking to a lake on a summer day — sitting under a shady tree and watching the water gleam under the sun. In this scene, the differences between light and shadow are examples of direct and indirect lighting. The sun shines onto the lake and the trees, making the water look like it’s shimmering Read article >
It’s the first GFN Thursday of the month and you know the drill — GeForce NOW is bringing a big batch of games to the cloud. Get ready for 38 exciting titles like Saints Row and Rumbleverse arriving on the GeForce NOW library in August. Members can kick off the month streaming 13 new games Read article >
Posted by Qifei Wang, Senior Software Engineer, and Feng Yang, Senior Staff Software Engineer, Google Research
Deep learning models for visual tasks (e.g., image classification) are usually trained end-to-end with data from a single visual domain (e.g., natural images or computer generated images). Typically, an application that completes visual tasks for multiple domains would need to build multiple models for each individual domain, train them independently (meaning no data is shared between domains), and then at inference time each model would process domain-specific input data. However, early layers between these models generate similar features, even for different domains, so it can be more efficient — decreasing latency and power consumption, lower memory overhead to store parameters of each model — to jointly train multiple domains, an approach referred to as multi-domain learning (MDL). Moreover, an MDL model can also outperform single domain models due to positive knowledge transfer, which is when additional training on one domain actually improves performance for another. The opposite, negative knowledge transfer, can also occur, depending on the approach and specific combination of domains involved. While previous work on MDL has proven the effectiveness of jointly learning tasks across multiple domains, it involved a hand-crafted model architecture that is inefficient to apply to other work.
In “Multi-path Neural Networks for On-device Multi-domain Visual Classification”, we propose a general MDL model that can: 1) achieve high accuracy efficiently (keeping the number of parameters and FLOPS low), 2) learn to enhance positive knowledge transfer while mitigating negative transfer, and 3) effectively optimize the joint model while handling various domain-specific difficulties. As such, we propose a multi-path neural architecture search (MPNAS) approach to build a unified model with heterogeneous network architecture for multiple domains. MPNAS extends the efficient neural architecture search (NAS) approach from single path search to multi-path search by finding an optimal path for each domain jointly. Also, we introduce a new loss function, called adaptive balanced domain prioritization (ABDP) that adapts to domain-specific difficulties to help train the model efficiently. The resulting MPNAS approach is efficient and scalable; the resulting model maintains performance while reducing the model size and FLOPS by 78% and 32%, respectively, compared to a single-domain approach.
Multi-Path Neural Architecture Search To encourage positive knowledge transfer and avoid negative transfer, traditional solutions build an MDL model so that domains share most of the layers that learn the shared features across domains (called feature extraction), then have a few domain-specific layers on top. However, such a homogenous approach to feature extraction cannot handle domains with significantly different features (e.g., objects in natural images and art paintings). On the other hand, handcrafting a unified heterogeneous architecture for each MDL model is time-consuming and requires domain-specific knowledge.
NAS is a powerful paradigm for automatically designing deep learning architectures. It defines a search space, made up of various potential building blocks that could be part of the final model. The search algorithm finds the best candidate architecture from the search space that optimizes the model objectives, e.g., classification accuracy. Recent NAS approaches (e.g., TuNAS) have meaningfully improved search efficiency by using end-to-end path sampling, which enables us to scale NAS from single domains to MDL.
Inspired by TuNAS, MPNAS builds the MDL model architecture in two stages: search and training. In the search stage, to find an optimal path for each domain jointly, MPNAS creates an individual reinforcement learning (RL) controller for each domain, which samples an end-to-end path (from input layer to output layer) from the supernetwork (i.e., the superset of all the possible subnetworks between the candidate nodes defined by the search space). Over multiple iterations, all the RL controllers update the path to optimize the RL rewards across all domains. At the end of the search stage, we obtain a subnetwork for each domain. Finally, all the subnetworks are combined to build a heterogeneous architecture for the MDL model, shown below.
Since the subnetwork for each domain is searched independently, the building block in each layer can be shared by multiple domains (i.e., dark gray nodes), used by a single domain (i.e., light gray nodes), or not used by any subnetwork (i.e., dotted nodes). The path for each domain can also skip any layer during search. Given the subnetwork can freely select which blocks to use along the path in a way that optimizes performance (rather than, e.g., arbitrarily designating which layers are homogenous and which are domain-specific), the output network is both heterogeneous and efficient.
Example architecture searched by MPNAS. Dashed paths represent all the possible subnetworks. Solid paths represent the selected subnetworks for each domain (highlighted in different colors). Nodes in each layer represent the candidate building blocks defined by the search space.
The figure below demonstrates the searched architecture of two visual domains among the ten domains of the Visual Domain Decathlon challenge. One can see that the subnetwork of these two highly related domains (one red, the other green) share a majority of building blocks from their overlapping paths, but there are still some differences.
Architecture blocks of two domains (ImageNet and Describable Textures) among the ten domains of the Visual Domain Decathlon challenge. Red and green path represents the subnetwork of ImageNet and Describable Textures, respectively. Dark pink nodes represent the blocks shared by multiple domains. Light pink nodes represent the blocks used by each path. The model is built based on MobileNet V3-like search space. The “dwb” block in the figure represents the dwbottleneck block. The “zero” block in the figure indicates the subnetwork skips that block.
Below we show the path similarity between domains among the ten domains of the Visual Domain Decathlon challenge. The similarity is measured by the Jaccard similarity score between the subnetworks of each domain, where higher means the paths are more similar. As one might expect, domains that are more similar share more nodes in the paths generated by MPNAS, which is also a signal of strong positive knowledge transfer. For example, the paths for similar domains (like ImageNet, CIFAR-100, and VGG Flower, which all include objects in natural images) have high scores, while the paths for dissimilar domains (like Daimler Pedestrian Classification and UCF101 Dynamic Images, which include pedestrians in grayscale images and human activity in natural color images, respectively) have low scores.
Confusion matrix for the Jaccard similarity score between the paths for the ten domains. Score value ranges from 0 to 1. A greater value indicates two paths share more nodes.
Training a Heterogeneous Multi-domain Model In the second stage, the model resulting from MPNAS is trained from scratch for all domains. For this to work, it is necessary to define a unified objective function for all the domains. To successfully handle a large variety of domains, we designed an algorithm that adapts throughout the learning process such that losses are balanced across domains, called adaptive balanced domain prioritization (ABDP).
Below we show the accuracy, model size, and FLOPS of the model trained in different settings. We compare MPNAS to three other approaches:
Domain independent NAS: Searching and training a model for each domain separately.
Single path multi-head: Using a pre-trained model as a shared backbone for all domains with separated classification heads for each domain.
Multi-head NAS: Searching a unified backbone architecture for all domains with separated classification heads for each domain.
From the results, we can observe that domain independent NAS requires building a bundle of models for each domain, resulting in a large model size. Although single path multi-head and multi-head NAS can reduce the model size and FLOPS significantly, forcing the domains to share the same backbone introduces negative knowledge transfer, decreasing overall accuracy.
Model
Number of parameters ratio
GFLOPS
Average Top-1 accuracy
Domain independent NAS
5.7x
1.08
69.9
Single path multi-head
1.0x
0.09
35.2
Multi-head NAS
0.7x
0.04
45.2
MPNAS
1.3x
0.73
71.8
Number of parameters, gigaFLOPS, and Top-1 accuracy (%) of MDL models on the Visual Decathlon dataset. All methods are built based on the MobileNetV3-like search space.
MPNAS can build a small and efficient model while still maintaining high overall accuracy. The average accuracy of MPNAS is even 1.9% higher than the domain independent NAS approach since the model enables positive knowledge transfer. The figure below compares per domain top-1 accuracy of these approaches.
Top-1 accuracy of each Visual Decathlon domain.
Our evaluation shows that top-1 accuracy is improved from 69.96% to 71.78% (delta: +1.81%) by using ABDP as part of the search and training stages.
Top-1 accuracy for each Visual Decathlon domain trained by MPNAS with and without ABDP.
Future Work We find MPNAS is an efficient solution to build a heterogeneous network to address the data imbalance, domain diversity, negative transfer, domain scalability, and large search space of possible parameter sharing strategies in MDL. By using a MobileNet-like search space, the resulting model is also mobile friendly. We are continuing to extend MPNAS for multi-task learning for tasks that are not compatible with existing search algorithms and hope others might use MPNAS to build a unified multi-domain model.
Acknowledgements This work is made possible through a collaboration spanning several teams across Google. We’d like to acknowledge contributions from Junjie Ke, Joshua Greaves, Grace Chu, Ramin Mehran, Gabriel Bender, Xuhui Jia, Brendan Jou, Yukun Zhu, Luciano Sbaiz, Alec Go, Andrew Howard, Jeff Gilbert, Peyman Milanfar, and Ming-Tsuan Yang.
Starting today, the NVIDIA Jetson AGX Orin 32GB production module is available for purchase. Combined with the world-standard NVIDIA AI software stack and an…
Starting today, the NVIDIA Jetson AGX Orin 32GB production module is available for purchase. Combined with the world-standard NVIDIA AI software stack and an ecosystem of services and products, the road to market has never been faster.
The NVIDIA Jetson AGX Orin 32GB module delivers up to 200 trillion operations per second (TOPS) of AI performance with power configurable between 15W and 40W, which is more than 6x the performance of Jetson AGX Xavier in the same compact form-factor for robotics and other autonomous machine use cases.
This latest system-on-module supports multiple concurrent AI application pipelines with an NVIDIA Ampere architecture GPU, next-generation deep learning and vision accelerators, high-speed IO, and fast memory bandwidth. Developers can build solutions using their largest and most complex AI models to solve problems such as natural language understanding, 3D perception, and multi-sensor fusion.
Jetson runs the NVIDIA AI software stack, and use-case specific application frameworks are available, including NVIDIA Isaac for robotics, DeepStream for vision AI, and Riva for conversational AI.
You can also save time using the NVIDIA Omniverse Replicator for synthetic data generation (SDG), and with NVIDIA TAO Toolkit for fine-tuning pretrained AI models from the NGC catalog.
A broad range of Jetson ecosystem partners offer additional AI and system software, developer tools, and custom software development. They can also help with cameras and other sensors, as well as full system carrier boards and design services for your product.
Learn more about all the partners solutions supporting Orin that were announced today.
The Jetson AGX Orin Developer Kit is also available now. Use it to accelerate your Orin development, emulate the entire family of Jetson Orin modules, and create advanced robotics and edge AI applications.
Look for additional Jetson Orin modules later this year, including Jetson Orin NX 16GB in October, Jetson AGX Orin 64GB in November, and Jetson Orin NX 8GB in December. Sign up to be notified when new Jetson Orin modules become available.
This is the first part of a two-part series discussing the NVIDIA FasterTransformer library, one of the fastest libraries for distributed inference of…
This is the first part of a two-part series discussing the NVIDIA FasterTransformer library, one of the fastest libraries for distributed inference of transformers of any size (up to trillions of parameters). It provides an overview of FasterTransformer, including the benefits of using the library.
Transformers are among the most influential AI model architectures today and are shaping the direction for future R&D in AI. Invented first as a tool for natural language processing (NLP), they are now used for almost any AI task, including computer vision, automatic speech recognition, classification of molecule structures, and processing of financial data. Accounting for such widespread use is the attention mechanism, which noticeably increases the computational efficiency, quality, and accuracy of the models.
Large transformer-based models with hundreds of billions of parameters behave like a gigantic encyclopedia and brain that contains information about everything it has learned. They structurize, represent, and summarize all this knowledge in a unique way. Having such models with this vast amount of prior knowledge allows us to use new and powerful one-shot or few-shot learning techniques to solve many NLP tasks.
Thanks to their computational efficiency, transformers scale well–and by increasing the size of the network and the amount of training data, researchers can improve observations and increase accuracy.
Training such large models is a non-trivial task, however. The models may require more memory than one GPU supplies–or even hundreds of GPUs. Thankfully, NVIDIA researchers have created powerful open-source tools, such as NeMo Megatron, that optimize the training process.
Fast and optimized inference allows enterprises to realize the full potential of these large models. The latest research demonstrates that increasing the size of the model as well as the dataset increases the quality of such a model on downstream tasks in different domains (NLP, CV, and others).
At the same time, data show that such a technique also works in multi-domain tasks. (See research papers like OpenAI’s DALLE-2 and Google’s Imagen on text-to-image generation, for example.) Research directions such as p-tuning that rely on “frozen” copies of huge models even increase the importance of having a stable and optimized inference pipeline. Optimized inference of such large models requires distributed multi-GPU multi-node solutions.
A library for accelerated inference of large transformers
NVIDIA FasterTransformer (FT) is a library implementing an accelerated engine for the inference of transformer-based neural networks, with a special emphasis on large models, spanning many GPUs and nodes in a distributed manner.
FasterTransformer contains the implementation of the highly-optimized version of the transformer block that contains the encoder and decoder parts.
Using this block, you can run the inference of both the full encoder-decoder architectures like T5, as well as encoder-only models, such as BERT, or decoder-only models, such as GPT. It is written in C++/CUDA and relies on the highly optimized cuBLAS, cuBLASLt , and cuSPARSELt libraries. This allows you to build the fastest transformer inference pipeline on GPU.
Figure 1. A couple of transformer/attention blocks are distributed between four GPUs using tensor parallelism (tensor MP partitions) and pipeline parallelism (pipeline MP partitions)
The distinctive feature of FT in comparison with other compilers like NVIDIA TensorRT is that it supports the inference of large transformer models in a distributed manner.
Figure 1 shows how a neural network with multiple classical transformer/attention layers could be split onto multiple GPUs and nodes using tensor parallelism (TP) and pipeline parallelism (PP) techniques.
Tensor parallelism occurs when each tensor is split up into multiple chunks, and each chunk of the tensor can be placed on a separate GPU. During computation, each chunk gets processed separately in-parallel on different GPUs and the results (final tensor) can be computed by combining results from multiple GPUs.
Pipeline parallelism occurs when a model is split up in-depth and different fulllayers are placed onto different GPUs/nodes.
Under the hood, enabling inter/intra-node communication relies on MPI and NVIDIA NCCL. Using this software stack, you can run large transformers in tensor parallelism mode on multiple GPUs to reduce computational latency.
At the same time, TP and PP may be combined together to run large transformer models with billions and trillions of parameters (which amount to terabytes of weights) on multi-GPU and multi-node environments.
Aside from the source codes in C, FasterTransformer also provides TensorFlow integration (using the TensorFlow op), PyTorch integration (using the PyTorch op), and Triton integration as a backend.
Currently, TensorFlow op only supports a single GPU, while PyTorch op and Triton backend both support multi-GPU and multi-node.
To prevent the additional work of splitting the model for model parallelism, FasterTransformer also provides a tool to split and convert models from different formats to the FasterTransformer binary file format. Then FasterTransformer can load the model in a binary format directly.
At this time, FT supports models like Megatron-LM GPT-3, GPT-J, BERT, ViT, Swin Transformer, Longformer, T5, and XLNet. You can check the latest support matrix in the FasterTransformer repo on GitHub.
FT works on GPUs with compute capability >= 7.0, such as V100, A10, A100, and others.
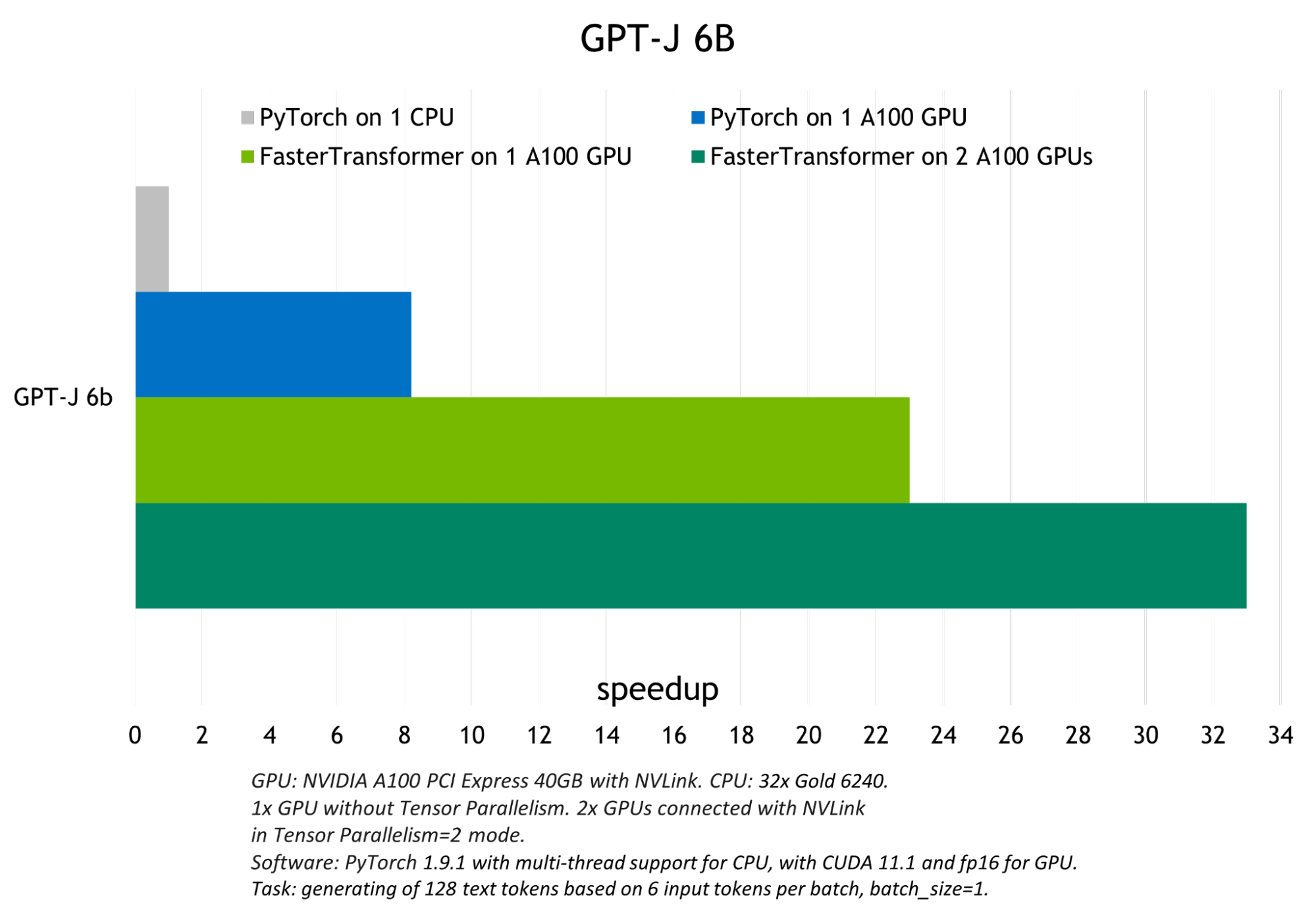
Figure 2. GPT-J 6B model inference speed-up comparison
Optimizations in FasterTransformer
FT enables you to get a faster inference pipeline, with lower latency and higher throughput for the transformer-based NNs in comparison to the common frameworks for deep learning training.
Some of the optimization techniques that allow FT to have the fastest inference for the GPT-3 and other large transformer models include:
Layer fusion – The set of techniques in the pre-processing stage that combine multiple layers of NNs into a single one that would be computed with one single kernel. This technique reduces data transfer and increases math density, thus accelerating computation at the inference stage. For example, all the operations in the multi-head attention block can be combined into one kernel.
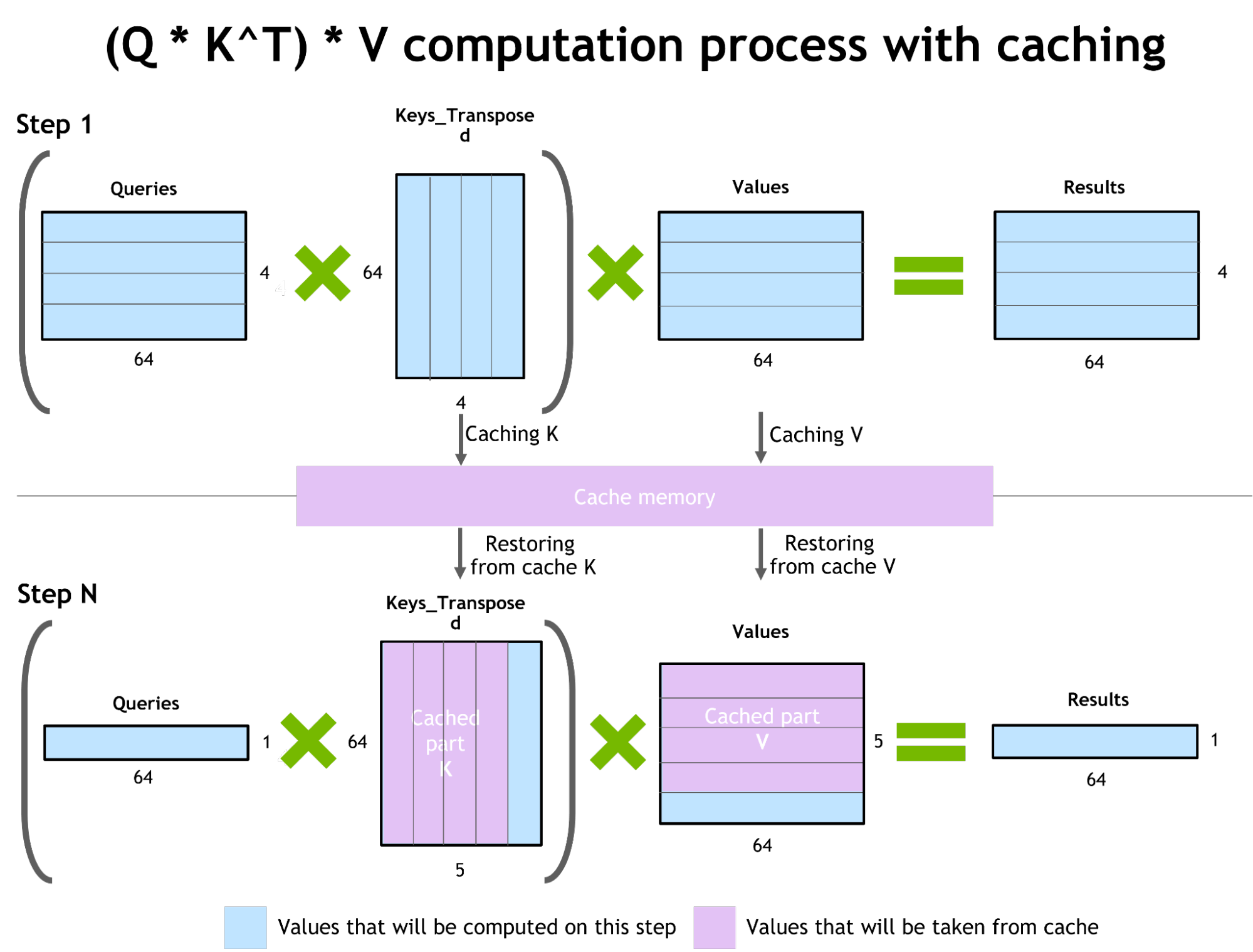
Figure 3. Demonstration of the caching mechanism in the NVIDIA FasterTransformer library
Inference optimization for autoregressive models / activations caching
To prevent recomputing the previous keys and values for each new token generator by transformer, FT allocates a buffer to store them at each step.
Although it takes some additional memory usage, FT can save the cost of recomputing, allocating a buffer at each step, and the cost of concatenation. The scheme of the process is presented in Figure 2. The same caching mechanism is used in multiple parts of the NN.
Memory optimization
Different from traditional models like BERT, large transformer models have up to trillions of parameters taking hundreds of GB of storage. GPT-3 175b takes 350 GB even if we store the model in half-precision. It’s therefore necessary to reduce memory usage for other parts.
For example, in FasterTransformer, we reuse the memory buffer of activations/outputs in different decoder layers. Since the number of layers in GPT-3 is 96, we only need 1/96 of the amount of memoryfor activations.
Usage of MPI and NCCL to enable inter/intra-node communication and support model parallelism
In the GPT model, FasterTransormer provides both tensor parallelism and pipeline parallelism. For tensor parallelism, FasterTransformer follows the idea of Megatron. For both the self-attention block and feed-forward network block, FT split the weights of the first matrix by row and split the weights of the second matrix by column. By optimization, FT can reduce the reduction operation to two times for each transformer block.
For pipeline parallelism, FasterTransformer splits the whole batch of requests into multiple micro-batches, hiding the bubble of communication. FasterTransformer will adjust the micro-batch size automatically for different cases.
MatMul kernel autotuning (GEMM autotuning)
Matrix multiplication is the main and the heaviest operation in transformer-based neural networks. FT uses functionalities from CuBLAS and CuTLASS libraries to execute these types of operations. It is important to know that MatMul operation can be executed in tens of different ways using different low-level algorithms at the “hardware” level.
GemmBatchedEx function implements MatMul operation and has “cublasGemmAlgo_t” as an input parameter. Using this parameter, you can choose different low-level algorithms for operation.
The FasterTransformer library uses this parameter to do a real-time benchmark of all low-level algorithms and to choose the best one for the parameters of the model (size of the attention layers, number of attention heads, size of the hidden layer) and for your input data. Additionally, FT uses hardware-accelerated low-level functions for some parts of the network such as __expf, __shfl_xor_sync.
Inference with lower precisions
FT has kernels that support inference using low-precision input data in fp16 and int8. Both these regimes allow acceleration due to a lower amount of data transfer and required memory. At the same time, int8 and fp16 computations can be executed on special hardware, such as the tensor cores (for all GPU architectures starting from Volta), and the transformers engine in the upcoming Hopper GPUs.
More
Rapidly fast C++ BeamSearch implementation
Optimized all-reduce for the TensorParallelism 8 mode When the weights parts of the model are split between eight GPUs
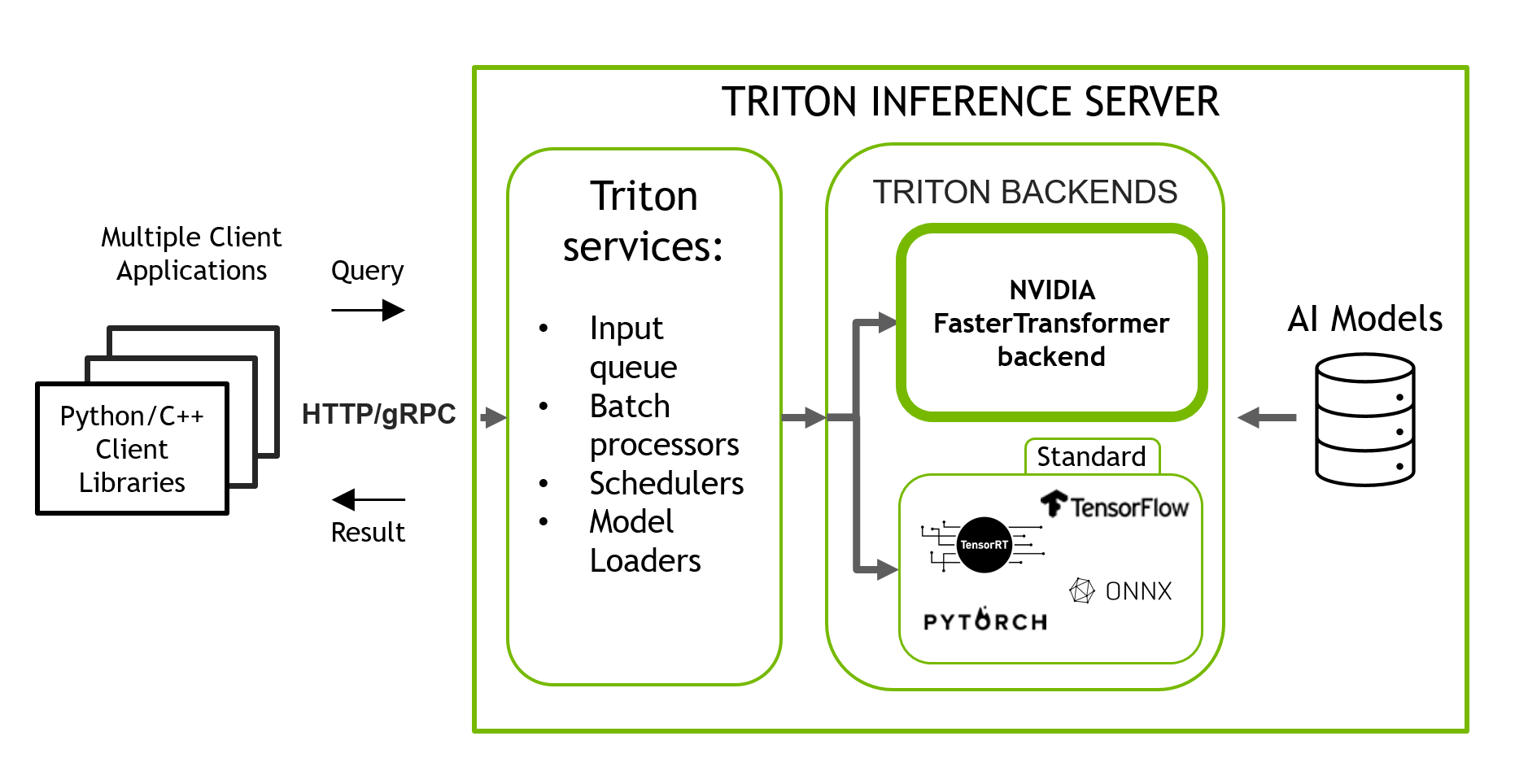
NVIDIA Triton inference server with FasterTransformer backend
NVIDIA Triton Inference Server is an open-source inference serving software that helps standardize model deployment and execution, delivering fast and scalable AI in production. Stable and fast, Triton allows you to run inference of your ML/DL models in a simple manner with a pre-baked Docker container using only one line of code and a simple JSON-like config.
Triton supports models using multiple backends such as PyTorch, TorchScript, Tensorflow, ONNXRuntime, and OpenVINO. Triton takes your exported model that was trained in one of the frameworks and runs this model in inference using the corresponding backend transparently for you. It can also be extended with custom backends. Triton wraps your model with HTTP/gRPC API and provides client-side libraries for multiple languages.
Figure 4. Triton inference server with multiple backends for inference of model trained with different frameworks
Triton includes the FasterTransformer library as a backend (Figure 4) that enables running distributed multi-GPU, multi-node inference of large transformer models with TP and PP. Today, GPT-J, GPT-Megatron, and T5 models are supported in Triton with FasterTransformer backend.

 The Acceleration Agency, a digital innovation and product design firm, is working on an active digital twin framework and toolkit called Project Gemini….
The Acceleration Agency, a digital innovation and product design firm, is working on an active digital twin framework and toolkit called Project Gemini….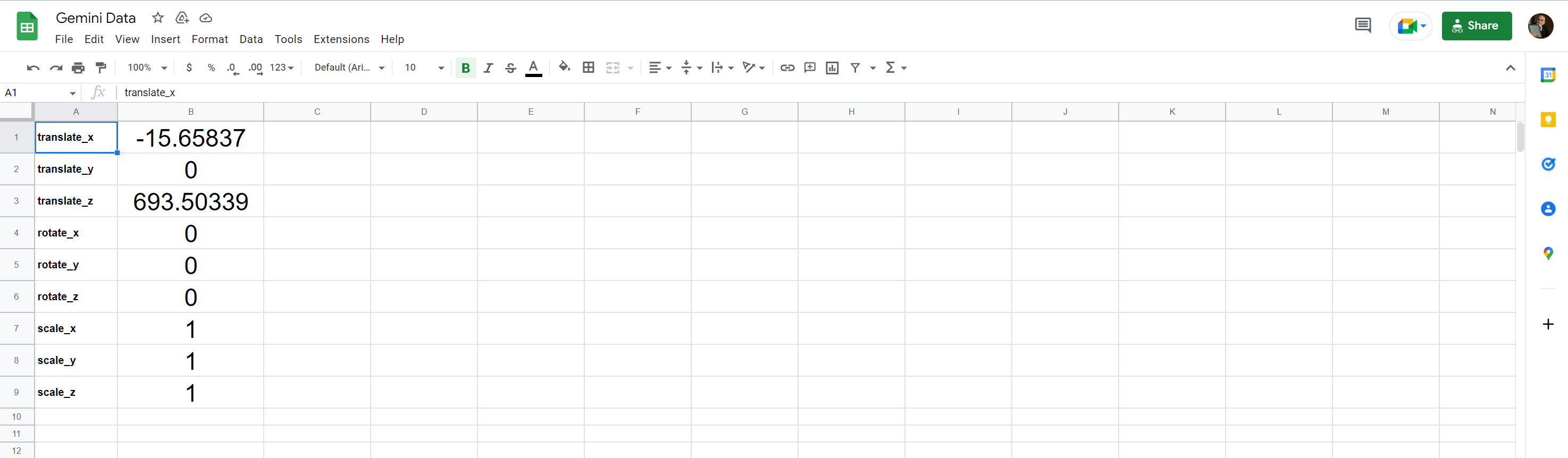

 Join us September 19-22 for a deep dive into the latest advances in edge AI, from reimagined shopping experiences to industrial automation.
Join us September 19-22 for a deep dive into the latest advances in edge AI, from reimagined shopping experiences to industrial automation.
.jpg)
.jpg)






 Starting today, the NVIDIA Jetson AGX Orin 32GB production module is available for purchase. Combined with the world-standard NVIDIA AI software stack and an…
Starting today, the NVIDIA Jetson AGX Orin 32GB production module is available for purchase. Combined with the world-standard NVIDIA AI software stack and an… This is the first part of a two-part series discussing the NVIDIA FasterTransformer library, one of the fastest libraries for distributed inference of…
This is the first part of a two-part series discussing the NVIDIA FasterTransformer library, one of the fastest libraries for distributed inference of…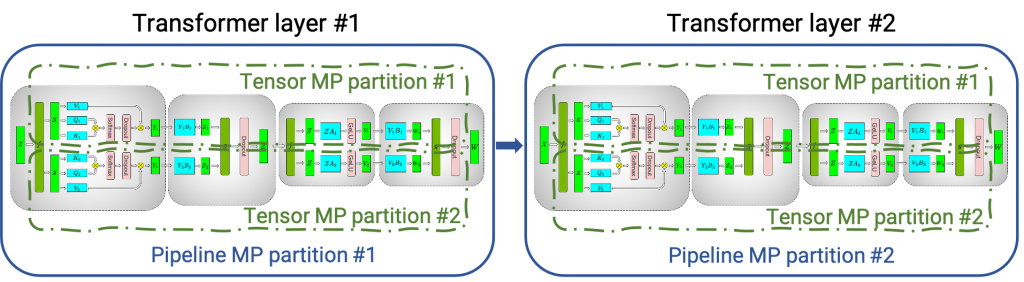
{kind=link}
{kind=link}