

|
submitted by /u/joanna58 [visit reddit] [comments] |
 DataBloom
DataBloom
|
|
submitted by /u/joanna58 [visit reddit] [comments] |
I am currently stuck in a dead end. I am trying to make an image caption generator from a federated approach. My initial idea was to have a different tokenizer for each client. That poses these issues however:
Every client will have a different sized vocabulary, and thus a different shape of y, which will cause issues with the global model configuration.
To counter the above issue, I could make size of y in each client equivalent to the largest size across all clients, and fill the extra columns in each client with 0.
E.g: [0,1,1,1] mapped to a size of 6 would become [0,1,1,1,0,0]
This brings me to the last possible flaw, which is that the same words in different clients will be having different indices. A word “rock” in client 1 might have an index of 6, while the same can have an index of 9 in another client. While training the global model, it will cause issues since the model is trying to learn different label indices for the same word, which will impact the accuracy?
This brings me to the final question: Is it against the idea of Federated Learning to tokenize all the words of all the training clients in a single tokenizer?
submitted by /u/ChaosAdm
[visit reddit] [comments]
 This walkthrough shares how a user can quickly build and deploy a computer vision application with the NVIDIA NGC catalog and Google Vertex AI.
This walkthrough shares how a user can quickly build and deploy a computer vision application with the NVIDIA NGC catalog and Google Vertex AI.
Advances in computer vision models are providing deeper insights to make our lives increasingly productive, our communities safer, and our planet cleaner.
We’ve come a long way from object detection that tells us whether a patient is walking or sitting on the floor but can’t alert us if the patient collapsed, for example. New computer vision models are overcoming these types of challenges by processing temporal information and predicting actions.
Building these models from scratch requires AI expertise, large amounts of training data, and loads of compute power. Fortunately, transfer learning enables you to build custom models with a fraction of these resources.
In this post, we walk through each step to build and deploy a computer vision application with NVIDIA AI software from the NGC catalog and run it on Google Cloud Vertex AI Workbench.
The NGC catalog provides GPU-optimized AI frameworks, training and inference SDKs, and pretrained models that can be easily deployed through ready-to-use Jupyter notebooks.
Google Cloud Vertex AI Workbench is a single development environment for the entire AI workflow. It accelerates data engineering by deeply integrating with all of the services necessary to rapidly build and deploy models in production.
NVIDIA and Google Cloud have partnered to enable easy deployment of the software and models from the NGC catalog to Vertex AI Workbench. It’s made easy through ready-to-use Jupyter notebooks with a single click, instead of a dozen complex steps.
This quick deploy feature launches the JupyterLab instance on Vertex AI with an optimal configuration, preloads the software dependencies, and downloads the NGC notebook in one go. This enables you to start executing the code right away without needing any expertise to configure the development environment.
A Google Cloud account with free credits is plenty to build and run this application.
You can also join us on June 22 during our live webinar where we will walk you step-by-step through how to build your computer vision application that recognizes human action, using software from the NGC catalog and Vertex AI Workbench.
To follow along, you need the following resources:
When you sign into the NGC catalog, you’ll see the curated content.
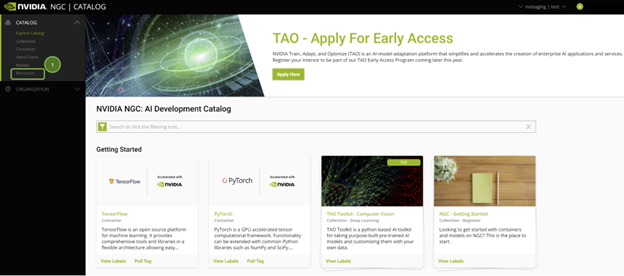
All Jupyter notebooks on NGC are hosted under Resources on the left pane. Find the TAO Action Recognition notebook.
There are a couple of ways to get started using the sample Jupyter notebooks from this resource:
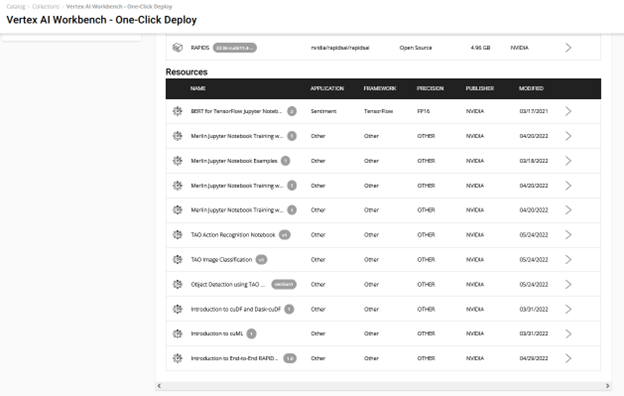
Take the easy route with quick deploy. It takes care of the end-to-end setup requirements like fetching the Jupyter notebook, configuring the GPU instance, installing dependencies, and running a JupyterLab interface to quickly get started with the development! Try it out by choosing Deploy on Vertex AI.
You see a window with detailed information about the resource and AI platform. The Deploy option leads to the Google Cloud Vertex AI platform Workbench.
The following information is preconfigured but can be customized, depending on the requirements of the resource:
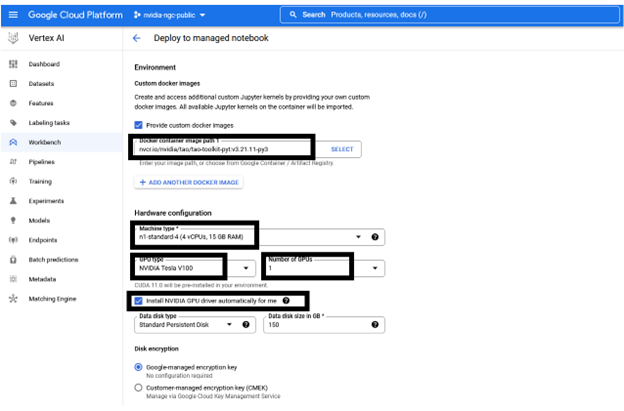
You can keep the recommended configuration as-is or change as required before choosing Create. Creating the GPU compute instance and setting up the JupyterLab environment takes about a couple of minutes.
To start up the interface, choose Open, Open JupyterLab. The instance loads up with the resources (Jupyter notebooks) pulled and the environment set up as a kernel in the JupyterLab.
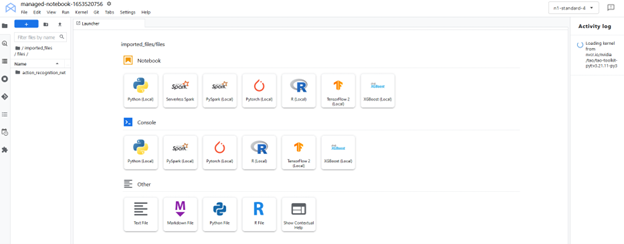
The JupyterLab interface pulls the resources (custom container and Jupyter notebooks) from NGC. Select the custom kernel tao-toolkit-pyt in the JupyterLab interface.
This action recognition Jupyter notebook showcases how to fine-tune an action recognition model that identifies five human actions. You use it for two actions in this dataset: fall-floor and ride-bike.
The notebook makes use of the HMDB51 dataset to fine-tune a pretrained model loaded from the NGC catalog. The notebook also showcases how to run inference on the trained model and deploy it into the real-time video analytics framework NVIDIA DeepStream.
Set the HOST_DATA_DIR, HOST_SPECS_DIR, HOST_RESULTS_DIR and env-key variables, then execute the cell. The data, specs, results folder, and Jupyter notebook are inside the action-recognition-net folder.
%env HOST_DATA_DIR=/absolute/path/to/your/host/data # note: You could set the HOST_SPECS_DIR to folder of the experiments specs downloaded with the notebook %env HOST_SPECS_DIR=/absolute/path/to/your/host/specs %env HOST_RESULTS_DIR=/absolute/path/to/your/host/results # Set your encryption key, and use the same key for all commands %env KEY = nvidia_tao
Run the subsequent cells to download the HMDB51 dataset and unzip it into $HOST_DATA_DIR. The preprocessing scripts clip the video and generate optical flow out of it, which gets stored in the $HOST_DATA_DIR/processed_data directory.
!wget -P $HOST_DATA_DIR "https://github.com/shokoufeh-monjezi/TAOData/releases/download/v1.0/hmdb51_org.zip" !mkdir -p $HOST_DATA_DIR/videos && unzip $HOST_DATA_DIR/hmdb51_org.zip -d $HOST_DATA_DIR/videos !mkdir -p $HOST_DATA_DIR/raw_data !unzip $HOST_DATA_DIR/videos/hmdb51_org/fall_floor.zip -d $HOST_DATA_DIR/raw_data !unzip $HOST_DATA_DIR/videos/hmdb51_org/ride_bike.zip -d $HOST_DATA_DIR/raw_data
Finally, split the dataset into train and test and verify the contents by running the following code cell example, as given in the Jupyter notebook:
# download the split files and unrar !wget -P $HOST_DATA_DIR https://github.com/shokoufeh-monjezi/TAOData/releases/download/v1.0/test_train_splits.zip !mkdir -p $HOST_DATA_DIR/splits && unzip $HOST_DATA_DIR/test_train_splits.zip -d $HOST_DATA_DIR/splits # run split_HMDB to generate training split !cd tao_toolkit_recipes/tao_action_recognition/data_generation/ && python3 ./split_dataset.py $HOST_DATA_DIR/processed_data $HOST_DATA_DIR/splits/test_train_splits/testTrainMulti_7030_splits $HOST_DATA_DIR/train $HOST_DATA_DIR/test
Verify the final test and train datasets:
!ls -l $HOST_DATA_DIR/train !ls -l $HOST_DATA_DIR/train/ride_bike !ls -l $HOST_DATA_DIR/test !ls -l $HOST_DATA_DIR/test/ride_bike

You use the NGC CLI to get the pre-trained models. For more information, go to NGC and on the navigation bar, choose SETUP.
!ngc registry model download-version "nvidia/tao/actionrecognitionnet:trainable_v1.0" --dest $HOST_RESULTS_DIR/pretrained
Check the downloaded models. You should see resnet18_3d_rgb_hmdb5_32.tlt and resnet18_2d_rgb_hmdb5_32.tlt.
print("Check that model is downloaded into dir.")
!ls -l $HOST_RESULTS_DIR/pretrained/actionrecognitionnet_vtrainable_v1.0
In the specs folder, you can find different specs files related to train, evaluate, infer, and export functions. Choose the train_rgb_3d_finetune.yaml file and you can change hyperparameters, such as the number of epochs, in this specs file.
Make sure that you edit the path in the specs file based on the path to the data and results folders in your system.
We provide a pretrained RGB-only model trained on HMDB5 dataset. With the pretrained model, you can even get better accuracy with fewer epochs.
print("Train RGB only model with PTM")
!action_recognition train
-e $HOST_SPECS_DIR/train_rgb_3d_finetune.yaml
-r $HOST_RESULTS_DIR/rgb_3d_ptm
-k $KEY
model_config.rgb_pretrained_model_path=$HOST_RESULTS_DIR/pretrained/actionrecognitionnet_vtrainable_v1.0/resnet18_3d_rgb_hmdb5_32.tlt
model_config.rgb_pretrained_num_classes=5
We provide two different sample strategies to evaluate the pretrained model on video clips.
Next, evaluate the RGB model trained with PTM:
!action_recognition evaluate
-e $HOST_SPECS_DIR/evaluate_rgb.yaml
-k $KEY
model=$HOST_RESULTS_DIR/rgb_3d_ptm/rgb_only_model.tlt
batch_size=1
test_dataset_dir=$HOST_DATA_DIR/test
video_eval_mode=center
video_eval_mode=center
Inferences
In this section, you run the action recognition inference tool to generate inferences with the trained RGB models and print the results.
There are also two modes for inference just like evaluation: center mode and conv mode. The final output shows each input sequence label in the videos: [video_sample_path] [labels list for sequences in the video sample]
!action_recognition inference
-e $HOST_SPECS_DIR/infer_rgb.yaml
-k $KEY
model=$HOST_RESULTS_DIR/rgb_3d_ptm/rgb_only_model.tlt
inference_dataset_dir=$HOST_DATA_DIR/test/ride_bike
video_inf_mode=center
You can see an example of the results of the inference function on this dataset.

NVIDIA TAO and the pretrained models help you accelerate your custom model development by eliminating the need for building models from scratch.
With the NGC catalog’s quick deploy feature, you can get access to an environment to build and run your computer vision application in a matter of minutes. This enables you to focus on development and avoid spending time on infrastructure setup.
 In part 2 of this series, we focus on solutions that optimize and modernize data center network operations.
In part 2 of this series, we focus on solutions that optimize and modernize data center network operations.
In part 2 of this series, we focus on solutions that optimize and modernize data center network operations. In the first installment, Optimizing Your Data Center Network, we looked at updating your networking infrastructure and protocols.
NetDevOps is an ideology that has been permeating through the IT infrastructure diaspora for the past 5 years. As a theory, it can provide many areas to optimize infrastructure operations.
We will discuss some applications of NetDevOps that can be applied to your operational workflows.
These include:
The principles behind IaC have been used in software development for developers to contribute code to the same software project in parallel. But they also create a centralized repository where the code project—including networking configurations for servers, NICs, routers, and switches—can reside and act as a singular source of truth.
The decentralized aspect of configuration management makes it fundamentally inefficient to enforce standardization. It also makes it difficult to determine the correct configuration or track changes.
Using IaC with source control management software like Git can help resolve issues, ensuring the correct network configurations and code are available to all admins, servers, and switches.
In large-scale infrastructures, components of the configuration will be the same regardless of the device. Configurations like syslog server, NTP server, SNMP settings, and other management settings can be automated with technology such as Zero Touch Provisioning (ZTP). ZTP can apply configurations to a switch-on boot to reduce the errors that may happen with manual configurations across many devices. Applying standard configurations and executing repetitive tasks are perfect for ZTP as it can be enforced consistently across every device.
Automation normally relies on an external tool to drive configurations after the device has fully booted. Automation is more dynamic and can be applied multiple times in a device’s operational cycle, whereas ZTP is used only during the first boot of each device.
Automation tools such as Ansible and Salt apply configurations at scale using templating technologies and scripting. These tools simplify infrastructure management by building standardized templates and relying only on key/value pair data structures to populate the templates. This way, an operator can be confident of the configurations and focus on validating that the correct configurations are going to the right devices.
Additionally, automation tools can apply configurations at scale. Any fixes for misconfigurations or bugs can be confidently applied to thousands of nodes with minimal effort and no risk of node misconfiguration due to a mistyped command or distracted administrator.
When using automation to apply configurations at scale to multiple nodes, it is critical to understand the larger impact before committing changes. Applying changes to a few nodes as a test often doesn’t reveal what will happen when the changes are applied to every node. The NVIDIA Air infrastructure simulation platform creates a digital twin of the environment for users to test all changes before deploying them.
With a digital twin you can run automation in a safe sandbox, to ensure the changes will not cause any unforeseen outages. Coupling the digital twin with a validation technology, such as NVIDIA NetQ, can create an automated testing pipeline to ensure that all configuration changes do exactly what is expected from each change window.
This series covered ways to optimize your data center network. The first approach was through modernizing the network architecture protocol. The second post focused on delivering operational efficiency gains through NetDevOps.
Optimization is critical to maintaining a high level of service, peak efficiency, and productivity. By leveraging the topics discussed, you’ll be able to optimize your data center network to be a more resilient platform that improves the overall performance of your business and save you money.
I encourage you to find additional ways to streamline data center operations and further optimization by clicking on the additional resource links below.
 The high-performance CUDA library for tensor primitives now features updates to increase support, fix bugs, stop false-positive CUDA API errors, and more.
The high-performance CUDA library for tensor primitives now features updates to increase support, fix bugs, stop false-positive CUDA API errors, and more.
Let’s say I have a tensor t=[1, 3, 1] I want to self-cross it to produce a 3×3 matrix but each element of the matrix should be:
In this case the output should be
[0 -1 0
1 0 1
0 -1 0]
submitted by /u/Jolly_Bus349
[visit reddit] [comments]

https://www.tensorflow.org/tutorials/images/segmentation
This tutorial is exactly what I am looking for. Rather than multiple types of ‘animals’ I have two ‘species’ that I want segmented. The predicted mask as the outcome is what I want. I have my data right now, my input image and true masks, but I’m really confused about formatting my dataset similar to this one so I can use the same model for my project.
I am very new to TensorFlow, so any help would be appreciated.
Thank y’all so much!
submitted by /u/Emugio
[visit reddit] [comments]
 AI-based applications demand entirely new tools and procedures to deploy and manage at the edge. Learn about the distinctive challenges associated with edge AI application deployment.
AI-based applications demand entirely new tools and procedures to deploy and manage at the edge. Learn about the distinctive challenges associated with edge AI application deployment.
Sign up for Edge AI News to stay up to date with the latest trends, customers use cases, and technical walkthroughs.
Nearly all enterprises today develop or adopt application software that codifies the processing of information such as invoices, human resource profiles, or product specifications. An entire industry has risen to deploy and execute these enterprise applications both in centralized data centers or clouds, as well as in edge locations such as stores, factories, and home appliances.
Recently, the nature of enterprise software has changed as developers now incorporate AI into their applications. According to Gartner, by 2027, machine learning in the form of deep learning will be included in over 65% of edge use cases, up from less than 10% in 2021*. With AI, you don’t need to codify the output for every possible input. Rather, AI models learn patterns from training data and then apply those patterns to new inputs.
Naturally, the processes required to manage AI-based applications differ from the management that has evolved for purely deterministic, code-based applications. This is true particularly for AI-based applications at the edge, where computing resources and network bandwidth are scarce, and where easy access to the devices poses security risks.
AI-based applications benefit from new tools and procedures to securely deploy, manage, and scale at the edge.
There are four fundamental differences between the way that traditional enterprise software and AI applications at the edge are designed and managed:
Virtualization has been the primary deployment and management tool adopted by enterprises to deploy traditional applications in data centers around the world. For traditional applications and environments, virtualization provides structure, management, and security for these workloads to run on hypervisors.
While virtualization is still used in almost every data center, we are seeing widespread adoption of container technology for AI applications, especially at the edge. In a recent report on The State of Cloud Native Development, the Cloud Native Computing Foundation highlighted that “…developers working on edge computing have the highest usage for both containers and Kubernetes.” with 76% of edge AI applications using containers and 63% using Kubernetes.
Why are so many developers using containers for AI workloads at the edge?
Containers virtualize a host operating system’s kernel, whereas in traditional virtualization, a hypervisor virtualizes physical hardware and creates guest operating systems in every instance. This allows containers to run with full bare-metal performance compared to near bare-metal performance. This is critical for many edge AI applications, especially those with safety-related use cases where response times are measured in sub-milliseconds.
Containers can also run multiple applications on the same system, providing consolidation without virtualization’s performance overhead.
An edge AI “data center” may be distributed across hundreds of locations. Cloud-based management platforms give administrators the tools to centrally manage environments that can scale across hundreds and thousands of locations. Scaling by leveraging the network and intelligent software, as opposed to personnel traveling to every edge location, leads to reduced cost, higher efficiency, and resiliency.
AI applications usually provide resilience through scaling. Multiple clones of the same application run behind a load balancer, and service continues when a clone fails.
Even when an edge environment has a single node, container policies can ensure that the application automatically restarts for minimal downtime.
After an application is containerized, it can be deployed on any infrastructure whether on bare-metal, virtual machines, or various public clouds. They can also be scaled up or down as needed. With containers, applications can be run just as easily on a server at the edge as it can in any cloud.
Virtual machines and containers differ in several ways but are two methods of deploying multiple isolated services on a single platform. Many vendors supply solutions that work for both environments such as Red Hat OpenShift and VMware Tanzu.
Edge environments see both virtualization and containerization, but as more edge AI workloads are put into production, expect to see a move towards bare metal and containers.
The next difference is about the role of data in the lifecycle of traditional edge applications and edge AI applications.
Traditional edge applications commonly ingest small streams of structured data such as point-of-purchase sale transactions, patient medical records, or instructions. After being processed, the application sends back similar streams of structured information, such as payment authorizations, analytical results, or record searches. When it’s consumed, the data is no longer useful to the application.
Unlike traditional applications, AI applications have a lifecycle that spans beyond analysis and inference and includes re-training and ongoing updates. AI applications stream data from a sensor, often a camera, and make inferences on that data. A portion of the data is collected at the edge location and shared back to a centralized data center or cloud so that it can be used for retraining the application.
Due to this reliance on data to improve the application, a strong data strategy is critical.
The cost to transmit data from the edge to the data center or cloud is impacted by data size, network bandwidth, and how frequently the application needs to be updated. Here are some of the different data strategies that people employ with AI applications at the edge:
At the very least, an organization should collect all incorrect inferences. When an AI makes an incorrect inference, the data needs to be identified, relabeled, and used for retraining to improve model accuracy.
However, if only false inferences are used for retraining, models will likely experience a phenomenon called model drift.
Organizations that opt to send all of their data to a central repository are often in situations where bandwidth and latency are not limiting factors. These organizations use the data to re-train or adjust and build new models. Or they might use it for batch data processing to glean different insights.
The benefit of collecting all data are the enormous pools of data to leverage. The downside is that it is incredibly costly. Often, it’s not even feasible to move that much data.
This is the sweet spot for data collection as it balances the need for valuable data with the cost of transmitting and storing that data.
Interesting data can encompass any data that an organization anticipates to be valuable to their current or future models or data analytics projects. For example, with self driving cars, most of the data collected from the same streets with similar weather would not drastically change the training of a model. However, if it was snowing, that data would be useful to send back to a central repository as it could improve the model for driving during extreme weather.
The functional content of traditional edge software is delivered through code. Developers write and compile sequences of instructions that execute on edge devices. Any management and orchestration platform must accommodate updates to the software to fix defects, add functionality, and remediate vulnerabilities.
Development teams most commonly release new code each month, quarter, or year, but not every new release is immediately pushed to edge systems. Instead, IT teams tend to wait for a critical mass of updates and do a more substantial update only when necessary.
In contrast, edge AI applications follow a different software lifecycle that centers on the training and retraining of the AI model. Every model update has the potential to improve accuracy and precision or increase or adjust functionality. The more frequently a model is updated, the more accurate it becomes, providing additional value to the organization.
For example, if an inspection AI application goes from 75% to 80% accuracy, that organization would see fewer defects missed, leading to improved product quality. Additionally, fewer false positives result in less wasted product.
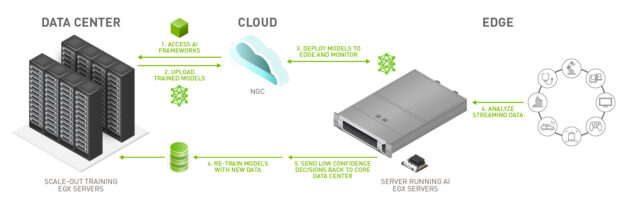
In Figure 1, steps 5 and 6 detail the retraining process, which is critical for updating models.
Frequent model updates should be anticipated by organizations that are deploying an edge AI solution. By building retraining processes from the start through cloud-native deployment practices such as containers and implementing strong data strategies, organizations can develop sustainable edge AI solutions.
Edge computing represents a dramatic shift in the security paradigm for many IT teams. In the castle-and-moat network security model, nobody outside of the network is able to access data on the inside but everyone inside the network can. In contrast, edge environments are inherently unsafe because almost everyone has physical access.
Edge AI applications exacerbate this issue, as they are built using highly valuable corporate intellectual property, which is the lifeline of a business. It represents the competitive advantage that allows for a business’s differentiation and is core to its function.
While security is important for all applications, it is important to increase security at the edge when working with AI applications. For more information, see Edge Computing: Considerations for Security Architects.
Because edge devices are located outside of a physical data center, edge computing sites must be designed with the assumption that malicious actors can get physical access to a machine. To combat this, technologies such as physical tamper detection and secure boot can be put in place as additional security checks.
Edge AI applications often store real-world data such as voice and imagery that convey highly private information about people’s lives and identities. Edge AI developers carry the burden of protecting such private data troves to preserve their users’ trust and to comply with regulations.
Inference engines incorporate the learning of massive, proprietary data and the expertise and work of machine learning teams. Losing control of these inference engines to a competitor could greatly impair a company’s competitiveness in the market.
Due to the distributed nature of these environments, it is almost guaranteed that someone will need to access them remotely. Just-in-time (JIT) access is a policy used to ensure that a person is granted the least amount of privilege needed to complete a task for a limited amount of time.
As enterprises shift from deploying traditional enterprise applications to AI applications at the edge, maintaining the same infrastructure that supported traditional applications is not a scalable solution.
For a successful edge AI application, updating your organization’s deployment methodology, data strategy, update cadence, and security policies is incredibly important.
NVIDIA offers software to help organizations develop, deploy, and manage their AI applications wherever they are located.
For example, to help organizations manage and deploy multiple AI workloads across distributed locations we created NVIDIA Fleet Command, a managed platform for container orchestration that streamlines the provisioning and deployment of systems and AI applications at the edge.
To help organizations get started quickly, we created NVIDIA LaunchPad, a free program that provides immediate, short-term access to the necessary hardware and software stacks to experience end-to-end solution workflows such as building and deploying an AI application.
Want to get experience deploying and managing an edge AI application? Register for a free LaunchPad experience today!
This week marks the beginning of the premier annual Computer Vision and Pattern Recognition conference (CVPR 2022), held both in-person in New Orleans, LA and virtually. As a leader in computer vision research and a Platinum Sponsor, Google will have a strong presence across CVPR 2022 with over 80 papers being presented at the main conference and active involvement in a number of conference workshops and tutorials.
If you are attending CVPR this year, please stop by our booth and chat with our researchers who are actively exploring the latest machine learning techniques for application to various areas of machine perception. Our researchers will also be available to talk about and demo several recent efforts, including on-device ML applications with MediaPipe, the Auto Arborist Dataset for urban forest monitoring, and much more.
You can also learn more about our research being presented at CVPR 2022 in the list below (Google affiliations in bold).
Organizing Committee
Tutorials Chairs
Include: Boqing Gong
Website Chairs
Include: AJ Piergiovanni
Area Chairs
Include: Alireza Fathi, Cordelia Schmid, Deqing Sun, Jonathan Barron, Michael Ryoo, Supasorn Suwajanakorn, Susanna Ricco
Diversity, Equity, and Inclusion Chairs
Include: Noah Snavely
Panel Discussion: Embodied Computer Vision
Panelists include: Michael Ryoo
Publications
Learning to Prompt for Continual Learning (see blog post)
Zifeng Wang*, Zizhao Zhang, Chen-Yu Lee, Han Zhang, Ruoxi Sun, Xiaoqi Ren, Guolong Su, Vincent Perot, Jennifer Dy, Tomas Pfister
GCR: Gradient Coreset Based Replay Buffer Selection for Continual Learning
Rishabh Tiwari, Krishnateja Killamsetty, Rishabh Iyer, Pradeep Shenoy
Zero-Shot Text-Guided Object Generation with Dream Fields
Ajay Jain, Ben Mildenhall, Jonathan T. Barron, Pieter Abbeel, Ben Poole
Towards End-to-End Unified Scene Text Detection and Layout Analysis
Shangbang Long, Siyang Qin, Dmitry Panteleev, Alessandro Bissacco, Yasuhisa Fujii, Michalis Raptis
FLOAT: Factorized Learning of Object Attributes for Improved Multi-object Multi-part Scene Parsing
Rishubh Singh, Pranav Gupta, Pradeep Shenoy, Ravikiran Sarvadevabhatla
LOLNerf: Learn from One Look
Daniel Rebain, Mark Matthews, Kwang Moo Yi, Dmitry Lagun, Andrea Tagliasacchi
Photorealistic Monocular 3D Reconstruction of Humans Wearing Clothing
Thiemo Alldieck, Mihai Zanfir, Cristian Sminchisescu
Learning Local Displacements for Point Cloud Completion
Yida Wang, David Joseph Tan, Nassir Navab, Federico Tombari
Density-Preserving Deep Point Cloud Compression
Yun He, Xinlin Ren, Danhang Tang, Yinda Zhang, Xiangyang Xue, Yanwei Fu
CMT-DeepLab: Clustering Mask Transformers for Panoptic Segmentation
Qihang Yu*, Huiyu Wang, Dahun Kim, Siyuan Qiao, Maxwell Collins, Yukun Zhu, Hartwig Adam, Alan Yuille, Liang-Chieh Chen
Deformable Sprites for Unsupervised Video Decomposition
Vickie Ye, Zhengqi Li, Richard Tucker, Angjoo Kanazawa, Noah Snavely
Learning with Neighbor Consistency for Noisy Labels
Ahmet Iscen, Jack Valmadre, Anurag Arnab, Cordelia Schmid
Multiview Transformers for Video Recognition
Shen Yan, Xuehan Xiong, Anurag Arnab, Zhichao Lu, Mi Zhang, Chen Sun, Cordelia Schmid
Kubric: A Scalable Dataset Generator
Klaus Greff, Francois Belletti, Lucas Beyer, Carl Doersch, Yilun Du, Daniel Duckworth, David J. Fleet, Dan Gnanapragasam, Florian Golemo, Charles Herrmann, Thomas Kipf, Abhijit Kundu, Dmitry Lagun, Issam Laradji, Hsueh-Ti (Derek) Liu, Henning Meyer, Yishu Miao, Derek Nowrouzezahrai, Cengiz Oztireli, Etienne Pot, Noha Radwan*, Daniel Rebain, Sara Sabour, Mehdi S. M. Sajjadi, Matan Sela, Vincent Sitzmann, Austin Stone, Deqing Sun, Suhani Vora, Ziyu Wang, Tianhao Wu, Kwang Moo Yi, Fangcheng Zhong, Andrea Tagliasacchi
3D Moments from Near-Duplicate Photos
Qianqian Wang, Zhengqi Li, David Salesin, Noah Snavely, Brian Curless, Janne Kontkanen
Mip-NeRF 360: Unbounded Anti-Aliased Neural Radiance Fields
Jonathan T. Barron, Ben Mildenhall, Dor Verbin, Pratul P. Srinivasan, Peter Hedman
RegNeRF: Regularizing Neural Radiance Fields for View Synthesis from Sparse Inputs
Michael Niemeyer*, Jonathan T. Barron, Ben Mildenhall, Mehdi S. M. Sajjadi, Andreas Geiger, Noha Radwan*
Ref-NeRF: Structured View-Dependent Appearance for Neural Radiance Fields
Dor Verbin, Peter Hedman, Ben Mildenhall, Todd Zickler, Jonathan T. Barron, Pratul P. Srinivasan
IRON: Inverse Rendering by Optimizing Neural SDFs and Materials from Photometric Images
Kai Zhang, Fujun Luan, Zhengqi Li, Noah Snavely
MAXIM: Multi-Axis MLP for Image Processing
Zhengzhong Tu*, Hossein Talebi, Han Zhang, Feng Yang, Peyman Milanfar, Alan Bovik, Yinxiao Li
Restormer: Efficient Transformer for High-Resolution Image Restoration
Syed Waqas Zamir, Aditya Arora, Salman Khan, Munawar Hayat, Fahad Shahbaz Khan, Ming-Hsuan Yang
Burst Image Restoration and Enhancement
Akshay Dudhane, Syed Waqas Zamir, Salman Khan, Fahad Shahbaz Khan, Ming-Hsuan Yang
Neural RGB-D Surface Reconstruction
Dejan Azinović, Ricardo Martin-Brualla, Dan B Goldman, Matthias Nießner, Justus Thies
Scene Representation Transformer: Geometry-Free Novel View Synthesis Through Set-Latent Scene Representations
Mehdi S. M. Sajjadi, Henning Meyer, Etienne Pot, Urs Bergmann, Klaus Greff, Noha Radwan*, Suhani Vora, Mario Lučić, Daniel Duckworth, Alexey Dosovitskiy*, Jakob Uszkoreit*, Thomas Funkhouser, Andrea Tagliasacchi*
ZebraPose: Coarse to Fine Surface Encoding for 6DoF Object Pose Estimation
Yongzhi Su, Mahdi Saleh, Torben Fetzer, Jason Rambach, Nassir Navab, Benjamin Busam, Didier Stricker, Federico Tombari
MetaPose: Fast 3D Pose from Multiple Views without 3D Supervision
Ben Usman, Andrea Tagliasacchi, Kate Saenko, Avneesh Sud
GPV-Pose: Category-Level Object Pose Estimation via Geometry-Guided Point-wise Voting
Yan Di, Ruida Zhang, Zhiqiang Lou, Fabian Manhardt, Xiangyang Ji, Nassir Navab, Federico Tombari
Rethinking Deep Face Restoration
Yang Zhao*, Yu-Chuan Su, Chun-Te Chu, Yandong Li, Marius Renn, Yukun Zhu, Changyou Chen, Xuhui Jia
Transferability Metrics for Selecting Source Model Ensembles
Andrea Agostinelli, Jasper Uijlings, Thomas Mensink, Vittorio Ferrari
Robust Fine-Tuning of Zero-Shot Models
Mitchell Wortsman, Gabriel Ilharco, Jong Wook Kim, Mike Li, Simon Kornblith, Rebecca Roelofs, Raphael Gontijo Lopes, Hannaneh Hajishirzi, Ali Farhadi, Hongseok Namkoong, Ludwig Schmidt
Block-NeRF: Scalable Large Scene Neural View Synthesis
Matthew Tancik, Vincent Casser, Xinchen Yan, Sabeek Pradhan, Ben Mildenhall, Pratul P. Srinivasan, Jonathan T. Barron, Henrik Kretzschmar
Light Field Neural Rendering
Mohammad Suhail*, Carlos Esteves, Leonid Sigal, Ameesh Makadia
Transferability Estimation Using Bhattacharyya Class Separability
Michal Pándy, Andrea Agostinelli, Jasper Uijlings, Vittorio Ferrari, Thomas Mensink
Matching Feature Sets for Few-Shot Image Classification
Arman Afrasiyabi, Hugo Larochelle, Jean-François Lalonde, Christian Gagné
Which Model to Transfer? Finding the Needle in the Growing Haystack
Cedric Renggli, André Susano Pinto, Luka Rimanic, Joan Puigcerver, Carlos Riquelme, Ce Zhang, Mario Lučić
Auditing Privacy Defenses in Federated Learning via Generative Gradient Leakage
Zhuohang Li, Jiaxin Zhang, Luyang Liu, Jian Liu
Estimating Example Difficulty Using Variance of Gradients
Chirag Agarwal, Daniel D’souza, Sara Hooker
More Than Words: In-the-Wild Visually-Driven Prosody for Text-to-Speech (see blog post)
Michael Hassid, Michelle Tadmor Ramanovich, Brendan Shillingford, Miaosen Wang, Ye Jia, Tal Remez
Robust Outlier Detection by De-Biasing VAE Likelihoods
Kushal Chauhan, Barath Mohan U, Pradeep Shenoy, Manish Gupta, Devarajan Sridharan
Deep 3D-to-2D Watermarking: Embedding Messages in 3D Meshes and Extracting Them from 2D Renderings
Innfarn Yoo, Huiwen Chang, Xiyang Luo, Ondrej Stava, Ce Liu*, Peyman Milanfar, Feng Yang
Knowledge Distillation: A Good Teacher Is Patient and Consistent
Lucas Beyer, Xiaohua Zhai, Amélie Royer*, Larisa Markeeva*, Rohan Anil, Alexander Kolesnikov
Urban Radiance Fields
Konstantinos Rematas, Andrew Liu, Pratul P. Srinivasan, Jonathan T. Barron, Andrea Tagliasacchi, Thomas Funkhouser, Vittorio Ferrari
Manifold Learning Benefits GANs
Yao Ni, Piotr Koniusz, Richard Hartley, Richard Nock
MaskGIT: Masked Generative Image Transformer
Huiwen Chang, Han Zhang, Lu Jiang, Ce Liu*, William T. Freeman
InOut: Diverse Image Outpainting via GAN Inversion
Yen-Chi Cheng, Chieh Hubert Lin, Hsin-Ying Lee, Jian Ren, Sergey Tulyakov, Ming-Hsuan Yang
Scaling Vision Transformers (see blog post)
Xiaohua Zhai, Alexander Kolesnikov, Neil Houlsby, Lucas Beyer
Fine-Tuning Image Transformers Using Learnable Memory
Mark Sandler, Andrey Zhmoginov, Max Vladymyrov, Andrew Jackson
PokeBNN: A Binary Pursuit of Lightweight Accuracy
Yichi Zhang*, Zhiru Zhang, Lukasz Lew
Bending Graphs: Hierarchical Shape Matching Using Gated Optimal Transport
Mahdi Saleh, Shun-Cheng Wu, Luca Cosmo, Nassir Navab, Benjamin Busam, Federico Tombari
Uncertainty-Aware Deep Multi-View Photometric Stereo
Berk Kaya, Suryansh Kumar, Carlos Oliveira, Vittorio Ferrari, Luc Van Gool
Depth-Supervised NeRF: Fewer Views and Faster Training for Free
Kangle Deng, Andrew Liu, Jun-Yan Zhu, Deva Ramanan
Dense Depth Priors for Neural Radiance Fields from Sparse Input Views
Barbara Roessle, Jonathan T. Barron, Ben Mildenhall, Pratul P. Srinivasan, Matthias Nießner
Trajectory Optimization for Physics-Based Reconstruction of 3D Human Pose from Monocular Video
Erik Gärtner, Mykhaylo Andriluka, Hongyi Xu, Cristian Sminchisescu
Differentiable Dynamics for Articulated 3D Human Motion Reconstruction
Erik Gärtner, Mykhaylo Andriluka, Erwin Coumans, Cristian Sminchisescu
Panoptic Neural Fields: A Semantic Object-Aware Neural Scene Representation
Abhijit Kundu, Kyle Genova, Xiaoqi Yin, Alireza Fathi, Caroline Pantofaru, Leonidas J. Guibas, Andrea Tagliasacchi, Frank Dellaert, Thomas Funkhouser
Pyramid Adversarial Training Improves ViT Performance
Charles Herrmann, Kyle Sargent, Lu Jiang, Ramin Zabih, Huiwen Chang, Ce Liu*, Dilip Krishnan, Deqing Sun
Proper Reuse of Image Classification Features Improves Object Detection
Cristina Vasconcelos, Vighnesh Birodkar, Vincent Dumoulin
SOMSI: Spherical Novel View Synthesis with Soft Occlusion Multi-Sphere Images
Tewodros Habtegebrial, Christiano Gava, Marcel Rogge, Didier Stricker, Varun Jampani
TubeFormer-DeepLab: Video Mask Transformer
Dahun Kim, Jun Xie, Huiyu Wang, Siyuan Qiao, Qihang Yu, Hong-Seok Kim, Hartwig Adam, In So Kweon, Liang-Chieh Chen
Contextualized Spatio-Temporal Contrastive Learning with Self-Supervision
Liangzhe Yuan, Rui Qian*, Yin Cui, Boqing Gong, Florian Schroff, Ming-Hsuan Yang, Hartwig Adam, Ting Liu
When Does Contrastive Visual Representation Learning Work?
Elijah Cole, Xuan Yang, Kimberly Wilber, Oisin Mac Aodha, Serge Belongie
Less Is More: Generating Grounded Navigation Instructions from Landmarks
Su Wang, Ceslee Montgomery, Jordi Orbay, Vighnesh Birodkar, Aleksandra Faust, Izzeddin Gur, Natasha Jaques, Austin Waters, Jason Baldridge, Peter Anderson
Forecasting Characteristic 3D Poses of Human Actions
Christian Diller, Thomas Funkhouser, Angela Dai
BEHAVE: Dataset and Method for Tracking Human Object Interactions
Bharat Lal Bhatnagar, Xianghui Xie, Ilya A. Petrov, Cristian Sminchisescu, Christian Theobalt, Gerard Pons-Moll
Motion-from-Blur: 3D Shape and Motion Estimation of Motion-Blurred Objects in Videos
Denys Rozumnyi, Martin R. Oswald, Vittorio Ferrari, Marc Pollefeys
End-to-End Generative Pretraining for Multimodal Video Captioning (see blog post)
Paul Hongsuck Seo, Arsha Nagrani, Anurag Arnab, Cordelia Schmid
Uncertainty-Aware Adaptation for Self-Supervised 3D Human Pose Estimation
Jogendra Nath Kundu, Siddharth Seth, Pradyumna YM, Varun Jampani, Anirban Chakraborty, R. Venkatesh Babu
Learning ABCs: Approximate Bijective Correspondence for Isolating Factors of Variation with Weak Supervision
Kieran A. Murphy, Varun Jampani, Srikumar Ramalingam, Ameesh Makadia
HumanNeRF: Free-Viewpoint Rendering of Moving People from Monocular Video
Chung-Yi Weng, Brian Curless, Pratul P. Srinivasan, Jonathan T. Barron, Ira Kemelmacher-Shlizerman
Deblurring via Stochastic Refinement
Jay Whang*, Mauricio Delbracio, Hossein Talebi, Chitwan Saharia, Alexandros G. Dimakis, Peyman Milanfar
NeRF in the Dark: High Dynamic Range View Synthesis from Noisy Raw Images
Ben Mildenhall, Peter Hedman, Ricardo Martin-Brualla, Pratul P. Srinivasan, Jonathan T. Barron
CoNeRF: Controllable Neural Radiance Fields
Kacper Kania, Kwang Moo Yi, Marek Kowalski, Tomasz Trzciński, Andrea Tagliasacchi
A Conservative Approach for Unbiased Learning on Unknown Biases
Myeongho Jeon, Daekyung Kim, Woochul Lee, Myungjoo Kang, Joonseok Lee
DeepFusion: Lidar-Camera Deep Fusion for Multi-Modal 3D Object Detection (see blog post)
Yingwei Li*, Adams Wei Yu, Tianjian Meng, Ben Caine, Jiquan Ngiam, Daiyi Peng, Junyang Shen, Yifeng Lu, Denny Zhou, Quoc V. Le, Alan Yuille, Mingxing Tan
Video Frame Interpolation Transformer
Zhihao Shi, Xiangyu Xu, Xiaohong Liu, Jun Chen, Ming-Hsuan Yang
Global Matching with Overlapping Attention for Optical Flow Estimation
Shiyu Zhao, Long Zhao, Zhixing Zhang, Enyu Zhou, Dimitris Metaxas
LiT: Zero-Shot Transfer with Locked-image Text Tuning (see blog post)
Xiaohua Zhai, Xiao Wang, Basil Mustafa, Andreas Steiner, Daniel Keysers, Alexander Kolesnikov, Lucas Beyer
Are Multimodal Transformers Robust to Missing Modality?
Mengmeng Ma, Jian Ren, Long Zhao, Davide Testuggine, Xi Peng
3D-VField: Adversarial Augmentation of Point Clouds for Domain Generalization in 3D Object Detection
Alexander Lehner, Stefano Gasperini, Alvaro Marcos-Ramiro, Michael Schmidt, Mohammad-Ali Nikouei Mahani, Nassir Navab, Benjamin Busam, Federico Tombari
SHIFT: A Synthetic Driving Dataset for Continuous Multi-Task Domain Adaptation
Tao Sun, Mattia Segu, Janis Postels, Yuxuan Wang, Luc Van Gool, Bernt Schiele, Federico Tombari, Fisher Yu
H4D: Human 4D Modeling by Learning Neural Compositional Representation
Boyan Jiang, Yinda Zhang, Xingkui Wei, Xiangyang Xue, Yanwei Fu
Gravitationally Lensed Black Hole Emission Tomography
Aviad Levis, Pratul P. Srinivasan, Andrew A. Chael, Ren Ng, Katherine L. Bouman
Deep Saliency Prior for Reducing Visual Distraction
Kfir Aberman, Junfeng He, Yossi Gandelsman, Inbar Mosseri, David E. Jacobs, Kai Kohlhoff, Yael Pritch, Michael Rubinstein
The Auto Arborist Dataset: A Large-Scale Benchmark for Multiview Urban Forest Monitoring Under Domain Shift
Sara Beery, Guanhang Wu, Trevor Edwards, Filip Pavetic, Bo Majewski, Shreyasee Mukherjee, Stanley Chan, John Morgan, Vivek Rathod, Jonathan Huang
Workshops
Ethical Considerations in Creative Applications of Computer Vision
Chairs and Advisors: Negar Rostamzadeh, Fernando Diaz, Emily Denton, Mark Diaz, Jason Baldridge
Dynamic Neural Networks Meet Computer Vision Organizers
Invited Speaker: Barret Zoph
Precognition: Seeing Through the Future
Organizer: Utsav Prabhu
Invited Speaker: Sella Nevo
Computer Vision in the Built Environment for the Design, Construction, and Operation of Buildings
Invited Speakers: Thomas Funkhouser, Federico Tombari
Neural Architecture Search: Lightweight NAS Challenge
Invited Speaker: Barret Zoph
Transformers in Vision
Organizer: Lucas Beyer
Invited Speakers and Panelists: Alexander Kolesnikov, Mathilde Caron, Arsha Nagrani, Lucas Beyer
Challenge on Learned Image Compression
Organizers: George Toderici, Johannes Balle, Eirikur Agustsson, Nick Johnston, Fabian Mentzer, Luca Versari
Invited Speaker: Debargha Mukherjee
Embodied AI
Organizers: Anthony Francis, Sören Pirk, Alex Ku, Fei Xia, Peter Anderson
Scientific Advisory Board Members: Alexander Toshev, Jie Tan
Invited Speaker: Carolina Parada
Sight and Sound
Organizers: Arsha Nagrani, William Freeman
New Trends in Image Restoration and Enhancement
Organizers: Ming-Hsuan Yang, Vivek Kwatra, George Toderici
EarthVision: Large Scale Computer Vision for Remote Sensing Imagery
Invited Speaker: John Quinn
LatinX in Computer Vision Research
Organizer: Ruben Villegas
Fine-Grained Visual Categorization
Organizer: Kimberly Wilber
The Art of Robustness: Devil and Angel in Adversarial Machine Learning
Organizer: Florian Tramèr
Invited Speaker: Nicholas Carlini
AI for Content Creation
Organizers: Deqing Sun, Huiwen Chang, Lu Jiang
Invited Speaker: Chitwan Saharia
LOng-form VidEo Understanding
Invited Speaker: Cordelia Schmid
Visual Perception and Learning in an Open World
Invited Speaker: Rahul Sukthankar
Media Forensics
Organizer : Christoph Bregler
Technical Committee Members: Shruti Agarwal, Scott McCloskey, Peng Zhou
Vision Datasets Understanding
Organizer: José Lezama
Embedded Vision
Invited Speaker: Matthias Grundmann
Federated Learning for Computer Vision
Invited Speaker: Zheng Xu
Large Scale Holistic Video Understanding
Organizer: David Ross
Invited Speaker: Anurag Arnab
Learning With Limited Labelled Data for Image and Video Understanding
Invited Speaker: Hugo Larochelle
Bridging the Gap Between Computational Photography and Visual Recognition
Invited Speaker: Xiaohua Zhai
Explainable Artificial Intelligence for Computer Vision
Invited Speaker: Been Kim
Robustness in Sequential Data
Organizers: Sayna Ebrahimi, Kevin Murphy
Invited Speakers: Sayna Ebrahimi, Balaji Lakshminarayanan
Sketch-Oriented Deep Learning
Organizer: David Ha
Invited Speaker: Jonas Jongejan
Multimodal Learning and Applications
Invited Speaker: Cordelia Schmid
Computational Cameras and Displays
Organizer: Tali Dekel
Invited Speaker: Peyman Millanfar
Artificial Social Intelligence
Invited Speaker: Natasha Jaques
VizWiz Grand Challenge: Algorithms to Assist People Who Are Blind
Invited Speaker and Panelist: Andrew Howard
Image Matching: Local Features & Beyond
Organizer: Eduard Trulls
Multi-Agent Behavior: Representation, Modeling, Measurement, and Applications
Organizer: Ting Liu
Efficient Deep Learning for Computer Vision
Organizers: Pete Warden, Andrew Howard, Grace Chu, Jaeyoun Kim
Gaze Estimation and Prediction in the Wild
Organizer: Thabo Beeler
Tutorials
Denoising Diffusion-Based Generative Modeling: Foundations and Applications
Invited Speaker: Ruiqi Gao
Algorithmic Fairness: Why It’s Hard and Why It’s Interesting
Invited Speaker: Sanmi Koyejo
Beyond Convolutional Neural Networks
Invited Speakers: Neil Houlsby, Alexander Kolesnikov, Xiaohua Zhai
Joint Ego4D and Egocentric Perception, Interaction & Computing
Invited Speaker: Vittorio Ferrari
Deep AUC Maximization
Invited Speakers: Tianbao Yang
Vision-Based Robot Learning
Organizers: Michael S. Ryoo, Andy Zeng, Pete Florence
Graph Machine Learning for Visual Computing
Organizers: Federico Tombari
Invited Speakers: Federico Tombari, Fabian Manhardt

3D artist Jae Solina, who goes by the stage name JSFILMZ, steps In the NVIDIA Studio this week to share his unique 3D creative workflow in the making of Cyberpunk Short Film — a story shrouded in mystery with a tense exchange between two secretive contacts.
The post 3D Artist Jae Solina Goes Cyberpunk This Week ‘In the NVIDIA Studio’ appeared first on NVIDIA Blog.