
|
submitted by /u/Prabeen1 [visit reddit] [comments] |
Categories
TensorFlow IO Kit From Google

 DataBloom
DataBloom
|
|
submitted by /u/Prabeen1 [visit reddit] [comments] |
Hello,
I’m working on a project where I aim to give an image on the night sky to my neural network, and it should tell me how many satellites are in the frame.
I’ve trained my network to learn what a satellite looks like by giving it 10×10 pxl cropped images, and so my model takes 100 input. I’m doing it as a classification problem, and so it gives me the probability of the 10×10 pxl image to contain a satellite.
I’ve trained the network with no issue, I’ve done the testing with no issue, but when it comes to actually giving it a single 10x10pxl image to give me an answer, I get this error message:
ValueError: Input 0 of layer sequential is incompatible with the layer: expected axis -1 of input shape to have value 100 but received input with shape (None, 1)
This is what my code looks like for the model training and testing:
visible = Input(shape=100) Hidden1 = Dense(32, activation = 'relu')(visible) Hidden2 = Dense(64, activation = 'relu')(Hidden1) Hidden3 = Dense(128, activation = 'relu')(Hidden2) Output = Dense(1, activation = 'softplus')(Hidden3) model = Model(inputs=visible, outputs=Output) model.compile(loss='huber',optimizer='adam', metrics=['accuracy']) batch_size = 112 epochs = 200 model.fit(x=x_train,y=y_train, batch_size=batch_size,epochs=epochs) test_loss, test_acc = model.evaluate(x_test, y_test) >Test Loss: 0.06204257160425186, Test Accuracy: 0.8361972570419312
I have written a little code that crops full size frames (480×640) into a multitude of 10×10 crops, and I want to feed each crop to the network to then tell me which crops contain a satellite.
# image size is 480*640 height = 480 length = 640 X_Try = [] for a in range(0, height, 10): for b in range(0, length, 10): img = image.crop((a, b, a+10, b+10)) img = np.array(img)/255.0 #to normalize my values img = img.flatten() #to make the matrix into a single array X_Try.append(img) print(len(X_Try)) >3072 print(len(X_Try[0])) >100
My X_Try is populated with arrays of shape (100,1), and my logic is that I should just give each of those arrays to my model to predict, and that should output a y_pred of shape (3072,1) containing the probability of each crop to contain a satellite.
However, my problem appears here:
y_pred=[] for f in range(0,len(X_Try)): y_p = model.predict(X_Try[f]) y_pred.append(y_p)
This is then where the error message appears: it seems to be of the opinion that I’m giving something of shape (None, 1), and it only takes input of shape (None,100), however I’ve checked before and all of my arrays in X_Try are indeed of size 100.
I’ve also tried with a single crop, in case it is the for loop that’s causing issue:
y_pred = model.predict(X_Try[0])
but that gives me the same error.
I’ve looked online for similar issue but most people seem to have that problem during the training or the testing, not at the prediction.
Could someone guide me in the right direction?
EDIT: I forgot to add that, but I find that doing
y_pred = model.predict(x_test)
does work, where x_test has a shape of (4481,100,1) but for some reason doing
y_pred = model.predict(X_Try)
doesn’t work, where X_Try has a shape of (3072,100,1) doesn’t work and gives me the error message:
ValueError: Layer model_2 expects 1 input(s), but it received 3072 input tensors.
submitted by /u/flaflou
[visit reddit] [comments]
I want to learn TensorFlow, for use in my Java projects. I have not found any official TensorFlow tutorials and introductions that use Java as the language. I can use one of the Python tutorials, and translate into Java as I go, but I would appreciate if anyone can point me in the direction of an official Java tutorial.
submitted by /u/OliverHPerry
[visit reddit] [comments]
Hello, I am trying to run the resnet model on custom images (transfer learning).
My directory tree looks like this:
train
class1
image1
image2
….
class2
image1
image2
…
val
class1
image1
image2
….
class2
image1
image2
…
And I created the tensorflow datasets like this:
train_ds = tf.keras.preprocessing.image_dataset_from_directory( “train”, labels=’inferred’, label_mode=’int’, image_size=(img_height, img_width), batch_size=batch_size)
val_ds = tf.keras.preprocessing.image_dataset_from_directory( “val”, labels=’inferred’, label_mode=’int’, image_size=(img_height, img_width), batch_size=batch_size)
Then I try to display the images for reference, running:
import matplotlib.pyplot as plt
class_names = val_ds.class_names
plt.figure(figsize=(10, 10)) for images, labels in val_ds.take(1): for i in range(30): ax = plt.subplot(5, 7, i + 1) plt.imshow(images[i].numpy().astype(“uint8”)) plt.title(class_names[labels[i]]) plt.axis(“off”)
But with val_ds, I get the error “Input is empty”, while with train_ds it actually shows the images. Anyone knows a possible reason why behind it? The dataset I am using is here – https://github.com/xuequanlu/I-Nema – and I have converted all the .tif images to .jpg.
Thanks in advance!
EDIT: here is the error log : https://pastecode.io/s/82hk68ar
submitted by /u/quaranprove
[visit reddit] [comments]
 Deep learning models have been successfully used in medical image analysis problems but they require a large, curated amount of labeled images to obtain good performance. Creating such annotations are tedious, time-consuming and typically require clinical expertise. To address this gap, Project MONAI has released MONAI Label v0.1 – an intelligent open source image labeling … Continued
Deep learning models have been successfully used in medical image analysis problems but they require a large, curated amount of labeled images to obtain good performance. Creating such annotations are tedious, time-consuming and typically require clinical expertise. To address this gap, Project MONAI has released MONAI Label v0.1 – an intelligent open source image labeling … Continued
Deep learning models have been successfully used in medical image analysis problems but they require a large, curated amount of labeled images to obtain good performance. Creating such annotations are tedious, time-consuming and typically require clinical expertise.
To address this gap, Project MONAI has released MONAI Label v0.1 – an intelligent open source image labeling and learning tool that helps researchers and clinicians collaborate, create annotated datasets easily and quickly, and build AI models in a standardized MONAI paradigm.
MONAI Label enables the adaptation of AI models to the clinical task at hand by continuously learning from the user’s interactions and new labels. It powers an AI Assisted annotation experience, allowing researchers and developers to make continuous improvements to their applications with iterative feedback from clinicians who are typically the end users of the medical imaging AI models.
At the Children’s Hospital of Philadelphia (CHOP), Dr. Matthew Jolley explains how they are innovating and driving clinical impact with machine learning algorithms.
“Children with congenital heart disease demonstrate a broad range of anatomy, and there are few readily available tools to facilitate image-based structural phenotyping and patient specific planning of complex cardiac interventions. However, currently 3D image-based heart model creation is slow, even in the hands of experienced modelers. As such, we have been working to develop machine learning algorithms to create models of heart valves in children with congenital heart disease, such as the tricuspid valve in hypoplastic left heart syndrome. Ongoing development of automation based on machine learning will allow rapid modeling and precise quantification of how a dysfunctional valve differs from normal valves across multiple parameters. That “structural valve profile” for an individual can then be contextualized within the spectrum of anatomy and function we see in the population, which may eventually inform improved medical decision making and interventions for children.”
With MONAI Label we envision creating a community of researchers and clinicians like Dr. Jolley and his team who can build upon a well maintained software foundation that will accelerate collaboration through continuous learning. The MONAI Label team and CHOP collaborated through a Slicer week project, and successfully developed a MONAI Label application for leaflet segmentation of heart valves in 3D echocardiographic (3DE) images. The team is now working to deploy this model as a MONAI Label application on a public facing server at CHOP where clinicians can directly interface with the model and trigger a training loop for adaptation – learn more.
It is incredibly important for an open source initiative like Project MONAI to have clinicians in the loop as we converge to develop a common set of best practices for AI lifecycle management in healthcare imaging. To quote Dr. Jolley:
“Open-source frameworks like Project MONAI provide a standardized, transparent, and reproducible template for the creation of, and deployment of medical imaged-focused machine learning models, potentiating efforts such as ours. They allow us to focus on investigating novel algorithms and their application, rather than developing and maintaining software infrastructure. This in turn has accelerated research progress which we are actively translating into tools of practical relevance to the pediatric community we serve.”
WHAT IS INCLUDED IN MONAI LABEL V0.1
MONAI Label is an open-source server-client system that is easy to set up and can run locally on a machine with one or two GPUs. The initial release does not yet support multiple user sessions, therefore both server and client operate on the same machine.
MONAI Label delivers on MONAI’s core promise of being modular, Pythonic, extensible, easy to debug, user friendly, and portable.
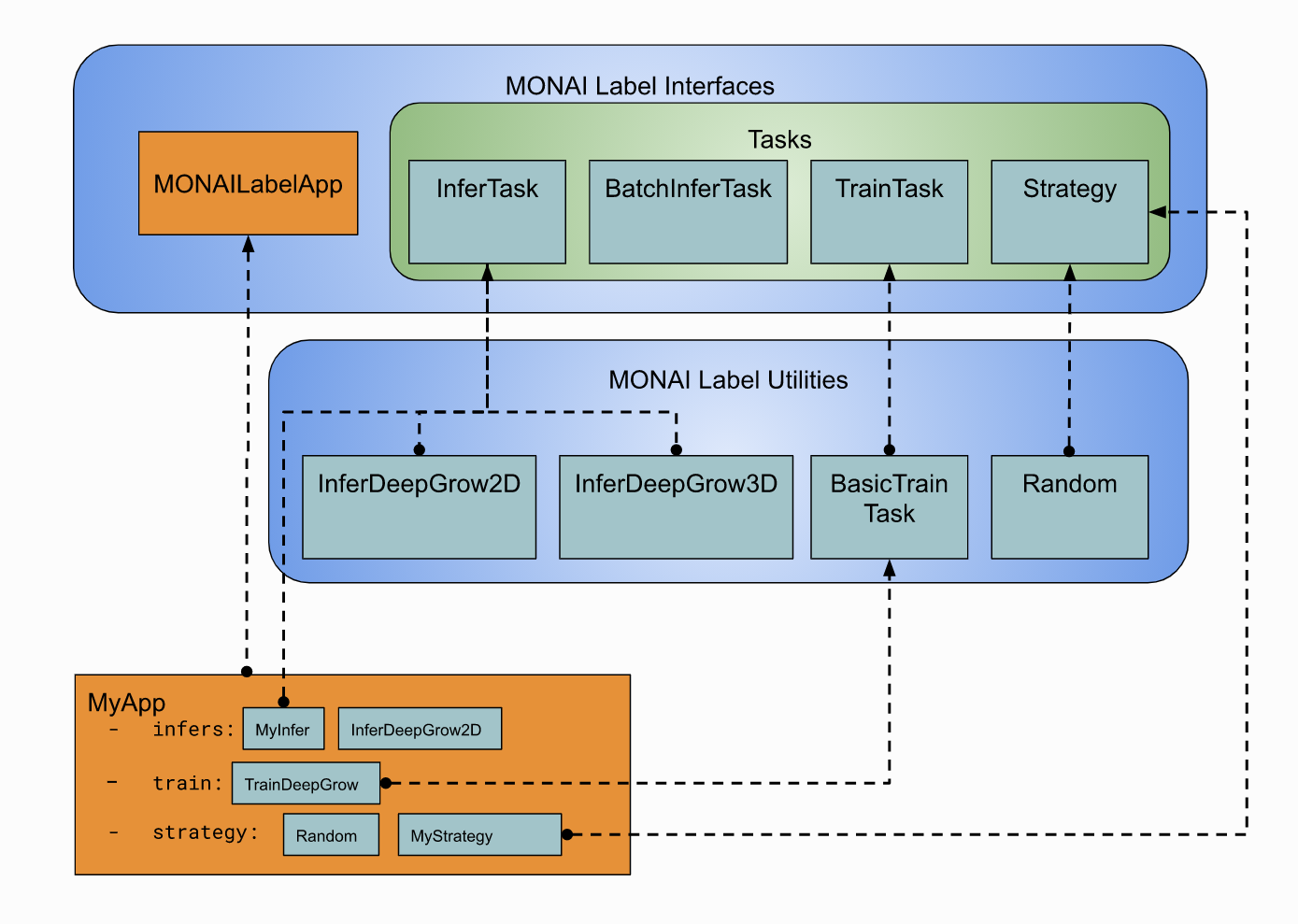
MONAI v0.1 includes:
Future releases of NVIDIA Clara AIAA will also leverage the MONAI Label framework. We continue to bring together development efforts for NVIDIA Clara medical imaging tools and MONAI to deliver domain-optimized, robust software tools for researchers and developers in healthcare imaging.
With contributions from an engaged community, MONAI Label aims to reduce the cost of labeling and maximize the collaboration between researchers & clinicians. Get started today with sample applications available on the MONAI Label GitHub and follow along with our step-by-step getting started guide available in the MONAI Label Documentation.
 New research out of the University of California, San Francisco has given a paralyzed man the ability to communicate by translating his brain signals into computer generated writing. The study, published in The New England Journal of Medicine, marks a significant milestone toward restoring communication for people who have lost the ability to speak. “To … Continued
New research out of the University of California, San Francisco has given a paralyzed man the ability to communicate by translating his brain signals into computer generated writing. The study, published in The New England Journal of Medicine, marks a significant milestone toward restoring communication for people who have lost the ability to speak. “To … Continued
New research out of the University of California, San Francisco has given a paralyzed man the ability to communicate by translating his brain signals into computer generated writing. The study, published in The New England Journal of Medicine, marks a significant milestone toward restoring communication for people who have lost the ability to speak.
“To our knowledge, this is the first successful demonstration of direct decoding of full words from the brain activity of someone who is paralyzed and cannot speak,” senior author and the Joan and Sanford Weill Chair of Neurological Surgery at UCSF, Edward Chang said in a press release. “It shows strong promise to restore communication by tapping into the brain’s natural speech machinery.”
Some with speech limitations use assistive devices–such as touchscreens, keyboards, or speech-generating computers to communicate. However, every year thousands lose their speech ability from paralysis or brain damage, leaving them unable to use assistive technologies.
The participant lost his ability to speak in 2003, paralyzed by a brain stroke following a car accident. The researchers were not sure if his brain retained neural activity linked to speech. To track his brain signals, a neuroprosthetic device consisting of electrodes was positioned on the left side of the brain, across several regions known for speech processing.
Over about four months the team embarked on 50 training sessions, where the participant was prompted to say individual words, form sentences, or respond to questions on a display screen. While responding to the prompts, the electrode device captured neural activity and transmitted the information to a computer with custom software.
“Our models needed to learn the mapping between complex brain activity patterns and intended speech. That poses a major challenge when the participant can’t speak,” David Moses, a postdoctoral engineer in the Chang lab and one of the lead authors of the study, said in a press release.
To decode the responses from his brain activity, the team created speech-detection and word classification models. Using the cuDNN-accelerated TensorFlow framework and 32 NVIDIA V100 Tensor Core GPUs the researchers trained, fine-tuned, and evaluated the models.
“Utilizing neural networks was essential to getting the classification and detection performance we did, and our final product was the result of lots of experimentation,’ said study co-lead Sean Metzger. “Because our dataset was constantly evolving and growing, being able to adapt the models we were using was critical. The GPUs helped us make changes, monitor progress, and understand our dataset.”
With up to 93% accuracy, and a median rate of 75%, the model decoded the participants word’s at a rate of up to 18 per minute.
“We want to get to 1,000 words, and eventually all words. This is just the starting point,” Chang said.
The study builds off previous work by Chang and his colleagues, which developed a deep learning method for decoding and converting brain signals. Unlike the current work, participants in the previous study were able to speak.
Read more >>>
Read the full article in The New England Journal of Medicine >>>
Groups across Google are actively pursuing research across the field of machine learning, ranging from theory to application. With scalable tools and architectures, we build machine learning systems to solve deep scientific and engineering challenges in areas of language, music, visual processing, and more.
Google is proud to be a Platinum Sponsor of the thirty-eighth International Conference on Machine Learning (ICML 2021), a premier annual event happening this week. As a leader in machine learning research — with over 100 accepted publications and Googlers participating in workshops — we look forward to our continued partnership with the broader machine learning research community.
Registered for ICML 2021? We hope you’ll visit the Google virtual booth to learn more about the exciting work, creativity, and fun that goes into solving a portion of the field’s most interesting challenges. Take a look below to learn more about the Google research being presented at ICML 2021 (Google affiliations in bold).
Organizing Committee
ICML Board Members include: Corinna Cortes, Hugo Larochelle, Shakir Mohamed
ICML Emeritus Board includes: William Cohen, Andrew McCallum
Tutorial Co-Chair member: Quoc Lee
Publications
Attention Is Not All You Need: Pure Attention Loses Rank Doubly Exponentially with Depth
Yihe Dong, Jean-Baptiste Cordonnier, Andreas Loukas
Scalable Evaluation of Multi-Agent Reinforcement Learning with Melting Pot
Joel Z. Leibo, Edgar Duéñez-Guzmán, Alexander Sasha Vezhnevets, John P. Agapiou, Peter Sunehag, Raphael Koster, Jayd Matyas, Charles Beattie, Igor Mordatch, Thore Graepel
On the Optimality of Batch Policy Optimization Algorithms
Chenjun Xiao, Yifan Wu, Tor Lattimore, Bo Dai, Jincheng Mei, Lihong Li*, Csaba Szepesvari, Dale Schuurmans
Low-Rank Sinkhorn Factorization
Meyer Scetbon, Marco Cuturi, Gabriel Peyré
Oops I Took A Gradient: Scalable Sampling for Discrete Distributions
Will Grathwohl, Kevin Swersky, Milad Hashemi, David Duvenaud, Chris J. Maddison
PID Accelerated Value Iteration Algorithm
Amir-Massoud Farahmand, Mohammad Ghavamzadeh
Dueling Convex Optimization
Aadirupa Saha, Tomer Koren, Yishay Mansour
What Are Bayesian Neural Network Posteriors Really Like?
Pavel Izmailov, Sharad Vikram, Matthew D. Hoffman, Andrew Gordon Wilson
Offline Reinforcement Learning with Pseudometric Learning
Robert Dadashi, Shideh Rezaeifar, Nino Vieillard, Léonard Hussenot, Olivier Pietquin, Matthieu Geist
Revisiting Rainbow: Promoting More Insightful and Inclusive Deep Reinforcement Learning Research (see blog post)
Johan S. Obando-Ceron, Pablo Samuel Castro
EMaQ: Expected-Max Q-Learning Operator for Simple Yet Effective Offline and Online RL
Seyed Kamyar Seyed Ghasemipour*, Dale Schuurmans, Shixiang Shane Gu
Variational Data Assimilation with a Learned Inverse Observation Operator
Thomas Frerix, Dmitrii Kochkov, Jamie A. Smith, Daniel Cremers, Michael P. Brenner, Stephan Hoyer
Tilting the Playing Field: Dynamical Loss Functions for Machine Learning
Michael E. Sander, Pierre Ablin, Mathieu Blondel, Gabriel Peyré
Model-Based Reinforcement Learning via Latent-Space Collocation
Oleh Rybkin, Chuning Zhu, Anusha Nagabandi, Kostas Daniilidis, Igor Mordatch, Sergey Levine
Momentum Residual Neural Networks
Michael E. Sander, Pierre Ablin, Mathieu Blondel, Gabriel Peyré
OmniNet: Omnidirectional Representations from Transformers
Yi Tay, Mostafa Dehghani, Vamsi Aribandi, Jai Gupta, Philip Pham, Zhen Qin, Dara Bahri, Da-Cheng Juan, Donald Metzler
Synthesizer: Rethinking Self-Attention for Transformer Models
Yi Tay, Dara Bahri, Donald Metzler, Da-Cheng Juan, Zhe Zhao, Che Zheng
Towards Domain-Agnostic Contrastive Learning
Vikas Verma, Minh-Thang Luong, Kenji Kawaguchi, Hieu Pham, Quoc V. Le
Randomized Entity-wise Factorization for Multi-Agent Reinforcement Learning
Shariq Iqbal, Christian A. Schroeder de Witt, Bei Peng, Wendelin Böhmer, Shimon Whiteson, Fei Sha
LIME: Learning Inductive Bias for Primitives of Mathematical Reasoning
Yuhuai Wu, Markus Rabe, Wenda Li, Jimmy Ba, Roger Grosse, Christian Szegedy
Emergent Social Learning via Multi-agent Reinforcement Learning
Kamal Ndousse, Douglas Eck, Sergey Levine, Natasha Jaques
Improved Contrastive Divergence Training of Energy-Based Models
Yilun Du, Shuang Li, Joshua Tenenbaum, Igor Mordatch
Characterizing Structural Regularities of Labeled Data in Overparameterized Models
Ziheng Jiang*, Chiyuan Zhang, Kunal Talwar, Michael Mozer
Actionable Models: Unsupervised Offline Reinforcement Learning of Robotic Skills
Yevgen Chebotar, Karol Hausman, Yao Lu, Ted Xiao, Dmitry Kalashnikov, Jake Varley, Alex Irpan, Benjamin Eysenbach, Ryan Julian, Chelsea Finn, Sergey Levine
PsiPhi-Learning: Reinforcement Learning with Demonstrations using Successor Features and Inverse Temporal Difference Learning
Angelos Filos, Clare Lyle, Yarin Gal, Sergey Levine, Natasha Jaques, Gregory Farquhar
EfficientNetV2: Smaller Models and Faster Training
Mingxing Tan, Quoc V. Le
Unbiased Gradient Estimation in Unrolled Computation Graphs with Persistent Evolution Strategies
Paul Vicol, Luke Metz, Jascha Sohl-Dickstein
Federated Composite Optimization
Honglin Yuan*, Manzil Zaheer, Sashank Reddi
Light RUMs
Flavio Chierichetti, Ravi Kumar, Andrew Tomkins
Catformer: Designing Stable Transformers via Sensitivity Analysis
Jared Quincy Davis, Albert Gu, Krzysztof Choromanski, Tri Dao, Christopher Re, Chelsea Finn, Percy Liang
Representation Matters: Offline Pretraining for Sequential Decision Making
Mengjiao Yang, Ofir Nachum
Variational Empowerment as Representation Learning for Goal-Conditioned Reinforcement Learning
Jongwook Choi*, Archit Sharma*, Honglak Lee, Sergey Levine, Shixiang Shane Gu
Beyond Variance Reduction: Understanding the True Impact of Baselines on Policy Optimization
Wesley Chung, Valentin Thomas, Marlos C. Machado, Nicolas Le Roux
Whitening and Second Order Optimization Both Make Information in the Dataset Unusable During Training, and Can Reduce or Prevent Generalization
Neha S. Wadia, Daniel Duckworth, Samuel S. Schoenholz, Ethan Dyer, Jascha Sohl-Dickstein
Understanding Invariance via Feedforward Inversion of Discriminatively Trained Classifiers
Piotr Teterwak*, Chiyuan Zhang, Dilip Krishnan, Michael C. Mozer
Policy Information Capacity: Information-Theoretic Measure for Task Complexity in Deep Reinforcement Learning
Hiroki Furuta, Tatsuya Matsushima, Tadashi Kozuno, Yutaka Matsuo, Sergey Levine, Ofir Nachum, Shixiang Shane Gu
Hyperparameter Selection for Imitation Learning
Leonard Hussenot, Marcin Andrychowicz, Damien Vincent, Robert Dadashi, Anton Raichuk, Lukasz Stafiniak, Sertan Girgin, Raphael Marinier, Nikola Momchev, Sabela Ramos, Manu Orsini, Olivier Bachem, Matthieu Geist, Olivier Pietquin
Disentangling Sampling and Labeling Bias for Learning in Large-Output Spaces
Ankit Singh Rawat, Aditya Krishna Menon, Wittawat Jitkrittum, Sadeep Jayasumana, Felix X. Yu, Sashank J. Reddi, Sanjiv Kumar
Revenue-Incentive Tradeoffs in Dynamic Reserve Pricing
Yuan Deng, Sebastien Lahaie, Vahab Mirrokni, Song Zuo
Debiasing a First-Order Heuristic for Approximate Bi-Level Optimization
Valerii Likhosherstov, Xingyou Song, Krzysztof Choromanski, Jared Davis, Adrian Weller
Characterizing the Gap Between Actor-Critic and Policy Gradient
Junfeng Wen, Saurabh Kumar, Ramki Gummadi, Dale Schuurmans
Composing Normalizing Flows for Inverse Problems
Jay Whang, Erik Lindgren, Alexandros Dimakis
Online Policy Gradient for Model Free Learning of Linear Quadratic Regulators with √T Regret
Asaf Cassel, Tomer Koren
Learning to Price Against a Moving Target
Renato Paes Leme, Balasubramanian Sivan, Yifeng Teng, Pratik Worah
Fairness and Bias in Online Selection
Jose Correa, Andres Cristi, Paul Duetting, Ashkan Norouzi-Fard
The Impact of Record Linkage on Learning from Feature Partitioned Data
Richard Nock, Stephen Hardy, Wilko Henecka, Hamish Ivey-Law, Jakub Nabaglo, Giorgio Patrini, Guillaume Smith, Brian Thorne
Reserve Price Optimization for First Price Auctions in Display Advertising
Zhe Feng*, Sébastien Lahaie, Jon Schneider, Jinchao Ye
A Regret Minimization Approach to Iterative Learning Control
Naman Agarwal, Elad Hazan, Anirudha Majumdar, Karan Singh
A Statistical Perspective on Distillation
Aditya Krishna Menon, Ankit Singh Rawat, Sashank J. Reddi, Seungyeon Kim, Sanjiv Kumar
Best Model Identification: A Rested Bandit Formulation
Leonardo Cella, Massimiliano Pontil, Claudio Gentile
Generalised Lipschitz Regularisation Equals Distributional Robustness
Zac Cranko, Zhan Shi, Xinhua Zhang, Richard Nock, Simon Kornblith
Stochastic Multi-Armed Bandits with Unrestricted Delay Distributions
Tal Lancewicki, Shahar Segal, Tomer Koren, Yishay Mansour
Regularized Online Allocation Problems: Fairness and Beyond
Santiago Balseiro, Haihao Lu, Vahab Mirrokni
Implicit Rate-Constrained Optimization of Non-decomposable Objectives
Abhishek Kumar, Harikrishna Narasimhan, Andrew Cotter
Leveraging Non-uniformity in First-Order Non-Convex Optimization
Jincheng Mei, Yue Gao, Bo Dai, Csaba Szepesvari, Dale Schuurmans
Dynamic Balancing for Model Selection in Bandits and RL
Ashok Cutkosky, Christoph Dann, Abhimanyu Das, Claudio Gentile, Aldo Pacchiano, Manish Purohit
Adversarial Dueling Bandits
Aadirupa Saha, Tomer Koren, Yishay Mansour
Optimizing Black-Box Metrics with Iterative Example Weighting
Gaurush Hiranandani*, Jatin Mathur, Harikrishna Narasimhan, Mahdi Milani Fard, Oluwasanmi Koyejo
Relative Deviation Margin Bounds
Corinna Cortes, Mehryar Mohri, Ananda Theertha Suresh
MC-LSTM: Mass-Conserving LSTM
Pieter-Jan Hoedt, Frederik Kratzert, Daniel Klotz, Christina Halmich, Markus Holzleitner, Grey Nearing, Sepp Hochreiter, Günter Klambauer
12-Lead ECG Reconstruction via Koopman Operators
Authors:Tomer Golany, Kira Radinsky, Daniel Freedman, Saar Minha
Finding Relevant Information via a Discrete Fourier Expansion
Mohsen Heidari, Jithin Sreedharan, Gil Shamir, Wojciech Szpankowski
LEGO: Latent Execution-Guided Reasoning for Multi-Hop Question Answering on Knowledge Graphs
Hongyu Ren, Hanjun Dai, Bo Dai, Xinyun Chen, Michihiro Yasunaga, Haitian Sun, Dale Schuurmans, Jure Leskovec, Denny Zhou
SpreadsheetCoder: Formula Prediction from Semi-structured Context
Xinyun Chen, Petros Maniatis, Rishabh Singh, Charles Sutton, Hanjun Dai, Max Lin, Denny Zhou
Combinatorial Blocking Bandits with Stochastic Delays
Alexia Atsidakou, Orestis Papadigenopoulos, Soumya Basu, Constantine Caramani, Sanjay Shakkottai
Beyond log2(T) Regret for Decentralized Bandits in Matching Markets
Soumya Basu, Karthik Abinav Sankararaman, Abishek Sankararaman
Robust Pure Exploration in Linear Bandits with Limited Budget
Ayya Alieva, Ashok Cutkosky, Abhimanyu Das
Latent Programmer: Discrete Latent Codes for Program Synthesis
Joey Hong, David Dohan, Rishabh Singh, Charles Sutton, Manzil Zaheer
Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision (see blog post)
Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc V. Le, Yunhsuan Sung, Zhen Li, Tom Duerig
On Linear Identifiability of Learned Representations
Geoffrey Roeder, Luke Metz, Diederik P. Kingma
Hierarchical Clustering of Data Streams: Scalable Algorithms and Approximation Guarantees
Anand Rajagopalan, Fabio Vitale, Danny Vainstein, Gui Citovsky, Cecilia M Procopiuc, Claudio Gentile
Differentially Private Quantiles
Jennifer Gillenwater, Matthew Joseph, Alex Kulesza
Active Covering
Heinrich Jiang, Afshin Rostamizadeh
Sharf: Shape-Conditioned Radiance Fields from a Single View
Konstantinos Rematas, Ricardo Martin-Brualla, Vittorio Ferrari
Learning a Universal Template for Few-Shot Dataset Generalization
Eleni Triantafillou*, Hugo Larochelle, Richard Zemel, Vincent Dumoulin
Private Alternating Least Squares: Practical Private Matrix Completion with Tighter Rates
Steve Chien, Prateek Jain, Walid Krichene, Steffen Rendle, Shuang Song, Abhradeep Thakurta, Li Zhang
Differentially-Private Clustering of Easy Instances
Edith Cohen, Haim Kaplan, Yishay Mansour, Uri Stemmer, Eliad Tsfadia
Label-Only Membership Inference Attacks
Christopher A. Choquette-Choo, Florian Tramèr, Nicholas Carlini, Nicolas Papernot
Neural Feature Matching in Implicit 3D Representations
Yunlu Chen, Basura Fernando, Hakan Bilen, Thomas Mensink, Efstratios Gavves
Locally Private k-Means in One Round
Alisa Chang, Badih Ghazi, Ravi Kumar, Pasin Manurangsi
Large-Scale Meta-Learning with Continual Trajectory Shifting
Jaewoong Shin, Hae Beom Lee, Boqing Gong, Sung Ju Hwang
Statistical Estimation from Dependent Data
Vardis Kandiros, Yuval Dagan, Nishanth Dikkala, Surbhi Goel, Constantinos Daskalakis
Oneshot Differentially Private Top-k Selection
Gang Qiao, Weijie J. Su, Li Zhang
Unsupervised Part Representation by Flow Capsules
Sara Sabour, Andrea Tagliasacchi, Soroosh Yazdani, Geoffrey E. Hinton, David J. Fleet
Private Stochastic Convex Optimization: Optimal Rates in L1 Geometry
Hilal Asi, Vitaly Feldman, Tomer Koren, Kunal Talwar
Practical and Private (Deep) Learning Without Sampling or Shuffling
Peter Kairouz, Brendan McMahan, Shuang Song, Om Thakkar, Abhradeep Thakurta, Zheng Xu
Differentially Private Aggregation in the Shuffle Model: Almost Central Accuracy in Almost a Single Message
Badih Ghazi, Ravi Kumar, Pasin Manurangsi, Rasmus Pagh, Amer Sinha
Leveraging Public Data for Practical Private Query Release
Terrance Liu, Giuseppe Vietri, Thomas Steinke, Jonathan Ullman, Zhiwei Steven Wu
Meta-Thompson Sampling
Branislav Kveton, Mikhail Konobeev, Manzil Zaheer, Chih-wei Hsu, Martin Mladenov, Craig Boutilier, Csaba Szepesvári
Implicit-PDF: Non-Parametric Representation of Probability Distributions on the Rotation Manifold
Kieran A Murphy, Carlos Esteves, Varun Jampani, Srikumar Ramalingam, Ameesh Makadia
Improving Ultrametrics Embeddings Through Coresets
Vincent Cohen-Addad, Rémi de Joannis de Verclos, Guillaume Lagarde
A Discriminative Technique for Multiple-Source Adaptation
Corinna Cortes, Mehryar Mohri, Ananda Theertha Suresh, Ningshan Zhang
Self-Supervised and Supervised Joint Training for Resource-Rich Machine Translation
Yong Cheng, Wei Wang*, Lu Jiang, Wolfgang Macherey
Correlation Clustering in Constant Many Parallel Rounds
Vincent Cohen-Addad, Silvio Lattanzi, Slobodan Mitrović, Ashkan Norouzi-Fard, Nikos Parotsidis, Jakub Tarnawski
Hierarchical Agglomerative Graph Clustering in Nearly-Linear Time
Laxman Dhulipala, David Eisenstat, Jakub Łącki, Vahab Mirrokni, Jessica Shi
Meta-Learning Bidirectional Update Rules
Mark Sandler, Max Vladymyrov, Andrey Zhmoginov, Nolan Miller, Andrew Jackson, Tom Madams, Blaise Aguera y Arcas
Discretization Drift in Two-Player Games
Mihaela Rosca, Yan Wu, Benoit Dherin, David G.T. Barrett
Reasoning Over Virtual Knowledge Bases With Open Predicate Relations
Haitian Sun*, Pat Verga, Bhuwan Dhingra, Ruslan Salakhutdinov, William W. Cohen
Learn2Hop: Learned Optimization on Rough Landscapes
Amil Merchant, Luke Metz, Samuel Schoenholz, Ekin Cubuk
Locally Adaptive Label Smoothing Improves Predictive Churn
Dara Bahri, Heinrich Jiang
Overcoming Catastrophic Forgetting by Bayesian Generative Regularization
Patrick H. Chen, Wei Wei, Cho-jui Hsieh, Bo Dai
Workshops (only Google affiliations are noted)
LatinX in AI (LXAI) Research at ICML 2021
Hosts: Been Kim, Natasha Jaques
Uncertainty and Robustness in Deep Learning
Organizers: Balaji Lakshminarayanan, Jasper Snoek Invited Speaker: Dustin Tran
Reinforcement Learning for Real Life
Organizers: Minmin Chen, Lihong Li Invited Speaker: Ed Chi
Interpretable Machine Learning in Healthcare
Organizers: Alan Karthikesalingam Invited Speakers: Abhijit Guha Roy, Jim Winkens
The Neglected Assumptions in Causal Inference
Organizer: Alexander D’Amour
ICML Workshop on Algorithmic Recourse
Invited Speakers: Been Kim, Berk Ustun
A Blessing in Disguise: The Prospects and Perils of Adversarial Machine Learning
Invited Speaker: Nicholas Carlini
Overparameterization: Pitfalls and Opportunities
Organizers: Yasaman Bahri, Hanie Sedghi
Information-Theoretic Methods for Rigorous, Responsible, and Reliable Machine Learning (ITR3)
Invited Speaker: Thomas Steinke
Beyond First-Order Methods in Machine Learning Systems
Invited Speaker: Courtney Paquette
ICML 2021 Workshop: Self-Supervised Learning for Reasoning and Perception
Invited Speaker: Chelsea Finn
Workshop on Reinforcement Learning Theory
Invited Speaker: Bo Dai
Tutorials (only Google affiliations are noted)
Responsible AI in Industry: Practical Challenges and Lessons Learned
Organizers: Ben Packer
Online and Non-stochastic Control
Organizers: Elad Hazan
Random Matrix Theory and ML (RMT +ML)
Organizers: Fabian Pedregosa, Jeffrey Pennington, Courntey Paquette Self-Attention for Computer Vision Organizers: Prajit Ramachandran, Ashish Vaswani
* Indicates work done while at Google

 A new session from GTC shares how to use synthetic data and Fleet Command to deploy highly accurate and scalable models.
A new session from GTC shares how to use synthetic data and Fleet Command to deploy highly accurate and scalable models.
The retail supply chain is complex and includes everything from creating a product, distributing it, putting it on shelves in stores, to getting it into customer hands. Retailers and Consumer Packaged Goods (CPG) companies must look at the entire supply chain for critical gaps and problems that can be solved with technology and automation. Computer vision has been implemented by many of these companies for years, with cameras distributed in their stores, warehouses, and on assembly lines. This is where edge computing comes in, AI applications can be run in remote locations that allow companies to turn these cameras from sources of information to sources of intelligence. With AI, these cameras can turn from sources of information to sources of intelligence. Whether providing in-store analytics to help evaluate traffic patterns and optimize product placement, to improving packaging detection and analysis, and overall health and safety within warehouses.
The challenge with computer vision applications in the retail space is the heavy data requirement that is needed to ensure AI models are accurate and safe. Once trained, these models then need to be deployed to many locations at the edge, often without the IT resources onsite. Kinetic Vision has partnered with NVIDIA to develop a new solution to this problem that allows retailers and CPG companies to generate accurate models, and scale them out at the edge.
Solving the challenge of data is key to enabling the training of AI models using NVIDIA tools like the DeepStream SDK and Transfer Learning Toolkit (TLT). With a Synthetic Data Generator, Kinetic Vision not only produces data volume, but also with the required variances to ensure the model will perform in any environment. Numerous angles, lighting, backgrounds, and product types can be generated quickly and easily using different methods including GANs, simulated sensor data (LIDAR, RADAR, IMU), photorealistic 3D environment, synthetic x-rays, and physics simulations.

The synthetic data is then used to train a model that can be tested in a digital twin, a virtual representation of the warehouse, supply line, store, or whatever environment the model will be deployed. Using the synthetic data and the digital twin, Kinetic Vision can train, simulate, and re-train the model to achieve the required level of accuracy.
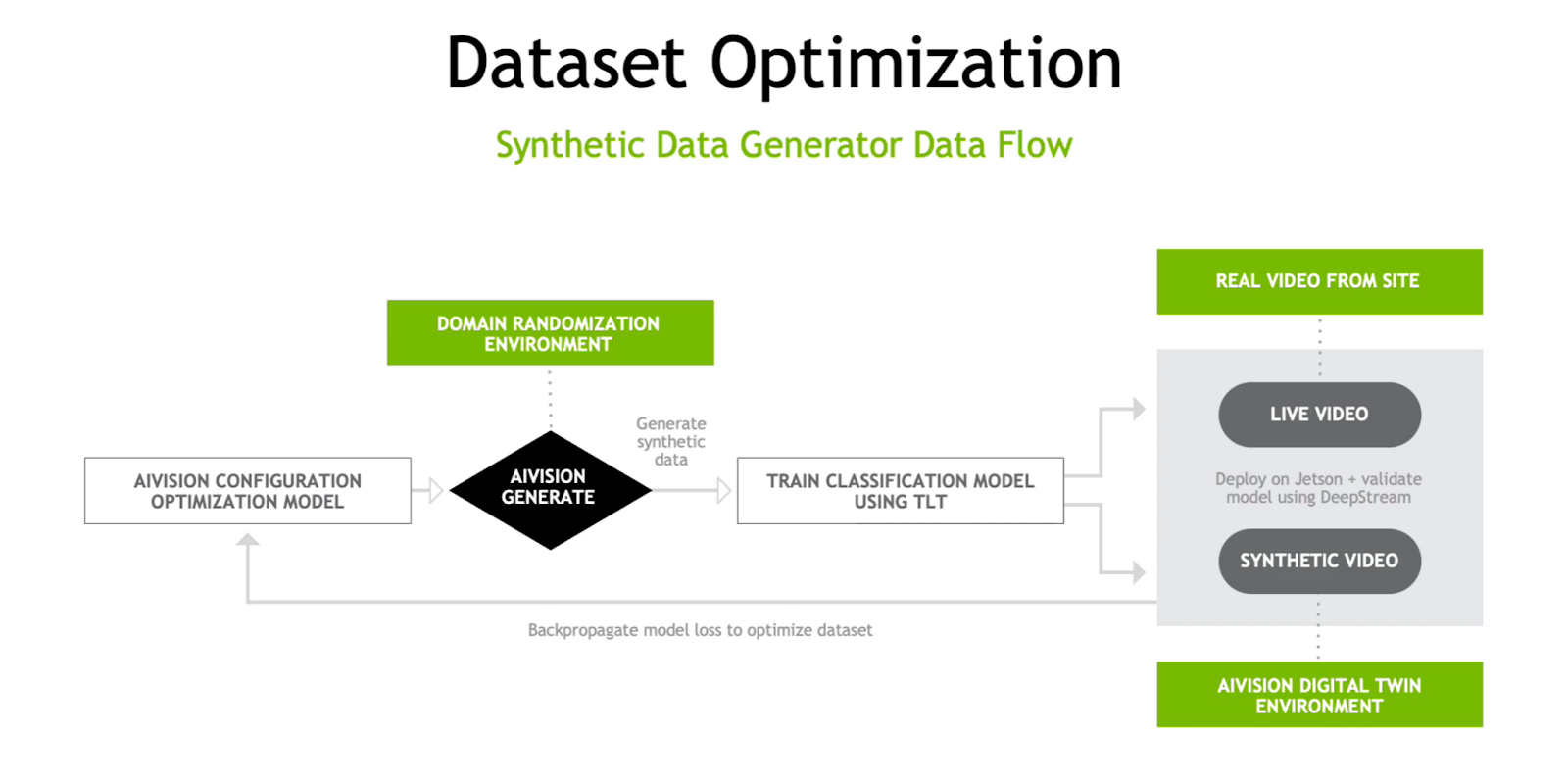
Once the AI model has achieved the desired level of performance, it must be tested in the real world. This is where NVIDIA Fleet Command comes in. Fleet Command is a hybrid-cloud platform for deploying and managing AI models at the edge. The pre-trained model is simply loaded into the NGC catalog and then deployed on the edge system using the Fleet Command UI in just a few clicks. Once deployed at the edge, the model can continue to be optimized with real world data sent back from the store or warehouse. These updates are once again easily deployed and managed using Fleet Command.
The advantages of this new approach to creating retail computer vision applications include both ROI and technological benefits. The cost of developing an AI model with a digital twin is easily 10 percent the time and cost required to do the same thing in a physical environment. With the digital twin, testing can be done without physical infrastructure or requiring production interruptions. Additionally, new products and product variations can be easily accommodated without requiring inventory photography that must be manually annotated. Finally, the digital twin results in a generalized and scalable model that still provides the accuracy required for production deployment.
To learn more about how to use synthetic data and Fleet Command to deploy highly accurate and scalable models, check out the GTC session “Novel Approach to Deploy Highly Accurate AI Retail Computer Vision Applications at the Edge“.
 ‘Meet the Researcher’ is a series in which we spotlight different researchers in academia who use NVIDIA technologies to accelerate their work. This month we spotlight Dr. Emanuel Gull, Associate Professor of Physics at University of Michigan, whose research focuses on the development of theoretical and computational methods for strongly correlated quantum systems. Gull is … Continued
‘Meet the Researcher’ is a series in which we spotlight different researchers in academia who use NVIDIA technologies to accelerate their work. This month we spotlight Dr. Emanuel Gull, Associate Professor of Physics at University of Michigan, whose research focuses on the development of theoretical and computational methods for strongly correlated quantum systems. Gull is … Continued
‘Meet the Researcher’ is a series in which we spotlight different researchers in academia who use NVIDIA technologies to accelerate their work.
This month we spotlight Dr. Emanuel Gull, Associate Professor of Physics at University of Michigan, whose research focuses on the development of theoretical and computational methods for strongly correlated quantum systems.
Gull is the recipient of a Sloan Research Fellow, Ralph E. Powe Junior Faculty Enhancement Award, DOE Early Career Research Award, SCES early career Nevill F. Mott Prize, and APS Outstanding Referee Program.
What are your research areas?
The physics of materials in which many quantum particles strongly interact with each other. These are the systems out of which we build our newest generation of magnets, superconductors, solar cells, and systems for standard approximative methods.
When did you know that you wanted to be a researcher and pursue this field?
I was always open to having a career in the software/computing side of industry/finance — but, when I had to decide whether to go for a postdoc, the financial crisis hit. Instead, I did a postdoc in the U.S. and managed to get hired into an academic position afterwards.
What motivated you to pursue your recent research area of focus?
‘Quantum’ theory is the reason why many of our recent technological breakthroughs work. After all, NVIDIA chips are just an application of quantum theory. However, taking just theory and predicting and improving material properties without further input is incredibly difficult, even though we believe we understand the theory very well. I have always been fascinated by the challenge of combining computers and theoretical methods to bring calculations closer to reality. This started with an internship I did at a high performance computer center back when I was a high school student.
What problems or challenges does your research address?
While we know the equations that govern the physics of systems with many interacting quantum particles well, they are impossibly difficult to solve. This is why we need to find approximations that are both numerically tractable and accurate. My research spans the entire gamut from theoretical derivations, to implementation of new algorithms, to HPC, to comparisons with experiments. All of my research aims to make quantum theories more predictive and more accurate.
What challenges did you face during the research process, and how did you overcome them?
Time management is probably the most crucial. It’s easy to have many ideas, but testing them, improving upon them, and revising them takes time. In research, you’re constantly juggling finding resources, training people, having and revising ideas, publishing, going to conferences, etc. Finding quiet intervals to work deeply on a problem is essential, but difficult. I don’t believe I’ve overcome that limitation.
What is the impact of your work on the field/community/world?
Stronger magnets, higher temperature superconductors, and better materials for sensors and chips.
How have you used NVIDIA technology either in your current or previous research?
Yes! In fact, our home-written ab-initio simulation toolkit uses NVIDIA codes to simulate the physics of real materials and their excitations. Most of our calculations would be either impossible or borderline without the NVIDIA fast and double-precision arithmetics on the V100 and A100. Our codes run at just about 50% of theoretical peak flop, and are parallelized with streams within each GPU and with MPI between different GPUs and nodes.
What research breakthroughs or interesting results can you share?
We did, and we’re just now writing a paper on a new high-temperature superconductor.
What’s next for your research?
We’re currently doing a big push for driving systems out of equilibrium. We’re exciting them with a laser, ‘quenching’ them with a short current pulse, or probing them in other nonequilibrium conditions. The nonequilibrium physics of quantum materials is very different from the equilibrium conditions, and many exciting new phenomena appear. Besides, most sensors work out of equilibrium. How to generalize our computational toolkit to these situations is currently an open question that we’re working on.
Any advice for new researchers, especially to those who are inspired and motivated by your work?
Ask the big questions. Why is this interesting? Why will it work or how will it not work? What have we learned if it does work? But, don’t lose sight of the small details. Pounce at the details that don’t quite make sense, that’s where there’s something that needs to be understood. When something turns into a dead end, learn to let it go (even if you’ve invested a lot of resources into it).
Also, know the established ways of thinking about a problem, but question them always. Know the limitations of your tools and theories, and invest in your toolkit. New tools (computer codes, theoretical methods, experimental setups) lead to new discoveries, so make sure you have the best ones available for your application.
A pair of new demos running GeForce RTX technologies on the Arm platform unveiled by NVIDIA today show how advanced graphics can be extended to a broader, more power-efficient set of devices. The two demos, shown at this week’s Game Developers Conference, included Wolfenstein: Youngblood from Bethesda Softworks and MachineGames, as well as The Bistro Read article >
The post Arm Is RTX ON! World’s Most Widely Used CPU Architecture Meets Real-Time Ray Tracing, DLSS appeared first on The Official NVIDIA Blog.