Episode 5 of the NVIDIA CUDA Tutorials Video series is out. Jackson Marusarz, product manager for Compute Developer Tools at NVIDIA, introduces a suite of tools…
Episode 5 of the NVIDIA CUDA Tutorials Video series is out. Jackson Marusarz, product manager for Compute Developer Tools at NVIDIA, introduces a suite of tools to help you build, debug, and optimize CUDA applications, making development easy and more efficient.
System-wide insights:NVIDIA Nsight Systems provides system-wide performance insights, visualization of CPU processes, GPU streams, and resource bottlenecks. It also traces APIs and libraries, helping developers locate optimization opportunities.
CUDA kernel profiling:NVIDIA Nsight Compute enables detailed analysis of CUDA kernel performance. It collects hardware and software counters and uses a built-in expert system for issue detection and performance analysis.
Episode 5 of the NVIDIA CUDA Tutorials Video series is out. Jackson Marusarz, product manager for Compute Developer Tools at NVIDIA, introduces a suite of tools to help you build, debug, and optimize CUDA applications, making development easy and more efficient.
Learn about key features for each tool, and discover the best fit for your needs.
Each year, nearly 32 million people travel through the Bengaluru Airport, or BLR, one of the busiest airports in the world’s most populous nation. To provide such multitudes with a safer, quicker experience, the airport in the city formerly known as Bangalore is tapping vision AI technologies powered by Industry.AI. A member of the NVIDIA Read article >
In the global entertainment landscape, TV show and film production stretches far beyond Hollywood or Bollywood — it’s a worldwide phenomenon. However, while streaming platforms have broadened the reach of content, dubbing and translation technology still has plenty of room for growth. Deepdub acts as a digital bridge, providing access to content by using generative Read article >
Posted by Yujin Tang and Wenhao Yu, Research Scientists, Google
Simple and effective interaction between human and quadrupedal robots paves the way towards creating intelligent and capable helper robots, forging a future where technology enhances our lives in ways beyond our imagination. Key to such human-robot interaction systems is enabling quadrupedal robots to respond to natural language instructions. Recent developments in large language models (LLMs) have demonstrated the potential to perform high-level planning. Yet, it remains a challenge for LLMs to comprehend low-level commands, such as joint angle targets or motor torques, especially for inherently unstable legged robots, necessitating high-frequency control signals. Consequently, most existingwork presumes the provision of high-level APIs for LLMs to dictate robot behavior, inherently limiting the system’s expressive capabilities.
In “SayTap: Language to Quadrupedal Locomotion”, we propose an approach that uses foot contact patterns (which refer to the sequence and manner in which a four-legged agent places its feet on the ground while moving) as an interface to bridge human commands in natural language and a locomotion controller that outputs low-level commands. This results in an interactive quadrupedal robot system that allows users to flexibly craft diverse locomotion behaviors (e.g., a user can ask the robot to walk, run, jump or make other movements using simple language). We contribute an LLM prompt design, a reward function, and a method to expose the SayTap controller to the feasible distribution of contact patterns. We demonstrate that SayTap is a controller capable of achieving diverse locomotion patterns that can be transferred to real robot hardware.
SayTap method
The SayTap approach uses a contact pattern template, which is a 4 X T matrix of 0s and 1s, with 0s representing an agent’s feet in the air and 1s for feet on the ground. From top to bottom, each row in the matrix gives the foot contact patterns of the front left (FL), front right (FR), rear left (RL) and rear right (RR) feet. SayTap’s control frequency is 50 Hz, so each 0 or 1 lasts 0.02 seconds. In this work, a desired foot contact pattern is defined by a cyclic sliding window of size Lw and of shape 4 X Lw. The sliding window extracts from the contact pattern template four foot ground contact flags, which indicate if a foot is on the ground or in the air between t + 1 and t + Lw. The figure below provides an overview of the SayTap method.
SayTap introduces these desired foot contact patterns as a new interface between natural language user commands and the locomotion controller. The locomotion controller is used to complete the main task (e.g., following specified velocities) and to place the robot’s feet on the ground at the specified time, such that the realized foot contact patterns are as close to the desired contact patterns as possible. To achieve this, the locomotion controller takes the desired foot contact pattern at each time step as its input in addition to the robot’s proprioceptive sensory data (e.g., joint positions and velocities) and task-related inputs (e.g., user-specified velocity commands). We use deep reinforcement learning to train the locomotion controller and represent it as a deep neural network. During controller training, a random generator samples the desired foot contact patterns, the policy is then optimized to output low-level robot actions to achieve the desired foot contact pattern. Then at test time a LLM translates user commands into foot contact patterns.
SayTap approach overview.
SayTap uses foot contact patterns (e.g., 0 and 1 sequences for each foot in the inset, where 0s are foot in the air and 1s are foot on the ground) as an interface that bridges natural language user commands and low-level control commands. With a reinforcement learning-based locomotion controller that is trained to realize the desired contact patterns, SayTap allows a quadrupedal robot to take both simple and direct instructions (e.g., “Trot forward slowly.”) as well as vague user commands (e.g., “Good news, we are going to a picnic this weekend!”) and react accordingly.
We demonstrate that the LLM is capable of accurately mapping user commands into foot contact pattern templates in specified formats when given properly designed prompts, even in cases when the commands are unstructured or vague. In training, we use a random pattern generator to produce contact pattern templates that are of various pattern lengths T, foot-ground contact ratios within a cycle based on a given gait type G, so that the locomotion controller gets to learn on a wide distribution of movements leading to better generalization. See the paper for more details.
Results
With a simple prompt that contains only three in-context examples of commonly seen foot contact patterns, an LLM can translate various human commands accurately into contact patterns and even generalize to those that do not explicitly specify how the robot should react.
SayTap prompts are concise and consist of four components: (1) general instruction that describes the tasks the LLM should accomplish; (2) gait definition that reminds the LLM of basic knowledge about quadrupedal gaits and how they can be related to emotions; (3) output format definition; and (4) examples that give the LLM chances to learn in-context. We also specify five velocities that allow a robot to move forward or backward, fast or slow, or remain still.
General instruction block
You are a dog foot contact pattern expert.
Your job is to give a velocity and a foot contact pattern based on the input.
You will always give the output in the correct format no matter what the input is.
Gait definition block
The following are description about gaits:
1. Trotting is a gait where two diagonally opposite legs strike the ground at the same time.
2. Pacing is a gait where the two legs on the left/right side of the body strike the ground at the same time.
3. Bounding is a gait where the two front/rear legs strike the ground at the same time. It has a longer suspension phase where all feet are off the ground, for example, for at least 25% of the cycle length. This gait also gives a happy feeling.
Output format definition block
The following are rules for describing the velocity and foot contact patterns:
1. You should first output the velocity, then the foot contact pattern.
2. There are five velocities to choose from: [-1.0, -0.5, 0.0, 0.5, 1.0].
3. A pattern has 4 lines, each of which represents the foot contact pattern of a leg.
4. Each line has a label. "FL" is front left leg, "FR" is front right leg, "RL" is rear left leg, and "RR" is rear right leg.
5. In each line, "0" represents foot in the air, "1" represents foot on the ground.
Example block
Input: Trot slowly
Output: 0.5
FL: 11111111111111111000000000
FR: 00000000011111111111111111
RL: 00000000011111111111111111
RR: 11111111111111111000000000
Input: Bound in place
Output: 0.0
FL: 11111111111100000000000000
FR: 11111111111100000000000000
RL: 00000011111111111100000000
RR: 00000011111111111100000000
Input: Pace backward fast
Output: -1.0
FL: 11111111100001111111110000
FR: 00001111111110000111111111
RL: 11111111100001111111110000
RR: 00001111111110000111111111
Input:
SayTap prompt to the LLM. Texts in blue are used for illustration and are not input to LLM.
Following simple and direct commands
We demonstrate in the videos below that the SayTap system can successfully perform tasks where the commands are direct and clear. Although some commands are not covered by the three in-context examples, we are able to guide the LLM to express its internal knowledge from the pre-training phase via the “Gait definition block” (see the second block in our prompt above) in the prompt.
Following unstructured or vague commands
But what is more interesting is SayTap’s ability to process unstructured and vague instructions. With only a little hint in the prompt to connect certain gaits with general impressions of emotions, the robot bounds up and down when hearing exciting messages, like “We are going to a picnic!” Furthermore, it also presents the scenes accurately (e.g., moving quickly with its feet barely touching the ground when told the ground is very hot).
Conclusion and future work
We present SayTap, an interactive system for quadrupedal robots that allows users to flexibly craft diverse locomotion behaviors. SayTap introduces desired foot contact patterns as a new interface between natural language and the low-level controller. This new interface is straightforward and flexible, moreover, it allows a robot to follow both direct instructions and commands that do not explicitly state how the robot should react.
One interesting direction for future work is to test if commands that imply a specific feeling will allow the LLM to output a desired gait. In the gait definition block shown in the results section above, we provide a sentence that connects a happy mood with bounding gaits. We believe that providing more information can augment the LLM’s interpretations (e.g., implied feelings). In our evaluation, the connection between a happy feeling and a bounding gait led the robot to act vividly when following vague human commands. Another interesting direction for future work is to introduce multi-modal inputs, such as videos and audio. Foot contact patterns translated from those signals will, in theory, still work with our pipeline and will unlock many more interesting use cases.
Acknowledgements
Yujin Tang, Wenhao Yu, Jie Tan, Heiga Zen, Aleksandra Faust and Tatsuya Harada conducted this research. This work was conceived and performed while the team was in Google Research and will be continued at Google DeepMind. The authors would like to thank Tingnan Zhang, Linda Luu, Kuang-Huei Lee, Vincent Vanhoucke and Douglas Eck for their valuable discussions and technical support in the experiments.
Dramatic gains in hardware performance have spawned generative AI, and a rich pipeline of ideas for future speedups that will drive machine learning to new heights, Bill Dally, NVIDIA’s chief scientist and senior vice president of research, said today in a keynote. Dally described a basket of techniques in the works — some already showing Read article >
NVIDIA DOCA SDK and acceleration framework empowers developers with extensive libraries, drivers, and APIs to create high-performance applications and services…
NVIDIA DOCA SDK and acceleration framework empowers developers with extensive libraries, drivers, and APIs to create high-performance applications and services for NVIDIA BlueField DPUs and ConnectX SmartNICs. It fuels data center innovation, enabling rapid application deployment.
With comprehensive features, NVIDIA DOCA serves as a one-stop-shop for BlueField developers looking to accelerate data center workloads and AI applications at scale.
With over 10,000 developers already benefiting, NVIDIA DOCA is now generally available, granting access to a broader developer community to leverage the BlueField DPU platform for innovative AI and cloud services.
New NVIDIA DOCA 2.2 features and enhancements
NVIDIA DOCA 2.2 introduces new features and enhancements for offloading, accelerating, and isolating network, storage, security, and management infrastructure within the data center.
Video 1. Watch an introduction to NVIDIA DOCA software framework
Programmability
The NVIDIA BlueField-3 DPU—in conjunction with its onboard, purpose-built data path accelerator (DPA) and the DOCA SDK framework—offers an unparalleled platform. It is now available for developers to create high-performance and scalable network applications that demand high throughput and low latency.
Data path accelerator
NVIDIA DOCA 2.2 delivers several enhancements to leverage the BlueField-3 DPA programming subsystem. DOCA DPA, a new compute subsystem part of the DOCA SDK package, offers a programming model for offloading communication-centric user code to run on the DPA processor. DOCA DPA helps to offload the CPU traffic and increase the performance through DPU acceleration.
Figure 1. NVIDIA BlueField-3 DPU incoming and outgoing traffic
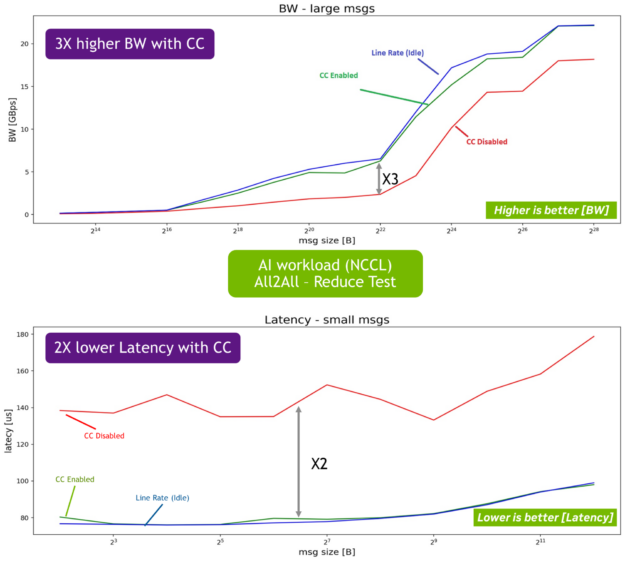
DOCA DPA also offers significant development benefits, including greater flexibility when creating custom emulations and congestion controls. Customized congestion control is critical for AI workflows, enabling performance isolation, improving fairness, and preventing packet drop on lossy networks.
The DOCA 2.2 release introduces the following SDKs:
DOCA-FlexIO: A low-level SDK for DPA programming. Specifically, the DOCA FlexIO driver exposes the API for managing and running code over the DPA.
DOCA-PCC: An SDK for congestion-control development that enables CSP and enterprise customers to create their own congestion control algorithms to increase stability and efficient network operations through higher bandwidth and lower latency.
NVIDIA also supplies the necessary toolchains, examples, and collateral to expedite and support development efforts. Note that NVIDIA DOCA DPA is available in both DPU mode and NIC mode.
Figure 2. DOCA-PCC offers higher bandwidth and lower latency
Networking
NVIDIA DOCA and the BlueField-3 DPU together enable the development of applications that deliver breakthrough networking performance with a comprehensive, open development platform. Including a range of drivers, libraries, tools, and example applications, NVIDIA DOCA continues to evolve. This release offers the following additional features to support the development of networking applications.
NVIDIA DOCA Flow
With NVIDIA DOCA Flow, you can define and control the flow of network traffic, implement network policies, and manage network resources programmatically. It offers network virtualization, telemetry, load balancing, security enforcement, and traffic monitoring. These capabilities are beneficial for processing high packet workloads with low latency, conserving CPU resources and reducing power usage.
This release includes the following new features that offer immediate benefits to cloud deployments:
Support for tunnel offloads – GENEVE and GRE: Offering enhanced security, visibility, scalability, flexibility, and extensibility, are the building blocks for site communication, network isolation, and multi-tenancy. Specifically, GRE tunnels used to connect separate networks and establish secure VPN communication support overlay networks, offer protocol flexibility, and enable traffic engineering.
Support per-flow meter with bps/pps option: Essential in cloud environments to monitor/analyze traffic (measure bandwidth or packet rate), manage QoS (enforce limits), or enhance security (block denial-of-service attacks).
Enhanced mirror capability (FDB/switch domain): Used for monitoring, troubleshooting, security analysis, and performance optimization, this added functionality also provides better CPU utilization for mirrored workloads.
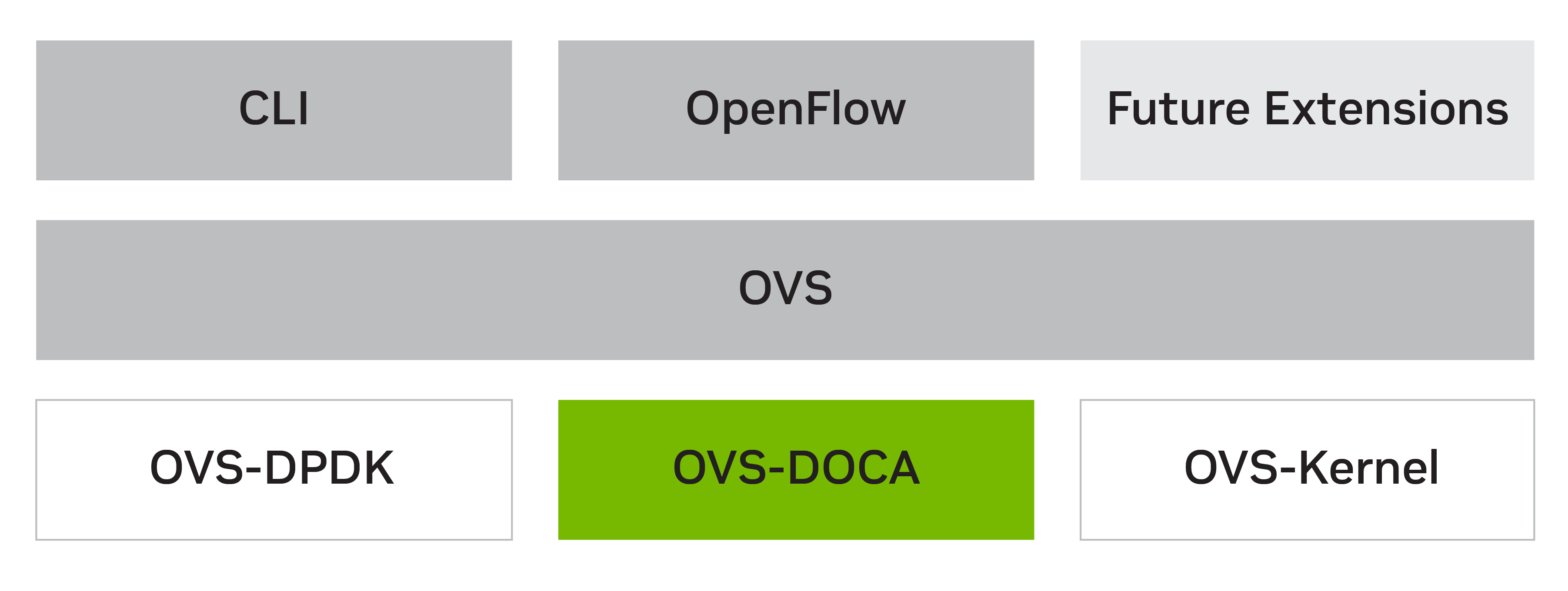
OVS-DOCA (Beta)
OVS-DOCA is a highly optimized virtual switch for NVIDIA Network Services. An extremely efficient design promotes next-generation performance and scale through an NVIDIA NIC or DPU. OVS-DOCA is now available in DOCA for DPU and DOCA for Host (binaries and source).
Figure 3. OVS-DOCA optimized for NVIDIA network services
Based on Open vSwitch, OVS-DOCA offers the same northbound API, OpenFlow, CLI, and data interface, providing a drop-in replacement alternative to OVS. Using OVS-DOCA enables faster implementation of future NVIDIA innovative networking features.
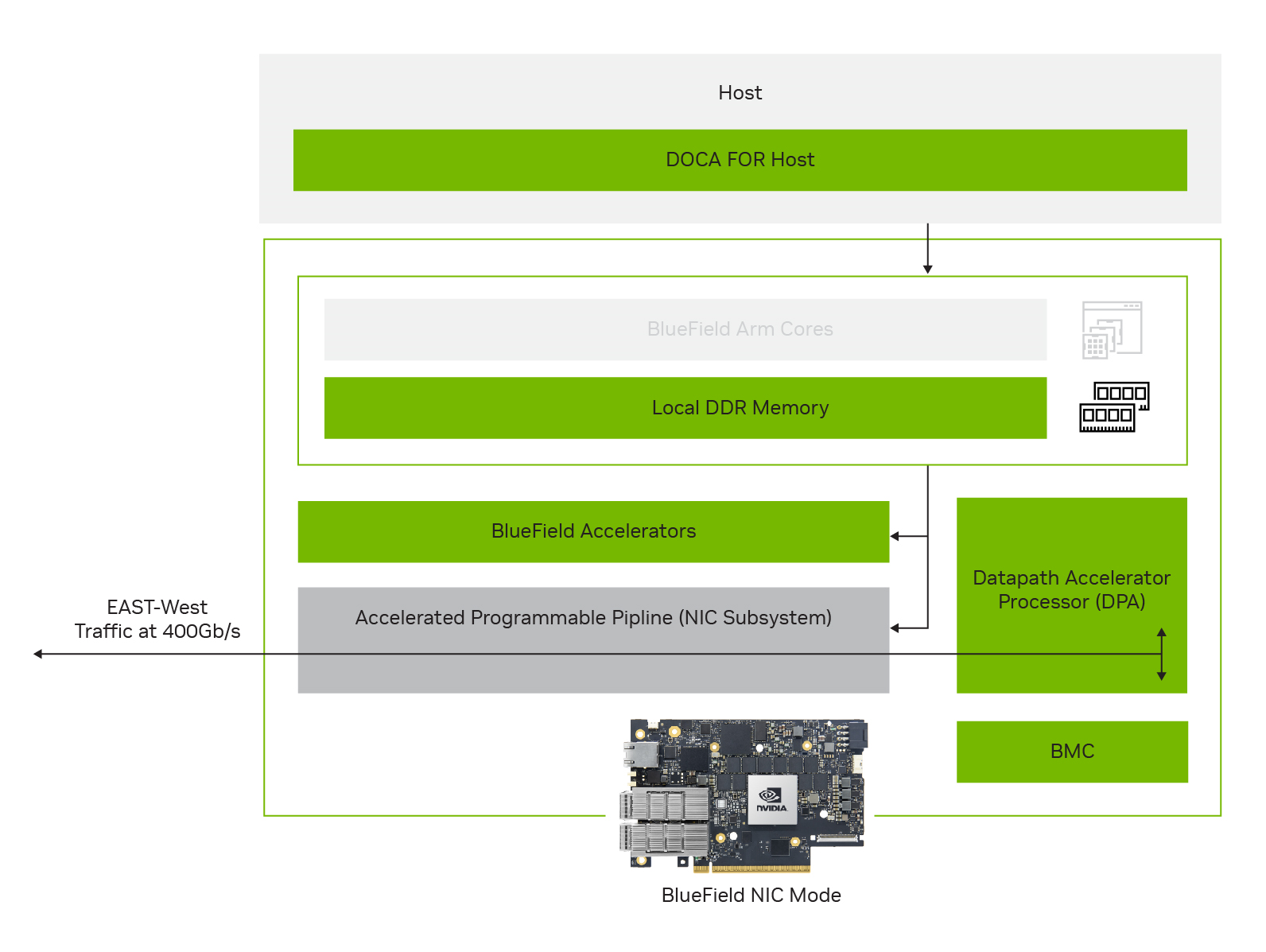
BlueField-3 (enhanced) NIC mode (Beta)
This release benefits from an enhanced BlueField-3 NIC mode, currently in Beta. In contrast to BlueField-3 DPU mode, where offloading, acceleration, and isolation are all available, BlueField-3 NIC mode only offers acceleration features.
Figure 4. BlueField-3 (enhanced) NIC mode
While continuing to leverage the BlueField low power and lower compute-intensive SKUs, the enhanced BlueField-3 NIC mode offers many advantages over the current ConnectX BlueField-2 NIC mode, including:
Higher performance and lower latency at scale using local DPU memory
Performant RDMA with Programmable Congestion Control (PCC)
Programmability with DPA and additional BlueField accelerators
Robust platform security with device attestation and on-card BMC
Note that BlueField-3 NIC mode will be productized as a software mode, not a separate SKU, to enable future DPU-mode usage. As such, BlueField-3 NIC mode is a fully supported software feature available on all BlueField-3 SKUs. DPA programmability for any BlueField-3 DPU operating in NIC mode mandates the installation of DOCA on the host and an active host-based service.
Services
NVIDIA DOCA services are containerized DOCA-based programs that provide an end-to-end solution for a given use case. These services are accessible through NVIDIA NGC, from which they can be easily deployed directly to the DPU. DOCA 2.2 gives you greater control and now enables offline installation of DOCA services.
NGC offline service installation
DOCA services installed from NGC require Internet connectivity. However, many customers operate in a secure production environment without Internet access. Providing the option for ‘nonconnected’ deployment enables service installation in a fully secure production environment, simplifying the process and avoiding the already unlikely scenario whereby each server would need a connection to complete the installation process.
For example, consider the installation of DOCA Telemetry Service (DTS) in a production environment to support metrics collection. The full installation process is completed in just two steps:
Step 1: NGC download on connected server
Step 2: Offline installation using internal secure delivery
Summary
NVIDIA DOCA 2.2 plays a pivotal and indispensable role in driving data center innovation and transforming cloud and enterprise data center networks for AI applications. By providing a comprehensive SDK and acceleration framework for BlueField DPUs, DOCA empowers developers with powerful libraries, drivers, and APIs, enabling the creation of high-performance applications and services.
With several new features and enhancements to DOCA 2.2, a number of immediate gains are available. In addition to the performance gains realized through DPU acceleration, the inclusion of DOCA-FlexIO and DOCA-PCC SDK offers developers accelerated computing for AI-centric benefits. These SDKs enable the creation of custom emulations and algorithms, reducing the time to market, and significantly improving the overall development experience.
Additionally, networking-specific updates to NVIDIA DOCA FLOW and OVS-DOCA offer simplified delivery pathways for software-defined networking and security solutions. These features increase efficiency and enhance visibility, scalability, and flexibility, essential for building sophisticated and secure infrastructures.
With wide-ranging contributions to data center innovation, AI application acceleration, and robust network infrastructure, DOCA is a crucial component of NVIDIA AI cloud services. As the industry moves towards more complex and demanding computing requirements, the continuous evolution of DOCA and integration with cutting-edge technologies will further solidify its position as a trailblazing platform for empowering the future of data centers and AI-driven solutions.
Download NVIDIA DOCA to begin your development journey with all the benefits DOCA has to offer. For more information, see the following resources:
NVIDIA is driving fast-paced innovation in 5G software and hardware across the ecosystem with its OpenRAN-compatible 5G portfolio. Accelerated computing…
NVIDIA is driving fast-paced innovation in 5G software and hardware across the ecosystem with its OpenRAN-compatible 5G portfolio. Accelerated computing hardware and NVIDIA Aerial 5G software are delivering solutions for key industry stakeholders such as telcos, cloud service providers (CSPs), enterprises, and academic researchers.
The awards showcase the deepening capabilities of the NVIDIA 5G ecosystem and illustrate how NVIDIA is helping the ecosystem to address particular market challenges. In particular, two key contributions stand out. First, the MGX with GH200 superchip delivers the most modular and ready-to-deploy accelerated computing solution for generative AI and 5G, driving ROI for telcos and CSPs. Second, Aerial Research Cloud offers the research community the most powerful, yet fully open, platform to do groundbreaking 5G+ and 6G research.
MGX with GH200: generative AI and 5G on NVIDIA accelerated cloud
The MGX with GH200 superchip features the NVIDIA GH200, which combines the NVIDIA Grace CPU and the NVIDIA H100 Tensor Core GPU with NVLink Chip-to-Chip in a single superchip in the MGX Reference Design (Figure 1). This combination can be used for a wide variety of use cases, from generative AI to 5G, with NVIDIA Aerial software at the edge and cloud.
The MGX with GH200 includes the NVIDIA BlueField-3 Data Processing Unit (DPU) targeted at telcos and CSPs. This enables them to deploy secure and accelerated computing platforms to run both generative AI and 5G for improving ROI and reducing TTM.
BlueField-3 inclusion in MGX enables crucial capabilities including accelerated VPC networking, zero-trust security, composable storage, and elastic GPU computing. Additionally, the NVIDIA Spectrum Ethernet switch with BlueField-3 DPU delivers a highly precise timing protocol for 5G as well as optimized routing for demanding AI workloads.
“The MGX with GH200-based generative AI and 5G data center platform is designed to improve the performance, scalability, and automated resource utilization of AI, 5G, and other telco-specific workloads from the edge to the cloud. This innovative solution will greatly benefit telcos who can leverage their space, power, and network connectivity to become AI factories of the future,” says Ronnie Vasishta, senior vice president for telecoms at NVIDIA.
Thanks to the GH200, the MGX server delivers one cloud platform for 5G and generative AI. This combination enables telcos and CSPs to maximize using their compute infrastructure by running 5G and generative AI interchangeably, boosting ROI significantly compared to a single-purpose 5G RAN infrastructure.
Figure 1. The MGX with GH200 and BlueField architecture
At COMPUTEX 2023, NVIDIA announced that it is collaborating with Softbank on a pioneering platform for generative AI and 5G/6G applications based on MGX with GH200. SoftBank plans to roll it out at new, distributed AI data centers across Japan.
NVIDIA Aerial Research Cloud: accelerated computing for 5G+ and 6G research
Aerial Research Cloud provides developers, researchers, operators, and network equipment providers with all the requisite components to deploy a campus network for research. It is delivered in collaboration with the Open Air Alliance (OIA) enabling researchers to do groundbreaking work on 5G+ and 6G. In the last 6 months, three partners have launched networks based on the platform, with more in progress.
“Aerial Research Cloud is targeted at research and innovation use cases. It offers a fully featured, and the industry’s first open, software-defined, programmable (in C), ML-ready performant cloud service for wireless research,” said Vasishta.
Figure 2 features a 3GPP release 15 compliant solution which is operational over-the-air, and an O-RAN 7.2 split campus 5G SA 4T4R wireless stack, with all network elements from the radio access network and 5G core. It is based on NVIDIA Aerial SDK Layer 1, which is integrated with OAI’s distributed unit, centralized unit, or 5G NR gNB and 5G core node network elements.
Figure 2. The Aerial Research Cloud (ARC) setup example configuration
Aerial Research Cloud also supports developer onboarding and algorithm development in real-time wireless networks. It uses a blueprint to ease onboarding, staging, and integrating 5G Advanced network components and verification steps through bi-directional UDP traffic. Lastly, it provides complete access to source code in C/C++, to jump-start customizations and next-generation wireless algorithm research.
What’s next
TMCnet’s award recognizes how NVIDIA is shaping the future of 5G and the OpenRAN community. The MGX with the GH200 platform is uniquely positioned to support the AI-driven innovation that will be essential for 6G networks. OpenRAN and other telco workloads benefit greatly from the MGX platform’s ability to deliver high performance, scalability, and resource efficiency. The Aerial Research Cloud roadmap will continue to develop features in advanced wireless technologies of interest to innovators including AI and ML.
These solutions, and more, from the NVIDIA 5G portfolio are being showcased at NVIDIA GTC 2024.
As generative AI and large language models (LLMs) continue to drive innovations, compute requirements for training and inference have grown at an astonishing pace. To meet that need, Google Cloud today announced the general availability of its new A3 instances, powered by NVIDIA H100 Tensor Core GPUs. These GPUs bring unprecedented performance to all kinds Read article >
From start-ups to large enterprises, businesses use cloud marketplaces to find the new solutions needed to quickly transform their businesses. Cloud…
From start-ups to large enterprises, businesses use cloud marketplaces to find the new solutions needed to quickly transform their businesses. Cloud marketplaces are online storefronts where customers can purchase software and services with flexible billing models, including pay-as-you-go, subscriptions, and privately negotiated offers. Businesses further benefit from committed spending at discount prices and a single source of billing and invoicing that saves time and resources.
NVIDIA Riva state-of-the-art speech and translation AI services are on the largest cloud service providers (CSP) marketplaces:
Companies can quickly find high-performance speech and translation AI that can be fully customized to best fit conversational pipelines such as question and answering services, intelligent virtual assistants, digital avatars, and agent assists for contact centers in different languages.
Organizations can quickly run Riva on the public cloud or integrate it with cloud provider services with greater confidence and a better return on their investment. With NVIDIA Riva in the cloud, you can now get instant access to Riva speech and translation AI through your browser—even if you don’t currently have your own on-premises GPU-accelerated infrastructure.
In this post and the associated videos, using Spanish-to-English speech-to-speech (S2S) translation as an example, you learn how to prototype and test Riva on a single CSP node. This post also covers deploying Riva in production at scale on a managed Kubernetes cluster.
Prototype and test Riva on a single node
Before launching and scaling a conversational application with Riva, prototype and test on a single node to find defects and improvement areas and ensure perfect production performance.
Select and launch the Riva virtual machine image (VMI) on the public CSPs
Access the Riva container on the NVIDIA GPU Cloud (NGC) catalog
Configure the NGC CLI
Edit the Riva Skills Quick Start configuration script and deploy the Riva server
Get started with Riva with tutorial Jupyter notebooks
Run speech-to-speech (S2S) translation inference
Video 1 explains how to launch a GCP virtual machine instance from the Riva VMI and connect to it from a terminal.
Video 1. NVIDIA Riva on GCP – Part 1: Setting Up and Connecting To the GCP VM Instance
Video 2 shows how to start the Riva Server and run Spanish-to-English speech-to-speech translation in the virtual machine instance.
Video 2. NVIDIA Riva on GCP – Part 2: Spanish-to-English S2T and S2S Translation
Select and launch the Riva VMI on a public CSP
The Riva VMI provides a self-contained environment that enables you to run Riva on single nodes in public cloud services. You can quickly launch with the following steps.
Choose the appropriate button to begin configuring the VM instance.
Set the compute zone, GPU and CPU types, and network security rules. The S2S translation demo should only take 13-14 GB of GPU memory and should be able to run on a 16 GB T4 GPU.
If necessary, generate an SSH key pair.
Deploy the VM instance and edit it further, if necessary. Connect to the VM instance using SSH and a key file in your local terminal (this is the safest way).
Connecting to a GCP VM instance with SSH and a key file requires the gcloud CLI rather than the built-in SSH tool. Use the following command format:
If you’ve already added the Project_ID and compute-zone values to your gcloud config, you can omit those flags in the command. The -L flag enables port forwarding, which enables you to launch Jupyter on the VM instance and access it in your local browser as though the Jupyter server were running locally.
Figure 1. Estimated monthly costs for Riva
Access the Riva container on NGC
The NGC catalog is a curated set of GPU-accelerated AI models and SDKs to help you quickly infuse AI into your applications.
The easiest way to download the Riva containers and desired models into the VM instance is to download the Riva Skills Quick Start resource folder with the appropriate ngc command, edit the provided config.sh script, and run the riva_init.sh and riva_start.sh scripts.
Your NGC CLI configuration ensures that you can access NVIDIA software resources. The configuration also determines which container registry space you can access.
The Riva VMI already provides the NGC CLI, so you don’t have to download or install it. You do still need to configure it.
Generate an NGC API key, if necessary. At the top right, choose your name and org. Choose Setup, Get API Key, and Generate API Key. Make sure to copy and save your newly generated API key someplace safe.
Run ngc config set and paste in your API key. Set the output format for the results of calls to the NGC CLI and set your org, team, and ACE.
Edit the Riva Skills Quick Start configuration script and deploy the Riva Server
Figure 2. Riva Skills Quick Start resource folder
Riva includes Quick Start scripts to help you get started with Riva speech and translation AI services:
Automatic speech recognition (ASR)
Text-to-speech (TTS)
Several natural language processing (NLP) tasks
Neural machine translation (NMT)
On the asset’s NGC overview page, choose Download. To copy the appropriate NGC CLI command into your VM instance’s terminal, choose CLI:
ngc registry resource download-version "nvidia/riva/riva_quickstart:2.12.1"
At publication time, 2.12.1 is the most recent version of Riva. Check the NGC catalog or the Riva documentation page for the latest version number.
After downloading the Riva Skills Quick Start resource folder in your VM instance’s terminal, implement a Spanish-to-English speech-to-speech (S2S) translation pipeline.
In the Riva Skills Quick Start home directory, edit the config.sh script to tell Riva which services to enable and which model files in the .rmir format to download.
Set service_enabled_nlp=false but leave the other services as true. You need Spanish ASR, Spanish-to-English NMT, and English TTS. There is no need for NLP.
To enable Spanish ASR, change language_code=("en-US") to language_code=("es-US").
Uncomment the line containing rmir_megatronnmt_any_en_500m to enable NMT from Spanish (and any of over 30 additional languages) to English.
To download the desired .rmir files and deploy them, run the following command. riva_init.sh wraps around the riva-deploy command.
bash riva_init.sh config.sh
To start the Riva server, run the following command:
bash riva_start.sh config.sh
If the server doesn’t start, output the relevant Docker logs to a file:
The VMI already contains a miniconda Python distribution, which includes Jupyter. Create a new conda environment from the base (default) environment in which to install dependencies, then launch Jupyter.
Clone the base (default) environment:
conda create --name conda-riva-tutorials --clone base
Activate the new environment:
conda activate conda-riva-tutorials
Install an iPython kernel for the new environment:
If you set up port forwarding when connecting to the VM instance with gcloud compute ssh, choose the link containing 127.0.0.1 to run Jupyter Lab in your local browser. If not, enter the following into your browser bar to run Jupyter Lab:
Your VM instance’s external IP address
A colon (:)
The port number (presumably 8888)
/lab?token=
If you don’t want to copy and paste the token in the browser bar, the browser asks you to enter the token in a dialog box instead.
Run the speech-to-speech translation demo
This speech-to-speech (S2S) demonstration consists of a modified version of the nmt-python-basics.ipynb tutorial notebook. To carry it out, perform the following steps.
Import the necessary modules:
import IPython.display as ipd
import numpy as np
import riva.client
Create a Riva client and connect to the Riva server:
The audio file contains a clip of a colleague reading a line from Miguel de Cervantes’ celebrated novel Don Quixote, “Cuando la vida misma parece lunática, ¿quién sabe dónde está la locura?”
This can be translated into English as, “When life itself seems lunatic, who knows where madness lies?”
Set up an audio chunk iterator, that is, divide the audio file into chunks no larger than a given number of frames:
# Create an empty array to store the receiving audio buffer
empty = np.array([])
# Send requests and listen to streaming response from the S2S service
for i, rep in enumerate(responses):
audio_samples = np.frombuffer(rep.speech.audio, dtype=np.int16) / (2**15)
print("Chunk: ",i)
try:
ipd.display(ipd.Audio(audio_samples, rate=44100))
except:
print("Empty response")
empty = np.concatenate((empty, audio_samples))
# Full translated synthesized speech
print("Final synthesis:")
ipd.display(ipd.Audio(empty, rate=44100))
This yields clips of synthesized speech in chunks and a final, fully assembled clip. The synthesized voice in the final clip should say, “When life itself seems lunatic, who knows where madness lies?”
Deploy Riva on a managed Kubernetes platform
After launching a Riva VMI and gaining access to the enterprise catalog, you can also deploy Riva to the various supported managed Kubernetes platforms like AKS, Amazon EKS, and GKE. These managed Kubernetes platforms are ideal for production-grade deployments because they enable seamless automated deployment, easy scalability, and efficient operability.
To help you get started, this post guides you through an example deployment for Riva on a GKE cluster. By combining the power of Terraform and Helm, you can quickly stand up production-grade deployments.
Set up a Kubernetes cluster on a managed Kubernetes platform with the NVIDIA Terraform modules
Deploy the Riva server on the Kubernetes cluster with a Helm chart
Interact with Riva on the Kubernetes cluster
Video 3 explains how to set up and run Riva on Google Kubernetes Engine (GKE) with Terraform.
Video 3. NVIDIA Riva on GKE – Part 1: Deploying a Kubernetes cluster to Google Kubernetes Engine (GKE) with Terraform
Video 4 shows how to scale up and out speech AI inference by deploying Riva on the Kubernetes cluster with Helm.
Video 4. NVIDIA Riva on GKE – Part 2: Deploying Riva on a Kubernetes cluster with Helm
Set up the GKE cluster with the NVIDIA Terraform modules
The NVIDIA Terraform modules make it easy to deploy a Riva-ready GKE cluster. For more information, see the /nvidia-terraform-modules GitHub repo.
To get started, clone the repo and install the prerequisites on a machine:
From within the nvidia-terraform-modules/gke directory, ensure that you have active credentials set with the gcloud CLI.
Update terraform.tfvars by uncommenting cluster_name and region and filling out the values specific to your project. By default, this module deploys the cluster into a new VPC. To deploy the cluster into an existing VPC, you must also uncomment and set the existing_vpc_details variable.
Alternatively, you can change any variable names or parameters in any of the following ways:
Add them directly to variables.tf.
Pass them in from the command line with the -var flag.
Pass them in as environment variables.
Pass them in from the command line when prompted.
In variables.tf, update the following variables for use by Riva: GPU type and region.
Select a supported GPU type:
variable "gpu_type" {
default = "nvidia-tesla-t4"
description = "GPU SKU To attach to Holoscan GPU Node (eg. nvidia-tesla-k80)"
}
(Optional) Select your region:
variable "region" {
default = "us-west1"
description = "The Region resources (VPC, GKE, Compute Nodes) will be created in"
}
Run gcloud auth application-default login to make your Google credentials available to the terraform executable. For more information, see Assigning values to root module variables in the Terraform documentation.
terraform init: Initialize the configuration.
terraform plan: See what will be applied.
terraform apply: Apply the code against your GKE environment.
Connect to the cluster with kubectl by running the following command after the cluster is created:
To delete cloud infrastructure provisioned by Terraform, run terraform destroy.
The NVIDIA Terraform modules can also be used for deployments in other CSPs and follow a similar pattern. For more information about deploying AKS and EKS clusters, see the /nvidia-terraform-modules GitHub repo.
Deploy the Riva Speech Skills API with a Helm chart
The Riva speech skills Helm chart is designed to automate deployment to a Kubernetes cluster. After downloading the Helm chart, minor adjustments adapt the chart to the way Riva is used in the rest of this post.
Start by downloading and untarring the Riva API Helm chart. The 2.12.1 version is the most recent as of this post. To download a different version of the Helm chart, replace VERSION_TAG with the specific version needed in the following code example:
In the riva-api folder, modify the following files as noted.
In the values.yaml file, in modelRepoGenerator.ngcModelConfigs.tritonGroup0, comment or uncomment specific models or change language codes as needed.
For the S2S pipeline used earlier:
Change the language code in the ASR model from US English to Latin American Spanish, so that rmir_asr_conformer_en_us_str_thr becomes rmir_asr_conformer_es_us_str_thr.
Uncomment the line containing rmir_megatronnmt_any_en_500m.
Ensure that service.type is set to ClusterIP rather than LoadBalancer. This exposes the service only to other services within the cluster, such as the proxy service installed later in this post.
In the templates/deployment.yaml file, follow up by adding a node selector constraint to ensure that Riva is only deployed on the correct GPU resources. Attach it to a node pool (called a node group in Amazon EKS). You can get this from the GCP console or by running the appropriate gcloud commands in your terminal:
$ gcloud container clusters list
NAME LOCATION MASTER_VERSION MASTER_IP MACHINE_TYPE NODE_VERSION NUM_NODES STATUS
riva-in-the-cloud-blog-demo us-west1 1.27.3-gke.100 35.247.68.177 n1-standard-4 1.27.3-gke.100 3 RUNNING
$ gcloud container node-pools list --cluster=riva-in-the-cloud-blog-demo --location=us-west1
NAME MACHINE_TYPE DISK_SIZE_GB NODE_VERSION
tf-riva-in-the-cloud-blog-demo-cpu-pool n1-standard-4 100 1.27.3-gke.100
tf-riva-in-the-cloud-blog-demo-gpu-pool n1-standard-4 100 1.27.3-gke.100
In spec.template.spec, add the following with your node pool name from earlier:
Ensure that you are in a working directory with /riva-api as a subdirectory, then install the Riva Helm chart. You can explicitly override variables from the values.yaml file.
A riva-model-init container that downloads and deploys the models.
A riva-speech-api container to start the speech service API.
Depending on the number of models, the initial model deployment could take an hour or more. To monitor the deployment, use kubectl to describe the riva-api Pod and to watch the container logs.
While this method of interacting with the server is probably not ideally suited to production environments, you can run the S2S translation demo from anywhere outside the GKE cluster by changing the URI in the call to riva.client.Auth so that the Riva Python client sends inference requests to the riva-api service on the GKE cluster rather than the local host. Obtain the appropriate URI with kubectl:
$ kubectl get services
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.155.240.1 443/TCP 1h
riva-api LoadBalancer 10.155.243.119 34.127.90.22 8000:30623/TCP,8001:30542/TCP,8002:32113/TCP,50051:30842/TCP 1h
No port forwarding is taking place here. To run the Spanish-to-English S2S translation pipeline on the GKE cluster from a Jupyter notebook outside the cluster, change the following line:
auth = riva.client.Auth(uri="localhost:50051")
Here’s the desired line:
auth = riva.client.Auth(uri=":50051")
There are multiple ways to interact with the server. One method involves deploying IngressRoute through a Traefik Edge router deployable through Helm. For more information, see Deploying the Traefik edge router.
NVIDIA Riva is available on the Amazon Web Services, Google Cloud, and Microsoft Azure marketplaces. Get started with prototyping and testing Riva in the cloud on a single node through quickly deployable VMIs. For more information, see the NVIDIA Riva on GCP videos.
Production-grade Riva deployments on Managed Kubernetes are easy with NVIDIA Terraform modules. For more information, see the NVIDIA Riva on GKE videos.
Deploy Riva on CSP compute resources with cloud credits by purchasing a license from a CSP marketplace:
Generative AI has become a transformative force of our era, empowering organizations spanning every industry to achieve unparalleled levels of productivity,…
Generative AI has become a transformative force of our era, empowering organizations spanning every industry to achieve unparalleled levels of productivity, elevate customer experiences, and deliver superior operational efficiencies.
Large language models (LLMs) are the brains behind generative AI. Access to incredibly powerful and knowledgeable foundation models, like Llama and Falcon, has opened the door to amazing opportunities. However, these models lack the domain-specific knowledge required to serve enterprise use cases.
Developers have three choices for powering their generative AI applications:
Pretrained LLMs: the easiest lift is to use foundation models, which work very well for use cases that rely on general-purpose knowledge.
Custom LLMs: pretrained models customized with domain-specific knowledge, and task-specific skills, connected to enterprises’ knowledge bases perform tasks and provide responses based on the latest proprietary information.
Develop LLMs: organizations with specialized data (for example, models catering to regional languages) cannot use pretrained foundation models and must build their models from scratch.
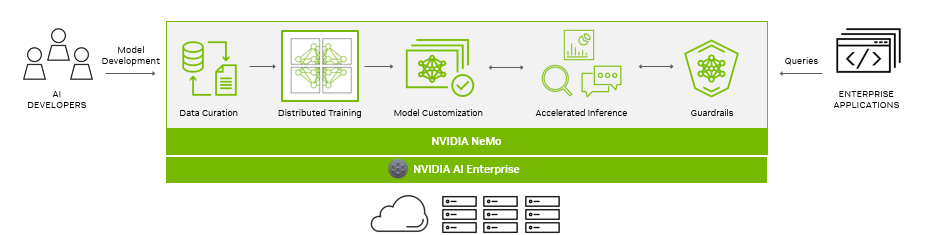
NVIDIA NeMo is an end-to-end, cloud-native framework for building, customizing, and deploying generative AI models. It includes training and inferencing frameworks, guardrails, and data curation tools, for an easy, cost-effective, and fast way to adopt generative AI.
Figure 1. End-to-end platform for production-ready generative AI with NeMo
As generative AI models and their development continue to progress, the AI stack and its dependencies become increasingly complex. For enterprises running their business on AI, NVIDIA provides a production-grade, secure, end-to-end software solution with NVIDIA AI Enterprise.
Organizations are running their mission-critical enterprise applications on Google Cloud, a leading provider of GPU-accelerated cloud platforms. NVIDIA AI Enterprise, which includes NeMo and is available on Google Cloud, helps organizations adopt generative AI faster.
Building a generative AI solution requires that the full stack, from compute to networking, systems, management software, training, and inference SDKs work in harmony.
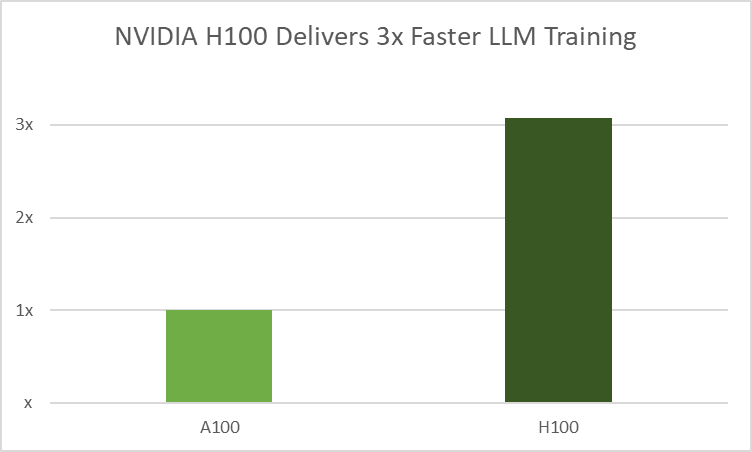
At Google Cloud Next 2023, Google Cloud announced the general availability of their A3 instances powered by NVIDIA H100 Tensor Core GPUs. Engineering teams from both companies are collaborating to bring NeMo to the A3 instances for faster training and inference.
In this post, we cover training and inference optimizations developers can enjoy while building and running their custom generative AI models on NVIDIA H100 GPUs.
Data curation at scale
The potential of a single LLM achieving exceptional outcomes across diverse tasks is due to training on an immense volume of Internet-scale data.
NVIDIA NeMo Data Curator facilitates the handling of trillion-token multilingual training data for LLMs. It consists of a collection of Python modules leveraging MPI, Dask, and a Redis cluster to scale tasks involved in data curation efficiently. These tasks include data downloads, text extractions, text reformatting, quality filtering, and removal of exact or fuzzy duplicate data. This tool can distribute these tasks across thousands of computational cores.
Using these modules aids developers in swiftly sifting through unstructured data sources. This technology accelerates model training, reduces costs through efficient data preparation, and yields more precise results.
Accelerated model training
NeMo employs distributed training using sophisticated parallelism methods to use GPU resources and memory across multiple nodes on a large scale. By breaking down the model and training data, NeMo enables optimal throughput and significantly reduces the time required for training, which also speeds up TTM.
H100 GPUs employ NVIDIA Transformer Engine (TE), a library that enhances AI performance by combining 16-bit and 8-bit floating-point formats with advanced algorithms. It achieves faster LLM training without losing accuracy by reducing math operations to FP8 from the typical FP16 and FP32 formats used in AI workloads. This optimization uses per-layer statistical analysis to increase precision for each model layer, resulting in optimal performance and accuracy.
Figure 2. NVIDIA H100 uses an FP8, a TE for accelerated LLM training. This example uses GPT-3, with 175B parameters, 300B tokens, and 64 NVIDIA A100 (BF16) and H100 (FP8) GPUs running across 8x DGX A100/H100 systems
AutoConfigurator delivers developer productivity
Finding model configurations for LLMs across distributed infrastructure is a time-consuming process. NeMo provides AutoConfigurator, a hyperparameter tool to find optimal training configurations automatically, enabling high throughput LLMs to train faster. This saves developers time searching for efficient model configurations.
It applies heuristics and grid search techniques to various parameters, such as tensor parallelism, pipeline parallelism, micro-batch size, and activation checkpointing layers, aimed at determining configurations with the highest throughputs.
AutoConfigurator can also find model configurations that achieve the highest throughput or lowest latency during inference. Latency and throughput constraints can be provided to deploy the model, and the tool will recommend suitable configurations.
In the realm of LLMs, one size rarely fits all, especially in enterprise applications. Off-the-shelf LLMs often fall short in catering to the distinct requirements of the organizations, whether it’s the intricacies of specialized domain knowledge, industry jargon, or unique operational scenarios.
This is precisely where the significance of custom LLMs comes into play. Enterprises must fine-tune models that support the capabilities for specific use cases and domain expertise. These customized models provide enterprises with the means to create solutions personalized to match their brand voice and streamline workflows, for more accurate insights, and rich user experiences.
NeMo supports a variety of customization techniques, for developers to use NVIDIA-built models by adding functional skills, focusing on specific domains, and implementing guardrails to prevent inappropriate responses.
Additionally, the framework supports community-built pretrain LLMs including Llama 2, BLOOM, and Bart, and supports GPT, T5, mT5, T5-MoE, and Bert architectures.
P-Tuning trains a small helper model to set the context for the frozen LLM to generate a relevant and accurate response.
Adapters/IA3 introduce small, task-specific feedforward layers within the core transformer architecture, adding minimal trainable parameters per task. This makes for easy integration of new tasks without reworking existing ones.
Low-Rank Adaption uses compact additional modules to enhance model performance on specific tasks without substantial changes to the original model.
Supervised Fine-tuning calibrates model parameters on labeled data of inputs and outputs, teaching the model domain-specific terms and how to follow user-specified instructions.
Reinforcement Learning with Human Feedback enables LLMs to achieve better alignment with human values and preferences.
Community LLMs are growing at an explosive rate, with increased demand from companies to deploy these models into production. The size of these LLMs is driving the cost and complexity of deployment higher, requiring optimized inference performance for production applications. Higher performance not only helps decrease costs but also improves user experiences.
LLMs such as LLaMa, BLOOM, ChatGLM, Falcon, MPT, and Starcoder have demonstrated the potential of advanced architectures and operators. This has created a challenge in producing a solution that can efficiently optimize these models for inference, something that is highly desirable in the ecosystem.
NeMo employs MHA and KV cache optimizations, flash attention, quantized KV cache, and paged attention, among other techniques to solve the large set of LLM optimization challenges. It enables developers to try new LLM and customize foundation models for peak performance without requiring deep knowledge of C++ or NVIDIA CUDA optimization.
NeMo also leverages NVIDIA TensorRT deep learning compiler, pre- and post-processing optimizations, and multi-GPU multi-node communication. In an open-source Python API, it defines, optimizes, and executes LLMs for inference in production applications.
NeMo Guardrails
LLMs can be biased, provide inappropriate responses, and hallucinate. NeMo Guardrails is an open-source, programmable toolkit for addressing these challenges. It sits between the user and the LLM, screening and filtering inappropriate user prompts as well as LLM responses.
Building guardrails for various scenarios is straightforward. First, define a guardrail by providing a few examples in natural language. Then, define a response when a question on that topic is generated. Lastly, define a flow, which dictates the set of actions to be taken when the topic or the flow is triggered.
NeMo Guardrails can help the LLM stay focused on topics, prevent toxic responses, and make sure that replies are generated from credible sources before they are presented to users. Read about building trustworthy, safe, and secure LLM conversational systems.
Simplify deployment with ecosystem tools
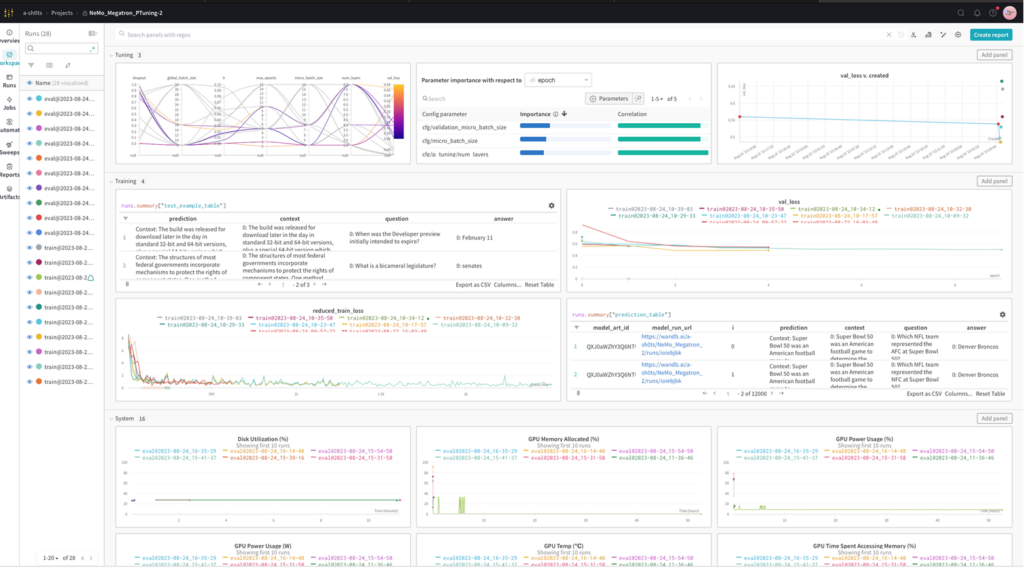
NeMo works with MLOps ecosystem technologies such as Weights & Biases (W&B) providing powerful capabilities for accelerating the development, tuning, and adoption of LLMs.
Developers can debug, fine-tune, compare, and reproduce models with the W&B MLOps platform. W&B Prompts help organizations understand, tune, and analyze LLM performance. W&B integrates with Google Cloud products commonly used in ML development.
Figure 3. LLM metrics analysis, such as hyperparameter importance and model performance in Weights & Biases
The combination of NeMo, W&B, and Google Cloud is on display at the NVIDIA booth at Google Cloud Next.
Fuel generative AI applications
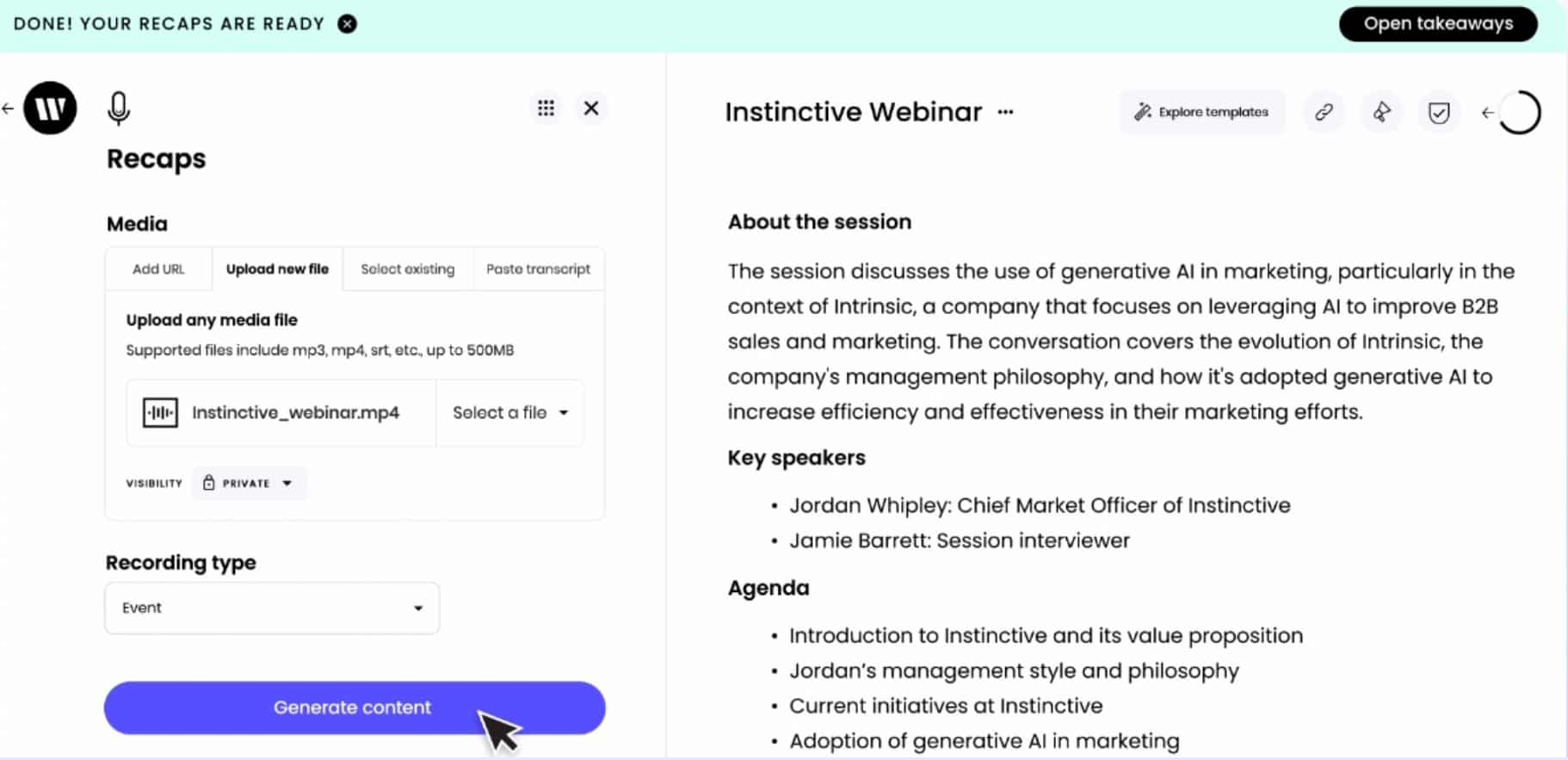
Writer, a leading generative AI-based content creation service, is harnessing NeMo capabilities and accelerated compute on Google Cloud. They’ve built up to 40B parameter language models that now cater to hundreds of customers, revolutionizing content generation.
Figure 4. The Writer Recap tool creates written summaries from audio recordings of an interview or event
APMIC is another success story with NeMo at its core. With a dual focus, they leverage NeMo for two distinct use cases. They’ve supercharged their contract verification and verdict summarization processes through entity linking, extracting vital information from documents quickly. They are also using NeMo to customize GPT models, offering customer service and digital human interaction solutions by powering question-answering systems.
Start building your generative AI application
Using AI playground, you can experience the full potential of community and NVIDIA-built generative AI models, optimized for the NVIDIA accelerated stack, directly through your web browser.
Video 1. NVIDIA AI Playground
Customize GPT, mT5, or BERT-based pretrained LLMs from Hugging Face using NeMo on Google Cloud:

 Episode 5 of the NVIDIA CUDA Tutorials Video series is out. Jackson Marusarz, product manager for Compute Developer Tools at NVIDIA, introduces a suite of tools…
Episode 5 of the NVIDIA CUDA Tutorials Video series is out. Jackson Marusarz, product manager for Compute Developer Tools at NVIDIA, introduces a suite of tools…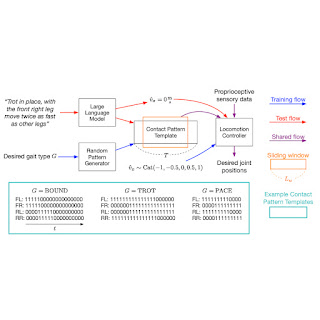

 NVIDIA DOCA SDK and acceleration framework empowers developers with extensive libraries, drivers, and APIs to create high-performance applications and services…
NVIDIA DOCA SDK and acceleration framework empowers developers with extensive libraries, drivers, and APIs to create high-performance applications and services…
 NVIDIA is driving fast-paced innovation in 5G software and hardware across the ecosystem with its OpenRAN-compatible 5G portfolio. Accelerated computing…
NVIDIA is driving fast-paced innovation in 5G software and hardware across the ecosystem with its OpenRAN-compatible 5G portfolio. Accelerated computing…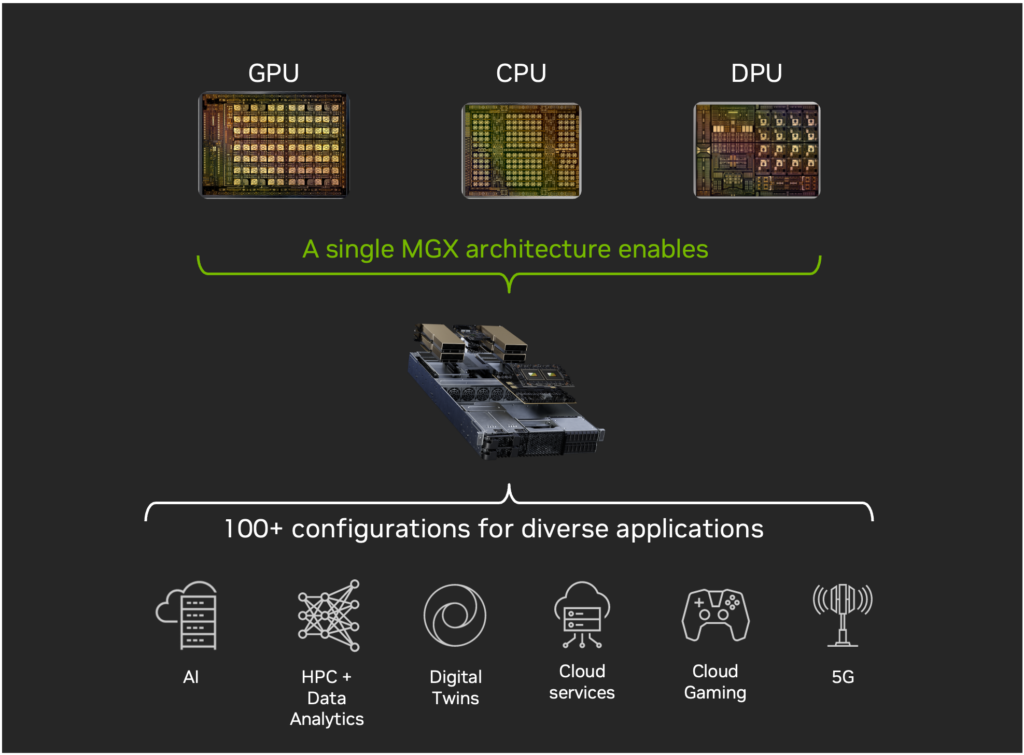

 From start-ups to large enterprises, businesses use cloud marketplaces to find the new solutions needed to quickly transform their businesses. Cloud…
From start-ups to large enterprises, businesses use cloud marketplaces to find the new solutions needed to quickly transform their businesses. Cloud…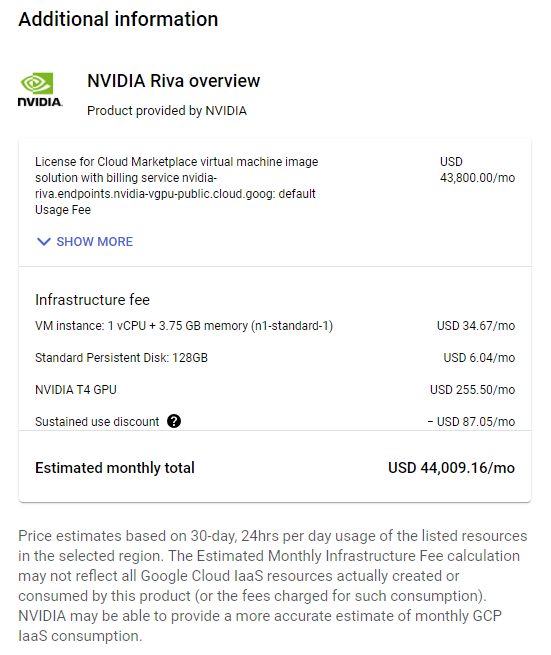
 Generative AI has become a transformative force of our era, empowering organizations spanning every industry to achieve unparalleled levels of productivity,…
Generative AI has become a transformative force of our era, empowering organizations spanning every industry to achieve unparalleled levels of productivity,…