
GFN Thursday is downright demonic, as Devil May Cry 5 comes to GeForce NOW. Capcom’s action-packed third-person brawler leads 15 titles joining the GeForce NOW library this week, including Gears Tactics and The Crew Motorfest. It’s also the last week to take on the Ultimate KovaaK’s Challenge. Get on the leaderboard today for a chance Read article >
Categories
New Course: Generative AI Explained
 Explore generative AI concepts and applications, along with challenges and opportunities in this self-paced course.
Explore generative AI concepts and applications, along with challenges and opportunities in this self-paced course.
Explore generative AI concepts and applications, along with challenges and opportunities in this self-paced course.
Generative AI-based models can not only learn and understand natural languages — they can learn the very language of nature itself, presenting new possibilities for scientific research. Anima Anandkumar, Bren Professor at Caltech and senior director of AI research at NVIDIA, was recently invited to speak at the President’s Council of Advisors on Science and Read article >
 Organizations are integrating machine learning (ML) throughout their systems and products at an unprecedented rate. They are looking for solutions to help deal…
Organizations are integrating machine learning (ML) throughout their systems and products at an unprecedented rate. They are looking for solutions to help deal…
Organizations are integrating machine learning (ML) throughout their systems and products at an unprecedented rate. They are looking for solutions to help deal with the complexities of deploying models at production scale.
NVIDIA Triton Management Service (TMS), exclusively available with NVIDIA AI Enterprise, is a new product that helps do just that. Specifically, it helps manage and orchestrate a fleet of NVIDIA Triton Inference Servers in a Kubernetes cluster. TMS enables users to scale their NVIDIA Triton deployments to handle large and varied workloads efficiently. It also improves the developer experience of coordinating the resources and tools required.
This post explores some of the most common challenges developers and MLOps teams face when deploying models at scale, and how NVIDIA Triton Management Service addresses them.
Challenges in scaling AI model deployment
Model deployments of any scale come with their own sets of challenges. Developers need to consider how to balance a variety of frameworks, model types, and hardware while maximizing performance and interfacing with the other components of the environment.
NVIDIA Triton is a powerful solution built to handle these issues and extract the best throughput and performance from the machine it’s deployed on. But as organizations incorporate AI into more of their core workflows, the number and size of inference workloads can grow beyond what a single server can handle. The model deployments have to scale. A new scale of deployment brings with it a new set of challenges—challenges related to the cost and complexity of managing distributed inference workloads.
Cost of deployment
As you deploy more models and find more use cases for them, it can quickly become necessary to scale out deployments to make use of a cluster of resources. A simple approach is to keep scaling your cluster linearly as you add more models, keeping all of your models live and ready for inference at all times.
However, this is not an approach with infinite scale potential. Focusing on expanding the capacity of your serving cluster can result in unnecessary expenses when you have the option to improve utilization of currently available hardware. You will also have to deal with the logistical challenges of adding more resources on premises, or bumping up against quota limits in the cloud.
Other approaches to scaling might appear less expensive, but can lead to steep performance trade-offs. For example, you could wait to load the models into memory until the inference requests come in, leading to long waits and an extended time-to-first-inference. Or you could overcommit your compute resources, leading to performance penalties from context switching during execution and errors from running out of memory on the device.
With careful preplanning and colocation of workloads, you can avoid some of the worst of these issues. Still, that only exacerbates the second major issue of large-scale deployments.
Operational complexity
At a small scale and early in the development of a process that requires model orchestration, it can be viable to manually configure and deploy your models. But as your ML deployments scale, it becomes increasingly challenging to coordinate all of the necessary resources. You need to manage when to launch or scale servers, where to load particular models, how to route requests to the right place, and how to handle the model lifecycle in your environment.
Determining which models can be colocated adds another layer of complexity to these deployments. Large models might exceed the memory capacity of your GPU or CPU if loaded concurrently into the same device. Some frameworks (such as PyTorch and TensorFlow) hold on to any memory allocated to them even after the models are unloaded, leading to inefficient utilization when models from those frameworks are run alongside models from other frameworks.
In general, different models will have different requirements regarding resource allocation and server configuration, making it difficult to standardize on a single type of deployment.
Cost-efficient deployment and scaling of AI models
Triton Management Service addresses these challenges with three main strategies: simplifying Triton Inference Server deployment, maximizing resource usage, and monitoring/scaling Triton inference servers.
Simplifying deployment
TMS automates the deployment and management of Triton server instances on Kubernetes using a simplified gRPC API and command-line tool. With these interfaces, you don’t need to write out extensive code or config files for creating deployments, services, and Kubernetes resources. Instead, you can use the API or CLI to easily launch Triton servers and automatically load models onto these servers as needed.
TMS also employs a method of grouping to optimize GPU or CPU memory utilization. This prevents issues that arise when different frameworks like PyTorch and TensorFlow models run on the same server and fail to release unused GPU or CPU? memory to each other.
Maximizing resources
TMS loads models on-demand and unloads them using a lease system when they are not in use, making sure that models are not kept active in the cluster unnecessarily. To bring up a model, you can submit an API request with a specified timeline or a checking mechanism. The system will keep the model available if it’s being used; otherwise, it will be taken down.
TMS also automatically colocates models on the same device when sufficient capacity is available. To enable this, you need to prespecify the expected GPU memory use of your models during deployment. While there is no automated way to measure this yet, you can rely on Triton Model Analyzer and other benchmarking tools to determine memory requirements beforehand. Together, these features enable you to run more workloads on your existing clusters, saving on costs, and reducing the need to acquire more computational resources.
Monitoring and autoscaling
TMS keeps track of the health and capacity of various Triton servers for high availability reasons. Autoscaling is integrated into the system, enabling TMS to deploy Kubernetes Horizontal Pod Autoscalers automatically based on the model deployment configuration. You can specify metrics for autoscaling, indicating the conditions under which scaling should occur. Load balancing is also applied when autoscaling is implemented across multiple Triton instances.
How Triton Management Service works
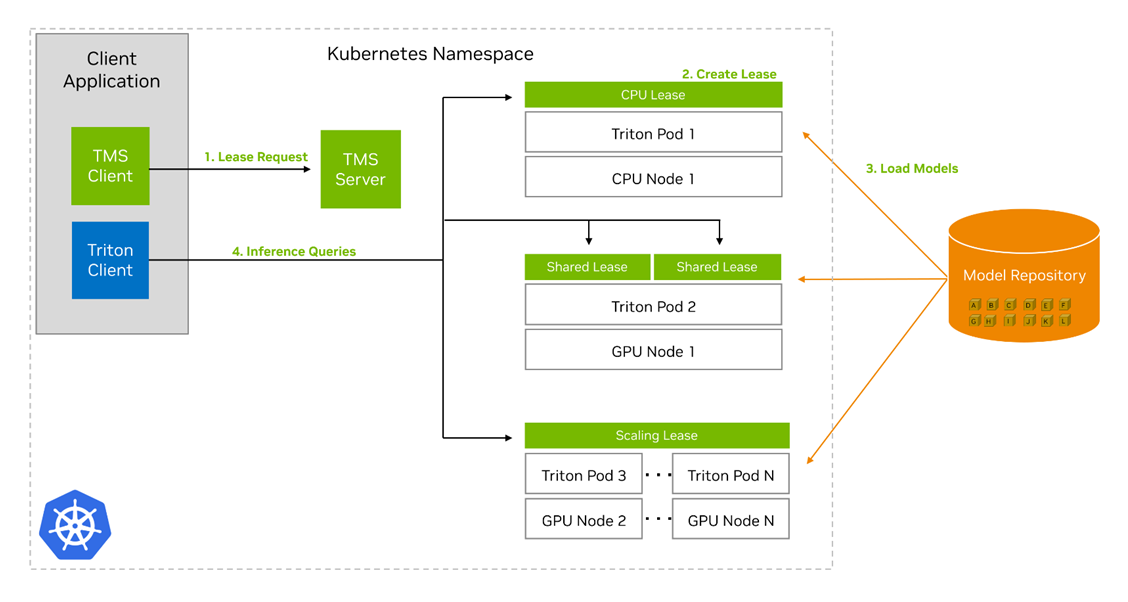
To install TMS, deploy a Helm chart with configurable values into a Kubernetes cluster. This Helm chart delpoys the TMS Server control plane into the cluster, along with a config map that holds many of the configuration settings for TMS. You can operate TMS through gRPC API calls to the TMS Server, or by using the provided tmsctl command-line tool.
The key concept in TMS is the lease. At its core, a lease is a grouping of models and some associated metadata that tells TMS how to treat those models, and what constraints exist for their deployment. Users can create, renew, and release leases. Creating a lease requires specifying a set of models from predefined repositories by a unique identifier, along with metadata including:
- Compute resources required by the lease
- Image/version of Triton to use for this lease
- Minimum duration of the lease
- Window size for detecting activity on the models in the lease
- Metrics and thresholds for scaling the lease
- Constraints on what models or leases with with the new lease can be collected
- A unique name for the lease that can be used to addressed it
When the TMS Server receives the lease request, it performs the actions listed below to create the lease:
- Check the model repositories to see if the models are present and accessible.
- If models are present and accessible, check for existing Triton Inference Servers present in the cluster that meet the constraints of the new lease.
- If none exist, create a new Kubernetes pod containing the Triton Inference Server container and a Triton Sidecar Container.
- Otherwise, choose one of the existing Triton pods to add the lease to.
- In either case, the Triton Sidecar in the Triton Pod will pull the models in your lease from the repository and load them into its paired Triton server.
TMS will also create several other Kubernetes resources to help with management and routing for the lease:
- A deployment that will revive Triton pods if they crash.
- A Kubernetes service based on the lease name that can be used to address the models in the lease.
- A horizontal pod autoscaler to automatically create replicas of the Triton pods based on the metrics and thresholds defined in the lease.
Once the lease has been created, you can use the Triton Inference Server API or an existing Triton client to send inference requests to the server for execution. The Triton client does not need any modifications to work with Triton Inference Servers deployed by Triton Management Service.
Get started with NVIDIA Triton Management Service
To get started with NVIDIA Triton Management Service and learn more about its features and functionality, check out the AI Model Orchestration with Triton Management Service lab on LaunchPad. This lab provides free access to a GPU-enabled Kubernetes cluster and a step-by-step guide on installing Triton Management Service and using it to deploy a variety of AI workloads.
If you have existing compatible on-premises systems or cloud instances, request a 90-day NVIDIA AI Enterprise Evaluation License to try Triton Management Service. If you are an existing NVIDIA AI Enterprise user, simply log in to the NGC Enterprise Catalog.
 Crossing the chasm and reaching its iPhone moment, generative AI must scale to fulfill exponentially increasing demands. Reliability and uptime are critical for…
Crossing the chasm and reaching its iPhone moment, generative AI must scale to fulfill exponentially increasing demands. Reliability and uptime are critical for…
Crossing the chasm and reaching its iPhone moment, generative AI must scale to fulfill exponentially increasing demands. Reliability and uptime are critical for building generative AI at the enterprise level, especially when AI is core to conducting business operations. NVIDIA is investing its expertise into building a solution for those enterprises ready to take the leap.
Introducing NVIDIA AI Enterprise 4.0
The latest version of NVIDIA AI Enterprise accelerates development through multiple facets with production-ready support, manageability, security, and reliability for enterprises innovating with generative AI.
Quickly train, customize, and deploy LLMs at scale with NVIDIA NeMo
Generative AI models have billions of parameters and require an efficient data training pipeline. The complexity of training models, customization for domain-specific tasks, and deployment of models at scale require expertise and compute resources.
NVIDIA AI Enterprise 4.0 now includes NVIDIA NeMo, an end-to-end, cloud-native framework for data curation at scale, accelerated training and customization of large language models (LLMs), and optimized inference on user-preferred platforms. From cloud to desktop workstations, NVIDIA NeMo provides easy-to-use recipes and optimized performance with accelerated infrastructure, greatly reducing time to solution and increasing ROI.
Build generative AI applications faster with AI workflows
NVIDIA AI Enterprise 4.0 introduces two new AI workflows for building generative AI applications: AI chatbot with retrieval augmented generation and spear phishing detection.
The generative AI knowledge base chatbot workflow, leveraging Retrieval Augmented Generation, accelerates the development and deployment of generative AI chatbots tuned on your data. These chatbots accurately answer domain-specific questions, retrieving information from a company’s knowledge base and generating real-time responses in natural language. It uses pretrained LLMs, NeMo, NVIDIA Triton Inference Server, along with third-party tools including Langchain and vector database, for training and deploying the knowledge base question-answering system.
The spear phishing detection AI workflow uses NVIDIA Morpheus and generative AI with NVIDIA NeMo to train a model that can detect up to 90% of spear phishing e-mails before they hit your inbox.
Defending against spear-phishing e-mails is a challenge. Spear phishing e-mails are indistinguishable from benign e-mails, with the only difference between the scam and legitimate e-mail being the intent of the sender. This is why traditional mechanisms for detecting spear phishing fall short.
Develop AI anywhere
Enterprise adoption of AI can require additional skilled AI developers and data scientists. Organizations will need a flexible high-performance infrastructure consisting of optimized hardware and software to maximize productivity and accelerate AI development. Together with NVIDIA RTX 6000 Ada Generation GPUs for workstations, NVIDIA AI Enterprise 4.0 provides AI developers a single platform for developing AI applications and deploying them in production.
Beyond the desktop, NVIDIA offers a complete infrastructure portfolio for AI workloads including NVIDIA H100, L40S, L4 GPUs, and accelerated networking with NVIDIA BlueField data processing units. With HPE Machine Learning Data Management, HPE Machine Learning Development Environment, Ubuntu KVM and Nutanix AHV virtualization support, organizations can use on-prem infrastructure to power AI workloads.
Manage AI workloads and infrastructure
NVIDIA Triton Management Service, an exclusive addition to NVIDIA AI Enterprise 4.0, automates the deployment of multiple Triton Inference Servers in Kubernetes with GPU resource-efficient model orchestration. It simplifies deployment by loading models from multiple sources and allocating compute resources. Triton Management Service is available for lab experience on NVIDIA LaunchPad.
NVIDIA AI Enterprise 4.0 also includes cluster management software, NVIDIA Base Command Manager Essentials, for streamlining cluster provisioning, workload management, infrastructure monitoring, and usage reporting. It facilitates the deployment of AI workload management with dynamic scaling and policy-based resource allocation, providing cluster integrity.
New AI software, tools, and pretrained foundation models
NVIDIA AI Enterprise 4.0 brings more frameworks and tools to advance AI development. NVIDIA Modulus is a framework for building, training, and fine-tuning physics-machine learning models with a simple Python interface.
Using Modulus, users can bolster engineering simulations with AI and build models for enterprise-scale digital twin applications across multiple physics domains, from CFD and Structural to Electromagnetics. The Deep Graph Library container is designed to implement and train Graph Neural Networks that can help scientists research the graph structure of molecules or financial services to detect fraud.
Lastly, three exclusive pretrained foundation models, part of NVIDIA TAO, speed time to production for industry applications such as vision AI, defect detection, and retail loss prevention.
NVIDIA AI Enterprise 4.0 is the most comprehensive upgrade to the platform to date. With enterprise-grade security, stability, manageability, and support, enterprises can expect reliable AI uptime and uninterrupted AI excellence.
Get started with NVIDIA AI Enterprise
Three ways to get accelerated with NVIDIA AI Enterprise:
- Sign up for NVIDIA LaunchPad for short-term access to sets of hands-on labs.
- Sign up for a free 90-day evaluation for existing on-prem or cloud infrastructure.
Purchase through NVIDIA Partner Network or major Cloud Service Providers including AWS, Microsoft Azure, and Google Cloud.
Routing in Google Maps remains one of our most helpful and frequently used features. Determining the best route from A to B requires making complex trade-offs between factors including the estimated time of arrival (ETA), tolls, directness, surface conditions (e.g., paved, unpaved roads), and user preferences, which vary across transportation mode and local geography. Often, the most natural visibility we have into travelers’ preferences is by analyzing real-world travel patterns.
Learning preferences from observed sequential decision making behavior is a classic application of inverse reinforcement learning (IRL). Given a Markov decision process (MDP) — a formalization of the road network — and a set of demonstration trajectories (the traveled routes), the goal of IRL is to recover the users’ latent reward function. Although past research has created increasingly general IRL solutions, these have not been successfully scaled to world-sized MDPs. Scaling IRL algorithms is challenging because they typically require solving an RL subroutine at every update step. At first glance, even attempting to fit a world-scale MDP into memory to compute a single gradient step appears infeasible due to the large number of road segments and limited high bandwidth memory. When applying IRL to routing, one needs to consider all reasonable routes between each demonstration’s origin and destination. This implies that any attempt to break the world-scale MDP into smaller components cannot consider components smaller than a metropolitan area.
To this end, in “Massively Scalable Inverse Reinforcement Learning in Google Maps“, we share the result of a multi-year collaboration among Google Research, Maps, and Google DeepMind to surpass this IRL scalability limitation. We revisit classic algorithms in this space, and introduce advances in graph compression and parallelization, along with a new IRL algorithm called Receding Horizon Inverse Planning (RHIP) that provides fine-grained control over performance trade-offs. The final RHIP policy achieves a 16–24% relative improvement in global route match rate, i.e., the percentage of de-identified traveled routes that exactly match the suggested route in Google Maps. To the best of our knowledge, this represents the largest instance of IRL in a real world setting to date.
 |
| Google Maps improvements in route match rate relative to the existing baseline, when using the RHIP inverse reinforcement learning policy. |
The benefits of IRL
A subtle but crucial detail about the routing problem is that it is goal conditioned, meaning that every destination state induces a slightly different MDP (specifically, the destination is a terminal, zero-reward state). IRL approaches are well suited for these types of problems because the learned reward function transfers across MDPs, and only the destination state is modified. This is in contrast to approaches that directly learn a policy, which typically require an extra factor of S parameters, where S is the number of MDP states.
Once the reward function is learned via IRL, we take advantage of a powerful inference-time trick. First, we evaluate the entire graph’s rewards once in an offline batch setting. This computation is performed entirely on servers without access to individual trips, and operates only over batches of road segments in the graph. Then, we save the results to an in-memory database and use a fast online graph search algorithm to find the highest reward path for routing requests between any origin and destination. This circumvents the need to perform online inference of a deeply parameterized model or policy, and vastly improves serving costs and latency.
 |
| Reward model deployment using batch inference and fast online planners. |
Receding Horizon Inverse Planning
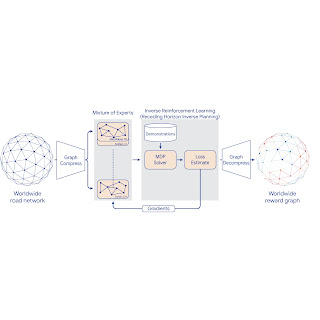
To scale IRL to the world MDP, we compress the graph and shard the global MDP using a sparse Mixture of Experts (MoE) based on geographic regions. We then apply classic IRL algorithms to solve the local MDPs, estimate the loss, and send gradients back to the MoE. The worldwide reward graph is computed by decompressing the final MoE reward model. To provide more control over performance characteristics, we introduce a new generalized IRL algorithm called Receding Horizon Inverse Planning (RHIP).
 |
| IRL reward model training using MoE parallelization, graph compression, and RHIP. |
RHIP is inspired by people’s tendency to perform extensive local planning (“What am I doing for the next hour?”) and approximate long-term planning (“What will my life look like in 5 years?”). To take advantage of this insight, RHIP uses robust yet expensive stochastic policies in the local region surrounding the demonstration path, and switches to cheaper deterministic planners beyond some horizon. Adjusting the horizon H allows controlling computational costs, and often allows the discovery of the performance sweet spot. Interestingly, RHIP generalizes many classic IRL algorithms and provides the novel insight that they can be viewed along a stochastic vs. deterministic spectrum (specifically, for H=∞ it reduces to MaxEnt, for H=1 it reduces to BIRL, and for H=0 it reduces to MMP).
 |
| Given a demonstration from so to sd, (1) RHIP follows a robust yet expensive stochastic policy in the local region surrounding the demonstration (blue region). (2) Beyond some horizon H, RHIP switches to following a cheaper deterministic planner (red lines). Adjusting the horizon enables fine-grained control over performance and computational costs. |
Routing wins
The RHIP policy provides a 15.9% and 24.1% lift in global route match rate for driving and two-wheelers (e.g., scooters, motorcycles, mopeds) relative to the well-tuned Maps baseline, respectively. We’re especially excited about the benefits to more sustainable transportation modes, where factors beyond journey time play a substantial role. By tuning RHIP’s horizon H, we’re able to achieve a policy that is both more accurate than all other IRL policies and 70% faster than MaxEnt.
Our 360M parameter reward model provides intuitive wins for Google Maps users in live A/B experiments. Examining road segments with a large absolute difference between the learned rewards and the baseline rewards can help improve certain Google Maps routes. For example:
 |
| Nottingham, UK. The preferred route (blue) was previously marked as private property due to the presence of a large gate, which indicated to our systems that the road may be closed at times and would not be ideal for drivers. As a result, Google Maps routed drivers through a longer, alternate detour instead (red). However, because real-world driving patterns showed that users regularly take the preferred route without an issue (as the gate is almost never closed), IRL now learns to route drivers along the preferred route by placing a large positive reward on this road segment. |
Conclusion
Increasing performance via increased scale – both in terms of dataset size and model complexity – has proven to be a persistent trend in machine learning. Similar gains for inverse reinforcement learning problems have historically remained elusive, largely due to the challenges with handling practically sized MDPs. By introducing scalability advancements to classic IRL algorithms, we’re now able to train reward models on problems with hundreds of millions of states, demonstration trajectories, and model parameters, respectively. To the best of our knowledge, this is the largest instance of IRL in a real-world setting to date. See the paper to learn more about this work.
Acknowledgements
This work is a collaboration across multiple teams at Google. Contributors to the project include Matthew Abueg, Oliver Lange, Matt Deeds, Jason Trader, Denali Molitor, Markus Wulfmeier, Shawn O’Banion, Ryan Epp, Renaud Hartert, Rui Song, Thomas Sharp, Rémi Robert, Zoltan Szego, Beth Luan, Brit Larabee and Agnieszka Madurska.
We’d also like to extend our thanks to Arno Eigenwillig, Jacob Moorman, Jonathan Spencer, Remi Munos, Michael Bloesch and Arun Ahuja for valuable discussions and suggestions.
In an event at the White House today, NVIDIA announced support for voluntary commitments that the Biden Administration developed to ensure advanced AI systems are safe, secure and trustworthy. The news came the same day NVIDIA’s chief scientist, Bill Dally, testified before a U.S. Senate subcommittee seeking input on potential legislation covering generative AI. Separately, Read article >
Generative AI’s transformative effect on the auto industry took center stage last week at the International Motor Show Germany, known as IAA, in Munich. NVIDIA’s Danny Shapiro, VP of automotive marketing, explained in his IAA keynote how this driving force is accelerating innovation and streamlining processes — from advancing design, engineering and digital-twin deployment for Read article >
 Spear phishing is the largest and most costly form of cyber threat, with an estimated 300,000 reported victims in 2021 representing $44 million in reported…
Spear phishing is the largest and most costly form of cyber threat, with an estimated 300,000 reported victims in 2021 representing $44 million in reported…
Spear phishing is the largest and most costly form of cyber threat, with an estimated 300,000 reported victims in 2021 representing $44 million in reported losses in the United States alone. Business e-mail compromises led to $2.4 billion in costs in 2021, according to the FBI Internet Crime Report. In the period from June 2016 to December 2021, costs related to phishing and spear phishing totaled $43 billion for businesses, according to IBM Security Cost of a Data Breach.
Spear phishing e-mails are indistinguishable from a benign e-mail that a victim would receive. This is also why traditional classification of spear phishing e-mails is so difficult. The content difference between a scam and a legitimate e-mail can be minuscule. Often, the only difference between the two is the intent of the sender: is the invoice legitimate, or is it a scam?
This post details a two-fold approach to improve spear phishing detection by boosting the signals of intent using NVIDIA Morpheus to run data processing and inferencing.
Generating e-mails with new phishing intent
The first step involves using generative AI to create large, varied corpora of e-mails with various intents associated with spear phishing and scams. As new threats emerge, the NVIDIA Morpheus team uses the NVIDIA NeMo framework to generate a new corpus of e-mails with such threats. Following the generation of new e-mails with the new type of phishing intent, the team trains a new language model to recognize the intent. In traditional phishing detection mechanisms, such models would require a significant number of human-labeled e-mails.
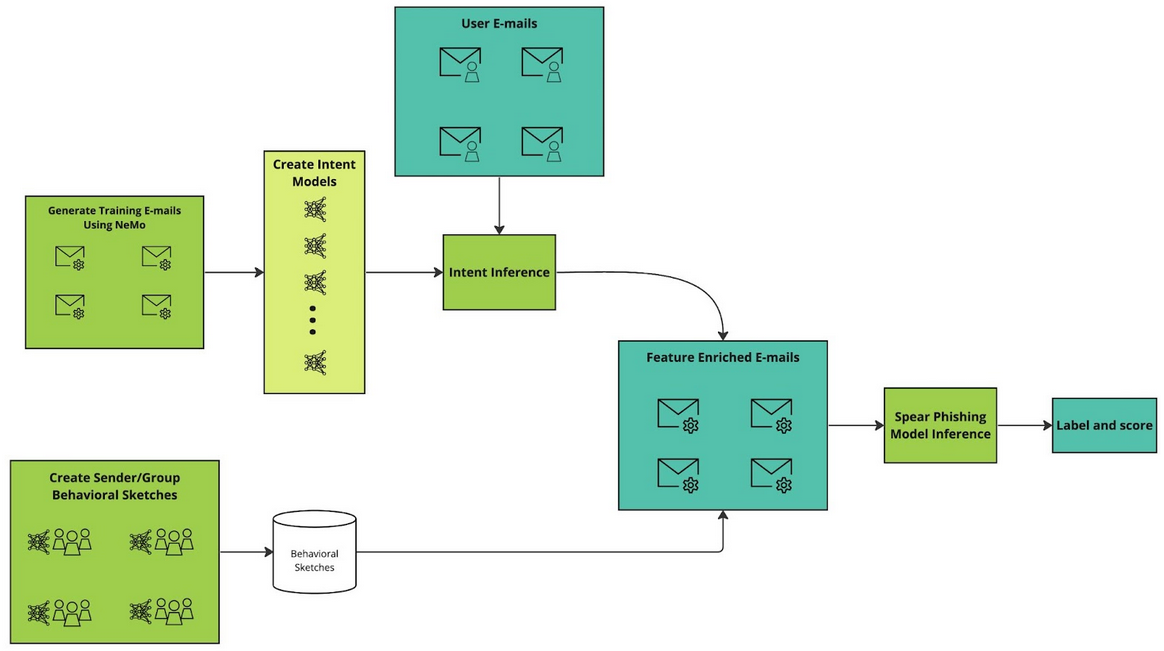
Detecting sender intent
The first step targets the intent behind the e-mail. The next step targets the intent of the sender. To defend against spear phishing attacks that use spoofing, known senders, or longer cons that do not express their true intent immediately, we construct additional signals by building up behavioral sketches from senders or groups of senders.
Building on the intent work described above, known senders’ past observed intents are recorded. For example, the first time a known sender asks for money can be a signal to alert the user.
Syntax usage is also observed and recorded. The syntax of new e-mails is compared to the syntax history of the sender. A deviation from the observed syntax could indicate a possible spoofing attack.
Finally, the temporal patterns of a sender’s e-mails are collected and cross-referenced when a new e-mail arrives to check for out-of-pattern behavior. Is the sender sending an e-mail for the first time at midnight on a Saturday? If so, that becomes a signal in the final prediction. These signals in aggregate are used to classify e-mails. They are also presented to the end user as an explanation for why an e-mail may be malicious.
Adapting to new attacks and improving protection
Existing machine learning (ML) methods rely nearly entirely on human-labeled data and cannot adapt to emerging threats quickly. The biggest benefit to detecting spear phishing e-mails using the approach presented here is how quickly the model can be adapted to new attacks. When a new attack emerges, generative AI is leveraged to create a training corpus for the attack. Intent models are trained to detect its presence in received e-mails.
Using models built with NeMo generates thousands of high-quality, on-topic e-mails in just a few hours. The new intents are added to the existing spear phishing detector. The entire end-to-end workflow of creating new phishing attack e-mails and updating the existing models happens in less than 24 hours. Once the models are in place, e-mail processing and inferencing become a Morpheus pipeline to provide near real-time protection against spear phishing threats.
Results
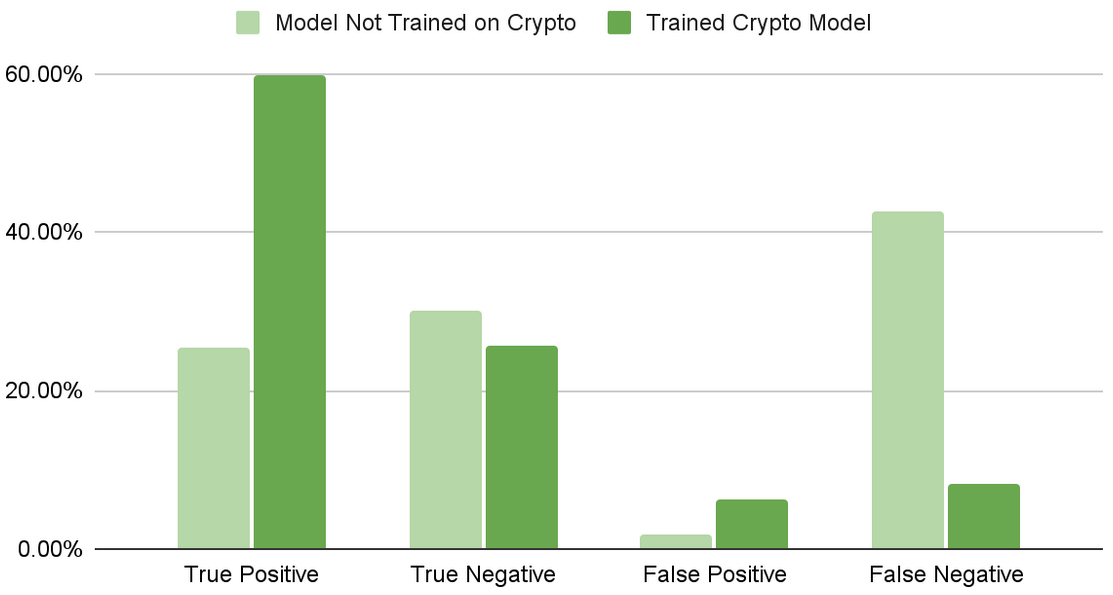
To illustrate the flexibility of this approach, a model was trained using only money, banking, and personal identifying information (PII) intents. Next, cryptocurrency-flavored phishing e-mails were generated using models built with NeMo. These e-mails were incorporated into the original training and validation subsets.
The validation set, now containing the new crypto attacks, was then passed into the original model. Then a second model was trained incorporating the crypto attack intents. Figure 2 shows how the models compare in their detection.
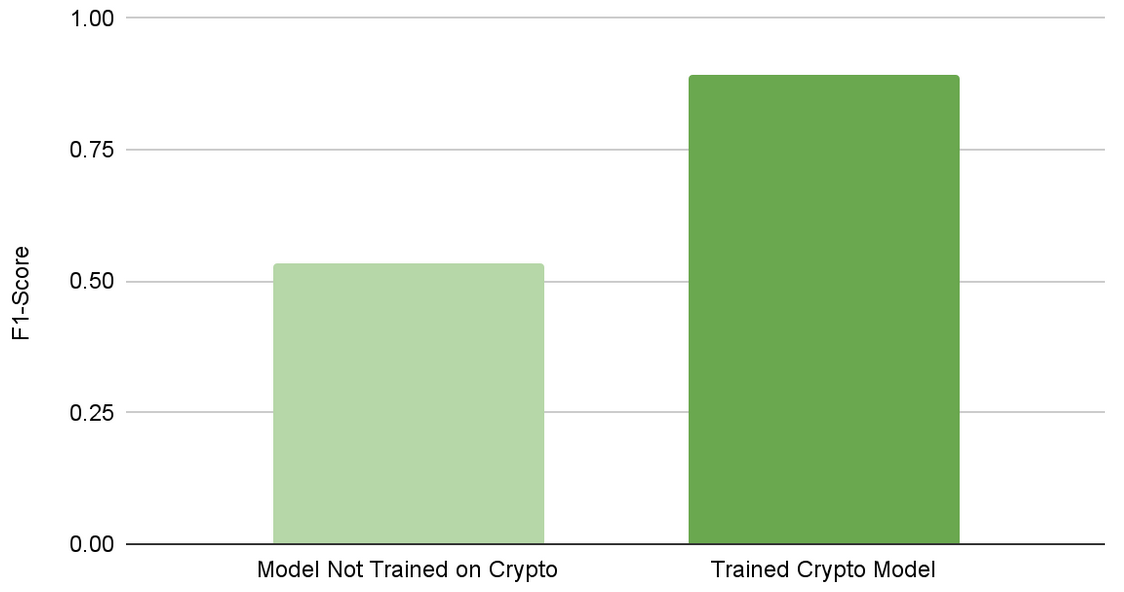
After training for the attack, the F1 score increased from 0.54 to 0.89 (Figure 3). This illustrates how quickly new attacks can be trained for and adapted to using NVIDIA Morpheus and NeMo.
Get started with NVIDIA Morpheus
Watch the video, Improve Spear Phishing Detection with Generative AI for more details. Learn more about how to use NVIDIA Morpheus to detect spear phishing e-mails faster and with greater accuracy using the NVIDIA AI workflow example. You can also apply to try NVIDIA Morpheus in LaunchPad and request a 90-day free trial to test drive NVIDIA Morpheus, part of the NVIDIA AI Enterprise software family.
 On Sept. 27, join us to learn recommender systems best practices for building, training, and deploying at any scale.
On Sept. 27, join us to learn recommender systems best practices for building, training, and deploying at any scale.
On Sept. 27, join us to learn recommender systems best practices for building, training, and deploying at any scale.