
Ten miles in from Long Island’s Atlantic coast, Shinjae Yoo is revving his engine. The computational scientist and machine learning group lead at the U.S. Department of Energy’s Brookhaven National Laboratory is one of many researchers gearing up to run quantum computing simulations on a supercomputer for the first time, thanks to new software. Yoo’s Read article >
 The camera module is the most integral part of an AI-based embedded system. With so many camera module choices on the market, the selection process may seem…
The camera module is the most integral part of an AI-based embedded system. With so many camera module choices on the market, the selection process may seem…
The camera module is the most integral part of an AI-based embedded system. With so many camera module choices on the market, the selection process may seem overwhelming. This post breaks down the process to help make the right selection for an embedded application, including the NVIDIA Jetson.
Camera selection considerations
Camera module selection involves consideration of three key aspects: sensor, interface (connector), and optics.
Sensor
The two main types of electronic image sensors are the charge-coupled device (CCD) and the active-pixel sensor (CMOS). For a CCD sensor, pixel values can only be read on a per-row basis. Each row of pixels is shifted, one by one, into a readout register. For a CMOS sensor, each pixel can be read individually and in parallel.
CMOS is less expensive and consumes less energy without sacrificing image quality, in most cases. It can also achieve higher frame rates due to the parallel readout of pixel values. However, there are some specific scenarios in which CCD sensors still prevail—for example, when long exposure is necessary and very low-noise images are required, such as in astronomy.
Electronic shutter
There are two options for the electronic shutter: global or rolling. A global shutter exposes each pixel to incoming light at the same time. A rolling shutter exposes the pixel rows in a certain order (top to bottom, for example) and can cause distortion (Figure 1).

The global shutter is not impacted by motion blur and distortion due to object movement. It is much easier to sync multiple cameras with a global shutter because there is a single point in time when exposure starts. However, sensors with a global shutter are much more expensive than those with a rolling shutter.
Color or monochrome
In most cases, a monochrome image sensor is sufficient for typical machine vision tasks like fault detection, presence monitoring, and recording measurements.
With a monochrome sensor, each pixel is usually described by eight bits. With a color sensor, each pixel has eight bits for the red channel, eight bits for the green channel, and eight bits for the blue channel. The color sensor requires processing three times the amount of data, resulting in a higher processing time and, consequently, a slower frame rate.
Dynamic range
Dynamic range is the ratio between the maximum and minimum signal that is acquired by the sensor. At the upper limit, pixels appear white for higher values of intensity (saturation), while pixels appear black at the lower limit and below. An HDR of at least 80db is needed for indoor application and up to 140db is needed for outdoor application.
Resolution
Resolution is a sensor’s ability to reproduce object details. It can be influenced by factors such as the type of lighting used, the sensor pixel size, and the capabilities of the optics. The smaller the object detail, the higher the required resolution.
Pixel resolution translates to how many millimeters each pixel is equal to on the image. The higher the resolution, the sharper your image will be. The camera or sensor’s resolution should enable coverage of a feature’s area of at least two pixels.
CMOS sensors with high resolutions tend to have low frame rates. While a sensor may achieve the resolution you need, it will not capture the quality images you need without achieving enough frames per second. It is important to evaluate the speed of the sensor.
A general rule of thumb to determine the resolution needed for the use case is shown below and in Figure 2. The multiplier (2) represents the typical desire to have a minimum two pixels on an object in order to successfully detect it.
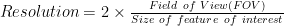
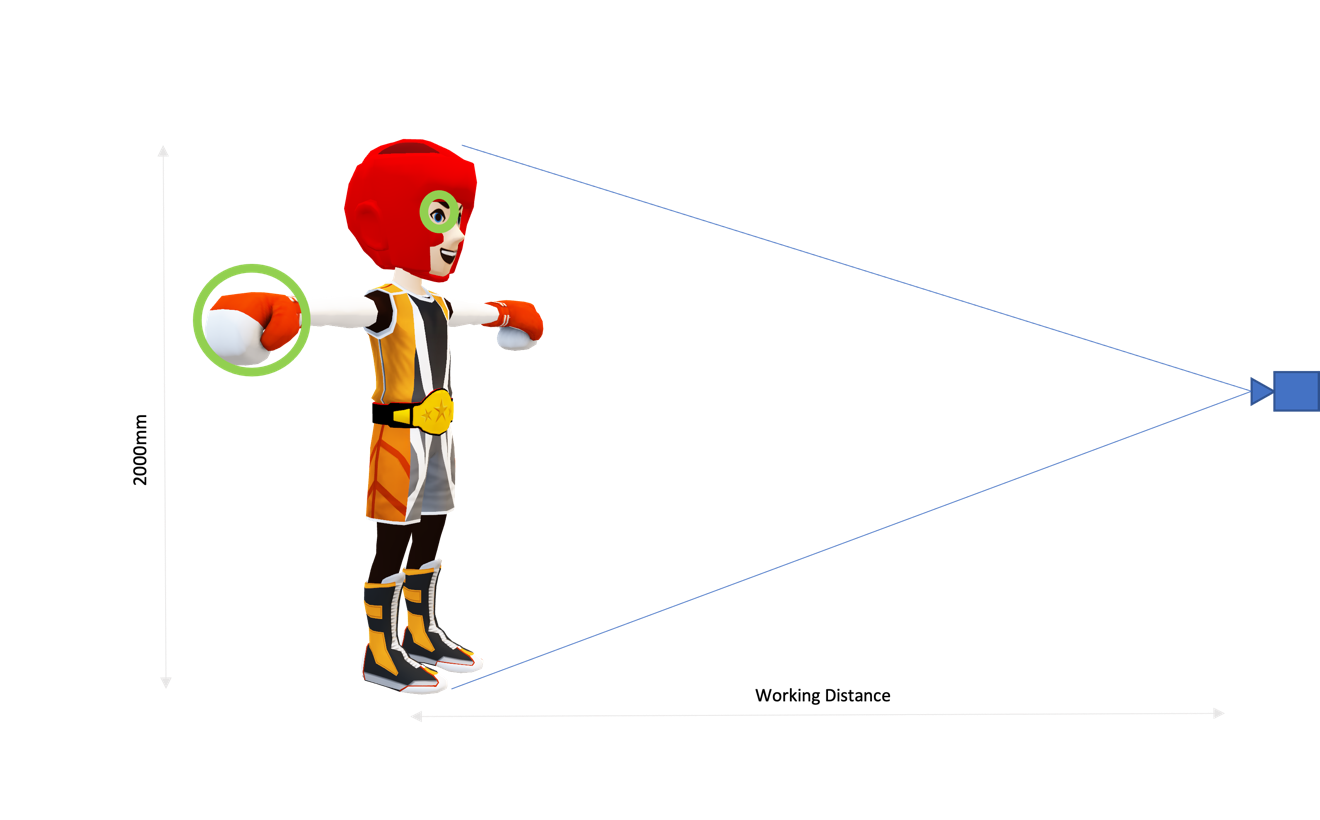
For example, suppose you have an image of an injury around the eye of a boxer.
- FOV, mm = 2000mm
- Size of feature of interest (the eye), mm = 4mm
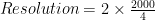
Based on the calculation, 1000 x 1000, a one-megapixel camera should be sufficient to detect the eye using a CV or AI algorithm.
Note that a sensor is made up of multiple rows of pixels. These pixels are also called photosites. The number of photons collected by a pixel is directly proportional to the size of the pixel. Selecting a larger pixel may seem tempting but may not be the optimal choice in all the cases.
| Small pixel | Sensitive to noise (-) | Higher spatial resolution for same sensor size (+) |
| Large pixel | Less sensitive to noise (+) | Less spatial resolution for same sensor size (-) |
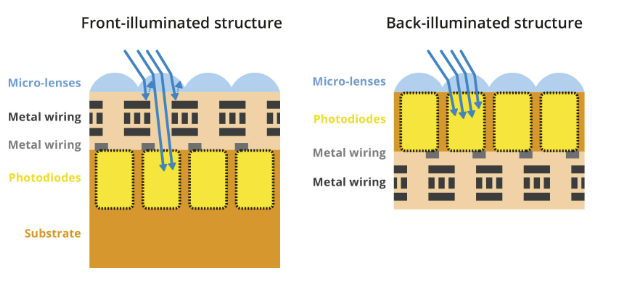
Back-illuminated sensors maximize the amount of light being captured and converted by each photodiode. In front-illuminated sensors, metal wiring above the photodiodes blocks off some photons, hence reducing the amount of light captured.
Frame rate and shutter speed
The frame rate refers to the number of frames (or images captured) per second (FPS). The frame rate should be determined based on the number of inspections required per second. This correlates with the shutter speed (or exposure time), which is the time that the camera sensor is exposed to capture the image.
Theoretically, the maximum frame rate is equal to the inverse of the exposure time. But achievable FPS is lower because of latency introduced by frame readout, sensor resolution, and the data transfer rate of the interface including cabling.
FPS can be increased by reducing the need for large exposure times by adding additional lighting, binning the pixels.
CMOS sensors can achieve higher FPS, as the process of reading out each pixel can be done more quickly than with the charge transfer in a CCD sensor’s shift register.
Interface
There are multiple ways to connect the camera module to an embedded system. Typically, for evaluation purposes, cameras with USB and Ethernet interfaces are used because custom driver development is not needed.
Other important parameters for interface selection are transmission length, data rate, and operating conditions. Table 2 lists the most popular interfaces. Each option has its pros and cons.
| Features | USB 3.2 | Ethernet (1 GbE) | MIPI CSI-2 | GMSL2 | FPDLINK III |
| Bandwidth | 10Gbps | 1Gbps | DPHY 2.5 Gbps/lane CPHY 5.71 Gbps/lane | 6Gbps | 4.2Gbps |
| Cable length supported | Up to 100m | ||||
| Plug-and-play | Supported | Supported | Not supported | Not supported | Not supported |
| Development costs | Low | Low | Medium to high | Medium to high | Medium to high |
| Operating environment | Indoor | Indoor | Indoor | Indoor and outdoor | Indoor and outdoor |
Optics
The basic purpose of an optical lens is to collect the light scattered by an object and recreate an image of the object on a light-sensitive image sensor (CCD or CMOS). The following factors should be considered when selecting an optimized lens-focal length, sensor format, field of view, aperture, chief ray angle, resolving power, and distortion.
Lenses are manufactured with a limited number of standard focal lengths. Common lens focal lengths include 6mm, 8mm, 12.5mm, 25mm, and 50mm.
Once you choose a lens with a focal length closest to the focal length required by your imaging system, you need to adjust the working distance to get the object under inspection in focus. Lenses with short focal lengths (less than 12mm) produce images with a significant amount of distortion.
If your application is sensitive to image distortion, try to increase the working distance and use a lens with a higher focal length. If you cannot change the working distance, you are somewhat limited in choosing an optimized lens.
| Wide-angle lens | Normal lens | Telephoto lens | |
| Focal length | 50mm | >=70mm | |
| Use case | Nearby scenes | Same as human eye | Far-away scenes |
To attach a lens to a camera requires some type of mounting system. Both mechanical stability (a loose lens will deliver an out-of-focus image) and the distance to the sensor must be defined.
To ensure compatibility between different lenses and cameras, the following standard lens mounts are defined.
| Most popular | For industrial applications | |
| Lens mount | M12/S mount | C-mount |
| Flange focal length | Non-standard | 17.526mm |
| Threads (per mm) | 0.5 | 0.75 |
| Sensor size accommodated (inches) | Up to ⅔ | Up to 1 |
NVIDIA camera module partners
NVIDIA maintains a rich ecosystem of partnerships with highly competent camera module makers all over the world. See Jetson Partner Supported Cameras for details. These partners can help you design imaging systems for your application from concept to production for the NVIDIA Jetson.

Summary
This post has explained the most important camera characteristics to consider when selecting a camera for an embedded application. Although the selection process may seem daunting, the first step is to understand your key constraints based on design, performance, environment, and cost.
Once you understand the constraints, then focus on the characteristics most relevant to your use case. For example, if the camera will be deployed away from the compute or in a rugged environment, consider using the GMSL interface. If the camera will be used in low-light conditions, consider a camera module with larger pixel and sensor sizes. If the camera will be used in a motion application, consider using a camera with a global shutter.
To learn more, watch Optimize Your Edge Application: Unveiling the Right Combination of Jetson Processors and Cameras. For detailed specs on AI performance, GPU, CPU, and more for both Xavier and Orin-based Jetson modules, visit Jetson Modules.
Editor’s note: This post is part of our weekly In the NVIDIA Studio series, which celebrates featured artists, offers creative tips and tricks and demonstrates how NVIDIA Studio technology improves creative workflows. When it comes to converting 2D concepts into 3D masterpieces, self-taught visual development artist Alex Treviño has confidence in the potential of all Read article >
 Explore how ray-traced caustics combined with NVIDIA RTX features can enhance the performance of your games.
Explore how ray-traced caustics combined with NVIDIA RTX features can enhance the performance of your games.
Explore how ray-traced caustics combined with NVIDIA RTX features can enhance the performance of your games.
Categories
Differentially private median and more
Differential privacy (DP) is a rigorous mathematical definition of privacy. DP algorithms are randomized to protect user data by ensuring that the probability of any particular output is nearly unchanged when a data point is added or removed. Therefore, the output of a DP algorithm does not disclose the presence of any one data point. There has been significant progress in both foundational research and adoption of differential privacy with contributions such as the Privacy Sandbox and Google Open Source Library.
ML and data analytics algorithms can often be described as performing multiple basic computation steps on the same dataset. When each such step is differentially private, so is the output, but with multiple steps the overall privacy guarantee deteriorates, a phenomenon known as the cost of composition. Composition theorems bound the increase in privacy loss with the number k of computations: In the general case, the privacy loss increases with the square root of k. This means that we need much stricter privacy guarantees for each step in order to meet our overall privacy guarantee goal. But in that case, we lose utility. One way to improve the privacy vs. utility trade-off is to identify when the use cases admit a tighter privacy analysis than what follows from composition theorems.
Good candidates for such improvement are when each step is applied to a disjoint part (slice) of the dataset. When the slices are selected in a data-independent way, each point affects only one of the k outputs and the privacy guarantees do not deteriorate with k. However, there are applications in which we need to select the slices adaptively (that is, in a way that depends on the output of prior steps). In these cases, a change of a single data point may cascade — changing multiple slices and thus increasing composition cost.
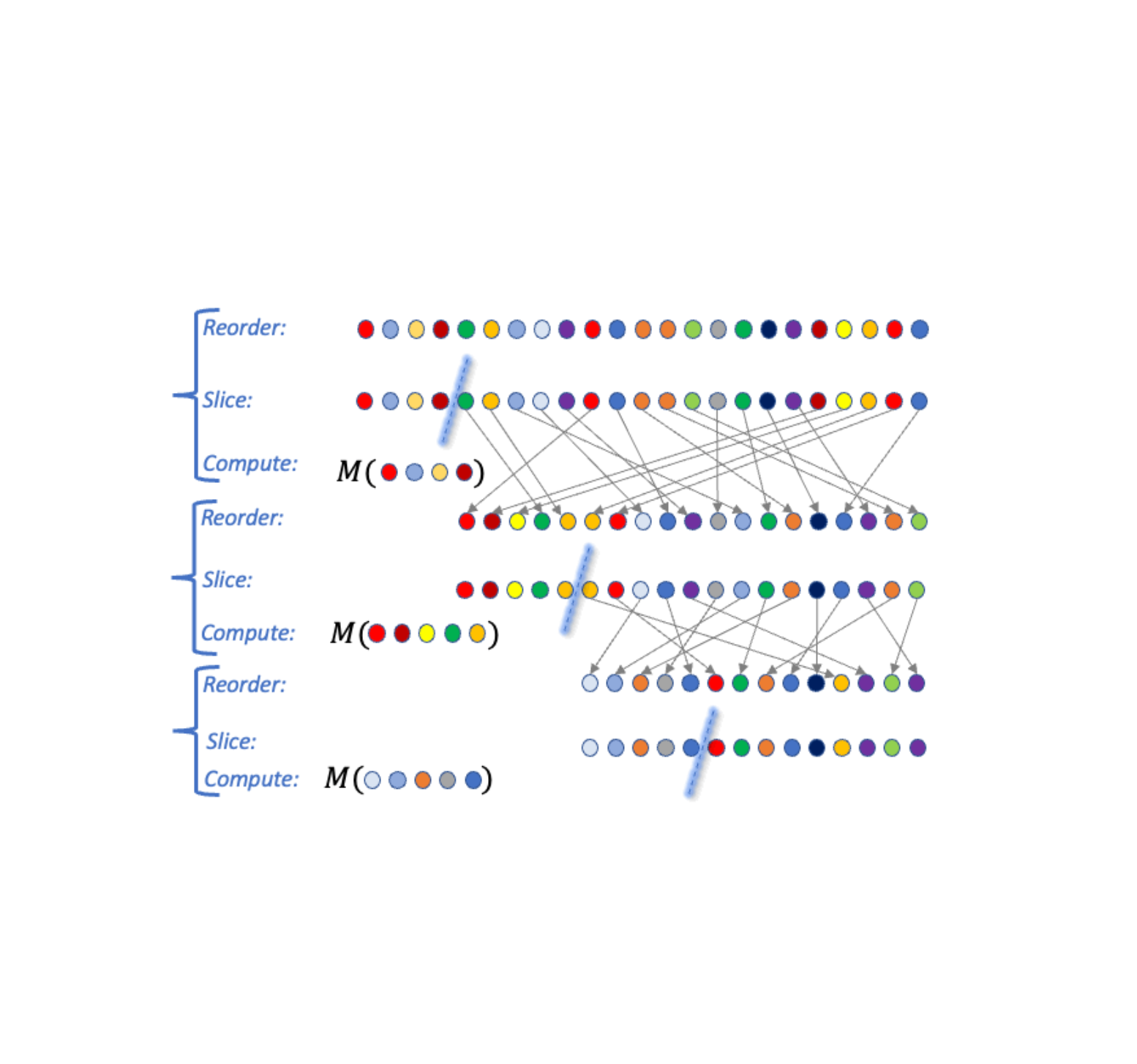
In “Õptimal Differentially Private Learning of Thresholds and Quasi-Concave Optimization”, presented at STOC 2023, we describe a new paradigm that allows for slices to be selected adaptively and yet avoids composition cost. We show that DP algorithms for multiple fundamental aggregation and learning tasks can be expressed in this Reorder-Slice-Compute (RSC) paradigm, gaining significant improvements in utility.
The Reorder-Slice-Compute (RSC) paradigm
An algorithm A falls in the RSC paradigm if it can be expressed in the following general form (see visualization below). The input is a sensitive set D of data points. The algorithm then performs a sequence of k steps as follows:
- Select an ordering over data points, a slice size m, and a DP algorithm M. The selection may depend on the output of A in prior steps (and hence is adaptive).
- Slice out the (approximately) top m data points according to the order from the dataset D, apply M to the slice, and output the result.
 |
| A visualization of three Reorder-Slice-Compute (RSC) steps. |
If we analyze the overall privacy loss of an RSC algorithm using DP composition theorems, the privacy guarantee suffers from the expected composition cost, i.e., it deteriorates with the square root of the number of steps k. To eliminate this composition cost, we provide a novel analysis that removes the dependence on k altogether: the overall privacy guarantee is close to that of a single step! The idea behind our tighter analysis is a novel technique that limits the potential cascade of affected steps when a single data point is modified (details in the paper).
Tighter privacy analysis means better utility. The effectiveness of DP algorithms is often stated in terms of the smallest input size (number of data points) that suffices in order to release a correct result that meets the privacy requirements. We describe several problems with algorithms that can be expressed in the RSC paradigm and for which our tighter analysis improved utility.
Private interval point
We start with the following basic aggregation task. The input is a dataset D of n points from an ordered domain X (think of the domain as the natural numbers between 1 and |X|). The goal is to return a point y in X that is in the interval of D, that is between the minimum and the maximum points in D.
The solution to the interval point problem is trivial without the privacy requirement: simply return any point in the dataset D. But this solution is not privacy-preserving as it discloses the presence of a particular datapoint in the input. We can also see that if there is only one point in the dataset, a privacy-preserving solution is not possible, as it must return that point. We can therefore ask the following fundamental question: What is the smallest input size N for which we can solve the private interval point problem?
It is known that N must increase with the domain size |X| and that this dependence is at least the iterated log function log* |X| [1, 2]. On the other hand, the best prior DP algorithm required the input size to be at least (log* |X|)1.5. To close this gap, we designed an RSC algorithm that requires only an order of log* |X| points.
The iterated log function is extremely slow growing: It is the number of times we need to take a logarithm of a value before we reach a value that is equal to or smaller than 1. How did this function naturally come out in the analysis? Each step of the RSC algorithm remapped the domain to a logarithm of its prior size. Therefore there were log* |X| steps in total. The tighter RSC analysis eliminated a square root of the number of steps from the required input size.
Even though the interval point task seems very basic, it captures the essence of the difficulty of private solutions for common aggregation tasks. We next describe two of these tasks and express the required input size to these tasks in terms of N.
Private approximate median
One of these common aggregation tasks is approximate median: The input is a dataset D of n points from an ordered domain X. The goal is to return a point y that is between the ⅓ and ⅔ quantiles of D. That is, at least a third of the points in D are smaller or equal to y and at least a third of the points are larger or equal to y. Note that returning an exact median is not possible with differential privacy, since it discloses the presence of a datapoint. Hence we consider the relaxed requirement of an approximate median (shown below).
We can compute an approximate median by finding an interval point: We slice out the N smallest points and the N largest points and then compute an interval point of the remaining points. The latter must be an approximate median. This works when the dataset size is at least 3N.
 |
| An example of a data D over domain X, the set of interval points, and the set of approximate medians. |
Private learning of axis-aligned rectangles
For the next task, the input is a set of n labeled data points, where each point x = (x1,….,xd) is a d-dimensional vector over a domain X. Displayed below, the goal is to learn values ai , bi for the axes i=1,…,d that define a d-dimensional rectangle, so that for each example x
- If x is positively labeled (shown as red plus signs below) then it lies within the rectangle, that is, for all axes i, xi is in the interval [ai ,bi], and
- If x is negatively labeled (shown as blue minus signs below) then it lies outside the rectangle, that is, for at least one axis i, xi is outside the interval [ai ,bi].
 |
| A set of 2-dimensional labeled points and a respective rectangle. |
Any DP solution for this problem must be approximate in that the learned rectangle must be allowed to mislabel some data points, with some positively labeled points outside the rectangle or negatively labeled points inside it. This is because an exact solution could be very sensitive to the presence of a particular data point and would not be private. The goal is a DP solution that keeps this necessary number of mislabeled points small.
We first consider the one-dimensional case (d = 1). We are looking for an interval [a,b] that covers all positive points and none of the negative points. We show that we can do this with at most 2N mislabeled points. We focus on the positively labeled points. In the first RSC step we slice out the N smallest points and compute a private interval point as a. We then slice out the N largest points and compute a private interval point as b. The solution [a,b] correctly labels all negatively labeled points and mislabels at most 2N of the positively labeled points. Thus, at most ~2N points are mislabeled in total.
 |
| Illustration for d = 1, we slice out N left positive points and compute an interval point a, slice out N right positive points and compute an interval point b. |
With d > 1, we iterate over the axes i = 1,….,d and apply the above for the ith coordinates of input points to obtain the values ai , bi. In each iteration, we perform two RSC steps and slice out 2N positively labeled points. In total, we slice out 2dN points and all remaining points were correctly labeled. That is, all negatively-labeled points are outside the final d-dimensional rectangle and all positively-labeled points, except perhaps ~2dN, lie inside the rectangle. Note that this algorithm uses the full flexibility of RSC in that the points are ordered differently by each axis. Since we perform d steps, the RSC analysis shaves off a factor of square root of d from the number of mislabeled points.
Training ML models with adaptive selection of training examples
The training efficiency or performance of ML models can sometimes be improved by selecting training examples in a way that depends on the current state of the model, e.g., self-paced curriculum learning or active learning.
The most common method for private training of ML models is DP-SGD, where noise is added to the gradient update from each minibatch of training examples. Privacy analysis with DP-SGD typically assumes that training examples are randomly partitioned into minibatches. But if we impose a data-dependent selection order on training examples, and further modify the selection criteria k times during training, then analysis through DP composition results in deterioration of the privacy guarantees of a magnitude equal to the square root of k.
Fortunately, example selection with DP-SGD can be naturally expressed in the RSC paradigm: each selection criteria reorders the training examples and each minibatch is a slice (for which we compute a noisy gradient). With RSC analysis, there is no privacy deterioration with k, which brings DP-SGD training with example selection into the practical domain.
Conclusion
The RSC paradigm was introduced in order to tackle an open problem that is primarily of theoretical significance, but turns out to be a versatile tool with the potential to enhance data efficiency in production environments.
Acknowledgments
The work described here was done jointly with Xin Lyu, Jelani Nelson, and Tamas Sarlos.
In its debut on the MLPerf industry benchmarks, the NVIDIA GH200 Grace Hopper Superchip ran all data center inference tests, extending the leading performance of NVIDIA H100 Tensor Core GPUs. The overall results showed the exceptional performance and versatility of the NVIDIA AI platform from the cloud to the network’s edge. Separately, NVIDIA announced inference Read article >
") Moment Factory is a global multimedia entertainment studio that combines specializations in video, lighting, architecture, sound, software, and interactivity to…
Moment Factory is a global multimedia entertainment studio that combines specializations in video, lighting, architecture, sound, software, and interactivity to…
Moment Factory is a global multimedia entertainment studio that combines specializations in video, lighting, architecture, sound, software, and interactivity to create immersive experiences for audiences around the world.
From live performances and multimedia shows to interactive installations, Moment Factory is known for some of the most awe-inspiring and entertaining experiences that bring people together in the real world. These include dazzling visuals at Billie Eilish’s Happier Than Ever world tour, Lumina Night Walks at natural sites around the world, and digital placemaking at the AT&T Discovery District.
With a team of over 400 professionals and offices in Montreal, Tokyo, Paris, New York City, and Singapore, Moment Factory has become a global leader in the entertainment industry.

Streamlining immersive experience development with OpenUSD
Bringing these experiences to life requires large teams of highly skilled experts with diverse specialties, all using unique tools. To achieve optimal efficiency in their highly complex production processes, Moment Factory looked to implement an interoperable open data format and development platform that could seamlessly integrate all aspects, from concept to operation.
Moment Factory chose Universal Scene Description, also known as OpenUSD, as the solution. OpenUSD is an extensible framework and ecosystem for describing, composing, simulating, and collaborating within 3D worlds. NVIDIA Omniverse is a software platform that enables teams to develop OpenUSD-based 3D workflows and applications. It provides the unified environment to visualize and collaborate on digital twins in real time with live connections to Moment Factory’s tools.
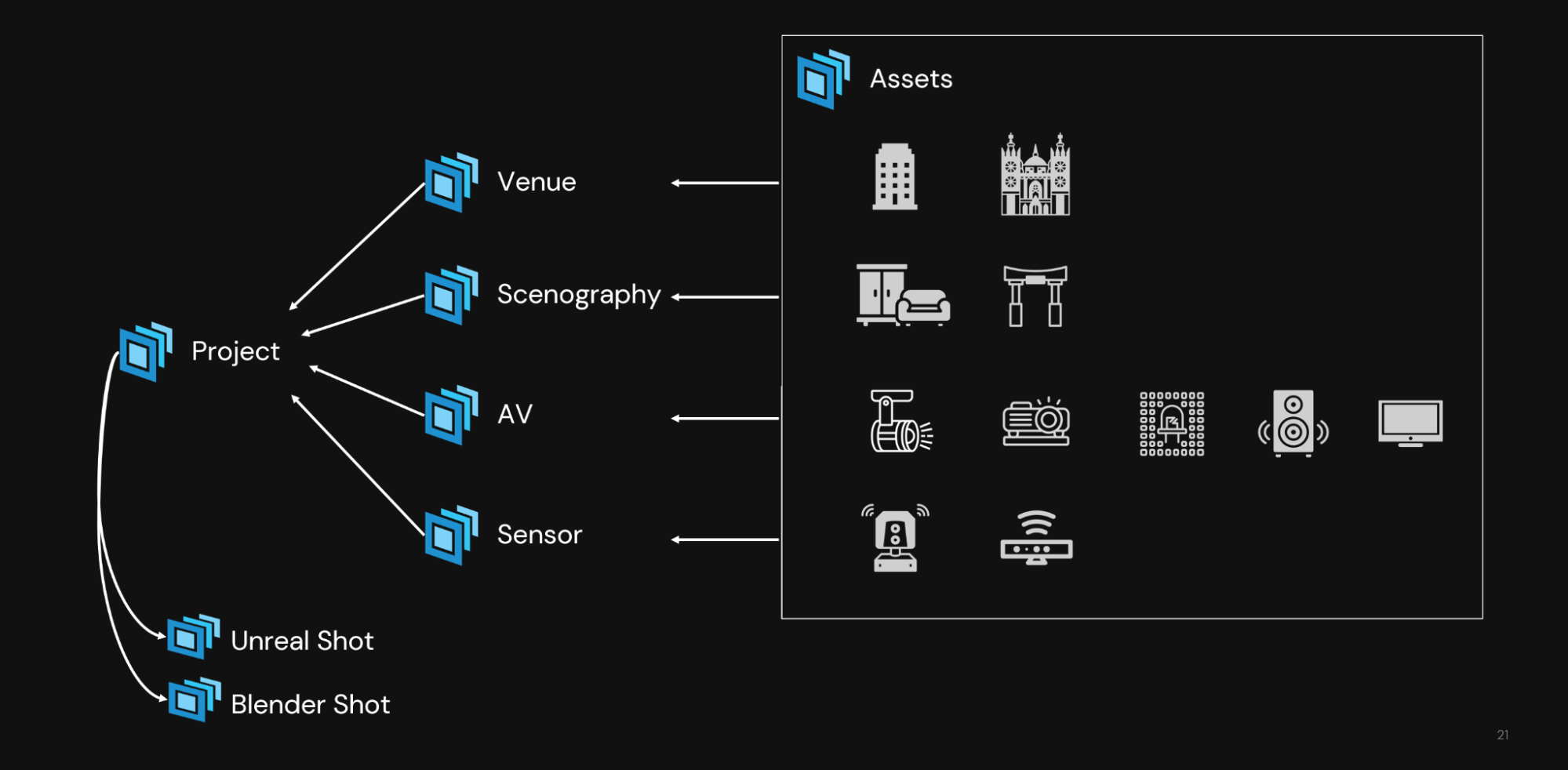
Using OpenUSD with Omniverse enables Moment Factory to unify data from their diverse digital content creation (DCC) tools to form a digital twin of a real-world environment. Every member of the team can interact with this digital twin and iterate on their aspect of the project without affecting other elements
For example, a scenographer can work on a base set and unique scene pieces using Vectorworks, 3D design software. At the same time in the same scene, an AV (audio visual) and lighting designer can take care of lighting and projectors with Moment Factory’s proprietary live entertainment operating system and virtual projection mapping software, X-Agora.
Simultaneously, artists and designers can render and create eye-catching visuals in the scene using tools like Epic Games Unreal Engine, Blender, and Adobe Photoshop—without affecting layers of the project still in progress.
“USD is unique in that it can be fragmented into smaller pieces that enable people to work on their own unique parts of a project while staying connected,” said Arnaud Grosjean, solution architect and project lead for Moment Factory’s Innovation Team. “Its flexibility and interoperability allows us to create powerful, custom 3D pipelines.”
Digital twins simulate real-world experiences
To simulate immersive events before deploying them in the real world, Moment Factory is developing digital twins of their installations in NVIDIA Omniverse. Omniverse, a computing platform that enables teams to develop OpenUSD-based 3D workflows and applications, provides the unified environment to visualize and collaborate on digital twins in real time with live connections to DCC tools.
The first digital twin they’ve created is that of Blackbox, which serves as an experimentation and prototyping space where they can preview fragments of immersive experiences before real-world deployment. It is a critical space for nearly every phase of the project lifecycle, from conception and design to integration and operation.
To build the digital twin of the Blackbox, Moment Factory used USD Composer, a fully customizable foundation application built on NVIDIA Omniverse.

The virtual replica of the installation enables the team to run innumerable iterations on the project to test for various factors. They can also better sell concepts for immersive experiences to prospective customers, who can see the show before live production in a virtual environment.
One of the key challenges in the process for building large-scale immersive experiences is reaching a consensus among various stakeholders and managing changes.
“Everyone has their own idea of how a scene should be structured, so we needed a way to align everyone contributing to the project in a unified, dynamic environment” explained Grosjean. “With the digital twin, potential ideas can be tested and simulated with stakeholders across every core expertise.”
As CAD drafters, AV designers, interactive designers, and others contribute to the digital twin of the Blackbox, artists and 2D/3D designers can render and experiment with beauty shots of the immersive experience in action.
To see the digital twin of the Blackbox in action, join the Omniverse Livestream with Moment Factory on Wednesday, September 13.
Developing Omniverse Connectors and extensions
Moment Factory is continuously building and testing extensions for Omniverse to bring new functionalities and possibilities into their digital twins.
They developed an Omniverse Connector for X-Agora, their proprietary multi-display software that allows you to design, plan and operate shows. The software now has a working implementation of a Nucleus connection, USD import/export, and an early live mode implementation.
Video projection is a key element of immersive events. The team will often experiment with mapping and projecting visual content onto architectural surfaces, scenic elements, and sometimes even moving objects, transforming static spaces into dynamic and captivating environments.
NDI, which stands for Network Design Interface, is a popular IP video protocol developed by NewTek that allows for efficient live video production and streaming across interconnected devices and systems. In their immersive experiences, Moment Factory typically connects a media system to physical projectors using video cables. With NDI, they can replicate this connection within a virtual venue, effectively simulating the entire experience digitally.
To enable seamless connectivity between the Omniverse RTX Renderer and their creative content, Moment Factory developed an NDI extension for Omniverse. The extension supports more than just video projection and allows the team to simulate LED walls, screens, and pixel fields to mirror their real-world setup in the digital twin.
The extension, which was developed with Omniverse Kit, also enables users to use video feeds as dynamic textures. Developers at Moment Factory used the kit-cv-video-example and kit-dynamic texture-example to develop the extension.
Anyone can access and use Moment Factory’s Omniverse-NDI-extension on GitHub, and install it on the Omniverse Launcher or launch with:
$ ./link_app.bat --app create
$ ./app/omni.create.bat --/rtx/ecoMode/enabled=false --ext-folder exts --enable mf.ov.ndi
Extensions in Omniverse serve as reusable components or tools that developers can build to accelerate and add new functionalities for 3D workflows. They can be built for simple tasks like randomizing objects or used to enable more complex workflows like visual scripting.
The team also developed an extension for converting MPDCI, a VESA standard describing multiprojector rigs, to USD called the Omniverse-MPCDI-converter. They are currently testing extensions for MVR (My Virtual Rig) and GDTF (General Device Type Format) Converters to import lighting fixtures and rigs into their digital twins.
Even more compelling is a lidar UDP simulator extension, which is being developed to enable sensor simulation in Omniverse and connect synthetic data to lidar-compatible software.
You can use Moment Factory’s NDI and MPDCI extensions today in your workflows. Stay tuned for new extensions coming soon.
To build extensions like Moment Factory, get started with all the Omniverse Developer Resources you’ll need, like documentation, tutorials, USD resources, GitHub samples, and more.
Get started with NVIDIA Omniverse by downloading the standard license free, or learn how Omniverse Enterprise can connect your team.
Developers can check out these Omniverse resources to begin building on the platform.
Stay up to date on the platform by subscribing to the newsletter and following NVIDIA Omniverse on Instagram, LinkedIn, Medium, Threads, and Twitter.
For more, check out our forums, Discord server, Twitch, and YouTube channels.
 In the AI landscape of 2023, vector search is one of the hottest topics due to its applications in large language models (LLM) and generative AI. Semantic…
In the AI landscape of 2023, vector search is one of the hottest topics due to its applications in large language models (LLM) and generative AI. Semantic…
In the AI landscape of 2023, vector search is one of the hottest topics due to its applications in large language models (LLM) and generative AI. Semantic vector search enables a broad range of important tasks like detecting fraudulent transactions, recommending products to users, using contextual information to augment full-text searches, and finding actors that pose potential security risks.
Data volumes continue to soar and traditional methods for comparing items one by one have become computationally infeasible. Vector search methods use approximate lookups, which are more scalable and can handle massive amounts of data more efficiently. As we show in this post, accelerating vector search on the GPU provides not only faster search times, but the index building times can also be substantially faster.
This post provides:
- An introduction to vector search with a brief review of popular applications
- An overview of the RAFT library for accelerating vector search on the GPU
- Performance comparison of GPU-accelerated vectors search indexes against the state-of-the-art on the CPU
The second post in this series dives deeper into each of the GPU-accelerated indexes mentioned in this post and gives a brief explanation of how the algorithms work, along with a summary of important parameters to fine-tune their behavior. For more information, see Accelerating Vector Search: Fine-Tuning GPU Index Algorithms.
What is vector search?

Figure 1 shows that vector search entails creating an index of vectors and performing lookups to find some number of vectors in the index that are closest to a query vector. The vectors could be as small as three-dimensional points from a lidar point cloud or larger embeddings from text documents, images, or videos.
Vector search is the process of querying a database to find the most similar vectors. This similarity search is done on numerical vectors that can represent any type of object (Figure 2). These vectors are often embeddings created from multimedia like images, video, and text fragments or entire documents that went through a deep learning model to encode their semantic characteristics into a vector form.
Embedding vectors typically have the advantage of being a smaller object than the original document (lower dimensionality), while maintaining as much information about the source as possible. Therefore, two documents that are similar often have similar embeddings.
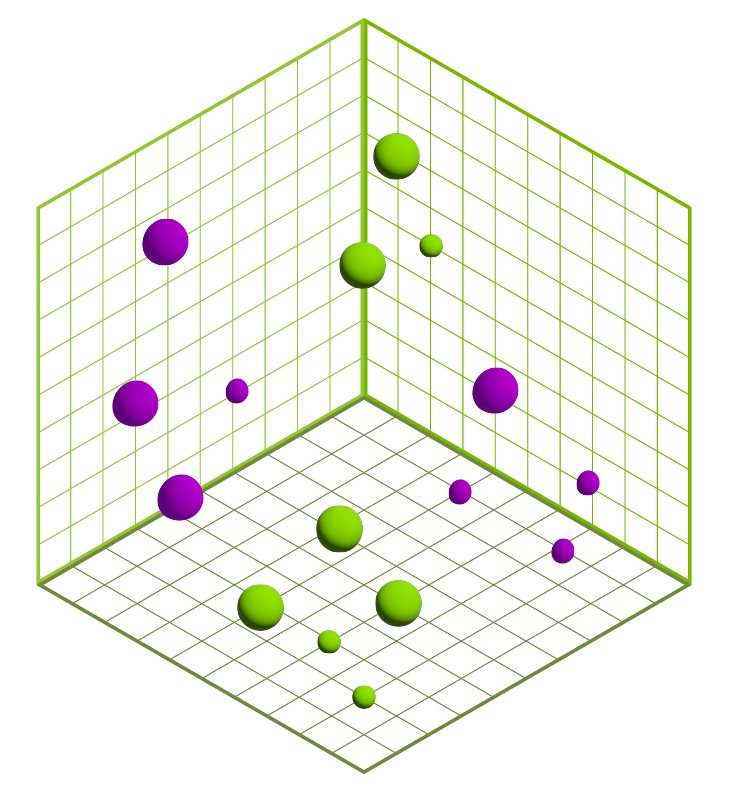
The points in Figure 2 are 3D but they could be 500 dimensions or even higher.
This makes it easier to compare objects, as the embedding vectors are smaller and retain most of the information. When two documents share similar characteristics, their embedding vectors are often spatially close, or similar.
Approximate methods for vector search
To handle larger datasets efficiently, approximate nearest neighbor (ANN) methods are often used for vector search. ANN methods speed up the search by approximating the closest vectors. This avoids the exhaustive distance computation often required by an exact brute-force approach, which requires comparing the query against every single vector in the database.
In addition to the search compute cost, storing many vectors can also consume a large amount of memory. To ensure both fast searches and low memory usage, you must index vectors in an efficient way. As we outline a bit later, this can sometimes benefit from compression. A vector index is a space-efficient data structure built on mathematical models that is used for efficiently querying several vectors at a time.
Updating the indexes, such as from inserting and deleting vectors, can cause problems when indexes take hours or even days to build. It turns out that these indexes can often be built much faster on the GPU. We showcase this performance later in the post.
Vector search in LLMs
LLMs have become popular for capturing and preserving the semantic meaning and context of the original documents. This means that the vectors resulting from LLM models can be searched using vector similarity search. This search finds items that happen to contain similar words, shapes, or moving objects. It also finds vectors that contextually and semantically mean similar things.
This semantic search doesn’t rely on exact word matching. For example, searching for the term, “I would like to buy a muscle car” in an image database should be able to contextualize the sentence to understand the following:
- Buying a car is different from renting a car, so you’d expect to find vectors closer to car dealerships and reviews from car purchasers, rather than car rental companies.
- A muscle car is different from a bodybuilder so you’d expect to find vectors about Dodge Chargers and not Arnold Schwarzenegger.
- Buying a muscle car is different from buying muscle relaxers or economy vehicles.
More recently, large language transformer-based models like ChatGPT, LLaMa, NeMo, and BERT have provided significant technical leaps that are increasing the contextual awareness of the models and making them even more useful and applicable to more industries.
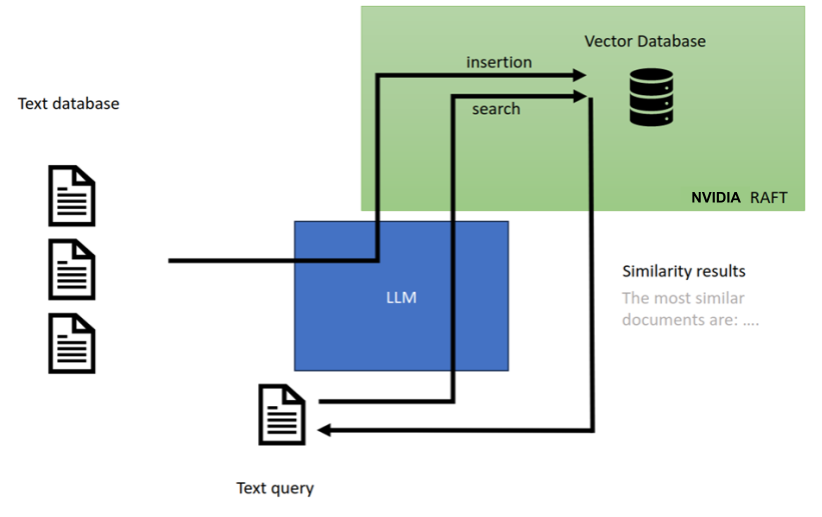
In addition to creating embedding vectors that can be stored and later searched, these new LLM models use semantic search in pipelines that generate new content from context gleaned by finding similar vectors. This content generation process, shown in Figure 3, is known as retrieval-augmented generative AI.
Using vector search in a vector database
A vector database stores high-dimensional vectors (for example, embeddings), and facilitates fast and accurate search and retrieval based on vector similarity (for example, ANN algorithms). Some databases are purpose-built for vector search (for example, Milvus). Other databases include vector search capabilities as an additional feature (for example, Redis).
Choosing which vector database to use depends on the requirements of your workflow.
Retrieval-augmented language models allow pretrained models to be customized for specific products, services, or other domain-specific use cases by augmenting a search with additional context that has been encoded into vectors by the LLM and stored in a vector database.
More specifically, a search is encoded into vector form and similar vectors are found in the vector database to augment the search. The vectors are then used with the LLM to formulate an appropriate response. Retrieval-augmented LLMs are a form of generative AI and they have revolutionized the industry of chatbots and semantic text search.
Other applications of vector similarity search
In addition to retrieval-augmented LLMs for generative AI, vector embeddings have been around for some time and have found many useful applications in the real world:
- Recommender systems: Provide personalized suggestions according to what a user has shown interest in or interacted with.
- Finance: Fraud detection models vectorize user transactions, making it possible to determine whether those transactions are similar to typical fraudulent activities.
- Cybersecurity: Uses embeddings to model and search behaviors of bad actors and anomalous activities.
- Genomics: Finds similar genes and cell structures in genomics analysis, such as single-cell RNA analysis.
- Chemistry: Models molecular descriptors or fingerprints of chemical structures to compare them or find similar structures in a database.
We are always interested in learning about your use cases so don’t hesitate to leave a comment if you either use vector search already or would like to discuss how it could benefit your application.
RAPIDS RAFT library for vector search
RAFT is a library of composable building blocks for accelerating machine learning algorithms on the GPU, such as those used in nearest neighbors and vector search. ANN algorithms are among the core building blocks that comprise vector search libraries. Most importantly, these algorithms can greatly benefit from GPU acceleration.
For more information about RAFT’s core APIs and the various accelerated building blocks that it contains, see Reusable Computational Patterns for Machine Learning and Data Analytics with RAPIDS RAFT.
ANN for fast searches
In addition to brute-force for exact search, RAFT currently provides three different algorithms for ANN search:
- IVF-Flat
- IVF-PQ
- CAGRA
The choice of the algorithm can depend upon your needs, as they each offer different advantages. Sometimes, brute force can even be the better option. More are being added in upcoming releases.
Because these algorithms are not doing an exact search, it is possible that some highly similar vectors are missed. The recall metric can be used to represent how many neighbors in the results are actual nearest neighbors of the query. Most of our benchmarks target recall levels of 85% and higher, meaning 85% (or more) of the relevant vectors were retrieved.
To tune the resulting indexes for different levels of recall, use various settings, or hyperparameters, when training approximate nearest-neighbors algorithms. Reducing the recall score often increases the speed of your searches and increasing the recall decreases the speed. This is known as the recall-speed tradeoff.
For more information, see Accelerating Vector Search: Fine-Tuning GPU Index Algorithms.
Performance comparison
GPUs excel at processing a lot of data at one time. All the algorithms just mentioned can outperform corresponding algorithms on the CPU when computing the nearest neighbors for thousands or tens of thousands of points at a time.
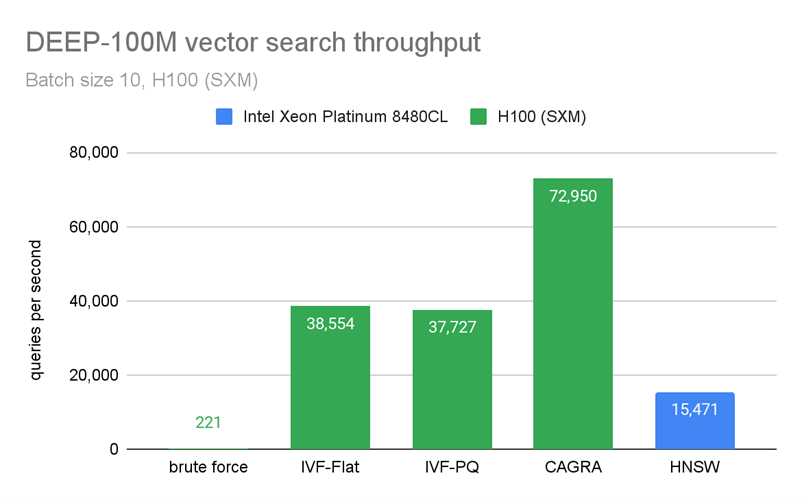
However, CAGRA was specifically engineered with online search in mind, which means that it outperforms the CPU even when only querying the nearest neighbors for a few data points at a time.
Figure 4 and Figure 5 show benchmarks that we performed by building an index on 100M vectors and querying only 10 vectors at a time. In Figure 4, CAGRA outperforms HNSW, which is one of the most popular indexes for vector search on CPU, in raw search performance even for an extremely small batch size of 10 vectors. This speed comes at a memory cost, however. In Figure 5, you can see that CAGRA’s memory footprint is a bit higher than the other nearest neighbors methods.
In Figure 5, the host memory of IVF-PQ is for the optional refinement step.
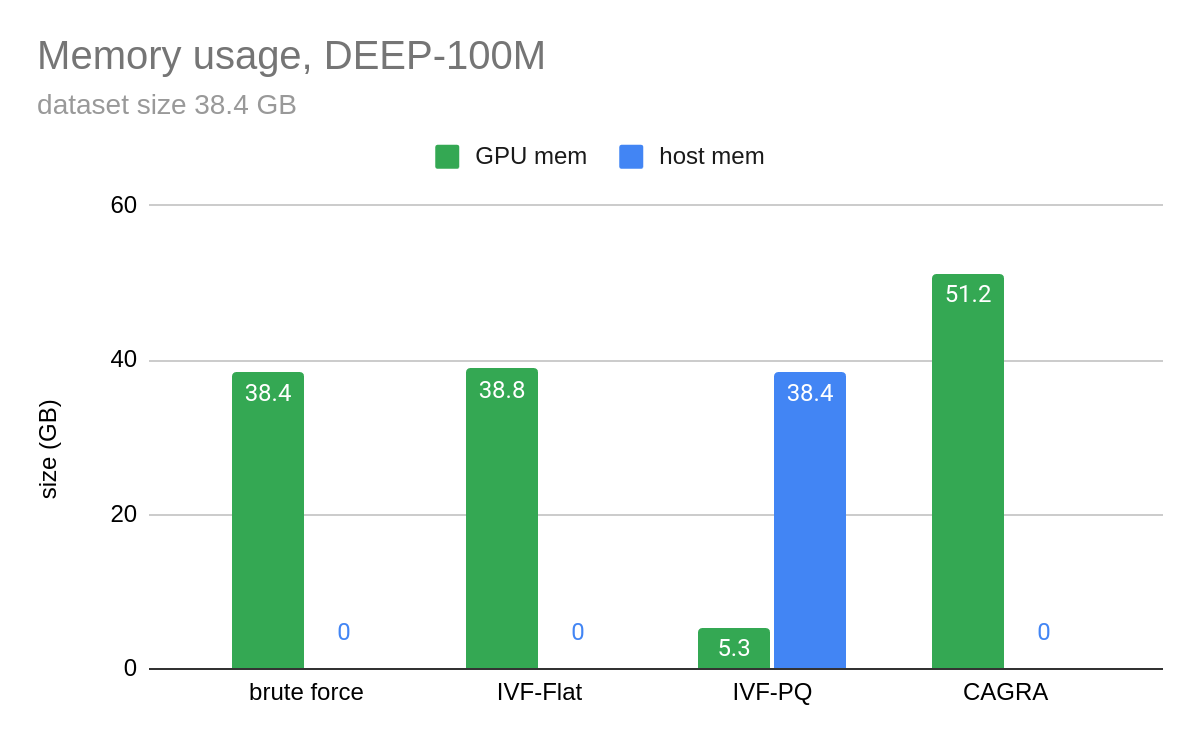
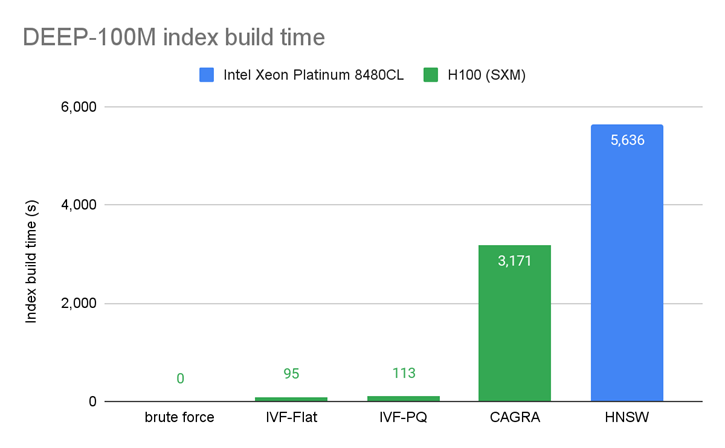
Figure 6 presents a comparison of the index build times and shows that indexes can often be built faster on the GPU.
Summary
From feature stores to generative AI, vector similarity search can be applied in every industry. Vector search on the GPU performs at lower latency and achieves higher throughput for every level of recall for both online and batch processing.
RAFT is a set of composable building blocks that can be used to accelerate vector search in any data source. It has pre-built APIs for Python and C++. Integration for RAFT is underway for Milvus, Redis, and FAISS. We encourage database providers to try RAFT and consider integrating it into their data sources.
In addition to state-of-the-art ANN algorithms, RAFT contains other GPU-accelerated building blocks, such as matrix and vector operations, iterative solvers, and clustering algorithms. The second post in this series dives deeper into each of the GPU-accelerated indexes mentioned in this post and gives a brief explanation of how the algorithms work, along with a summary of important parameters to fine-tune their behavior. For more information, see Accelerating Vector Search: Fine-Tuning GPU Index Algorithms.
RAPIDS RAFT is fully open source and available on the /rapidsai/raft GitHub repo. You can also follow us on Twitter at @rapidsai.
 The first post in this series introduced vector search indexes, explained the role they play in enabling a widespread range of important applications, and…
The first post in this series introduced vector search indexes, explained the role they play in enabling a widespread range of important applications, and…
The first post in this series introduced vector search indexes, explained the role they play in enabling a widespread range of important applications, and provided a brief overview of vector search on the GPU with the RAFT library.
In this post, we dive deeper into each of the GPU-accelerated indexes mentioned in Part 1 and give a brief explanation of how the algorithms work, along with a summary of important parameters to fine-tune their behavior.
We then go through a simple end-to-end example to demonstrate RAFT’s Python APIs on a question-and-answer problem with a pretrained large language model and provide a performance comparison of RAFT’s algorithms against HNSW for a few different scenarios involving different numbers of query vectors being passed to the search algorithm concurrently.
This post provides:
- An overview of vector search index algorithms that can be used with GPUs
- An end-to-end example demonstrating how easy it can be to run vector search on the GPU with Python
- Performance comparison of vector search on the GPU against HNSW, the current state-of-the-art method on the CPU
Vector search indexes
When working with vector search, the vectors are often converted to an indexed format that is optimized for fast lookups. Choosing the right indexing algorithm is important as it can affect both index build and search times. Furthermore, each different index type comes with its own set of knobs for fine-tuning the behavior, trading off index construction time, storage cost, search quality, and search speed.
When the right indexing algorithm is paired with the correct parameter settings, vector search on the GPU provides both faster build and search times for all levels of recall.
IVF-Flat
As it’s the simplest index type, start with the IVF-Flat algorithm. In this algorithm, a set of training vectors are first split into some clusters and then stored in the GPU memory organized by their closest cluster centers. The index-building step is faster than that of other algorithms presented in this post, even at high numbers of clusters.
To search an IVF-Flat index, the closest clusters to each query vector are selected, and the k-nearest neighbors (k-NN) are computed from each of those closest clusters. Because IVF-Flat stores the vectors in an exact, or flat format, meaning without compression, it has the advantage of computing exact distances within each of the clusters it searches. As we describe later in this post, this provides an advantage that often has a higher recall than IVF-PQ when the same number of closest clusters are searched. IVF-Flat index is a good choice when the full index can fit in GPU memory.
RAFT’s IVF-Flat index contains a couple of parameters to help trade off the query performance and accuracy:
- When training the index, the
n_listsparameter determines the number of clusters to partition the training dataset. - The search parameter
n_probesdetermines the number of closest clusters to search through to compute the nearest neighbors for a set of query points.
In general, a smaller number of probes leads to a faster search at the expense of recall. When the number of probes is set to the number of lists, exact results are computed. However, in that case, a call to RAFT’s brute-force search is more performant.
IVF-PQ
When your dataset becomes too large to fit on the GPU, you gain some mileage by compressing the vectors using the IVF-PQ index type. Like IVF-Flat, IVF-PQ splits the points into a number of clusters (also specified by a parameter called n_lists) and searches the closest clusters to compute the nearest neighbors (also specified by a parameter called n_probes), but it shrinks the sizes of the vectors using a technique called product quantization.
Compressing the index ultimately allows for more vectors to be stored on the GPU. The amount of compression can be controlled with tuning parameters, which we describe later in this post, but higher levels of compression can provide a faster lookup time at the cost of recall. IVF-PQ is currently RAFT’s most memory-efficient vector index.
RAFT’s IVF-PQ provides two parameters that control memory usage:
pq_dimsets the target dimensionality of the compressed vector.pq_bitssets the number of bits for each vector element after compression.
We recommend setting the former to a multiple of 32 while the latter is limited to a range of 4-8 bits. By default, RAFT selects a dimensionality value that minimizes quantization loss according to pq_bits, but this value can be adjusted to lower the memory footprint for each vector. It is useful to play with these parameters to see which settings work best for you.
When using large amounts of compression, an additional refinement step can be performed by querying the IVF-PQ index for a larger number of neighbors than needed and computing an exact search over the resulting neighbors to reduce the set down to the final desired number. The refinement step requires the original uncompressed dataset on the host memory.
For more information about building an IVF-PQ index, with in-depth details and recommendations, see the complete guide to RAFT IVF-PQ notebook on our GitHub repo.
CAGRA
CAGRA is RAFT’s new state-of-the-art ANN index. It is a high-performance, GPU-accelerated, graph-based method that has been specifically optimized for small-batch cases, where each lookup contains only one or a few query vectors. Like other popular graph-based methods, such as hierarchical navigable small-world graphs (HNSW) and SONG, an optimized k-NN graph is built at index training time with various qualities that yield efficient search at reasonable levels of recall.
CAGRA performs a search by first randomly selecting candidate vertices from the graph and then expanding, or traversing, those vertices to compute distances to their children, storing off the nearest neighbors along the way (Figure 1). Each time it traverses a set of vertices, it has performed one iteration.
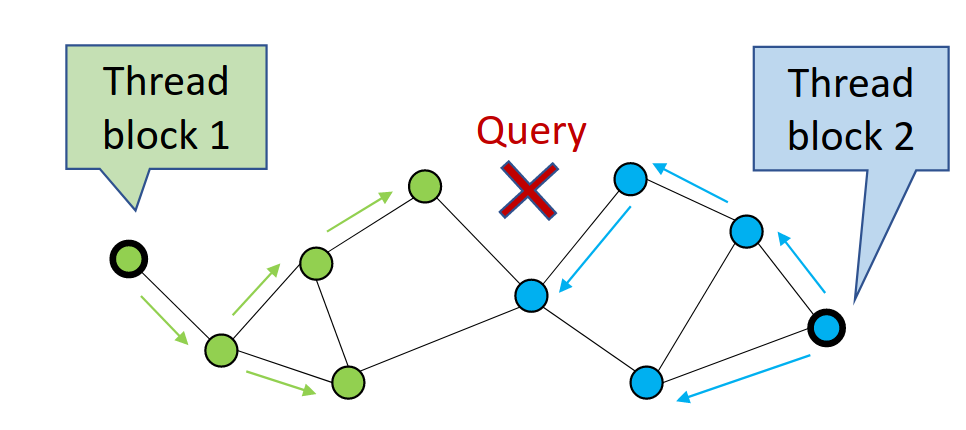
In Figure 1, CAGRA is using multiple thread blocks to visit more graph nodes in parallel. This is maximizing GPU utilization for single-query searches.
Because CAGRA returns the approximate nearest neighbors like the algorithms described earlier, it also provides a few parameters to control the recall and the speed.
The main parameter that can be adjusted to trade off search speed is itopk_size, which specifies the size of an internal sorted list that stores the nodes that can be explored in the next iteration. Higher values of itopk_size keep a larger search context in memory that improves recall at the cost of more time spent in maintaining the queue.
The parameter search_width defines the number of the closest parent vertices that are traversed to expand their children in each search iteration.
Another useful parameter is the number of iterations to perform. The setting is selected automatically by default, but this can be changed to a higher or lower value to trade off recall for a faster search.
CAGRA’s optimized graph is fixed-degree, which is tuned using the parameter graph_degree. The fixed-degree makes better use of GPU resources by keeping the number of computations uniform when searching the graph. It builds the initial k-NN graph by computing an actual k-NN, for example by using IVF-PQ explained earlier, to compute the nearest neighbors of all the points in the training dataset.
The number of k-nearest neighbors (k) of this intermediate k-NN graph can be tuned using a parameter called intermediate_graph_degree to trade off the quality of the final searchable CAGRA graph.
A higher quality graph can be built with a larger intermediate_graph_degree value, which means that the final optimized graph is more likely to find nearest neighbors that yield a high recall. RAFT provides several useful parameters to tune the CAGRA algorithm. For more information, see the CAGRA API documentation.
Again, this parameter can be used to control how thoroughly the overall space is covered by the search but again this comes at the cost of having to search more to find the nearest neighbors, which reduces the search performance.
Getting started with pylibraft
Pylibraft is the lightweight Python library of RAFT and enables you to use RAFT’s ANN algorithms for vector search right in Python. Pylibraft can accept any object that supports __cuda_array_interface__, such as a Torch or CuPy array.
The following example briefly demonstrates how you can build and query a RAFT CAGRA index with Pylibraft.
from pylibraft.neighbors import cagra
import cupy as cp
# On small batch sizes, using "multi_cta" algorithm is efficient
index_params = cagra.IndexParams(graph_degree=32)
search_params = cagra.SearchParams(algo="multi_cta")
corpus_embeddings = cp.random.random((1500,96), dtype=cp.float32)
query_embeddings = cp.random.random((1,96), dtype=cp.float32)
cagra_index = cagra.build(index_params, corpus_embeddings)
# Find the 10 closest vectors
hits = cagra.search(search_params, cagra_index, query_embeddings, k=10)
With the recent success of LLMs, semantic search is a perfect way to showcase vector similarity search in action using RAFT. In the following example, a DistilBERT transformer model combined with each of the three ANN indexes is used to solve a simple question retrieval problem. The Simple English Wikipedia dataset is used to answer the user’s search query.
The language model first transforms the training sentences into vector embeddings that are inserted into a RAFT ANN index. The inference is done by encoding the query and using our trained ANN index to find vectors similar to the encoded query vector. The answer that you return to the user is the nearest article in Simple Wikipedia, which you fetch using the closest vector from the similarity search.
You can get started with RAFT by using pylibraft and this notebook for a question-retrieval task:
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
Viewer requires iframe.
Benchmarks
Using GPU as a hardware accelerator for your vector search application can lead to an increase in performance, and it is best showcased on large datasets. The benchmarks can be fully reproduced by following RAFT’s end-to-end benchmark documentation. Our benchmarks consider that the data is already available for computation, which means that data transfer is not taken into consideration, although this should not be a significant difference thanks to the high transfer speed of recent NVIDIA hardware (over 25 GB/s).
We used the DEEP-100M dataset on an H100 GPU to compare RAFT indexes with HNSW running on an Intel Xeon Platinum 8480CL CPU.
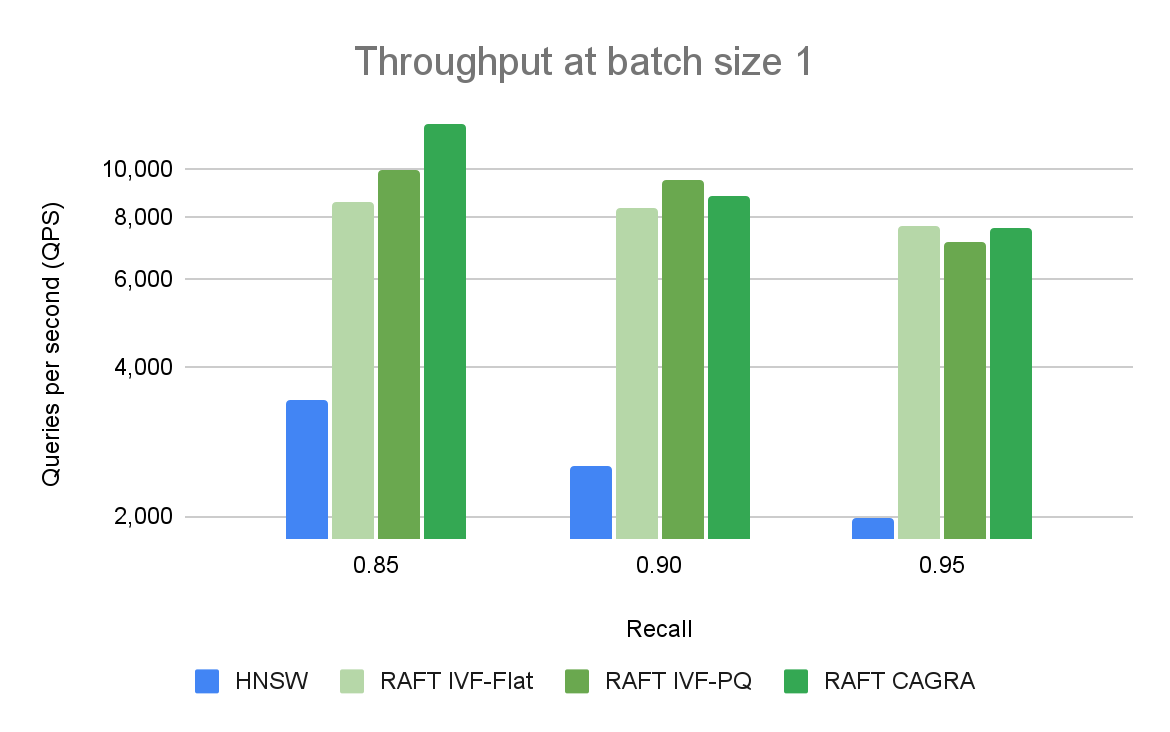
Figure 2 compares ANN algorithms at various levels of recall and throughput for a single query. At high levels of recall, RAFT’s methods demonstrate higher throughput than other alternative libraries.
We ran a performance comparison on queries for a single vector at a time, called online search. It’s one of the main use cases for vector search. RAFT-based indexes provide a higher throughput, measured in queries-per-second (QPS), than other libraries that are using CPU or GPU.
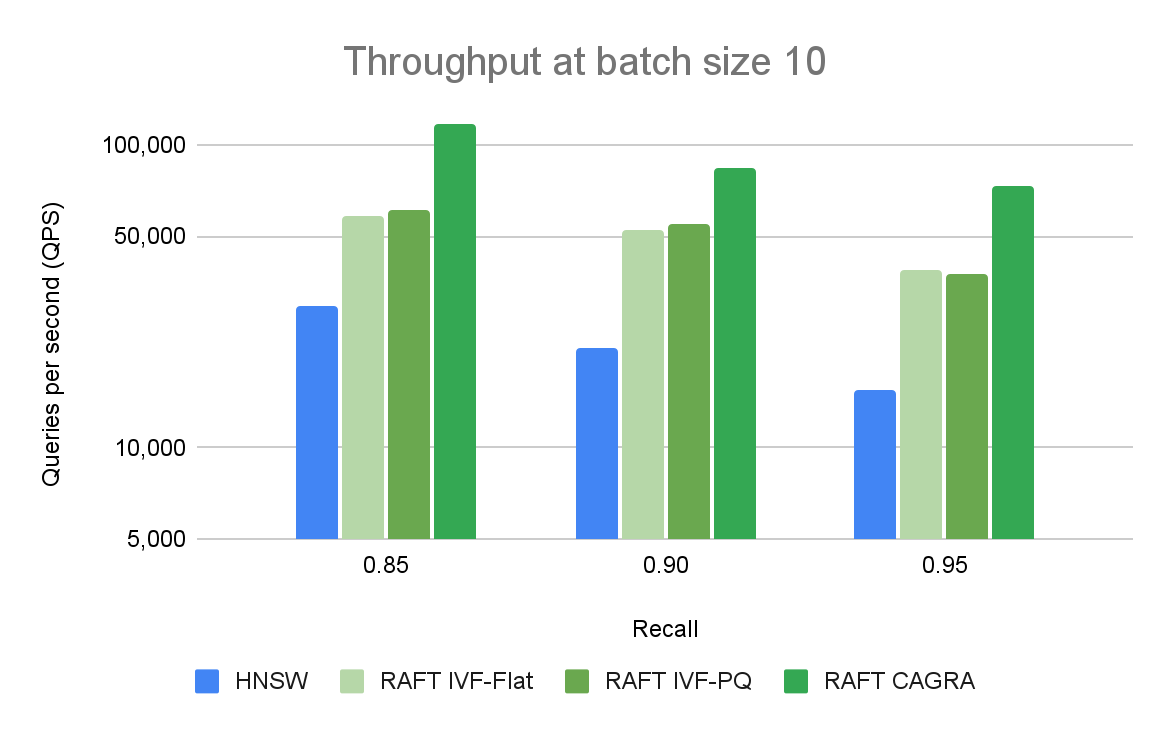
Figure 3 compares ANN algorithms at various levels of recall and throughput with a batch size of 10 queries. RAFT’s methods demonstrate higher throughput than HNSW for all experiments.
The benefits of using GPU for vector search applications are most prevalent at higher batch sizes. The performance gap between CPU and GPU is significant and can scale up easily. Figure 3 shows that for a batch size of 10, only RAFT-based indexes are relevant when comparing the number of queries per second. For a batch size of 10k (Figure 4), CAGRA outperforms all other indexes by far.
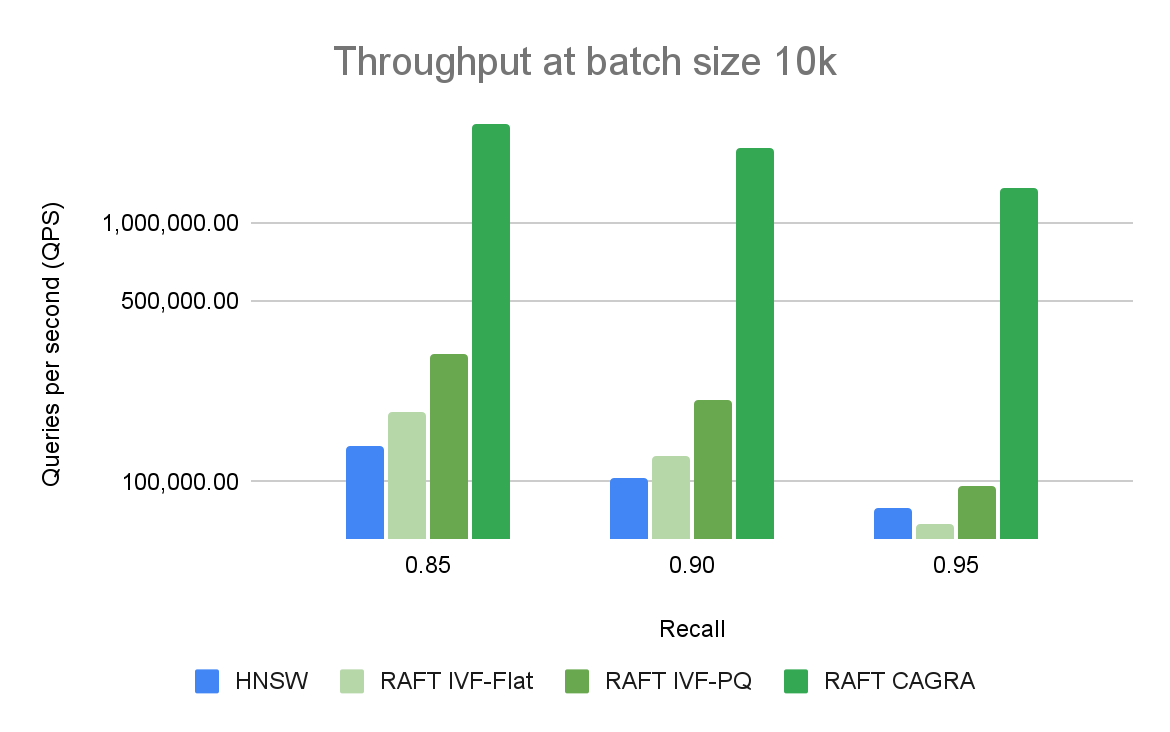
Figure 4 compares ANN algorithms at various levels of recall and throughput with a batch size of 10K query. RAFT’s methods demonstrate higher throughput than HNSW for all experiments.
Summary
Each different vector search index type has benefits and drawbacks which ultimately depend on your needs. This post outlined some of those benefits and drawbacks, providing a brief explanation of how each different algorithm works, along with a few of the most important parameters that can be tuned to trade off storage costs, build times, search quality, and search performance. In all cases, GPUs can improve both index construction and search performance.
RAPIDS RAFT is fully open source and available on the /rapidsai/raft GitHub repo. You can get started with RAFT by reading through the docs, running the reproducible benchmarking suite, or building upon the example vector search template project. Also be sure to look for options to enable RAFT indexes in Milvus, Redis, and FAISS. Finally, you can follow us on Twitter at @rapidsai.
 AI is transforming computing, and inference is how the capabilities of AI are deployed in the world’s applications. Intelligent chatbots, image and video…
AI is transforming computing, and inference is how the capabilities of AI are deployed in the world’s applications. Intelligent chatbots, image and video…
AI is transforming computing, and inference is how the capabilities of AI are deployed in the world’s applications. Intelligent chatbots, image and video synthesis from simple text prompts, personalized content recommendations, and medical imaging are just a few examples of AI-powered applications.
Inference workloads are both computationally demanding and diverse, requiring that platforms be able to process many predictions on never-seen-before data quickly as well as run inference on a breadth of AI models. Organizations looking to deploy AI need a way to evaluate the performance of infrastructure objectively across a breadth of workloads, environments, and deployment scenarios. This is true for both AI training and inference.
MLPerf Inference v3.1, developed by the MLCommons consortium, is the latest edition of an industry-standard AI inference benchmark suite. It complements MLPerf Training and MLPerf HPC. MLPerf Inference v3.1 measures inference performance across a variety of important workloads, including image classification, object detection, natural language processing, speech recognition, and recommender systems, across common data center and edge deployment scenarios.
MLPerf Inference v3.1 includes two important updates to better reflect modern AI use cases:
- The addition of a large language model (LLM) test based on GPT-J–an open source, 6B-parameter LLM–to represent text summarization, a form of generative AI.
- An updated DLRM test with a new model architecture and a substantially larger dataset that mirrors the DLRM update introduced in MLPerf Training v3.0. The update better reflects the scale and complexity of modern recommender systems.
Powered by the full NVIDIA AI Inference software stack, including the latest TensorRT 9.0, NVIDIA made submissions in MLPerf Inference v3.1 using a wide array of products. These included the debut submission of the NVIDIA GH200 Grace Hopper Superchip, which extended the great per-accelerator performance delivered by the NVIDIA H100 Tensor Core GPU. NVIDIA also submitted the NVIDIA L4 Tensor Core GPU for mainstream servers, as well as both the NVIDIA Jetson AGX Orin and Jetson Orin NX platforms for edge AI and robotics.
The rest of this post provides highlights of the NVIDIA submissions as well as a peek into how these exceptional results were achieved.
Grace Hopper Superchip extends NVIDIA Hopper inference performance
The NVIDIA GH200 Grace Hopper Superchip combines the NVIDIA Hopper GPU and the NVIDIA Grace CPU through the coherent NVLink-C2C at 900 GB/s to create a single superchip. That’s 7x higher than PCIe Gen5 at 5x lower power. It also incorporates up to 576 GB of fast access memory through the combination of 96 GB of HBM3 GPU memory and up to 480 GB of low-power, high-bandwidth LPDDR5X memory.
The GH200 Grace Hopper Superchip has integrated power management features that enable the GH200 to take advantage of the energy efficiency of the Grace CPU to balance efficiency and performance. For more information, see NVIDIA Grace Hopper Superchip Architecture In-Depth and the NVIDIA Grace Hopper Superchip Architecture whitepaper.
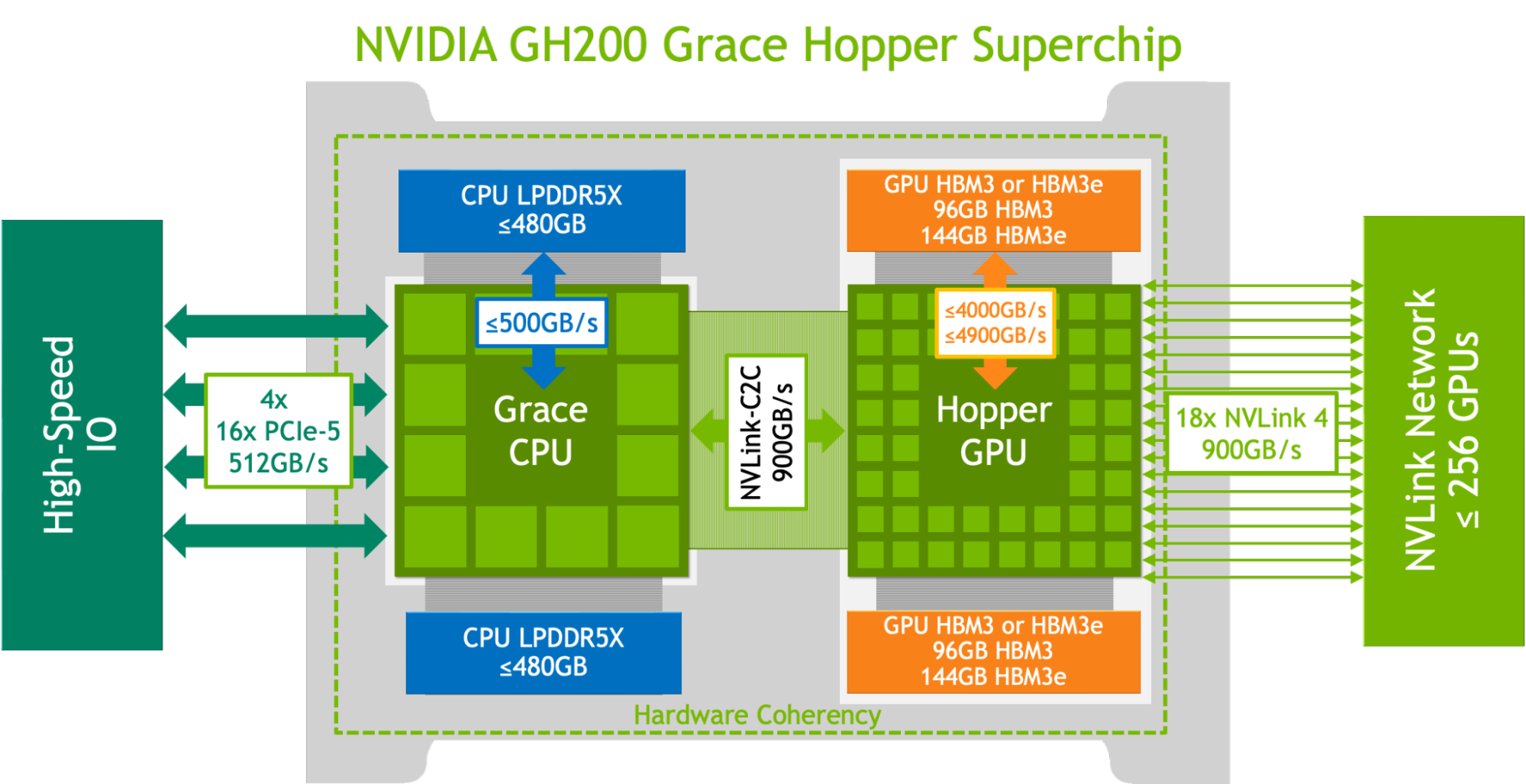
The NVIDIA GH200 Grace Hopper Superchip is designed for the versatility required to deliver leading performance across compute and memory-intensive workloads. It also delivers substantially higher performance on the most demanding frontier workloads, such as large transformer-based models with hundreds of billions or trillions of parameters, recommender systems with multi-terabyte embedding tables, and vector databases.
In addition to being built for the most intensive AI workloads, the GH200 Grace Hopper Superchip also shines on the popular, mainstream workloads tested by MLPerf Inference. It ran every test, demonstrating its seamless support for the full NVIDIA software stack. It extended the exceptional performance achieved by NVIDIA’s single H100 SXM submission on every workload.
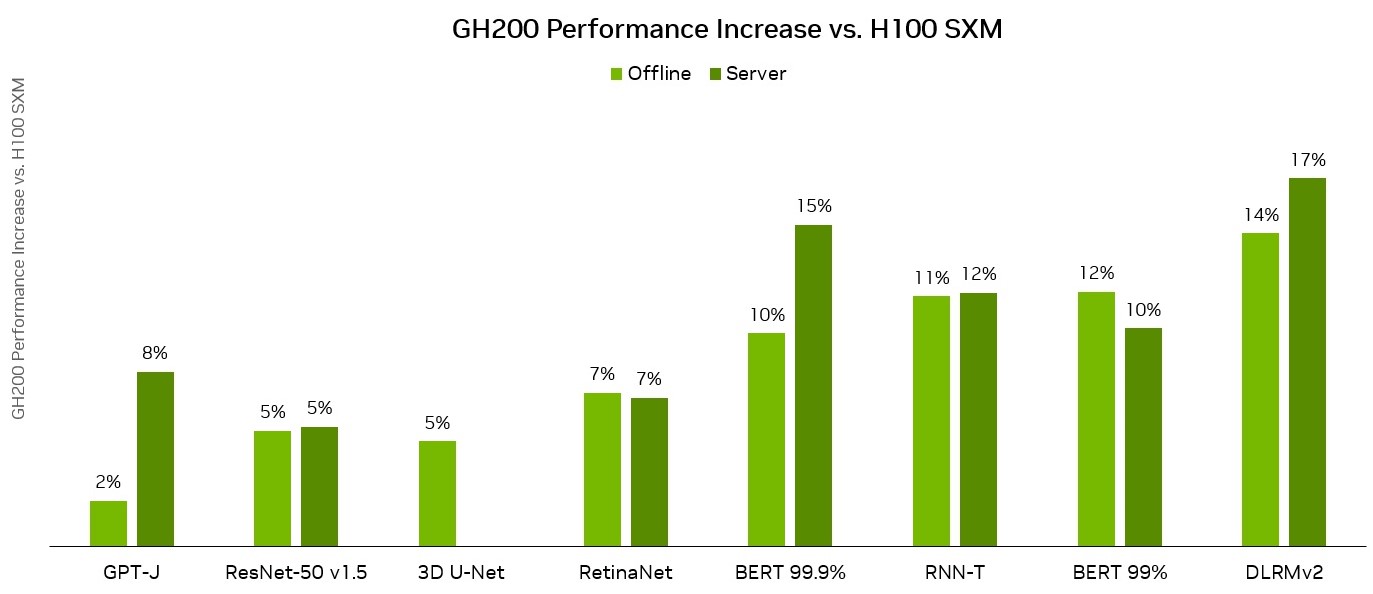
MLPerf Inference: Datacenter v3.1, Closed. Submission IDs: NVIDIA 3.1-0107(1xH100 SXM), 3.1-0110(1xGH200 Grace Hopper Superchip)
The MLPerf name and logo are trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. For more information, see www.mlcommons.org.
The GH200 Grace Hopper Superchip incorporates 96 GB of HBM3 and provides up to four TB/s of HBM3 memory bandwidth, compared to 80 GB and 3.35 TB/s for H100 SXM, respectively. This larger memory capacity, as well as greater memory bandwidth, enabled the use of larger batch sizes for workloads on the NVIDIA GH200 Grace Hopper Superchip compared to the NVIDIA H100 SXM. For example, both RetinaNet and DLRMv2 ran with up to double the batch sizes in the Server scenario and 50% greater batch sizes in the Offline scenario.
The GH200 Grace Hopper Superchip’s high-bandwidth NVLink-C2C link between the NVIDIA Hopper GPU and the Grace CPU enables fast communication between the CPU and GPU, which can help boost performance.
For example, in the MLPerf DLRMv2 workload, transferring a batch of tensors over PCIe takes approximately 22% of the batch inference time on H100 SXM. The GH200 Grace Hopper Superchip, however, performed the same transfer using just 3% of the inference time as a result of NVLink-C2C.
Thanks to higher memory bandwidth and larger memory capacity, the Grace Hopper Superchip delivered up to 17% higher per-chip performance advantage compared to the H100 GPU on MLPerf Inference v3.1 workloads. These results showcase the performance and versatility of both the GH200 Grace Hopper Superchip and the NVIDIA software stack.
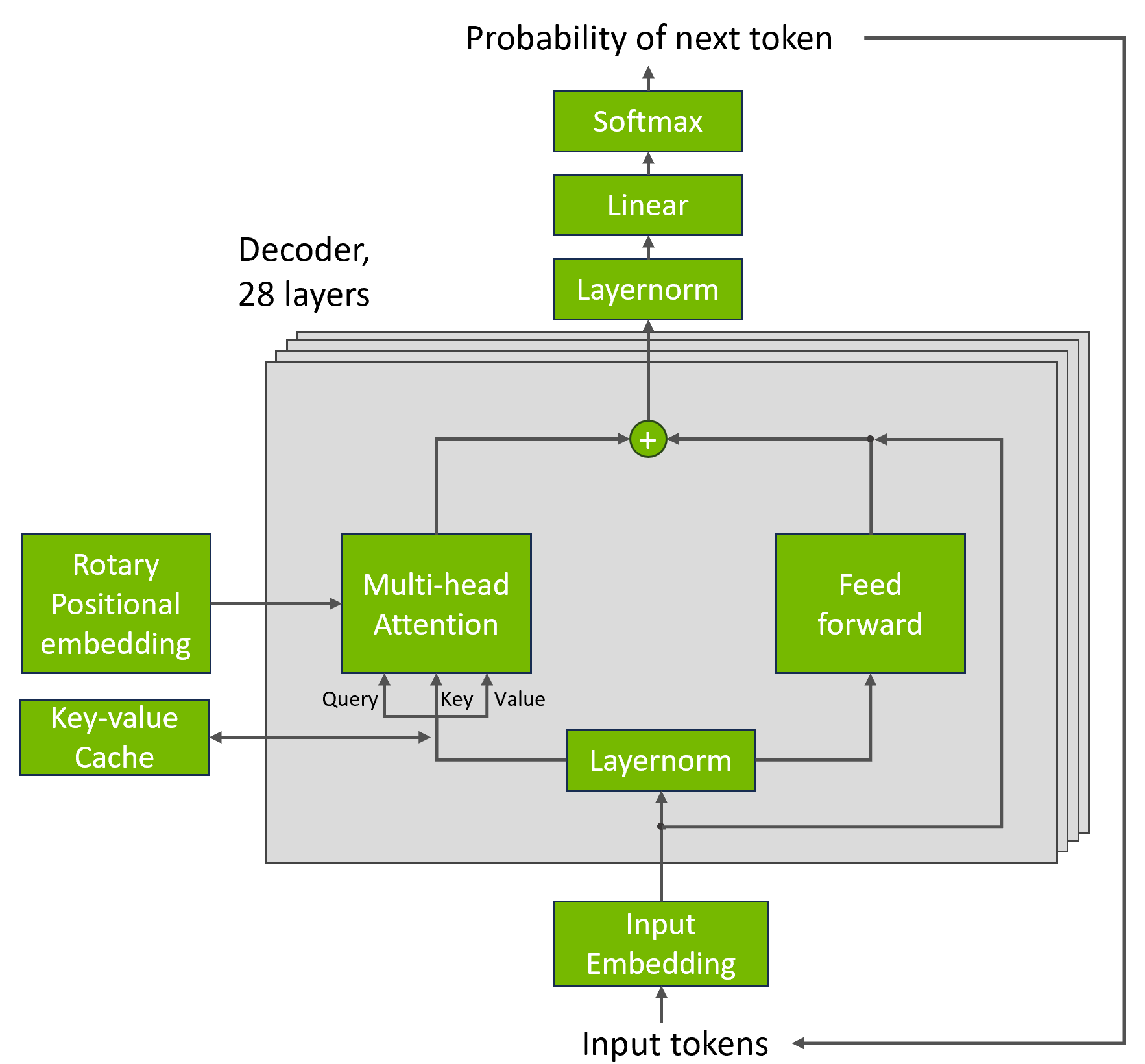
Optimizing GPT-J 6B for LLM inference
To represent LLM inference workloads, MLPerf Inference v3.1 introduces a new test based on the GPT-J 6B model: an LLM with 6B parameters. The task tested by the new benchmark is text summarization using the CNN/DailyMail dataset.
The NVIDIA platform delivered strong results on the GPT-J workload, with GH200 Grace Hopper Superchip delivered the highest per-accelerator performance on both the Offline and Server scenarios on a per-accelerator basis. The NVIDIA L4 GPU also delivered strong performance, outpacing the best CPU-only result up to 6x in a 1-slot PCIe card with a thermal design power (TDP) of just 72 Watts.
To achieve these results, NVIDIA software for LLM inference intelligently applies both FP8 and FP16 precisions to increase performance while also meeting target accuracy requirements.
A key challenge for performing GPT-J inference is the high memory consumption of the key-value (KV) cache in the transformer block. By storing the KV cache in the FP8 data format, the NVIDIA submission significantly increased the batch size used. This boosted GPU memory utilization and enabled better use of the immense compute performance of NVIDIA GPUs.
Enabling DLRM-DCNv2 submissions
MLPerf Inference v3.1 introduced an update to the DLRMv1 model used in prior versions of the benchmark. This DLRMv2 model replaces the interactions layer with a three-layer DCNv2 cross network. DLRMv2 also uses multi-hot categorical inputs rather than one-hot, which are synthetically generated from the Criteo Terabyte Click Logs Dataset.
One of the challenges of recommender inference arises from fitting the embedding tables on the system. By converting the model to FP16 precision, including the embedding table, we could both improve performance and halve the memory footprint of the embedding table, reducing it to 49 GB. This enables the entire embedding table to fit within a single H100 GPU.
To enable our submission on the L4 GPU, which has 24 GB of memory, NVIDIA software intelligently splits the embedding table between GPU and host memory using row-frequency data obtained by analyzing the training dataset. Using this data, NVIDIA software can minimize memory transfers between the host CPU and GPU by storing the most frequently used embedding table rows on the GPU.
The NVIDIA platform demonstrated exceptional results on DLRMv2, with GH200 showing up to a 17% increase compared to the great performance delivered by H100 SXM.
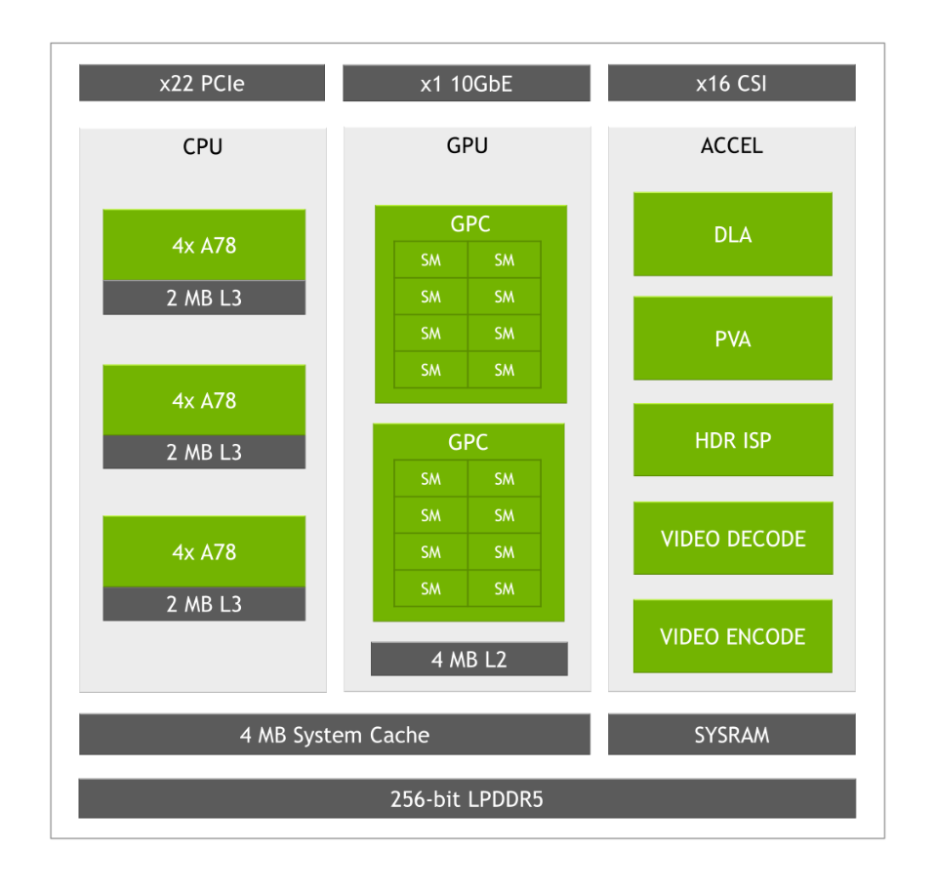
Maximizing parallelism on NVIDIA Jetson Orin with Programmable Vision Accelerator
The Jetson AGX Orin series and Jetson Orin NX series are embedded modules for edge AI and robotics, based on the NVIDIA Orin system-on-chip (SoC). To deliver exceptional AI performance and efficiency across a range of use cases, Jetson Orin incorporates many compute engines:
- A GPU based on the NVIDIA Ampere Architecture, with third-generation Tensor Cores
- Two second-generation, fixed-function NVIDIA Deep Learning Accelerators (NVDLA v2.0)
- One second-generation Programmable Vision Accelerator (PVA v2.0).
These accelerators can be used to offload the GPU and enable additional AI inference performance on the Jetson Orin modules.
NVDLA is a fixed-function accelerator optimized for deep learning operations and is designed to do full hardware acceleration of convolutional neural network inferencing.
For the first time in MLPerf Inference v3.1, we demonstrate the concurrent use of the PVA alongside GPU and DLA for inference. The second-generation PVA provides dedicated hardware for various computer vision kernels such as filtering, warping, and fast Fourier transforms (FFT). It also supports advanced programmed kernels, which can serve as the backend runtime of TensorRT custom plug-ins.
With the 23.08 Jetson CUDA-X AI Developer Preview, we’ve included a sample PVA SDK. This package provides runtime support for a non-maximum suppression (NMS) layer. It demonstrates that the PVA can serve as a highly capable accelerator, complementing the powerful Jetson Orin GPU.
NVIDIA has developed a TensorRT custom NMS PVA plug-in as a reference for Jetson Orin users and it was included as part of the NVIDIA MLPerf Inference v3.1 submission.
In the NVIDIA MLPerf Inference v3.0 RetinaNet submission on NVIDIA Orin platforms, the GPU handled all outputs from the ResNext + FPN backbone from the GPU as well as from the two DLAs.
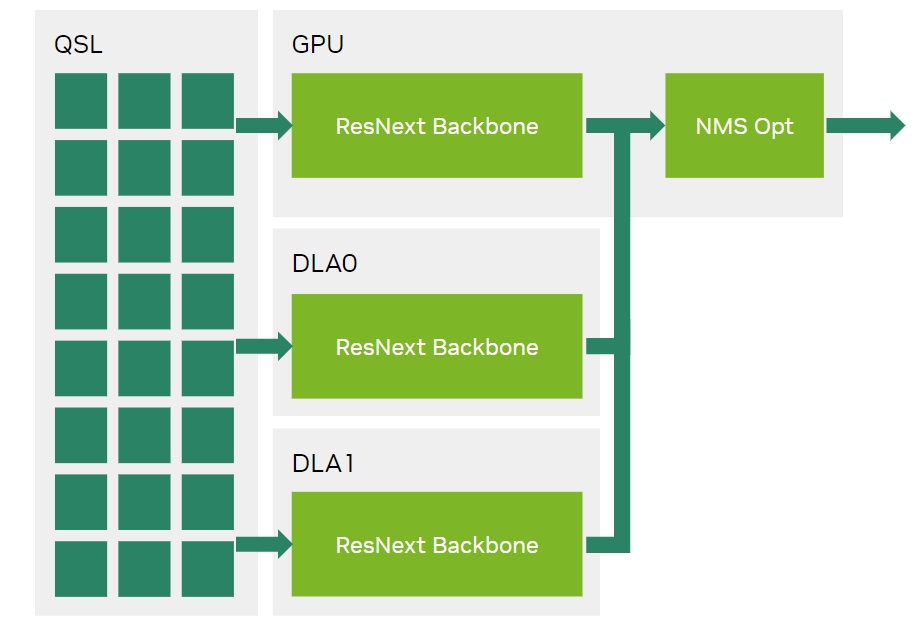
Figure 5 shows how, in MLPerf Inference v3.0 submissions, the GPU was responsible for outputs from the ResNext+FPN backbone from both the GPU and the DLAs.
By using the NMS PVA plug-in, the NMS operator is now offloaded from GPU to PVA, enabling three fully parallel inference flows on Jetson Orin AGX and Jetson Orin NX. The output from the ResNext and the FPN backbone running on the two DLAs is now consumed by the two PVAs running the NMS PVA plug-in inside the end-to-end RetinaNet TensorRT engine.
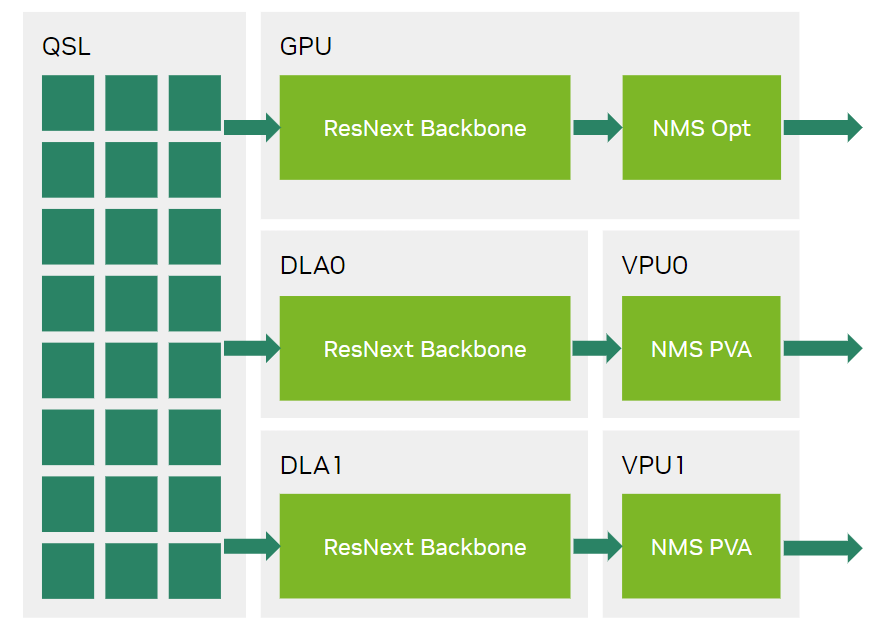
In Figure 6, the NVIDIA MLPerf Inference v3.1 submission enables computations to run fully in parallel through optimized use of Jetson Orin PVAs.
This careful use of PVA along with GPU and DLA boosts performance by 30% on both the Jetson AGX Orin 64GB and the Jetson Orin NX 16GB modules. When this use of PVA is coupled with a newly optimized NMS Opt GPU plug-in, Jetson AGX Orin delivers 61% higher performance and 38% better power efficiency on the RetinaNet workload. The Jetson Orin NX 16GB showed an even larger gain, with an 84% performance boost on the same test.
Algorithmic optimizations further improve BERT performance
In MLPerf Inference v3.1, NVIDIA made a submission on the BERT Large workload using the L4 GPU in the open division using techniques developed by the OmniML team. OmniML is a startup acquired by NVIDIA in early 2023 that brought expertise in machine learning algorithmic model optimization for use cases spanning cloud platforms to edge devices.
The open division submission on BERT applied structured pruning with distillation techniques to improve the performance by up to 4.7x while maintaining 99% accuracy. This submission demonstrates the potential of algorithmic optimizations for enhancing significantly the already exceptional performance of the NVIDIA platform.
NVIDIA deployed a proprietary, automatic, structured pruning tool that uses a gradient-based sensitivity analysis to prune the model to the given target FLOPs and fine-tune it with distillation to recover most of the accuracy. The number of transformer layers, attention heads, and linear layer dimensions were pruned in all the transformer layers in the model while the embedding dimension was kept unchanged.
Compared to the original MLPerf Inference BERT INT8 model, our pruned model reduced the number of parameters by 4x and the number of FLOPs by 5.6x. This model has a varying number of heads and linear layer dimensions in each layer. The resulting TensorRT engine built from the pruned model is 3.4x smaller, 177 MB compared to 607 MB.
The fine-tuned model is quantized to INT8 precision using the same technique employed in the NVIDIA closed division submission. The submission also employed distillation during quantization-aware training (QAT) to achieve an accuracy that is 99% or higher.
| Scenario | Closed Division | Open Division | Speedup |
| Offline samples/sec | 1029 | 4609 | 4.5x |
| Server samples/sec | 899 | 4265 | 4.7x |
| Single Stream p90 Latency (ms) | 2.58 | 0.82 | 3.1x |
To understand better how each of the model optimizations affects performance, NVIDIA performed a stacking analysis and applied different model optimization methods individually (Figure 8).
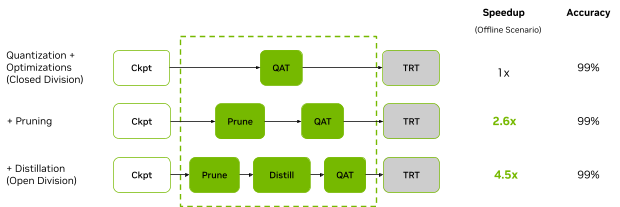
Figure 7 shows that, through model pruning and distillation, the NVIDIA open division submission on the BERT workload using L4 provides a 4.5x speedup compared to the same GPU running the closed division workload in the offline scenario.
Each model optimization method applied can be easily integrated with each other. Together, they yielded a substantial performance improvement compared to the baseline model.
NVIDIA accelerated computing boosts performance for inference and AI training workloads
In its MLPerf debut, the GH200 Grace Hopper Superchip turned in exceptional performance on all workloads and scenarios in the closed division of the data center category, boosting performance by up to 17% on the NVIDIA single-chip H100 SXM submission. The NVIDIA software stack fully supports the GH200 Grace Hopper Superchip today.
For mainstream servers, the L4 GPU showed delivery of a large performance leap over CPU-only offerings in a compact, low-power, PCIe add-in card.
For edge AI and robotics applications, the Jetson AGX Orin and Jetson Orin NX modules achieved great performance. Software optimizations helped to further unlock the potential of the powerful NVIDIA Orin SoC that powers those modules. It boosted performance on RetinaNet, a popular AI network for object detection, by up to 84%.
In this round, NVIDIA also submitted results in the open division, providing a first look at the potential for model optimizations to speed inference performance dramatically while still achieving excellent accuracy.
The latest MLPerf Inference v3.1 benchmarks show that the NVIDIA accelerated computing platform continues to deliver leadership performance and versatility. There’s innovation at every layer of the technology stack, from cloud to edge, at the speed of light.