
Goran Vuksic is the brain behind a project to build a real-world pit droid, a type of Star Wars bot that repairs and maintains podracers which zoom across the much-loved film series. The edge AI Jedi used an NVIDIA Jetson Orin Nano Developer Kit as the brain of the droid itself. The devkit enables the Read article >
 Geospatial data provides rich real-world environmental and contextual information, spatial relationships, and real-time monitoring capabilities for applications…
Geospatial data provides rich real-world environmental and contextual information, spatial relationships, and real-time monitoring capabilities for applications…
Geospatial data provides rich real-world environmental and contextual information, spatial relationships, and real-time monitoring capabilities for applications in the industrial metaverse.
Recent years have seen an explosion in 3D geospatial data. The rapid increase is driven by technological advancements such as high-resolution aerial and satellite imagery, lidar scanners on autonomous cars and machines, improvements in 3D reconstruction algorithms and AI, and the proliferation of scanning technology to handheld devices and smartphones that enable everyday people to capture their environment.
To process and disperse massive heterogenous 3D geospatial data to geospatial applications and runtime engines across industries, Cesium has created 3D Tiles, an open standard for efficient streaming and rendering of massive, heterogeneous datasets. 3D Tiles are a streamable, optimized format designed to support the most demanding analytics and large-scale simulations.
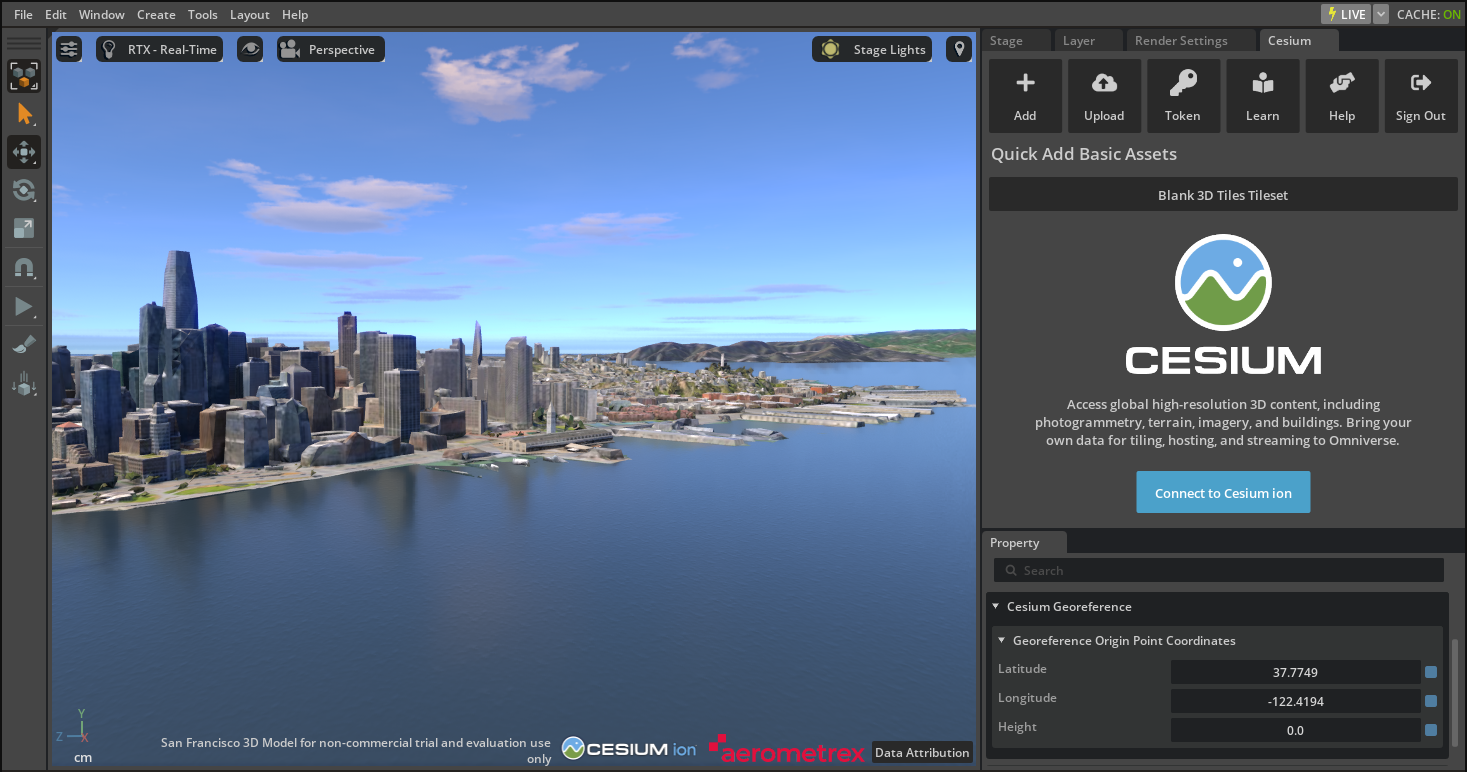
Cesium for Omniverse is Cesium’s open-source extension for NVIDIA Omniverse. It delivers 3D Tiles and real-world digital twins at global scale with remarkable speed and quality. The extension enables users to create real-world-ready models from any source of 3D geospatial content—at rapid speed and with high accuracy—using Universal Scene Description (OpenUSD).
With Cesium for Omniverse, you can jump-start 3D geospatial app development with tiling pipelines for streaming your own content. You can also enhance your 3D content by incorporating real-world context from popular 3D and photogrammetry applications such as Autodesk, Bentley Systems, and Matterport.
For example, you can integrate Bentley’s iTwin model of an iron ore mining facility with Cesium for project planners to visualize and analyze the facility in its precise geospatial context. With Cesium for Omniverse, project planners can use a digital twin of the facility to share plans and potential impacts with local utilities, engineers, and residents, accounting for location-specific details such as weather and lighting.

One of the most intriguing features of the extension is an accurate, full-scale WGS84 virtual globe with real-time ray tracing and AI-powered analytics for 3D geospatial workflows. Developers can create interactive applications with the globe for sharing dynamic geospatial data.
New opportunities for 3D Tiles with OpenUSD
Just as Cesium is building the 3D geospatial ecosystem through openness and interoperability with 3D Tiles, NVIDIA is enabling an open and collaborative industrial metaverse built on OpenUSD. Originally developed by Pixar, OpenUSD is an open and extensible ecosystem for describing, composing, simulating, and collaborating within 3D worlds.
By connecting 3D Tiles to the OpenUSD ecosystem, Cesium is opening new possibilities for customization and integration of 3D Tiles into metaverse applications built by developers across global industries. For example, popular AECO tools can leverage OpenUSD to add 3D geospatial context streamed by Cesium to enable powerful workflows.
To further interoperate with USD, developers at Cesium created a custom schema in USD to support their full-scale virtual globe (Figure 2).
Cesium’s virtual globe is a digital representation of the earth’s surface based on the World Geodetic System 1984 (WGS84) coordinate system. It encompasses the earth’s terrain, oceans, and atmosphere, enabling users to explore and visualize geospatial data and models with high accuracy and realism.
Creating a full-scale virtual globe

“Leveraging the interoperability of USD with 3D Tiles and glTF, we create additional workflows, like importing content from Bentley’s LumenRT for Omniverse, Trimble Sketchup, Autodesk Revit, Autodesk 3ds Max, and Esri ArcGIS CityEngine into NVIDIA Omniverse in precise 3D geospatial context,” said Shehzan Mohammed, director of 3D Engineering and Ecosystems at Cesium.
In Omniverse, all the information for the globe such as tilesets, imagery layers, and georeferencing data is stored in USD. USD is a highly extensible and powerful interchange for virtual worlds. A key USD feature is custom schemas, which you can use to extend data for complex and sophisticated virtual world use cases.
Cesium’s team developed a custom schema, with specific classes defined for key elements of the virtual globe. The C++ layer of the schema actively monitors state changes using the OpenUSD TfNotice system, ensuring that tilesets are updated promptly whenever necessary. Cesium Native is used for efficient tile streaming. The lower-level Fabric API from Omniverse is employed for tile rendering, ensuring optimal performance and high-quality visual representation of the globe.
The result is a robust and precise WGS84 virtual globe created and seamlessly integrated within the USD framework.
Developing the extension
To develop the extension for Omniverse, Cesium’s developers leveraged Omniverse Kit, a low-code toolkit to help developers get started building tools. Omniverse Kit provides sample applications, templates, and popular components in Omniverse that serve as the building blocks for powerful applications.
Omniverse Kit supports both Python and C++. The extension’s code was predominantly written in Python, while the tile streaming code was implemented in C++. Communication between the Python code and C++ code uses a combination of PyBind11 bindings and Carbonite plug-ins where possible.
During the initial stages of the project, the team heavily relied on the kit-extension-template-cpp as a reference. After becoming familiar with the platform, they began to take advantage of Omniverse Kit’s highly modular design, and developed their own Kit application to facilitate the development process. This application served as a common development environment across Cesium’s team where they could establish their own default settings and easily enable often-used extensions.
Cesium used many existing Omniverse Kit extensions, like omni.example.ui and omni.kit.debug.vscode, and created their own to streamline task execution. For instance, their extension Cesium Power Tools has more advanced developer tools, like geospatial coordinate conversions and syncing Sun Study with the scene’s georeferencing information. They plan on developing more of these extensions in the future as they scale with Omniverse.
High-performance streaming
Maintaining high-performance streaming for 3D Tiles and global content can be a challenge for Cesium’s street-level to global scale workloads. To address this, their team relied on the Omniverse Fabric API, which enables high-performance creation, modification, and access of scene data. Fabric plays a vital role in achieving optimal performance levels for Cesium, improving load speed, runtime performance, simulation performance, and availability of data on GPUs.

Building on Fabric, Cesium incorporated an object pool mechanism that enables recycling geometry and materials as tiles unload, optimizing resource utilization. Tile streaming occurs either over HTTP or through the local filesystem, providing efficient data transmission.
Getting started with Cesium for Omniverse
Cesium for Omniverse is free and open source under the Apache 2.0 License and is integrated with Cesium ion. This provides instant access to cloud-based global high-resolution 3D content including photogrammetry, terrain, imagery, and buildings. Additionally, industry-leading 3D tiling pipelines and global curated datasets are available as part of an optional commercial subscription to Cesium ion, enabling you to transform content into optimized, spatially indexed 3D Tiles ready for streaming to Omniverse. Learn more about Cesium for Omniverse.
Explore Cesium learning content and sample projects for Omniverse. To get started building your own extension like Cesium for Omniverse, visit Omniverse Developer Resources.
Attending SIGGRAPH? Add this session to your schedule: Digital Twins Go Geospatial With OpenUSD, 3D Tiles, and Cesium on August 9 at 10:30 a.m. PT.
Get started with NVIDIA Omniverse by downloading the standard license free, or learn how Omniverse Enterprise can connect your team. If you are a developer, get started with Omniverse resources to build extensions and apps for your customers. Stay up to date on the platform by subscribing to the newsletter, and following NVIDIA Omniverse on Instagram, Medium, and Twitter. For resources, check out our forums, Discord server, Twitch, and YouTube channels.
To grow and succeed, organizations must continuously focus on technical skills development, especially in rapidly advancing areas of technology, such as generative AI and the creation of 3D virtual worlds. NVIDIA Training, which equips teams with skills for the age of AI, high performance computing and industrial digitalization, has released new courses that cover these Read article >
The Ultimate upgrade is complete — GeForce NOW Ultimate performance is now streaming all throughout North America and Europe, delivering RTX 4080-class power for gamers across these regions. Celebrate this month with 41 new games, on top of the full release of Baldur’s Gate 3 and the first Bethesda titles coming to the cloud as Read article >
CFO Commentary to Be Provided in Writing Ahead of CallSANTA CLARA, Calif., Aug. 02, 2023 (GLOBE NEWSWIRE) — NVIDIA will host a conference call on Wednesday, Aug. 23, at 2 p.m. PT (5 p.m. ET), …
 A new paradigm for data modeling and interchange is unlocking possibilities for 3D workflows and virtual worlds.
A new paradigm for data modeling and interchange is unlocking possibilities for 3D workflows and virtual worlds.
A new paradigm for data modeling and interchange is unlocking possibilities for 3D workflows and virtual worlds.
 Smart cities are the future of urban living. Yet they can present various challenges for city planners, most notably in the realm of transportation. To be…
Smart cities are the future of urban living. Yet they can present various challenges for city planners, most notably in the realm of transportation. To be…
Smart cities are the future of urban living. Yet they can present various challenges for city planners, most notably in the realm of transportation. To be successful, various aspects of the city—from environment and infrastructure to business and education—must be functionally integrated.
This can be difficult, as managing traffic flow alone is a complex problem full of challenges such as congestion, emergency response to accidents, and emissions.
To address these challenges, developers are creating AI software with field programmability and flexibility. These software-defined IoT solutions can provide scalable, ready-to-deploy products for real-time environments like traffic management, number plate recognition, smart parking, and accident detection.
Still, building effective AI models is easier said than done. Omitted values, duplicate examples, bad labels, and bad feature values are common problems with training data that can lead to inaccurate models. The results of inaccuracy can be dangerous in the case of self-driving cars, and can also lead to inefficient transportation systems or poor urban planning.
Digital twins of real-time city traffic
End-to-end AI engineering company SmartCow, an NVIDIA Metropolis partner, has created digital twins of traffic scenarios on NVIDIA Omniverse. These digital twins generate synthetic data sets and validate AI model performance.
The team resolved common challenges due to a lack of adequate data for building optimized AI training pipelines by generating synthetic data with NVIDIA Omniverse Replicator.
The foundation for all Omniverse Extensions is Universal Scene Description, known as OpenUSD. USD is a powerful interchange with highly extensible properties on which virtual worlds are built. Digital twins for smart cities rely on highly scalable and interoperable USD features for large, high-fidelity scenes that accurately simulate the real world.
Omniverse Replicator, a core extension of the Omniverse platform, enables developers to programmatically generate annotated synthetic data to bootstrap the training of perception of AI models. Synthetic data is particularly useful when real data sets are limited or hard to obtain.
By using a digital twin, the SmartCow team generated synthetic data that accurately represents real-world traffic scenarios and violations. These synthetic datasets help validate AI models and optimize AI training pipelines.
Building the license plate detection extension
One of the most significant challenges for intelligent traffic management systems is license plate recognition. Developing a model that will work in a variety of countries and municipalities with different rules, regulations, and environments requires diverse and robust training data. To provide adequate and diverse training data for the model, SmartCow developed an extension in Omniverse to generate synthetic data.
Extensions in Omniverse are reusable components or tools that deliver powerful functionalities to augment pipelines and workflows. After building an extension in Omniverse Kit, developers can easily distribute it to customers to use in Omniverse USD Composer, Omniverse USD Presenter, and other apps.
SmartCow’s extension, which is called License Plate Synthetic Generator (LP-SDG), uses an environmental randomizer and a physics randomizer to make synthetic datasets more diverse and realistic.
The environmental randomizer simulates variations in lighting, weather, and other factors in the digital twin environment such as rain, snow, fog, or dust. The physics randomizer simulates scratches, dirt, dents, and discoloration that could affect the ability of the model to recognize the number on the license plate.
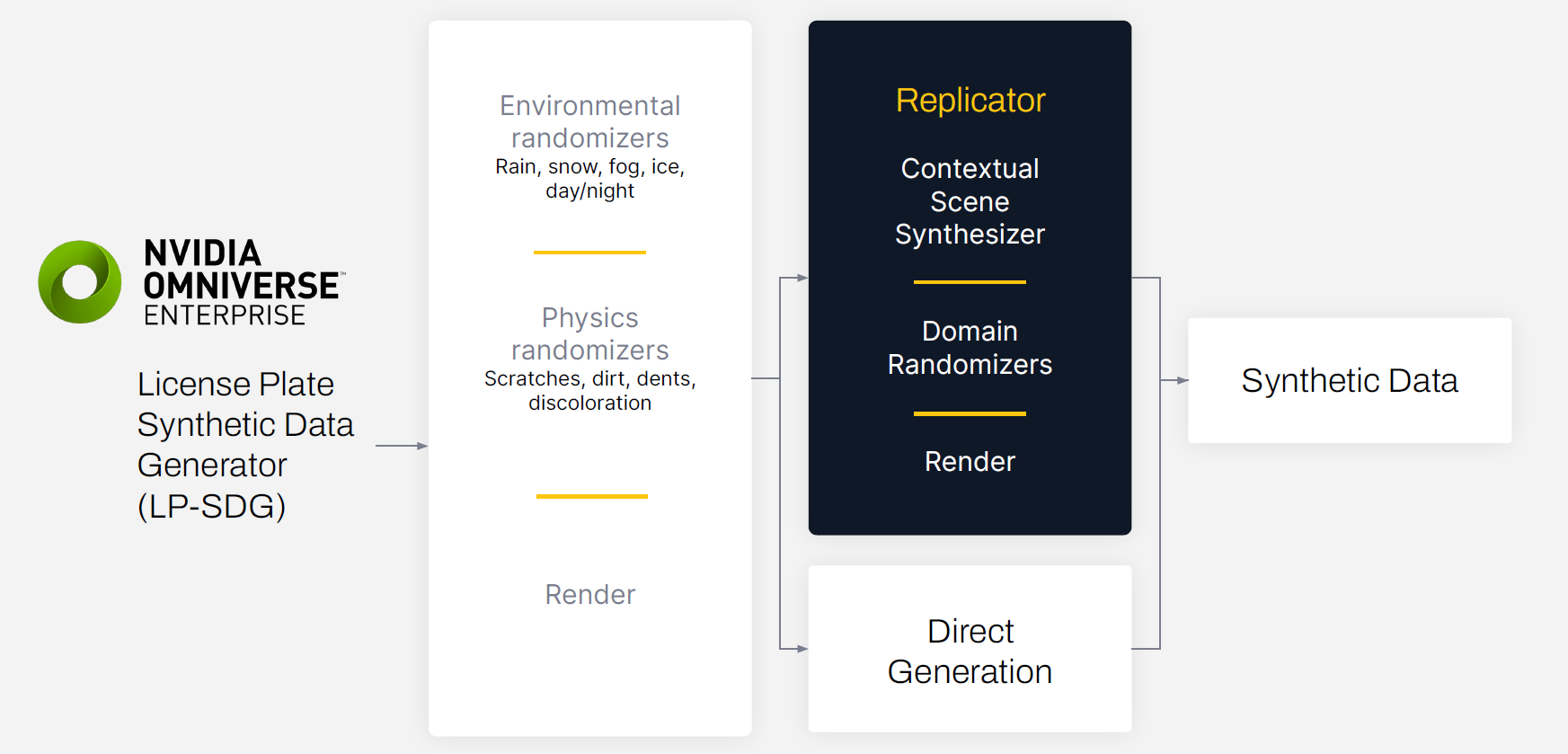
Synthetic data generation with NVIDIA Omniverse Replicator
The data generation process starts with creating a 3D environment in Omniverse. The digital twin in Omniverse can be used for many simulation scenarios, including generating synthetic data. The initial 3D scene was built by SmartCow’s in-house technical artists, ensuring that the digital twin matched reality as best as possible.

Once the scene was generated, domain randomization was used to vary the light sources, textures, camera positions, and materials. This entire process was accomplished programmatically using the built-in Omniverse Replicator APIs.
The generated data was exported with bounding box annotations and additional output variables needed for training.
Model training
The initial model was trained on 3,000 real images. The goal was to understand the baseline model performance and validate aspects such as correct bounding box dimensions and light variation.
Next, the team staged experiments to compare benchmarks on synthetically generated datasets of 3,000 samples, 30,000 samples, and 300,000 samples.

“With the realism obtained through Omniverse, the model trained on synthetic data occasionally outperformed the model trained on real data,” said Natalia Mallia, software engineer at SmartCow. “Using synthetic data actually removes the bias, which is naturally present in the real image training dataset.”
To provide accurate benchmarking and comparisons, the team randomized the data across consistent parameters such as time of day, scratches, and viewing angle when training on the three sizes of synthetically generated data sets. Real-world data was not mixed with synthetic data for training, to preserve comparative accuracy. Each model was validated against a dataset of approximately 1,000 real images.
SmartCow’s team integrated the training data from the Omniverse LP-SDG extension with NVIDIA TAO, a low-code AI model training toolkit that leverages the power of transfer learning for fine-tuning models.
The team used the pretrained license plate detection model available in the NGC catalog and fine-tuned it using TAO and NVIDIA DGX A100 systems.
Model deployment with NVIDIA DeepStream
The AI models were then deployed onto custom edge devices using NVIDIA DeepStream SDK.
They then implemented a continuous learning loop that involved collecting drift data from edge devices, feeding the data back into Omniverse Replicator, and synthesizing retrainable datasets that were passed through automated labeling tools and fed back into TAO for training.
This closed-loop pipeline helped to create accurate and effective AI models for automatically detecting the direction of traffic in each lane and any vehicles that are stalled for an unusual amount of time.
Getting started with synthetic data, digital twins, and AI-enabled smart city traffic management
Digital twin workflows for generating synthetic data sets and validating AI model performance are a significant step towards building more effective AI models for transportation in smart cities. Using synthetic datasets helps overcome the challenge of limited data sets, and provides accurate and effective AI models that can lead to efficient transportation systems and better urban planning.
If you’re looking to implement this solution directly, check out the SmartCow RoadMaster and SmartCow PlateReader solutions.
If you’re a developer interested in building your own synthetic data generation solution, download NVIDIA Omniverse for free and try the Replicator API in Omniverse Code. Join the conversation in the NVIDIA Developer Forums.
Join NVIDIA at SIGGRAPH 2023 to learn about the latest breakthroughs in graphics, OpenUSD, and AI. Save the date for the session, Accelerating Self-Driving Car and Robotics Development with Universal Scene Description.
Get started with NVIDIA Omniverse by downloading the standard license free, or learn how Omniverse Enterprise can connect your team. If you’re a developer, get started with Omniverse resources. Stay up to date on the platform by subscribing to the newsletter, Twitch, and YouTube channels.
Pixar, Adobe, Apple, Autodesk, and NVIDIA, together with the Joint Development Foundation (JDF), an affiliate of the Linux Foundation, today announced the Alliance for OpenUSD (AOUSD) to promote the standardization, development, evolution, and growth of Pixar’s Universal Scene Description technology.
NVIDIA joined Pixar, Adobe, Apple and Autodesk today to found the Alliance for OpenUSD, a major leap toward unlocking the next era of 3D graphics, design and simulation. The group will standardize and extend OpenUSD, the open-source Universal Scene Description framework that’s the foundation of interoperable 3D applications and projects ranging from visual effects to Read article >
Principal NVIDIA artist and 3D expert Michael Johnson creates highly detailed art that’s both technically impressive and emotionally resonant.