Synchronization in graphics programming refers to the coordination and control of concurrent operations to ensure the correct and predictable execution of…
Synchronization in graphics programming refers to the coordination and control of concurrent operations to ensure the correct and predictable execution of rendering tasks. Improper synchronization across the CPU and GPU can lead to slow performance, race conditions, and visual artifacts.
Recommended
If running workloads asynchronously, make sure that they stress different GPU units. For example, pair bandwidth-heavy tasks with math-heavy tasks. That is, use z-prepass and BVH build or post-processing.
Always verify whether the asynchronous implementation is faster across the different architectures.
Asynchronous work can belong to different frames. Using this technique can help find better-paired workloads.
Wait and signal the absolute minimum of semaphores/fences. Every excessive semaphore/fence can introduce a bubble in a pipeline.
Use GPU profiling tools (NVIDIA Nsight Graphics in GPU trace mode, PIX, or GPUView) to see how well work overlaps and fences play together without stalling one queue or another.
To avoid extra synchronizations and resource barriers, asynchronous copy/transfer work can be done in compute queue.
Not recommended
Do not create queues that you don’t use.
Each additional queue adds processing overhead.
Multiple asynchronous compute queues will not overlap, due to the OS scheduler, unless hardware scheduling is enabled. For more information, see Hardware Accelerated GPU Scheduling.
Avoid tiny asynchronous tasks and group them if possible. Asynchronous workloads that take
Avoid using fences to synchronize work within the queue. Command lists/buffers are guaranteed to be executed in order of submission within a command queue by specification.
Semaphores/fences should not be used instead of resource barriers. They are way more expensive and support different purposes.
Do not implement low-occupancy workloads with the intention to align them with more work on the graphics queue. GPU capabilities may change and low-occupancy work might become a long, trailing tail that stalls another queue.
Precisely reproducing VR experiences is critical to many workflows, yet it is extremely challenging. But VR testing is critical for many teams, especially when…
Precisely reproducing VR experiences is critical to many workflows, yet it is extremely challenging. But VR testing is critical for many teams, especially when they’re looking to troubleshoot a VR experience, or want to gain more insights into what customers see when they put on the headset.
Chaos Enscape is using NVIDIA VR Capture and Replay (VCR) to streamline their VR build tests by playing back recorded VR sessions using NVIDIA VCR to confirm that new Enscape builds perform as expected.
Enscape is a real-time visualization tool used predominantly in the AECO space that has VR capabilities. The team at Chaos is responsible for developing the VR functionalities of the app. Before using VCR, a large part of Chaos Enscape’s VR menu and movement testing relied on manual testing: a hands-on process that was time-consuming and labor-intensive.
To test VR scenes, a user must navigate a VR scene and press the VR controller buttons in a sequence. For every test, the user must do the same VR headset motions and press the same button sequences to get consistent results. But, it’s impossible to always repeat every movement with identical position and timing.
NVIDIA VCR helps address these challenges by providing an easy-to-use solution for VR recording, editing, analysis, and replay. This enables the engineering team to streamline the VR testing process.
“With NVIDIA VCR, our testing has improved because its capture and replay capabilities enable us to run automated tests simulating complex VR interactions as part of our continuous integration,” said Josua Meier, rendering engineer at Chaos.
Automating the VR testing process
Previously, testing VR features and software builds were only performed manually and periodically for Chaos Enscape. This meant that it often took longer to find issues within their VR.
Now, in addition to manual testing, the Chaos Enscape team uses NVIDIA VCR to run automated tests every day to ensure that their VR implementation works as expected.
Here’s how NVIDIA VCR works:
NVIDIA VCR records VR user inputs: head and controller motion and controller button inputs.
For playback, the VR application receives VR inputs from an NVIDIA VCR-recorded file. The replayed session is an extremely accurate reproduction of the original session.
The same VR session can be replayed repeatedly at the desktop, and replay does not require a physical VR operator.
Figure 1. Chaos Enscape demonstrating the Lake|Flato Architects office space model, captured in NVIDIA VCR
NVIDIA VCR playback is precise and enables engineers at Chaos to test controller inputs and teleport through a scene using automated playback scripts.
“NVIDIA VCR helps us find issues in our VR implementation faster, potentially saving us days in the test cycle before a release,” said Meier. “It’s a great solution for running stable, reproducible VR tests, which is also easy to integrate into existing systems.”
Based on previous testing across multiple ISVs, developers have experienced reduced times for VR testing, an average of 2.5 hours per week.
Learn more
In addition to streamlining VR application testing, you can use NVIDIA VCR as a developer tool for filtering NVIDIA VCR-recorded sessions. Using the included C++ API, you can create scripts for editing, re-timing, and filtering to smooth out user inputs.
NVIDIA VCR can also help marketing and analytics teams, as it enables VR sessions to be replayed to objectively review where VR users look to target optimal product placement in VR retail experiences.
For more information, see the following resources:
From smart factories to next-generation railway systems, developers and enterprises across the world are racing to fuel industrial digitalization opportunities at every scale. Key to this is the open-source Universal Scene Description (USD) framework, or OpenUSD, along with metaverse applications powered by AI. OpenUSD, originally developed by Pixar for large-scale feature film pipelines for animation Read article >
Autonomous vehicle (AV) development requires massive amounts of sensor data for perception development. Developers typically get this data from two…
Autonomous vehicle (AV) development requires massive amounts of sensor data for perception development.
Developers typically get this data from two sources—replay streams of real-world drives or simulation. However, real-world datasets offer limited flexibility, as the data is fixed to only the objects, events, and view angles captured by the physical sensors. It is also difficult to simulate the detail and imperfection of real-world conditions—such as sensor noise or occlusions—at scale.
Neural fields have gained significant traction in recent years. These AI tools capture real-world content and simulate it from novel viewpoints with high levels of realism, achieving the fidelity and diversity required for AV simulation.
At NVIDIA GTC 2022, we showed how we use neural reconstruction to build a 3D scene from recorded camera sensor data in simulation, which can then be rendered from novel views. A paper we published for ICCV 2023—which runs Oct. 2 to Oct.6—details how we applied a similar approach to address these challenges in synthesizing lidar data.
Figure 1. An example novel viewpoint rendered by neural lidar fields
The method, called neural lidar fields, optimizes a neural radiance field (NeRF)-like representation from lidar measurements that enables synthesizing realistic lidar scans from entirely new viewpoints. It combines neural rendering with a physically based lidar model to accurately reproduce sensor behaviors—such as beam divergence, secondary returns, and ray dropping.
With neural lidar fields, we can achieve improved realism of novel views, narrowing the domain gap with real lidar data recordings. In doing so, we can improve the scalability of lidar sensor simulation and accelerate AV development.
By applying neural rendering techniques such as neural lidar fields in NVIDIA Omniverse, AV developers can bypass the time– and cost-intensive process of rebuilding real-world scenes by hand. They can bring physical sensors into a scalable and repeatable simulation.
Novel view synthesis
While replaying recorded data is a key component of testing and validation, it is critical to also simulate new scenarios for the AV system to experience.
These scenarios make it possible to test situations where the vehicle deviates from the original trajectory. It will view the world from novel views. This benefit also extends to testing a sensor suite on a different vehicle type, where the rig may be positioned differently (for example, switching from a sedan to an SUV).
With the ability to modify sensor properties such as beam divergence and ray pattern, we can also use a different lidar type in simulation than the sensor that originally recorded the data.
However, previous explicit approaches to simulating novel views have proven cumbersome and often inaccurate. First, surface representation—such as surfels or a triangular mesh—must be extracted from scanned lidar point clouds. Then, lidar measurements are simulated from a novel viewpoint by casting rays and intersecting them with the surface model.
These methods—known as explicit reconstruction—introduce noticeable errors in the rendering as well as assuming a perfect lidar model with no divergence of beams.
Neural lidar fields method
Rather than rely on an error-prone reconstruction pipeline, the neural lidar fields method takes a NeRF-style approach. It is based on neural scene representation and sensor modeling, which is directly optimized to render sensor measurements. This results in a more realistic output.
Specifically, we used an improved, lidar-specific volume rendering procedure, which creates range and intensity measurements from the 3D scene. Then, we added beam divergence for improved realism. We took into account that lidar works as an active sensor—rather than a passive one like a camera. This, along with characteristics such as beam divergence, enabled us to reproduce sensor properties, including dropped rays and multiple returns.
To test the accuracy of the neural lidar fields, we ran the scenes in a lidar simulator, comparing results with a variety of viewpoints taken at different distances from the original scan.
These scans were then compared with real data from the Waymo Open dataset, using metrics such as real-world intensities, ray drop, and secondary returns to evaluate fidelity. We also used real data to validate the accuracy of the neural lidar fields’ view synthesis in challenging scenes.
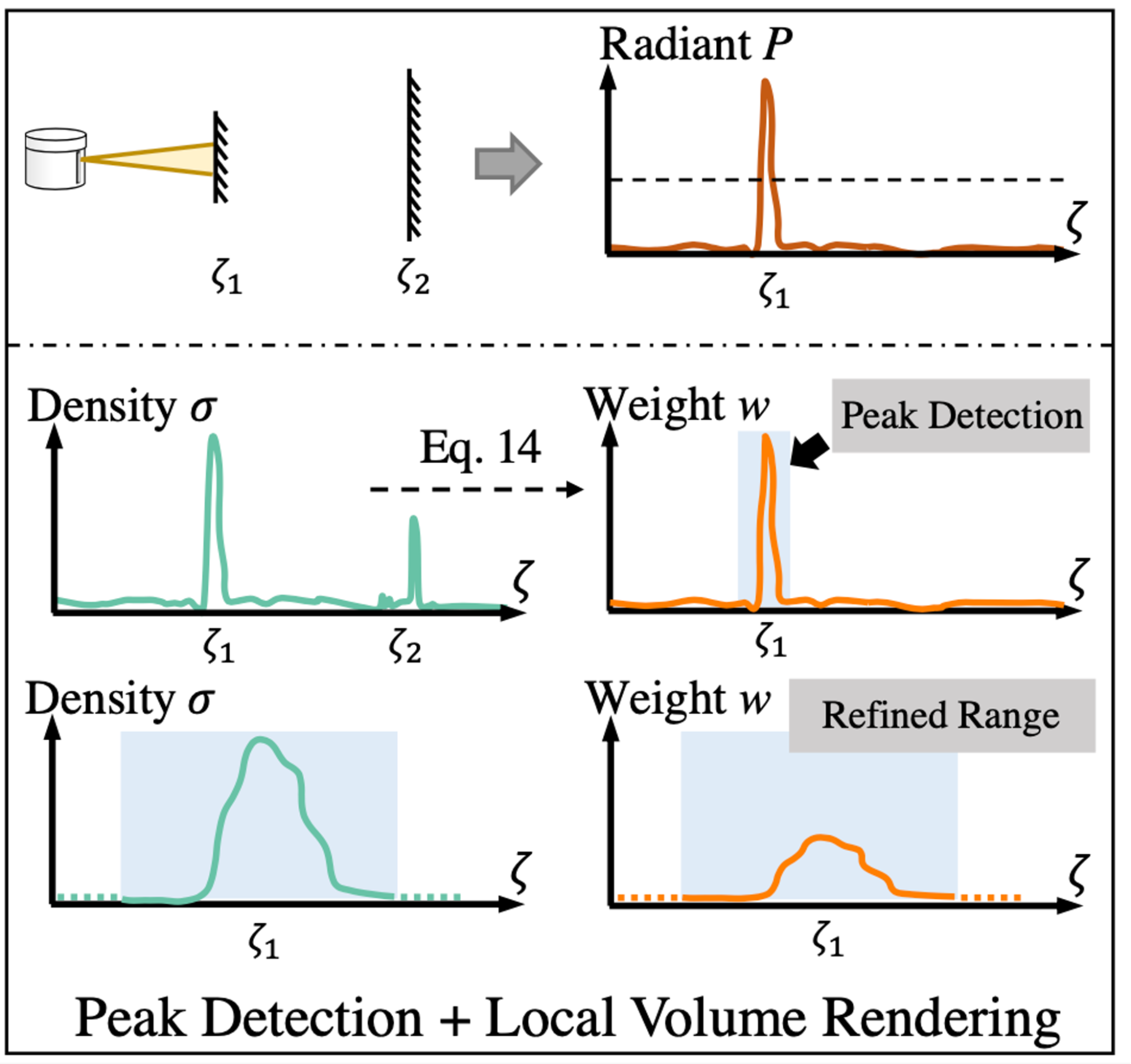
Figure 2. Neural lidar fields model the waveform
In Figure 2, the neural lidar fields accurately reproduce the waveform properties. The top row shows that the first surface fully scatters the lidar energy. The other rows shows that neural lidar fields estimate range through peak detection on the computed weights followed by volume rendering-based range refinement.
Results
Using these evaluation methods, we compared neural lidar field-synthesized lidar views with traditional reconstruction processes.
By accounting for real-world lidar characteristics, neural lidar field views reduced range errors and improved performance compared with explicit reconstruction. We also found the implicit method synthesized challenging scenes with high accuracy.
After we established performance, we then validated the neural lidar field-generated scans using two low-level perception tasks: point cloud registration and semantic segmentation.
We applied the same model to both real-world lidar scans and various synthesized scans to evaluate how well the scans maintained accuracy. We found that neural lidar fields outperformed the baseline methods on datasets with complex geometry and high noise levels.
Figure 3. Qualitative visualization of lidar novel view synthesis on the Waymo dataset.
For semantic segmentation, we applied the same pretrained model to both real and synthetic lidar scans. Neural lidar fields achieved the highest recall for vehicles, which are especially difficult to render due to sensor noise such as dual returns and ray drops.
While neural lidar fields are still an active research method, it is a critical tool for scalable AV simulation. Next, we plan to focus on generalizing the networks across scenes and handling dynamic environments. Eventually, developers on Omniverse and the NVIDIA DRIVE Sim AV simulator will be able to tap into these AI-powered approaches for accelerated and physically based simulation.
We would like to thank our collaborators at ETH Zurich, Shengyu Huang and Konrad Schindler, as well as Zan Gojcic, Zian Wang, Francis Williams, Yoni Kasten, Sanja Fidler, and Or Litany from the NVIDIA Research team.
Machine learning-based weather prediction has emerged as a promising complement to traditional numerical weather prediction (NWP) models. Models such as NVIDIA…
Machine learning-based weather prediction has emerged as a promising complement to traditional numerical weather prediction (NWP) models. Models such as NVIDIA FourCastNet have demonstrated that the computational time for generating weather forecasts can be reduced from hours to mere seconds, a significant improvement to current NWP-based workflows.
Traditional methods are formulated from first principles and typically require a timestep restriction to guarantee the accuracy of the underlying numerical method. ML-based approaches do not come with such restrictions, and their uniform memory access patterns are ideally suited for GPUs.
However, these methods are purely data-driven, and you may rightfully ask:
How can we trust these models?
How well do they generalize?
How can we further increase their skill, trustworthiness, and explainability, if they are not formulated from first principles?
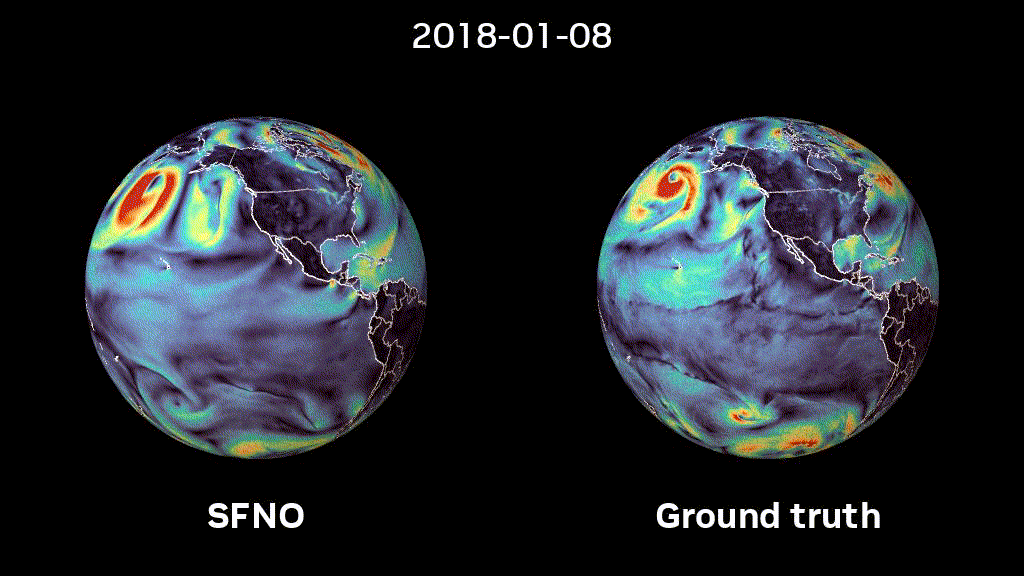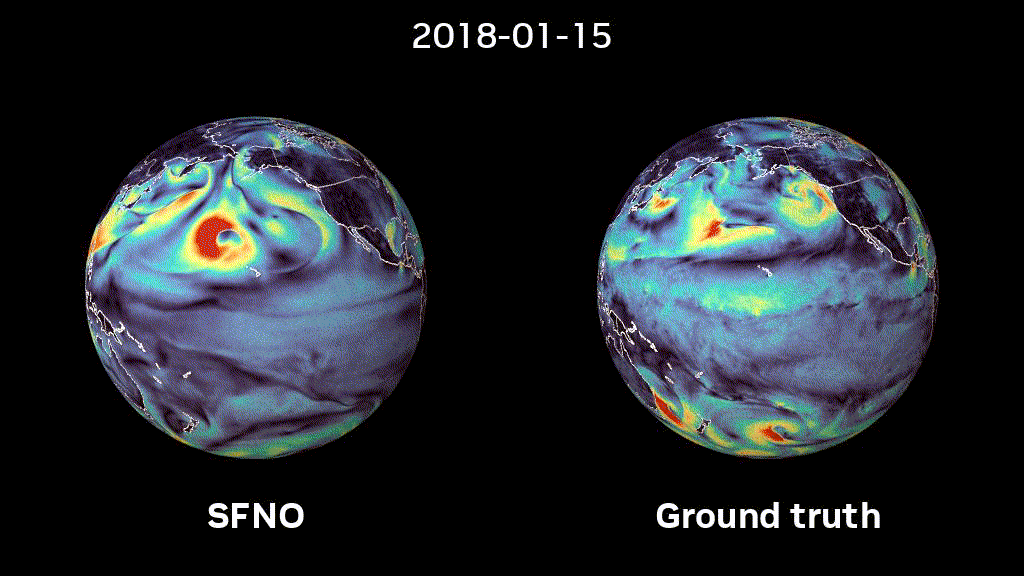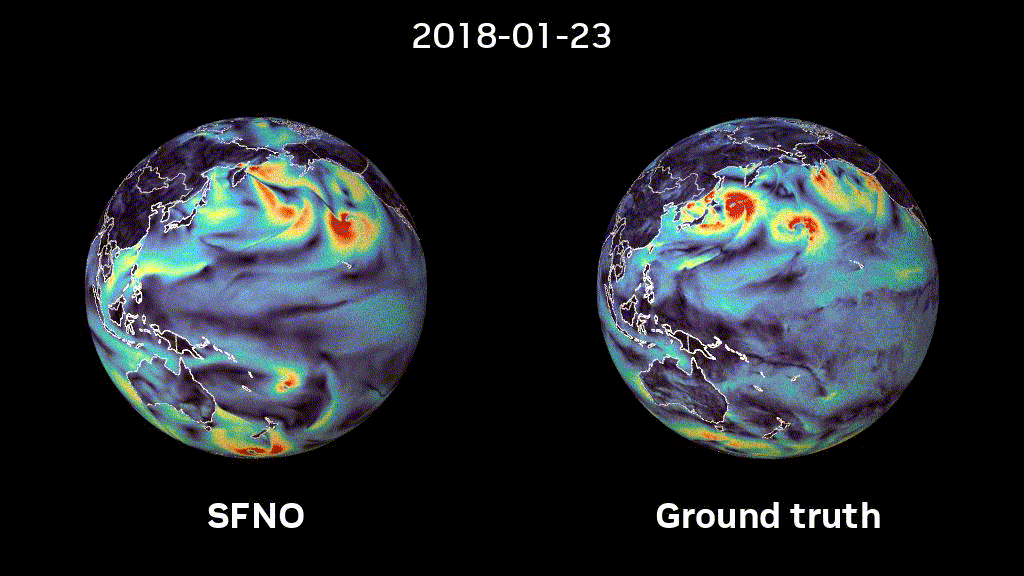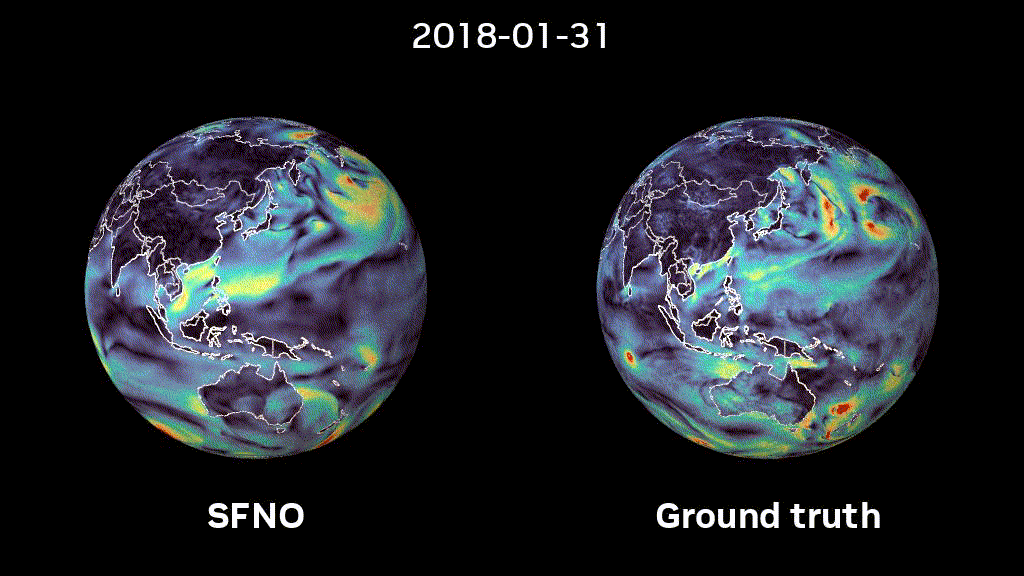
Figure 1: 5-month-long rollout of SFNO. Surface windspeed predictions with SFNO and ground truth data are compared to each other.
A potential approach to creating principled and trustworthy models involves formulating them in a manner akin to the formulation of physical laws.
Physical laws are typically formulated from symmetry considerations:
We do not expect physics to depend on the frame of reference.
We further expect underlying physical laws to remain unchanged if the frame of reference is altered.
In the context of physical systems on the sphere, changes in the frame of reference are accomplished through rotations. Thus, we strive to establish a formulation that remains equivariant under rotations.
Current ML-based weather prediction models treat the state of the atmosphere as a discrete series of vectors representing physical quantities of interest at various spatial locations over time. Any of these vectors are updated by a learned function, which maps the current state to the next state in the sequence.
In plain terms, we ask a neural network to consecutively predict the weather in the next time step when showing it the weather of today. This is comparable to the integration of a physical system using traditional methods, with the caveat of having learned the dynamics in a purely data-driven manner, as opposed to deriving them from physical laws. This approach enables significantly larger time steps as opposed to traditional methods.
The task at hand can thus be understood as learning image-to-image mappings between finite-dimensional vector spaces.
While a broad variety of neural network topologies such as U-Nets are applicable to this task, such approaches ignore the functional nature of the problem. Both input and output are functions and their evolution is governed by partial differential equations.
Traditional ML approaches such as U-Nets ignore this, as they learn a map at a fixed resolution. Neural operators generalize neural networks to solve this problem. Rather than learning maps between finite-dimensional spaces, they learn an operator that can directly map one function to another.
As such, Fourier neural operators (FNOs) provide a powerful framework for learning maps between function spaces and approximating the solution operator of PDEs, which maps one state to the next.
However, classical FNOs are defined in Cartesian space, whose associated symmetries differ from those of the sphere. In practice, ignoring the geometry and pretending that Earth is a periodic rectangle leads to artifacts, which accumulate on long rollouts, due to the autoregressive nature of the model. Such artifacts typically occur around the poles and lead to a breakdown of the model (Figure 2).
You may now wonder, what would an FNO on a sphere look like?
Figure 2. Temperature predictions using AFNO vs. SFNO
Figure 2 shows temperature predictions using adaptive Fourier neural operators (AFNO) as compared to spherical Fourier neural operators (SFNO). Respecting the spherical geometry and associated symmetries avoids artifacts and enables a stable rollout.
Spherical Fourier neural operators
To respect the spherical geometry of Earth, we implemented spherical Fourier neural operators (SFNOs), a Fourier neural operator that is directly formulated in spherical coordinates. To achieve this, we made use of a convolution theorem formulated on the sphere.
Global convolutions are the central building blocks of FNOs. Their computation through FFTs is enabled by the convolution theorem: a powerful mathematical tool that connects convolutions to the Fourier transform.
Similarly, a convolution theorem on the sphere connects spherical convolutions to the generalization of the Fourier transform on the sphere: the spherical harmonic transform (SHT).
To enable the implementation of SFNOs, we required a differentiable SHT. To this end, we implemented torch-harmonics, a PyTorch library for differentiable SHTs. The library natively supports the computation of SHTs on single and multiple GPUs as well as CPUs, to enable scalable model parallelism. torch-harmonics can be installed easily by running the following command:
pip install torch-harmonics
torch-harmonics seamlessly integrates with PyTorch. The differentiable SHT can be easily integrated into any existing ML architecture as a module. To compute the SHT of a random function, run the following code example:
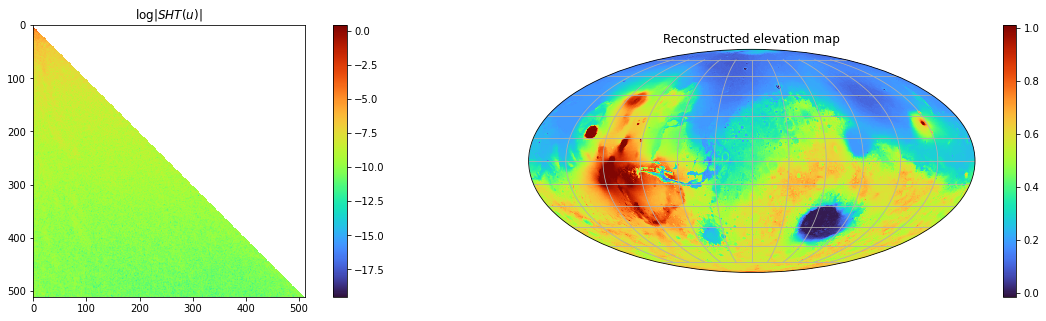
To get started with torch-harmonics, we recommend the getting-started notebook, which guides you through the computation of the spherical harmonic coefficients of Mars’ elevation map (Figure 3). The example showcases the computation of the coefficients using both the SHT and the differentiability of the ISHT.
Figure 3. Spherical harmonic coefficients of the elevation map of Mars, computed with torch-harmonics (left). Reconstructed signal computed with the inverse spherical harmonic transform (right).
Implications for ML-based weather forecasting
We trained SFNOs on the ERA5 dataset, provided by the European Centre for Medium-range Weather Forecasts (ECMWF). This dataset represents our best understanding of the state of Earth’s atmosphere over the past 44 years. Figure 2 shows that SFNO shows no signs of artifacts over the poles and rollouts remain remarkably stable, over thousands of autoregressive steps, for up to a year (Figure 1).
These results pave the way for the deployment of ML-based weather prediction methods. They offer a glimpse of how ML-based methods may hold the key to bridging the gap between weather forecasting and climate prediction, in the holy grail of sub-seasonal-to-seasonal forecasting.
A single rollout of SFNOs for a year, which involves 1460 autoregressive steps, is computed in 13 minutes on a single NVIDIA RTX A6000. That is over a thousand times faster than traditional numerical weather prediction methods.
Such substantially faster forecasting tools open the door to the computation of thousands of possible scenarios in the same time that it took to do a single one using traditional NWP, enabling higher confidence predictions of the risk of rare but high-impact extreme weather events.
More about SFNOs and the NVIDIA Earth-2 initiative
To see how SFNOs were used to generate thousands of ensemble members and predict the 2018 Algerian heat wave, watch the following video:
Video 1. Predicting Extreme Weather Risk Three Weeks in Advance with FourCastNet
For more information about SFNOs, see the following resources:
AI is improving ways to power the world by tapping the sun and the wind, along with cutting-edge technologies. The latest episode in the I AM AI video series showcases how artificial intelligence can help optimize solar and wind farms, simulate climate and weather, enhance power grid reliability and resilience, advance carbon capture and power Read article >
Get ready for Gunfire Games and Gearbox Publishing’s highly anticipated Remnant II, available for members to stream on GeForce NOW at launch. It leads eight new games coming to the cloud gaming platform. Ultimate and Priority members, make sure to grab the Guild Wars 2 rewards, available now through Thursday, Aug. 31. Visit the GeForce Read article >
ServiceNow (NYSE: NOW), NVIDIA (NASDAQ: NVDA), and Accenture (NYSE: ACN) today announced the launch of AI Lighthouse, a first-of-its-kind program designed to fast-track the development and adoption of enterprise generative AI capabilities.
AWS users can now access the leading performance demonstrated in industry benchmarks of AI training and inference. The cloud giant officially switched on a new Amazon EC2 P5 instance powered by NVIDIA H100 Tensor Core GPUs. The service lets users scale generative AI, high performance computing (HPC) and other applications with a click from a Read article >

 Synchronization in graphics programming refers to the coordination and control of concurrent operations to ensure the correct and predictable execution of…
Synchronization in graphics programming refers to the coordination and control of concurrent operations to ensure the correct and predictable execution of… NVIDIA HPC SDK version 23.7 is now available and provides minor updates and enhancements.
NVIDIA HPC SDK version 23.7 is now available and provides minor updates and enhancements. Precisely reproducing VR experiences is critical to many workflows, yet it is extremely challenging. But VR testing is critical for many teams, especially when…
Precisely reproducing VR experiences is critical to many workflows, yet it is extremely challenging. But VR testing is critical for many teams, especially when…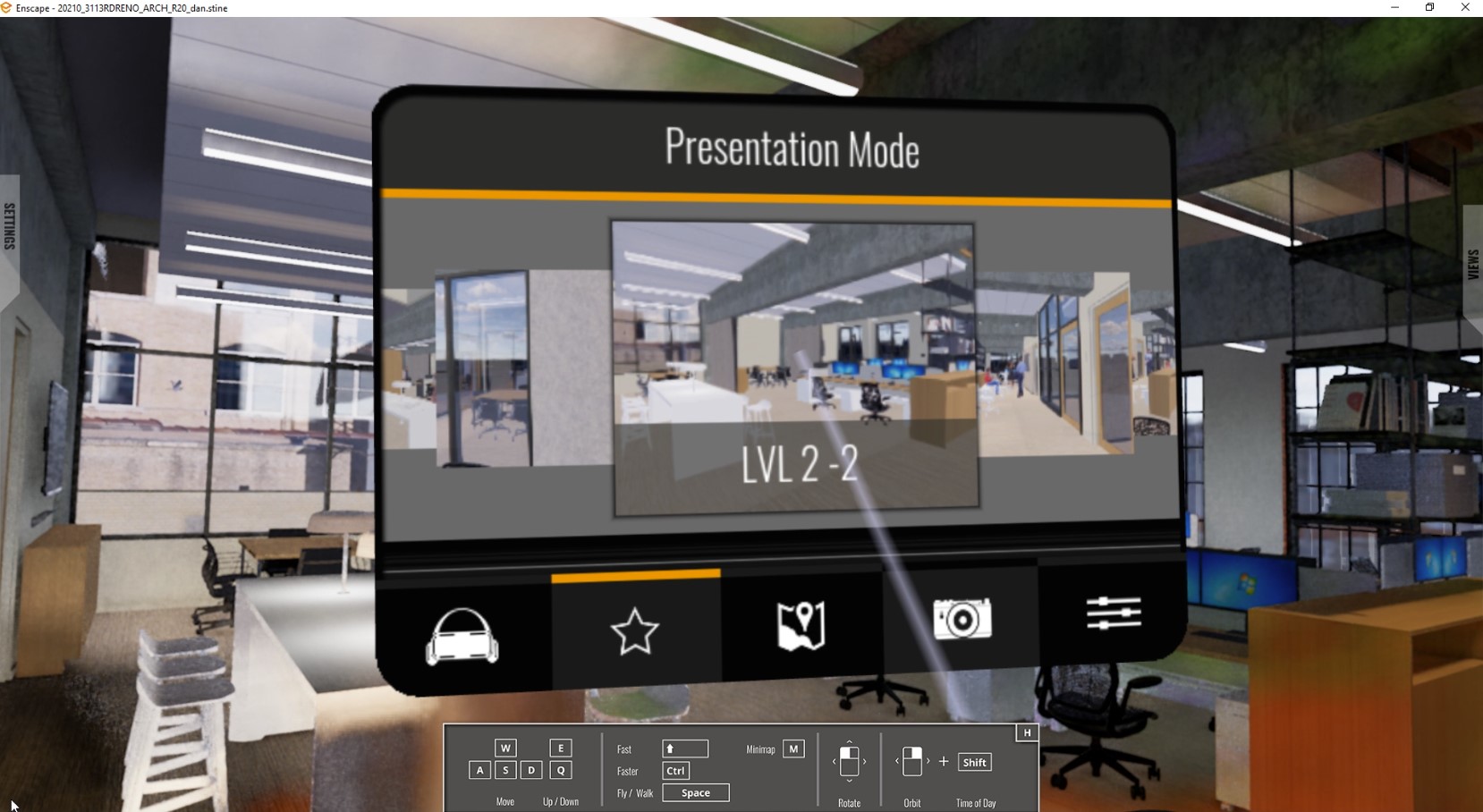
 Autonomous vehicle (AV) development requires massive amounts of sensor data for perception development. Developers typically get this data from two…
Autonomous vehicle (AV) development requires massive amounts of sensor data for perception development. Developers typically get this data from two…

 Machine learning-based weather prediction has emerged as a promising complement to traditional numerical weather prediction (NWP) models. Models such as NVIDIA…
Machine learning-based weather prediction has emerged as a promising complement to traditional numerical weather prediction (NWP) models. Models such as NVIDIA…