Autonomous vehicle developers now have access to flexible, scalable, and high-performance hardware and software to build the next generation of safer, more…
Autonomous vehicle developers now have access to flexible, scalable, and high-performance hardware and software to build the next generation of safer, more efficient transportation.
NVIDIA DRIVE AGX Orin Developer Kit is now available for general access. Powered by a single Orin system-on-a-chip (SoC), the AI compute platform includes the hardware, software, and sample applications needed to develop production-level autonomous vehicles. It’s also modular, sharing the same design as NVIDIA Jetson, NVIDIA Isaac, and NVIDIA Clara AGX platforms.
With a rich automotive I/O, you have the flexibility to expand and iterate upon your autonomous driving solutions. DRIVE AGX Orin includes a base kit for bench development and an add-on vehicle kit for vehicle installation. The platform also has a smaller footprint than previous generations, with system and accessories included in a single box.
Additionally, NVIDIA DRIVE OS 6 is now available on the NVIDIA DRIVE Developer Download page, providing the latest operating system purpose-built for autonomous vehicles.
NVIDIA DRIVE OS includes NvMedia for sensor input processing, NVIDIA CUDA libraries for efficient parallel computing implementations, and NVIDIA TensorRT for real-time AI inference.
The current version available is DRIVE OS 6.0.4, which supports sensors included in the NVIDIA DRIVE Hyperion 8.1 platform architecture.
Successfully deploying an automatic speech recognition (ASR) application can be a frustrating experience. For example, it is difficult for an ASR system to…
Successfully deploying an automatic speech recognition (ASR) application can be a frustrating experience. For example, it is difficult for an ASR system to correctly identify words while maintaining low latency, considering the many different dialects and pronunciations that exist.
Whether you are using a commercial or open-source solution, there are many challenges to consider when building an ASR application.
In this post, I highlight major pain points that developers face when adding ASR capabilities to applications. I share how to approach and overcome these challenges, using NVIDIA Riva speech AI SDK as an example.
Challenges of building ASR applications
Here are a few challenges present in the creation of any ASR system:
High accuracy
Low latency
Compute resource allocation
Flexible deployment and scalability
Customization
Monitoring and tracking
High accuracy
One key metric to measure speech recognition accuracy is the word error rate (WER). WER is defined as the ratio of total incorrect and missing words identified during transcription and sum of total number of words present in the labeled transcripts.
Several reasons cause transcription errors in ASR models leading to misinterpretations of information:
Quality of the training dataset
Different dialects and pronunciations
Accents and variations in speech
Custom or domain-specific words and acronyms
Contextual relationship of words
Differentiating phonetically similar sentences
Due to these factors, it is difficult to build a robust ASR model with a low WER score.
Low latency
A conversational AI application is an end-end pipeline composed of speech AI and natural language processing (NLP).
For any conversational AI application, response time plays a critical factor to make any natural conversations. It would not be practical to converse with a bot if a customer only receives a response after 1 minute of waiting time.
It has been observed that any conversation AI application should deliver a latency of less than 300 msec. So, it becomes critical to make sure that speech AI model latency is far below the 300 msec limit to be integrated into an end-end pipeline for real-time conversational AI applications.
Many factors affect the overall latency of the ASR model:
Model size: Large and complex models have better accuracy but require a lot of computation power and add to the latency compared to smaller models; that is, the inference cost is high.
Hardware: Edge deployment of such complex models further adds to the complexity of latency requirements.
Network bandwidth: Sufficient bandwidth is needed for streaming audio content and transcripts, especially in the case of cloud-based deployment.
Compute resource allocation
Optimizing the ASR model and its resource utilizations applies to all AI models and is not only specific to the ASR model. However, it is a critical factor that impacts overall latency as well as the compute cost to run any AI application.
The whole point of optimizing a model is to reduce the inference cost both at compute level as well as the latency level. But all models available online for a particular architecture are not created equally and do not have the same code quality. They also have dramatic differences in performance.
Also, not all of them respond in the same way to knowledge distillation, pruning, quantization, and other optimization techniques to result in improved inference performance without impacting the accuracy results.
Flexible deployment and scalability
Creating an accurate and efficient model is only a small fraction of any real-time AI application. The required surrounding infrastructure is vast and complex. For example, deployment infrastructure should include:
Streaming support
Resource management service
Servicing infrastructure
Analytics tool support
Monitoring service
Creating a custom end-end optimized deployment pipeline that supports the required latency requirement for any ASR application is challenging because it requires optimization and acceleration at each pipeline stage.
Based on the number of audio streams that must be supported at a given instance, your speech recognition application should be able to auto-scale the application deployment to provide acceptable performance.
Customization
Getting a model to work out-of-the-box is always the goal. However, the performance of currently available models depends on the dataset used during its training phase. Models typically work great for the use case they’ve already been exposed to, but the same model’s performance may degrade as soon as it is deployed in different domain applications.
Specifically, in the case of ASR, the model’s performance depends on accent or language and variations in speech. You should be able to customize models based on the application use case.
For instance, speech recognition models being deployed in healthcare– or financial-related applications require support for domain-specific vocabulary. This vocabulary differs from what is normally used during ASR model training.
To support regional languages for ASR, you need a complete set of training pipelines to easily customize the model and efficiently handle different dialects.
Monitoring and tracking
Real-time monitoring and tracking help in getting instant insights, alerts, and notifications so that you can take timely corrective actions. This helps in tracking the resource consumption as per the incoming traffic so that the corresponding application can be auto-scaled. Quota limits can also be set to minimize the infrastructure cost without impacting the overall throughput.
Capturing all these stats requires integrating multiple libraries to capture performance at various stages of the ASR pipeline.
Examples of how the Riva SDK addresses ASR challenges
Advanced SDKs can be used to conveniently add a voice interface to your applications. In this post, I demonstrate how a GPU-accelerated SDK like Riva can be applied to solve these challenges when building speech recognition applications.
High accuracy and compute optimization
You can use pretrained Riva speech models in NGC that can be fine-tuned with TAO Toolkit on a custom data set, further accelerating domain-specific model development by 10x.
All NGC models are optimized and sped up for GPU deployment to achieve better recognition accuracy. These models are also fully supported by NVIDIA TensorRT optimization. Riva’s high-performance inference is powered by TensorRT optimizations and served using the NVIDIA Triton Inference Server to optimize the overall compute requirement and, in turn, improve the server throughput
For example, here are a few ASR models on NGC that are further optimized as part of the Riva pipeline for better performance:
Figure 1. ASR performance acceleration using NVIDIA Riva
Low latency
Latencies and throughput measurements for streaming and offline configurations are reported under theASR performance section of Riva documentation.
In “streaming low latency” Riva ASR model deployment mode, the average latency (ms) is far less than 50 ms for most of the cases. Using such ASR models, it becomes easier to create a real-time conversational AI pipeline and still achieve the
Flexible deployment and scaling
Deploying your speech recognition application on any platform with ease requires full support. The Riva SDK provides flexibility at each step from fine-tuning models on domain-specific datasets to customizing pipelines. It can also be deployed in the cloud, on-premises, edge, and embedded devices.
To support scaling, Riva is fully containerized and can scale to hundreds and thousands of parallel streams. Riva is also included in the NGC Helm repository, which is a chart designed to automate for push-button deployment to a Kubernetes cluster.
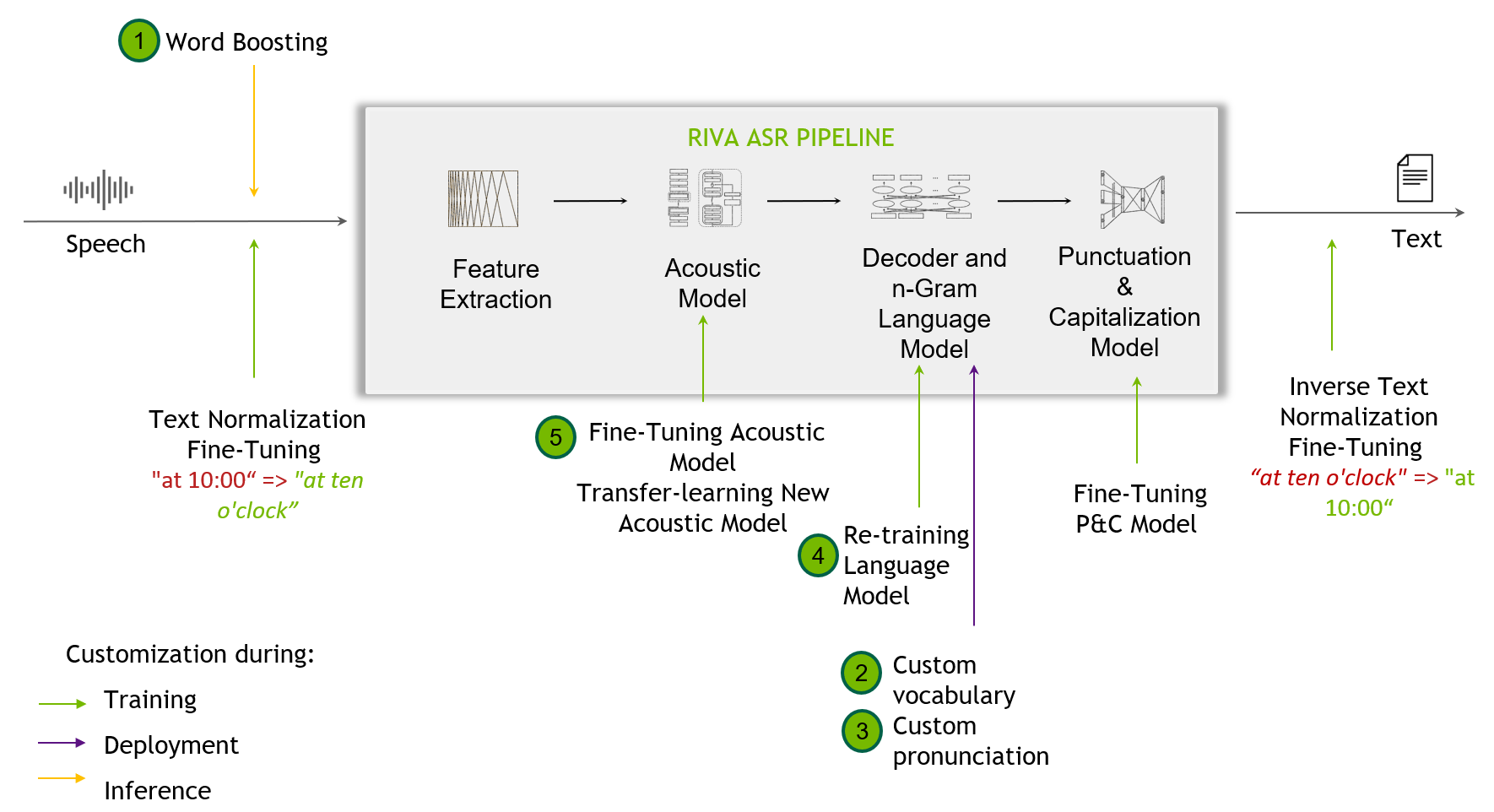
Figure 2.Customization techniques range from word boosting to fine-tuning punctuation and capitalization models
Customization techniques are helpful when out-of-the-box Riva models fall short dealing with challenging scenarios not seen in the training data. This might include recognizing narrow domain terminologies, new accents, or noisy environments.
SDKs like Riva supportcustomization, starting from the word-boosting level, and provision for the end user to custom train their acoustic models.
Riva speech skills also provide high-quality, pretrained models across a variety of languages. For more information about all the models for supported languages, see the Language Support section.
Monitoring and tracking
In Riva, underlying Triton Inference Server metrics are available to the end users to use, based on the customization and dashboard creation. These metrics are only available by accessing the endpoint.
NVIDIA Triton provides Prometheus metrics, as well as indicating GPU and request statistics. This helps in monitoring and tracking the production deployment setup.
Key takeaways
This post provides you with a high-level overview of common pain points that arise when developing AI applications with ASR capabilities. Being aware of the factors impacting your ASR application’s overall performance helps you streamline and improve the end-to-end development process.
We also shared a few functionalities of Riva that can help mitigate these problems to an extent and even provide customizability tips for ASR applications to support your domain-specific use case.
For more information, see the following resources:
Ready for a hands-on lab? Use pretrained models and quickly try out ASR customization techniques, such as word boosting, with the free lab, Customizing ASR with NVIDIA Riva.
Register now to experience the most advanced developer tools and learn how experts across industries are using vision AI to increase operational efficiency.
Register now to experience the most advanced developer tools and learn how experts across industries are using vision AI to increase operational efficiency.
NVIDIA is collaborating with the United Nations Economic Commission for Africa (UNECA) to equip governments and developer communities in 10 nations with data science training and technology to support more informed policymaking and accelerate how resources are allocated. The initiative will empower the countries’ national statistical offices — agencies that handle population censuses data, economic Read article >
Joseph Fraunhofer was a 19th-century pioneer in optics who brought together scientific research with industrial applications. Fast forward to today and Germany’s Fraunhofer Society — Europe’s largest R&D organization — is setting its sights on the applied research of key technologies, from AI to cybersecurity to medicine. Its Fraunhofer IML unit is aiming to push Read article >
Data is the fuel that makes artificial intelligence run. Training machine learning and AI systems requires data. And the quality of datasets has a big impact on the systems’ results. But compiling quality real-world data for AI and ML can be difficult and expensive. That’s where synthetic data comes in. The guest for this week’s Read article >
In the NVIDIA Studio celebrates the Open Broadcaster Software (OBS) Studio’s 10th anniversary and its 28.0 software release. Plus, popular streamer WATCHHOLLIE shares how she uses OBS and a GeForce RTX 3080 GPU in a single-PC setup to elevate her livestreams.
The increasing adoption of cloud-native workloads is causing a significant shift in infrastructure architecture to support next-generation applications such as…
The increasing adoption of cloud-native workloads is causing a significant shift in infrastructure architecture to support next-generation applications such as AI and big data. Infrastructure must evolve to provide composability and flexibility using virtualization, containers, or bare metal servers.
Traditional software-defined infrastructure provides flexibility but suffers from performance and scalability limitations, as up to 30% of server CPU cores may be consumed by workloads such as networking, storage, and security.
VMware saw this as an opportunity to enhance vSphere infrastructure and reengineered it to take a hardware-based, disaggregated approach. The infrastructure software stack is now tightly coupled to the hardware stack. The result is VMware vSphere Distributed Services Engine (VMware Project Monterey), which integrates closely with the NVIDIA BlueField DPU to provide an evolutionary architectural approach for data center, cloud, and edge. It addresses the changing requirements of next-gen and cloud-native workloads.
To help organizations test the benefits of vSphere on BlueField DPUs, NVIDIA LaunchPad has curated a lab with exclusive access to live demonstrations and self-paced learning. The lab is designed to provide your IT team with deep, practical experience in a hosted environment before starting an on-premises deployment.
vSphere Distributed Services Engine
vSphere Distributed Services Engine is a software-defined and hardware-accelerated architecture for VMware’s Cloud Foundation. It provides a breakthrough solution that supports virtualization, containers, and scalable management.
The BlueField DPU offloads, accelerates, and isolates the infrastructure workloads, allowing the server CPUs to focus on core applications and revenue-generating tasks. The integration of VMware vSphere and NVIDIA BlueField simplifies building a cloud-ready infrastructure, while providing a consistent service quality in multi-cloud environments.
VMware enables workload composability and portability that supports multi-cloud. At the same time, BlueField handles critical networking, storage, security, and management, including telemetry tasks, freeing up the CPUs to run business and tenant applications. The BlueField DPU also provides security isolation by running firewall, key management, and IDS/IPS on its Arm cores, in a separate domain from the applications.
NVIDIA LaunchPad
LaunchPad gives you access to dedicated hardware and software through a remote lab, so that IT teams can walk through the entire process of deploying and managing a vSphere on BlueField DPUs. The lab is designed to provide your IT team with deep, practical experience in a hosted environment before starting your on-premises deployment.
Background
To understand why this is important, start by looking at how modern applications have changed. Modern applications are driving many underlying hardware infrastructure requirements, including
Increased networking traffic that creates performance and scale challenges
Hardware acceleration requirements that drive significant operational complexities
A lack of a clear definition of the traditional data center perimeter, which intensifies the need for new security models.
We are seeing that modern applications require more server CPU cycles. As the application requirements for compute continue to grow, increased infrastructure requirements for CPU cycles compete with application requirements.
Specialized data processing units (DPUs) have been developed to offload, accelerate and isolate CPU networking, storage, security, and management tasks. With DPUs, organizations free up server-CPU cycles for core application processing, which accelerates job completion time over a robust zero-trust data center infrastructure.
Selected functions that used to run on the core CPU are offloaded, accelerated, and isolated on BlueField to support new possibilities, including the following:
Improved performance for application and infrastructure services
Enhanced visibility, application security, and observability
Isolated security capabilities
Enhanced data center efficiency and reduced enterprise, edge, and cloud costs
Next steps
VMware vSphere is leading the shift to advanced hybrid-cloud data center architectures, which benefit from the hypervisor and accelerated software-defined networking, security, and storage. With access to vSphere on BlueField DPU preconfigured clusters, you can explore the evolution of VMware Cloud Foundation and take advantage of the disruptive hardware capabilities of servers equipped with BlueField DPUs.
In the machine learning and MLOps world, GPUs are widely used to speed up model training and inference, but what about the other stages of the workflow like ETL…
In the machine learning and MLOps world, GPUs are widely used to speed up model training and inference, but what about the other stages of the workflow like ETL pipelines or hyperparameter optimization?
Within the RAPIDS data science framework, ETL tools are designed to have a familiar look and feel to data scientists working in Python. Do you currently use Pandas, NumPy, Scikit-learn, or other parts of the PyData stack within your KubeFlow workflows? If so, you can use RAPIDS to accelerate those parts of your workflow by leveraging the GPUs likely already available in your cluster.
In this post, I demonstrate how to drop RAPIDS into a KubeFlow environment. You start with using RAPIDS in the interactive notebook environment and then scale beyond your single container to use multiple GPUs across multiple nodes with Dask.
Optional: Installing KubeFlow with GPUs
This post assumes you are already somewhat familiar with Kubernetes and KubeFlow. To explore how you can use GPUs with RAPIDS on KubeFlow, you need a KubeFlow cluster with GPU nodes. If you already have a cluster or are not interested in KubeFlow installation instructions, feel free to skip ahead.
KubeFlow is a popular machine learning and MLOps platform built on Kubernetes for designing and running machine learning pipelines, training models, and providing inference services.
KubeFlow also provides a notebook service that you can use to launch an interactive Jupyter server in your Kubernetes cluster and a pipeline service with a DSL library, written in Python, to create repeatable workflows. Tools for adjusting hyperparameters and running a model inference server are also accessible. This is essentially all the tooling that you need for building a robust machine learning service.
For this post, you use Google Kubernetes Engine (GKE) to launch a Kubernetes cluster with GPU nodes and install KubeFlow onto it, but any KubeFlow cluster with GPUs will do.
Creating a Kubernetes cluster with GPUs
First, use the gcloud CLI to create a Kubernetes cluster.
$ gcloud container clusters create rapids-gpu-kubeflow
--accelerator type=nvidia-tesla-a100,count=2 --machine-type a2-highgpu-2g
--zone us-central1-c --release-channel stable
Note: Machines with GPUs have certain limitations which may affect your workflow. Learn more at https://cloud.google.com/kubernetes-engine/docs/how-to/gpus
Creating cluster rapids-gpu-kubeflow in us-central1-c...
Cluster is being health-checked (master is healthy)...
Created
kubeconfig entry generated for rapids-gpu-kubeflow.
NAME LOCATION MASTER_VERSION MASTER_IP MACHINE_TYPE NODE_VERSION NUM_NODES STATUS
rapids-gpu-kubeflow us-central1-c 1.21.12-gke.1500 34.132.107.217 a2-highgpu-2g 1.21.12-gke.1500 3 RUNNING
With this command, you’ve launched a GKE cluster called rapids-gpu-kubeflow. You’ve specified that it should use nodes of type a2-highgpu-2g, each with two A100 GPUs.
KubeFlow also requires a stable version of Kubernetes, so you specified that along with the zone in which to launch the cluster.
Then, install KubeFlow by cloning the KubeFlow manifests repo, checking out the latest release, and applying them.
$ git clone https://github.com/kubeflow/manifests
$ cd manifests
$ git checkout v1.5.1 # Or whatever the latest release is
$ while ! kustomize build example | kubectl apply -f -; do echo "Retrying to apply resources"; sleep 10; done
After all the resources have been created, KubeFlow still has to bootstrap itself on your cluster. Even after this command finishes, things may not be ready yet. This can take upwards of 15 minutes.
Eventually, you should see a full list of KubeFlow services in the kubeflow namespace.
After all your pods are in a Running state, port forward the KubeFlow web user interface, and access it in your browser.
Navigate to 127.0.0.1:8080 and log in with the default credentials user@example.com and 12341234. Then, you should see the KubeFlow dashboard (Figure 1).
Before launching your cluster, you must create a configuration profile that is important for when you start using Dask later. To do this, apply the following manifest:
Now, choose a RAPIDS version to use. Typically, you want to choose the container image for the latest release. The default CUDA version installed on GKE Stable is 11.4, so choose that. As of version 11.5 and later, it won’t matter as they will be backward compatible. Copy the container image name from the installation command:
Scroll down to Configurations, check the configure dask dashboard option, scroll to the bottom of the page, and then choose Launch. You should see it starting up in your list of notebooks. The RAPIDS container images are packed full of amazing tools, so this step can take a little while.
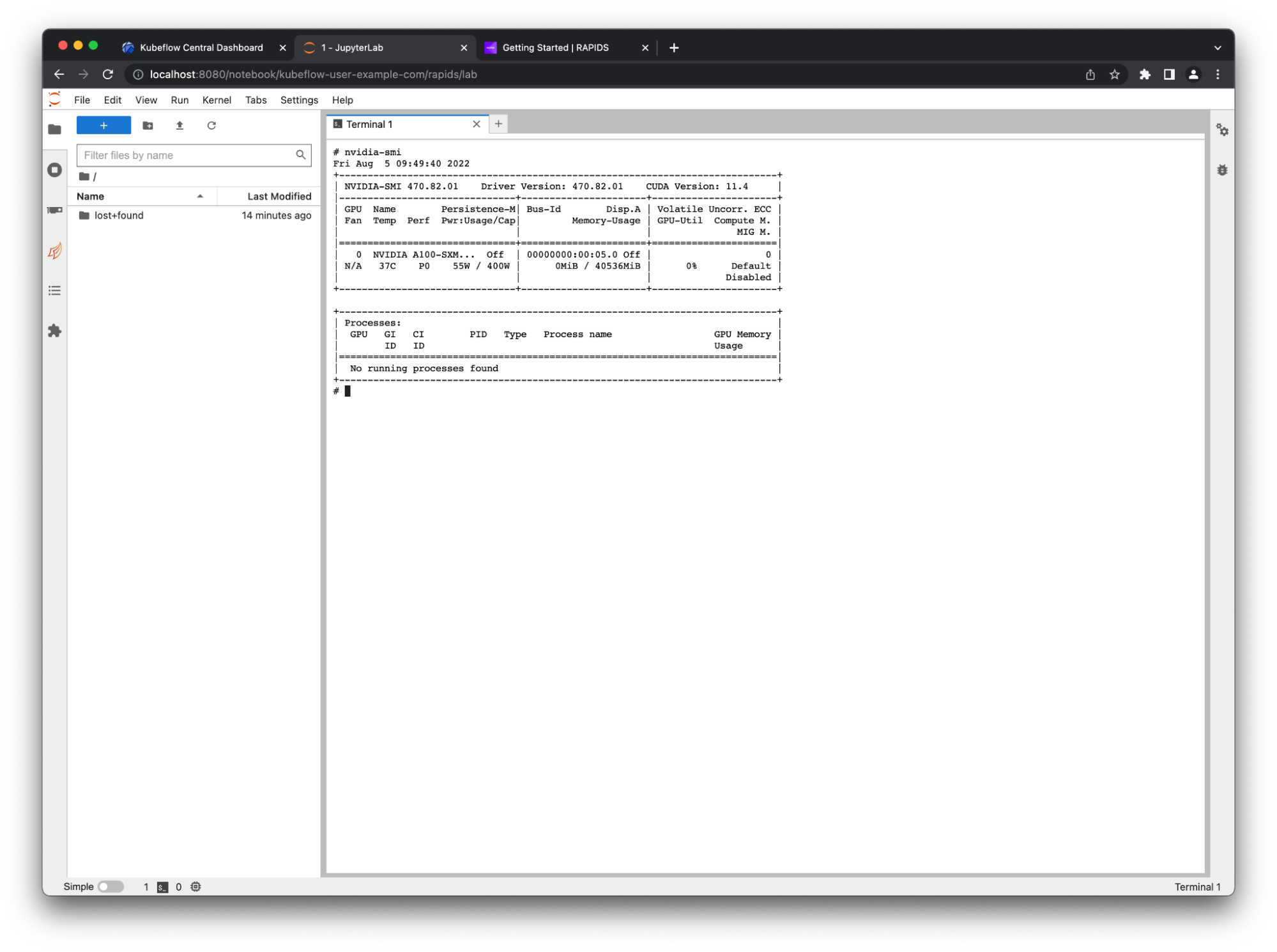
When the notebook is ready, to launch Jupyter, choose Connect. Verify that everything works okay by opening a terminal window and running nvidia-smi (Figure 2).
Figure 2. The nvidia-smi command is a great way to check that your GPU is set up
Success! Your A100 GPU is being passed through into your notebook container.
The RAPIDS container that you chose also comes with some example notebooks, which you can find in /rapidsai/notebooks. Make a quick symbolic link to these from your home directory so that you can navigate using the file explorer on the left:
ln -s /rapids/notebooks /home/jovyan/notebooks.
Navigate to those example notebooks and explore all the libraries that RAPIDS offers. For example, ETL developers that use pandas should check out the cuDF notebooks for examples of accelerated DataFrames.
Scaling your RAPIDS workflows
Many RAPIDS libraries also support scaling out your computations onto multiple GPUs spread over many nodes for added acceleration. To do this, use Dask, an open-source Python library for distributed computing.
To use Dask, create a scheduler and some workers to perform your calculations. These workers also need GPUs and the same Python environment as the notebook session. Dask has an operator for Kubernetes that you can use to manage Dask clusters on your KubeFlow cluster, so install that now.
Installing the Dask Kubernetes operator
To install the operator, you create the operator itself and its associated custom resources. For more information, see Installing in the Dask documentation.
In the terminal window that you used to create your KubeFlow cluster, run the following commands:
Verify that your resources were applied successfully by listing your Dask clusters. You shouldn’t expect to see any but the command should succeed.
$ kubectl get daskclusters
No resources found in default namespace.
You can also check that the operator pod is running and ready to launch new Dask clusters.
$ kubectl get pods -A -l application=dask-kubernetes-operator
NAMESPACE NAME READY STATUS RESTARTS AGE
dask-operator dask-kubernetes-operator-775b8bbbd5-zdrf7 1/1 Running 0 74s
Lastly, make sure that your notebook session can create and manage the Dask custom resources. To do this, edit the kubeflow-kubernetes-edit cluster role that gets applied to your notebook pods. Add a new rule to the rules section for this role to allow everything in the kubernetes.dask.org API group.
Now, create DaskCluster resources in Kubernetes to launch all the necessary pods and services for your cluster to work. You can do this in YAML through the Kubernetes API if you like but for this post, use the Python API from the notebook session.
Back in the Jupyter session, create a new notebook and install the dask-kubernetes package that you need for launching your clusters.
!pip install dask-kubernetes
Next, create a Dask cluster using the KubeCluster class. Confirm that you set the container image to match the one you chose for your notebook environment and set the number of GPUs to 1. You also tell the RAPIDS container not to start Jupyter by default and run the Dask command instead.
This can take a similar amount of time to starting up the notebook container, as it also has to pull the RAPIDS Docker image.
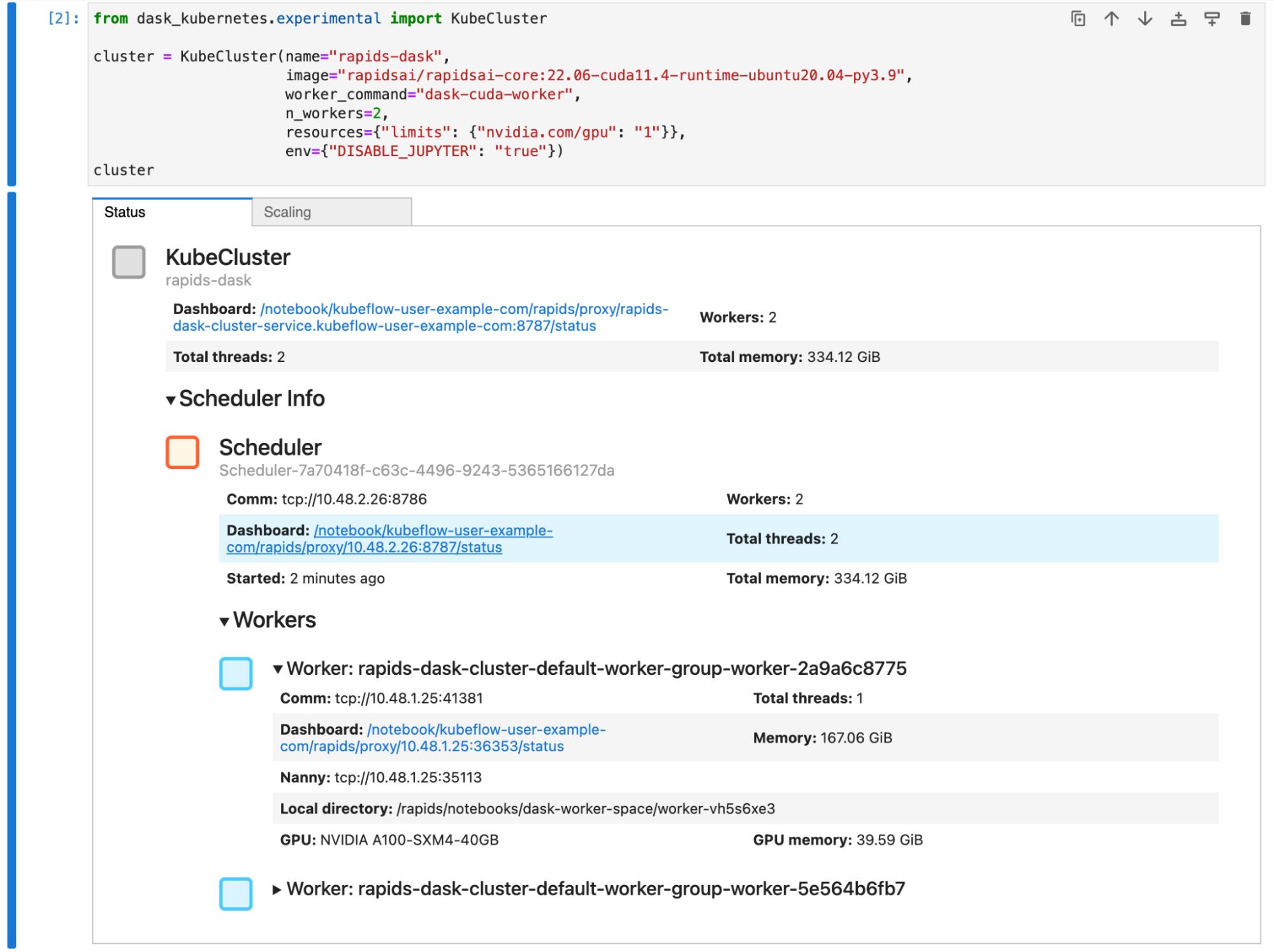
Figure 3 shows that you have a Dask cluster with two workers, and that each worker has an A100 GPU, the same as your Jupyter session.
Figure 3. Dask has many useful widgets that you can view in your notebook to show the status of your cluster
You scale this cluster up and down with either the scaling tab in the widget in Jupyter or by calling cluster.scale(n) to set the number of workers, and therefore the number of GPUs.
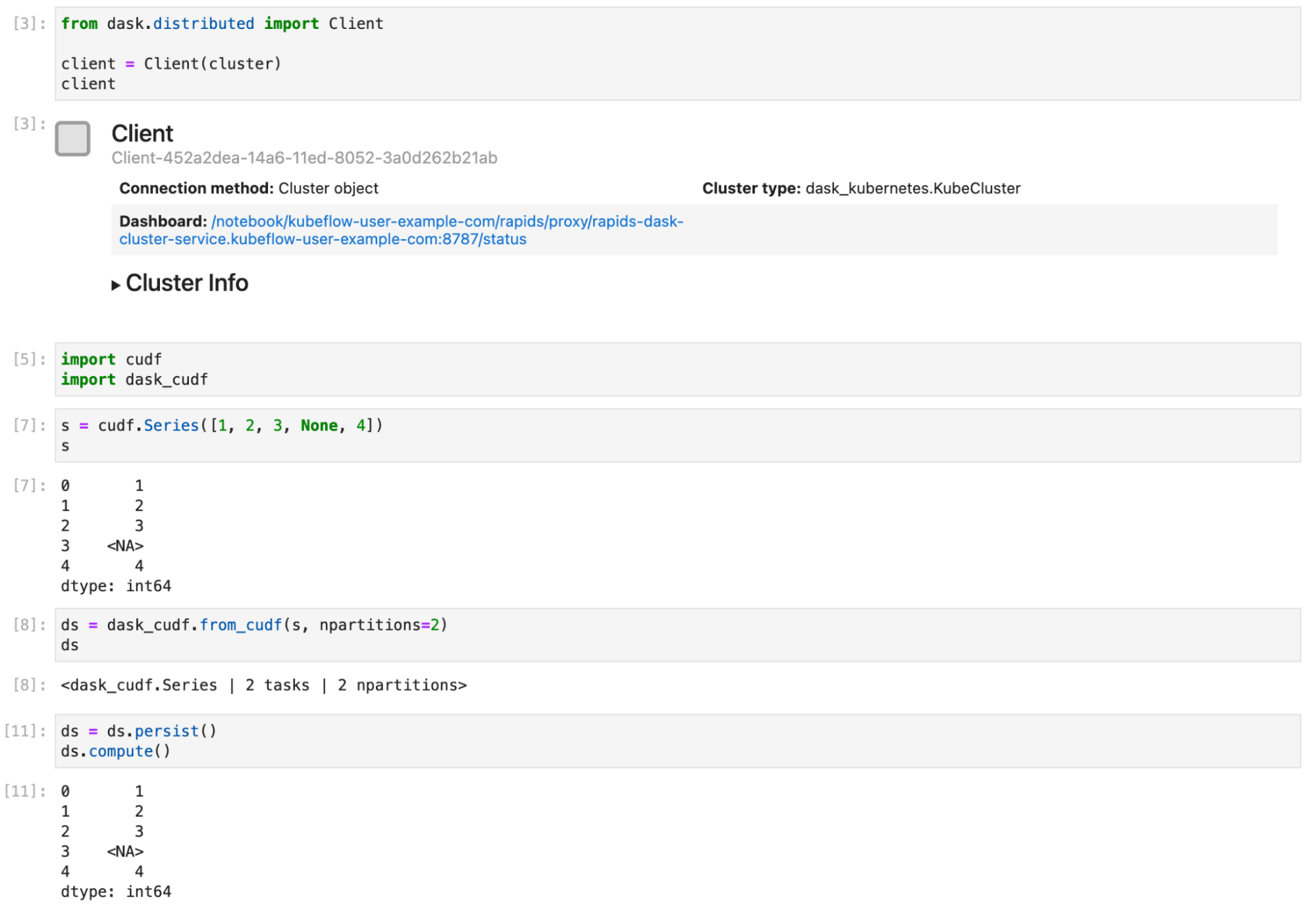
Now, connect a Dask client to your cluster. From that point on, any RAPIDS libraries that support Dask, such as dask_cudf, use your cluster to distribute your computation over all your GPUs. Figure 4 shows a short example of creating a Series object and distributing it with Dask.
Figure 4. Create a cuDF DataFrame, distributed it with Dask, then perform a computation and get the results
Accessing the Dask dashboard
At the beginning of this section, you added an extra config file with some options for the Dask dashboard. These options are necessary to enable you to access the dashboard running in the scheduler pod on your Kubernetes cluster from your Jupyter environment.
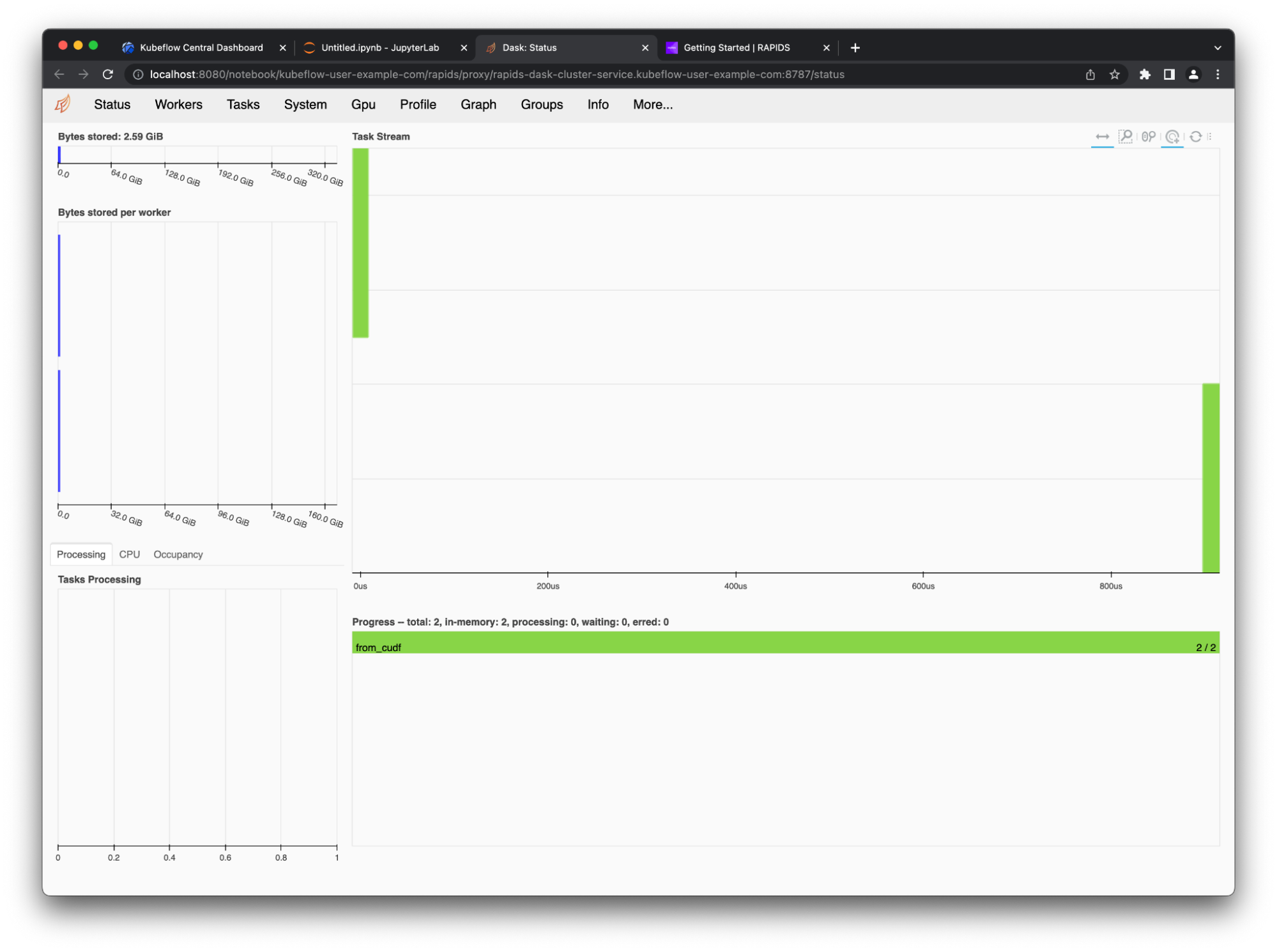
You may have noticed that the cluster and client widgets both had links to the dashboard. Select these links to open the dashboard in a new tab (Figure 5).
Figure 5. Dask dashboard with the from_cudf call
You can also use the Dask JupyterLab extension to view various plots and stats about your Dask cluster right in JupyterLab.
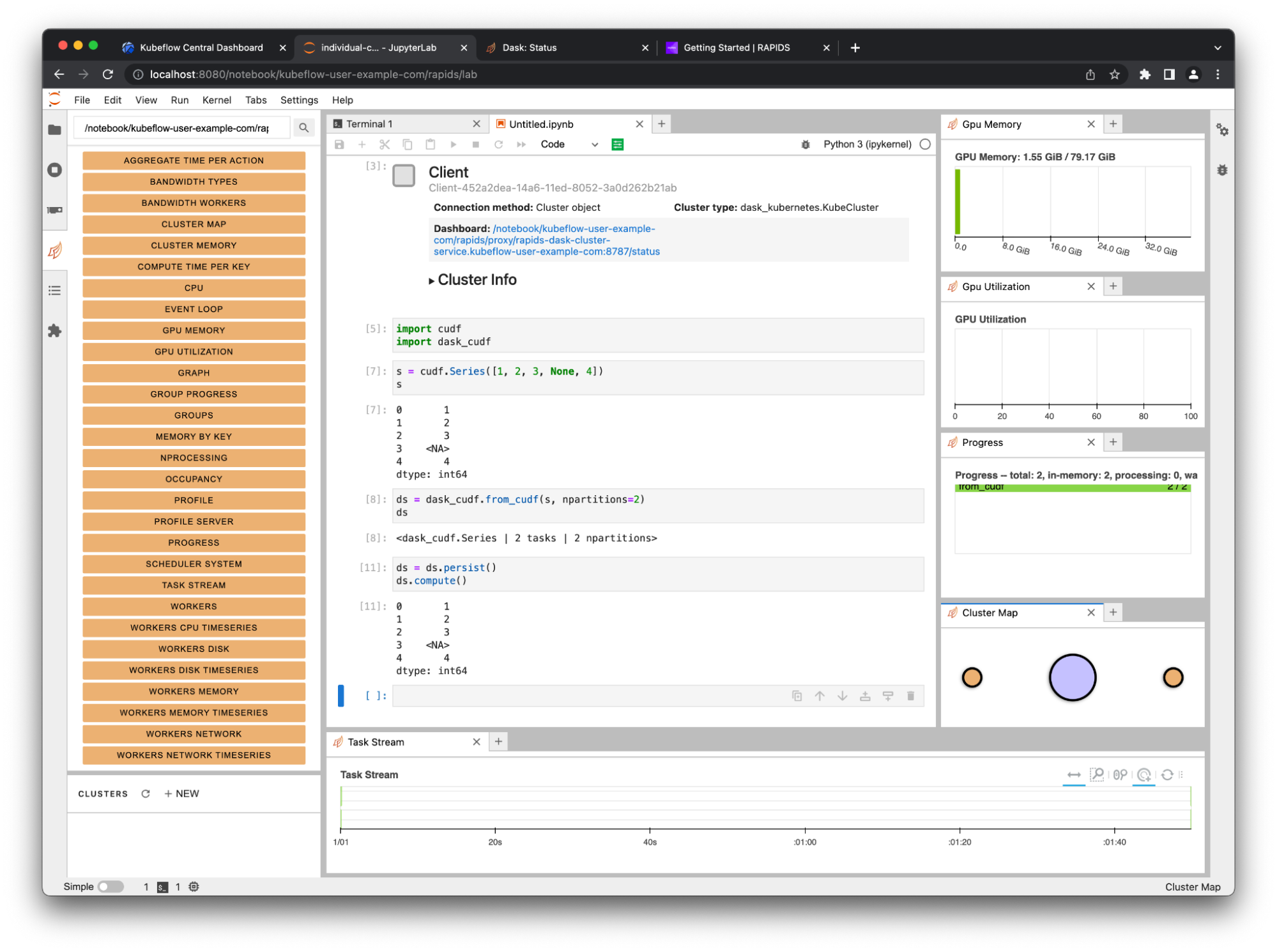
On the Dask tab on the left, choose the search icon. This connects JupyterLab to the dashboard through the client in your notebook. Select the various plots and arrange them in JupyterLab by dragging the tabs around.
Figure 6. The Dask dashboard has many useful plots, including some dedicated GPU metrics like memory use and utilization
If you followed along with this post, clean up all the created resources by deleting the GKE cluster created at the start.
RAPIDS integrates seamlessly with KubeFlow enabling you to use your GPU resources in the ETL stages of your workflows, as well during training and inference.
You can either drop the RAPIDS environment straight into the KubeFlow notebooks service for single-node work or use the Dask Operator for Kubernetes from KubeFlow Pipelines to scale that workload onto many nodes and GPUs.
For more information about using RAPIDS, see the following resources:
Crafted by AI for AI, GPUNet is a class of convolutional neural networks designed to maximize the performance of NVIDIA GPUs using NVIDIA TensorRT. Built using…
Crafted by AI for AI, GPUNet is a class of convolutional neural networks designed to maximize the performance of NVIDIA GPUs using NVIDIA TensorRT.
Built using novel neural architecture search (NAS) methods, GPUNet demonstrates state-of-the-art inference performance up to 2x faster than EfficientNet-X and FBNet-V3.
The NAS methodology helps build GPUNet for a wide range of applications such that deep learning engineers can directly deploy these neural networks depending on the relative accuracy and latency targets.
GPUNet NAS design methodology
Efficient architecture search and deployment-ready models are the key goals of the NAS design methodology. This means little to no interaction with the domain experts and efficient use of cluster nodes for training potential architecture candidates. Most important is that the generated models are deployment-ready.
Crafted by AI
Finding the best performing architecture search for a target device can be time-consuming. NVIDIA built and deployed a novel NAS AI agent that efficiently makes the tough design choices required to build GPUNets that beat the current SOTA models by a factor of 2x.
This NAS AI agent automatically orchestrates hundreds of GPUs in the Selene supercomputer without any intervention from the domain experts.
Optimized for NVIDIA GPU using TensorRT
GPUNet picks up the most relevant operations required to meet the target model accuracy with related TensorRT inference latency cost, promoting GPU-friendly operators (for example, larger filters) over memory-bound operators (for example, fancy activations). It delivers the SOTA GPU latency and the accuracy on ImageNet.
Deployment-ready
The GPUNet reported latencies include all the performance optimization available in the shipping version of TensorRT, including fused kernels, quantization, and other optimized paths. Built GPUNets are ready for deployment.
Building a GPUNet: An end-to-end NAS workflow
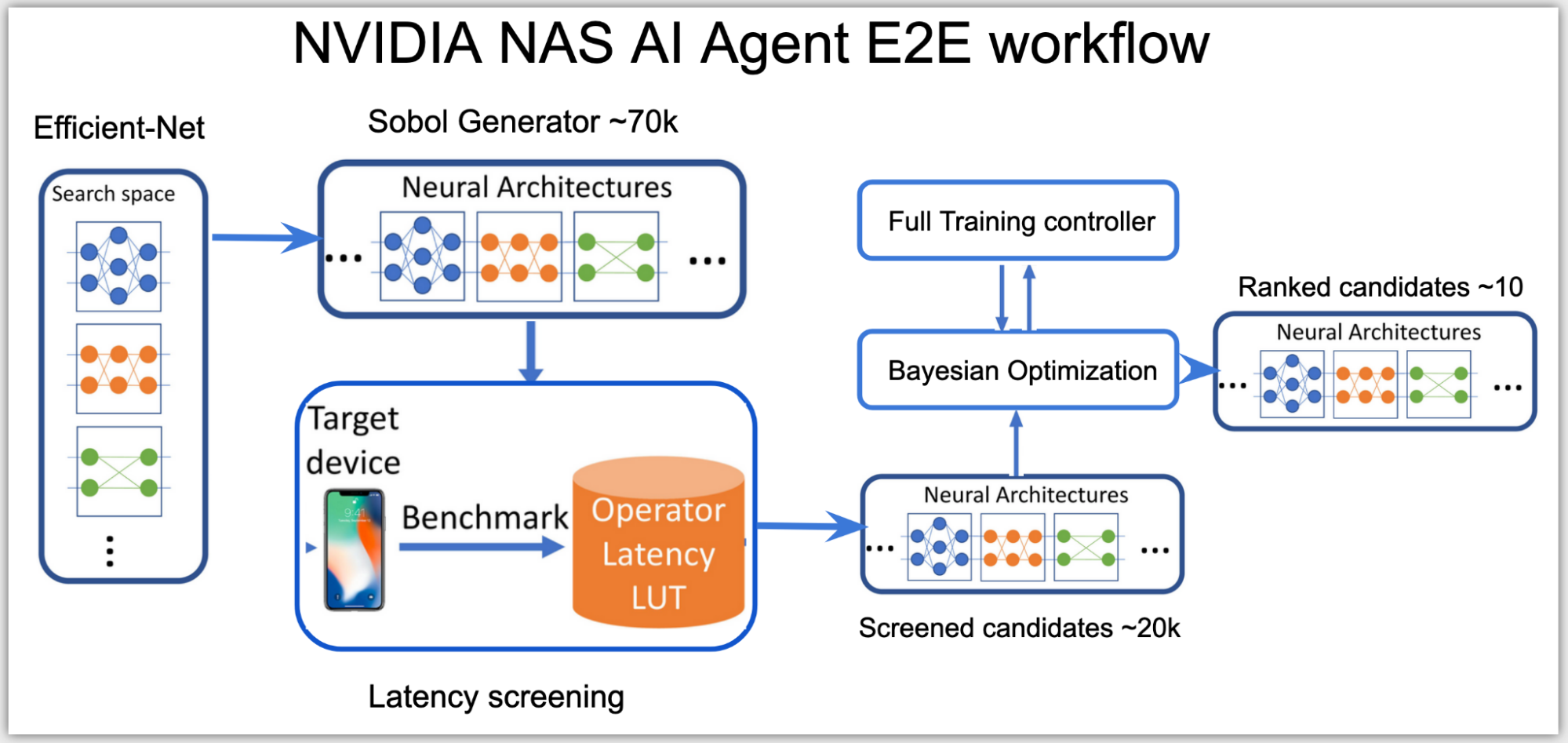
At a high level, the neural architecture search (NAS) AI agent is split into two stages:
Categorizing all possible network architectures by the inference latency.
Using a subset of these networks that fit within the latency budget and optimizing them for accuracy.
In the first stage, as the search space is high-dimensional, the agent uses Sobol sampling to distribute the candidates more evenly. Using the latency look-up table, these candidates are then categorized into a subsearch space, for example, a subset of networks with total latency under 0.5 msecs on NVIDIA V100 GPUs.
The inference latency used in this stage is an approximate cost, calculated by summing up the latency of each layer from the latency lookup table. The latency table uses input data shape and layer configurations as keys to look up the related latency on the queried layer.
In the second stage, the agent sets up Bayesian optimization loss function to find the best performing higher accuracy network within the latency range of the subspace:
Figure 2. NVIDIA NAS AI Agent End-to-End workflow
The AI agent uses a client-server distributed training controller to perform NAS simultaneously across multiple network architectures. The AI agent runs on one server node, proposing and training network candidates that run on several client nodes on the cluster.
Based on the results, only the promising network architecture candidates that meet both the accuracy and the latency targets of the target hardware get ranked, resulting in a handful of best-performing GPUNets that are ready to be deployed on NVIDIA GPUs using TensorRT.
GPUNet model architecture
The GPUNet model architecture is an eight-stage architecture using EfficientNet-V2 as the baseline architecture.
The search space definition includes searching on the following variables:
Type of operations
Number of strides
Kernel size
Number of layers
Activation function
IRB expansion ratio
Output channel filters
Squeeze excitation (SE)
Table 1 shows the range of values for each variable in the search space.
Table 1. Value ranges for search space variables
Stage
Type
Stride
Kernel
Layers
Activation
ER
Filters
SE
0
Conv
2
[3,5]
1
[R,S]
[24, 32, 8]
1
Conv
1
[3,5]
[1,4]
[R,S]
[24, 32, 8]
2
F-IRB
2
[3,5]
[1,8]
[R,S]
[2, 6]
[32, 80, 16]
[0, 1]
3
F-IRB
2
[3,5]
[1,8]
[R,S]
[2, 6]
[48, 112, 16]
[0, 1]
4
IRB
2
[3,5]
[1,10]
[R,S]
[2, 6]
[96, 192, 16]
[0, 1]
5
IRB
1
[3,5]
[0,15]
[R,S]
[2, 6]
[112, 224, 16]
[0, 1]
6
IRB
2
[3,5]
[1,15]
[R,S]
[2, 6]
[128, 416, 32]
[0, 1]
7
IRB
1
[3,5]
[0,15]
[R,S]
[2, 6]
[256, 832, 64]
[0, 1]
8
Conv1x1 & Pooling & FC
The first two stages search for the head configurations using convolutions. Inspired by EfficientNet-V2, the second and third stages use Fused-IRB. Fused-IRBs result in higher latency though, so in stages 4 to 7 these are replaced by IRBs.
The column Layers show the range of layers in the stage. For example, [1, 10] in stage 4 means that the stage can have 1 to 10 IRBs. The column Filters shows the range of output channel filters for the layers in the stage. This search space also tunes the expansion ratio (ER), activation types, kernel sizes, and the Squeeze Excitation (SE) layer inside the IRB/Fused-IRB.
Finally, the dimensions of the input image are searched from 224 to 512, at the step of 32.
Each GPUNet candidate build from the search space is encoded into a 41-wide integer vector (Table 2).
Table 2. The encoding scheme of networks in the search space
Stage
Type
Hyperparameters
Length
Resolution
[Resolution]
1
0
Conv
[#Filters]
1
1
Conv
[Kernel, Activation, #Layers]
3
2
Fused-IRB
[#Filters, Kernel, E, SE, Act, #Layers]
6
3
Fused-IRB
[#Filters, Kernel, E, SE, Act, #Layers]
6
4
IRB
[#Filters, Kernel, E, SE, Act, #Layers]
6
5
IRB
[#Filters, Kernel, E, SE, Act, #Layers]
6
6
IRB
[#Filters, Kernel, E, SE, Act, #Layers]
6
7
IRB
[#Filters, Kernel, E, SE, Act, #Layers]
6
At the end of the NAS search, the returned ranked candidates is a list of these best-performing encodings, which are in turn the best-performing GPUNets.
Summary
All ML practitioners are encouraged to read the CVPR 2022 GPUNet paper, with related GPUNet training code on the NVIDIA/DeepLearningExamples GitHub repo, and run inference on the colab instance on available cloud GPUs. GPUNet inference is also available on the PyTorch hub. The colab run instance uses the GPUNet checkpoints hosted on the NGC hub. These checkpoints have varying accuracy and latency tradeoffs, which can be applied based on the requirement of the target application.

 Autonomous vehicle developers now have access to flexible, scalable, and high-performance hardware and software to build the next generation of safer, more…
Autonomous vehicle developers now have access to flexible, scalable, and high-performance hardware and software to build the next generation of safer, more… Successfully deploying an automatic speech recognition (ASR) application can be a frustrating experience. For example, it is difficult for an ASR system to…
Successfully deploying an automatic speech recognition (ASR) application can be a frustrating experience. For example, it is difficult for an ASR system to…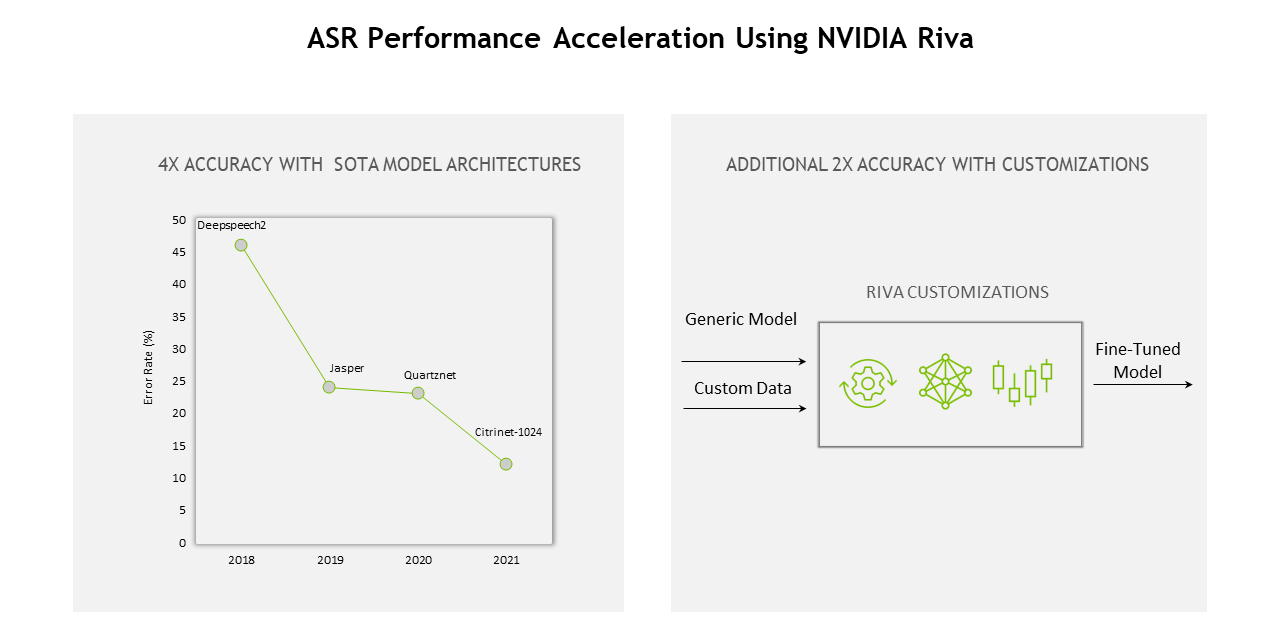
") Register now to experience the most advanced developer tools and learn how experts across industries are using vision AI to increase operational efficiency.
Register now to experience the most advanced developer tools and learn how experts across industries are using vision AI to increase operational efficiency. The increasing adoption of cloud-native workloads is causing a significant shift in infrastructure architecture to support next-generation applications such as…
The increasing adoption of cloud-native workloads is causing a significant shift in infrastructure architecture to support next-generation applications such as…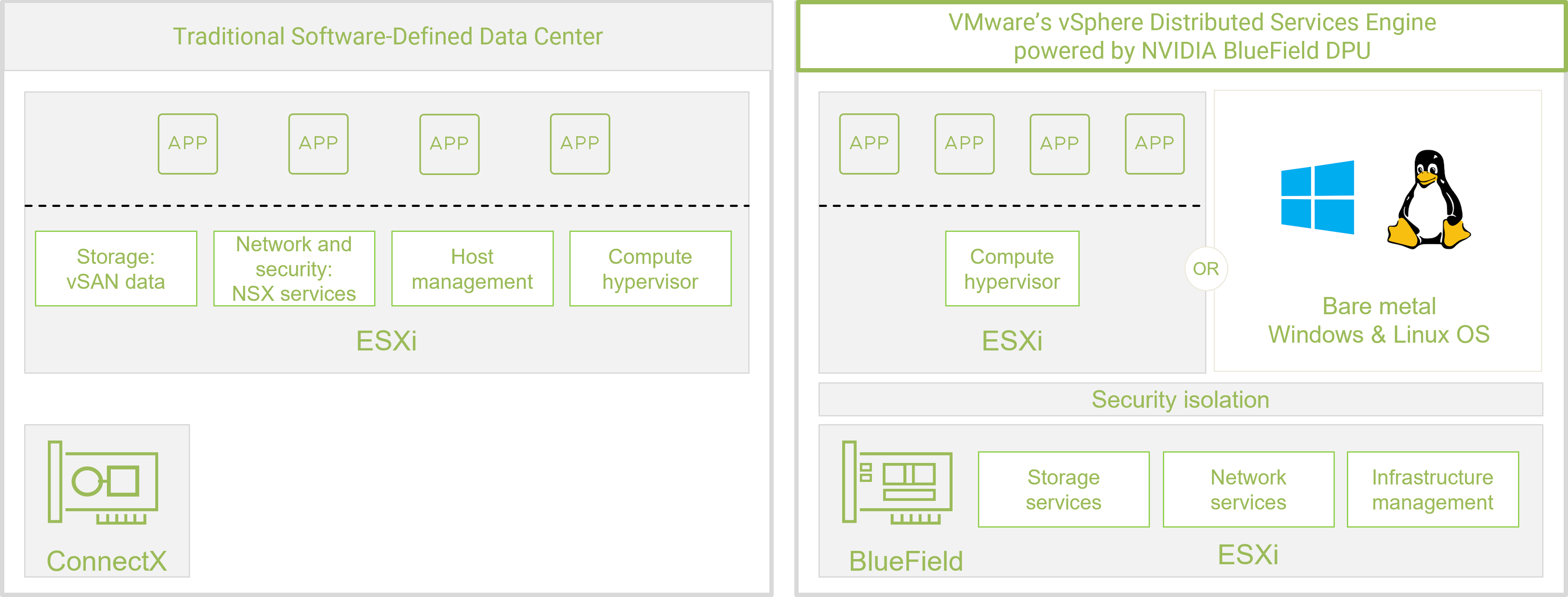
 In the machine learning and MLOps world, GPUs are widely used to speed up model training and inference, but what about the other stages of the workflow like ETL…
In the machine learning and MLOps world, GPUs are widely used to speed up model training and inference, but what about the other stages of the workflow like ETL…
 Crafted by AI for AI, GPUNet is a class of convolutional neural networks designed to maximize the performance of NVIDIA GPUs using NVIDIA TensorRT. Built using…
Crafted by AI for AI, GPUNet is a class of convolutional neural networks designed to maximize the performance of NVIDIA GPUs using NVIDIA TensorRT. Built using…