RuntimeError: CUDA out of memory. Tried to allocate 20.00 MiB (GPU 0; 4.00 GiB total capacity; 3.42 GiB already allocated; 0 bytes free; 3.49 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
Sign up to watch Deepu Talla present “Machines That Can See: Deploying Computer Vision into Production” during the re:Mars keynote session June 24, from 9-11 am.
NVIDIA VPI is a computer vision and image-processing software library to implement algorithms that are accelerated on different hardware backends.
NVIDIA Vision Programming Interface (VPI) is a computer vision and image-processing software library from NVIDIA that enables you to implement algorithms that are accelerated on different hardware backends available on NVIDIA Jetson embedded devices and discrete GPUs.
Some of the algorithms in the library include filtering methods, perspective warp, temporal noise reduction, histogram equalization, stereo disparity, and lens distortion correction. VPI provides easy-to-use Python bindings, along with a C++ API.
In addition to interfacing with OpenCV, VPI is capable of interoperating with PyTorch and other libraries based on Python. In this post, we show you how this interoperability works through a PyTorch-based object detection and tracking example. For more information, see the Vision Programming Interface (VPI) page and Vision Programming Interface documentation.
Interoperability with PyTorch and other libraries
You may have to use multiple libraries depending on the application that you are implementing in computer vision and deep learning pipelines. One of the challenges in developing such pipelines is the efficiency with which these libraries interact with each other. For instance, there could be performance issues due to memory copies when the image data is being exchanged between them.
With VPI, you now have interoperability available with PyTorch or any other library that supports the __cuda_array_interace__. The __cuda_array_interface__ (CUDA Array Interface) is an attribute in Python that enables interoperability between different implementations of GPU array-like objects in various projects, such as libraries.
The array object, such as images, may be created in one library and modified in another, without copying the data in the GPU or passing it through the CPU.
Figure 1. Interoperability between VPI and other libraries using __cuda_array_interface__
Temporal noise reduction to improve object detection and tracking
Noise is a common characteristic across frames in a video. Such temporal noise negatively impacts the performance of the object detection and tracking algorithm in videos.
In this walkthrough, you use a PyTorch-based object detection and tracking example on a noisy video (Figure 2). You then apply the TNR algorithm from VPI to reduce noise, thus improving object detection and tracking.
We show that both VPI and PyTorch work seamlessly without any memory copies during the execution of algorithms from both VPI and PyTorch.
Figure 2. Sample of the noisy input video
The example covers the following:
PyTorch object detection and tracking on raw input video
PyTorch object detection and tracking on cleaned input video by VPI TNR
Interoperability between VPI and PyTorch using the CUDA array interface
PyTorch object detection and tracking on raw input video
Create a class called PyTorchDetection to handle all PyTorch objects and calls. When creating an object of this class, the application is loading a pretrained, deep-learning model for object detection to the GPU for inference only. The following code example shows the needed imports and class constructor definition:
The PyTorchDetection class is also responsible for creating a CUDA image frame from an array, effectively uploading it to the GPU. Later, you use OpenCV to read an input video from a file, where each video frame is a NumPy array that serves as input for this class creation function.
In addition, the PyTorchDetection class can convert the CUDA image frame into a CUDA tensor object, making it ready for model inferencing, and converting a VPI-based CUDA frame into a tensor. This last conversion uses the __cuda_array_interface__ interoperability of VPI to avoid copying the frame.
Apart from the functions defined earlier, the PyTorchDetection class defines a function to detect and draw objects in the current OpenCV frame, given a scores_threshold value:
def DetectAndDraw(self, cv_frame, torch_tensor, title, scores_threshold=0.2):
with torch.no_grad():
pred = self.torch_model(torch_tensor)
(...)
For this post, we have omitted the code to draw attention to the PyTorch model’s prediction results. By downloading or using the code, you accept the terms and conditions of this code here. You can download and review the code.
The next section explains how to use VPI to reduce noise in the input video, coupling VPI with PyTorch to improve its object detection.
PyTorch object detection and tracking on cleaned input video by VPI TNR
In this section, define a VPI-based utility class, VPITemporalNoiseReduction, to clean up noise from video frames.
When creating an object of this class, the application loads the main VPI TNR object and a VPI-based CUDA frame to store the cleaned output. The following code example shows the needed import and class constructor definition:
The constructor of the VPITemporalNoiseReduction class expects the shape (image width and height) and format of each input image frame. For simplicity, you are accepting only BGR8 image formats, as this is the format used by OpenCV when reading an input video.
Also, you are creating the VPI image to store the output frame using the provided shape and format. The TNR object is then constructed for this shape, using the TNR code version 3 and CUDA backend. The input format for TNR is NV12_ER, different from the one in the input image frame. You deal with converting frames in the Denoise utility function next.
The last function does the actual cleanup of input image frames. This function removes noise from a PyTorch-based input CUDA frame, returning an output VPI-based CUDA frame.
The PyTorch CUDA frame is first converted to VPI, using the vpi.asimage function. torch_cuda_frame shares the same memory space of vpi_input_frame: that is, there are no memory copies involved.
Next, the input frame is converted from the given input format (BGR8) to NV12_ER in CUDA for processing.
The TNR algorithm is executed on this converted input frame, using the TNR preset OUTDOOR_LOW_LIGHT and a given TNR strength.
The cleaned input frame (the output of the TNR algorithm) is converted back to the original format (BGR8) and stored in the VPI-based CUDA output frame.
The resulting output frame is returned for later use by PyTorch.
Interoperability between VPI and PyTorch using the CUDA Array Interface
To wrap up, you define a MainWindow class in the main module. This class is based on PySide2 and provides a graphical user interface for this example.
The window interface shows two output image frames, one using only PyTorch for detection and another using PyTorch after VPI TNR. Also, the window interface contains two sliders to control the scores threshold for PyTorch detection and TNR strength for VPI temporal noise removal.
import cv2
import numpy as np
(...)
from PySide2 import QtWidgets, QtGui, QtCore
(...)
from vpitnr import VPITemporalNoiseReduction
from torchdetection import PyTorchDetection
class MainWindow(QMainWindow):
def __init__(self, input_path):
super().__init__()
#-------- OpenCV part --------
self.video_capture = cv2.VideoCapture(input_path)
if not self.video_capture.isOpened():
self.Quit()
self.input_width = int(self.video_capture.get(cv2.CAP_PROP_FRAME_WIDTH))
self.input_height = int(self.video_capture.get(cv2.CAP_PROP_FRAME_HEIGHT))
self.output_video_shape = (self.input_height * 2, self.input_width, 3)
self.output_frame_shape = (self.input_height, self.input_width, 3)
self.cv_output_video = np.zeros(self.output_video_shape, dtype=np.uint8)
#-------- Main objects of this example --------
self.torch_detection = PyTorchDetection()
self.vpi_tnr = VPITemporalNoiseReduction((self.input_width,
self.input_height), 'BGR8')
(...)
def UpdateDetection(self):
in_frame = self.cv_input_frame
if in_frame is None:
return
cuda_input_frame = self.torch_detection.CreateCUDAFrame(in_frame)
# -------- Top Frame: No VPI ---------
cuda_tensor = self.torch_detection.ConvertToTensor(cuda_input_frame)
self.torch_detection.DetectAndDraw(self.TopFrame(), cuda_tensor,
'Pytorch only (no VPI)', self.scores_threshold)
# -------- Bottom Frame: With VPI ---------
vpi_output_frame = self.vpi_tnr.Denoise(cuda_input_frame,
self.tnr_strength)
with vpi_output_frame.rlock_cuda() as cuda_frame:
cuda_output_frame=self.torch_detection.ConvertFromVPIFrame(cuda_frame)
cuda_tensor = self.torch_detection.ConvertToTensor(cuda_output_frame)
self.torch_detection.DetectAndDraw(self.BottomFrame(), cuda_tensor, 'Pytorch + VPI TNR', self.scores_threshold)
(...)
The constructor of the MainWindow class expects the path for the input video. It uses OpenCV to read the input video and create an output video frame with twice the height of the input video. This is used to store two output frames, one with the PyTorch-only output and another with the VPI+PyTorch output.
The constructor also creates the objects for PyTorch detection and VPI TNR. For this post, we omitted the code for creating the widgets of the graphical user interface and handling its callbacks. We also omitted the code for creating the main window and starting the application. For more information about this part of TNR code, download the example.
The UpdateDetection function, called when a new input video frame is available, creates a PyTorch-based CUDA input frame from the NumPy OpenCV input frame. It then converts it to a tensor to do the detect and draw of the PyTorchDetection class. This pipeline for the top frame runs PyTorch detection directly in the input video frame.
The next pipeline for the bottom frame starts by denoising the PyTorch CUDA-based input frame. The denoised output is a VPI-based CUDA frame named vpi_output_frame, which is locked for reading in CUDA, using the rlock_cuda function. This function provides the __cuda_array_interface__ for VPI CUDA interoperability in the cuda_frame object. This object is converted to the PyTorch CUDA frame and then to tensor. Again, the detect and draw function is called on the result of the pipeline. This second pipeline runs PyTorchDetection after the VPI denoise functionality.
Results
Figure 3 shows the results of PyTorch object detection and tracking without and with VPI TNR on the noisy input video of pedestrians in a public place. As you can see from the output videos with annotations, the detection and tracking results are improved when applying denoising before detection (right).
Figure 3. PyTorch object detection and tracking (left) without and (right) with VPI TNR
The frames per second (FPS) shown (32.8 for PyTorch only and 32.1 for VPI + PyTorch) on the bottom right of the video frames show that adding VPI to the PyTorch detection pipeline does not add too much overhead. This is in part due to avoiding more than 20Mb per frame copies from CUDA memory to the CPU memory and back, which was enabled through using __cuda_array_interface__.
Summary
In this post, we showed how interoperability works between VPI and other libraries that support __cuda_array_interface__ using PyTorch object detection and tracking as an example. You applied temporal noise reduction from VPI before object detection and tracking to improve it. We also demonstrated that there is no loss of performance with the addition of VPI in the PyTorch pipeline.
For younger generations, paper bills, loan forms and even cash might as well be in a museum. Smartphones in hand, their financial services largely take place online. The financial-technology companies that serve them are in a race to develop AI that can make sense of the vast amount of data the companies collect — both Read article >
I have a got a CNN, have run it on given training/testing data for a satisfactory amount of epochs, and then saved it as a .hd5 file. Now, I have got fresh images, in jpeg format, and need to run them through my model and obtain predictions. I have just the jpegs and they are not labelled. How do I proceed?I am using this snippet, to run the predictions on the test/validation dataset.
y_pred = mod(test_examples[:50], training = False) y_pred_argmax = np.argmax(y_pred, axis=3)
Test and Train images are of 512x512x1 shape. Number of classes(features) in the model is 8.
I come from python and wanted to test some client side ML with TensorFlow js. During the fit process I noticed some unexpected behaviour with some callbacks getting called and others not and some callbacks not receiving data.
Here my short example:
“`javascript model.fit(X, y, { callbacks: {
// called but empty logs object? (okay because no data available yet) onTrainBegin: (logs) => { console.log('TrainBegin'); console.log(logs); }, // called but empty logs object? (why?? Training is over and it should have data) onTrainEnd: (logs) => { console.log('TrainEnd'); console.log(logs); }, // never called??? onEpochStart: (epoch, logs) => { console.log('EpochStart'); console.log(`Epoch ${epoch}: loss = ${logs.loss}; accuracy = ${logs.acc}`); }, // works! onEpochEnd: (epoch, logs) => { console.log('EpochEnd'); console.log(`Epoch ${epoch}: loss = ${logs.loss}; accuracy = ${logs.acc}`); }, // never called??? onBatchStart: (batch, logs) => { console.log('BatchStart'); console.log(`Batch ${batch}: loss = ${logs.loss}; accuracy = ${logs.acc}`); }, // works! onBatchEnd: (batch, logs) => { console.log('BatchEnd'); console.log(`Batch ${batch}: loss = ${logs.loss}; accuracy = ${logs.acc}`); },
}, }); “`
I looked through the documentation but could not find an explanation for this behaviour. Does anyone have any ideas and can enlighten me? 😀


 annotators for ALBERT, BERT, DistilBERT, DeBERTa, RoBERTa, Longformer, and XLM-RoBERTa, official support for Apple silicon M1, support oneDNN to improve CPU up to 97%, improved transformers on GPU up to +700%, 1000+ SOTA models")
") Sign up to watch Deepu Talla present “Machines That Can See: Deploying Computer Vision into Production” during the re:Mars keynote session June 24, from 9-11 am.
Sign up to watch Deepu Talla present “Machines That Can See: Deploying Computer Vision into Production” during the re:Mars keynote session June 24, from 9-11 am. _16x9") NVIDIA VPI is a computer vision and image-processing software library to implement algorithms that are accelerated on different hardware backends.
NVIDIA VPI is a computer vision and image-processing software library to implement algorithms that are accelerated on different hardware backends.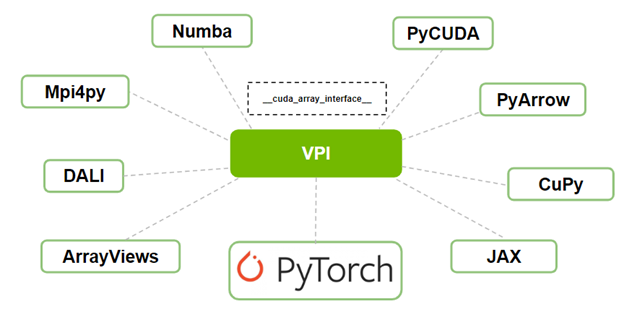


")