
 Researchers combine CT imaging with deep learning to evaluate dinosaur fossils. The approach could change how paleontologists study ancient remains.
Researchers combine CT imaging with deep learning to evaluate dinosaur fossils. The approach could change how paleontologists study ancient remains.
Applying new technology to studying ancient history, researchers are looking to expand their understanding of dinosaurs with a new AI algorithm. The study, published in Frontiers in Earth Science, uses high-resolution Computed Tomography (CT) imaging combined with deep learning models to scan and evaluate dinosaur fossils. The research is a step toward creating a new tool that would vastly change the way paleontologists study ancient remains.
“Computed Tomography as well we other imaging techniques have revealed previously hidden structures in fossils, but the high-resolution images require paleontologists spending weeks to even months in post-processing, usually segmenting fossils from rock matrices. The introduction of AI can not only accelerate data processing in fossil studies, but also establish benchmarks for more objective and more reproducible studies,” said lead author Congyu Yu, a Ph.D. student at the Richard Gilder Graduate School at the American Museum of Natural History.
For a complete picture of ancient vertebrates, paleontologists focus on internal anatomy such as cranial capacity, inner ears, or vascular spaces. To do this, researchers use a technique called thin sectioning. Removing a small piece (as thin as several micrometers) from a fossil, examining it under a microscope, and annotating the structures they find, helps them piece together the morphology of a dinosaur. However, this technique is destructive to the remains and can be extremely time consuming.
Computed tomography (CT) scans have given scientists the ability to look inside a sample while leaving the fossil unscathed. The technology essentially examines a fossil section, capturing thousands of images of it. Software then reconstructs the images and generates a three-dimensional graphic, resulting in an internal snapshot of the sample. Scientists can then examine and label identifiable morphology in the graphic to learn more about a specimen.
Imaging has given scientists a tool for revealing hidden internal structures and advancing 3D models of dinosaurs. Studies have helped researchers estimate body mass, analyze skulls, and even understand dental morphology along with tooth replacement patterns.
However, with this approach, scientists still manually choose segments, examine, and label images, which beyond being time intensive, is subjective, and can introduce errors. Plus, scans have limitations differentiating between the rock that may be coating a fossil and the bones themselves, making it difficult to determine where a rock ends and fossil begins.
AI has proven capable of quick image segmentation in the medical world, ranging from identifying brain lesions to skin cancer. The researchers saw an opportunity to apply similar deep learning models to CT fossil images.
They tested this new approach using deep neural networks and over 10,000 annotated CT scans of three well-preserved embryonic skulls of Protoceratop dinosaurs. Recovered in the 1990s from the Mongolian Gobi Desert, these fossils come from early horned dinosaurs and are a smaller relative of the better-known Triceratops.
The team used a classic U-net deep neural network for processing fossil segmentation, teaching the algorithm to recognize rock from the fossils. A modified DeepLab v3+ network was used for training feature identification, categorizing parts of the CT images, and 3D rendering.
The models were trained using 7,986 manually annotated bone structure CT slices on the cuDNN-accelerated TensorFlow deep learning framework with dual NVIDIA GeForce RTX 2080 Ti GPUs.
Testing the results against a dataset of 3,329, they found that while the segmentation model reached high accuracy of around 97%, the 3D feature renderings were not as meticulous or accurate as humans. While the results showed that the features models did not perform as accurately as the scientists, the segmentation models worked smoothly and did so in record time. The models segmented each slice in seconds—manually segmenting the same piece took minutes or even hours in some cases. This could help paleontologists reduce their time spent working to differentiate fossils from rock.

The researchers suggest that larger data sets incorporating other dinosaur species and different sediment types could help create a high-performing algorithm down the line.
”We are confident that a segmentation model for fossils from the Gobi Desert is not far away, but a more generalized model needs not only more training dataset but innovations in algorithms,” Yu said in a press release. “I believe deep learning can eventually process imagery better than us, and there have already been various examples in deep learning performance exceeding humans, including Go playing and protein 3D-structure prediction.”
The dataset used in the study, CT Segmentation of Dinosaur Fossils by Deep Learning, is available for download.
Read more. >
Read the study in Frontiers in Earth Science. >>

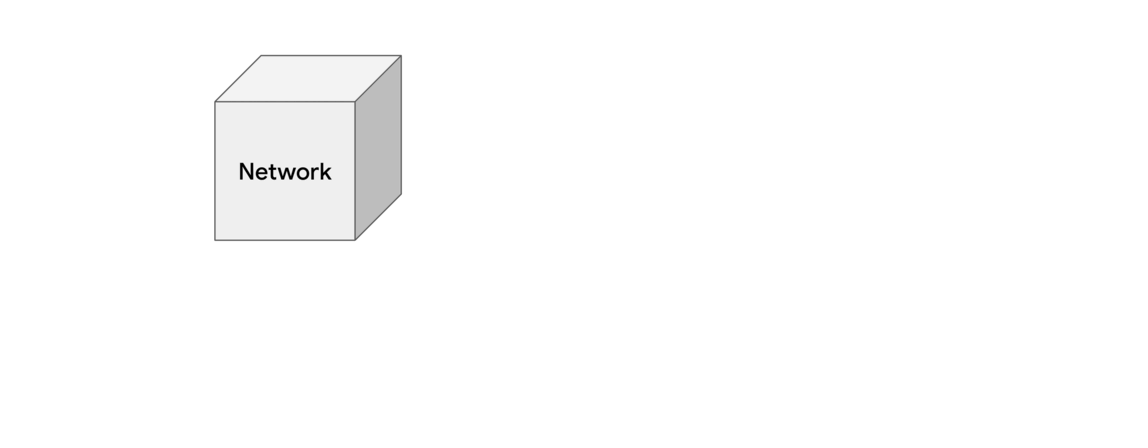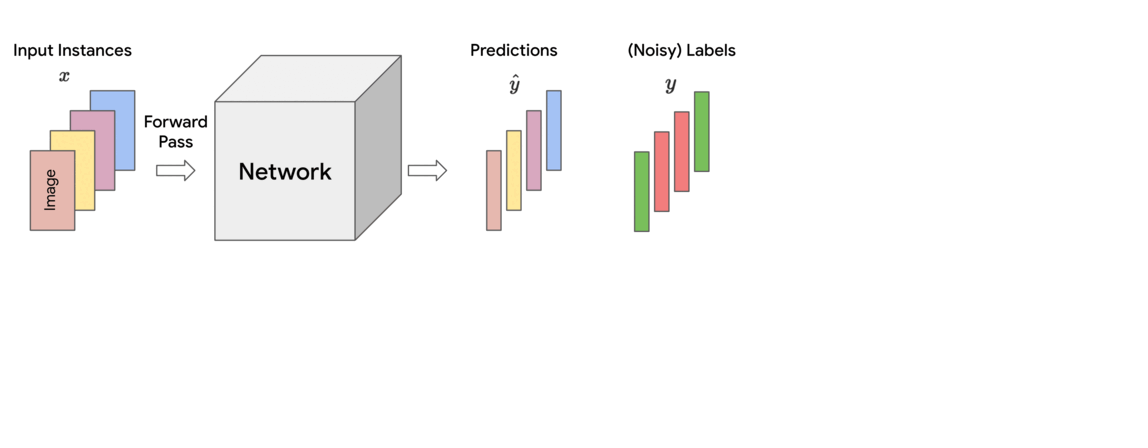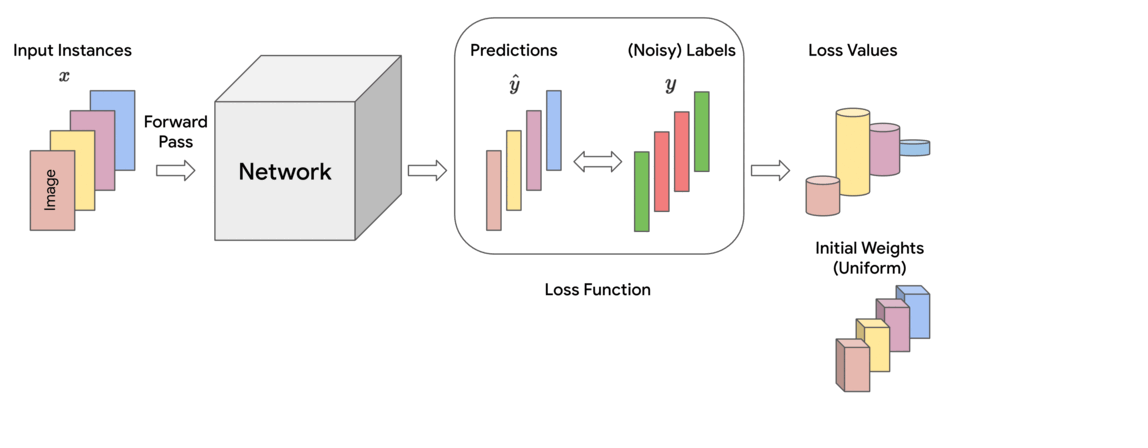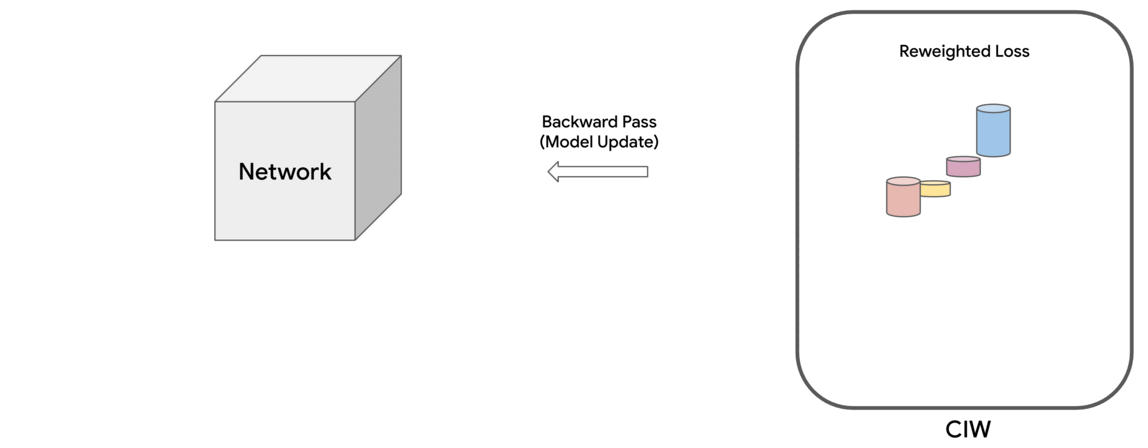




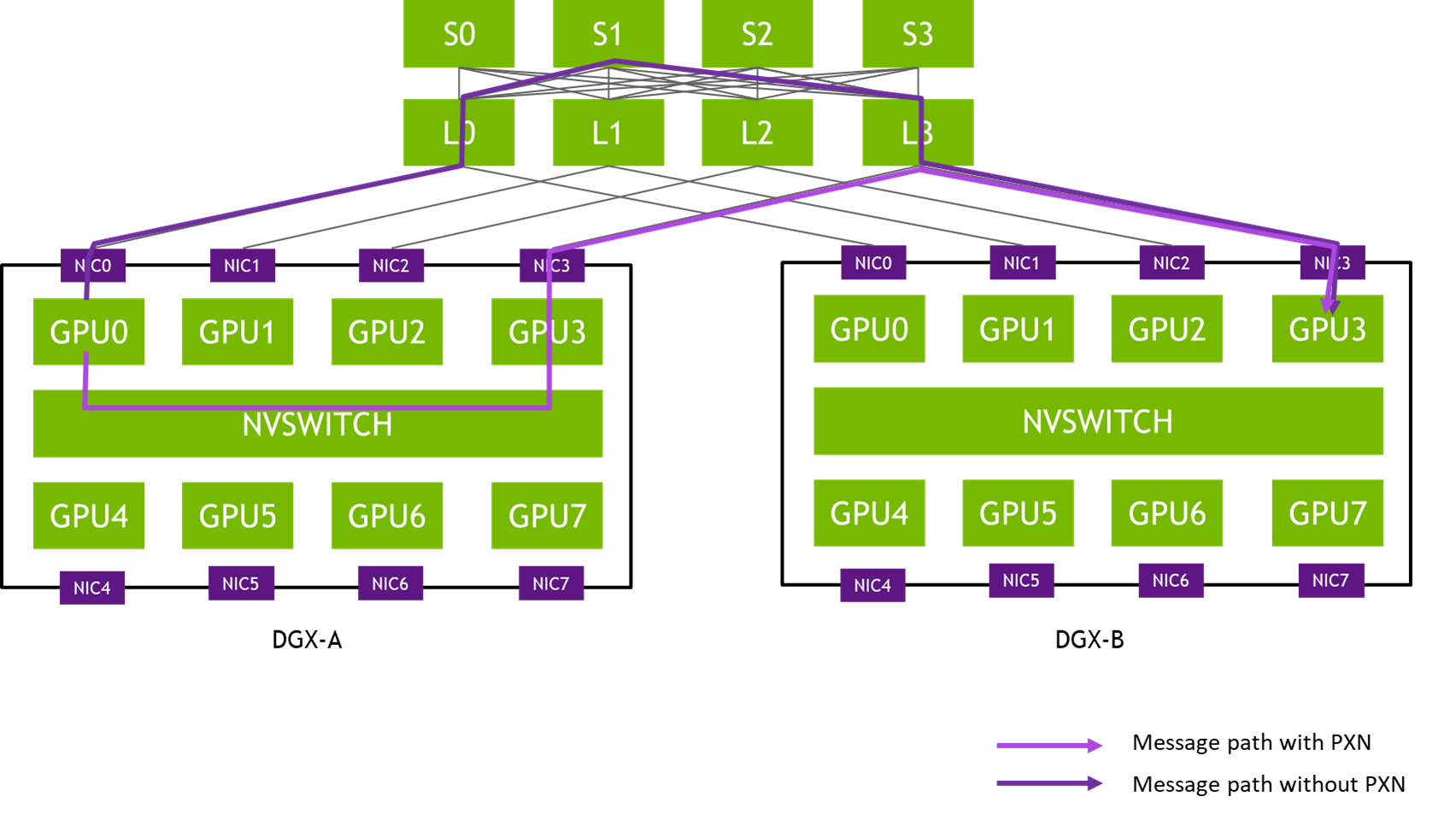
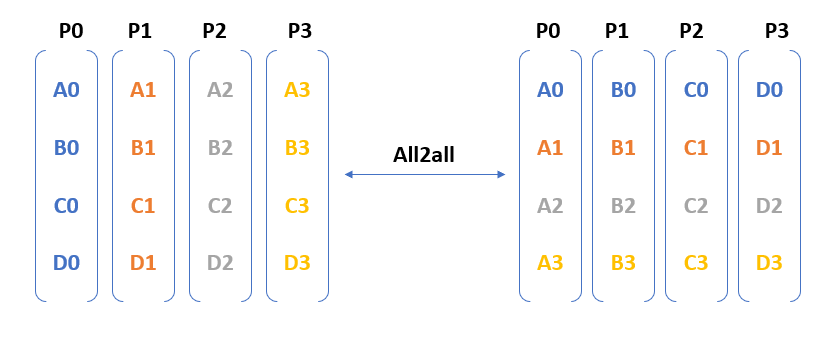
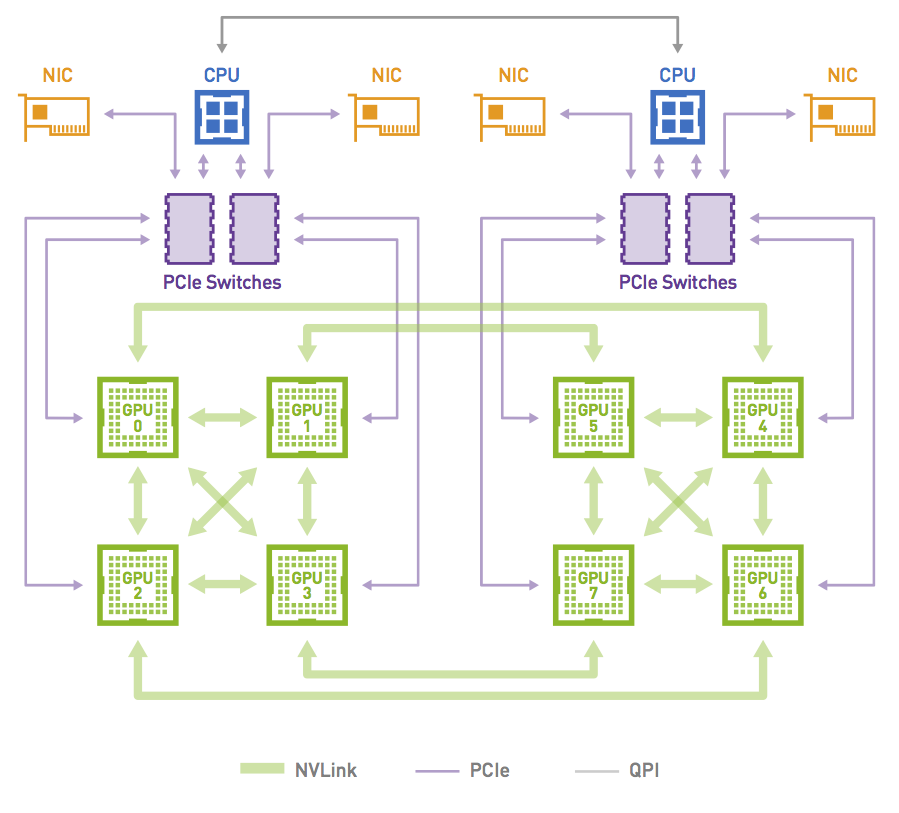
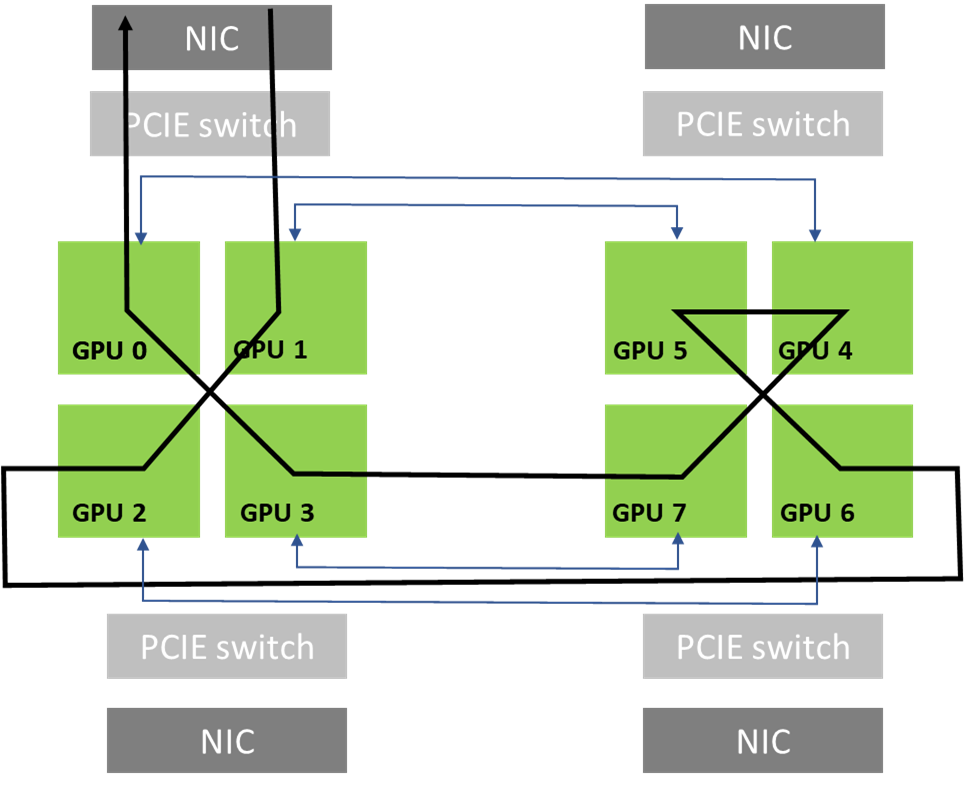
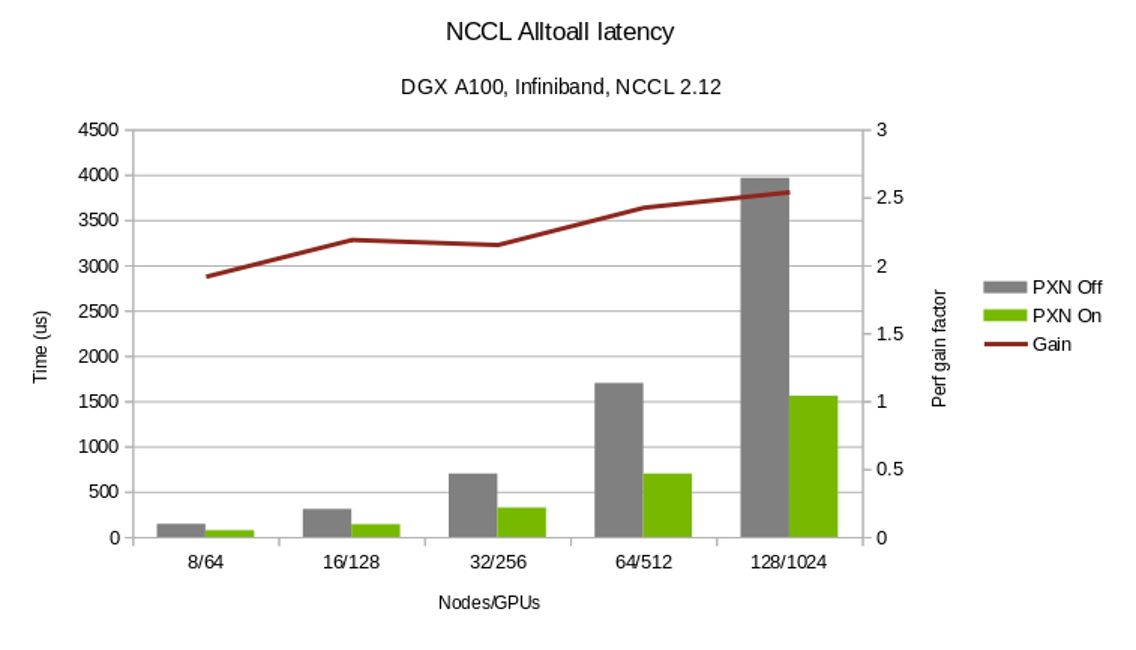
 The NCCL 2.12 release significantly improves all2all communication collective performance, with the PXN feature.
The NCCL 2.12 release significantly improves all2all communication collective performance, with the PXN feature.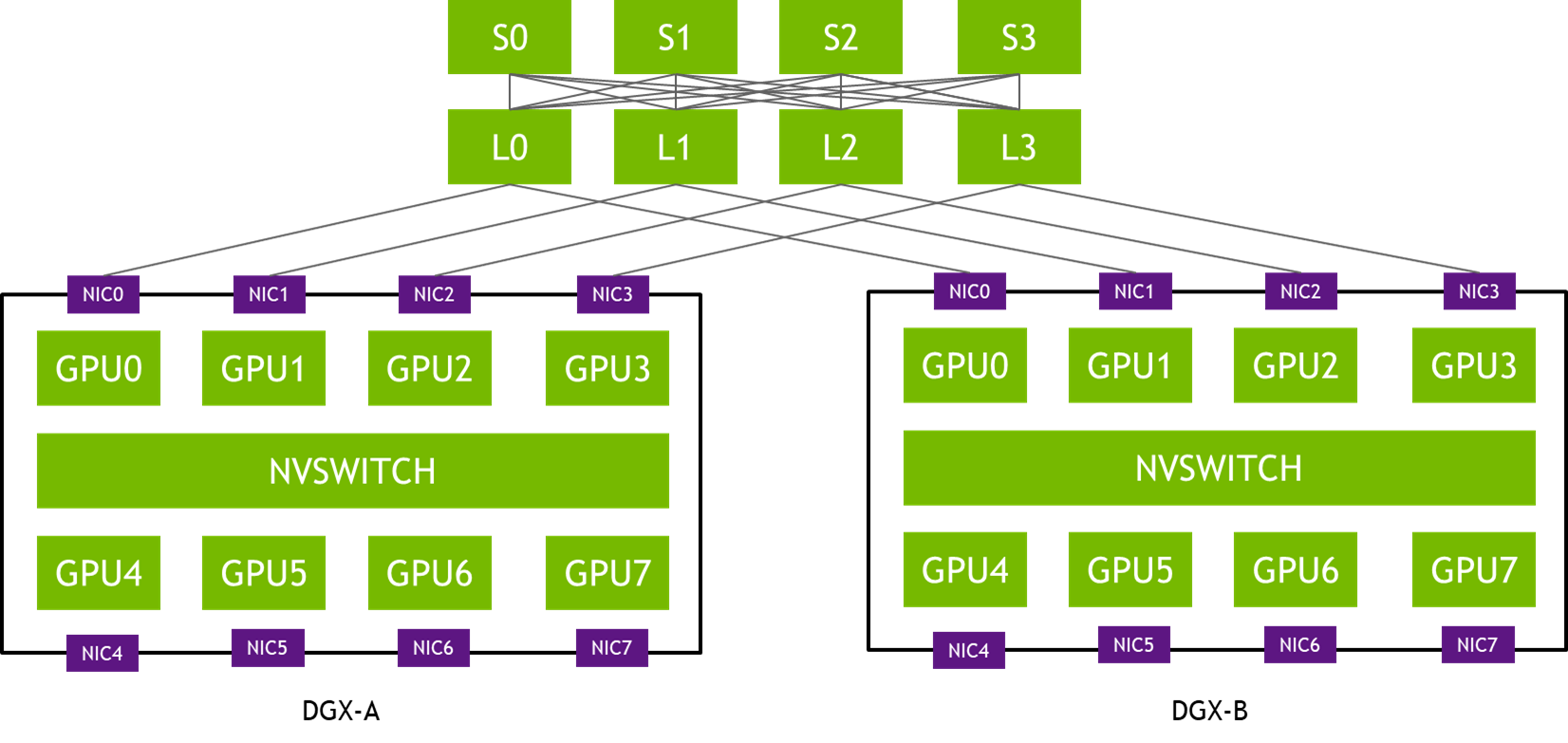



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}