Support for the new GeForce RTX 3080 Ti and 3070 Ti Laptop GPUs is available today in the February Studio driver. Updated monthly, NVIDIA Studio drivers support NVIDIA tools and optimize the most popular creative apps, delivering added performance, reliability and speed to creative workflows. Creatives will also benefit from the February Studio driver with Read article >
Developing and application and offloading it in two ways, via DPDK and via DOCA libraries, to run on the BlueField Data Processing Unit
The NVIDIA BlueField DPU (data processing unit) can be used for network function acceleration. This network offloading is possible using DPDK and the NVIDIA DOCA software framework.
In this series, I built an app and offloaded it two ways, through the use of DPDK and the NVIDIA DOCA SDK libraries. I recorded each step as a separate code patch and provided the complete steps in each series. This shows you what it takes to program the BlueField DPU and the choice for the most elegant option for your unique use case. For part 2, see Developing Applications with NVIDIA BlueField DPU and NVIDIA DOCA Libraries.
Use case
First, I needed a simple yet meaningful use case for deploying an application on the DPU. I chose policy-based routing (PBR) to steer traffic to different gateways based on Layer 3 and Layer 4 packet attributes, overriding (or supplementing) the gateway chosen by the X86-host. This can be done for a variety of reasons in the real world, including the following examples:
Sending select host traffic to an external firewall for additional auditing
Enhanced load balancing to anycast servers
Applying QoS
Figure 1. Traffic is steered from the host to one of the two gateways using PBR
I used PBR on the DPU (bf2-arm) to steer traffic from the host (server1-x86) to one of the two gateways [leaf2, leaf3]. The leaf switch subsequently forwards the traffic to its locally attached anycast service provider [server2, server3].
Building the application
First question: do I write a brand-new app or do I offload an existing one?
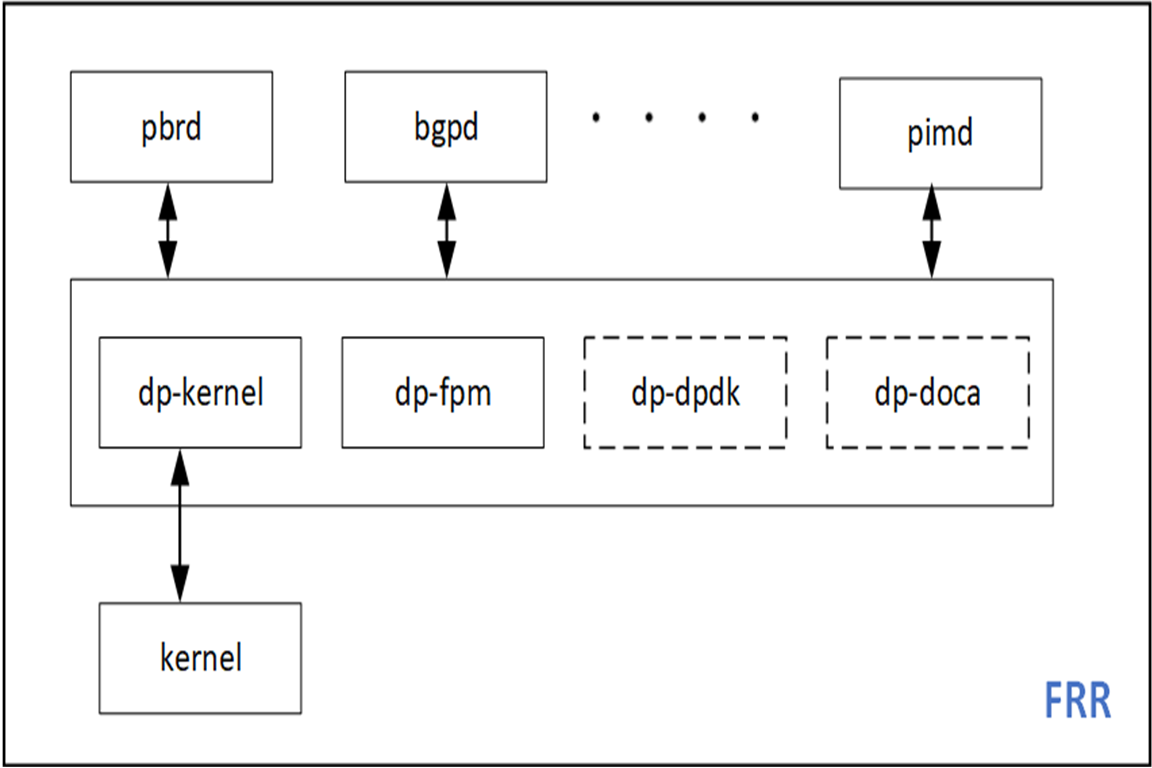
I decided to offload the PBR functionality of my favorite open-source routing stack, FRRouting (FRR). This allows me to extend an existing codebase and provides a nice contrast to the existing sample apps. FRR has an infrastructure for multiple dataplane plugins so DPDK and DOCA can be easily added as new FRR plugins.
Figure 2. DPDK and DOCA plugins can easily be added to FRRouting
DPU application prototyping
In this section, I walk through the prep work needed for creating an app with DPU hardware acceleration.
DPU hardware
I have a BlueField-2 DPU hosted by an x86 server. This DPU has two 25G uplinks and an Arm CPU with 8G RAM. For more information about hardware installation, see the DOCA SDK docs. You can alternately bootstrap your setup using the DPU PocKit.
I installed the BlueField boot file (BFB), which provides the Ubuntu OS image for the DPU and comes with the libraries for DOCA-1.2 and DPDK-20.11.3.
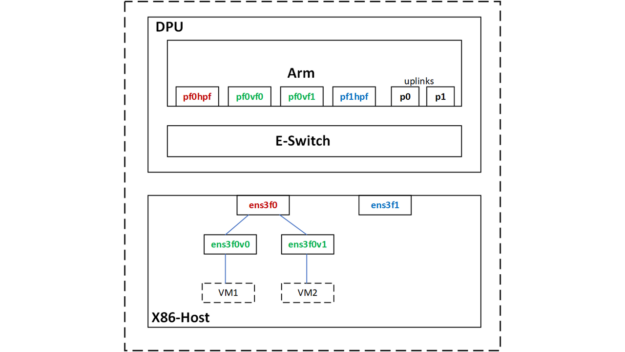
Figure 3. Netdev representors
Using SR-IOV, I created two virtual function (VF) interfaces on the host for two VMs.
Testpmd is memory hungry and allocates a cool 3.5G by default. As I didn’t need to process data traffic in the CPU, I allocated a total-mem value of 200M, where total-mem = total-num-mbufs * mbuf-size (the default mbuf-size is 2048 bytes). I also used flow-isolation because I had to send ARP packets up to the kernel networking stack on the DPU, for PBR next-hop resolution). The -i option drops you into the testpmd interactive shell after the initialization is complete.
As a part of the rte_eal initialization done by testpmd, the mlx5_pci devices are probed and the DPDK ports populated.
testpmd> show port summary all Number of available ports: 6 Port MAC Address Name Driver Status Link 0 04:3F:72:BF:AE:38 0000:03:00.0 mlx5_pci up 25 Gbps 1 4A:6B:00:53:79:E5 0000:03:00.0_representor_vf4294967295 mlx5_pci up 25 Gbps 2 62:A1:93:8D:68:C4 0000:03:00.0_representor_vf0 mlx5_pci up 25 Gbps 3 0A:8E:97:F5:C0:41 0000:03:00.0_representor_vf1 mlx5_pci up 25 Gbps 4 04:3F:72:BF:AE:39 0000:03:00.1 mlx5_pci up 25 Gbps 5 D2:0B:15:45:94:E8 0000:03:00.1_representor_vf4294967295 mlx5_pci up 25 Gbps testpmd>
The DPDK ports that you see here correspond to the PF/VF representors and the two uplinks.
DPDK port
DPU netdev
Comments
0
p0
25G uplink attached to leaf1
1
pf0hpf
2
pf0vf0
VM1
3
pf0vf1
VM2
4
p1
5
pf1hpf
Table 2. DPDK port mapping
Flow creation
Next, I set up the PBR rule as a rte_flow by defining the ingress port, source IP, destination IP, protocol, and port. Along with that, I defined the action to take on matching packets. The source and destination MACs are rewritten, the TTL is decremented, and the egress port is set to the physical uplink, p0.
This PBR rule receives UDP and DNS traffic from VM1 and sends it to a specific GW (leaf2, server2). I also attached a counter-action to the flow for easy troubleshooting.
testpmd> flow create 2 ingress transfer pattern eth / ipv4 src is 172.20.0.8 dst is 172.30.0.8 proto is 17 / udp dst is 53 / end actions dec_ttl / set_mac_src mac_addr 00:00:00:00:00:11 / set_mac_dst mac_addr 00:00:5e:00:01:fa / port_id id 0 / count / end Flow rule #0 created testpmd>
The DPU can operate in the DPU-switch or DPU-NIC modes. In this use case, I had to redirect traffic from the X86-host to the 25G-uplink, after a few packet modifications. So, I conceptually used it in the switch or FDB mode. There is no additional configuration to setting up this mode beyond using the right rte_flow attribute, which in this case is transfer.
Flow verification
I sent some traffic from VM1 to see if it matched the flow that I created with the testpmd flow query command.
The flow is matched, and traffic is seen on leaf2/server2 with the modified packet headers. The traffic that is being steered is DNS, so to test the flow, I sent DNS requests from VM1. To have some control over the traffic rate and other packet fields, I used mz for test traffic generation.
ip netns exec vm1 mz ens3f0v0 -a 00:de:ad:be:ef:01 -b 00:de:ad:be:ef:02 -A 172.20.0.8 -B 172.30.0.8 -t udp "sp=25018, dp=53" -p 80 -c 0 -d 1s
An additional sanity check is to see if this flow is really offloaded. There are two ways to do that:
Use tcpdump on the Arm CPU to ensure that this packet flow is NOT received by the kernel.
Check if the hardware eSwitch is programmed with the flow.
mlx_steering_dump allows you to look at the hardware programmed flows. Download and install the tool using git.
This command dumps all the flows programmed by the testpmd app. And we can see the outer IP header matches that we setup – [SIP=172.20.0.8, DIP=172.30.0.8, IP-proto=UDP, UDP-dport=53]. The flow counters are read and cleared as a part of the dump.
Prototyping, the final step of the app design-thinking process is now complete. I now know I can build a PBR rule in DPDK, that is installed in hardware and is taking action on our packets. Now to add the DPDK dataplane in the next section.
Building the DPDK dataplane plugin
In this section, I walk through the steps for PBR hardware acceleration on the DPU by adding a DPDK dataplane plugin to Zebra. I broke these steps into individual code-commits and the entire patch-set is available as a reference.
As the target architecture is DPU-Arm, you can build directly on an Arm CPU, cross-compile on a X86 CPU, or build in the cloud. For this post, I coded and built directly on the DPU Arm CPU.
Run app as root user
FRR is typically run as a non-root user. FRR can download and upload the entire internet routing table; what could possibly go wrong with that? However, almost all the DPDK apps are run as root users and the DPDK libraries and drivers have come to expect that.
After much experimentation, I couldn’t make FRR work as a non-root user and re-compiled it with the root-user options. This is acceptable as I was running FRR in a secure space, the DPU-Arm CPU.
Adding a new plugin to Zebra
Zebra is a daemon in FRR that is responsible for consolidating the updates from routing protocol daemons and building the forwarding tables. Zebra also has an infrastructure for pushing those forwarding tables into dataplanes like the Linux kernel.
Link DPDK shared libraries to zebra
FRR has its own build system which limits direct import of external make files. Thanks to the simple elegance of pkg-config, linking the relevant libraries to Zebra was easy.
I located libdpdk.pc and added that to the PKG_CONFIG_PATH value:
I added the pkg check-and-define macro for DPDK in the FRR makefile (configure.ac).
if test "$enable_dp_dpdk" = "yes"; then PKG_CHECK_MODULES([DPDK], [libdpdk], [ AC_DEFINE([HAVE_DPDK], [1], [Enable DPDK backend]) DPDK=true ], [ AC_MSG_ERROR([configuration specifies --enable-dp-dpdk but DPDK libs were not found]) ]) fi
I included the DPDK libs and cflags abstractions into the zebra-dp-dpdk make macro (zebra/subdir.am).
This probes the PCIe devices and populates the DPDK rte_eth_dev database.
Initialize ports
Next, I set up the hardware ports.
Set up port mapping for the app
FRR has its own interface (port) table based on the Linux netdevs table, which is populated using NetLink updates and keyed in using ifIndex. PBR rules are anchored to an interface in this table. To program PBR dataplane entries, you need a mapping table between the Linux ifIndex and DPDK port-id values. The netdev information is already available in the DPDK driver and can be queried through rte_eth_dev_info_get.
struct rte_eth_dev_info *dev_info
RTE_ETH_FOREACH_DEV(port_id) { /* dev_info->if_index is used for setting up the dpdk port_idif_index mapping table * in zebra */ rte_eth_dev_info_get(port_id, dev_info); }
Configure hardware ports
In addition, all the ports need to be placed in flow isolation mode and started.
rte_flow_isolate(port_id, 1, &error);
Flow isolation sends flow-miss packets to the kernel networking stack, allowing it to handle things like ARP requests.
rte_eth_dev_start(port_id);
Program PBR rules using rte_flow APIs
PBR rules now need to be programmed as rte_flow lists. Here is a sample rule:
Filling these data structures requires a fair amount of mostly repetitive code.
Flow actions
DPDK uses a separate data structure for each action and then allows you to provide all the actions as a variable length array at the time of flow creation. The relevant actions are as follows:
Flow validation is typically used to check if the underlying DPDK driver can support the specific flow configuration. Flow validation is an optional step and in the final code, you can jump directly to flow creation.
Rte_flow commands are anchored to the incoming port. It is possible to create groups of flow entries and chain them. Even if a flow entry is not the first in the chain, not in group-0, it must still be anchored to the incoming port. That group-0 has performance limitations.
Flow insertion rate is limited in group-0. To bypass that limitation, you can install a default flow in group-0 to “jump to group-1” and then program the app’s steering flows in group-1.
Flow deletion
The flow creation API returns a flow pointer that must be cached for subsequent flow deletion.
rc = rte_flow_destroy(port_id, flow_ptr, &error);
The FRR-PBR daemon manages the state machine for resolving and adding or deleting PBR flows. So, I didn’t have to age them out using DPDK-native functions.
Flow statistics
At the time of flow creation, I attached a count-action to the flow. That can be used for querying the flow statistics and hits.
Next, I configured the PBR rule to match DNS traffic from VM1 and redirect it to leaf2, using frr.conf.
! interface pf0vf0 pbr-policy test ! pbr-map test seq 1 match src-ip 172.20.0.8/32 match dst-ip 172.30.0.8/32 match dst-port 53 match ip-protocol udp set nexthop 192.168.20.250 !
I sent DNS queries from VM1 to the anycast DNS server.
root@dpu-arm:~# vtysh -c "show dplane dpdk pbr flows" Rules if pf0vf0 Seq 1 pri 300 SRC IP Match 172.20.0.8/32 DST IP Match 172.30.0.8/32 DST Port Match 53 Tableid: 10000 Action: nh: 192.168.20.250 intf: p0 Action: mac: 00:00:5e:00:01:fa DPDK: installed 0x40 DPDK stats: packets 14 bytes 1708 root@dpu-arm:~#
Flow is matched and traffic is forwarded to the destination, leaf2/server2, with the modified packet headers. This can be verified with the counters attached to the flow and through the hardware dumps using mlx_steering_dump.
The development process for DPUs can get complex. This is where NVIDIA DOCA comes in. With several built-in libraries that allows for plug-n-play and simple application development.
In this post, I take you through the creation of the FRR DOCA dataplane plugin and show you how to offload PBR rules using the new DOCA flow library. In the previous post, you saw the creation of a FRR dataplane plugin to accelerate PBR rules on BlueField using the DPDK rte_flow library. For part 1, see Developing Applications with NVIDIA BlueField DPU and DPDK.
Adding the DOCA dataplane plugin to Zebra
I still used the DPDK APIs for hardware initialization, but then used the DOCA flow APIs for setting up the dataplane flow pipeline. To do that I had to link the DPDK (libdpdk.pc) and DOCA flow (doca-flow.pc) shared libraries to the DOCA dataplane plugin.
I added the pkg check-and-define macro for DPDK and DOCA flow in the FRR makefile (configure.ac).
if test "$enable_dp_doca" = "yes"; then PKG_CHECK_MODULES([DOCA], [libdpdk doca-flow], [ AC_DEFINE([HAVE_DOCA], [1], [Enable DOCA backend]) DOCA=true ], [ AC_MSG_ERROR([configuration specifies --enable-dp-doca but DOCA libs were not found]) ]) fi
I included both the DPDK and DOCA flow libs and cflags into the zebra-dp-doca make macro (zebra/subdir.am).
The DOCA dataplane plugin can be enabled when the FRR service is started using /etc/frr/daemons.
zebra_options= " -M dplane_doca -A 127.0.0.1"
Hardware initialization and port mapping
Using the DPDK APIs, rte_eal_init and rte_eth_dev_info_get, for initializing the hardware and for setting up the Zebra interface to DPDK port mapping. This workflow is the same as with the DPDK dataplane plugin in the previous section.
To use doca-flow for programming PBR rules, I had to initialize the doca-flow and doca-flow-port databases. This initialization was done after the hardware was initialized using rte_eal_init.
I used doca_flow_init for initializing the doca-flow library with the flow and queue count config.
I skipped populating fields such as eth or eth-mask. This is because the doca-flow library can auto-populate such fields to RTE_ETHER_TYPE_IPV4 or RTE_ETHER_TYPE_IPV6, based on other match fields, dst_ip or src_ip.
Flow actions
To route the packet, I had to change the destination MAC address to the gateway (leaf2) MAC, decrement the TTL, and change the source MAC address. This was originally discussed in part 1, Developing Applications with NVIDIA BlueField DPU and DPDK.
The first step creates a software template for a lookup stage. The second step uses the template to program the flow in the hardware.
Pipes are useful when you must program many similar flows. For such a case, you can set up a single match template (pipe) and indicate which match-field must be updated at the time of flow entry creation (for example, a layer 4 destination port). Subsequent flow entries need onlypopulate the match fields that vary from the pipe (the layer 4 destination port).
In the case of PBR, each flow pattern is unique, so I created a separate pipe and entry for each PBR rule using the flow attributes that I already populated.
// hit counters – query.total_pkts and query.total_bytes memset(&query, 0, sizeof(query)); doca_flow_query(flow_entry, &query);
Verifying hardware acceleration
The FRR-PBR rule configuration and traffic generation is the same as with dpdk-plugin. The traffic is forwarded by the DPU hardware as expected and can be verified using the flow counters.
root@dpu-arm:~# vtysh -c "show dplane doca pbr flow" Rules if pf0vf0 Seq 1 pri 300 SRC IP Match: 172.20.0.8/32 DST IP Match: 172.30.0.8/32 IP protocol Match: 17 DST Port Match: 53 Tableid: 10000 Action: nh: 192.168.20.250 intf: p0 Action: mac: 00:00:5e:00:01:fa DOCA flow: installed 0xffff28005150 DOCA stats: packets 202 bytes 24644root@dpu-arm:~#
FRR now has a second dataplane plugin for hardware acceleration of PBR rules, using doca-flow.
Application development takeaways
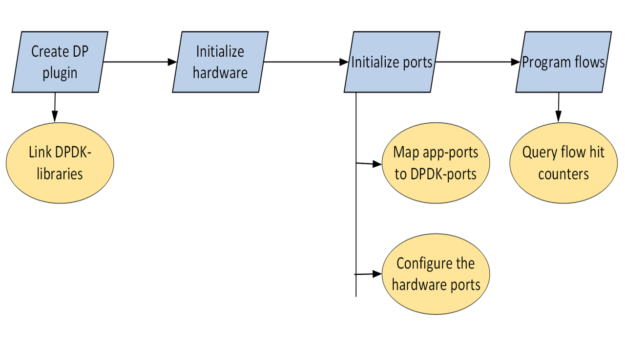
In this series, you saw how a DPU networking application can be hardware-accelerated with four steps using rte_flow or doca_flow:
Link the DOCA/DPDK libraries to the application.
Initialize the hardware.
Setup the application to hardware port mapping.
Program flows for steering the traffic.
As more elements are offloaded on the DPU, the development process can get complex with increasing source lines of code (SLOC). That’s where DOCA abstractions help:
DOCA comes with several built-in libraries such as doca-dpi, gRPC, Firefly time synchronization, and more. These libraries enable quick plug-n-play for your application.
DOCA constructs such as doca_pipe enable you to templatize your pipeline, eliminating boilerplate code and optimizing flow insertion.
Upcoming DOCA libraries, such as the hardware-accelerated LPM (Longest prefix match) make building switch pipelines easier. This is particularly relevant to the sample application that you saw in this series, FRR, which is commonly deployed for building a LPM routing table (or RIB) with BGP.
With DOCA, you can also leapfrog into the exciting world of GPU + DPU development on the converged accelerators.
Figure 1. Converged Accelerator
Are you ready to take your application development to dizzying heights? Sign up for the DOCA Early Access developer program to start building today.
For more information, see the following resources:
Hey all, first time poster, and have not been active due to my projects, I am very new to deep learning and ML, I have trained some semantic segmentation models in the past, but not a whole lot. I am just asking for some help with an error that I keep getting, it is a no gradient provided for any variable error, I am doing some semantic segmentation of brain data, its taking brain data and categorizing (onehot) into 4 specific categories, this data was filtered for the specific categories needed. Below is my main code, I believe it is due to the one hot encoding method from keras but if anyone has ever dealt with something similar, some tips would be really helpful.
Thanks all, and have a great day, here is the code:
class DataEncoder(keras.utils.Sequence):
‘Generates data for Keras’
def __init__(self, imgs_list, masks_list, patch_size=(128, 128), batch_size=32, shuffle=True):
def __len__(self):
‘Denotes the number of batches per epoch’
return len(self.imgs_list) // self.batch_size
def __getitem__(self, index):
‘Generate one batch of data’
# Generate indexes of the batch
batch_indexes = self.indexes[index * self.batch_size:(index + 1) * self.batch_size]
# Generate data
X, Y = self.__data_generation(batch_indexes)
return X, Y
def on_epoch_end(self):
‘Updates indexes after each epoch’
self.indexes = np.arange(self.nsamples)
if self.shuffle == True:
np.random.shuffle(self.indexes)
def __data_generation(self, batch_indexes):
‘Generates data containing batch_size samples’
# Initialization
X = np.empty((self.batch_size, self.patch_size[0], self.patch_size[1], 1))
Y = np.empty((self.batch_size, self.patch_size[0], self.patch_size[1], 1))
for (jj, ii) in enumerate(batch_indexes):
aux_img = np.load(self.imgs_list[ii])
aux_mask = np.load(self.masks_list[ii])
# Implement data augmentation function
aux_img_patch, aux_mask_patch = self.__extract_patch(aux_img, aux_mask)
The new expanded NVIDIA Metropolis program offers access to the world’s best development tools and services to reduce time and cost of managing your vision AI deployments.
The newly expanded NVIDIA Metropolis program offers you access to the world’s best development tools and services to reduce the time and cost of managing your vision-AI deployments. Join this developer meetup (dates and times below) with NVIDIA experts to learn five ways the NVIDIA Metropolis program will grow your vision AI business and enhance your go-to-market efforts.
In this meetup, you will learn how:
Metropolis Validation Labs optimize your applications and accelerate deployments.
NVIDIA Fleet Command simplifies provisioning and management of edge deployments accelerating the time to scale from POC to production.
NVIDIA LaunchPad provides easy access to GPU instances for faster POCs and customer trials.
Partners around the world are achieving success through this program.
Additionally, you will hear from elite partner Milestone Systems, who will share how NVIDIA Metropolis is boosting its AI software development, integration, and business development efforts.
Get Metropolis Certified to gain access to the NVIDIA Software stack, GPU servers, and marketing promotions worth over $100,000 in value.
Select one of the following sessions in the region most convenient to you (Feb. 16 and 17):
Interior renovations have never looked this good. TCImage, a studio based in Taipei, is showcasing compelling landscape and architecture designs by creating realistic 3D graphics and presenting them in virtual, augmented, and mixed reality — collectively known as extended reality, or XR. For clients to get a better understanding of the designs, TCImage produces high-quality, Read article >
Preventable train accidents like the 1985 disaster outside Tel Aviv in which a train collided with a school bus, killing 19 students and several adults, motivated Shahar Hania and Elen Katz to help save lives with technology. They founded Rail Vision, an Israeli startup that creates obstacle-detection and classification systems for the global railway industry Read article >
EditGAN takes AI-driven image editing to the next level by providing high levels of accuracy while not sacrificing image quality.
The desire to edit photos of cats, cars, or even antique paintings, has never been more accessible thanks to a generative adversarial network (GAN) model called EditGAN. The work—from NVIDIA, the University of Toronto, and MIT researchers—builds off DatasetGAN, an Artificial Intelligence vision model that can be trained with as few as 16 human-annotated images and performs as effectively as other methods that require 100x more images. EditGAN takes the power of the previous model and empowers the user to edit or manipulate the desired image with simple commands, such as drawing, without compromising the original image quality.
What is EditGAN?
According to the paper: “EditGAN is the first GAN-driven image-editing framework, which simultaneously offers very high-precision editing, requires very little annotated training data (and does not rely on external classifiers), can be run interactively in real time, allows for straightforward compositionality of multiple edits, and works on real embedded, GAN-generated, and even out-of-domain images.”
The model learns a specific number of editing vectors, which can be applied to an image interactively. Essentially, it forms an intuitive understanding of the images and their content, which can then be leveraged by users for specific modifications and editing. The model learns from similar images and recognizes different components and specific parts of the objects inside the images. A user can utilize this for targeted modifications of the different subparts or for editing within specific areas. Because of how precise the model is, the image is not distorted outside of the parameters set by the user.
Figure 1. EditGAN in action, the AI trained in the model allows the user to make, sometimes dramatic, changes to the original image.
“The framework allows us to learn an arbitrary number of editing vectors, which can then be directly applied on other images at interactive rates.” The researchers explained in their study. “We experimentally show that EditGAN can manipulate images with an unprecedented level of detail and freedom while preserving full image quality. We can also easily combine multiple edits and perform plausible edits beyond EditGAN’s training data. We demonstrate EditGAN on a wide variety of image types and quantitatively outperform several previous editing methods on standard editing benchmark tasks.”
From adding smiles, changing the direction someone is looking, creating a new hairstyle, or giving a car a nicer set of wheels, the researchers show just how intrinsic the model can be with minimal data annotation. The user can draw a simple sketch or mask corresponding to the desired editing and guides the AI model to realize the modification, such as bigger cat ears or cooler headlights on a car. The AI then renders the image while maintaining a very high level of accuracy and maintaining the quality of the original image. Afterwards, the same edit can be applied to other images in real-time.
Figure 2. An example of the pixels assigned to different parts of the image. The AI recognizes the different areas and can make edits based on human input.
How does this GAN work?
EditGAN assigns each pixel of the image to a category, such as a tire, windshield, or car frame. These pixels are controlled within the AI latent space and based on the input of the user, who can easily and flexibly edit those categories. EditGAN manipulates only those pixels associated with the desired change. The AI knows what each pixel represents based on other images used in training the model, so you could not attempt to add cat ears to a car with accurate results. But when used within the correct model, EditGAN is a phenomenal tool that provides exceptional image editing results.
Figure 3. EditGAN can train on a variety of classes of imagery, from animals to environments, forming a detailed understanding of their content.
EditGAN’s potential
AI-driven photo and image editing have the potential to streamline the workflow of photographers and content creators and to enable new levels of creativity and digital artistry. EditGAN also enables novice photographers and editors to produce high-quality content, along with the occasional viral meme.
“This AI may transform how we edit photos and perhaps eventually video. It allows someone to take an image and alter it by using simple text commands. If you have a photo of a car and you want to make the wheels bigger, just type “make wheels bigger,” and poof!—there’s a completely photorealistic picture of the same car with bigger wheels.” – Fortune magazine
EditGAN may also be used for other important applications in the future. For example, EditGAN’s editing capabilities could be utilized to create large image datasets with certain characteristics. Such specific datasets can be useful when training downstream machine-learning models on different computer vision tasks.
Furthermore, the EditGAN framework may impact the development of future generations of GANs. While the present version of EditGAN focuses on image editing, similar methods could potentially be used to edit 3D shapes and objects, which would be useful when creating virtual 3D content for games, movies, or the metaverse.
To read more about this amazing methodology, check out their paper.
NVIDIA is always on the cutting edge of technology, check out NVIDIA Research for more innovative research.
I have 10k+ documents which belong either to class 0 or 1. I want to train a model by feeding it each sentence in a document through a textvectorize layer ➡️ embedding layer ➡️ lstm layer Then concat all lstm layers for each sentence feed them to 1 dense layer with outputsize of 128 ➡️ dense layer outputsize of 1 with softmax as activation.
Number of sentences in each document is somewhere between 0 and 5000. Each sentence has between 1-5 words.
I have managed to create a model for predicting which class a sentence most likely belong to. But i want to basically extend it to take all sentences from an exampledocument for classifying entire document. Each sentence is not related to the other.

 Developing and application and offloading it in two ways, via DPDK and via DOCA libraries, to run on the BlueField Data Processing Unit
Developing and application and offloading it in two ways, via DPDK and via DOCA libraries, to run on the BlueField Data Processing Unit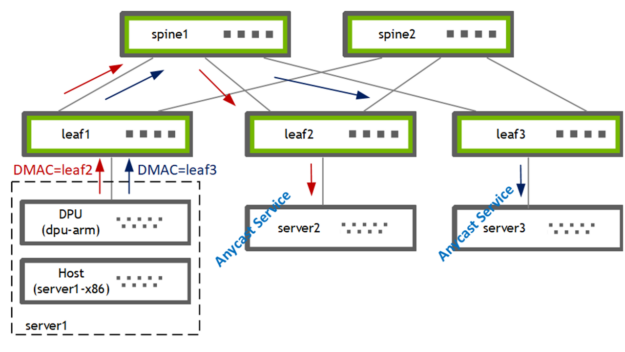
 The development process for DPUs can get complex. This is where NVIDIA DOCA comes in. With several built-in libraries that allows for plug-n-play and simple application development.
The development process for DPUs can get complex. This is where NVIDIA DOCA comes in. With several built-in libraries that allows for plug-n-play and simple application development. 
 The new expanded NVIDIA Metropolis program offers access to the world’s best development tools and services to reduce time and cost of managing your vision AI deployments.
The new expanded NVIDIA Metropolis program offers access to the world’s best development tools and services to reduce time and cost of managing your vision AI deployments. EditGAN takes AI-driven image editing to the next level by providing high levels of accuracy while not sacrificing image quality.
EditGAN takes AI-driven image editing to the next level by providing high levels of accuracy while not sacrificing image quality.