I’m wondering how the pre-trained models actually handle the variety of inputs? Do the original layer weights stay exactly the same?
Many thanks in advance for your care & time.
submitted by /u/talhak
[visit reddit] [comments]
 DataBloom
DataBloomI’m wondering how the pre-trained models actually handle the variety of inputs? Do the original layer weights stay exactly the same?
Many thanks in advance for your care & time.
submitted by /u/talhak
[visit reddit] [comments]
I have been looking around and haven’t been able to find the answer to this one. I am having trouble trying to resume training on a CGAN that I am working with after loading the h5 file. When I try to start training the model again after loading the files, the generator loss will begin to move towards zero very quickly, within 3-4 epochs.
Below is some of the code for loading the models and resuming training. Any help or suggestions would be greatly appreciated!
Loading Models:
d_model = load_model('Aeon5/cgan_model/discriminator_0_to_83.h5') g_model = load_model('Aeon5/cgan_model/generator_0_to_83.h5') gen_noise, gen_label = g_model.input gen_output = g_model.output gan_output = d_model([gen_output, gen_label]) combined = Model([gen_noise, gen_label], gan_output) opt = Adam(lr=0.0002, beta_1=0.5) combined.compile(loss=['binary_crossentropy'], optimizer=opt)
Resuming Training:
def resume_train(epochs, start, generator, discriminator, combined_model, latent_dim, data_loader, name_append, batch_size=50): for epoch in range(start, epochs): random = np.random.randint(0, 11) for index in range(int(50000/batch_size)): valid = np.ones((batch_size, 1)) fake = np.zeros((batch_size, 1)) idx = np.random.randint(0, 50000, batch_size) x_train = data_loader.get_img_batch(idx) y_train = data_loader.get_label_batch(idx) x_train = (x_train.astype(np.float32) - 127.5)/127.5 if index % 100 == random: valid = np.zeros((batch_size, 1)) + (np.random.random()*0.1) fake = np.ones((batch_size, 1)) - (np.random.random()*0.1) noise = np.random.randn(batch_size, latent_dim) gen_img = generator.predict([noise, y_train]) d_loss_real, _ = discriminator.train_on_batch([x_train, y_train], valid) d_loss_fake, _ = discriminator.train_on_batch([gen_img, y_train], fake) d_loss = 0.5*(np.add(d_loss_real, d_loss_fake)) sample_label = np.random.randint(0, 10, batch_size).reshape(-1, 1) valid = np.ones((batch_size, 1)) g_loss = combined_model.train_on_batch([noise, sample_label], valid) if index % (batch_size) == 0: sample_images(epoch, latent_dim, generator, data_loader) print("%d [D loss: %f] [G loss: %f]" % (epoch, d_loss, g_loss)) #Save the combined model and the generator name = './cgan_model/combined_' + name_append + '.h5' combined_model.save(name) name = './cgan_model/generator_' + name_append + '.h5' generator.save(name) name = './cgan_model/discriminator_' + name_append + '.h5' discriminator.save(name)
submitted by /u/Wrathnut
[visit reddit] [comments]
What better way to look back at NVIDIA’s top five videos of 2021 than to hop into the cockpit of a virtual plane flying over Taipei. That was how NVIDIA’s Jeff Fisher and Manuvir Das invited viewers into their COMPUTEX keynote on May 31. Their aircraft sailed over the city’s green hills and banked around Read article >
The post It Was a Really Virtual Year: Top Five NVIDIA Videos of 2021 appeared first on The Official NVIDIA Blog.
Where I work, we need to quantize our models to run them quick enough, and we found that Quantization Aware Training is the only one that has a chance of retaining the desired accuracy. Using Post-training Quantization incurs too many losses.
However, QAT is incredibly difficult and cumbersome in TF 2 because it only applies to models defined through the functional API, whereas many interesting models use for example the object-oriented approach of defining a model.
Does anyone know if there are plans to make QAT easier to use in the future?
submitted by /u/wattnurt
[visit reddit] [comments]
I have been searching for some quality tutorials on tensorflow for quite a while and I can’t find some good ones.
Can anyone please suggest me any tutorial (I would prefer video) to learn tensorflow with hands on (I mean using it practically too not just go through docs only)?
submitted by /u/outofthisworld420
[visit reddit] [comments]
First of all, nice to meet you, I’m new. Well, I already read him a lot about the theory and he had even bought courses, but I feel that the examples were already old or not useful. I have also been reading some posts in this sub and I have noticed that tensorflow and keras have their inefficiencies, so I don’t know what tools and resources to use to start with.
Beforehand thank you very much.
submitted by /u/Cextremo
[visit reddit] [comments]

Over the past few years, I’ve been building out an abstract news summarizing app from the ground up. The summarizer is built using TensorFlow and the app is built using React Native.
This has been a solo project and there was a lot of learning on the go. Happy to hear your thoughts, feedback, and questions!
You can find the full iOS app here
submitted by /u/devforfuntimes
[visit reddit] [comments]
submitted by /u/tmp-1379
[visit reddit] [comments]
 Use NVIDIA CloudXR alongside AWS to build immersive XR experiences from the cloud for key advantages at every stage from development to distribution.
Use NVIDIA CloudXR alongside AWS to build immersive XR experiences from the cloud for key advantages at every stage from development to distribution.
Creating immersive applications with high-fidelity 3D graphics has never been more accessible thanks to recent advances in extended reality (XR) hardware and software. Despite this growth, developing augmented reality (AR) and virtual reality (VR) applications still come with challenges:
By using NVIDIA CloudXR alongside Amazon NICE DCV streaming protocols, you can use on-demand compute resources for all aspects of your immersive application development. This includes services to support end-to-end workflows, tight control over the security of your data, and simplifying the management of deploying and delivering application updates.
Production-grade interactive XR applications require a collection of supporting technologies to successfully build, deliver, and consume content. The advent of microservices from cloud infrastructure has made it easier to deploy these components to an end-to-end solution. The compute, storage, and networking resources of Amazon Web Services (AWS) can be used to develop, deploy, and distribute XR applications. These can then be remotely rendered and streamed using NVIDIA CloudXR over distributed networks.
Leveraging both AWS and NVIDIA CloudXR presents several advantages:
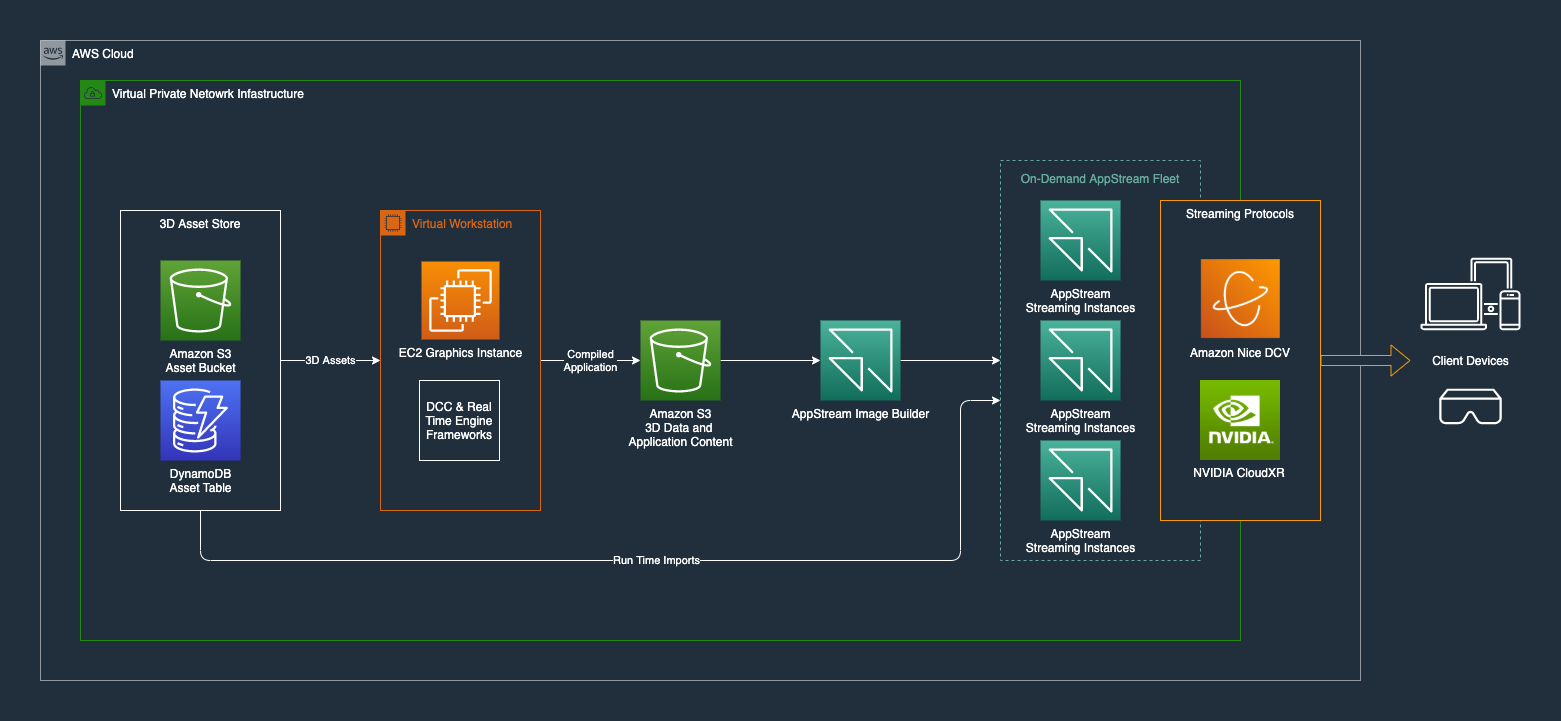
Figure 1 demonstrates an example configuration of NVIDIA CloudXR with AWS services to develop, deploy, and distribute XR applications.
NVIDIA CloudXR is an SDK that enables you to implement real-time GPU rendering and streaming of rich VR, AR, and XR applications on remote servers, including the cloud. Applications that typically require tethered HMDs can connect and stream remotely on low-powered VR devices or tablets without degrading performance.
NVIDIA CloudXR fulfills the key component of XR streaming and enables AWS customers to use the cloud for end-to-end XR application development. The NVIDIA CloudXR Amazon Machine Image is bundled with RTX Virtual Workstation and currently supports Amazon EC2 G4 instances.
Amazon NICE DCV is a high-performance remote display protocol. It lets you securely deliver remote desktops and application streaming from any cloud or data center to any device, over varying network conditions. By using NICE DCV with Amazon EC2, you can run graphics-intensive applications remotely on Amazon EC2 instances.
Powered by the latest NVIDIA GPUs, NICE DCV delivers low-latency performance for artists and developers building next-generation immersive applications. You can then stream the results to more modest client machines, eliminating the need for expensive dedicated workstations.
Streaming applications require content in order to be useful. When creating an asset management pipeline for immersive applications in the cloud, AWS services like Amazon Simple Storage Service (S3), Amazon DynamoDB (a NoSQL low-latency database), and Amazon API Gateway serve as core components.
When your application is ready to be deployed, build artifacts can be sent from S3 to Amazon AppStream 2.0, a fully managed nonpersistent desktop and application-streaming service, or an NVIDIA GPU-equipped Amazon EC2 instance. These instances are also configured with an NVIDIA CloudXR SDK server, which allows them to receive requests from devices loaded with the NVIDIA CloudXR client.

By streaming experiences with NVIDIA CloudXR, data never leaves the data center. Globally available AWS instances allow you to render experiences close to your end users, but NVIDIA CloudXR does the heavy lifting to reduce the perceived latency and provide a smooth experience for end users. Using NVIDIA CloudXR as part of your development and testing process means you can build applications for the same target platform for testing as well as final deployment.
Using NVIDIA CloudXR to stream immersive experiences from the AWS cloud, you can deliver high-fidelity graphics to untethered AR and VR devices. With development workstations running NICE DCV on Amazon EC2, you can spin up graphics workstations for your team from any location. The AWS cloud for development, deployment, and distribution of your immersive applications is a highly scalable, secure, and resilient single source of truth for all of your 3D content.
To get started with NVIDIA CloudXR on AWS, see the NVIDIA CloudXR AMI listed on the AWS Marketplace.
For more information about running virtual workstations on AWS, see Nimble Studio, which gives you the tools to get up and running quickly, with graphics workstations streamed from the cloud.
Finally, be sure to check out AppStream 2.0, a fully managed service to deploy streaming applications to any type of device.


|
submitted by /u/metalwhalecom [visit reddit] [comments] |