
 Use unsupervised AI and time series modeling to create microtargeted models for every user and account; as humans and machine/account combinations running on your network.
Use unsupervised AI and time series modeling to create microtargeted models for every user and account; as humans and machine/account combinations running on your network.
Traditional approaches to finding and stopping threats have ceased to be appropriately effective. One reason is the scope of ways an attacker can enter a system and do damage have proliferated as the interconnections between apps and systems have proliferated.
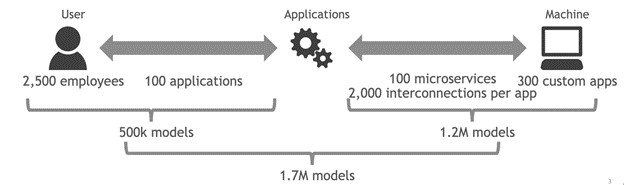
Applying AI to the problem seems like a natural choice but this in some sense broadens the data problem. A typical user may interact with 100 or more apps while doing their job, and integrations between apps means that there may be tens of thousands of interconnections and permissions shared across those 100 apps. If you have 10,000 users, you’d need 10,000 models as a beginning.
The good news is that NVIDIA Morpheus addresses this problem. NVIDIA recently announced an update to Morpheus, an end-to-end tool to apply data science to cybersecurity problems.
Problem overview
A breached credential for any given app can give an attacker a huge world of permissions that will not be obvious or static over time. In 2021, compromised credentials were at the root of 61% of attacks.
While most apps and systems will create logs, the variety, volume, and velocity of these logs means that much of the response possible is “closing the barn door after the horse has left.” Identifying credential breaches and the damage done can take weeks if you’re lucky, months if you’re average.
With any number of users beyond “modest” or “very modest,” traditional rule-based systems to create warnings are insufficient. A person who knew how another person or system typically behaves could notice something fishy almost immediately when that user or system started doing something that was unusual.
Every account has a digital fingerprint: a typical set of things it does or doesn’t do in a specific sequence in time. This problem is no longer addressed by just strong passwords that reset periodically, a table of rules, and periodic drop-sized spot checks of logs from the ocean of log data.
The problem is understanding every user’s day-to-day, moment-by-moment work. This is a data science problem.
Model ensemble for multiple methods
10,000 models are daunting enough. But if we’re committed to approaching the cybersecurity problem like the serious data science problem it is, one model isn’t enough. The state of the art in the most critical data-science problems is ensembling multiple models.
A model ensemble is where models are combined in some way to give better predictions than a single model could. The “wisdom of the crowd” turns out to be just as true, with a crowd of machine learning methods all trying to predict the same thing.
In the case of identifying the digital fingerprint of a malevolent attack, Morpheus takes two different models and uses them to alert human analysts to possible serious danger. One method is only a few years old and the other is several hundred years old:
- Because attacks seek to hide their behavior by mimicking a given account’s behavior, autoencoders test how typical a given user’s behavior is as a flat snapshot.
- Because an attack is temporal, Fourier transforms are used to understand the typical behavior over time.
Method 1: Autoencoders
In the specific example that is enabled with Morpheus, an autoencoder is trained on AWS CloudTrail data. The CloudTrail logs are nested JSON objects that can be transformed into tabular data. The data fields can vary widely across time and users. This requires the flexibility that neural net methods provide and the preprocessing speed of RAPIDS, a part of the Morpheus platform. The particular neural net method that Morpheus deploys in this use case is an autoencoder.
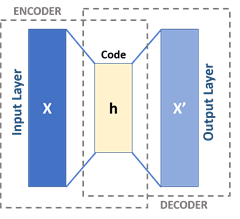
At a high level, an autoencoder is a type of neural network that tries to extract noise from a given datum and reconstruct that datum in an approximated form without that noise while being as true as possible to the actual datum.
For example, think of a photograph with scratches over the surface. A good autoencoder reproduces the underlying picture without the scratches. A well-trained autoencoder, one that knows its domain well, has low “loss” or error as it reconstructs a given datum.
In this case, you take a given user’s typical behavior, take out the “noise” of slight variation, and reproduce that digital fingerprint. Each encoding event has a loss or error associated with it, like any statistics problem.
To deploy this solution, update the pretrained model that comes with Morpheus with a period of typical, attack-free data for each user/service and machine/service interaction. Move these models to the NVIDIA Triton Inference Server layer of Morpheus.
What may be surprising is that the actual auto-encoding is discarded and the loss number is preserved. A user-defined threshold is defined to flag accounts to be reviewed by a human. The default option is a classic Z-score: Is the loss four standard deviations higher than the average loss for this user?
Method 2: Fast Fourier Transforms
Fast Fourier transforms (FFTs) distill the essential behavior of a wave under the data noise. Fourier analysis was developed in the late 1700s and has continued to be invaluable to the applied mathematical analysis of fields as diverse as finance, traffic engineering, economics, and in this case, cybersecurity.
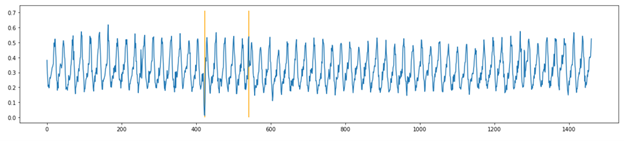
A given time series is compostable into various components, showing regular seasonal, weekly, and hourly variations along with a trend. Decomposing a time series enables analysts to understand if something that goes up and down a lot over time is actually growing despite constant oscillations. They can also understand if the time series is of interest to the cybersecurity use case, and if there is something truly unusual going on beyond the normal ebb and flow of traffic.
Machine application activity tends to oscillate over time, and attacker activities can be difficult to detect among the periodic noise in data with just a volumetric alert. To find subtle anomalies inside periodic data, you transform the data from the time domain to the frequency domain using FFT. You then reconstruct the signal back to the time domain (with iFFT) but use only the top 90% of frequencies. A large difference between the original signal and the reconstructed signal indicates the times at which the machine’s activity is unusual and potentially compromised by malicious human activity.
Morpheus applies FFTs by learning what a normal period or periods of activity looks like for a given user/service and machine/service system interaction. After this, GPUs perform decomposition quickly and apply a rolling Z-score to the transformed data to flag periods that are anomalous. For reference, CuPy FFT decompositions are as much as 120x faster than comparable operations done through NumPy. For more information, see FFT Speedtest comparing Tensorflow, PyTorch, CuPy, PyFFTW and NumPy.
Putting it all together
Morpheus is a tool to aid human analysts. This means that it is at its most useful when it sends the right amount of data to a person.
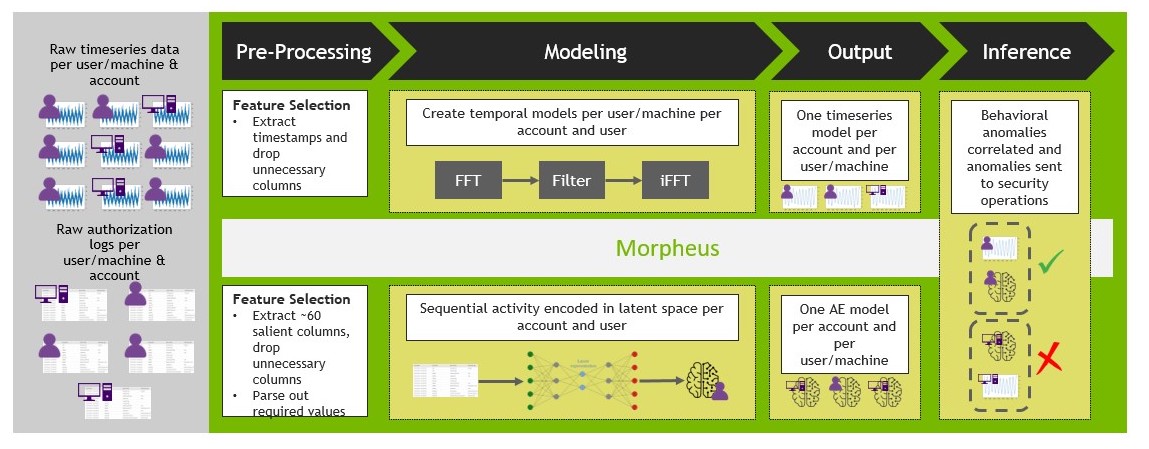
Returning to the ensembling discussion from earlier, Morpheus uses a voting ensemble. Data flagged by both models with the most urgency is sent to the human security team. This enables a force multiplier for cybersecurity red teams by directing their valuable time to threats as they unfold in real time, rather than weeks or months later.
The cybersecurity data problem is like refining ore from silt: you begin with a huge amount of nothing and as you sift, refine, and assay, you get to something actually worth looking at. While we wouldn’t suggest that system intrusions are gold, we know that the time of analysts is.
Effective defense requires intelligence tools to aid traceability and prioritization. The ensembling of sophisticated methods that Morpheus deploys does just that. This means reduced financial, reputational, and operational risk for enterprises that deploy Morpheus.
Try it out
Morpheus ships with the code, data, and models for you to be able to see how the use case works and to get a feel for how Morpheus would work for your enterprise. Using the earlier workflow, you observed a micro-F1 score of 1. In addition, across multiple experiments, you saw a near 0% rate of false attribution (machine compared to human).
Beyond the state-of-the-art data science and prebuilt models, Morpheus is designed to be a platform for cybersecurity data science. It seamlessly combines a suite of NVIDIA and Cyber Log Accelerator (CLX) technologies to make deployment easy and fast.
Keep in mind that these models, particularly the FFT model, cannot start totally cold and must be given some amount of data that is representative of a normal, attack-free stream of CloudTrail logs.
This is just the beginning of what Morpheus can do to stop the hacking specter haunting enterprises. It is easy to imagine that, in the near future, even more models are deployed simultaneously for even greater predictive accuracy. For access to the latest release of NVIDIA Morpheus, register for the expanded early access program.


 The NVIDIA Network Operator includes an RDMA Shared Device Plug-In and OFED Driver.
The NVIDIA Network Operator includes an RDMA Shared Device Plug-In and OFED Driver. 




 Learn how AI-enabled video analytics is helping companies and employees work smarter and safer.
Learn how AI-enabled video analytics is helping companies and employees work smarter and safer. {kind=link}