
Achieving 100 Gbps intrusion prevention on a single server, Zhao et al., OSDI’20
Papers-we-love is hosting a mini-event this Wednesday (18th) where I’ll be leading a panel discussion including one of the authors of today’s paper choice: Justine Sherry. Please do join us if you can.
We always want more! This stems from a combination of Jevon’s paradox and the interconnectedness of systems – doing more in one area often leads to a need for more elsewhere too. At the end of the day, there are three basic ways we can increase capacity:
- Increasing the number of units in a system (subject to Amdahl’s law).
- Improving the efficiency with which we can coordinate work across a collection of units (see the Universal Scalability Law)
- Increasing the amount of work we can do on a single unit
Options 1 and 2 are of course the ‘scale out’ options, whereas option 3 is ‘scale up’. With more nodes and more coordination comes more complexity, both in design and operation. So while scale out has seen the majority of attention in the cloud era, it’s good to remind ourselves periodically just what we really can do on a single box or even a single thread.
Today’s paper choice is a wonderful example of pushing the state of the art on a single server. We’ve been surrounding CPUs with accelerators for a long time, but at the heart of Pigasus‘ design is a really interesting inversion of control – the CPU isn’t coordinating and calling out to the accelerator, instead the FGPA is in charge, and the CPU is playing the support role.
IDS/IPS requirements
Pigasus is an Intrusion Detection / Prevention System (IDS/IPS). An IDS/IPS monitors network flows and matches incoming packets (or more strictly, Protocol Data Units, PDUs) against a set of rules. There can be tens of thousands of these rules, which are called signatures. A signature in turn is comprised of one or more patterns matching against either the header or the packet content, including both exact string matches and regular expressions. Patterns may span multiple packets. So before matching, the IDS/IPS has to reconstruct a TCP bytestream in the face of packet fragmentation, loss, and out-of-order delivery – a process known as reassembly.
When used in prevention mode (IPS), this all has to happen inline over incoming traffic to block any traffic with suspicious signatures. This makes the whole system latency sensitive.
So we need low latency, but we also need very high throughput:
A recurring theme in IDS/IPS literature is the gap between the workloads they need to handle and the capabilities of existing hardware/software implementations. Today, we are faced with the need to build IDS/IPSes that support line rates on the order of 100Gbps with hundreds of thousands of concurrent flows and capable of matching packets against tens of thousands of rules.
Moreover, Pigasus wants to do all this on a single server!
Back of the envelope
One of the joys of this paper is that you don’t just get to see the final design, you also get insight into the forces and trade-offs that led to it. Can you really do all this on a single server??
The traditional approach to integrating FPGAs in IDS/IPS processing is to have the CPU in charge, and offload specific tasks, such as regular expression parsing, to the FPGA. The baseline for comparison is Snort 3.0, “the most powerful IPS in the world” according to the Snort website. In particular, Pigasus is designed to be compatible with Snort rulesets and evaluated using the Snort Registered Ruleset (about 10K signatures). The biggest fraction of CPU time in Snort is spent in the Multi-String Pattern Matcher (MSPM) module, which is used for header and partial string matching.
Using Amdahl’s Law, we can see that even if MSPM were offloaded to an imaginary, infinitely fast accelerator, throughput would increase by only 85% to 600Mbps/core, still requiring 166 cores to reach 100Gpbs.
In fact, whatever module of Snort you try to offload to a hypothetical infinitely fast accelerator, you can never get close to the performance targets of Pigasus. That fixes Pigasus’ first design decision: the FPGA needs to be in charge as the primary compute platform, and the CPU will be secondary in service of it. (FPGAs are chosen because they are both energy efficient and available on SmartNICs).
Having settled on an FPGA-first design, this means that stateful packet processing for matching and reassembly needs to be performed on the FPGA. And that in turn means that the primary design constraint is the amount of FPGA memory available, especially Block RAM (BRAM). The target FPGA for Pigasus has 16MB of BRAM.
Of concern here is the regular expression matching performed by the Full Matcher. Regular expression matching is well studied, but state of the art hardware algorithms don’t reach the performance and memory targets needed for Pigasus. Performing RE matching on the FPGA would consume a lot of memory, and offer only marginal overall performance gains since most packets don’t touch the full matcher. This brings us to another major design decision: regular expression matching will be offloaded from the FPGA to the CPU.
Introducing Pigasus
Putting together everything we’ve learned so far, the overall architecture of Pigasus looks like this:
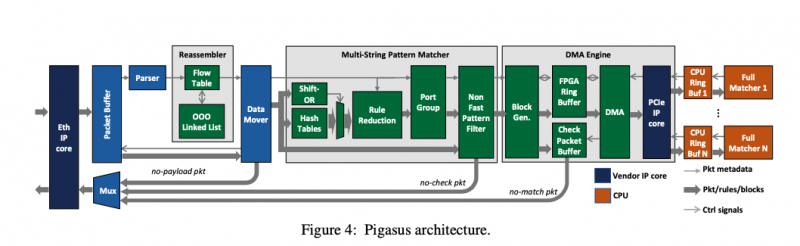
- The reassembler is responsible for ordering TCP packets. It needs to do this at line rate while maintaining state for 100K flows.
- The multi-string pattern matcher (MSPM) does header matching for all 10,000 rules, and exact string-match filtering to determine which further rules might possibly match.
- If the MSPM indicates a possible match, the packet and rule IDs are sent to the DMA Engine, which farms work out to the CPU for full matching.
- The Full Matcher runs on the CPU, polling a ring buffer populated by the DMA Engine.
To save the precious BRAM for the most performance sensitive tasks (reassembly and MSPM), the packet buffer and DMA Engine use the less powerful eSRAM and DRAM available on the FPGA.
Both the reassembler and MSPM modules required careful design to meet their performance and memory targets.
The reassembler: processing fast and slow
The key objective of our Reassemble is to perform this re-ordering for 100K’s of flows, while operating at 100Gbps, within the memory limitations of the FPGA.
The FPGA hardware really wants to operate in a highly parallel mode using fixed size data structures. This works well until we consider out of order packet arrival. To accomodate out-of-order packets though, a memory dense structure such as a linked list works better.
The solution is to divide the reassembly pipeline into a fast path handling in-order flows using fixed size buffers and constant time operations, and a slow path handling the remaining out of order flows. The constant time operations on the fast path guarantee a processing rate of 25 million packets-per-second, enough to reach the 100Gbps target at 500B+ packets. The slow path can’t take advantage of constant time operations, but fortunately is less often used as most packets arrive in order. It’s also used when inserting new flows.
The fast path, new flow insertion, and out-of-order processing all synchronise over shared flow state using a cuckoo-hashing based hash table design from FlowBlaze.
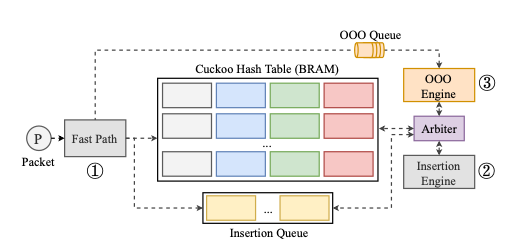
MPSM: First things first
There are challenges in the design of the MSPM too.
To the best of our knowledge, there are no other hardware or software projects reporting multi-string matching of tens of thousands of strings at 100Gpbs.
Snort 3.0 uses Intel’s Hyperscan library for MSPM. The Hyperscan string matching library is parallelisable and provides an 8x speedup over software state-machine based string matchers. But a simple translation to FPGA would blow the memory budget, requiring about 25MB of BRAM.
By carefully staging the work, Pigasus manages to fit everything into just 2MB of BRAM. This means it even has capacity to do more work in the MSPM stage than Snort itself does, reducing the amount of packets that need to be passed to the full matcher.
At the end of the day, a packet must match all the patterns in a signature for the rule to be triggered. The key insight in Pigasus is that some tests can be done very cheaply in terms of time and memory, while others are more memory intensive. Put this together with the realisation that most packets and most indices don’t match any rules at all and a plan emerges: make a filtering pipeline that progressively narrows. At the start of the pipeline we can afford to run lots of memory-cheap filters in parallel. Only a subset of incoming packets make it past these filters, so we need less of the more memory intensive filters running in parallel behind them to achieve the desired line rate.
Applying this filter first allows us to use fewer replicas of subsequent data structures (which are larger and more expensive), since most bytestream indices have already been filtered out by the string matcher. This enables high (effective) parallelism with a lower memory overhead.
This strategy is so effective that whereas Snort passes a packet to the full matcher if any filter matches, Pigasus is able to test for all string matches and further reduce the fraction of packets that head to the CPU for full-matching to just 5%. This testing is performed in parallel using a bloom-filter like representation, see §5.2 in the paper for details.
Headline results
Our experiments with a variety of traces show that Pigasus can support 100Gbps using an average of 5 cores and 1 FPGA, using 38x less power than a CPU-only approach.
There’s a full evaluation in §6 of the paper which I don’t have space to cover here. The headline is that Pigasus meets its design objectives using 23-200 fewer cores than Snort, and 18-62x less power!
The design of Pigasus is a singular proof point that a seemingly unattainable goal (…) on a single server is well within our grasp… Given the future hardware roadmaps of FPGAs and SmartNICs, we believe that our insights and successes can more broadly inform in-network acceleration beyond IDS/IPS as well.