
Bias in word embeddings, Papakyriakopoulos et al., FAT*’20
There are no (stochastic) parrots in this paper, but it does examine bias in word embeddings, and how that bias carries forward into models that are trained using them. There are definitely some dangers to be aware of here, but also some cause for hope as we also see that bias can be detected, measured, and mitigated.
…we want to provide a complete overview of bias in word embeddings: its detection in the embeddings, its diffusion in algorithms using the embeddings, and its mitigation at the embeddings level and at the level of the algorithm that uses them.
It’s been shown before (‘Man is to computer programmer as woman is to homemaker?’) that word embeddings contain bias. The dominant source of that bias is the input dataset itself, i.e. the text corpus that the embeddings are trained on. Bias in, bias out. David Hume put his finger on the fundamental issue at stake here back in 1737 when he wrote about the unjustified shift in stance from describing what is and is not to all of a sudden talking about what ought or ought not to be. The inputs to a machine learning model are a description of what is. If we train a model on them within thinking, the outputs of the model will treat what is as if it were what ought to be. We have made a sophisticated machine for reinforcing the status quo, warts and all.
When it comes to word embeddings this effect can be especially powerful because the embeddings isolate the words from the contexts in which they were originally used, leaving behind a static residue of bias:
…the projection of words in a mathematical space by the embeddings consolidates stereotyping and prejudice, assigning static properties to social groups and individuals. Relations are no longer context-dependent and dynamic, and embeddings become deterministic projections of the bias of the social world. This bias is diffused into further algorithms unchanged, resulting in socially discriminative decisions.
The authors proceed in the following manner:
- Firstly, they train one set of word embeddings based on the complete German wikipedia, and another set based on Facebook and Twitter content relating to the six main political parties in Germany. The training is done using GloVe. To be able to compare these word embeddings (by placing them both within the same vector space), they then find the linear transformation matrix that places all words from one into the vector space of the other with minimal translation. Since the translation is linear, the normalised distance between words does not change and hence any bias is preserved.
- They then measure bias in the trained embeddings
- Having demonstrated that the word embeddings do indeed contain bias, the next step is to see if a model trained using these word embeddings exhibits bias in its outputs (which they show it does).
- Given the resulting models does show bias, they then explore mechanisms for mitigating that bias at both the word embedding level and at the level of the final trained classifier.
- Finally, they show how biased word embeddings can actually help us to detect the same biases in new text samples (for example, the output of a language model?).
Measuring bias in word embeddings
Say we want to know whether a word embedding for a concept $c$ has a gender bias. We can take the cosine distance between $c$ and ‘Man’ and subtract the cosine distance between $c$ and ‘Woman’. A non-zero result reveals bias in one direction or the other, and the magnitude of the result tells us the amount of the bias. Since the study is done using the German language, which is gendered, concepts with male and female versions are represented by word pairs. This basic technique is used to assess bias in the trained word embeddings for professions, for Germans vs foreigners, and for homosexual vs heterosexual.
The results show that the trained vectors are more likely to associated women with professions such as nursing and secretarial work, whereas men are associated with roles such as policemen and commanders. Germans are linked to positive sentiments such as charm and passion, cooperation and union, while foreigners are generally linked to concepts such as immigration, law, and crime. Homosexuals are related to roles such as hairdresser or artist, and heterosexuals to blue collar professions and science. Homosexuality was associated with negative sentiments, and heterosexuality with positive ones.
Summaries of the most extremely biased words in both the Wikipedia and social media data sets are given in the tables below.
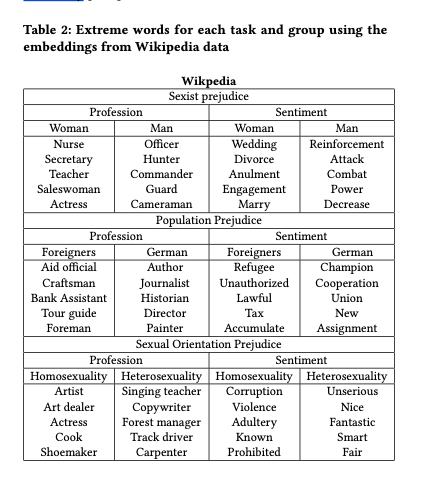
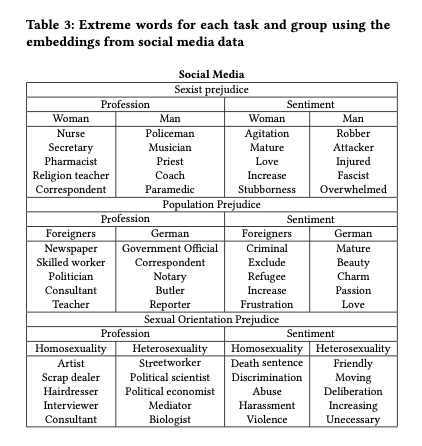
[the] results illustrate that word embeddings contain a high level of bias in them in terms of group stereotypes and prejudice. The intergroup comparison between sexes, populations, and sexual orientations revealed the existence of strong stereotypes and unbalanced evaluation of groups. Although Wikipedia contained a stronger bias in terms of stereotypes, social media contained a higher bias in terms of group prejudice.
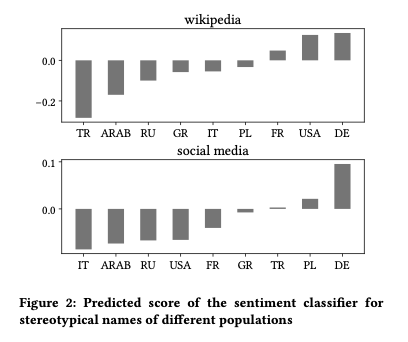
Do biased word embeddings lead to biased models?
The authors trained a model that took a word embedding as input and predicted whether that word has a positive or negative sentiment. To assess bias in the trained model, the authors fed names as inputs with the expectation that in the absence of bias, names should have a zero sentiment score as they are polarity independent. The chosen names were stereotypical first names for nine population groups: German, Turkish, Polish, Italian, Greek, French, US American, Russian, and Arabic. The authors also compared male and female names.
The study illustrated the use of biased word embeddings results in the creation of biased machine learning classifiers. Models trained on the embeddings replicate the preexisting bias. Bias diffusion was proved both for sexism and xenophobia, with sentiment classifiers assigning positive sentiments to Germans and negative sentiments to foreigners. In addition, the amount of polarity for men and women in the embeddings was diffused unaltered into the models.
Mitigating bias
The authors investigate two different methods for bias mitigation in the sentiment classifier:
- Removing bias at the individual word embedding level (by making theoretically neutral words orthogonal to the sentiment vector, where the sentiment vector is e.g. good – bad, positive – negative etc.).
- Removing bias at the level of the classifier by adjusting the linear hyperplane learned by the linear SVM classifier, such that this plane is orthogonal to the sentiment vector.
While both methods reduce bias in the resulting classifications, the classifier-level correction is much more effective, as can be seen in the following figure.
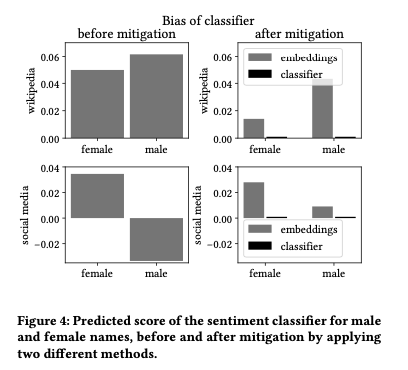
This is because correcting embeddings for a theoretically neutral set of words still leaves other potential biases in place that weren’t corrected for. The classifier is good at finding these!
…the classifier learns further associations between the vectors, which are not taken into consideration when debiasing at the embeddings level… Hence, we show that debiasing at the classifier level is a much better and safer methodology to follow.
Detecting bias in text
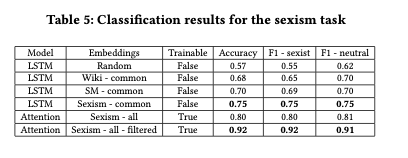
The authors created a dataset containing an equal number of sexist and non-sexist comments from Facebook pages of German political parties. Then they trained models with LSTM and attention-based architectures to classify comments as sexist or non-sexist. Multiple variants were trained, using random embeddings, the Wikipedia embeddings, the social media embeddings, and embeddings trained on the sexist comments.
The more similar the bias in the embeddings with the target data, the higher the ability of the classifier to detect them.
The attention-based network architecture, when given the sexism embeddings, allowed to freely retrain them, and tested on comments only containing words with embeddings, achieved an accuracy of 92%.
A call to action
The study showed that bias in word embeddings can result in algorithmic social discrimination, yielding negative inferences on specific social groups and individuals. Therefore, it is necessary not only to reflect on the related issues, but also to develop frameworks of action for the just use of word embeddings…
When it comes to generative language models, one possibility that strikes me is to use the model to generate a text corpus, train word embeddings on that corpus, and then analyse them for bias. Any detected bias could then be fed back into the language model training process as a form of negative reinforcement.