
 The NVIDIA Deep Learning Institute (DLI) released the Accelerated Data Science Teaching Kit, co-developed with Professor Polo Chau from Georgia Institute of Technology and Professor Xishuang Dong from Prairie View A&M University.
The NVIDIA Deep Learning Institute (DLI) released the Accelerated Data Science Teaching Kit, co-developed with Professor Polo Chau from Georgia Institute of Technology and Professor Xishuang Dong from Prairie View A&M University.
This week, the NVIDIA Deep Learning Institute (DLI) released the Accelerated Data Science Teaching Kit, co-developed with Professor Polo Chau from Georgia Institute of Technology and Professor Xishuang Dong from Prairie View A&M University.
The comprehensive teaching materials cover fundamental and advanced topics in data collection and pre-processing, accelerated data science with RAPIDS, scalable and distributed computing, GPU-accelerated machine learning, data visualization and graph analytics, and addresses the growing need of teaching data science skills to students in higher education and research institutions.
This first release includes focused modules covering:
- Introduction to Data Science and RAPIDS
- Data Collection and Pre-processing (ETL)
- Data Ethics and Bias in Data Sets
- Data Integration and Analytics
- Data Visualization
- Scalable and Distributed Computing with Hadoop, Hive and Spark
More modules are planned for future releases.
The kit also covers culturally-responsive topics such as fairness and data bias, as well as challenges and important figures from underrepresented groups.
Lecture slides and notes, hands-on labs, iPython notebooks, solutions (held in private repo), sample data sets, quiz/exam questions/answers, GPU compute resources via free AWS cloud credits, and free DLI online courses/certificates are all included. Lecture videos are planned for future releases.
The RAPIDS data science framework is a GPU-accelerated collection of libraries for executing end-to-end data science pipelines completely on the GPU. The primary objective behind using RAPIDS is to accelerate individual parts of the typical data science workflow, and thereby accelerating the complete end-to-end workflow in Data Preparation and Machine Learning.
One of the first Jupyter notebook-based labs has students dive right into RAPIDS using pandas and cuDF. Pandas is a data analysis and manipulation tool built on top of the Python programming language to perform various tasks (e.g.: loading, joining, aggregating, filtering data). cuDF is a RAPIDS-based GPU DataFrame library that helps perform similar functionalities with GPU acceleration.
Students are first tasked with understanding how to create DataFrame objects in cuDF, assigning values to those objects, and then calling methods and applying user-defined functions on the values. Once students have a grasp on working with cuDF DataFrames, they are tasked with creating one from a Netflix movie dataset from Kaggle.
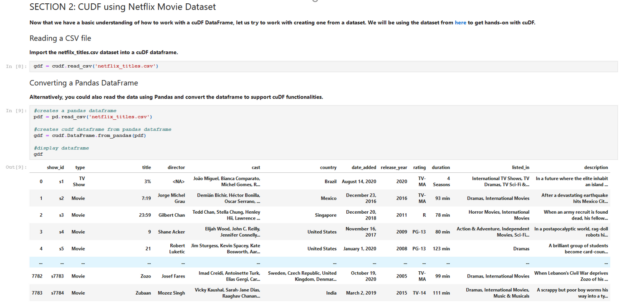
From there, students learn how to manipulate and interrogate the data, from dropping missing columns and values, querying, and finding unique values, to sorting, counting and grouping. The students will get a feel for how fast and easy it is by using RAPIDS and GPUs versus traditional methods also covered in the Teaching Kit. As a bonus task in the lab, students are finally asked to use cuDF One-hot encoding to convert the dataset’s movie and TV show titles to vectors of 0s and 1s to improve the accuracy of analyzing the data.
“Data Science unlocks the immense potential of data in solving societal challenges and large-scale complex problems across virtually every domain, from business, technology, science, engineering, healthcare, to government, and many more,” said Professor Polo Chau. “As data continues to grow in volume, velocity and complexity, there is an ever-increasing demand for data science talent and skill sets to help design the best solutions.”
This is the fourth Teaching Kit as part of the existing program of 7,000 qualified educators.
Get started with NVIDIA Teaching Kits >>