
Understanding generalization is one of the fundamental unsolved problems in deep learning. Why does optimizing a model on a finite set of training data lead to good performance on a held-out test set? This problem has been studied extensively in machine learning, with a rich history going back more than 50 years. There are now many mathematical tools that help researchers understand generalization in certain models. Unfortunately, most of these existing theories fail when applied to modern deep networks — they are both vacuous and non-predictive in realistic settings. This gap between theory and practice is largest for overparameterized models, which in theory have the capacity to overfit their train sets, but often do not in practice.
In “The Deep Bootstrap Framework: Good Online Learners are Good Offline Generalizers”, accepted at ICLR 2021, we present a new framework for approaching this problem by connecting generalization to the field of online optimization. In a typical setting, a model trains on a finite set of samples, which are reused for multiple epochs. But in online optimization, the model has access to an infinite stream of samples, and can be iteratively updated while processing this stream. In this work, we find that models that train quickly on infinite data are the same models that generalize well if they are instead trained on finite data. This connection brings new perspectives on design choices in practice, and lays a roadmap for understanding generalization from a theoretical perspective.
The Deep Bootstrap Framework
The main idea of the Deep Bootstrap framework is to compare the real world, where there is finite training data, to an “ideal world”, where there is infinite data. We define these as:
- Real World (N, T): Train a model on N train samples from a distribution, for T minibatch stochastic gradient descent (SGD) steps, re-using the same N samples in multiple epochs, as usual. This corresponds to running SGD on the empirical loss (loss on training data), and is the standard training procedure in supervised learning.
- Ideal World (T): Train the same model for T steps, but use fresh samples from the distribution in each SGD step. That is, we run the exact same training code (same optimizer, learning-rates, batch-size, etc.), but sample a fresh train set in each epoch instead of reusing samples. In this ideal world setting, with an effectively infinite “train set”, there is no difference between train error and test error.
 |
| Test soft-error for ideal world and real world during SGD iterations for ResNet-18 architecture. We see that the two errors are similar. |
A priori, one might expect the real and ideal worlds may have nothing to do with each other, since in the real world the model sees a finite number of examples from the distribution while in the ideal world the model sees the whole distribution. But in practice, we found that the real and ideal models actually have similar test error.
In order to quantify this observation, we simulated an ideal world setting by creating a new dataset, which we call CIFAR-5m. We trained a generative model on CIFAR-10, which we then used to generate ~6 million images. The scale of the dataset was chosen to ensure that it is “virtually infinite” from the model’s perspective, so that the model never resamples the same data. That is, in the ideal world, the model sees an entirely fresh set of samples.
 |
| Samples from CIFAR-5m |
The figure below presents the test error of several models, comparing their performance when trained on CIFAR-5m data in the real world setting (i.e., re-used data) and the ideal world (“fresh” data). The solid blue line shows a ResNet model in the real world, trained on 50K samples for 100 epochs with standard CIFAR-10 hyperparameters. The dashed blue line shows the corresponding model in the ideal world, trained on 5 million samples in a single pass. Surprisingly, these worlds have very similar test error — the model in some sense “doesn’t care” whether it sees re-used samples or fresh ones.
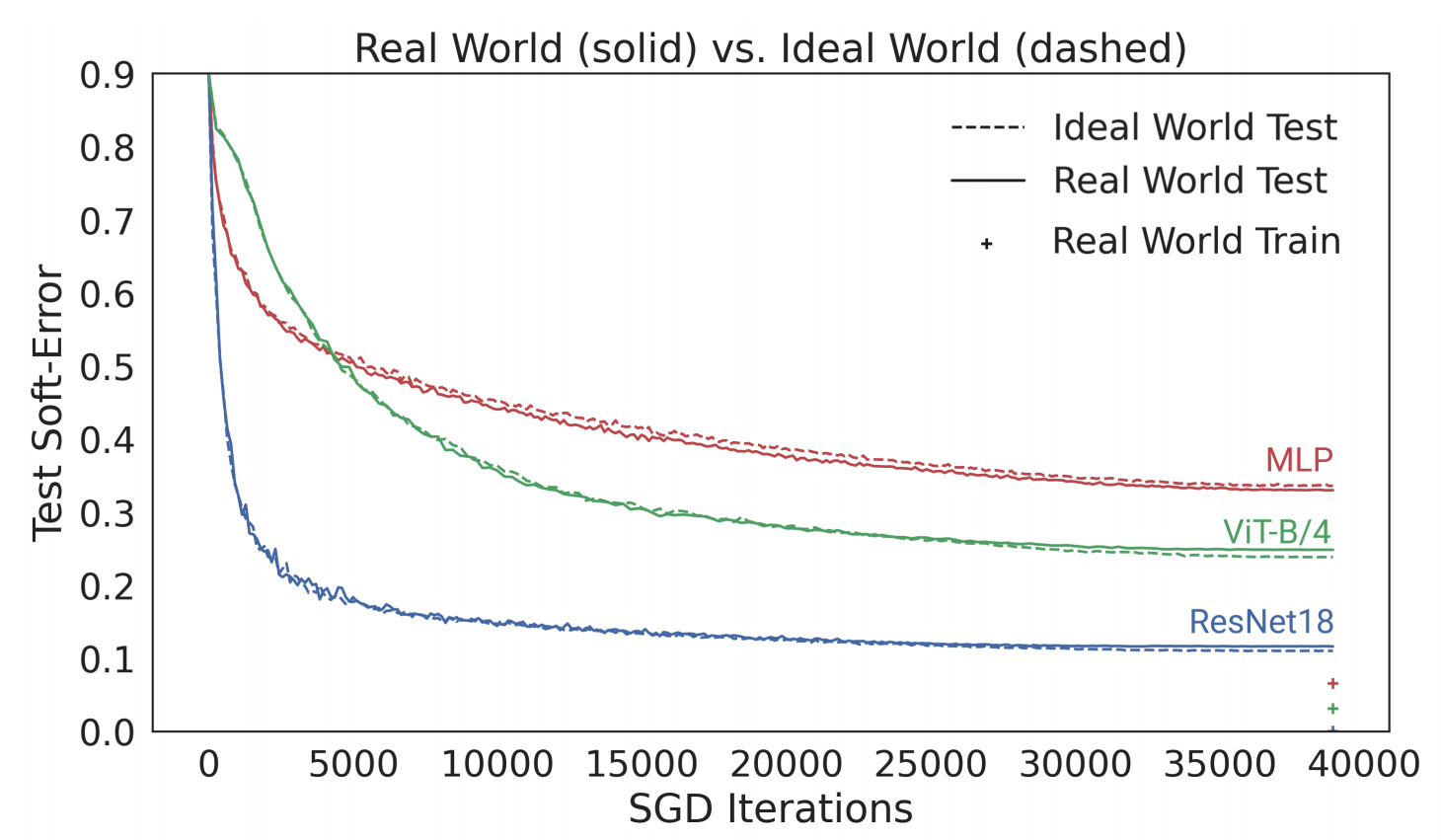 |
| The real world model is trained on 50K samples for 100 epochs, and the ideal world model is trained on 5M samples for a single epoch. The lines show the test error vs. the number of SGD steps. |
This also holds for other architectures, e.g., a Multi-Layer-Perceptron (red), a Vision Transformer (green), and across many other settings of architecture, optimizer, data distribution, and sample size. These experiments suggest a new perspective on generalization: models that optimize quickly (on infinite data), generalize well (on finite data). For example, the ResNet model generalizes better than the MLP model on finite data, but this is “because” it optimizes faster even on infinite data.
Understanding Generalization from Optimization Behavior
The key observation is that real world and ideal world models remain close, in test error, for all timesteps, until the real world converges (< 1% train error). Thus, one can study models in the real world by studying their corresponding behavior in the ideal world.
This means that the generalization of the model can be understood in terms of its optimization performance under two frameworks:
- Online Optimization: How fast the ideal world test error decreases
- Offline Optimization: How fast the real world train error converges
Thus, to study generalization, we can equivalently study the two terms above, which can be conceptually simpler, since they only involve optimization concerns. Based on this observation, good models and training procedures are those that (1) optimize quickly in the ideal world and (2) do not optimize too quickly in the real world.
All design choices in deep learning can be viewed through their effect on these two terms. For example, some advances like convolutions, skip-connections, and pre–training help primarily by accelerating ideal world optimization, while other advances like regularization and data-augmentation help primarily by decelerating real world optimization.
Applying the Deep Bootstrap Framework
Researchers can use the Deep Bootstrap framework to study and guide design choices in deep learning. The principle is: whenever one makes a change that affects generalization in the real world (the architecture, learning-rate, etc.), one should consider its effect on (1) the ideal world optimization of test error (faster is better) and (2) the real world optimization of train error (slower is better).
For example, pre-training is often used in practice to help generalization of models in small-data regimes. However, the reason that pre-training helps remains poorly understood. One can study this using the Deep Bootstrap framework by looking at the effect of pre-training on terms (1) and (2) above. We find that the primary effect of pre-training is to improve the ideal world optimization (1) — pre-training turns the network into a “fast learner” for online optimization. The improved generalization of pretrained models is thus almost exactly captured by their improved optimization in the ideal world. The figure below shows this for Vision-Transformers (ViT) trained on CIFAR-10, comparing training from scratch vs. pre-training on ImageNet.
 |
| Effect of pre-training — pre-trained ViTs optimize faster in the ideal world. |
One can also study data-augmentation using this framework. Data-augmentation in the ideal world corresponds to augmenting each fresh sample once, as opposed to augmenting the same sample multiple times. This framework implies that good data-augmentations are those that (1) do not significantly harm ideal world optimization (i.e., augmented samples don’t look too “out of distribution”) or (2) inhibit real world optimization speed (so the real world takes longer to fit its train set).
The main benefit of data-augmentation is through the second term, prolonging the real world optimization time. As for the first term, some aggressive data augmentations (mixup/cutout) can actually harm the ideal world, but this effect is dwarfed by the second term.
Concluding Thoughts
The Deep Bootstrap framework provides a new lens on generalization and empirical phenomena in deep learning. We are excited to see it applied to understand other aspects of deep learning in the future. It is especially interesting that generalization can be characterized via purely optimization considerations, which is in contrast to many prevailing approaches in theory. Crucially, we consider both online and offline optimization, which are individually insufficient, but that together determine generalization.
The Deep Bootstrap framework can also shed light on why deep learning is fairly robust to many design choices: many kinds of architectures, loss functions, optimizers, normalizations, and activation functions can generalize well. This framework suggests a unifying principle: that essentially any choice that works well in the online optimization setting will also generalize well in the offline setting.
Finally, modern neural networks can be either overparameterized (e.g., large networks trained on small data tasks) or underparmeterized (e.g., OpenAI’s GPT-3, Google’s T5, or Facebook’s ResNeXt WSL). The Deep Bootstrap framework implies that online optimization is a crucial factor to success in both regimes.
Acknowledgements
We are thankful to our co-author, Behnam Neyshabur, for his great contributions to the paper and valuable feedback on the blog. We thank Boaz Barak, Chenyang Yuan, and Chiyuan Zhang for helpful comments on the blog and paper.
