
 This post was originally published on the Mellanox blog in April 2020. People generally assume that faster network interconnects maximize endpoint performance. In this post, I examine the key factors and considerations when choosing the right speed for your leaf-spine data center network. To establish a common ground and terminology, Table 1 lists the five … Continued
This post was originally published on the Mellanox blog in April 2020. People generally assume that faster network interconnects maximize endpoint performance. In this post, I examine the key factors and considerations when choosing the right speed for your leaf-spine data center network. To establish a common ground and terminology, Table 1 lists the five … Continued
This post was originally published on the Mellanox blog in April 2020.
People generally assume that faster network interconnects maximize endpoint performance. In this post, I examine the key factors and considerations when choosing the right speed for your leaf-spine data center network.
To establish a common ground and terminology, Table 1 lists the five building blocks of a standard leaf-spine networking infrastructure.
| Building block | Role |
| Network interface card (NIC) | A gateway between the server (compute resource) and network. |
| Leaf switch/top-of-rack switch | The first connection from the NIC to the rest of the network. |
| Spine switch | The “highway” junctions, responsible for the east-west traffic. Its port capacity determines the number of required racks. |
| Cable | Connects the different devices in the network. |
| Optic transceiver | Allows longer distances of connectivity (above a few meters) between a leaf-to-spine switch by modulating the data into light that traverses the optic cable. |
I start by reviewing the trends in 2020 for data center leaf-spine networks deployments and describing the main ecosystem that lies behind it all. Figure 1 shows an overview of leaf-spine network connectivity. It is divided into two main connectivity parts, each of which takes different factors into consideration when picking the deployment rate:
- Switch-to-switch (applies also when using a level of super-spine)
- NIC-to-switch
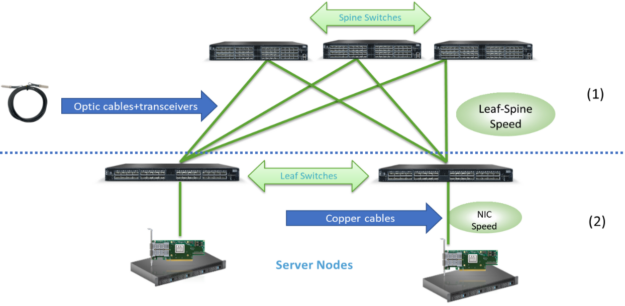
Together these parts comprise an ecosystem, which I now analyze in depth.
Switch-to-switch speed dynamics
New leaf-spine data center deployments in 2020 evolve around four IEEE approved speeds: 40, 100, 200, and 400GbE. There are different combinations of supported switches per speed. For example, constructing a network of 400GbE leaf-spine connectivity requires the network owner to pick switches and cables that can support those rates.
Like every other product in the world, each speed generation demonstrates a unique product life cycle (PLC), while each stage comes with its own attributes.
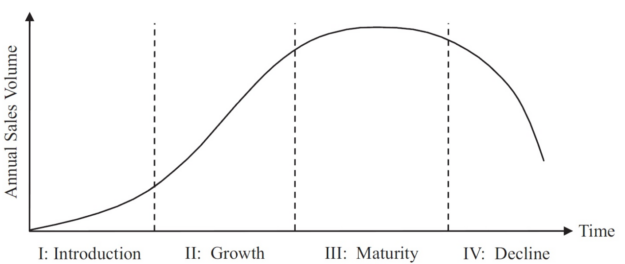
- Introduction—Product adoption is concentrated within a small group of innovators who are neither afraid to take risks nor suffer from birth pangs. In networking, these are usually the networking giants (also known as hyperscalers).
- Growth—Occurs as leaders and decision makers start adopting a new generation.
- Maturity—Characterized by the adoption of products by more conservative customers.
- Decline—A speed generation is used to connect legacy equipment.
The main questions that pop-up in my mind are, “Why do generations change?” and “What drives the ambition for faster switch-to-switch connectivity?” The answer for both is surprisingly simple: $MONEY$. When you constantly optimize your production process and, at the same time, allow bigger scale (bigger ASIC switching capacity), the result is lower connectivity costs.

This price reduction does not happen at once; it takes time to reach maturity. Hyperscalers can benefit from cost reduction even when a generation is in its Introduction stage, because being big allows them to get better prices (the economy of scale offers better buying power), often much lower than the manufacturer’s suggested retail price. In some sense, you could say that hyperscalers are paving the way for the rest of the market to use new generations.
Armed with this new knowledge, here’s some analysis.
Before focusing on the present, rewind a decade, back to 2010-11, when 10GbE was approaching maturity and the industry was hyped about transitioning from a 10 to 100GbE switch-to-switch speed. At the time, the 100GbE leaf-spine ecosystem had many caveats, including that 100GbE NRZ technology spine switches did not have the right radix for scale, providing only 12 ports of 100GbE in a spine switch, meaning only 12 racks could have been connected in a leaf-spine cluster.
Also, at the same time, 40GbE switch-to-switch connectivity started to gain traction even though it was slower, due to mature SerDes technology, a reliable ASIC process, better scale, and lower overall cost for most of the market.
Put yourself in the shoes of a decision maker who needs to deploy a new cluster in 2011: what switch-to-switch speed would you pick? Hard dilemma, right? Fortunately, as it was a decade ago, we have since accumulated lots of data about what happened. Take a moment to analyze Figure 3. The 10/40GbE generation is a perfect example for a PLC curve.
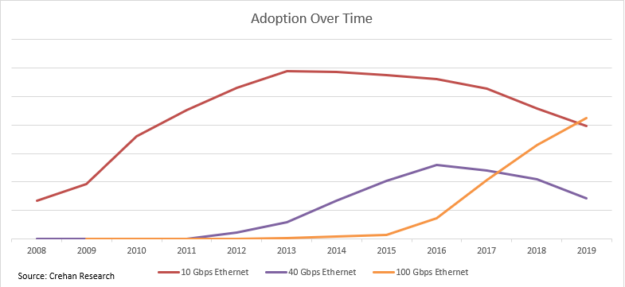
Beginning in 2011 until 2015, most of the industry picked 40GbE as its leaf-spine network speed. When asked in retrospect about the benefits of 40GbE, businesses typically mention improved application performance and better ROI. Only at the end of 2015, roughly four years after the advent of 40GbE, did the 100GbE leaf-spine ecosystem begin its rise and be seen as reliable and cost-effective. Some deployments did benefit from 100GbE, since picking “the latest and the greatest” would fit some use cases, even at higher prices.
Fast forward to 2020
New data center deployments enjoy a set of wonderful new options of switch-to-switch rates to pick from, starting from 40GbE to 400GbE. Most of the current deployments are using 100GbE connections, which is mature at this point. With the continuous drive to lower costs, the demand for faster network speeds isn’t easing up, as newer technologies of 200GbE and 400GbE are deployed. Figure 4 presents the attributes currently associated with each switch-to-switch speed generation.
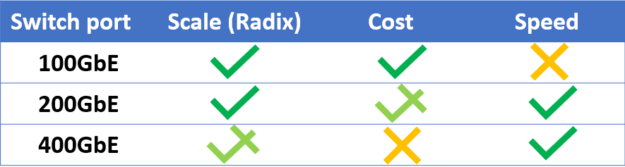
You can conclude that each generation has its own pros and cons and picking one should be based on your personal preferences. Now I explain the dynamics taking place in the data center speed ecosystem and try to answer which switch-to-switch speed generation fits you best: 100, 200, or 400GbE?
Dynamics between switch-to-switch speed and NIC-to-switch speed
As mentioned earlier, new switch-to-switch data center deployments in 2020 evolve around four IEEE approved speeds: 40, 100, 200, and 400GbE. Each one is at a different PLC stage (Table 2).
| switch-to-switch speed | switch-to-switch generation stage (2020) |
| 40GbE | Decline |
| 100GbE | Maturity |
| 200GbE | Growth |
| 400GbE | Introduction (with several years to reach growth, according to past leaps and current market trends) |
Let me share with you the reasons I view the market in this way. To begin with, 400GbE is the current latest and greatest. No doubt, it will take a major part of deployments in the future by offering the fastest connectivity, with a projected lowest cost per GbE. However, at the present, it still has not reached the required maturity to gain the associated benefits of commoditization.
A small number of hyperscalers—known for innovation, compute-intense applications, engineering capabilities, and most importantly, enjoying the economy of scale—are deploying clusters at that speed. To mitigate technical issues with 400GbE native connections, some have shifted to 2x200GbE or pure 200GbE deployments. The reason is that with 200GbE leaf-spine connections, hyperscalers can rely on a more resilient infrastructure, leveraging both cheaper optics and switch radix that allows for scaling a fabric.
At present, non-hyperscalers trying to move to 400GbE switch-to-switch connectivity may come to realize that the cables and transceivers are still expensive and produced in low volumes. Moreover, the 7nm ASIC process for creating high-capacity switches is not optimized.
At the opposite side of the curve lies the 40GbE, which is a generation in decline. You should consider 40GbE if you are deploying a legacy cluster, with legacy equipment that cannot work at faster speeds.
Most of the market is not being caught up in the hype and doesn’t waste money on unnecessary bandwidth. It is focused on the 100GbE mature ecosystem. Because it exhibits textbook characteristics when it comes to cost reduction, market availability and reliability means that the 100GbE is not going away. It is here to stay.
This is a great opportunity to mention the other part of the story: the NIC-to-switch speed. At this point, it might seem that they co-exist orthogonally, but in fact they are entwined and affect one another.
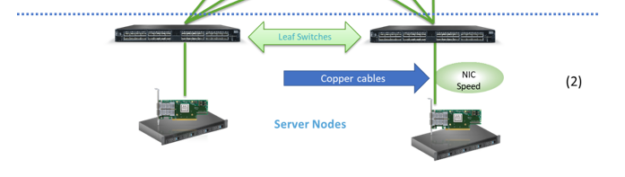
Whether your application is in the field of intense compute, storage, or AI, the NIC is the heart of it. In practice, the NIC speed determines the optimal choice of the surrounding network infrastructure, as it connects your compute and storage to the network. When deciding the switch-to-switch speed to pick, also consider what kind of traffic, generated from the compute nodes, is going to run between the switches. Different applications have different traffic patterns. Nowadays, most of the traffic in a data center is east-west traffic, from one NIC to another.
To get the best application performance, opt for a leaf switch that has the appropriate blocking factor (optimally non-blocking at all) to avoid congestion, by deploying enough uplink and downlink ports.
Data center deployments frequently use NICs at one of the following speeds:
- 10GbE (NRZ)
- 25GbE (NRZ)
- 50GbE (PAM-4)
- 100GbE (PAM-4)
There are also 50GbE and 100GbE NRZ NICs, but they are less common.
This is where the complete ecosystem builds up, the point where switch-to-switch and NIC-to-switch complement each other. After reviewing dozens of different data center deployments, I noticed that there is a clear pattern when it comes to overall costs, regarding choosing a switch-to-switch speed when considering also the NIC-to-switch speed-of-choice. The math just works that way. There is an optimal point where a specific switch-to-switch speed generation allows the NIC-to-switch speed to maximize application performance, both in terms of bandwidth utilization and ROI.
Take into consideration the application, wanted blocking factor, and price per GbE. If your choice is based on the NIC speed, you would probably want to use the switch-to-switch speed, as shown in Table 3.
| NIC port speed | Possible use case (2020) | Recommended switch-to-switch speed |
| 100GbE PAM-4 | Hyperscalers, innovators | 200/400GbE |
| 50GbE PAM-4 | Hyperscalers, innovators, AI, advanced storage applications, public cloud | 200/400GbE |
| 25GbE NRZ | Enterprises, private cloud, HCI, edge | 100GbE |
| 10GbE NRZ | Legacy | 40GbE |
50/100GbE NRZ act the same as 25GbE NRZ economically.
Of course, other combinations might be better, depending on the prices you get from your vendor, but on average, this is how I view the market.
Here are some important takeaways:
- Lower the cost per GbE, the switch-to-switch speed is always increasing. A new generation is introduced every several years.
- When picking according to the NIC-to-switch speed, consider the projected traffic patterns and the necessary blocking pattern from the leaf-switch.
- Data center maturity is determined from the maturity of both switch-to-switch and NIC-to-switch speeds.
Along comes 200GbE
If you’ve made it this far, then you must have realized that 200GbE leaf-spine speed is also an option to consider.
In December 2017, the IEEE approved a standard that contains the specifications for 200 and 400GbE. As discussed earlier, a small number of hyperscalers are upgrading their deployment from 100GbE to 400GbE directly. Practically speaking, the industry acknowledged that the 200GbE can serve as an intermediate step, like the transition between 10 to 100GbE, in which 40GbE served as an intermediate step.
So, what’s in it for you?
200GbE switch-to-switch deployments enjoy a comprehensive set of benefits:
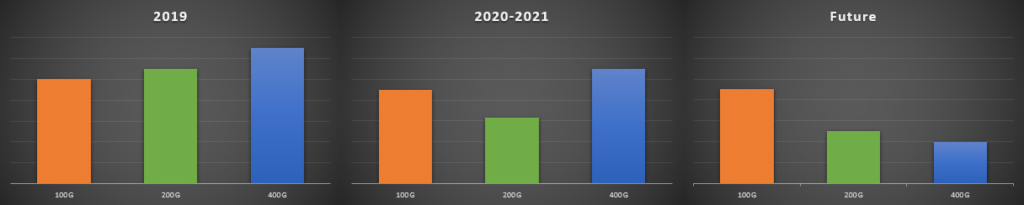
- Increased ROI by doubling the bandwidth using a ready-to-deploy ecosystem (NIC, Switch, Cable & Transceiver) with an economical premium over 100GbE. The cost analysis just makes sense, providing the lowest price per GbE (Figure 6).
- The next generation of switch and NIC ASICs, with an improved feature set, including enhanced telemetry.
- A reduced cable footprint, to avoid signal integrity problems and cable crosstalk in a high-density front panel 100GbE switch compared to half the number of ports in a 200GbE switch.
- 200G is a native rate of InfiniBand (IB). Leading the IB market in supplying switches, NICs and cables/transceivers, NVIDIA has proven this technology mature, by providing over 1M ports of 200G, reaching economy of scale and optimizing price. The NVIDIA 200GbE supporting devices (NICs, cables, and transceivers) are shared between IB and Ethernet.
In preparation for the 200/400GbE era, NVIDIA has optimized its 200GbE switch portfolio. It allows the fabric to scale the radix with better ROI than 400GbE, by using a 64×200(12.8Tbps) spine and 12×200+48×50(6.4Tbps) as a non-blocking leaf switch.
When you consider the competition, NVIDIA offers an optimized non-blocking leaf switch (top-of-rack) for 50 G PAM-4 NICs.
NVIDIA Spectrum-2 based platforms provide a capacity of 6.4 Tb, 50 G PAM-4 SerDes and a feature set that complies with the virtualized data center environment.
Using a competitor’s 12.8TbE switch as a leaf switch is just overkill for today’s deployments because the majority of top-of-rack switches have 48 downlink ports of 50GbE. By doing the math to get to a non-blocking ratio, the switches need 6 ports of 400 or 12 ports of 200GbE, resulting in a total of 4.8TbE. There is no added value to paying for unused switching capacity.
By the way, NVIDIA offers a 200GbE development kit for people who want to take the SN3700 Ethernet switch for a test drive.
Summary
Deploying or upgrading a data center in 2020? Make sure to take into consideration the following:
- The market is dynamic, and past trends may assist you in predicting future ones
- Select your switch-to-switch and NIC-to-switch speed according to your requirements
- 200GbE holds massive benefits
Disagree with the need for 200GbE, or anything else in this post? Feel free to reach out to me. I would love to have a discussion with you.