
 NVIDIA announced its latest update to the HPL-AI Benchmark version 2.0.0, which will reside in the HPC-Benchmarks container version 21.4.
NVIDIA announced its latest update to the HPL-AI Benchmark version 2.0.0, which will reside in the HPC-Benchmarks container version 21.4.
NVIDIA announced its latest update to the HPL-AI Benchmark version 2.0.0, which will reside in the HPC-Benchmarks container version 21.4. The HPL-AI (High Performance Linpack – Artificial Intelligence) benchmark helps evaluate the convergence of HPC and data-driven AI workloads.
Historically, HPC workloads are benchmarked at double-precision, representing the accuracy requirements in computational astrophysics, computational fluid dynamics, nuclear engineering, and quantum computing. AI workloads on the other hand can deliver acceptable results using much lower precision for training and inference. This distinctive characteristic led to the development of technology such as the Tensor Cores. Tensor Cores provide substantial speedups in mixed-precision workloads by accelerating precisions such as TF32, BF16, FP16, INT8, and INT4.
Many vendors provide specially tuned versions of HPL for their hardware. NVIDIA is releasing the NVIDIA HPC-Benchmarks container on NGC. This container includes three different versions of the HPL benchmark for double precision arithmetic; HPL-AI, applied to mixed precision workloads, and HPCG, which performs a fixed number of multigrid preconditioned conjugate gradient (PCG) iterations at double precision.
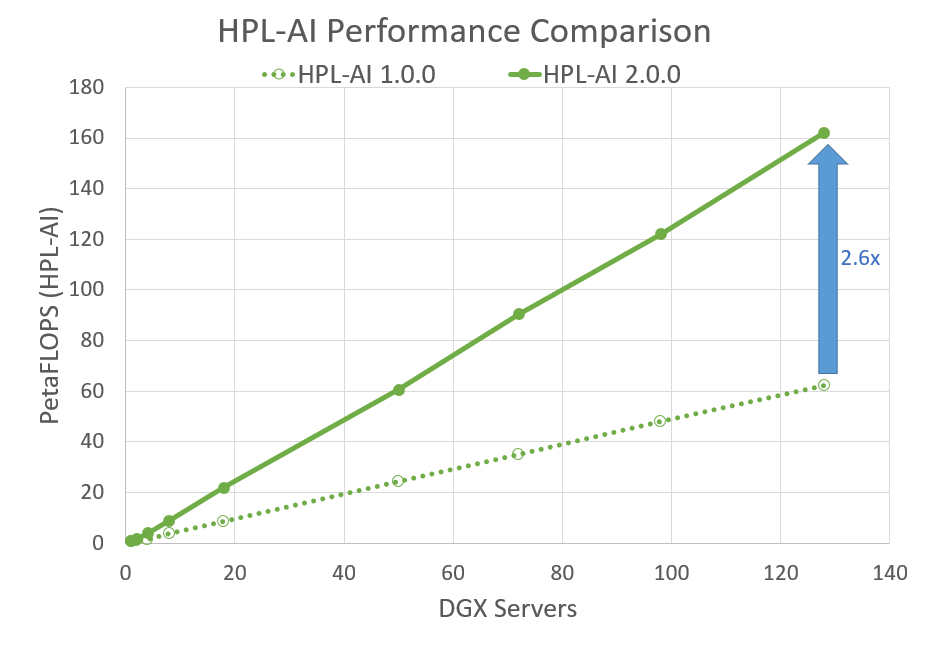
With this latest release, the HPL-AI benchmark deliveries double the performance over the initial container released in Fall 2020. This is largely due to major improvements to load balancing at the communication layers. Multi-node communications are usually handled by the CPU, which can lead to performance bottlenecks if GPU become idle. MPI-aware communication between GPUs allows the CPU to be bypassed and keep the GPU busy. When possible data transfers are sent at a lower precision reducing the time GPUs are waiting for data. After minimizing communication, GPUs can process larger datasets to provide maximum compute efficiency. Lastly, the latest version of the NVIDIA Math Libraries are used to deliver optimal performance on an A100.
The plot below shows that with 128 DGX A100s, or 1024 NVIDIA A100 GPUs, the latest release of HPL-AI performs 2.6 times faster.
To checkout these improvements, download the latest NVIDIA HPC-Benchmark container, version 21.4, from NGC. The HPC-Benchmark landing page includes detailed instructions and additional resources. If you have any questions or issues, please send email to HPCBenchmarks@nvidia.com.