
 Introduction In part 1 of this blog series, we introduced The GA360 SQL Knowledge Graph that timbr has created, acting as a user-friendly strategic tool that shortens time to value. We discussed how users can conveniently connect GA360 exports to BigQuery in no time with the use of an SQL Ontology Template, which allows users … Continued
Introduction In part 1 of this blog series, we introduced The GA360 SQL Knowledge Graph that timbr has created, acting as a user-friendly strategic tool that shortens time to value. We discussed how users can conveniently connect GA360 exports to BigQuery in no time with the use of an SQL Ontology Template, which allows users … Continued
Introduction
In part 1 of this blog series, we introduced The GA360 SQL Knowledge Graph that timbr has created, acting as a user-friendly strategic tool that shortens time to value. We discussed how users can conveniently connect GA360 exports to BigQuery in no time with the use of an SQL Ontology Template, which allows users to understand, explore and query the data by means of concepts, instead of dealing with many tables and columns. In addition to the many features and capabilities the GA360 SQL Knowledge Graph has to offer, we touched on the fact that the knowledge graph, queryable in SQL is empowered with graph algorithms.
In this second part of our blog series, we take a deep dive into the use of graph algorithms with our GA360 SQL Knowledge Graph. We do so with RAPIDS cuGraph created by NVIDIA, a collection of powerful graph algorithms implemented over NVIDIA GPUs, leveraging our ability to analyze data at unmatched speeds.

RAPIDS cuGraph is paving the way in the graph world with multi-GPU graph analytics, allowing users to scale to billion and even trillion scale graphs, with performance speeds never seen before. cuGraph is equipped with many graph algorithms, falling into the following classes: Centrality, Community, Components, Core, Layout, Linear Assignment, Link Analysis, Link Prediction, Traversal, Structure, and other unique algorithms.
As there is a large rise in interest among companies to improve their analytics and boost their performance, many companies are turning to different graph options to get more out of their data. One of the main things holding companies back is the different implementation costs and barriers of adoption of these new technologies. Learning new languages to connect between your existing data infrastructure and new graph technologies is not only a headache but also a large expense.
This is where timbr comes into the picture. Timbr dramatically reduces implementation costs, as it does not require companies to transfer data or learn new languages. Instead, timbr acts as a virtual layer over the company’s existing data infrastructure, turning simple columns and tables into an easily accessible knowledge graph empowered with tools for exploration, visualization, and querying of data using graph algorithms. This is all delivered in a semantic SQL familiar to every analyst.
In the blog post, we demonstrate the power of RAPIDS cuGraph combined with timbr by applying the Louvain Community Detection Algorithm as well as the Jaccard Similarity Algorithm on The GA360 SQL Knowledge Graph.
The Louvain Community Detection Algorithm
The Louvain community detection algorithm is used for detecting communities in large networks with a high density of connections, helping us uncover the different connections in a network.
In order to understand the connections and be able to quantify their strength, we use what’s called modularity. Modularity is used to measure the strength of a partitioning of a graph into groups, clusters or communities, by constructing a score representing the modularity of a particular partitioning. The higher the modularity score, the denser the connections between the nodes in that community.
Community detection is used today in many industries for many different reasons. The banking industry uses community detection for fraud analysis to find anomalies and evaluate whether a group has just a few discrete bad behaviors or is acting as a fraud ring. The health industry uses community detection to investigate different biological networks to identify various disease modules. The stock market uses community detection to build portfolios based on the correlation of stock prices.
So, with the many different uses of community detection that exist today, what can be done with community detection when it comes to Google Analytics? And how will it function when being used with RAPIDS cuGraph in comparison to the standard CPU in the form of NetworkX.
Let’s take a look:
After connecting our Google Analytics knowledge graph to cuGraph, we began with our first query requesting to see all the products purchased, allocated to their specific communities based on the customers who purchased these products. To run this query we used the gtimbr schema, which is timbr’s virtual schema for running graph algorithms. For the algorithm, we used the Louvain algorithm for community detection.
Here is the exact query that was used:
SELECT id as productsku, community FROM gtimbr.louvain( SELECT distinct productsku, info_of[hits].has_session[ga_sessions].fullvisitorid FROM dtimbr.product )
To understand the difference in performance when running this algorithm query, we tested running this query with cuGraph and then ran it again using NetworkX.
Here are the performance difference:
cuGraph vs NetworkX Performance Speeds
| NetworkX | RAPIDS cuGraph | ||
| Performance Speed | 5 seconds | 0.04 seconds |
After running the query, we received a list of 982 products, each product belonging to a community ID.
Having a large list of products, we needed to understand how many communities we were dealing with, so we ran the following query:
SELECT community, count(productsku) as number_of_products FROM dtimbr.product_community GROUP BY community ORDER BY 1 asc
There were our results:
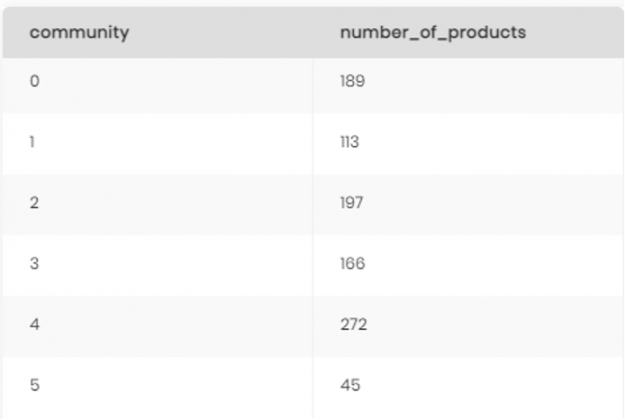
It was pretty clear from our results that having 982 products represented by just 6 communities makes it hard to understand the connections between the different products and customers. To resolve this, we decided to drill down into each community and create sub-communities to really highlight which products belong with which customers.
The first step was to simply create a new concept in the knowledge graph called product_community and map the data to it from our first query showing each of the 982 products and the community they belong to.
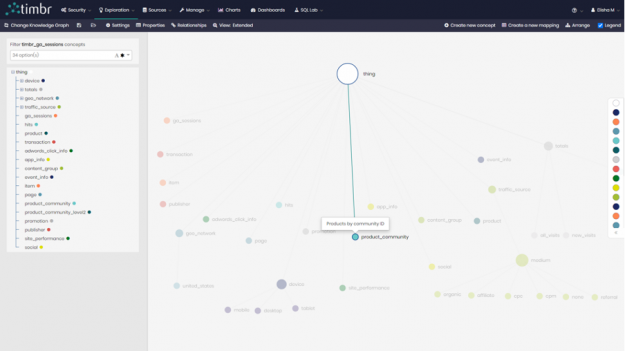
product_community concept in the Knowledge Graph model.Mapping the data was then performed in simple SQL, similar to the syntax used when creating and mapping data with tables and columns in relational databases, and looked as follows:
CREATE OR REPLACE MAPPING map_product_community into product_community AS
SELECT id as productsku, community
FROM gtimbr.louvain(
SELECT distinct productsku, info_of[hits].has_session[ga_sessions].fullvisitorid
FROM dtimbr.product )Now that we had a concept representing our products by the community, we created a second concept called product_community_level2 to represent the sub-communities of our original 6 communities.
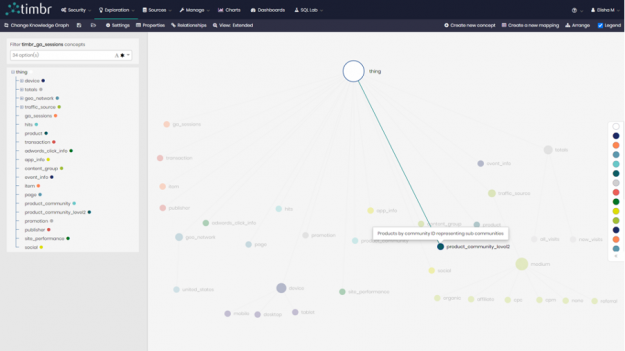
To create the sub-communities for our new concept we created a new mapping for each of the 6 original communities. So for example, here is the new mapping to present the sub-communities for community ID “0”:
CREATE OR REPLACE MAPPING map_product_community_level2_0 into product_community_level2 AS
SELECT id as productsku, community, 0 as parent_community
FROM gtimbr.louvain(
SELECT distinct productsku, `info_of[hits].has_session[ga_sessions].fullvisitorid`
FROM dtimbr.product
WHERE productsku IN (SELECT distinct productsku
FROM dtimbr.product_community
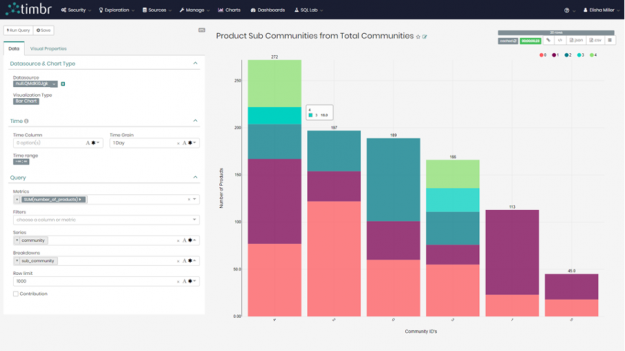
WHERE community = 0))Once we queried and mapped the data of all the sub-communities to the new concept, we decided to view the results in our built-in BI Tool and created the following bar chart where we can clearly see the breakdown of the sub-communities for each of the original 6 communities:
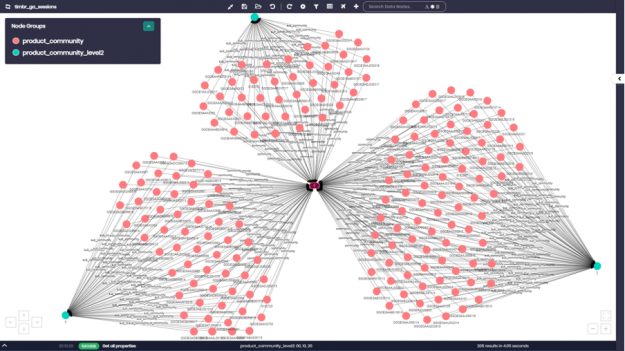
Lastly, we want to view the communities and sub-communities with all their products using timbr’s data explorer. We entered the concepts with the specific communities we wanted and asked to see their products. In this case, we asked for community numbers 0,1, and 4 as well as their sub-communities showing us products by sub-community within the larger community.
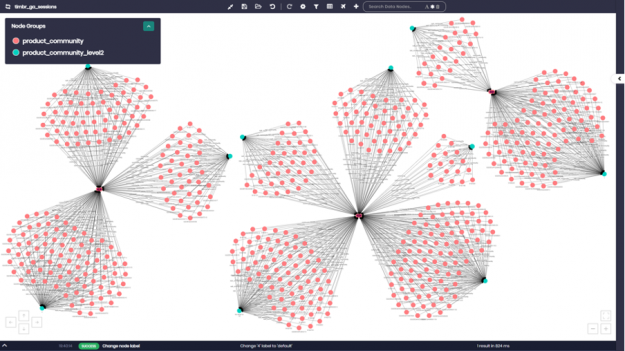
If we zoom in for example on community ID number “0”, we can see all the different product numbers appearing as pink nodes. Each product number is connected to the different sub-community that it belongs to, which appear as light blue nodes on the graph.
Link Prediction using Jaccard Similarity Algorithm
A variety of Similarity Algorithms are used today, algorithms such as Jaccard, Cosine, Pearson, Overlap, and others. In our GA Knowledge Graph, we demonstrate the use of the Jaccard similarity with an emphasis on link prediction.
The Jaccard similarity algorithm examines the similarity between different pairs and sets of items, whether it be people, products, or anything else. When using the similarity algorithm, we become exposed to connections between different pairs of people or items that we would have never been able to identify without the use of this unique algorithm.
The use of link prediction with similarity acts as a recommendation algorithm, which extends the idea of linkage measure to a recommendation in a bipartite network. In our case, a bipartite is a network of products and customers.
The Similarity Algorithm and link prediction are used today in many different use cases. Social networks use this algorithm for many different uses, including making recommendations to users regarding who to connect with based on similar relationships and connections, to deciding what advertisements to post for which users based on common interests with other users, all the way to offering a user a product based on the fact that the similarity algorithm matched him with a different user who bought that same product, which we will touch on shortly.
Governments use the algorithm to compare populations. Scientists use the algorithm to discover connections between different biological components, enabling them to safely develop new drugs, all the way to companies using the algorithm to advance their machine learning efforts and link prediction analysis.
So, now let’s apply similarity and link prediction in our Google Analytics Knowledge Graph empowered by NVIDIA’s cuGraph and witness its strength.
We began by creating a relationship called similar in our concept ga_sessions, a concept which contains data about all the sessions and visits of users to our website. Unlike in our example earlier on community detection, where we created a relationship between two concepts in our knowledge graph, here we decided to create a relationship between `ga_sessions` and itself, where the relationship would calculate the similarity between customers that searched for more than 1 similar keyword.
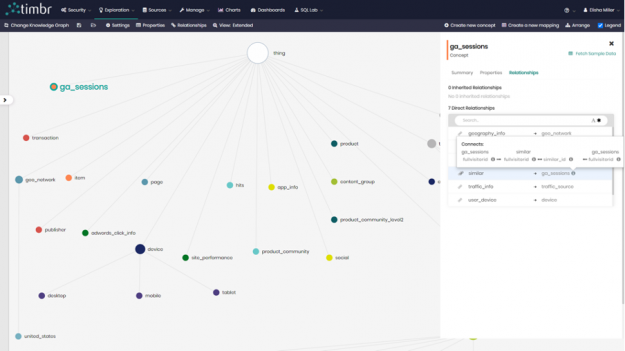
Once the relationship was created, it was time to map the data to the relationship. timbr allows us to not only map data to concepts but also to map data directly to relationships and extend them with their own properties (thus building a Property Graph).
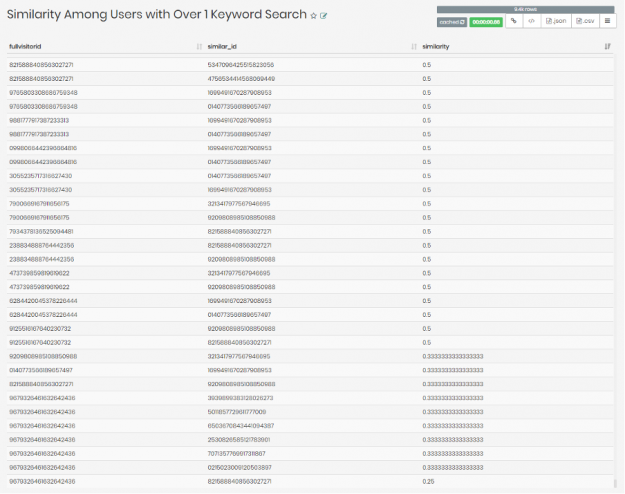
The query we ran give us the similarity between customers that searched for more than 1 similar keyword, which we later mapped to our relationship similar in ga_session went as follows:
SELECT id as fullvisitorid, similar_id as similarid, similarity
FROM gtimbr.jaccard(
SELECT `has_session[ga_sessions].fullvisitorid`, keyword
FROM dtimbr.traffic_source
WHERE `has_session[ga_sessions].fullvisitorid` in (
-- Users that searched more than 1 keyword
SELECT distinct `has_session[ga_sessions].fullvisitorid` as id
FROM dtimbr.traffic_source
WHERE keyword IS NOT NULL AND keyword != '(not provided)'
GROUP BY `has_session[ga_sessions].fullvisitorid`
HAVING count(1) > 1)
AND keyword IS NOT NULL AND keyword != '(not provided)')
Once again, we compared the performance speeds running this algorithm query with cuGraph and NetworkX and received the following results:
cuGraph vs NetworkX Performance Speeds
| NetworkX | RAPIDS cuGraph | ||
| Performance Speed | 24 seconds | 0.04 seconds | [1] |
In the query, we asked for the fullvisitorid which is the user ID, the similar_id which returns IDs of similar users, as well as similarity which returns a Jaccard similarity score for each match of user IDs.
These were the results:
Next, we wanted to create a visualization using our similar relationship that we have created. We wrote the following query to do so:
SELECT DISTINCT `fullvisitorid` AS user_id,
`similar[ga_sessions].fullvisitorid` AS similar_user_id,
`similar[ga_sessions]_similarity` AS similarity
FROM dtimbr.ga_sessions
WHERE `similar[ga_sessions].fullvisitorid` IS NOT NULL
Now that we had all the visitor IDs and similar visitor ID’s that had more than 1 similar keyword, as well as _similarity where the underline before similarity represents the similarity score in the relationship, we were ready to visualize the results.
We decided to choose the Sankey Diagram to represent our findings.
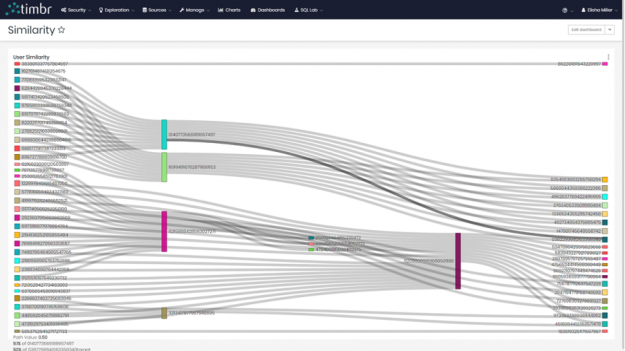
We were able to see the different users on the left and right side connecting to their similar match in the middle. Many of these users both in the middle and on the sides connected to multiple users.
Combining the community and similarity algorithms
In our final example, we decided to build a recommendation query combing the relationships we’ve created for our community and similarity algorithms.
Here is the recommendation query:
SELECT similar[ga_sessions].has_hits[hits].ecommerce_product_data[product].productsku as productsku,
similar[ga_sessions].has_hits[hits].ecommerce_product_data[product].in_community[product_community].community AS community,
COUNT(distinct similar[ga_sessions].fullvisitorid) num_of_users
FROM dtimbr.ga_sessions
WHERE fullvisitorid = '9209808985108850988'
AND similar[ga_sessions].has_hits[hits].ecommerce_product_data[product].productsku is not null
GROUP BY similar[ga_sessions].has_hits[hits].ecommerce_product_data[product].productsku, similar[ga_sessions].has_hits[hits].ecommerce_product_data[product].in_community[product_community].community
ORDER BY num_of_users DESC
What we did in this query, is we choose to focus on a random visitor with ID number ‘9209808985108850988’. We wanted the query to recommend products for our chosen user based on similar users who bought the recommended products. In order to gain more insight, we decided to ask for the communities that the recommended products belong to and see if there are any visible trends.
After running the query, the following results returned:
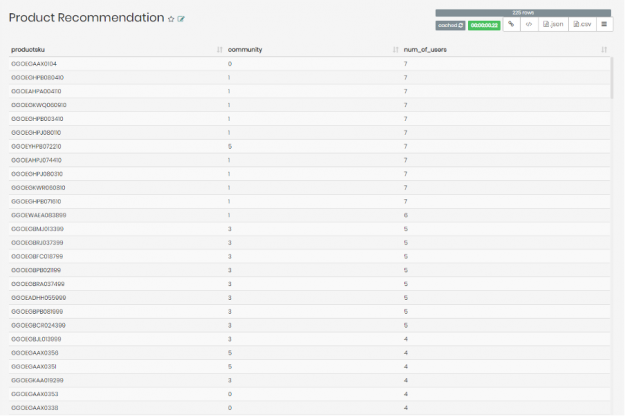
We were able to see the list of recommended products for user ID number ‘9209808985108850988’, and the community these products belong to, as well as the number of similar users to user ‘9209808985108850988’ who bought the specific product on the list.
Interestingly enough, the products recommended for user ‘9209808985108850988’ that have the most similar users who bought these products seem to largely fall in community ‘1’. If we were investigating further, this could have directed us to check whether it’s worth recommending user ‘9209808985108850988’ with more products belonging to community ‘1’.
Conclusion
We were able to demonstrate timbr’s advanced semantic capabilities using the Google Analytics Knowledge Graph combined with Graph Algorithms all in simple SQL, allowing us to analyze, explore and visualize our data. Not only were we able to perform in-depth analysis, but were able to do so with extremely high-performance speeds, going through large amounts of data in a matter of seconds.
We were able to accomplish our tasks and leverage our knowledge graph by connecting with RAPIDS cuGraph and NVIDIA GPU capabilities. Using cuGraph allowed us to query and analyze a mass amount of data in a fraction of the time it would have taken to do so using the standard CPU in NetworkX.
Click on timbr.ai and learn how you can leverage your data and performance speeds like never before.