
 With the continued growth of AI models and data sets and the rise of real-time applications, getting optimal inference performance has never been more important. In this post, you learn how to get the best natural language inference performance from AWS G4dn instance powered by NVIDIA T4 GPUs, and how to deploy BERT networks easily using NVIDIA Triton Inference Server.
With the continued growth of AI models and data sets and the rise of real-time applications, getting optimal inference performance has never been more important. In this post, you learn how to get the best natural language inference performance from AWS G4dn instance powered by NVIDIA T4 GPUs, and how to deploy BERT networks easily using NVIDIA Triton Inference Server.
As the explosive growth of AI models continues unabated, natural language processing and understanding are at the forefront of this growth. As the industry heads toward trillion-parameter models and beyond, acceleration for AI inference is now a must-have.
Many organizations deploy these services in the cloud and seek to get optimal performance and utility out of every instance they rent. Instances like the AWS G4dn, powered by NVIDIA T4 GPUs, is a great platform for delivering AI inference to cutting-edge applications. The combination of Tensor Core technology, TensorRT, INT8 precision, and NVIDIA Triton Inference Server team up to get the best inference performance from AWS.
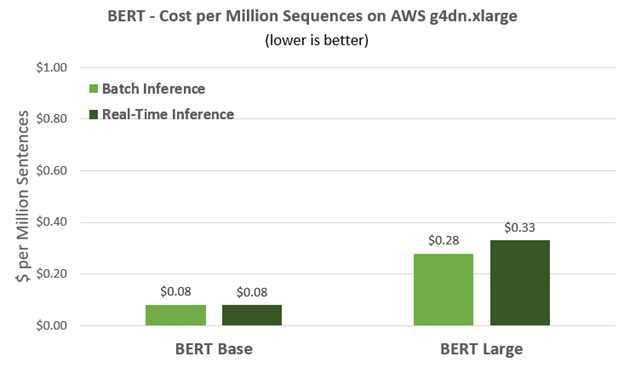
For starters, here are the dollars and cents. Running BERT-based networks, AWS customers can get a million sentences inferenced for about a dime. Using BERT Large, which is about three times larger than BERT Base, you can get a million sentences inferenced for around 30 cents. The efficiency of the T4 GPU that powers the AWS g4dn.xlarge instance means you can cost effectively deploy smart, powerful natural language applications to attract new customers, and deliver great experiences to existing customers.
Deploying inference-powered applications is still sometimes harder than it must be. To that end, we created NVIDIA Triton Inference Server. This open-source server software eases deployment, with automatic load balancing, automatic scaling, and dynamic batching. This last feature is especially useful as many natural language AI applications must operate in real time.
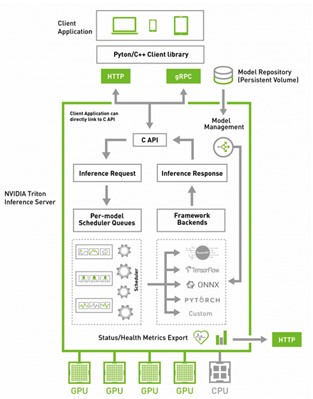
Currently, NVIDIA Triton supports a variety of major AI frameworks, including TensorFlow, TensorRT, PyTorch, and ONNX. You can also implement your own custom inference workload by using the Python and C++ custom backend.
With the new feature introduced in the NVIDIA Triton tools model analyzer, you can set a latency budget of five milliseconds. NVIDIA Triton automatically sets the optimal batch size for best throughput while maintaining that latency budget. In addition, NVIDIA Triton is tightly coupled with Kubernetes. It can be used with cloud provider-managed Kubernetes services like Amazon EKS, Google Kubernetes Engine, and Azure Kubernetes Service.
BERT inference performance
Because language models are often used in real-time applications, we discuss performance at several latency targets, specifically 5ms and 10ms. To simulate a real-world application, assume that there are multiple end users all sending inference requests with a batch size of one simultaneously. What’s of interest is how many requests can be handled per second.
For these measurements on G4dn, we used NVIDIA Triton to serve the BERT QA model with a sequence length of 128 and precision of INT8. Using INT8 precision, we saw up to an 80% performance improvement compared to FP16, which translates into more simultaneous requests at any given latency requirement.
Much higher throughput can be obtained with the NVIDIA Triton optimizations of concurrent model execution and dynamic batching. You can also make use of the model analyzer tool to help you find the optimal configurations to maximize the throughput under the required latency of 5 ms and 10 ms.
| Batch throughput | Real-time throughput | Batch inference cost per 1M inferences |
Real-time inference Cost per 1M inferences |
|
| BERT Base | 1,794 | 1,794 | $0.08 | $0.08 |
| BERT Large | 525 | 449 | $0.33 | $0.28 |
For BERT Base, you can see that T4 can get nearly 1,800 sentences/sec within a 10ms latency budget. T4 very quickly achieves its maximum throughput, and so the real-time throughput is about the same as the high batch throughput. This performance means that a single T4 GPU can simultaneously deliver answers to nearly 1,800 simultaneous requests and deliver a million of these answers for less than a dime, making it a cost-effective solution.
BERT-Large is about three times larger than BERT-Base and can deliver more accurate and refined answers. With this model, T4 on G4dn can deliver 449 samples per second within the 10ms latency limit, and 525 sentences/sec for batch throughput. In terms of cost per million inferences, this translates into an instance cost of 33 cents for real-time and 28 cents for batch throughput, again delivering great performance/dollar.
Optimal inference with TensorRT
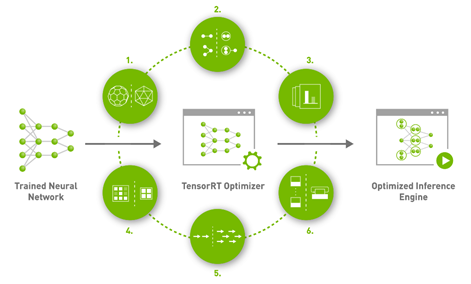
NVIDIA TensorRT plays a key role in getting the most performance and value out of AWS G4 instances. This inference SDK delivers high-performance, deep learning inference. It includes a deep learning inference optimizer and runtime that brings low latency and high throughput for deep learning inference applications. Figure 2 shows the major features:
- Reduce mixed precision: Maximizes throughput by quantizing models to INT8 while preserving accuracy.
- Layer and tensor fusion: Optimized use of GPU memory and bandwidth by fusing nodes in a kernel.
- Kernel auto-tuning: Selects best layers and algorithms based on the target GPU platform.
- Dynamic tensor memory: Minimizes memory footprint and reuses memory for tensors efficiently.
- Multi-stream execution: Uses a scalable design to process multiple input streams in parallel.
- Time fusion: Optimizes recurrent neural networks over time with dynamically generated kernels.
TensorRT maximizes throughput by quantizing models to INT8 while preserving accuracy, and automatically selects best data layers and algorithms that are optimized for the target GPU platform.
TensorRT and NVIDIA Triton Inference Server software are both available from NGC Catalog, the curated set of NVIDIA GPU-optimized software for AI, HPC, and visualization. The NGC Catalog consists of containers, pretrained models, Helm charts for Kubernetes deployments, and industry-specific AI toolkits with SDKs. TensorRT and NVIDIA Triton are also both available in the NGC Catalog in AWS Marketplace, making it even easier to use these resources on AWS G4 instances.
Amazon EC2 G4 instances
AWS offers the G4dn Instance based on NVIDIA T4 GPUs, and describes G4dn as “the lowest cost GPU-based instances in the cloud for machine learning inference and small scale training.”
Amazon EC2 offers a variety of G4 instances with one or multiple GPUs, and with different amounts of vCPU and memory. You can perform BERT inference below 5 ms on a single T4 GPU with 16 GB, such as on a g4dn.xlarge instance. The cost of this instance at the time of publication is $0.526 per hour on demand in the US East (N. Virginia) Region
Running BERT on AWS G4dn
Here’s how to get the most performance from the popular language model BERT, a transformer-based model introduced by Google a few years ago. We discuss performance for both BERT-Base and BERT-Large and then walk through how to set up NVIDIA Triton to perform inferences on both models.
To experience the outstanding performance shown earlier, follow the detailed steps in the TensorRT demo. To save all the efforts needed for complicated environment setup and configuring, you can start directly with updated monthly, performance-optimized containers available on NGC.
Launch an EC2 instance. Select the Deep Learning AMI (Ubuntu 18.04) version 43.0 to run on a g4dn.xlarge instance with at least 150G of storage space. Log into your instance.
Clone TensorRT repository into your local environment:
git clone -b master https://github.com/nvidia/TensorRT TensorRT
Pull and launch the container:
docker run --gpus all -it --rm -v $HOME/TensorRT:/workspace/TensorRT nvcr.io/nvidia/tensorflow:21.04-tf1-py3
Set up the NGC command line interface and download dataset as well as models. To set up the NGC command line interface, follow the download instructions based on your OS (AMD64 Linux, in this case).
Change to the BERT directory:
cd /workspace/TensorRT/demo/BERT
Download SQuAD v2.0 training and dev dataset.
bash ./scripts/download_squad.sh v2_0
Download TensorFlow checkpoints for BERT base model with sequence length 128, fine-tuned for SQuAD v2.0. It takes few minutes to download the model.
bash scripts/download_model.sh base
Install related packages and Build the TensorRT engine. To build an engine, follow these steps. Install the required package:
pip install pycuda
Create a directory to store the engines:
mkdir -p engines
Run the builder.py script to build the engine with FP16 precision:
python3 builder.py -m models/fine-tuned/bert_tf_ckpt_base_qa_squad2_amp_128_v19.03.1/model.ckpt -o engines/bert_base_128.engine -b 1 -s 128 --fp16 -c models/fine-tuned/bert_tf_ckpt_base_qa_squad2_amp_128_v19.03.1
Run the builder.py script to build the engine with INT8 precision to obtain the best performance, as shown earlier:
python3 builder.py -m models/fine-tuned/bert_tf_ckpt_base_qa_squad2_amp_128_v19.03.1/model.ckpt -o engines/bert_base_128_int8mix.engine -b 1 -s 128 --int8 --fp16 --strict -c models/fine-tuned/bert_tf_ckpt_base_qa_squad2_amp_128_v19.03.1 --squad-json ./squad/train-v2.0.json -v models/fine-tuned/bert_tf_ckpt_base_qa_squad2_amp_128_v19.03.1/vocab.txt --calib-num 100 -iln -imh
Test and benchmark the TensorRT engine that you just created. For benchmarking the model generated at 5.c, run the following command:
python3 perf.py -e /workspace/TensorRT/demo/BERT/engines/bert_base_128.engine -b 1 -s 128
For benchmarking the model generated at 5.d, run the following command:
python3 perf.py -e /workspace/TensorRT/demo/BERT/engines/bert_base_128_int8mix.engine -b 1 -s 128
For more information about performance results on various GPU architectures and settings, see BERT Inference Using TensorRT: Results.
Deploy the BERT QA model for inference with NVIDIA Triton Inference Server
NVIDIA Triton supports the following optimization modes:
- Concurrent model execution: Enables multiple models, or multiple instances of the same model, to execute in parallel on the same GPU or on multiple GPUs to exploit the parallelism of GPU better.
- Dynamic batching: Instruct the server to wait a predefined amount of time to combine individual inference requests into a preferred batch size preconfigured to enhance GPU utilization and improve inference throughput.
For more information about framework-specific optimization, see Optimization.
In this section, we show you how to deploy the TensorRT model with NVIDIA Triton Inference Server and turn on concurrent model execution. We also demonstrate dynamic batching with only a few lines of code. Follow these steps on the g4dn.xlarge instance launched earlier.
In the first step, you regenerate the model files with a larger batch size to enable NVIDIA Triton dynamic batching optimizations. This is supposed to run in the same container as the one in previous sections.
Regenerate the TensorRT engine files with a larger batch size:
mkdir -p triton_engines python3 builder.py -m models/fine-tuned/bert_tf_ckpt_base_qa_squad2_amp_128_v19.03.1/model.ckpt -o triton_engines/bert_base_128_int8mix.engine -b 16 -s 128 --int8 --fp16 --strict -c models/fine-tuned/bert_tf_ckpt_base_qa_squad2_amp_128_v19.03.1 --squad-json ./squad/train-v2.0.json -v models/fine-tuned/bert_tf_ckpt_base_qa_squad2_amp_128_v19.03.1/vocab.txt --calib-num 100 -iln -imh
Exit the current Docker environment and create a directory for triton_serving by running the following commands:
exit mkdir -p $HOME/triton_serving/bert_base_qa/1 cp $HOME/TensorRT/demo/BERT/triton_engines/bert_base_128_int8mix.engine $HOME/triton_serving/bert_base_qa/1/model.plan
You can change the bert_base_128_int8mix.engine to other engine files that you would like to serve on NVIDIA Triton.
It should be in the following format if everything works correctly:
triton_serving └── bert_base_qa └── config.pbtxt (optional) └── 1 └── model.plan
In this format, triton_serving is the model repository containing all your models, bert_base_qa is the model name, and 1 is the version number.
If you don’t know what to put into the config.pbtxt file yet, you may use the --strict-model-config False flag to let NVIDIA Triton serve the model with an automatically generated configuration.
In addition to the default configuration automatically generated by the NVIDIA Triton server, we recommend finding an optimal configuration based on the actual workload that users need. Download our example config.pbtxt file.
As you can see from the config.pbtxt file, you only need four lines of code to enable dynamic batching:
dynamic_batching {
preferred_batch_size: 4
max_queue_delay_microseconds: 2000
}
Here, the preferred_batch_size option means the preferred batch size that you would like to combine your input requests into. The max_queue_delay_microseconds option is how long the NVIDIA Triton server waits when the preferred size cannot be created from the available requests.
For concurrent model execution, directly specify the model concurrency per GPU by changing the count number in the instance_group.
instance_group {
count: 2
kind: KIND_GPU
}
For more information about the configuration files, see Model Configuration.
Start the NVIDIA Triton server by running the following command:
docker run --gpus all --rm -p8000:8000 -p8001:8001 -p8002:8002 -v $HOME/triton_serving/:/models nvcr.io/nvidia/tritonserver:21.04-py3 tritonserver --model-repository=/models (--strict-model-config False)
The --strict-model-config False is only needed if you are not including the config.pbtxt file in your NVIDIA Triton server directory.
With that, congratulations on having your first NVIDIA Triton server running! Feel free to use the HTTP and grpc protocols to send your request or use the Performance Analyzer tool to test the server performance.
NVIDIA Triton performance benchmarking with perf_analyzer
For the following benchmark, you use the perf_analyzer application to generate concurrent inference requests and measure the throughput and latency of those requests. By default, perf_analyzer sends requests with concurrency number 1 and batch size 1. The whole process works as follows:
- The perf_analyzer sends one inference request to NVIDIA Triton, waits for the response, and only sends the subsequent request once the previous response is received.
- To simulate multiple end users using the service simultaneously, increase the request concurrency number to generate more loads to the NVIDIA Triton server.
While the NVIDIA Triton server from the previous step is still running, open a new terminal, connect using SSH to the instance that you were running, and run the NGC NVIDIA Triton SDK container:
docker run -it --rm --net=host nvcr.io/nvidia/tritonserver:21.04-py3-sdk
Generate a real input file with the format required. For an easy start, you can also directly download one example available input.json.
Run the perf analyzer with the following command:
perf_analyzer -m bert_base_qa --input-data input.json
This starts the perf analyzer sending the request with the default request concurrency 1 and batch size 1. A detailed log of throughput and latency with breakdown is printed for further analysis. You may also add the --concurrency-range and -b flags to increase the request concurrency and batch size to simulate more heavy load scenarios. For example:
perf_analyzer -m bert_base_qa --input-data input.json --concurrency-range 8 -b 1
The preceding command sends the request with request concurrency 8 and batch size 1 to the NVIDIA Triton server.
Tables 2 and 3 show the inference throughput and latency results.
| Instance | Batch size | Request concurrency | Model concurrency GPU | Preferred batch size for dynamic batching | Throughput (sentences/sec) | p99 latency (ms) |
| g4dn.xlarge | 1 | 1 | 1 | Not enabled | 427 | 2.5 |
| g4dn.xlarge | 1 | 8 | 2 | 4 | 1,639 | 5.2 |
| g4dn.xlarge | 1 | 16 | 2 | 8 | 1,794 | 9.4 |
| Instance | Batch size | Request concurrency | Model concurrency GPU | Preferred batch size for dynamic batching | Throughput (sentences/sec) | p99 latency (ms) |
| g4dn.xlarge | 1 | 1 | 1 | Not enabled | 211 | 4.8 |
| g4dn.xlarge | 1 | 4 | 2 | 2 | 449 | 9.5 |
Table 3 shows that NVIDIA Triton can provide higher throughput with the concurrent model execution and dynamic batching features compared to the baseline without these optimizations on the same infrastructure.
With the default configuration for BERT-Base, you can reduce P99 latency down to 2.5 ms. You can achieve a throughput of 1639 sentences/sec with P99 latency around 5ms and 1794 sentences/sec with P99 latency less than 10ms by combining dynamic batching and concurrent model execution.
With dynamic batching and concurrent model execution enabled, you can do inference for BERT-Large:
- A P99 latency of 4.8 ms with the lowest latency
- A best throughput of 449 sentences/sec under 10 ms P99 latency
Conclusion
To summarize, you converted a fine-tuned BERT model for QA tasks into a TensorRT engine, which is highly optimized for inference. The optimized BERT QA engine was then deployed on NVIDIA Triton Inference Server, with concurrent model execution and dynamic batching to get the best performance from NVIDIA T4 GPUs.
Be sure to visit NGC, where you can find GPU-optimized AI, high-performance computing (HPC), and data analytics applications, as well as enterprise-grade containers, pretrained AI models, and industry-specific SDKs to aid in the development of your own workload. Also, stay tuned for the upcoming TensorRT 8, which includes new features like sparsity optimization for NVIDIA Ampere Architecture GPUs, quantization-aware training, and an enhanced compiler to accelerate transformer-based networks.