As explained in the Batch Normalization paper, training neural networks becomes way easier if its input is Gaussian. This is clear. And if your model inputs are not Gaussian, RAPIDS will just transform it to Gaussian in the blink of an eye. Gauss rank transformation is a novel standardization technique to transform input data for … Continued
As explained in the Batch Normalization paper, training neural networks becomes way easier if its input is Gaussian. This is clear. And if your model inputs are not Gaussian, RAPIDS will just transform it to Gaussian in the blink of an eye.
Input normalization is critical for training neural nets. The idea of Gauss rank transformation was first introduced by Michael Jahrer in his winning solution of Porto Seguro’s Safe Driver Prediction challenge. He trained denoising auto-encoders and experimented with several input normalization methods. In the end, he drew this conclusion:
The best thing I found during the past and works straight out of the box is GaussRank. This works usually much better than standard mean/std scaler or min/max (normalization).
How it works
There are three steps to transform a vector of continuous values under arbitrary distribution to Gaussian distribution based on ranks, as shown in the figure 1.
Figure 1: Gauss Rank Transformation.
The CuPy implementation is straightforward and remarkably resembles NumPy operations. In fact, it is as simple as changing the imported functions to move the whole process from CPU to GPU without any other code changes.
Comparison of CuPy and NumPy implementations of Gauss rank transformation.
Inverse Transformation is used to restore the original values from the Gaussian transformations. This is another great example to show the interoperability of cuDF and CuPy. Just like you can do with NumPy and Pandas, you can weave cuDF and CuPy together in the same workflow while keeping the data entirely on the GPU.
Comparison of CuPy and NumPy implementations of inverse Gauss rank transformation.
A real-world example
For this example, we will use the CHAMPS molecular properties prediction dataset. The task is to predict scalar coupling constants (the ground truth)between atom pairs in molecules for eight different chemical bond types. What’s challenging is that the distribution of the ground truth differs significantly for each bond type, with varied mean and variance. This makes it difficult for the neural network to converge.
Figure 2: Distribution of the ground truths for each bond type.
Hence, we applied the Gauss rank transformation to the ground truths of training data to create one unified clean Gaussian distribution for all bond types.
Figure 3: Workflow for converting ground truths using GaussRank.
In this regression task, ground truths of training data are transformed using GaussRank.
For inference, we applied the inverse Gauss rank transformation to the predictions of the test data so that they match the original different distributions for each bond type. Since the true distribution of targets of the test data is unknown, the inverse transformation of the predictions of the test data is calculated based on the distribution of target variables in training data. It should be noted that such an inverse transformation is only needed for target variables.
Figure 4: Predictions are inversely transformed to match the original distribution.
Keep in mind that GaussRank does have some limitations:
It works only for continuous variables, and
if the input is already close to Gaussian, or very asymmetrical, performance might not be improved or even become worse.
The interplay between gauss rank transformation and different kinds of neural networks is an active research topic.
Speedup
We measure the total time of transformation and the inverse transformation. For the proceeding CHAMPS dataset, the cuDF+CuPy implementation on a single NVIDIA V100 GPU achieves 25x speedup over the Pandas+NumPy implementation on an Intel Xeon CPU. We generate synthetic random data for a more comprehensive comparison. For 10M data points and more, our RAPIDS implementation is more than 100x faster.
Figure 5: Speedup comparison of GaussRank transformation + inverse transformation on synthetic random data.
Conclusion
RAPIDS has come a long way to deliver stunning performance with little or no code changes. This blog post showcases how easy it is to use RAPIDS cuDF and CuPy as drop-in replacements to Pandas and NumPy to realize the performance improvements on GPUs. As shown inthe full notebook, by adding just two lines of code, the Gauss rank transformation detects the input tensor is on GPU and automatically switches to cuDF+CuPy from Pandas+NumPy. It can’t be much easier than that.
Up until a week ago, I had no problem using the apple provided TF version for the new M1 Macs. 2 Days ago the Repository was archived and Apple published new instruction to using TF with the M! Macs. The previous TF for mac Version stopped working at the same time, unfortunately the new Version which I just installed trained my simple MNIST Model 15x slower. Does anyone know why this is or if this is a Bug?
Hey all, I trained a “RoastBot” a while ago using a dataset I scraped from /r/RoastMe. The inputs are images of people and the outputs are high rated comments that are “roasts” of the people.
I use Inceptionv3 to preprocess the images into latent vectors, and then I use a recurrent decoder with visual attention to create the sequences. This works good enough to come up with something decent every now and again, but the model just seems like it would do better if it started the training process already knowing about grammar and syntax.
I was thinking I could replace my decoder with a pre-trained BERT model, but BERT and any other transformer models only take text as input, right? I think at least BERT preprocesses the text, I’m not sure how though.
My latent tensors are of shape (8,8,2048), and I imagine that the input text tensors for BERT are (num_tokens, 1). I guess I can flatten my tensor to be of shape (882048, 1), but also I don’t know if BERT will even do a good job going from image data to text…
If I could find a large model for image captioning that would be perfect for fine-tuning, but I don’t think it exists.
I have the following problem statement in which I only need to predict whether a given image is an apple or not. For training only 8 images are provided with the following details:
apple_1 image – 2400×1889 PNG
apple_2 image – 641×618 PNG
apple_3 image – 1000×1001 PNG
apple_4 image – 500×500 PNG contains a sticker on top of fruit
apple_5 image – 2400×1889 PNG
apple_6 image – 1000×1000 PNG
apple_7 image – 253×199 JPG
apple_8 image – 253×199 JPG
I am thinking about using Transfer learning: either VGG or ResNet-18/34/50. Maybe ResNet is an overkill for this problem statement? How do I deal with such varying image sizes and of different file extensions (PNG, JPG)?
Any online code tutorial will be helpful. I found this example code online.
Human pose estimation is a popular computer vision task of estimating key points on a person’s body such as eyes, arms, and legs. This can help classify a person’s actions, such as standing, sitting, walking, lying down, jumping, and so on. Understanding the context of what a person might be doing in a scene has … Continued
Human pose estimation is a popular computer vision task of estimating key points on a person’s body such as eyes, arms, and legs. This can help classify a person’s actions, such as standing, sitting, walking, lying down, jumping, and so on.
Understanding the context of what a person might be doing in a scene has broad application across a wide range of industries. In a retail setting, this information can be used to understand customer behavior, enhance security, and provide richer analytics. In healthcare, this can be used to monitor patients and alert medical personnel if the patient needs immediate attention. On a factory floor, human pose can be used to identify if proper safety protocols are being followed.
In general, this is a reliable approach in applications that require understanding of human activity and commonly used as one of the key components in more complex tasks such as gesture, tracking, anomaly detection, and so on.
Video 1. Pose estimation demo
Open-source methods of developing pose estimation exist but are not optimal in terms of inference performance and are time consuming to integrate into production applications. With this post, we show you how to develop and deploy pose estimation models that are easy to use across device profiles, perform extremely well, and are highly accurate.
Pose estimation has been integrated with the NVIDIA Transfer Learning Toolkit (TLT) 3.0 so that you can take advantage of all the TLT features, like model pruning and quantization, to create both an accurate and a high-performance model. After it’s trained, you can deploy this model for inference for real-time performance.
This post series walks you through the steps of training, optimizing, deploying a real-time high performance pose estimation model. In part 1, you learn how to train a 2D pose estimation model using open-source COCO dataset. In part 2, you learn how to optimize the model for inference throughput and then deploy the model using TLT CV inference pipeline. We compare the trained model from TLT with other state-of-the-art models.
Training a 2D Pose Estimation model with TLT
In this section, we cover the following topics on training a 2D pose estimation model with TLT:
Methodology
Environment setup
Data preparation
Experiment configuration file
Training
Evaluation
Model verification
Methodology
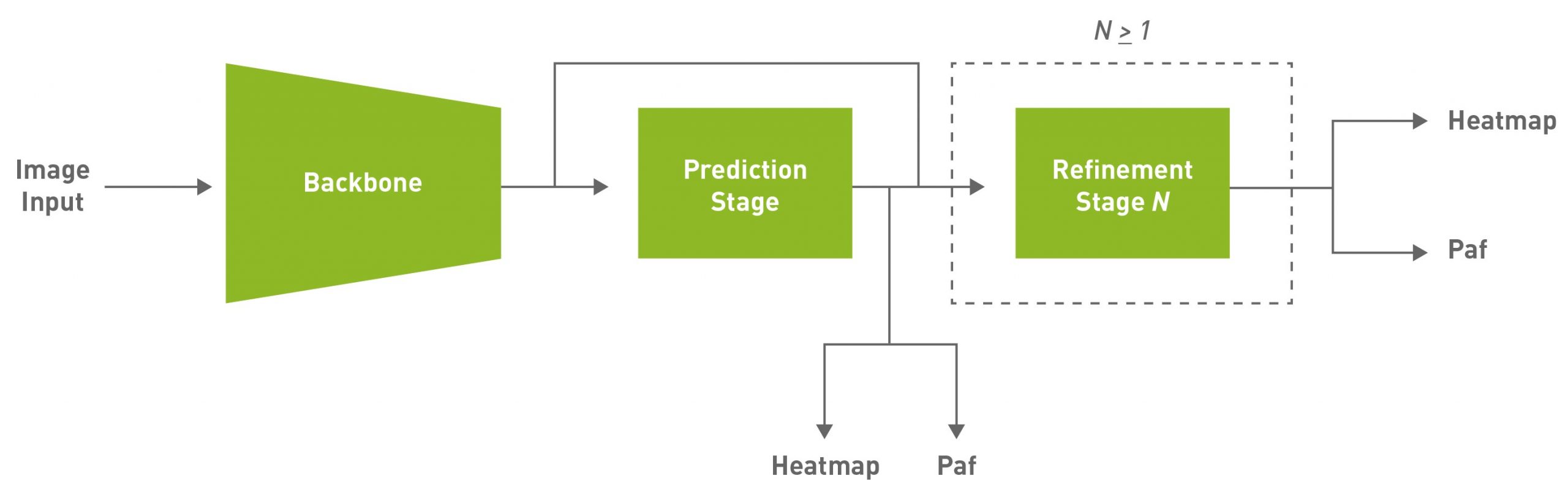
The BodyPoseNet model aims to predict the skeleton for every person in a given input image, which consists of keypoints and the connections between them.
The two commonly used approaches to pose estimation are top-down and bottom-up. A top-down approach typically uses an object detection network to localize the bounding boxes of all humans in a frame, and then uses a pose network to localize the body parts within that bounding box. A bottom-up approach, as the name suggests, builds the skeleton from bottom-up. It first detects all human body parts within a frame and then uses a methodology to group the parts that belong to a specific person.
There are several reasons to adopt a bottom-up approach. One is higher inference performance. With a bottom-up approach, there is no need for a separate person detector, unlike top-down pose estimation methods. The compute does not scale linearly with the number of persons in the scene. This enables you to achieve real-time performance for crowded scenes as well. Moreover, bottom-up also has the advantage of having global context as the entire image is provided as input to the network. It can handle complex poses and crowding better.
Given some of those reasons, this approach aims to achieve efficient single-shot, bottom-up pose estimation while also delivering competitive accuracy. The default model used in this post is a fully convolutional model and consists of a backbone network, an initial prediction stage which does a pixel-wise prediction of confidence maps (heatmap) and part-affinity fields (PAF) followed by multistage refinement (0 to N stages) on the initial predictions. This solution simplifies and abstracts much of the complexities of the bottom-up approach while allowing for the necessary knobs to be tuned for specific applications.
Figure 1. Simplified block diagram of the default model architecture.
PAFs are one way to represent association scores in a bottom-up approach. For more information, see Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields. It consists of a set of 2D vector fields that encode the location and orientation of limbs. This, in association with the heatmap, is used to build up the skeleton during post-processing by performing a bipartite matching and associating body part candidates.
Environment setup
NVIDIA TLT toolkit helps abstract away the AI/DL framework complexity and enables you to build production quality models faster, with no coding required. For more information about hardware and software requirements, setting up required dependencies, and installing the TLT launcher, see the TLT Quick Start Guide.
Download the latest samples using the following command:
ngc registry resource download-version "nvidia/tlt_cv_samples:v1.1.0"
You can find the sample notebook located at tlt_cv_samples:v1.1.0/bpnet, which also includes all the steps in detail.
Set up env variables for cleaner command line commands. Update the following variable values:
export KEY=
export NUM_GPUS=1
# Local paths# The dataset is expected to be present in $LOCAL_PROJECT_DIR/bpnet/data.
export LOCAL_PROJECT_DIR=/home//tlt-experiments
export SAMPLES_DIR=/home//tlt_cv_samples_vv1.1.0
# Container paths
export USER_EXPERIMENT_DIR=/workspace/tlt-experiments/bpnet
export DATA_DIR=/workspace/tlt-experiments/bpnet/data
export SPECS_DIR=/workspace/examples/bpnet/specs
export DATA_POSE_SPECS_DIR=/workspace/examples/bpnet/data_pose_config
export MODEL_POSE_SPECS_DIR=/workspace/examples/bpnet/model_pose_config
To run the TLT launcher, map the ~/tlt-experiments directory on the local machine to the Docker container using the ~/.tlt_mounts.json file. For more information, see TLT Launcher.
Create the ~/.tlt_mounts.json file and update the following content inside:
Make sure that the source directory paths to be mounted are valid. This mounts the path /home//tlt-experiments on the host machine to be the path /workspace/tlt-experiments inside the container. It also mounts the downloaded specs on the host machine to be the path /workspace/examples/bpnet/specs, /workspace/examples/bpnet/data_pose_config, and /workspace/examples/bpnet/model_pose_config inside the container.
Make sure that you have installed the required dependencies by running the following command:
To get started, set up an NGC account and then download the pretrained model. Currently, only the vgg19 backbone is supported.
# Create the target destination to download the model.
mkdir -p $LOCAL_EXPERIMENT_DIR/pretrained_vgg19/
# Download the pretrained model from NGC
ngc registry model download-version nvidia/tlt_bodyposenet:vgg19
--dest $LOCAL_EXPERIMENT_DIR/pretrained_vgg19
Data preparation
We use the COCO (common objects on context) 2017 dataset in this post as an example. Download the dataset and extract as per the instructions:
Unzip the images directories into the $LOCAL_DATA_DIR directory and the annotations into $LOCAL_DATA_DIR/annotations.
To prepare the data for training, you must generate segmentation masks to be used for masking the loss of unlabeled persons and tfrecords to feed to the training pipeline. The mask folder is based on the path provided in the coco_spec.json file. mask_root_dir_path directory is a relative path to root_directory_path, as are mask_root_dir_path and annotation_root_dir_path.
Prepare the data and annotations in a format similar to the COCO dataset.
Create a dataset spec under data_pose_config, similar to coco_spec.json, that includes the dataset paths, pose configuration, occlusion labeling convention, and so on.
Convert your annotations to the COCO annotations format.
The next step is to configure the spec file for training. The experiment spec file is essential, as it compiles all the necessary hyperparameters for achieving a good model. The specification file for BodyPoseNet training configures these components of the training pipe:
Trainer
Dataloader
Augmentation
Label Processor
Model
Optimizer
You can find the default specification file at $SPECS_DIR/bpnet_train_m1_coco.yaml. We expand on each component of the specification file but we don’t cover all the parameters here. For more information, see Create a Train Experiment Configuration File.
Trainer (Top-level config)
The top-level experiment configs include basic parameters for an experiment; for example, number of epochs, pretrained weights, whether to load the pretrained graph, and so on. An encrypted checkpoint is saved per the checkpoint_n_epoch value. Here’s a code example of some of the top-level configs.
All the paths (checkpoint_dir and pretrained_weights) are internal to the Docker container. To verify correctness, check ~/.tlt_mounts.json. For more information about these parameters, see the Body Pose Trainer section.
Dataloader
This section helps you with defining datapaths, image configuration, the target pose configuration, normalization parameters, and so on. The augmentation_config section provides some on-the-fly augmentation options. It supports basic spatial augmentations, such as flip, zoom, rotate, and translate, which can be configured before training experiments. The label_processor_config section provides the required parameters to configure the ground truth feature map generation.
The target_shape value depends on the image_dims and model stride values (target_shape = input_shape / model stride). The current model has a stride of 8.
Make sure to use the same root_data_path value as root_directory_path in dataset_spec. The mask and image data directories in dataset_spec are relative to root_data_path.
All paths, including pose_config_path, dataset_config, and dataset_specs, are internal to Docker.
Several spatial_augmentation_modes are supported:
person_centric: Augmentations are centered around a person of interest in the ground truth.
standard: Augmentations are standard (that is, centered around the center of the image) and the aspect ratio of the image is retained.
standard_with_fixed_aspect_ratio: Same as standard, but the aspect ratio is fixed to the network input aspect ratio.
For more information about each parameter, see the Dataloader section.
Model
The BodyPoseNet model can be configured using the model option in the spec file. The following is a sample model config to instantiate a custom VGG19-backbone-based model.
The number of total stages for pose estimation (stages of refinement + 1) in the network is captured by the stages param which takes any value >= 2. We recommend using the L1 regularizer when training a network before pruning, as L1 regularization makes it easier to prune the network weights. For more information about each parameter in the model, see the Model section.
Optimizer
This section describes how to configure the optimizer and learning-rate schedule:
The default base_learning_rate is set for a single-GPU training. To use multi-GPU training, you may have to modify the learning_rate value to get similar accuracy. In most cases, scaling up the learning rate by a factor of $NUM_GPUS would be a good start. For instance, if you are using two GPUs, use 2 * base_learning_rate used in one GPU setting, and if you are using four GPUs, use 4 * base_learning_rate. For more information about each parameter in the model, see the Optimizer section.
Training
After following the steps to generate TFRecords and masks and setting up a train specification file, you are now ready to start training the body pose estimation network. Use the following command to launch training:
Training with more GPUs enables networks to ingest more data faster, saving you precious time during the development process. TLT supports multi-GPU training so that you can train the model with several GPUs in parallel. We recommend using four GPUs or more for training the model as one GPU might take several days to complete. The training time roughly decreases by a factor of $NUM_GPUS. Make sure that you update the learning rates accordingly, based on the linear scaling method described in the Optimizer section.
BodyPoseNet supports restarting from checkpoint. In case the training job is killed prematurely, you may resume training from the last saved checkpoint by simply rerunning the same command. Make sure that you use the same number of GPUs when restarting the training.
Evaluation
Start with configuring the inference and evaluation specification file. The following code example is a sample specification:
The value of input_shape here can be different from the input_dims value used for training. The multi_scale_inference parameter enables multiscale refinement over the provided scales. Because you are using a model of stride 8, output_upsampling_factor is set to 8.
To keep the evaluation consistent with bottom-up human pose estimation research, there are two modes and specification files to evaluate the model:
$SPECS_DIR/infer_spec.yaml: Single-scale, nonstrict input. This configuration does a single-scale inference on the input image. The aspect ratio of the input image is retained by fixing one of the sides of the network input (height or width), and adjusting the other side to match the aspect ratio of the input image.
$SPECS_DIR/infer_spec_refine.yaml: Multiscale, nonstrict input. This configuration does a multiscale inference on the input image. The scales are configurable.
There is another mode used primarily to verify against the final exported TRT models. You use this in later sections.
$SPECS_DIR/infer_spec_strict.yaml: Single-scale, strict input. This configuration does a single-scale inference on the input image. Aspect ratio of the input image is retained by padding the image on the sides as needed to fit the network input size as the TRT model input dims are fixed.
The --model_filename argument overrides the model_path variable in the inference specification file.
Now that you’ve trained the model, run inference and verify the predictions. To verify the model visually with TLT, use the tlt bpnet inference command. The tool supports running inference on the .tlt model, as well as the TensorRT .engine model. It generates annotated images with skeleton rendered on them and serialized frame-by-frame keypoint labels and metadata in detections.json. For example, to run inference with a trained .tlt model, run the following command:
Figure 1 shows an example of the original image and Figure 2 shows the output image with pose results rendered. As you can see, the model is robust to an image that is different from the COCO training data.
Figure 2. Original image.
Figure 3. Output image with pose rendered on the original image.
Conclusion
In this post, you learned about training body pose models using the BodyPoseNet app in TLT. The post showed taking an open-source COCO dataset with a pretrained backbone from NGC to train a model with TLT. To optimize the trained model for inference and deployment, see Training and Optimizing the 2D Pose Estimation Model, Part 2.
For more information, see the following resources:
The first post in this series covered how to train a 2D pose estimation model using an open-source COCO dataset with the BodyPoseNet app in the NVIDIA Transfer Learning Toolkit. In this post, you learn how to optimize the pose estimation model in the NVIDIA Transfer Learning Toolkit. It walks you through the steps of … Continued
The first post in this series covered how to train a 2D pose estimation model using an open-source COCO dataset with the BodyPoseNet app in the NVIDIA Transfer Learning Toolkit.
In this post, you learn how to optimize the pose estimation model in the NVIDIA Transfer Learning Toolkit. It walks you through the steps of model pruning and INT8 quantization to optimize the model for inference.
Model optimizations and export
This section covers few topics of model optimization and export:
Pruning
INT8 quantization
Best practices for improving speed and accuracy
Pruning
BodyPoseNet supports model pruning to remove unnecessary connections, reducing the number of parameters by an order of magnitude. This results in an optimized model architecture.
Usually, you just have to adjust -pth (threshold) for accuracy and model size trade off. For some internal studies, we’ve noticed that a pth value between the range [0.05, 3.0] is a good starting point for BodyPoseNet models.
Retrain the pruned model
After the model has been pruned, there might be a slight decrease in accuracy because some previously useful weights may have been removed. To regain the accuracy, we recommend retraining this pruned model over the same dataset. You can follow the same instructions as in the Train experiment configuration file section. The main change is now to specify pretrained_weights as the path to pruned model and enable load_graph. Because the model is being initialized with pruned model weights, the model converges faster.
# Retraining using the pruned model as model graph
tlt bpnet train -e $SPECS_DIR/bpnet_retrain_m1_coco.yaml
-r $USER_EXPERIMENT_DIR/models/exp_m1_retrain
-k $KEY
--gpus $NUM_GPUS
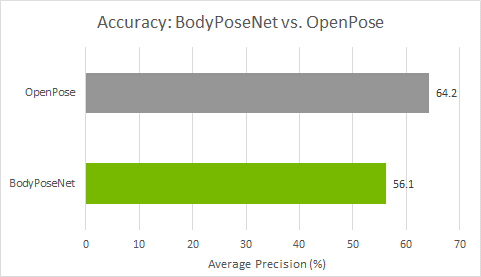
You can follow similar instructions as in the Evaluation and Model verification sections to evaluate and verify the pruned model. After retraining the pruned model with pth 0.05, you can observe an accuracy of 56.1% AP with multiscale inference. Here are the metrics on COCO validation set:
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets= 20 ] = 0.561
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets= 20 ] = 0.776
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets= 20 ] = 0.609
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets= 20 ] = 0.567
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets= 20 ] = 0.556
...
Export the .etlt model
Inference throughput and how quickly you can create an efficient model are two key metrics for deploying deep learning applications because they directly affect the time to market and the cost of deployment. TLT includes an export command to export and prepare TLT models for deployment.
The model is exported as a .etlt (encrypted TLT) file. The file is consumable by the TLT CV Inference, which decrypts the model and converts it to a TensorRT engine. Exporting the model decouples the training process from inference and allows conversion to TensorRT engines outside the TLT environment. TensorRT engines are specific to each hardware configuration and should be generated for each unique inference environment. The following code example shows the export of the pruned, retrained model.
The export command can optionally generate the calibration cache for running inference at INT8 precision. This is described more in detail in later sections.
INT8 quantization
The BodyPoseNet model supports int8 inference mode in TensorRT. To do this, the model is first calibrated to run 8-bit inferences. To calibrate the model, you need a directory with a sampled set of images to be used for calibration.
We’ve provided a helper script that parses the annotations and samples the required number of images at random based on specified criteria like number of people in the image, number of keypoints per person, and so on.
# Number of calibration samples to use
export NUM_CALIB_SAMPLES=2000
python3 sample_calibration_images.py
-a $LOCAL_EXPERIMENT_DIR/data/annotations/person_keypoints_train2017.json
-i $LOCAL_EXPERIMENT_DIR/data/train2017/
-o $LOCAL_EXPERIMENT_DIR/data/calibration_samples/
-n $NUM_CALIB_SAMPLES
-pth 1
--randomize
Generate INT8 calibration cache and engine
The following command exports the pruned, retrained model to the .etlt format, performs INT8 calibration, and generates the INT8 calibration cache and TensorRT engine for the current hardware.
# Set dimensions of desired output model for inference/deployment
export IN_HEIGHT=288
export IN_WIDTH=384
export IN_CHANNELS=3
export INPUT_SHAPE=288x384x3
# Set input name
export INPUT_NAME=input_1:0
tlt bpnet export
-m $USER_EXPERIMENT_DIR/models/exp_m1_retrain/bpnet_model.tlt
-o $USER_EXPERIMENT_DIR/models/exp_m1_final/bpnet_model.etlt
-k $KEY
-d $IN_HEIGHT,$IN_WIDTH,$IN_CHANNELS
-e $SPECS_DIR/bpnet_retrain_m1_coco.yaml
-t tfonnx
--data_type int8
--engine_file $USER_EXPERIMENT_DIR/models/exp_m1_final/bpnet_model.$IN_HEIGHT.$IN_WIDTH.int8.engine
--cal_image_dir $USER_EXPERIMENT_DIR/data/calibration_samples/
--cal_cache_file $USER_EXPERIMENT_DIR/models/exp_m1_final/calibration.$IN_HEIGHT.$IN_WIDTH.bin
--cal_data_file $USER_EXPERIMENT_DIR/models/exp_m1_final/coco.$IN_HEIGHT.$IN_WIDTH.tensorfile
--batch_size 1
--batches $NUM_CALIB_SAMPLES
--max_batch_size 1
--data_format channels_last
Make sure that the directory mentioned in --cal_image_dir has at least (batch_size * batches) number of images in it. To generate a F16 engine for the current hardware, specify --data_type as FP16. For more information about the parameters used here, see the INT8 model overview.
Evaluate the TensorRT engine
This evaluation is mainly used as a sanity check for the exported TRT (INT8/FP16) models. This doesn’t reflect the true accuracy of the model as the input aspect ratio here can vary a lot from the aspect ratio of the images in the validation set. The set has a collection of images with various resolutions. Here, you retain a strict input resolution and pad the image to retrain the aspect ratio. So, the accuracy here might vary based on the aspect ratio and the network resolution that you choose.
You can run the evaluation of the .tlt model in strict mode as well to compare with the accuracies of the INT8/FP16/FP32 models for any drop in accuracy. The FP16 and FP32 models should have no or minimal drop in accuracy when compared to the .tlt model in this step. The INT8 models would have similar accuracies (or comparable within 2-3% AP range) to the .tlt model.
You can follow similar instructions as in the Evaluation and Model verification sections to evaluate and verify the models. One change would be that you now use $SPECS_DIR/infer_spec_retrained_strict.yaml as inference_spec and the model to use would be a pruned TLT model, INT8 engine, or FP16 engine.
Deployable model export
After the INT8/FP16/FP32 model is verified, you must reexport the model so it can be used to run on inference platforms like TLT CV Inference. You use the same guidelines as in the previous sections, but you must add the --sdk_compatible_model flag to the export command, which adds a few nontraininable post-process layers to the model to enable compatibility with the inference pipelines. Reuse the calibration tensorfile (cal_data_file) generated in the earlier step to keep it consistent, but you must regenerate the cal_cache_file and the .etlt model.
In this section, we look at some best practices to improve model performance and accuracy.
Network input resolution for deployment
Network input resolution of the model is one of the major factors that determine the accuracy of bottom-up approaches. Bottom-up methods must feed the whole image at one time, resulting in a smaller resolution per person. Hence, higher input resolution yields better accuracy, especially on small- and medium-scale persons with regard to the image scale. However, with a higher input resolution, the runtime of the CNN also would be higher. So, the accuracy/runtime tradeoff should be determined by the accuracy and runtime requirements for the target use case.
If your application involves pose estimation for one or more persons close to the camera such that the scale of the person is relatively large, then you could go with a smaller network input height. If you are targeting to use the network for persons with smaller relative scales, like crowded scenes, you might want to go with a higher network input height. After you freeze the height of the network, the width can be decided based on the aspect ratio for your input data used during deployment time.
Illustration of accuracy/runtime variation for different resolutions
These are approximate runtimes and accuracies for the default architecture and spec used in the notebook. Any changes to the architecture or params yields different results. This is primarily to get a better sense of which resolution would suit your needs.
Input Resolution
Precision
Runtime (GeForce RTX 2080)
Runtime (Jetson AGX)
320×448
INT8
1.80ms
8.90ms
288×384
INT8
1.56ms
6.38ms
224×320
INT8
1.33ms
5.07ms
Table 1. CNN runtimes.
You can expect to see a 7-10% AP increase in the area=medium category when going from 224×320 to 288×384 and an additional 7-10% AP when you choose 320×448. The accuracy for area=large remains almost the same across these resolutions, so you can stick to a lower resolution if this is what you need. As per the COCO keypoint evaluation, medium area is defined as persons occupying less than area between 36^2 to 96^2. Anything higher is categorized as large.
We use a default size 288×384 in this post. To use a different resolution, you need the following changes:
Update the env variables mentioned in INT8 quantization with the desired shape.
Update the input_shape in infer_spec_retrained_strict.yaml, which enables you to do a sanity evaluation of the exported TRT model. By default, it is set to [288, 384].
The height and width should be a multiple of 8, preferably a multiple of 16/32/64.
Number of refinement stages in the network
Figure 1 shows that the model architecture includes refinement stages, where each stage refines the results of the previous stage. You can use the stages parameter under the model section to configure this. stages include both the initial prediction stage and the refinement stages. We recommend using a minimum of one refinement stage, and a maximum of six, which corresponds to stages within the range [2, 7].
When you use more stages of refinement, it may help improve the accuracy but keep in mind that this would result in an increased inference time. We use a default of two refinement stages (stages=3) in this post, which is tuned for optimal performance and accuracy. For even faster performance, use stages=2.
Pruning and regularization
Pruning can help with a significant decrease in the number of parameters and maximize speed while preserving the accuracy or at the cost of some drop in accuracy. A higher pruning threshold gives you a smaller model and thus higher inference speed but might cause a drop in accuracy.
The threshold to use depends on the dataset. If the retrain accuracy is good, you can increase this value to get smaller models. Otherwise, lower this value to get better accuracy. We recommend iterating with the prune-retrain cycle until you are satisfied with the accuracy-speed tradeoff. You can also use a higher L1 regularization weight when training the model before pruning. It would push more weights towards zero, making it easier to prune the network weights.
Model accuracy and performance
In this section, we dive deeper into the model accuracy and performance, and compare it against the state of the art, and across platforms.
Comparison with OpenPose
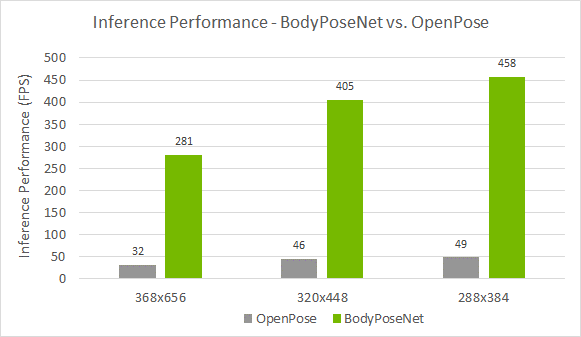
We compare this approach against OpenPose as this method follows a similar single-shot bottom-up methodology. Figure 4 shows that you achieve a much better accuracy-performance tradeoff as compared to the OpenPose model. The accuracy is lower by ~8% AP whereas you achieve close to a 9x speedup for the model trained with the default parameters provided in this post.
Figure 4. Model accuracy of BodyPoseNet compared to OpenPose
Figure 5. Inference performance of BodyPoseNet compared to OpenPose on NVIDIA RTX 2080
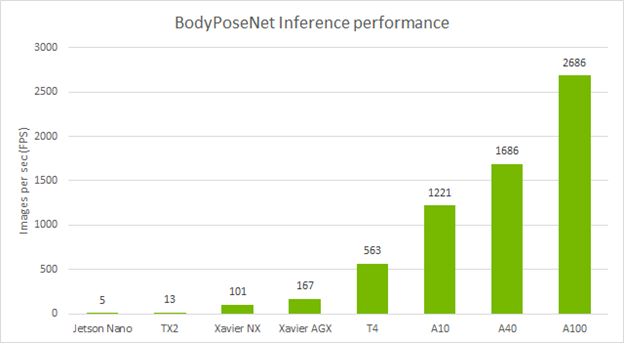
Standalone performance across devices
The following table shows the inference performance of the BodyPoseNet model trained with TLT by using the default parameters. We profiled the model inference with the trtexec command of TensorRT.
Figure 6. Inference performance (FPS) of BodyPoseNet across various NVIDIA platforms
Conclusion
In this post, you learned about optimizing body pose models using the BodyPoseNet app in TLT. The post showed taking an open-source COCO dataset with a pretrained backbone from NGC to train and optimize a model with TLT. For information regarding model deployment, see the TLT CV inference pipeline Quick Start Scripts and Deployment instructions.
With this model, you can get up to 9x improvement in inference performance as compared to OpenPose, helping you achieve real-time performance even on embedded devices. Pruning plus INT8 precision gives you the highest inference performance on your edge devices.
For more information, see the following resources:
It’s time for autonomous vehicle developers to blaze new trails. NVIDIA has agreed to acquire DeepMap, a startup dedicated to building high-definition maps for autonomous vehicles to navigate the world safely. “The acquisition is an endorsement of DeepMap’s unique vision, technology and people,” said Ali Kani, vice president and general manager of Automotive at NVIDIA. “DeepMap is expected to extend our mapping products, help us Read article >
I am finishing up my CS program but have no interest in anything other than machine learning. Do you think getting the developer cert would be enough for applying to internships/jobs? TIA
Arnab Bose and Yuheng Kuang, Staff Software Engineers, Robotics at Google
Disciplines in the natural sciences, social sciences, and medicine all have to grapple with how to evaluate and compare results within the context of the continually changing real world. In contrast, a significant body of machine learning (ML) research uses a different method that relies on the assumption of a fixed world: measure the performance of a baseline model on fixed data sets, then build a new model aimed at improving on the baseline, and evaluate its performance (on the same fixed data) by comparing its performance to the baseline.
Research into robotics systems and their applications to the real world requires a rethinking of this experiment design. Even in controlled robotic lab environments, it is possible that real-world changes cause the baseline model to perform inconsistently over time, making it unclear whether new models’ performance is an improvement compared to the baseline, or just the result of unintentional, random changes in the experiment setup. As robotics research advances into more complex and challenging real-world scenarios, there is a growing need for both understanding the impact of the ever-changing world on baselines and developing systematic methods to generate informative and clear results.
In this post, we demonstrate how robotics research, even in the relatively controlled environment of a lab, is meaningfully affected by changes in the environment, and discuss how to address this fundamental challenge using random assignment and A/B testing. Although these are classical research methods, they are not generally employed by default in robotics research — yet, they are critical to producing meaningful and measurable scientific results for robotics in real-world scenarios. Additionally, we cover the costs, benefits, and other considerations of using these methods.
The Ever-Changing Real World in Robotics Even in a robotics lab environment, which is designed to minimize all changes that are not experimental conditions, it is notoriously difficult to set up a perfectly reproducible experiment. Robots get bumped and are subject to wear and tear, lighting changes affect perception, battery charge influences the torque applied to motors — all things that can affect results in ways large and small.
To illustrate this on real robot data, we collected success rate data on one of our simplest setups — moving identical foam dice from one bin to another. For this task, we ran about 33k task trials on two robots over more than five months with the same software and ML model, and took the overall success rate of the last two weeks as baseline. We then measured the historic performance over time in this “very well controlled” environment.
Video of a real robot completing the task: moving identical foam dice from one bin to another.
Given that we did not purposefully change anything during data collection, one would expect the success rate to be statistically similar over time. And yet, this is not what was observed.
The y-axis represents the 95% confidence interval of % change in success rate relative to baseline. If the confidence intervals contain zero, that indicates the success rate is statistically similar to the success rate of baseline. Confidence intervals were computed using Jackknife, with Cochran-Mantel-Haenszel correction to remove operator bias.
Using the sequential data from the plot above, one might conclude that the model ran during weeks 13-14 performed best and that ran during weeks 9-10 performed the worst. One might also expect most, if not all, of the confidence intervals above to contain 0, but only one did. Because no changes were made at any time during these trials, this example effectively demonstrates the impact of unintentional, random real-world changes on even very simple setups. It’s also worth noting that having more trials per experiment wouldn’t remove these differences, instead they will more likely produce a narrower confidence interval making the impact more obvious.
However, what happens when one uses random assignment to compare results, grouping the data randomly rather than sequentially? To answer this, we randomly assigned the above data to the same number of groups for comparison with the baseline. This is equivalent to performing A/B testing where all groups receive the same treatment.
Looking at the chart, we observe that the confidence intervals include zero, indicating success similar to the baseline, as expected.
We performed similar studies with a few other robotics tasks, comparing between sequential and random assignments. They all yielded similar results.
We see that even with no intentional changes, there are statistically significant differences observed for sequential assignment, while random assignment shows the expected result of no statistically significant differences.
Considerations for A/B testing in robotics While it’s clear based on the above that A/B testing with random assignment is an effective way to control for the unexplainable variance of the real world in robotics, there are some considerations when adopting this approach. Here are several, along with their accompanying pros, cons, and solutions:
Absolute vs relative performance: Each experiment needs to be measured against a baseline that is run concurrently. The relative performance metric between baseline and experiment is published with a confidence interval. The absolute performance metric (in baseline or experiment) is less informative, because it depends to an unknown degree on the state of the world when the measurement was taken. However, the statistical differences we’ve measured between the experiment and baseline are sound and robust to reproduction.
Data efficiency:With this approach, the baseline always needs to run in parallel with the experimental conditions so they can be compared against each other. Although this may seem wasteful, it is worth the cost when compared against the drawbacks of making an invalid inference against a stale baseline. Furthermore, as the number of random assignment experiments scale up, we can use a single baseline arm with multiple simultaneous experiment arms across independent factors leveraging Google’s overlapping experiment infrastructure. Data efficiency improves with scale.
Environmental biases: If there’s any external factor affecting performance overall (lighting, slicker surfaces, etc.), both the baseline and all experiment arms will encounter this factor with similar probability, so its effect will cancel if there’s no relative impact. If there is a correlation between environmental factors and experiment arms, this will show up as differences over time (each environmental factor accumulates in the episodes collected). This can substantially reduce or eliminate the need for effortful environmental resets, and lets us run lifelong experiments and still measure improvements across experimental arms.
Human biases: One advantage of random assignment is a reduction in biases introduced by humans. Since human operators cannot know which data sample gets routed to which arm of the experiment, it is harder to have biased experimenters influence any particular outcome.
The Path Forward The A/B testing experiment framework has been successfully used for a long time in many scientific disciplines to measure performance against changing, unpredictable real-world environments. In this blog post, we show that robotics research can benefit from using this same methodology: it improves the quality and confidence of research results, and avoids the impossible task of perfectly controlling all elements of a fundamentally changing environment. Doing this well requires infrastructure to continuously operate robots, collect data, and tools to make the statistical framework easily accessible to researchers.
Acknowledgements Arnab Bose, Tuna Toksoz, Yuheng Kuang, Anthony Brohan, Razvan Sudulescu developed the experiment infrastructure and conducted the research. Matthieu Devin suggested the A/A analysis to showcase the differences using existing data. Special thanks to Bill Heavlin, Chris Harris, Vincent Vanhoucke who provided invaluable feedback and support to the work.
Posted by Joel Shor, Software Engineer, Google Research, Tokyo and Sachin Joglekar, Software Engineer, TensorFlow
Representation learning is a machine learning (ML) method that trains a model to identify salient features that can be applied to a variety of downstream tasks, ranging from natural language processing (e.g., BERT and ALBERT) to image analysis and classification (e.g., Inception layers and SimCLR). Last year, we introduced a benchmark for comparing speech representations and a new, generally-useful speech representation model (TRILL). TRILL is based on temporal proximity, and tries to map speech that occurs close together in time to a lower-dimensional embedding that captures temporal proximity in the embedding space. Since its release, the research community has used TRILL on a diverse set of tasks, such as age classification, video thumbnail selection, and language identification. However, despite achieving state-of-the-art performance, TRILL and other neural network-based approaches require more memory and take longer to compute than signal processing operations that deal with simple features, like loudness, average energy, pitch, etc.
In our recent paper “FRILL: A Non-Semantic Speech Embedding for Mobile Devices“, to appear at Interspeech 2021, we create a new model that is 40% the size of TRILL and and a feature set that can be computed over 32x faster on mobile phone, with an average decrease in accuracy of less than 2%. This marks an important step towards fully on-device applications of speech ML models, which will lead to better personalization, improved user experiences and greater privacy, an important aspect of developing AI responsibly. We release the code to create FRILL on github, and a pre-trained FRILL model on TensorFlow Hub.
FRILL: Smaller, Faster TRILL The TRILL architecture is based on a modified version of ResNet50, an architecture that is computationally taxing for constrained hardware, like mobile phones or smart home devices. On the other hand, architectures like MobileNetV3 have been designed with hardware-aware AutoML to perform well on mobile devices. To take advantage of this, we leverage knowledge distillation to combine the benefits of MobileNetV3’s performance with TRILL’s representations.
In the distillation process, the smaller model (i.e., the “student”) tries to match the output of the larger model (“teacher”) on the AudioSet dataset. Whereas the original TRILL model learned its weights by optimizing a self-supervised loss that clustered audio segments close in time, the student model learns its weights through a fully-supervised loss that ignores temporal matching and instead tries to match TRILL outputs on the training data. The fully-supervised learning signal is often stronger than self-supervision, and allows us to train more quickly.
Knowledge distillation for non-semantic speech embeddings. The dashed line shows the student model output. The “teacher network” is the TRILL network, where “Layer 19” was the best-performing internal representation. The “Student Hyperparameters” on the left are the options explored in this study, the result of which are 144 distinct models. These models were trained with mean-squared error (MSE) to try to match TRILL’s Layer 19.
Choosing the Best Student Model We perform distillation with a variety of student models, each trained with a specific combination of architecture choices (explained below). To measure each student model’s latency, we leverage TensorFlow Lite (TFLite), a framework that enables execution of TensorFlow models on edge devices. Each candidate model is first converted into TFLite’s flatbuffer format for 32-bit floating point inference and then sent to the target device (in this case, a Pixel 1) for benchmarking. These measurements help us to accurately assess the latency versus quality tradeoffs across all student models and to minimize the loss of quality in the conversion process.
Architecture Choices and Optimizations We explored different neural network architectures and features that balance latency and accuracy — models with fewer parameters are usually smaller and faster, but have less representational power and therefore generate less generally-useful representations. We trained 144 different models across a number of hyperparameters, all based on the MobileNetV3 architecture:
MobileNetV3 size and width: MobileNetV3 was released in different sizes for use in different environments. The size refers to which MobileNetV3 architecture we used. The width, sometimes known as alpha, proportionally decreases or increases the number of filters in each layer. A width of 1.0 corresponds to the number of filters in the original paper.
Global average pooling: MobileNetV3 normally produces a set of two-dimensional feature maps. These are flattened, concatenated, and passed to the bottleneck layer. However, this bottleneck is often still too large to be computed quickly. We reduce the size of the bottleneck layer kernel by taking the global average of all ”pixels” in each output feature map. Our intuition is that the discarded temporal information is less important for learning a non-semantic speech representation due to the fact that relevant aspects of the signal are stable across time.
Quantization-aware training: Since the bottleneck layer has most of the model weights, we use quantization-aware training (QAT) to gradually reduce the numerical precision of the bottleneck weights during training. QAT allows the model to adjust to the lower numerical precision during training, instead of potentially causing performance degradation by introducing quantization after training finishes.
Results We evaluated each of these models on the Non-Semantic Speech Benchmark (NOSS) and two new tasks — a challenging task to detect whether a speaker is wearing a mask and the human-noise subset of the Environment Sound Classification dataset, which includes labels like “coughing” and “sneezing”. After eliminating models that have strictly better alternatives, we are left with eight ”frontier” models on the quality vs. latency curve, which are the models that had no faster and better performance alternatives at a corresponding quality threshold or latency in our batch of 144 models. We plot the latency vs. quality curve of only these “frontier” models below, and we ignore models that are strictly worse.
Embedding quality and latency tradeoff. The x-axis represents the inference latency and the y-axis shows the difference in accuracy from TRILL’s performance, averaged across benchmark datasets.
FRILL is the best performing sub-10ms inference model, with an inference time of 8.5 ms on a Pixel 1 (about 32x faster than TRILL), and is also roughly 40% the size of TRILL. The frontier curve plateaus at about 10ms latency, which means that at low latency, one can achieve much better performance with minimal latency costs, while achieving improved performance at latencies beyond 10ms is more difficult. This supports our choice of experiment hyperparameters. FRILL’s per-task performance is shown in the table below.
Accuracy on each of the classification tasks (higher is better). *Results in our study use a small subset of Voxceleb1 filtered according to internal privacy guidelines. Interested readers can run our study on the full dataset using TensorFlow Datasets and our open-source evaluation code.
Finally, we evaluate the relative contribution of each of our hyperparameters. We find that for our experiments, quantization-aware training, bottleneck compression and global average pooling most reduced the latency of the resulting models. At the same time bottleneck compression most reduced the quality of the resulting model, while pooling reduced the model performance the least. The architecture width parameter was an important factor in reducing the model size, with minimal performance degradation.
Linear regression weight magnitudes for predicting model quality, latency, and size. The weights indicate the expected impact of changing the input hyperparameter. A higher weight magnitude indicates a greater expected impact.
Our work is an important step in bringing the full benefits of speech machine learning research to mobile devices. We also provide our public model, corresponding model card, and evaluation code to help the research community responsibly develop even more applications for on-device speech representation research.
Acknowledgements We’d like to thank our paper co-authors: Jacob Peplinksi and Shwetak Patel. We’d like to thank Aren Jansen for his technical support on this project, Françoise Beaufays, and Tulsee Doshi for help open sourcing the model, and Google Research, Tokyo for logistical support.

 Human pose estimation is a popular computer vision task of estimating key points on a person’s body such as eyes, arms, and legs. This can help classify a person’s actions, such as standing, sitting, walking, lying down, jumping, and so on. Understanding the context of what a person might be doing in a scene has …
Human pose estimation is a popular computer vision task of estimating key points on a person’s body such as eyes, arms, and legs. This can help classify a person’s actions, such as standing, sitting, walking, lying down, jumping, and so on. Understanding the context of what a person might be doing in a scene has …