
Hey all!
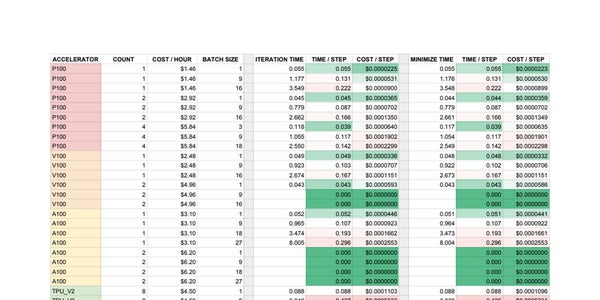
I’m currently doing some tests in preparation for my first real bit of training. I’m using Google Cloud AI Platform to train, and am trying to find the optimal machine setup. It’s a work in progress, but here’s a table I’m putting together to get a sense of the efficiency of each setup. On the left you’ll see the accelerator type, ordered from least to most expensive. Here you’ll also find the number of accelerator’s used, the cost per hour, and the batch size. To the right are the average time it took to complete an entire training iteration and how long it took to complete the minimization step. You’ll notice that the values are almost identical for each setup; I’m using Google Research’s SEED RL, so I thought to record both values since I’m not sure exactly everything that happens between iterations. Turns out it’s not much. There’s also a calculation of the the time it takes to complete a single “step” (aka, a single observation from a single environment), as well as the average cost per step.
So, the problem. I was under the assumption that batching with a GPU or TPU would increase the efficiency of the training. Instead, it turns out that a batch size of 1 is the most efficient both in time per step and cost per step. I’m still fairly new to ML so maybe it’s just a matter of me being uninformed, but this goes against everything I thought I knew about ML training. Since I’m using Google’s own SEED codebase I would assume that it’s not a problem with the code, but I can’t be sure about that.
Is this just a matter of me misunderstanding how training works, or am I right in thinking something is really off?
submitted by /u/EdvardDashD
[visit reddit] [comments]