
 Most CUDA developers are familiar with the cudaMalloc and cudaFree API functions to allocate GPU accessible memory. However, there has long been an obstacle with these API functions: they aren’t stream ordered. In this post, we introduce new API functions, cudaMallocAsync and cudaFreeAsync, that enable memory allocation and deallocation to be stream-ordered operations. In part … Continued
Most CUDA developers are familiar with the cudaMalloc and cudaFree API functions to allocate GPU accessible memory. However, there has long been an obstacle with these API functions: they aren’t stream ordered. In this post, we introduce new API functions, cudaMallocAsync and cudaFreeAsync, that enable memory allocation and deallocation to be stream-ordered operations. In part … Continued
Most CUDA developers are familiar with the cudaMalloc and cudaFree API functions to allocate GPU accessible memory. However, there has long been an obstacle with these API functions: they aren’t stream ordered. In this post, we introduce new API functions, cudaMallocAsync and cudaFreeAsync, that enable memory allocation and deallocation to be stream-ordered operations.
In part 2 of this series, we highlight the benefits of this new capability by sharing some big data benchmark results and provide a code migration guide for modifying your existing applications. We also cover advanced topics to take advantage of stream-ordered memory allocation in the context of multi-GPU access and the use of IPC. This all helps you improve performance within your existing applications.
Stream ordering efficiency
The following code example on the left is inefficient because the first cudaFree call has to wait for kernelA to finish, so it synchronizes the device before freeing the memory. To make this run more efficiently, the memory can be allocated upfront and sized to the larger of the two sizes, as shown on the right.
cudaMalloc(&ptrA, sizeA); kernelA>>(ptrA); cudaFree(ptrA); // Synchronizes the device before freeing memory cudaMalloc(&ptrB, sizeB); kernelB>>(ptrB); cudaFree(ptrB);
cudaMalloc(&ptr, max(sizeA, sizeB)); kernelA>>(ptr); kernelB>>(ptr); cudaFree(ptr);
This increases code complexity in the application because the memory management code is separated out from the business logic. The problem is exacerbated when other libraries are involved. For example, consider the case where kernelA is launched by a library function instead:
libraryFuncA(stream);
cudaMalloc(&ptrB, sizeB);
kernelB>>(ptrB);
cudaFree(ptrB);
void libraryFuncA(cudaStream_t stream) {
cudaMalloc(&ptrA, sizeA);
kernelA>>(ptrA);
cudaFree(ptrA);
}
This is much harder for the application to make efficient because it may not have complete visibility or control over what the library is doing. To circumvent this problem, the library would have to allocate memory when that function is invoked for the first time and never free it until the library is deinitialized. This not only increases code complexity, but it also causes the library to hold on to the memory longer than it needs to, potentially denying another portion of the application from using that memory.
Some applications take the idea of allocating memory upfront even further by implementing their own custom allocator. This adds a significant amount of complexity to application development. CUDA aims to provide a low-effort, high-performance alternative.
CUDA 11.2 introduced a stream-ordered memory allocator to solve these types of problems, with the addition of cudaMallocAsync and cudaFreeAsync. These new API functions shift memory allocation from global-scope operations that synchronize the entire device to stream-ordered operations that enable you to compose memory management with GPU work submission. This eliminates the need for synchronizing outstanding GPU work and helps restrict the lifetime of the allocation to the GPU work that accesses it. Consider the following code example:
cudaMallocAsync(&ptrA, sizeA, stream); kernelA>>(ptrA); cudaFreeAsync(ptrA, stream); // No synchronization necessary cudaMallocAsync(&ptrB, sizeB, stream); // Can reuse the memory freed previously kernelB>>(ptrB); cudaFreeAsync(ptrB, stream);
It is now possible to manage memory at function scope, as in the following example of a library function launching kernelA.
libraryFuncA(stream);
cudaMallocAsync(&ptrB, sizeB, stream); // Can reuse the memory freed by the library call
kernelB>>(ptrB);
cudaFreeAsync(ptrB, stream);
void libraryFuncA(cudaStream_t stream) {
cudaMallocAsync(&ptrA, sizeA, stream);
kernelA>>(ptrA);
cudaFreeAsync(ptrA, stream); // No synchronization necessary
}
Stream-ordered allocation semantics
All the usual stream-ordering rules apply to cudaMallocAsync and cudaFreeAsync. The memory returned from cudaMallocAsync can be accessed by any kernel or memcpy operation as long as the kernel or memcpy is ordered to execute after the allocation operation and before the deallocation operation, in stream order. Deallocation can be performed in any stream, as long as it is ordered to execute after the allocation operation and after all accesses on all streams of that memory on the GPU.
In effect, stream-ordered allocation behaves as if allocation and free were kernels. If kernelA produces a valid buffer on a stream and kernelB invalidates it on the same stream, then an application is free to access the buffer after kernelA and before kernelB in the appropriate stream order.
The following example shows various valid usages.
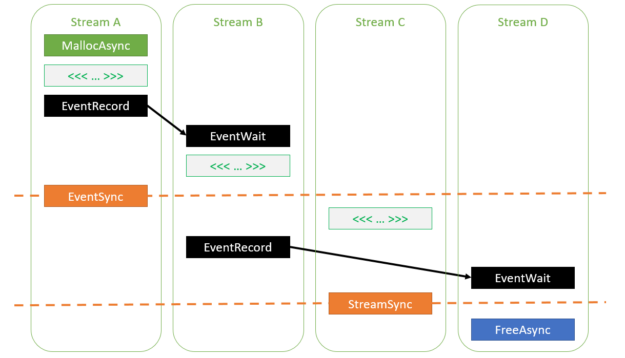
auto err = cudaMallocAsync(&ptr, size, streamA); // If cudaMallocAsync completes successfully, ptr is guaranteed to be // a valid pointer to memory that can be accessed in stream order assert(err == cudaSuccess); // Work launched in the same stream can access the memory because // operations within a stream are serialized by definition kernel>>(ptr); // Work launched in another stream can access the memory as long as // the appropriate dependencies are added cudaEventRecord(event, streamA); cudaStreamWaitEvent(streamB, event, 0); kernel>>(ptr); // Synchronizing the stream at a point beyond the allocation operation // also enables any stream to access the memory cudaEventSynchronize(event); kernel>>(ptr); // Deallocation requires joining all the accessing streams. Here, // streamD will be deallocating. // Adding an event dependency on streamB ensures that all accesses in // streamB will be done before the deallocation cudaEventRecord(event, streamB); cudaStreamWaitEvent(streamD, event, 0); // Synchronizing streamC also ensures that all its accesses are done before // the deallocation cudaStreamSynchronize(streamC); cudaFreeAsync(ptr, streamD);
Figure 1 shows the various dependencies specified in the earlier code example. As you can see, all kernels are ordered to execute after the allocation operation and complete before the deallocation operation.
Memory allocation and deallocation cannot fail asynchronously. Memory errors that occur because of a call to cudaMallocAsync or cudaFreeAsync (for example, out of memory) are reported immediately through an error code returned from the call. If cudaMallocAsync completes successfully, the returned pointer is guaranteed to be a valid pointer to memory that is safe to access in the appropriate stream order.
err = cudaMallocAsync(&ptr, size, stream);
if (err != cudaSuccess) {
return err;
}
// Now you’re guaranteed that ‘ptr’ is valid when the kernel executes on stream
kernel>>(ptr);
cudaFreeAsync(ptr, stream);
The CUDA driver uses memory pools to achieve the behavior of returning a pointer immediately.
Memory pools
The stream-ordered memory allocator introduces the concept of memory pools to CUDA. A memory pool is a collection of previously allocated memory that can be reused for future allocations. In CUDA, a pool is represented by a cudaMemPool_t handle. Each device has a notion of a default pool whose handle can be queried using cudaDeviceGetDefaultMemPool.
You can also explicitly create your own pools and either use them directly or set them as the current pool for a device and use them indirectly. Reasons for explicit pool creation include custom configuration, as described later in this post. When no explicitly created pool has been set as the current pool for a device, the default pool acts as the current pool.
When called without an explicit pool argument, each call to cudaMallocAsync infers the device from the specified stream and attempts to allocate memory from that device’s current pool. If the pool has insufficient memory, the CUDA driver calls into the OS to allocate more memory. Each call to cudaFreeAsync returns memory to the pool, which is then available for re-use on subsequent cudaMallocAsync requests. Pools are managed by the CUDA driver, which means that applications can enable pool sharing between multiple libraries without those libraries having to coordinate with each other.
If a memory allocation request made using cudaMallocAsync can’t be serviced due to fragmentation of the corresponding memory pool, the CUDA driver defragments the pool by remapping unused memory in the pool to a contiguous portion of the GPU’s virtual address space. Remapping existing pool memory instead of allocating new memory from the OS also helps keep the application’s memory footprint low.
By default, unused memory accumulated in the pool is returned to the OS during the next synchronization operation on an event, stream, or device, as the following code example shows.
cudaMallocAsync(ptr1, size1, stream); // Allocates new memory into the pool kernel>>(ptr); cudaFreeAsync(ptr1, stream); // Frees memory back to the pool cudaMallocAsync(ptr2, size2, stream); // Allocates existing memory from the pool kernel>>(ptr2); cudaFreeAsync(ptr2, stream); // Frees memory back to the pool cudaDeviceSynchronize(); // Frees unused memory accumulated in the pool back to the OS // Note: cudaStreamSynchronize(stream) achieves the same effect here
Retaining memory in the pool
Returning memory from the pool to the system can affect performance in some cases. Consider the following code example:
for (int i = 0; i >>(ptr); cudaFreeAsync(ptr, stream); cudaStreamSynchronize(stream); }
By default, stream synchronization causes any pools associated with that stream’s device to release all unused memory back to the system. In this example, that would happen at the end of every iteration. As a result, there is no memory to reuse for the next cudaMallocAsync call and instead memory must be allocated through an expensive system call.
To avoid this expensive reallocation, the application can configure a release threshold to enable unused memory to persist beyond the synchronization operation. The release threshold specifies the maximum amount of memory the pool caches. It releases all excess memory back to the OS during a synchronization operation.
By default, the release threshold of a pool is zero. This means that allunused memory in the pool is released back to the OS during every synchronization operation. The following code example shows how to change the release threshold.
cudaMemPool_t mempool; cudaDeviceGetDefaultMemPool(&mempool, device); uint64_t threshold = UINT64_MAX; cudaMemPoolSetAttribute(mempool, cudaMemPoolAttrReleaseThreshold, &threshold); for (int i = 0; i >>(ptr); cudaFreeAsync(ptr, stream); cudaStreamSynchronize(stream); // Only releases memory down to “threshold” bytes }
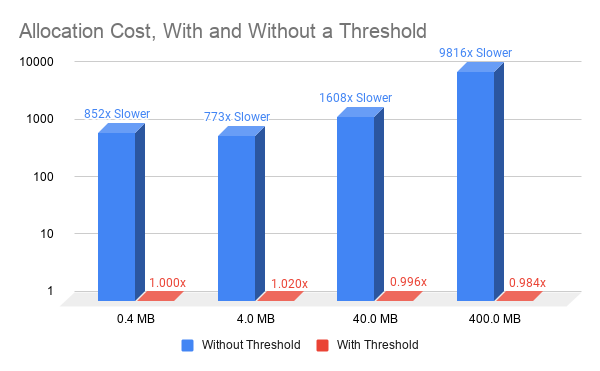
Using a nonzero release threshold enables reusing memory from one iteration to the next. This requires only simple bookkeeping and makes the performance of cudaMallocAsync independent of the size of the allocation, which results in dramatically improved memory allocation performance (Figure 2).
The pool threshold is just a hint. Memory in the pool can also be released implicitly by the CUDA driver to enable an unrelated memory allocation request in the same process to succeed. For example, a call to cudaMalloc or cuMemCreate could cause CUDA to free unused memory from any memory pool associated with the device in the same process to serve the request.
This is especially helpful in scenarios where an application makes use of multiple libraries, some of which use cudaMallocAsync and some that do not. By automatically freeing up unused pool memory, those libraries do not have to coordinate with each other to have their respective allocation requests succeed.
There are limitations to when the CUDA driver automatically reassigns memory from a pool to unrelated allocation requests. For example, the application may be using a different interface, like Vulkan or DirectX, to access the GPU, or there may be more than one process using the GPU at the same time. Memory allocation requests in those contexts do not cause automatic freeing of unused pool memory. In such cases, the application may have to explicitly free unused memory in the pool, by invoking cudaMemPoolTrimTo.
size_t bytesToKeep = 0; cudaMemPoolTrimTo(mempool, bytesToKeep);
The bytesToKeep argument tells the CUDA driver how many bytes it can retain in the pool. Any unused memory that exceeds that size is released back to the OS.
Better performance through memory reuse
The stream parameter to cudaMallocAsync and cudaFreeAsync helps CUDA reuse memory efficiently and avoid expensive calls into the OS. Consider the following trivial code example.
cudaMallocAsync(&ptr1, size1, stream); kernelA>>(ptr1); cudaFreeAsync(ptr1, stream); cudaMallocAsync(&ptr2, size2, stream); kernelB>>(ptr2);
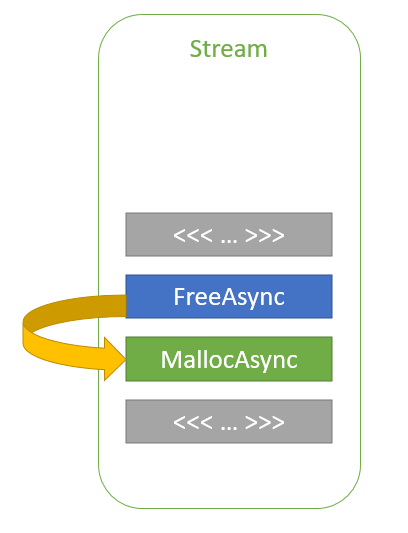
In this code example, ptr2 is allocated in stream order after ptr1 is freed. The ptr2 allocation could reuse some, or all, of the memory that was used for ptr1 without any synchronization, because kernelA and kernelB are launched in the same stream. So, stream-ordering semantics guarantee that kernelB cannot begin execution and access the memory until kernelA has completed. This way, the CUDA driver can help keep the memory footprint of the application low while also improving allocation performance.
The CUDA driver can also follow dependencies between streams inserted through CUDA events, as shown in the following code example:
cudaMallocAsync(&ptr1, size1, streamA); kernelA>>(ptr1); cudaFreeAsync(ptr1, streamA); cudaEventRecord(event, streamA); cudaStreamWaitEvent(streamB, event, 0); cudaMallocAsync(&ptr2, size2, streamB); kernelB>>(ptr2);
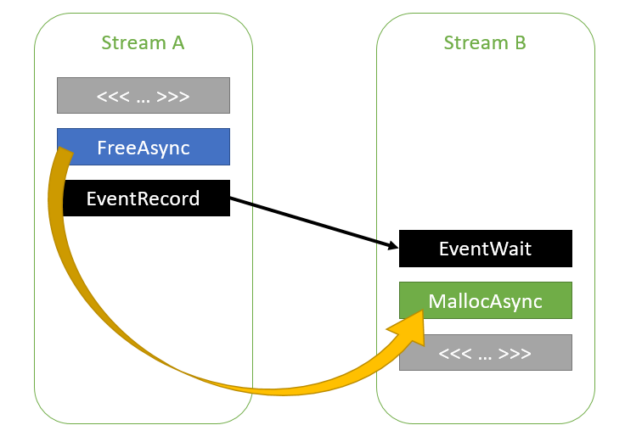
As the CUDA driver is aware of the dependency between streams A and B, it can reuse the memory used by ptr1 for ptr2. The dependency chain between streams A and B can contain any number of streams, as shown in the following code example.
cudaMallocAsync(&ptr1, size1, streamA); kernelA>>(ptr1); cudaFreeAsync(ptr1, streamA); cudaEventRecord(event, streamA); for (int i = 0; i >>(ptr2);
If necessary, the application can disable this feature on a per-pool basis:
int enable = 0; cudaMemPoolSetAttribute(mempool, cudaMemPoolReuseFollowEventDependencies, &enable);
The CUDA driver can also reuse memory opportunistically in the absence of explicit dependencies specified by the application. While such heuristics may help improve performance or avoid memory allocation failures, they can add nondeterminism to the application and so can be disabled on a per-pool basis. Consider the following code example:
cudaMallocAsync(&ptr1, size1, streamA); kernelA>>(ptr1); cudaFreeAsync(ptr1); cudaMallocAsync(&ptr2, size2, streamB); kernelB>>(ptr2); cudaFreeAsync(ptr2);
In this scenario, there are no explicit dependencies between streamA and streamB. However, the CUDA driver is aware of how far each stream has executed. If, on the second call to cudaMallocAsync in streamB, the CUDA driver determines that kernelA has finished execution on the GPU, then it can reuse some or all of the memory used by ptr1 for ptr2.
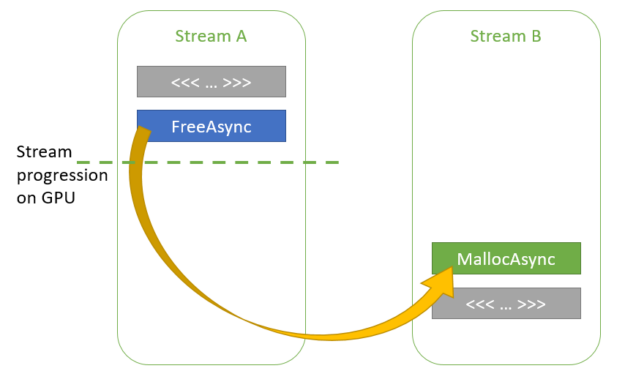
If kernelA has not finished execution, the CUDA driver can add an implicit dependency between the two streams such that kernelB does not begin executing until kernelA finishes.
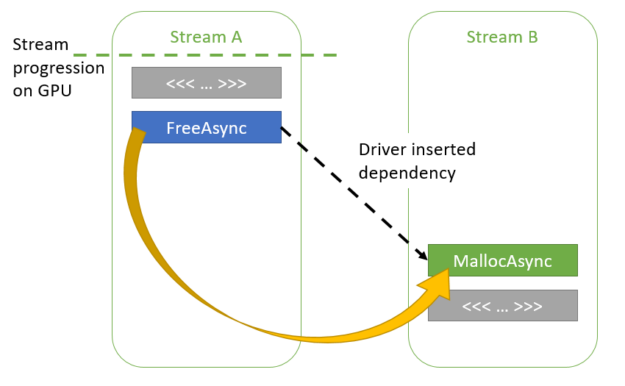
The application can disable these heuristics as follows:
int enable = 0; cudaMemPoolSetAttribute(mempool, cudaMemPoolReuseAllowOpportunistic, &enable); cudaMemPoolSetAttribute(mempool, cudaMemPoolReuseAllowInternalDependencies, &enable);
Summary
In part 1 of this series, we introduced the new API functions cudaMallocAsync and cudaFreeAsync , which enable memory allocation and deallocation to be stream-ordered operations. Use them to avoid expensive calls to the OS through memory pools maintained by the CUDA driver.
In part 2 of this series, we share some benchmark results to show the benefits of stream-ordered memory allocation. We also provide a step-by-step recipe for modifying your existing applications to take full advantage of this advanced CUDA capability.