I made the transfer learning model in Tensorflow python with the pretrained model Mobilenet V2, it performed so great in python even when I predicted. After that, I save the model to keras h5 format and convert it to tensorflow.js model. Then I create a static page that implements the tensorflow.js model and run it with Web Server for Chrome in Chrome browser. The prediction result I got is really confusing as the result was always the same one, no matter that I changed the image to be predicted. Any inputs, suggestion and solutions on this problem are highly appreciated. Thanks in advance!
Deathtrap Dungeon: The Golden Room is a gripping choose-your-own-adventure story, but it’s no page-turner. Based on the best-selling book of the same name, it’s an interactive film in which viewers become the player on their quest to find The Golden Room while facing down dungeon masters and avoiding traps. NVIDIA RTX technology powers the real-time Read article >
Relying on the capabilities of GPUs, a team from Facebook AI Research has developed a faster, more efficient way for AI to run similarity searches. The study, published in IEEE Transactions on Big Data, creates a deep learning algorithm capable of handling and comparing high-dimensional data from media that is notably faster, while just as … Continued
Relying on the capabilities of GPUs, a team from Facebook AI Research has developed a faster, more efficient way for AI to run similarity searches. The study, published in IEEE Transactions on Big Data, creates a deep learning algorithm capable of handling and comparing high-dimensional data from media that is notably faster, while just as accurate as previous techniques.
In a world with an ever-growing supply of data, the work promises to ease both the compute power and time needed for processing large libraries.
“The most straightforward technique for searching and indexing [high-dimensional data] is by brute-force comparison, whereby you need to check [each image] against every other image in the database. This is impractical for collections containing billions of vectors,” Jeff Johnson, study colead and a research engineer at Facebook, said in a press release.
Containing millions of pixels and data points, every image and video creates billions of vectors. This large amount of data is valuable for analyzing, detecting, indexing, and comparing vectors. It is also problematic for calculating similarities of large libraries with traditional CPU algorithms that rely on several supercomputer components, slowing down overall computing time.
Using only four GPUs with CUDA, the researchers designed an algorithm for GPUs to both host and analyze library image data points. The method also compresses the data, making it easier, and thus faster to analyze.
An example of how the algorithm computes the smoothest path between images where only the first and the last image are given. Credit: Facebook/Johnson et al
The new algorithm processed over 95 million high-dimensional images in 35 minutes. A graph of a billion vectors took less than 12 hours to compute. According to a comparison test in the study, handling the same database with a cluster of 128 CPU servers took 108.7 hours-about 8.5x longer.
“By keeping computations purely on a GPU, we can take advantage of the much faster memory available on the accelerator, instead of dealing with the slower memories of CPU servers and even slower machine-to-machine network interconnects within a traditional supercomputer cluster,” said Johnson.
The researchers state the methods are already being applied to a wide variety of tasks, including a language processing search for translations. Known as the Facebook AI Similarity Search library, the approach is open source for implementation, testing, and comparison.
Developers, researchers, graphics professionals, and others from around the world will get a sneak peek at the latest innovations in computer graphics at the SIGGRAPH 2021 virtual conference, taking place August 9-13.
Developers, researchers, graphics professionals, and others from around the world will get a sneak peek at the latest innovations in computer graphics at the SIGGRAPH 2021 virtual conference, taking place August 9-13.
NVIDIA will be presenting the breakthroughs that NVIDIA RTX technology delivers, from real-time ray tracing to AI-enhanced workflows.
Watch the NVIDIA special address on Tuesday, August 10 at 8:00 a.m. PDT, where we will showcase the latest tools and solutions that are driving graphics, AI, and the emergence of shared worlds.
And on Wednesday, August 11, catch the global premiere of “Connecting in the Metaverse: The Making of the GTC Keynote” at 11:00 a.m. PDT. The new documentary highlights the creative minds and groundbreaking technologies behind the NVIDIA GTC 2021 keynote. See how a small team of artists used NVIDIA Omniverse to blur the line between real and rendered.
Explore the Latest from NVIDIA Research
At SIGGRAPH, the NVIDIA Research team will be presenting the following papers:
Dive into Technical Training with NVIDIA Deep Learning Institute
Here’s a preview of some DLI sessions you don’t want to miss:
Omniverse 101: Getting Started with Universal Scene Description for Collaborative 3D Workflows
This free self-paced training provides an introduction to USD. Go through a series of hands-on exercises consisting of training videos accompanied by live scripted examples, and learn about concepts like layer composition, references and variants.
Fundamentals of Ray Tracing Development using NVIDIA Nsight Graphics and NVIDIA Nsight Systems
With NVIDIA RTX and real-time ray-tracing APIs like DXR and Vulkan Ray Tracing, see how it’s now easier than ever to create stunning visuals at interactive frame rates. This instructor-led workshop will show audiences how to utilize NVIDIA Nsight graphics and NVIDIA Nsight Systems to profile and optimize 3D applications that are using ray tracing. Space is limited.
Graphics and Omniverse Teaching Kit
Designed for college and university educators looking to bring graphics and NVIDIA Omniverse into the classroom, this teaching kit includes downloadable teaching materials and online courses that provide the foundation for understanding and building hands-on expertise in graphics and Omniverse.
Discover the Latest Tools and Solutions in Our Virtual Demos
We’ll be showcasing how NVIDIA technology is transforming workflows in some of our exciting demos, including:
Factory of the Future: Explore the next era of manufacturing with this demo, which showcases BMW Group’s factory of the future – designed, simulated, operated, and maintained entirely in NVIDIA Omniverse.
Multiple Artists, One Server: See how teams can accelerate visual effects production with the NVIDIA EGX Platform, which enables multiple artists to work together on a powerful, secure server from anywhere.
3D Photogrammetry on an RTX Mobile Workstation: Watch how NVIDIA RTX-powered mobile workstations help drive the process of 3D scanning using photogrammetry, whether in a studio or in a remote location.
Interactive volumes with NanoVDB in Blender Cycles: Learn how NanoVDB makes volume rendering more GPU memory efficient, meaning larger and more complex scenes can be interactively adjusted and rendered with NVIDIA RTX-accelerated ray tracing and AI denoising.
Enter for a Chance to Win Some Gems
Attendees can win a limited-edition hard copy ofRay Tracing Gems II, the follow up to 2019’s Ray Tracing Gems.
Ray Tracing Gems II brings the community of rendering experts back together to share their knowledge. The book covers everything in ray tracing and rendering, from basic concepts geared toward beginners to full ray tracing deployment in shipping AAA games.
Join NVIDIA at SIGGRAPH and learn more about the latest tools and technologies driving real-time graphics, AI-enhanced workflows, and virtual collaboration.
This GFN Thursday shines a spotlight on the latest games joining the collection of over 1,000 titles in the GeForce NOW library from the many publishers that have opted in to stream their games on our open cloud-gaming service. Members can look forward to 14 games — including Evil Genius 2: World Domination from Rebellion Read article >
Developed by XeloGames, an indie studio of just three, and published by Headup Games, Escape from Naraka achieves eye-catching ray-traced lighting using RTXGI and significant performance boosts from DLSS.
Developed by XeloGames, an indie studio of just three, and published by Headup Games, Escape from Naraka achieves eye-catching ray-traced lighting using RTX Global Illumination (RTXGI) and significant performance boosts from Deep Learning Super Sampling (DLSS). NVIDIA had the opportunity to speak with the XeloGames team about their experience using NVIDIA’s SDKs while developing their debut title.
“We believe that, sooner or later, everyone will have ray tracing,” XeloGames said, discussing their motivation to use RTXGI, “so it’s really good for us to start earlier, especially in Indonesia.”
Starting early, in this case, is an understatement for XeloGames. Escape from Naraka is actually the first-ever ray tracing title from Indonesia; the team used ray-traced reflections, shadows, and global illumination to paint a dramatic labyrinth for the player to explore.
Such a feat, executed by such a small studio, speaks to the usefulness of RTXGI as a tool for development. Escape from Naraka was made in Unreal Engine 4, using NVIDIA’s NvRTX branch to bring ray tracing and DLSS into production. Once ray-traced global illumination was integrated into the engine, XeloGames reported benefits they immediately experienced:
“RTXGI really helps with how quick you can set up a light in a scene. Instead of the old ways where you have to manually adjust every light, you can put in a Dynamic Diffuse Global Illumination (DDGI) volume and immediately see a difference.”
Rapid in-engine updates expedited the task of lighting design in Escape from Naraka, alongside the ability to make any object emissive for “cost-free performance lighting”, XeloGames added. Of course, implementing RTXGI in their title came with its challenges as well. For Escape from Naraka specifically, a unique obstacle presented itself; the abundance of rocks in their level design often made it challenging to find opportunities to make full use of ray-traced lighting. “Rocks are not really that great at bouncing lights around”, XeloGames developers remarked.
RTXGI is undoubtedly a powerful tool to have in a game developers toolkit, but the mileage that can be achieved with its features can vary case-by-case. An important step before using ray traced global illumination is deciding if it’s features are a right fit for your game.
Regardless of the rock conflict (mitigated by making certain textures emissive to brighten darker areas) and a couple of bugs that had to be squashed along the way, XeloGames’ three person team was able to achieve a beautiful integration of RTXGI in Escape from Naraka. Check out the Escape from Naraka Official RTX Reveal Trailer for a look at how RTX Global Illumination was able to enhance the game’s visual appeal:
“It definitely made scenes look more natural,” said XeloGames developer on the enhancements RTXGI brought to their game, “lights bounce around more naturally instead of just directly.”
The results of global illumination can speak for themselves, pairing excellently with ray-traced reflection and shadows for stunning results.
RTXGI is not the only NVIDIA feature XeloGames packed into their newest release. Deep Learning Super Sampling (DLSS) is implemented as well to bring an AI-powered frame rate boost.
“Adding NVIDIA DLSS to the game was fast and easy with the UE4 plugin, providing our players maximum performance as they take on all the challenges Escape From Naraka has to offer.”
XeloGames reported a swift implementation of DLSS with NvRTX, emphasizing the importance of using DLSS as a frame booster as well as an enabler to turn ray tracing on with the performance headroom it provides. In concert, RTXGI and DLSS empower a rich and fully-immersive experience in Escape from Naraka.
AttributeError: ‘google.protobuf.pyext._message.RepeatedCompositeCo’ object has no attribute ‘_values’
Protobuf version=3.15 Mediapiper version=0.8.6 Tensorflow version=2.5.0 I have tried installing all the version in virtual environment but error won’t go away.
This chapter, written by Juha Sjöholm, Paula Jukarainen, and Tatu Aalto, presents how all ray tracing based effects were implemented in Remedy Entertainment’s Control.
Next week, Ray Tracing Gems II will finally be available in its entirety as a free download, or for purchase as a physical release from Apress or Amazon. Since the start of July, we’ve been providing early access to a new chapter every week. Today’s chapter, by Juha Sjöholm, Paula Jukarainen, and Tatu Aalto, presents how all ray tracing based effects were implemented in Remedy Entertainment’s Control. This includes opaque and transparent reflections, near field indirect diffuse illumination, contact shadows, and the denoisers tailored for these effects.
You can also learn more about Game of the Year Winner Control here.
We’ve collaborated with our partners to make limited edition versions of the book, including custom covers that highlight real-time ray tracing in Fortnite, Control, and Watch Dogs: Legion.
NVIDIA GTC21 had numerous great and engaging contents, especially around RAPIDS, so it would be easy to miss our debut presentation “Using RAPIDS to Accelerate Node.js JavaScript for Visualization and Beyond.” Yep – we are bringing the power of GPU accelerated data science to the JavaScript Node.js community with the Node-RAPIDS project. Node-RAPIDS is an … Continued
Node-RAPIDS is an open-source, technical preview of modular RAPIDS’ library bindings in Node.js, as well as, complementary methods for enabling high-performance, browser-based visualizations.
What’s the problem with web viz?
Around a decade ago, the mini-renaissance around web-based data visualization showed the benefits of highly interactive, easy to share, and use tools such as D3. While not as performant as C/C++ or Python frameworks, their popularity took off because of JavaScript’s accessibility. No surprise that it often ranks as the most popular developer language, preceding Python or Java, and there is now a full catalog of visualization and data tools.
Yet, this large JavaScript community of developers is impeded by the lack of first-class and accelerated data tools in their preferred language. The analysis is most effective when it is paired as close as possible to its data source, science, and visualizations. To fully access GPU hardware with JavaScript, (beyond webGL limitations and hacks) requires being a polyglot to set up complicated middleware plumbing or use non-js frameworks like Plotly Dash. As a result, data engineers, data scientists, visualization specialists, and front-end developers are often siloed, even within organizations. This is detrimental because data visualization is the ideal medium of communication between these groups.
As for the RAPIDS Viz team, ever since our first proof of concept, we’ve wanted to build tools that can more seamlessly interact with hundreds of millions of data points in real-time through our browsers – and we finally have a way.
Why Node.js
If you are not familiar with Node.js, it is an open-source, cross-platform runtime environment based on C/C++ that executes JavaScript code outside of a web browser. Over 1 Million Node.js downloads occur perday. Node Package Manager (NPM) is the default JavaScript package manager and Microsoft owns it. Node.js is used in the backend of online marketplaces like eBay, AliExpress, and is used by high-traffic websites, such as Netflix, PayPal, and Groupon. Clearly, it is a powerful framework.
Figure 1: XKCD – Node.js is a Universal Connector.
Node.js is the connector that gives us JavaScript with direct access to hardware, which results in a streamlined API and the ability to use NVIDIA CUDA . By creating node-rapids bindings, we enable a massive developer community with the ability to use GPU acceleration without the need to learn a new language or work in a new environment. We also give the same community access to a high-performance data science platform: RAPIDS!
Here is a snippet of node-RAPIDS in action based on our basic notebook, which shows a 6x speedup for a small regex example:
Similar to node projects, Node-RAPIDS is designed to be modular. Our aim is not to build turnkey web applications, but to create an inventory of functionality that enables or accelerates a wide variety of use cases and pipelines. The preceding is an overview of the current and planned Node-RAPIDS modules grouped in general categories. A Node-RAPIDS application can use as many or as few of the modules as needed.
To make starting out less daunting, we are also building a catalog of demos that can serve as templates for generalized applications. As we develop more bindings, we will create more demos to showcase their capabilities.
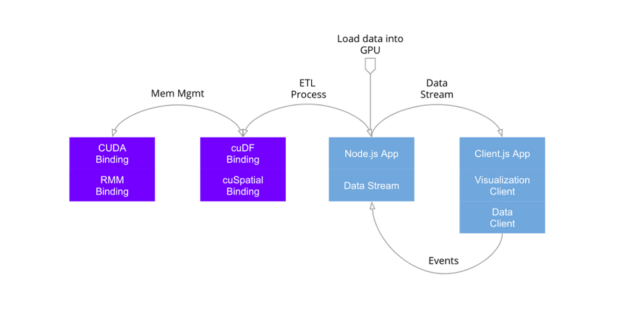
Figure 3: Example of a Cross Filter App.
The preceding is an idealized stack of a geospatial cross filter dashboard application using RAPIDS cuDF and RAPIDS cuSpatial libraries. We have a simple demo using Deck.gl that you can preview with our video and explore demo code on Github.
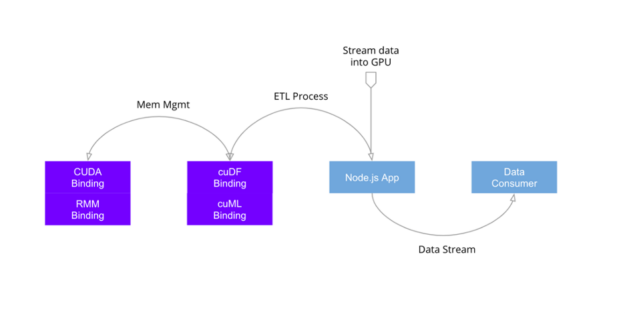
Figure 4: Example of Streaming ETL Process.
The last example preceding is a server-side only ETL pipeline without any visualization. We have an example of a straightforward ETL process using cuDF bindings and the nteract notebook desktop application, which you can preview with our video and nteract with (get it) on our Notebook.
What is next?
While we have been thinking about this project for a while, we are just getting started in development. RAPIDS is an incredible framework, and we want to bring it to more people and more applications – RAPIDS everywhere as we say.
Near-term next steps:
Some short-term next steps are to continue building core RAPIDS binding features, which you can check out on our current binding coverage table.
If the idea of GPU accelerated SQL queries straight from your web app sounds interesting (it does to us), we hope to get started on some blazingSQL bindings soon too.
And most noteworthy, we plan to start creating and publishing modular docker containers, which will dramatically simplify the current from-source tech preview installation process.
As always, we need community engagement to help guide us. If you have feature requests, questions, or use cases, you canreach out to us!
This project has numerous potentials. It can accelerate a wide variety of Node.js applications, as well as bring first-class, high-performance data science and visualization tools to a huge community. We hope you join us at the beginning of this exciting project.
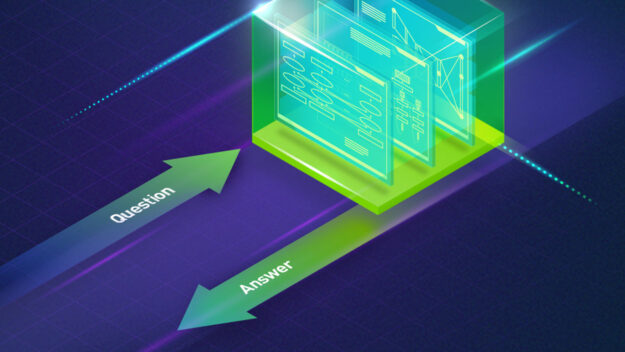
There is a high chance that you have asked your smart speaker a question like, “How tall is Mount Everest?” If you did, it probably said, “Mount Everest is 29,032 feet above sea level.” Have you ever wondered how it found an answer for you? Question answering (QA) is loosely defined as a system consisting … Continued
There is a high chance that you have asked your smart speaker a question like, “How tall is Mount Everest?” If you did, it probably said, “Mount Everest is 29,032 feet above sea level.” Have you ever wondered how it found an answer for you?
Question answering (QA) is loosely defined as a system consisting of information retrieval (IR) and natural language processing (NLP), which is concerned with answering questions posed by humans in a natural language. If you are not familiar with information retrieval, it is a technique to obtain relevant information to a query, from a pool of resources, webpages, or documents in the database, for example. The easiest way to understand the concept is the search engine that you use daily.
You then need an NLP system to find an answer within the IR system that is relevant to the query. Although I just listed what you need for building a QA system, it is not a trivial task to build IR and NLP from scratch. Here’s how NVIDIA Riva makes it easy to develop a QA system.
Riva overview
NVIDIA Riva is an accelerated SDK for building multimodal conversational AI services that use an end-to-end deep learning pipeline. The Riva framework includes optimized services for speech, vision, and natural language understanding (NLU) tasks. In addition to providing several pretrained models for the entire pipeline of your conversational AI service, Riva is also architected for deployment at scale. In this post, I look closely into the QA function of Riva and how you can create your own QA application with it.
Riva QA function
To understand how the Riva QA function works, start with Bidirectional Encoder Representations from Transformers (BERT). It’s a transformer-based, NLP, pretraining method developed by Google in 2018, and it completely changed the field of NLP. BERT understands the contextual representation of a given word in a text. It is pretrained on a large corpus of data, including Wikipedia.
With the pretrained BERT, a strong NLP engine, you can further fine-tune it to perform QA with many question-answer pairs like those in the Stanford Question Answering Dataset (SQuAD). The model can now find an answer for a question in natural language from a given context: sentences or paragraphs. Figure 1 shows an example of QA, where it highlights the word “gravity” as an answer to the query, “What causes precipitation to fall?”. In this example, the paragraph is the context and the successfully fine-tuned QA model returns the word “gravity” as an answer.
Teams of engineers and researchers at NVIDIA deliver a quality QA function that you can use right out-of-the-box with Riva. The Riva NLP service provides a set of high-level API actions that include QA, NaturalQuery. TheWikipedia API action allows you to fetch articles posted on Wikipedia, an online encyclopedia, with a query in natural language. That’s the information retrieval system that I discussed earlier. Combining the Wikipedia API action and Riva QA function, you can create a simple QA system with a few lines of Python code.
Start by installing the Wikipedia API for Python. Next, import the Riva NLP service API and gRPC, the underlying communication framework for Riva.
!pip install wikipedia
import wikipedia as wiki
import grpc
import riva_api.riva_nlp_pb2 as rnlp
import riva_api.riva_nlp_pb2_grpc as rnlp_srv
Now, create an input query. Use the Wikipedia API action to fetch the relevant articles and define the number of them to fetch, defined as max_articles_combine. Ask a question, “What is speech recognition?” You then print out the titles of the articles returned from the search. Finally, you add the summaries of each article into a variable: combined_summary.
input_query = "What is speech recognition?"
wiki_articles = wiki.search(input_query)
max_articles_combine = 3
combined_summary = ""
if len(wiki_articles) == 0:
print("ERROR: Could not find any matching results in Wikipedia.")
else:
for article in wiki_articles[:min(len(wiki_articles), max_articles_combine)]:
print(f"Getting summary for: {article}")
combined_summary += "n" + wiki.summary(article)
Figure 2. Titles of articles fetched by Wikipedia API action.
Next, open a gRPC channel that points to the location where the Riva server is running. Because you are running the Riva server locally, it is ‘localhost:50051‘. Then, instantiate NaturalQueryRequest, and send a request to the Riva server, passing both the query and the context. Finally, print the response, returned from the Riva server.
With Riva QA and the Wikipedia API action, you just created a simple QA application. If there’s an article in Wikipedia that is relevant to your query, you can theoretically find answers. Imagine that you have a database full of articles relevant to your domain, company, industry, or anything of interest. You can create a QA service that can find answers to the questions specific to your field of interest. Obviously, you would need an IR system that would fetch relevant articles from your database, like the Wikipedia API action used in this post. When you have the IR system in your pipeline, Riva can help you find an answer for you. We look forward to the cool applications that you’ll create with Riva. .

 Relying on the capabilities of GPUs, a team from Facebook AI Research has developed a faster, more efficient way for AI to run similarity searches. The study, published in IEEE Transactions on Big Data, creates a deep learning algorithm capable of handling and comparing high-dimensional data from media that is notably faster, while just as …
Relying on the capabilities of GPUs, a team from Facebook AI Research has developed a faster, more efficient way for AI to run similarity searches. The study, published in IEEE Transactions on Big Data, creates a deep learning algorithm capable of handling and comparing high-dimensional data from media that is notably faster, while just as … 
 Developers, researchers, graphics professionals, and others from around the world will get a sneak peek at the latest innovations in computer graphics at the SIGGRAPH 2021 virtual conference, taking place August 9-13.
Developers, researchers, graphics professionals, and others from around the world will get a sneak peek at the latest innovations in computer graphics at the SIGGRAPH 2021 virtual conference, taking place August 9-13.

 Developed by XeloGames, an indie studio of just three, and published by Headup Games, Escape from Naraka achieves eye-catching ray-traced lighting using RTXGI and significant performance boosts from DLSS.
Developed by XeloGames, an indie studio of just three, and published by Headup Games, Escape from Naraka achieves eye-catching ray-traced lighting using RTXGI and significant performance boosts from DLSS. This chapter, written by Juha Sjöholm, Paula Jukarainen, and Tatu Aalto, presents how all ray tracing based effects were implemented in Remedy Entertainment’s Control.
This chapter, written by Juha Sjöholm, Paula Jukarainen, and Tatu Aalto, presents how all ray tracing based effects were implemented in Remedy Entertainment’s Control. NVIDIA GTC21 had numerous great and engaging contents, especially around RAPIDS, so it would be easy to miss our debut presentation “Using RAPIDS to Accelerate Node.js JavaScript for Visualization and Beyond.” Yep – we are bringing the power of GPU accelerated data science to the JavaScript Node.js community with the Node-RAPIDS project. Node-RAPIDS is an …
NVIDIA GTC21 had numerous great and engaging contents, especially around RAPIDS, so it would be easy to miss our debut presentation “Using RAPIDS to Accelerate Node.js JavaScript for Visualization and Beyond.” Yep – we are bringing the power of GPU accelerated data science to the JavaScript Node.js community with the Node-RAPIDS project. Node-RAPIDS is an … 
 . By creating node-rapids bindings, we enable a massive developer community with the ability to use GPU acceleration without the need to learn a new language or work in a new environment. We also give the same community access to a high-performance data science platform: RAPIDS!
. By creating node-rapids bindings, we enable a massive developer community with the ability to use GPU acceleration without the need to learn a new language or work in a new environment. We also give the same community access to a high-performance data science platform: RAPIDS!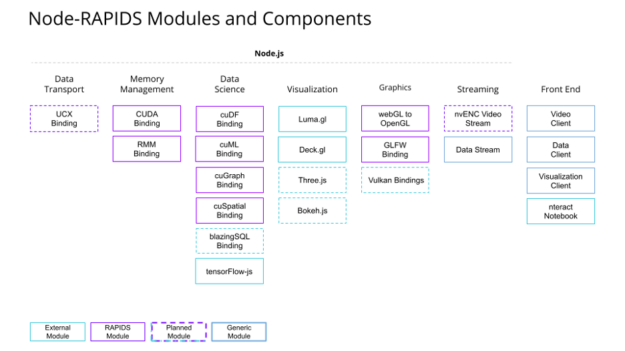
 There is a high chance that you have asked your smart speaker a question like, “How tall is Mount Everest?” If you did, it probably said, “Mount Everest is 29,032 feet above sea level.” Have you ever wondered how it found an answer for you? Question answering (QA) is loosely defined as a system consisting …
There is a high chance that you have asked your smart speaker a question like, “How tall is Mount Everest?” If you did, it probably said, “Mount Everest is 29,032 feet above sea level.” Have you ever wondered how it found an answer for you? Question answering (QA) is loosely defined as a system consisting …