Azure recently announced support for NVIDIA’s T4 Tensor Core Graphics Processing Units (GPUs) which are optimized for deploying machine learning inferencing or analytical workloads in a cost-effective manner. With Apache Spark™ deployments tuned for NVIDIA GPUs, plus pre-installed libraries, Azure Synapse Analytics offers a simple way to leverage GPUs to power a variety of data … Continued
Azure recently announced support for NVIDIA’s T4 Tensor Core Graphics Processing Units (GPUs) which are optimized for deploying machine learning inferencing or analytical workloads in a cost-effective manner. With Apache Spark™ deployments tuned for NVIDIA GPUs, plus pre-installed libraries, Azure Synapse Analytics offers a simple way to leverage GPUs to power a variety of data … Continued
Azure recently announced support for NVIDIA’s T4 Tensor Core Graphics Processing Units (GPUs) which are optimized for deploying machine learning inferencing or analytical workloads in a cost-effective manner. With Apache Spark deployments tuned for NVIDIA GPUs, plus pre-installed libraries, Azure Synapse Analytics offers a simple way to leverage GPUs to power a variety of data processing and machine learning tasks. With built-in support for RAPIDS acceleration, the Azure Synapse version of GPU-accelerated Spark offers at least 2x performance gain on standard analytical benchmarks compared to running on CPUs, all without any code changes.
deployments tuned for NVIDIA GPUs, plus pre-installed libraries, Azure Synapse Analytics offers a simple way to leverage GPUs to power a variety of data processing and machine learning tasks. With built-in support for RAPIDS acceleration, the Azure Synapse version of GPU-accelerated Spark offers at least 2x performance gain on standard analytical benchmarks compared to running on CPUs, all without any code changes.
Currently, this GPU acceleration feature in Azure Synapse is available for private preview by request.
Benefits of NVIDIA GPU acceleration
NVIDIA GPUs offer extraordinarily high compute performance, bringing parallel processing to multi-core servers to accelerate demanding workloads. A CPU consists of a few cores optimized for sequential serial processing, whereas. On the other hand, a GPU has a massively parallel architecture consisting of thousands of smaller and more efficient cores designed to handle multiple tasks simultaneously. Considering that data scientists spend up to 80% of their time on data pre-processing, GPUs are a critical tool to accelerate data processing pipelines compared to relying on pipelines containing CPUs alone.
One of the most efficient and familiar ways to build these pipelines is using Apache Spark. The benefits of NVIDIA GPU acceleration in Apache Spark include:
- Faster to complete data processing, queries, and model training, which grants accelerated iteration and time to insight.
- The same GPU-accelerated infrastructure is helpful to eliminate the need for complex decision-making and tuning for both Spark and ML/DL frameworks.
- Fewer compute nodes are required; reducing infrastructure cost and potentially helping avoid scale-related problems.
NVIDIA and Azure synapse collaboration
NVIDIA and Azure Synapse have teamed up to bring GPU acceleration to data scientists and data engineers. This integration will give customers the freedom to use NVIDIA GPUs for Apache Spark applications with no-code changes and with an experience identical to a CPU cluster. In addition, this collaboration will continue to add support for the latest NVIDIA GPUs and networking products and provide continuous enhancements for big data customers who are looking to improve productivity and save costs with a single pipeline for data engineering, data preparation, and machine learning.
To learn more about this project, check out our presentation at NVIDIA’s GTC 2021 Conference.
Apache Spark 3.0 GPU Acceleration in Azure Synapse
While Apache Spark provides GPU support out-of-box, configuring and managing all the required hardware and installing all the low-level libraries can take significant effort. When you try GPU-enabled Apache Spark pools in Azure Synapse, you will immediately notice a surprisingly simple user experience:
Behind the scenes heavy lifting: To efficiently use GPUs, libraries are used to perform communication with the graphics card on the host machine. Installing and configuring these libraries takes time and effort. Azure Synapse takes care of pre-installing these libraries and setting up all the complex networking between compute nodes through integration with GPU Apache Spark pools. Within just a few minutes, you can stop worrying about setup and focus on solving business problems.
Optimized Spark configuration: By collaborating between NVIDIA and Azure Synapse, we have come up with optimal configurations for your GPU-enabled Apache Spark pools. Thus, your workloads run most optimally saving you both time and operational costs.
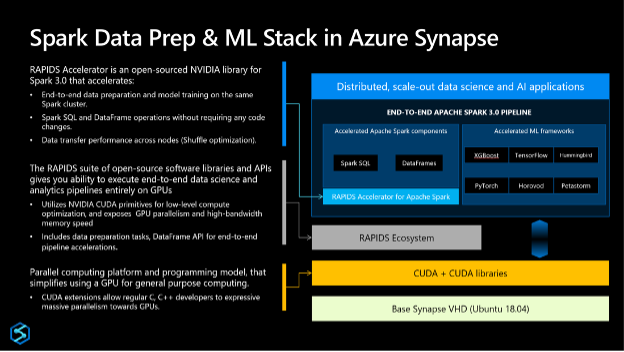
Packed with Data Prep and ML Libraries: The GPU-enabled Apache Spark pools in Azure Synapse come built-in with two popular libraries with support for more on the way:
- RAPIDS for Data Prep: RAPIDS is a suite of open-source software libraries and APIs for executing end-to-end data science and analytics pipelines entirely on GPUs for a substantial speed-up, particularly on large data sets. Built on top of NVIDIA CUDA and UCX, the RAPIDS Accelerator for Apache Spark enables GPU-accelerated SQL, DataFrame operations, and Spark shuffles. Since there are no code changes required to leverage these accelerations, you can also accelerate your data pipelines that rely on Linux Foundation’s Delta Lake or Microsoft’s Hyperspace indexing (both of which are available on Synapse out-of-box).
- Hummingbird for accelerating scoring and inference over your traditional ML models. Hummingbird is a library for converting traditional ML operators to tensors, with the goal of accelerating inference (scoring/prediction) for traditional machine learning models.
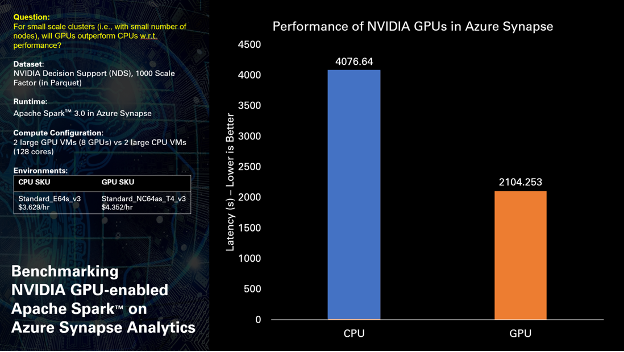
When running NVIDIA Decision Support (NDS) test queries, derived from industry-known benchmarks, over 1 TB of Parquet data our early results indicate that GPUs can deliver nearly 2x acceleration in overall query performance, without any code changes.
- Contact us if you are interested in being added to the private preview list.
- Use the limited-time free quantities available in Azure Synapse to try new features.