
 When using RAPIDS, practitioners can quickly accelerate data science workloads on NVIDIA GPUs, and with Saturn Cloud allows practitioners and enterprises to focus on solving their business challenges.
When using RAPIDS, practitioners can quickly accelerate data science workloads on NVIDIA GPUs, and with Saturn Cloud allows practitioners and enterprises to focus on solving their business challenges.
GPU-accelerated computing is a game-changer for data practitioners and enterprises, but leveraging GPUs can be challenging for data professionals. RAPIDS remediates these challenges by abstracting the complexities of accelerated data science through familiar interfaces. When using RAPIDS, practitioners can quickly accelerate data science workloads on NVIDIA GPUs, reducing operations like data loading, processing, and training from hours to seconds.
Managing large-scale data science infrastructure presents significant challenges. With Saturn Cloud, managing GPU-based infrastructure is made easier, allowing practitioners and enterprises to focus on solving their business challenges.
What is Saturn Cloud?
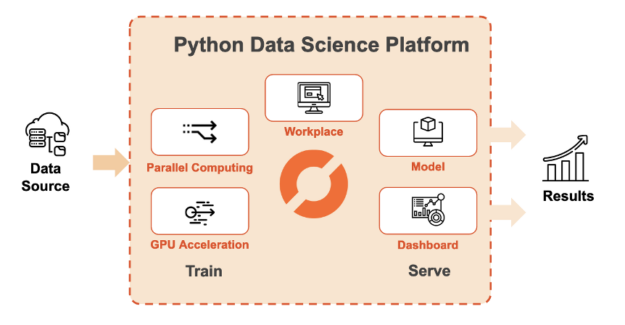
Saturn Cloud is an end-to-end platform that makes Python-based data science accessible with scalable computing resources in the cloud. Saturn Cloud offers an easy path to moving to the cloud with no cost, setup, or infrastructure work. This includes access to GPU-equipped computing resources with pre-built environments that include tools like RAPIDS, PyTorch, and TensorFlow.
Users are able to write their code in a hosted JupyterLab environment or connect their own IDE (integrated development environment) using SSH. As their data sizes increase, users can scale up to a GPU-enabled Dask cluster to execute code across a distributed network of machines. After a data pipeline, model, or dashboard is developed, users can deploy it to a persistent location or create a job to run it on a schedule.
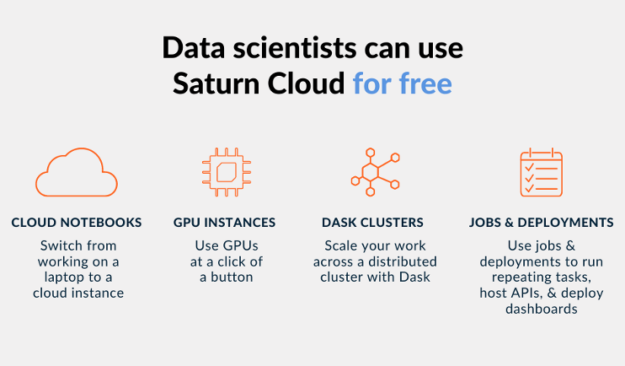
In addition to Saturn Cloud’s enterprise offering, Saturn Cloud also provides hosted offerings where anyone can get started with GPU-accelerated data science for free. The Hosted Free plan includes 10 hours of a Jupyter workspace and 3 hours of a Dask cluster per month. If you want more resources, you can upgrade to the Hosted Pro plan and pay as you go.
Saturn Cloud provides an easy-to-use platform for GPU-accelerated data science applications. With this platform, GPUs become a core component of the everyday data science stack.
Get started with RAPIDS on Saturn Cloud
You can quickly get going with RAPIDS after creating a free account on Saturn Cloud Hosted. In this section, we show how Saturn Cloud can be used to train a machine learning model on New York taxi data using RAPIDS. We then go further and run RAPIDS on a Dask cluster. By combining RAPIDS and Dask, you can use a network of multi-node GPU systems to train a model far faster than with a single GPU.
After creating your free account on Saturn Cloud Hosted, open the service and go to the “Resources” page. From there, look at the premade resource templates and click the one labeled RAPIDS.
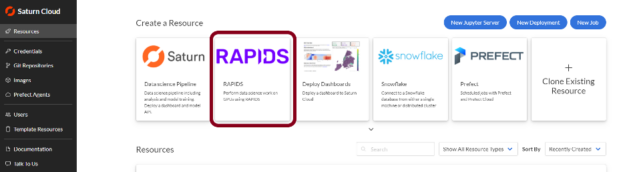
You will be taken to the newly created resource. Everything is already set up for you here to run your code on GPU hardware, with a Docker image that has all the necessary Python and RAPIDS packages installed.
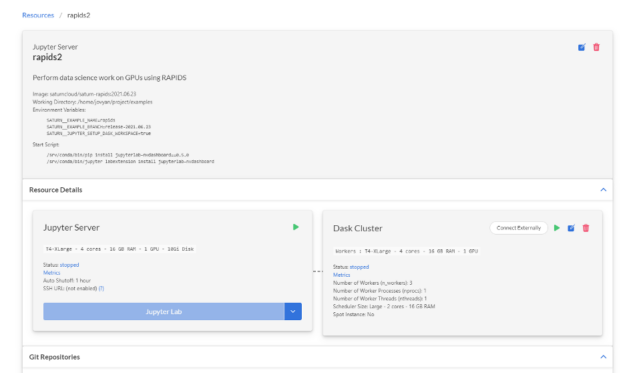
Out-of-the-box, this environment includes:
- 4 vCPUs with 16 GB of RAM
- NVIDIA T4 GPU with 16GB of GPU RAM
- RAPIDS: including cuDF, cuML, XGBoost, and more[1] [2] [3]
- NVDashboard JupyterLab extension, for real-time GPU metrics
- Dask and the Dask JupyterLab extension for monitoring the cluster
- Common PyData packages such as NumPy, SciPy, pandas, and scikit-learn
Click the play button on the “Jupyter Server” and “Dask Cluster” cards to start your resources. Now your cluster is ready to go; follow along to see how a GPU can significantly speed up model training time.
Train a random forest model with RAPIDS
For this exercise, we will use the NYC Taxi dataset. We will load a CSV file, select our features, then train a random forest model. To illustrate the runtime speedups we can achieve using RAPIDS on a GPU, we’ll first use traditional CPU-based PyData packages like pandas and scikit-learn.
Our machine learning model answers the question:
> Based on characteristics that can be known at the beginning of a trip, will this trip result in a high tip?
The dependent variable here is the “tip percentage”, or the dollar amount of the tip divided by the dollar amount of the ride cost. We’ll use pickup destination, drop-off destination, and the number of passengers as independent variables.
To follow along, you can copy the code chunks below into a new notebook in the Saturn Cloud JupyterLab interface. Alternatively, you can download the entire notebook here. First, we’ll set up a context manager to time different portions of the code:
from time import time
from contextlib import contextmanager
times = {}
@contextmanager
def timing(description: str) -> None:
start = time()
yield
elapsed = time() - start
times[description] = elapsed
print(f"{description}: {round(elapsed)} seconds")
Then we will pull a CSV file down from the NYC Taxi S3 bucket. Note that we could read the file directly from S3 into a dataframe. However, we want to separate network IO time from processing time on the CPU or GPU, and in case we want to run this step with modifications dozens of times, we won’t have to incur the network cost multiple times.
!curl https://s3.amazonaws.com/nyc-tlc/trip+data/yellow_tripdata_2019-01.csv > data.csv
Before we get to the GPU part, let’s see how this would look with traditional PyData packages such as pandas and scikit-learn that use the CPU for computations.
import pandas as pd
from sklearn.ensemble import RandomForestClassifier as RFCPU
with timing("CPU: CSV Load"):
taxi_cpu = pd.read_csv(
"data.csv",
parse_dates=["tpep_pickup_datetime", "tpep_dropoff_datetime"],
)
X_cpu = (
taxi_cpu[["PULocationID", "DOLocationID", "passenger_count"]]
.fillna(-1)
)
y_cpu = (taxi_cpu["tip_amount"] > 1)
rf_cpu = RFCPU(n_estimators=100, n_jobs=-1)
with timing("CPU: Random Forest"):
_ = rf_cpu.fit(X_cpu, y_cpu)
The CPU code will take a few minutes, so go ahead and open a new notebook for the GPU code. You’ll notice that the GPU code looks almost identical to the CPU code, except we’re swapping out `pandas` for `cudf` and `scikit-learn` for `cuml`. The RAPIDS packages resemble typical PyData packages on purpose, making it as easy as possible to enable your code to run on GPUs!
import cudf
from cuml.ensemble import RandomForestClassifier as RFGPU
with timing("GPU: CSV Load"):
taxi_gpu = cudf.read_csv(
"data.csv",
parse_dates=["tpep_pickup_datetime", "tpep_dropoff_datetime"],
)
X_gpu = (
taxi_gpu[["PULocationID", "DOLocationID", "passenger_count"]]
.astype("float32")
.fillna(-1)
)
y_gpu = (taxi_gpu["tip_amount"] > 1).astype("int32")
rf_gpu = RFGPU(n_estimators=100)
with timing("GPU: Random Forest"):
_ = rf_gpu.fit(X_gpu, y_gpu)
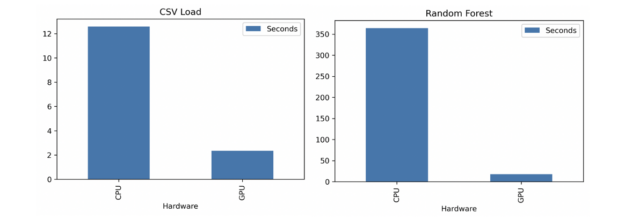
You should have been able to copy this into a new notebook and execute the whole thing before the CPU version finished. Once that’s done, check out the difference in the runtimes of each.
With the CPU, CSV loading took 13 seconds while random forest training took 364 seconds (6 minutes). With the GPU, CSV loading took 2 seconds while random forest training took 18 seconds. That’s 7x faster CSV loading and 20x faster random forest training.
Using RAPIDS + Dask for your big data problems
While a single GPU is powerful enough for many use cases, modern data science use cases often benefit from increasingly large datasets to generate more accurate and profound insights. Many use cases require scale-out infrastructure consisting of multiple GPUs or nodes to churn through workloads. RAPIDS pairs well with Dask to support scaling out to large GPU clusters.
With Saturn Cloud, you can connect to a GPU-powered Dask cluster from the same project we were using earlier. Then, to utilize Dask on GPUs, you would swap out the cudf package for dask_cudf for loading data, and use the cuml.dask submodule for machine learning. Notice now that we’re using glob syntax with dask_cudf.read_csv to load in data for all of 2019, rather than a single month as we did previously. This processes approximately 12x the amount of data as our previous example but only takes 90 seconds with the GPU cluster.
from dask.distributed import Client, wait
from dask_saturn import SaturnCluster
import dask_cudf
from cuml.dask.ensemble import RandomForestClassifier as RFDask
cluster = SaturnCluster()
client = Client(cluster)
taxi_dask = dask_cudf.read_csv(
"s3://nyc-tlc/trip data/yellow_tripdata_2019-*.csv",
parse_dates=["tpep_pickup_datetime", "tpep_dropoff_datetime"],
storage_options={"anon": True},
assume_missing=True,
)
X_dask = (
taxi_dask[["PULocationID", "DOLocationID", "passenger_count"]]
.astype("float32")
.fillna(-1)
)
y_dask = (taxi_dask["tip_amount"] > 1).astype("int32")
X_dask, y_dask = client.persist([X_dask, y_dask])
_ = wait(X_dask)
rf_dask = RFDask(n_estimators=100)
_ = rf_dask.fit(X_dask, y_dask)
Make Accelerated Data Science Easy with RAPIDS and Saturn Cloud
This example showed how easy it is to accelerate your data science workloads with RAPIDS on a GPU or a GPU Dask cluster. Using RAPIDS can increase training times by an order of magnitude, which can help you iterate your models more quickly. With Saturn Cloud, you can spin up Jupyter Notebooks, Dask clusters, and other cloud resources right when you want them.
If you would like to learn more about RAPIDS and GPU-accelerated data science, check out RAPIDS.ai or learn more about NVIDIA accelerated data science here. For Saturn Cloud, you can read the documentation page.
To get started with GPUs on Saturn Cloud, create a free account here and see what the power of accelerated compute can bring to your data science workloads.