
 Running PyCarert on GPU not only streamline model building but offsets the time cost.
Running PyCarert on GPU not only streamline model building but offsets the time cost.
PyCaret is a low-code Python machine learning library based on the popular Caret library for R. It automates the data science process from data preprocessing to insights, such that short lines of code can accomplish each step with minimal manual effort. In addition, the ability to compare and tune many models with simple commands streamlines efficiency and productivity with less time spent in the weeds of creating useful models.
The PyCaret team added NVIDIA GPU support in version 2.2, including all the latest and greatest from RAPIDS. With GPU acceleration, PyCaret modeling times can be between 2 and 200 times faster depending on the workload.
This post will go over how to use PyCaret on GPUs to save both development and computation costs by an order of magnitude.
All benchmarks were run with nearly identical code on a machine with a 32-core CPU and four NVIDIA Tesla T4s. For simplicity, GPU code was written to run on a single GPU.
Getting started with PyCaret
Using PyCaret is as simple as importing the library and executing a set-up statement. The setup() function creates the environment and offers a host of pre-processing features all in one go.
from pycaret.regression import *
exp_reg = setup(data = df, target = ‘Year’, session_id = 123, normalize = True)After a simple setup, a data scientist can develop the rest of their pipeline, including data preprocessing/preparation, model training, ensembling, analysis, and deployment. After the data is prepared, a great place to start is by comparing models.
True to PyCaret’s ethos of simplicity, we can compare a host of standard models to see which are best for our data with a single line of code. The compare_models command trains all the models in PyCaret’s model library using default hyperparameters and evaluates performance metrics using cross-validation. A data scientist can then select the models they’d like to use, tune, and ensemble based on this info.
top3 = compare_models(exclude = [‘ransac’], n_select=3)Comparing Models
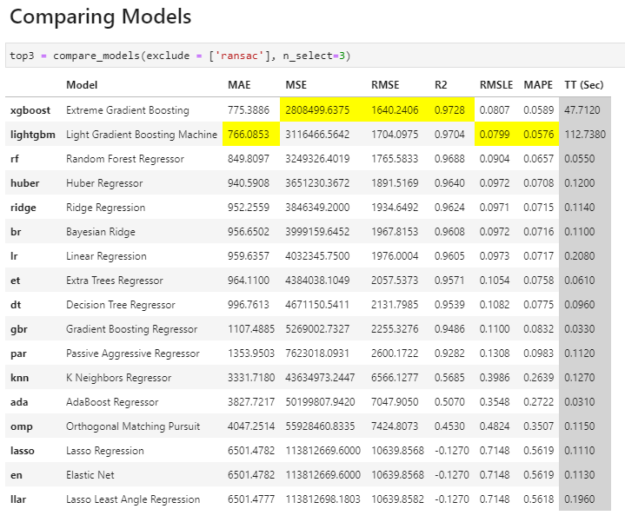
**Models are sorted best to worst, and PyCaret highlights the top results in each metric category for ease of use.
Accelerating PyCaret with RAPIDS cuML
PyCaret is a great tool for any data scientist to have in their arsenal, as it streamlines model building and makes running many models easy. PyCaret can be made even better with GPUs. Since PyCaret does so much work behind the scenes, seemingly simple commands can take a long time. For example, we ran the commands preceding on a dataset with roughly half a million instances and over 90 attributes (UC Irvine’s Year Prediction MSD dataset). On the CPU, it took over 3 hours. On a GPU, it took less than half that.
In the past, using PyCaret on a GPU would have required many manual coding, but thankfully, the PyCaret team has integrated the RAPIDS machine learning library (cuML), meaning you can use the same simple API that makes PyCaret so effective while also using the computational ability of your GPU.
Running PyCaret on a GPU tends to be much faster-meaning you can make full use of everything PyCaret has to offer without balancing time costs. Using the same dataset just mentioned, we tested PyCaret ML functionality on both a CPU and a GPU, including comparing, creating, tuning, and ensembling models. Performing the switch to GPU is simple; we set use_gpu to True in the setup function:
exp_reg = setup(data = df, target = ‘Year’, session_id = 123, normalize = True, use_gpu = True)With PyCaret set to run on GPU, it uses cuML to train all of the following models:
- Logistic Regression
- Ridge Classifier
- Random Forest
- K Neighbors Classifier
- K Neighbors Regressor
- Support Vector Machine
- Linear Regression
- Ridge Regression
- Lasso Regression
- K-Means Clustering
- Density-Based Spatial Clustering
Running the same compare_models code solely on GPU was over 2.5 times as fast.
The impact was even greater on a model-by-model basis with popular but computationally expensive models. The K Neighbors Regressor, for example, was 265 times as fast on GPU.
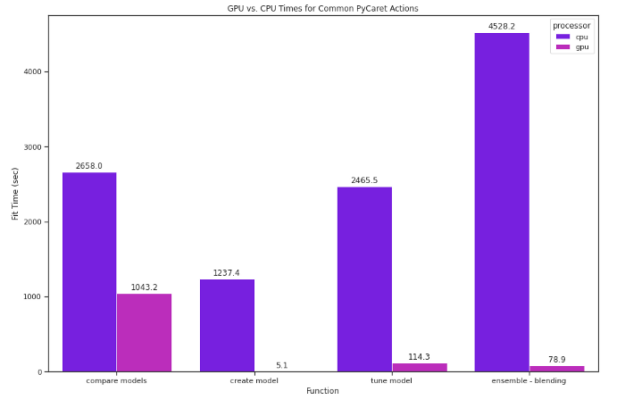
Impact
The simplicity of PyCaret’s API frees up time that would otherwise be spent coding so data scientists can do more experiments and fine-tune their experiments. When paired with GPUs, this impact is even greater, as the computation costs of taking full advantage of PyCaret’s suite of evaluation and comparison tools are significantly lower.
Conclusion
Extensive comparing and evaluating models can help improve the quality of your results, and doing so efficiently is exactly what PyCaret is for. PyCaret on GPU offsets the time costs that go along with so much processing.
The goal of RAPIDS is to accelerate your data science, and PyCaret is among a growing list of libraries whose compatibility with the RAPIDS suite can help bring a new layer of efficiency to your machine learning pursuits.
**Code used for this notebook can be found here.