
Machine learning (ML) agents are increasingly deployed in the real world to make decisions and assist people in their daily lives. Making reasonable predictions about the future at varying timescales is one of the most important capabilities for such agents because it enables them to predict changes in the world around them, including other agents’ behaviors, and plan how to act next. Importantly, successful future prediction requires both capturing meaningful transitions in the environment (e.g., dough transforming into bread) and adapting to how transitions unfold over time in order to make decisions.
Previous work in future prediction from visual observations has largely been constrained by the format of its output (e.g., pixels that represent an image) or a manually-defined set of human activities (e.g., predicting if someone will keep walking, sit down, or jump). These are either too detailed and hard to predict or lack important information about the richness of the real world. For example, predicting “person jumping” does not capture why they’re jumping, what they’re jumping onto, etc. Also, with very few exceptions, previous models were designed to make predictions at a fixed offset into the future, which is a limiting assumption because we rarely know when meaningful future states will happen.
For example, in a video about making ice cream (depicted below), the meaningful transition from “cream” to “ice cream” occurs over 35 seconds, so models predicting such transitions would need to look 35 seconds ahead. But this time interval varies a large amount across different activities and videos — meaningful transitions occur at any distance into the future. Learning to make such predictions at flexible intervals is hard because the desired ground truth may be relatively ambiguous. For example, the correct prediction could be the just-churned ice cream in the machine, or scoops of the ice cream in a bowl. In addition, collecting such annotations at scale (i.e., frame-by-frame for millions of videos) is infeasible. However, many existing instructional videos come with speech transcripts, which often offer concise, general descriptions throughout entire videos. This source of data can guide a model’s attention toward important parts of the video, obviating the need for manual labeling and allowing a flexible, data-driven definition of the future.
In “Learning Temporal Dynamics from Cycles in Narrated Video”, published at ICCV 2021, we propose an approach that is self-supervised, using a recent large unlabeled dataset of diverse human action. The resulting model operates at a high level of abstraction, can make predictions arbitrarily far into the future, and chooses how far into the future to predict based on context. Called Multi-Modal Cycle Consistency (MMCC), it leverages narrated instructional video to learn a strong predictive model of the future. We demonstrate how MMCC can be applied, without fine-tuning, to a variety of challenging tasks, and qualitatively examine its predictions. In the example below, MMCC predicts the future (d) from present frame (a), rather than less relevant potential futures (b) or (c).
 |
| This work uses cues from vision and language to predict high-level changes (such as cream becoming ice cream) in video (video from HowTo100M). |
Viewing Videos as Graphs
The foundation of our method is to represent narrated videos as graphs. We view videos as a collection of nodes, where nodes are either video frames (sampled at 1 frame per second) or segments of narrated text (extracted with automatic speech recognition systems), encoded by neural networks. During training, MMCC constructs a graph from the nodes, using cross-modal edges to connect video frames and text segments that refer to the same state, and temporal edges to connect the present (e.g., strawberry-flavored cream) and the future (e.g., soft-serve ice cream). The temporal edges operate on both modalities equally — they can start from either a video frame, some text, or both, and can connect to a future (or past) state in either modality. MMCC achieves this by learning a latent representation shared by frames and text and then making predictions in this representation space.
Multi-modal Cycle Consistency
To learn the cross-modal and temporal edge functions without supervision, we apply the idea of cycle consistency. Here, cycle consistency refers to the construction of cycle graphs, in which the model constructs a series of edges from an initial node to other nodes and back again: Given a start node (e.g., a sample video frame), the model is expected to find its cross-modal counterpart (i.e., text describing the frame) and combine them as the present state. To do this, at the start of training, the model assumes that frames and text with the same timestamps are counterparts, but then relaxes this assumption later. The model then predicts a future state, and the node most similar to this prediction is selected. Finally, the model attempts to invert the above steps by predicting the present state backward from the future node, and thus connecting the future node back with the start node.
The discrepancy between the model’s prediction of the present from the future and the actual present is the cycle-consistency loss. Intuitively, this training objective requires the predicted future to contain enough information about its past to be invertible, leading to predictions that correspond to meaningful changes to the same entities (e.g., tomato becoming marinara sauce, or flour and eggs in a bowl becoming dough). Moreover, the inclusion of cross-modal edges ensures future predictions are meaningful in either modality.
To learn the temporal and cross-modal edge functions end-to-end, we use the soft attention technique, which first outputs how likely each node is to be the target node of the edge, and then “picks” a node by taking the weighted average among all possible candidates. Importantly, this cyclic graph constraint makes few assumptions for the kind of temporal edges the model should learn, as long as they end up forming a consistent cycle. This enables the emergence of long-term temporal dynamics critical for future prediction without requiring manual labels of meaningful changes.
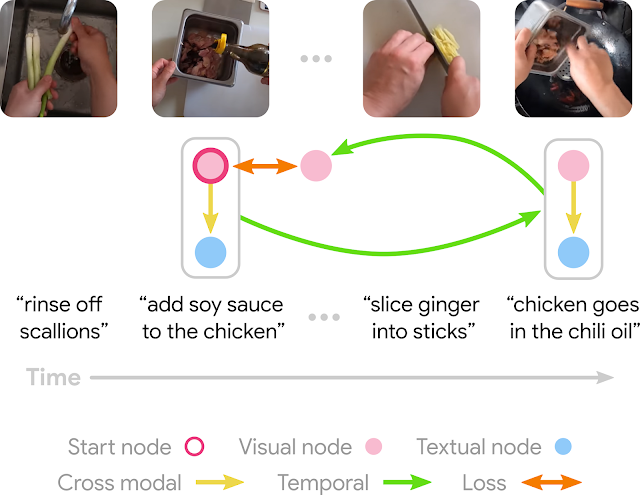 |
| An example of the training objective: A cycle graph is expected to be constructed between the chicken with soy sauce and the chicken in chili oil because they are two adjacent steps in the chicken’s preparation (video from HowTo100M). |
Discovering Cycles in Real-World Video
MMCC is trained without any explicit ground truth, using only long video sequences and randomly sampled starting conditions (a frame or text excerpt) and asking the model to find temporal cycles. After training, MMCC can identify meaningful cycles that capture complex changes in video.
 |
| Given frames as input (left), MMCC selects relevant text from video narrations and uses both modalities to predict a future frame (middle). It then finds text relevant to this future and uses it to predict the past (right). Using its knowledge of how objects and scenes change over time, MMCC “closes the cycle” and ends up where it started (videos from HowTo100M). |
 |
| The model can also start from narrated text rather than frames and still find relevant transitions (videos from HowTo100M). |
Zero-Shot Applications
For MMCC to identify meaningful transitions over time in an entire video, we define a “likely transition score” for each pair (A, B) of frames in a video, according to the model’s predictions — the closer B is to our model’s prediction of the future of A, the higher the score assigned. We then rank all pairs according to this score and show the highest-scoring pairs of present and future frames detected in previously unseen videos (examples below).
 |
| The highest-scoring pairs from eight random videos, which showcase the versatility of the model across a wide range of tasks (videos from HowTo100M). |
We can use this same approach to temporally sort an unordered collection of video frames without any fine-tuning by finding an ordering that maximizes the overall confidence scores between all adjacent frames in the sorted sequence.
 |
| Left: Shuffled frames from three videos. Right: MMCC unshuffles the frames. The true order is shown under each frame. Even when MMCC does not predict the ground truth, its predictions often appear reasonable, and so, it can present an alternate ordering (videos from HowTo100M). |
Evaluating Future Prediction
We evaluate the model’s ability to anticipate action, potentially minutes in advance, using the top-k recall metric, which here measures a model’s ability to retrieve the correct future (higher is better). On CrossTask, a dataset of instruction videos with labels describing key steps, MMCC outperforms the previous self-supervised state-of-the-art models in inferring possible future actions.
| Recall | |||||||
| Model | Top-1 | Top-5 | Top-10 | ||||
| Cross-modal | 2.9 | 14.2 | 24.3 | ||||
| Repr. Ant. | 3.0 | 13.3 | 26.0 | ||||
| MemDPC | 2.9 | 15.8 | 27.4 | ||||
| TAP | 4.5 | 17.1 | 27.9 | ||||
| MMCC | 5.4 | 19.9 | 33.8 | ||||
Conclusions
We have introduced a self-supervised method to learn temporal dynamics by cycling through narrated instructional videos. Despite the simplicity of the model’s architecture, it can discover meaningful long-term transitions in vision and language, and can be applied without further training to challenging downstream tasks, such as anticipating far-away action and ordering collections of images. An interesting future direction is transferring the model to agents so they can use it to conduct long-term planning.
Acknowledgements
The core team includes Dave Epstein, Jiajun Wu, Cordelia Schmid, and Chen Sun. We thank Alexei Efros, Mia Chiquier, and Shiry Ginosar for their feedback, and Allan Jabri for inspiration in figure design. Dave would like to thank Dídac Surís and Carl Vondrick for insightful early discussions on cycling through time in video.
