
 Learn about the optimizations and techniques used across the full stack in the NVIDIA AI platform that led to a record-setting performance in MLPerf HPC v1.0.
Learn about the optimizations and techniques used across the full stack in the NVIDIA AI platform that led to a record-setting performance in MLPerf HPC v1.0.
In MLPerf HPC v1.0, NVIDIA-powered systems won four of five new industry metrics focused on AI performance in HPC. As an industry-wide AI consortium, MLPerf HPC evaluates a suite of performance benchmarks covering a range of widely used AI workloads.
In this round, NVIDIA delivered 5x better results for CosmoFlow, and 7x more performance on DeepCAM, compared to strong scaling results from MLPerf 0.7. The strong showing is the result of a mature NVIDIA AI platform with a full stack of software.
Offering a rich and diverse set of libraries, SDKs, tools, compilers, and profilers it can be difficult to know when and where to apply the right asset in the right situation. This post details the tools, techniques, and benefits for various scenarios, and outlines the results achieved for the CosmoFlow and DeepCAM benchmarks.
We have published similar guides for MLPerf Training v1.0 and MLPerf Inference v1.1, which are recommended for other benchmark-oriented cases.
The tuning plan
We tuned our code with tools including NVIDIA DALI to accelerate data processing, and CUDA Graphs to reduce small-batch latency for efficiently scaling out to 1,024 or more GPUs. We also applied NVIDIA SHARP to accelerate communications by offloading some operations to the network switch.
The software used in our submissions is available from the MLPerf repository. We regularly add new tools along with new versions to the NGC catalog—our software hub for pretrained AI models, industry application frameworks, GPU applications, and other software resources.
Major performance optimizations
In this section, we dive into the selected optimizations that are implemented for MLPerf HPC 1.0.
Using NVIDIA DALI library for data preprocessing
Data is fetched from the disk and preprocessed before each iteration. We moved from the default dataloader to NVIDIA DALI library. This provides optimized data loading and preprocessing functions for GPUs.
Instead of performing data loading and preprocessing on CPU and moving the result to GPU, DALI library uses a combination of CPU and GPU. This leads to more efficient preprocessing of the data for the upcoming iteration. The optimization results in significant speedup for both CosmoFlow and DeepCAM. DeepCAM achieved over a 50% end-to-end performance gain.
In addition, DALI also provides asynchronous data loading for the upcoming iteration to eliminate I/O overhead from the critical path. With this mode enabled, we saw an additional 70% gain on DeepCAM.
Applying the channels-last NHWC layout
By default, the DeepCAM benchmark uses NCHW layout, for the activation tensors. We used PyTorch’s channels-last (NHWC layout) support to avoid extra transpose kernels. Most convolution kernels in cuDNN are optimized for NHWC layout.
As a result, using NCHW layout in the framework requires additional transpose kernels to convert from NCHW to NHWC for efficient convolution operation. Using NHWC layout in-framework avoids these redundant copies, and delivered about 10% performance gains on the DeepCAM model. NHWC support is available in the PyTorch framework in beta mode.
CUDA Graphs
CUDA Graphs allow launching a single graph that consists of a sequence of kernels, instead of individually launching each of the kernels from CPU to GPU. This feature minimizes CPU involvement in each iteration, substantially improving performance by minimizing latencies—especially for strong scaling scenarios.
MXNet previously added CUDA Graphs support, and CUDA Graphs support was also recently added to PyTorch. CUDA Graphs support in PyTorch resulted in around a 15% end-to-end performance gain in DeepCAM for the strong scaling scenario, which is most sensitive to latency and jitter.
Efficient data staging with MPI
For the case of weak scaling, the performance of the distributed file system cannot sustain the demand from GPUs. To increase the aggregate total storage bandwidth, we stage the dataset into node-local NVME memory for DeepCAM.
Since the individual instances are small, we can shard the data statically, and thus only need to stage a fraction of the full dataset per node. This solution is depicted in Figure 1. Here we denote the number of instances with M and the number of ranks per instance with N.
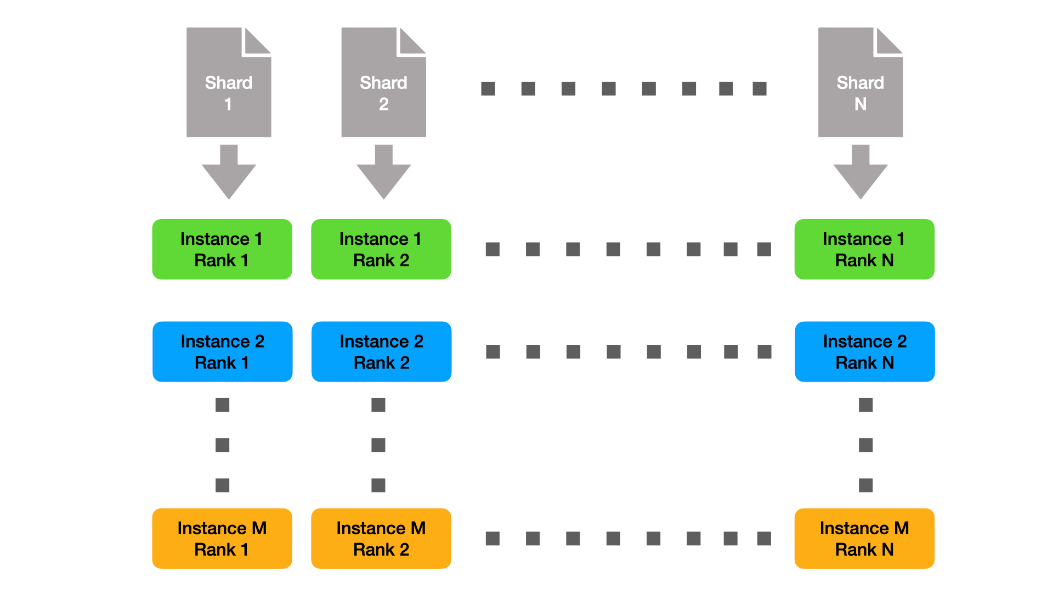
Note that across instances, each rank with the same rank ID uses the same shard of data. This means that natively, each data shard is read M times. To reduce pressure on the file system, we created subshards of the data orthogonal to the instances, depicted in Figure 2.
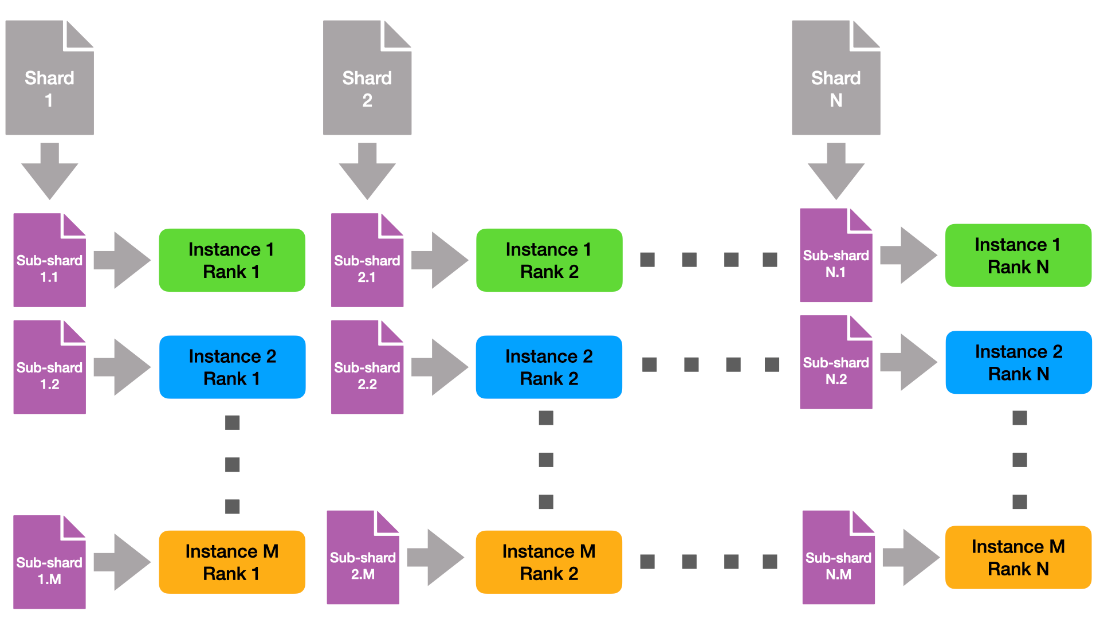
This way, each file is read-only once from the global file system. Finally, each instance needs to receive all the data. For this purpose, we created new MPI communicators orthogonal to the intra-instance communicator, that is, we combine all instance ranks with the same rank id into the same interinstance communicators. Then we can use MPI allgather to combine the individual subshards into M copies of the original shard.
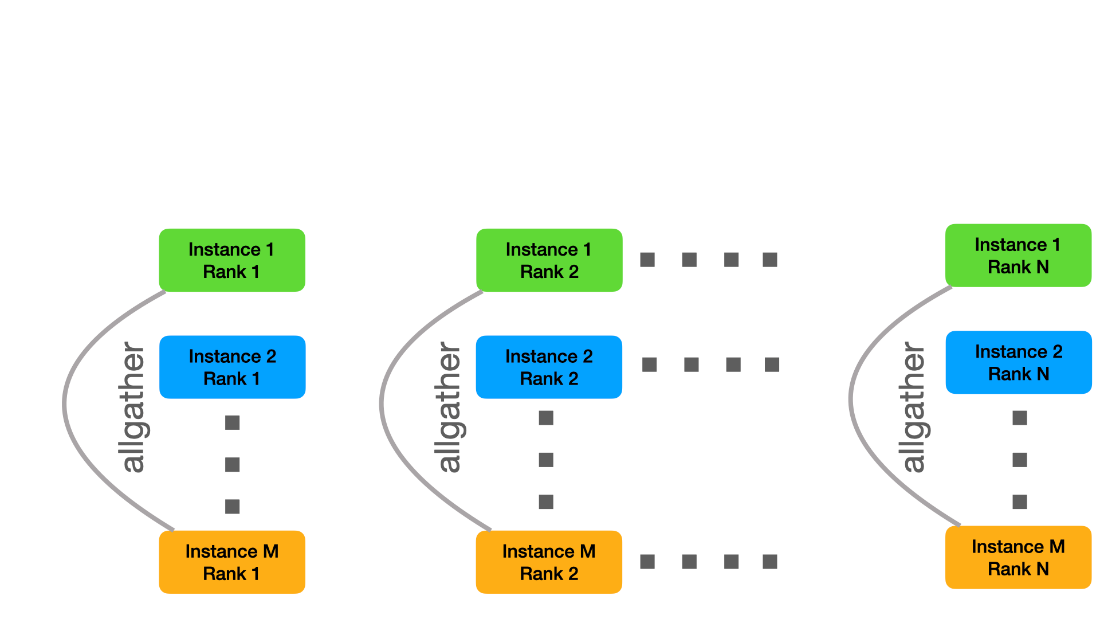
Instead of performing these steps sequentially, we use batching to create a pipeline that overlaps data reading and distribution of the subshards. In order to improve the read and write performance, we further implemented a small helper tool that uses O_DIRECT to improve I/O bandwidth.
The optimization resulted in more than 2x end-to-end speedup for the DeepCAM benchmark. This is available in the submission repository.
Loss hybridization
An imperative approach for model definition and execution is a flexible solution for defining a ML model like a standard Python program. On the other hand, symbolic programming is a way for declaring computation upfront, before execution. This approach allows the engine to perform various optimizations, but loses flexibility of the imperative approach.
Hybridization is a way of combining those two approaches in the MXNet framework. An imperatively defined calculation can be compiled into symbolic form and optimized when possible. CosmoFlow extends the model hybridization with loss.
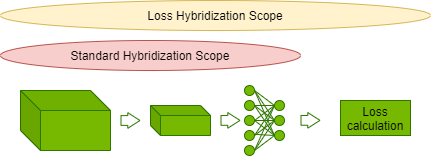
This allows fusing element-wise operations in loss calculation with scaled activation output from CosmoFlow model, reducing overall iteration latency. The optimization resulted in close to a 5% end-to-end performance gain for CosmoFlow.
Employing SHARP for internode all-reduce collective
SHARP allows offloading collective operations from CPU to the switches in internode network fabric. This effectively doubles the internode bandwidth of InfiniBand network for the allreduce operation. This optimization results in up to 5% performance gain for MLPerf HPC benchmarks, especially for strong scaling scenarios.
Moving forward with MLPerf HPC
Scientists are making breakthroughs at an accelerated pace, in part because AI and HPC are combining to deliver insight faster and more accurately than could be done using traditional methods.
MLPerf HPC v1.0 reflects the supercomputing industry’s need for an objective, peer-reviewed method to measure and compare AI training performance for use cases relevant to HPC. In this round, the NVIDIA compute platform demonstrated clear leadership by winning all three benchmarks for performance, and also demonstrated the highest efficiency for both throughput measurements.
NVIDIA has also worked with several supercomputing centers around the world for their submissions with NVIDIA GPUs. One of them, the Jülich Supercomputing Centre, has the fastest submissions from Europe.
Read more stories of 2021 Gordon Bell finalists, as well as a discussion of how HPC and AI are making new types of science possible.
Learn more about the MLPerf benchmarks and results from NVIDIA.
Featured image of the Juwels Booster powered by NVIDIA A100 image courtesy of „Forschungszentrum Jülich / Sascha Kreklau”
Disclaimer:
MLPerf v1.0 HPC Closed Strong & Weak Scaling – Result retrieved from https://mlcommons.org/en/training-hpc-10 on Nov. 16, 2021.
v1.0 HPC Closed Strong & Weak Scaling – Result retrieved from https://mlcommons.org/en/training-hpc-10 on Nov. 16, 2021.
The MLPerf name and logo are trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use is strictly prohibited. See www.mlcommons.org for more information.