Hey guys I get this error message when i try to run
import tensorflow as tf
print(tf. __version__)
2021-11-17 19:57:46.733325: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library ‘cudart64_110.dll’; dlerror: cudart64_110.dll not found 2021-11-17 19:57:46.739099: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine. 2.7.0
To that end, in “Deep RL at the Edge of the Statistical Precipice”, accepted as an oral presentation at NeurIPS 2021, we discuss how statistical uncertainty of results needs to be considered, especially when using only a few training runs, in order for evaluation in deep RL to be reliable. Specifically, the predominant practice of reporting point estimates ignores this uncertainty and hinders reproducibility of results. Related to this, tables with per-task scores, as are commonly reported, can be overwhelming beyond a few tasks and often omit standard deviations. Furthermore, simple performance metrics like the mean can be dominated by a few outlier tasks, while the median score would remain unaffected even if up to half of the tasks had performance scores of zero. Thus, to increase the field’s confidence in reported results with a handful of runs, we propose various statistical tools, including stratified bootstrap confidence intervals, performance profiles, and better metrics, such as interquartile mean and probability of improvement. To help researchers incorporate these tools, we also release an easy-to-use Python library RLiable with a quickstart colab.
Statistical Uncertainty in RL Evaluation Empirical research in RL relies on evaluating performance on a diverse suite of tasks, such as Atari 2600 video games, to assess progress. Published results on deep RL benchmarks typically compare point estimates of the mean and median scores aggregated across tasks. These scores are typically relative to some defined baseline and optimal performance (e.g., random agent and “average” human performance on Atari games, respectively) so as to make scores comparable across different tasks.
In most RL experiments, there is randomness in the scores obtained from different training runs, so reporting only point estimates does not reveal whether similar results would be obtained with new independent runs. A small number of training runs, coupled with the highvariabilityin performance of deep RL algorithms, often leads to large statistical uncertainty in such point estimates.
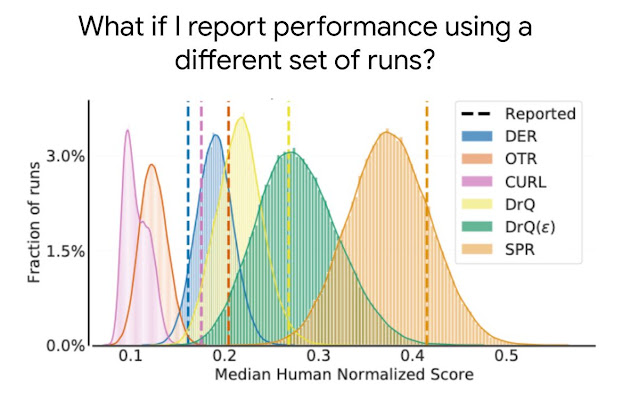
The distribution of median human normalized scores on the Atari 100k benchmark, which contains 26 games, for five recently published algorithms, DER, OTR, CURL, two variants of DrQ, and SPR. The reported point estimates of median scores based on a few runs in publications, as shown by dashed lines, do not provide information about the variability in median scores and typically overestimate (e.g., CURL, SPR, DrQ) or underestimate (e.g., DER) the expected median, which can result in erroneous conclusions.
As benchmarks become increasingly more complex, evaluating more than a few runs will be increasingly demanding due to the increased compute and data needed to solve such tasks. For example, five runs on 50 Atari games for 200 million frames takes 1000+ GPU days. Thus, evaluating more runs is not a feasible solution for reducing statistical uncertainty on computationally demanding benchmarks. While priorwork has recommended statistical significance tests as a solution, such tests are dichotomous in nature (either “significant” or “not significant”), so they often lack the granularity needed to yield meaningful insights and are widely misinterpreted.
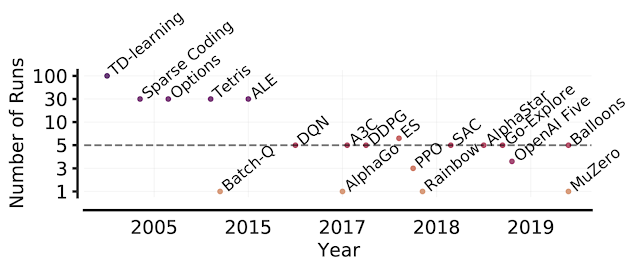
Number of runs in RL papers over the years. Beginning with the Arcade Learning Environment (ALE), the shift toward computationally-demanding benchmarks has led to the practice of evaluating only a handful of runs per task, increasing the statistical uncertainty in point estimates.
Tools for Reliable Evaluation Any aggregate metric based on a finite number of runs is a random variable, so to take this into account, we advocate for reporting stratified bootstrapconfidence intervals (CIs), which predict the likely values of aggregate metrics if the same experiment were repeated with different runs. These CIs allow us to understand the statistical uncertainty and reproducibility of results. Such CIs use the scores on combined runs across tasks. For example, evaluating 3 runs each on Atari 100k, which contains 26 tasks, results in 78 sample scores for uncertainty estimation.
In each task, colored balls denote scores on different runs. To compute statified bootstrap CIs using the percentile method, bootstrap samples are created by randomly sampling scores with replacement proportionately from each task. Then, the distribution of aggregate scores on these samples is the bootstrapping distribution, whose spread around the center gives us the confidence interval.
Most deep RL algorithms often perform better on some tasks and training runs, but aggregate performance metrics can conceal this variability, as shown below.
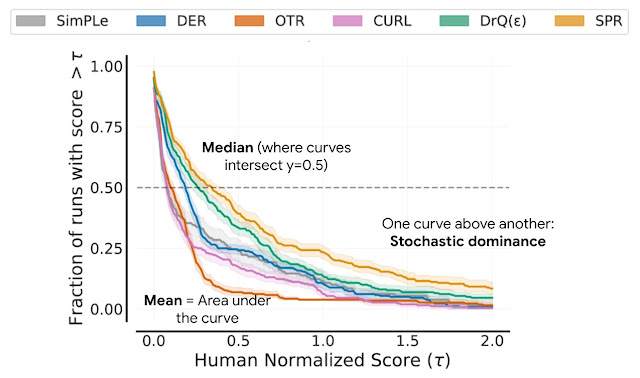
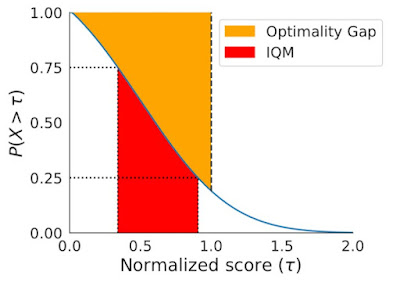
Instead, we recommend performance profiles, which are typically used for comparing solve times of optimization software. These profiles plot the score distribution across all runs and tasks with uncertainty estimates using stratified bootstrap confidence bands. These plots show the total runs across all tasks that obtain a score above a threshold (𝝉) as a function of the threshold.
Performance profiles correspond to the empirical tail distribution of scores on runs combined across all tasks. Shaded regions show 95% stratified bootstrap confidence bands.
Such profiles allow for qualitative comparisons at a glance. For example, the curve for one algorithm above another means that one algorithm is better than the other. We can also read any score percentile, e.g., the profiles intersect y = 0.5 (dotted line above) at the median score. Furthermore, the area under the profile corresponds to the mean score.
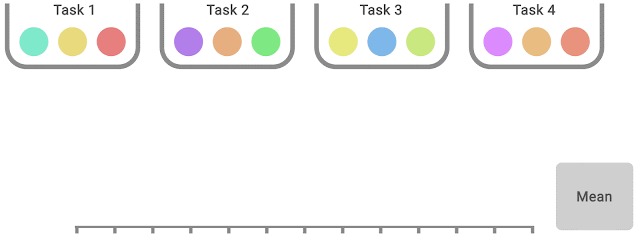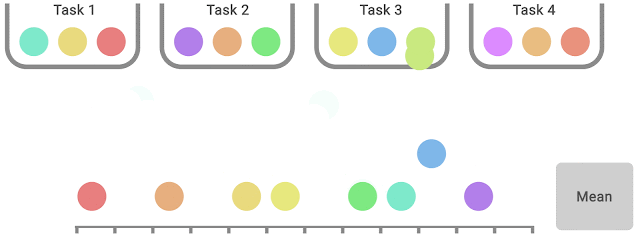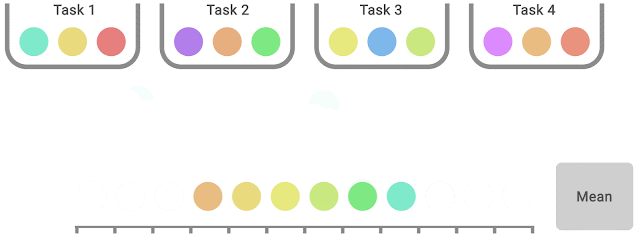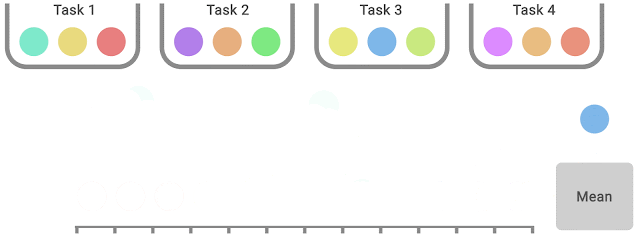
While performance profiles are useful for qualitative comparisons, algorithms rarely outperform other algorithms on all tasks and thus their profiles often intersect, so finer quantitative comparisons require aggregate performance metrics. However, existing metrics have limitations: (1) a single high performing task may dominate the task mean score, while (2) the task median is unaffected by zero scores on nearly half of the tasks and requires a large number of training runs for small statistical uncertainty. To address the above limitations, we recommend two alternatives based on robust statistics: the interquartile mean (IQM) and the optimality gap, both of which can be read as areas under the performance profile, below.
IQM (red) corresponds to the area under the performance profile, shown in blue, between the 25 and 75 percentile scores on the x-axis. Optimality gap (yellow) corresponds to the area between the profile and horizontal line at y = 1 (human performance), for scores less than 1.
As an alternative to median and mean, IQM corresponds to the mean score of the middle 50% of the runs combined across all tasks. It is more robust to outliers than mean, a better indicator of overall performance than median, and results in smaller CIs, and so, requires fewer runs to claim improvements. Another alternative to mean, optimality gap measures how far an algorithm is from optimal performance.
IQM discards the lowest 25% and highest 25% of the combined scores (colored balls) and computes the mean of the remaining 50% scores.
For directly comparing two algorithms, another metric to consider is the average probability of improvement, which describes how likely an improvement over baseline is, regardless of its size. This metric is computed using the Mann-Whitney U-statistic, averaged across tasks.
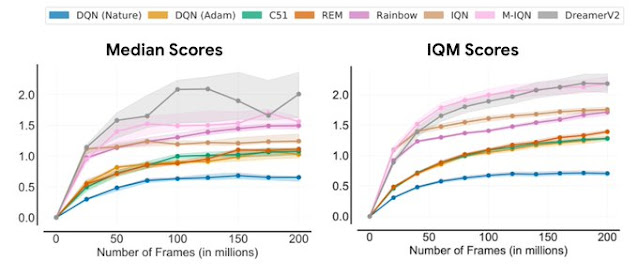
Re-evaluating Evaluation Using the above tools for evaluation, we revisit performance evaluations of existing algorithms on widely used RL benchmarks, revealing inconsistencies in prior evaluation. For example, in the Arcade Learning Environment (ALE), a widely recognized RL benchmark, the performance ranking of algorithms changes depending on the choice of aggregate metric. Since performance profiles capture the full picture, they often illustrate why such inconsistencies exist.
Median (left) and IQM (right) human normalized scores on the ALE as a function of the number of environment frames seen during training. IQM results in significantly smaller CIs than median scores.
On DM Control, a popular continuous control benchmark, there are large overlaps in 95% CIs of mean normalized scores for most algorithms.
DM Control Suite results, averaged across six tasks, on the 100k and 500k step benchmark. Since scores are normalized using maximum performance, mean scores correspond to one minus the optimality gap. The ordering of the algorithms is based on their claimed relative performance — all algorithms except Dreamer claimed improvement over at least one algorithm placed below them. Shaded regions show 95% CIs.
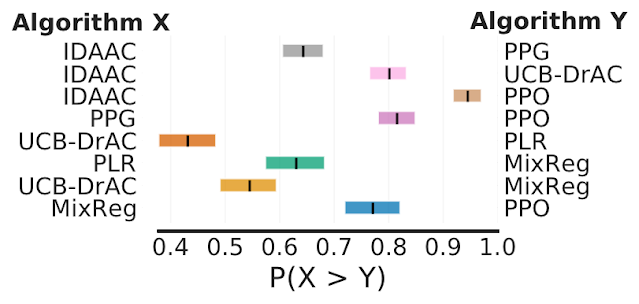
Finally, on Procgen, a benchmark for evaluating generalization in RL, the average probability of improvement shows that some claimed improvements are only 50-70% likely, suggesting that some reported improvements could be spurious.
Each row shows the probability that the algorithm X on the left outperforms algorithm Y on the right, given that X was claimed to be better than Y. Shaded region denotes 95% stratified bootstrap CIs.
Conclusion Our findings on widely-used deep RL benchmarks show that statistical issues can have a large influence on previously reported results. In this work, we take a fresh look at evaluation to improve the interpretation of reported results and standardize experimental reporting. We’d like to emphasize the importance of published papers providing results for all runs to allow for future statistical analyses. To build confidence in your results, please check out our open-source library RLiable and the quickstart colab.
Acknowledgments This work was done in collaboration with Max Schwarzer, Aaron Courville and Marc G. Bellemare. We’d like to thank Tom Small for an animated figure used in this post. We are also grateful for feedback by several members of the Google Research, Brain Team and DeepMind.
NVIDIA-powered systems won four of five tests in MLPerf HPC 1.0, an industry benchmark for AI performance on scientific applications in high performance computing. They’re the latest results from MLPerf, a set of industry benchmarks for deep learning first released in May 2018. MLPerf HPC addresses a style of computing that speeds and augments simulations Read article >
Learn about the optimizations and techniques used across the full stack in the NVIDIA AI platform that led to a record-setting performance in MLPerf HPC v1.0.
In MLPerf HPC v1.0, NVIDIA-powered systems won four of five new industry metrics focused on AI performance in HPC. As an industry-wide AI consortium, MLPerf HPC evaluates a suite of performance benchmarks covering a range of widely used AI workloads.
In this round, NVIDIA delivered 5x better results for CosmoFlow, and 7x more performance on DeepCAM, compared to strong scaling results from MLPerf 0.7. The strong showing is the result of a mature NVIDIA AI platform with a full stack of software.
Offering a rich and diverse set of libraries, SDKs, tools, compilers, and profilers it can be difficult to know when and where to apply the right asset in the right situation. This post details the tools, techniques, and benefits for various scenarios, and outlines the results achieved for the CosmoFlow and DeepCAM benchmarks.
We tuned our code with tools including NVIDIA DALI to accelerate data processing, and CUDA Graphs to reduce small-batch latency for efficiently scaling out to 1,024 or more GPUs. We also applied NVIDIA SHARP to accelerate communications by offloading some operations to the network switch.
The software used in our submissions is available from the MLPerf repository. We regularly add new tools along with new versions to the NGC catalog—our software hub for pretrained AI models, industry application frameworks, GPU applications, and other software resources.
Major performance optimizations
In this section, we dive into the selected optimizations that are implemented for MLPerf HPC 1.0.
Using NVIDIA DALI library for data preprocessing
Data is fetched from the disk and preprocessed before each iteration. We moved from the default dataloader to NVIDIA DALI library. This provides optimized data loading and preprocessing functions for GPUs.
Instead of performing data loading and preprocessing on CPU and moving the result to GPU, DALI library uses a combination of CPU and GPU. This leads to more efficient preprocessing of the data for the upcoming iteration. The optimization results in significant speedup for both CosmoFlow and DeepCAM. DeepCAM achieved over a 50% end-to-end performance gain.
In addition, DALI also provides asynchronous data loading for the upcoming iteration to eliminate I/O overhead from the critical path. With this mode enabled, we saw an additional 70% gain on DeepCAM.
Applying the channels-last NHWC layout
By default, the DeepCAM benchmark uses NCHW layout, for the activation tensors. We used PyTorch’s channels-last (NHWC layout) support to avoid extra transpose kernels. Most convolution kernels in cuDNN are optimized for NHWC layout.
As a result, using NCHW layout in the framework requires additional transpose kernels to convert from NCHW to NHWC for efficient convolution operation. Using NHWC layout in-framework avoids these redundant copies, and delivered about 10% performance gains on the DeepCAM model. NHWC support is available in the PyTorch framework in beta mode.
CUDA Graphs
CUDA Graphs allow launching a single graph that consists of a sequence of kernels, instead of individually launching each of the kernels from CPU to GPU. This feature minimizes CPU involvement in each iteration, substantially improving performance by minimizing latencies—especially for strong scaling scenarios.
MXNet previously added CUDA Graphs support, and CUDA Graphs support was also recently added to PyTorch. CUDA Graphs support in PyTorch resulted in around a 15% end-to-end performance gain in DeepCAM for the strong scaling scenario, which is most sensitive to latency and jitter.
Efficient data staging with MPI
For the case of weak scaling, the performance of the distributed file system cannot sustain the demand from GPUs. To increase the aggregate total storage bandwidth, we stage the dataset into node-local NVME memory for DeepCAM.
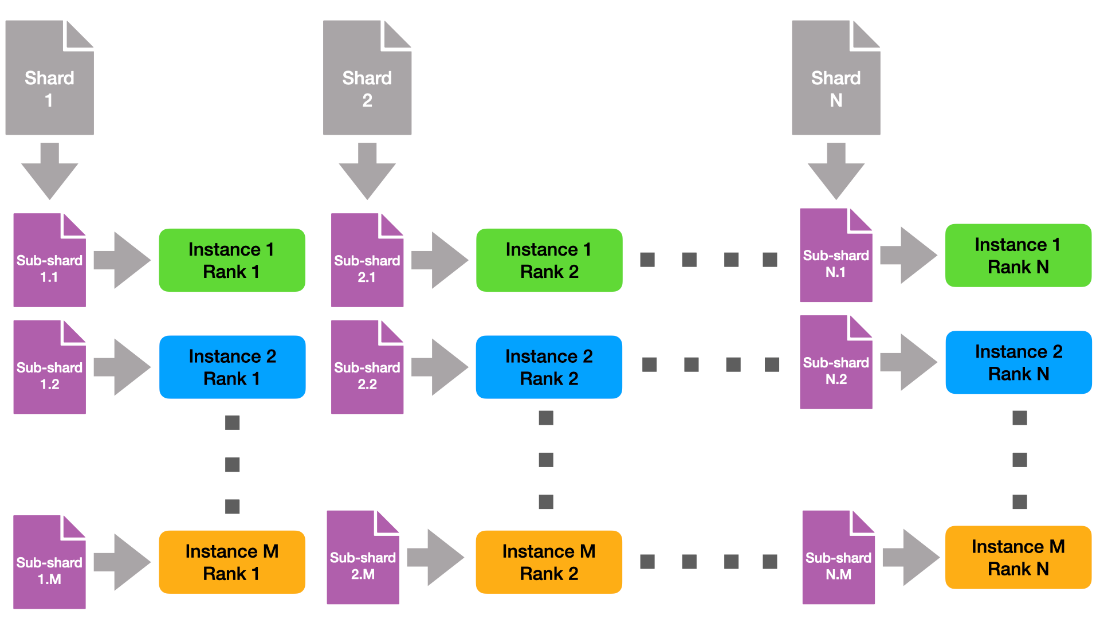
Since the individual instances are small, we can shard the data statically, and thus only need to stage a fraction of the full dataset per node. This solution is depicted in Figure 1. Here we denote the number of instances with M and the number of ranks per instance with N.
Figure 1: Clustering of ranks into shards.
Note that across instances, each rank with the same rank ID uses the same shard of data. This means that natively, each data shard is read M times. To reduce pressure on the file system, we created subshards of the data orthogonal to the instances, depicted in Figure 2.
Figure 2: Demonstration of subsharding.
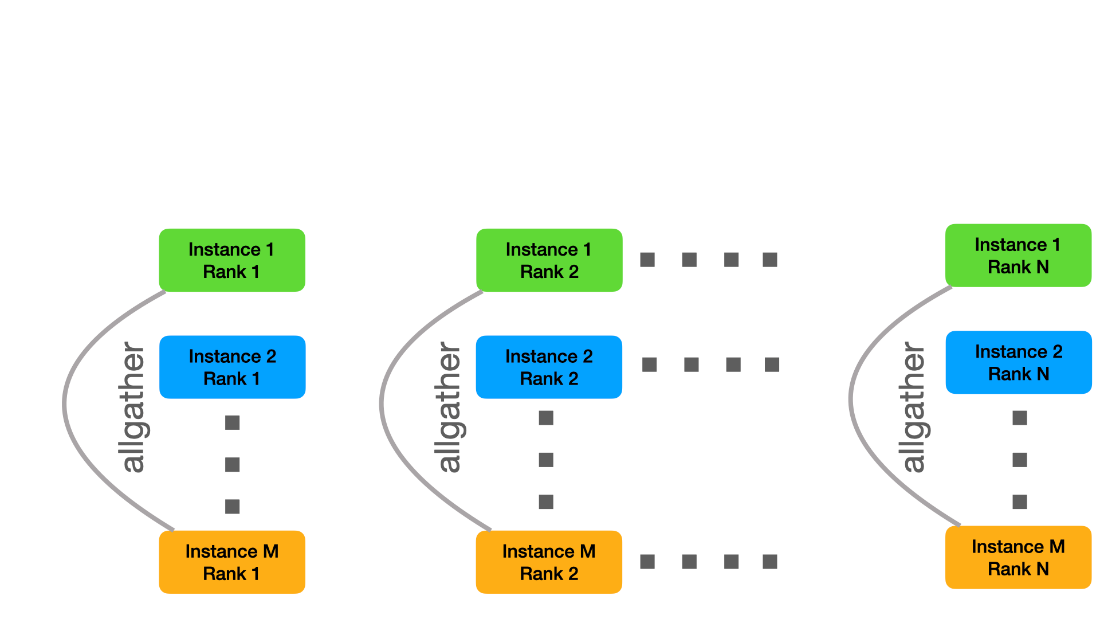
This way, each file is read-only once from the global file system. Finally, each instance needs to receive all the data. For this purpose, we created new MPI communicators orthogonal to the intra-instance communicator, that is, we combine all instance ranks with the same rank id into the same interinstance communicators. Then we can use MPI allgather to combine the individual subshards into M copies of the original shard.
Figure 3: Distribution of subshards.
Instead of performing these steps sequentially, we use batching to create a pipeline that overlaps data reading and distribution of the subshards. In order to improve the read and write performance, we further implemented a small helper tool that uses O_DIRECT to improve I/O bandwidth.
The optimization resulted in more than 2x end-to-end speedup for the DeepCAM benchmark. This is available in the submission repository.
Loss hybridization
An imperative approach for model definition and execution is a flexible solution for defining a ML model like a standard Python program. On the other hand, symbolic programming is a way for declaring computation upfront, before execution. This approach allows the engine to perform various optimizations, but loses flexibility of the imperative approach.
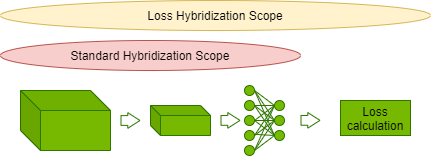
Hybridization is a way of combining those two approaches in the MXNet framework. An imperatively defined calculation can be compiled into symbolic form and optimized when possible. CosmoFlow extends the model hybridization with loss.
Figure 4: Hybridization of the loss function.
This allows fusing element-wise operations in loss calculation with scaled activation output from CosmoFlow model, reducing overall iteration latency. The optimization resulted in close to a 5% end-to-end performance gain for CosmoFlow.
Employing SHARP for internode all-reduce collective
SHARP allows offloading collective operations from CPU to the switches in internode network fabric. This effectively doubles the internode bandwidth of InfiniBand network for the allreduce operation. This optimization results in up to 5% performance gain for MLPerf HPC benchmarks, especially for strong scaling scenarios.
Moving forward with MLPerf HPC
Scientists are making breakthroughs at an accelerated pace, in part because AI and HPC are combining to deliver insight faster and more accurately than could be done using traditional methods.
MLPerf HPC v1.0 reflects the supercomputing industry’s need for an objective, peer-reviewed method to measure and compare AI training performance for use cases relevant to HPC. In this round, the NVIDIA compute platform demonstrated clear leadership by winning all three benchmarks for performance, and also demonstrated the highest efficiency for both throughput measurements.
NVIDIA has also worked with several supercomputing centers around the world for their submissions with NVIDIA GPUs. One of them, the Jülich Supercomputing Centre, has the fastest submissions from Europe.
Read more stories of 2021 Gordon Bell finalists, as well as a discussion of how HPC and AI are making new types of science possible.
TheMLPerfname and logo are trademarks ofMLCommonsAssociation in the United States and other countries. All rights reserved. Unauthorized use is strictly prohibited. Seewww.mlcommons.orgfor moreinformation.
Learn more about the many ways scientists are applying advancements in Million-X computing and solving global challenges.
At NVIDIA GTC last week, Jensen Huang laid out the vision for realizing multi-Million-X speedups in computational performance. The breakthrough could solve the challenge of computational requirements faced in data-intensive research, helping scientists further their work.
Solving challenges with Million-X computing speedups
Million-X unlocks new worlds of potential and the applications are vast. Current examples from NVIDIA include accelerating drug discovery, accurately simulating climate change, and driving the future of manufacturing.
Drug discovery
Researchers at NVIDIA, CalTech, and the startup Entos blended machine learning and physics to create OrbNet, speeding up molecular simulations by many orders of magnitude. As a result, Entos can accelerate its drug discovery simulations by 1,000x, finishing in 3 hours what would have taken more than 3 months.
Climate change
Last week, Jensen Huang announced plans to build Earth 2, building a digital twin of the Earth in Omniverse. The world’s most powerful AI supercomputer will be dedicated to simulating climate models that predict the impacts of global warming in different places across the globe. Understanding these changes over time can help humanity plan for and mitigate these changes at a regional level.
Future manufacturing
The earth is not the first digital twin project enabled by NVIDIA. Researchers are already building physically accurate digital twins of cities and factories. The simulation frontier is still young and full of potential, waiting for the catalyst mass increases in computing will provide.
Share your Million-X challenge
Share how you are using Million-X computing on Facebook, LinkedIn, or Twitter using #MyMillionX and tagging @NVIDIAHPCDev.
The NVIDIA developer community is already changing the world, using technology to solve difficult challenges. Join the community. >>
Below are a handful of notable examples.
The community that is changing the world
Smart waterways, safer public transit, and eco-monitoring in Antarctica
Figure 1. Dr. Johan Barthelemy.
The work of Johan Barthelemy is interdisciplinary and covers a variety of industries. As the head of the University of Wollongong’s Digital Living Lab, he aims to deliver innovative AIoT solutions that champion ethical and privacy-compliant AI.
Currently, Barthelemy is working on an assortment of projects including a smart waterways computer vision application that detects stormwater blockage in real-time, helping cities prevent city-wide issues.
Another project, currently being deployed in multiple cities is AI camera software, which detects and reports violence on Sydney trains through aggressive stance modeling.
An AIoT platform for remotely monitoring Antarctica’s terrestrial environment is also in the works. Built around an NVIDIA Jetson Xavier NX edge computer, the platform will be used to monitor the evolution of moss beds—their health being an early indicator of the impact of climate change. The data collected will also inform a variety of models developed by the Securing Antarctica’s Environmental Future community of researchers, in particular hydrology and microclimate models.
NVIDIA researchers and 14 partners successfully developed a platform to explore the composition, structure, and dynamics of aerosols and aerosolized viruses at the atomic level.
This work surmounts the previously limited ability to examine aerosols at the atomic and molecular level, obscuring our understanding of airborne transmission. Leveraging the platform, the team produced a series of novel discoveries regarding the SARS-CoV-2 Delta variant.
These breakthroughs dramatically extend the capabilities of multiscale computational microscopy in experimental methods. The full impact of the project has yet to be realized.
Species recognition, environmental monitoring, and adaptive streaming
Figure 3. Dr. Albert Bifet.
Dr. Albert Bifet is the Director of the Te Ipu o te Mahara, The Artificial Intelligence Institute at the University of Waikato, and Professor of Big Data at Télécom Paris, Institute.
Bifet also leads the TAIAO project, a data science program using an NVIDIA DGX A100 to build deep learning models on species recognition. He is codeveloping a new machine-learning library in Python called River for online/streaming machine learning, and building a new data repository to improve reproducibility in environmental data science.
Additionally, researchers at TAIAO are building new approaches to compute GPU-based SHAP values for XGBoost, and developing a new adaptive streaming XGBoost.
Medical imaging, therapy robots, and NLP depression detection
Figure 4. Robots developed for medical use.
The current interests of Dr. Ekapol Chuangsuwanich fall within the medical imaging domain, including chest x-ray and histopathology technology. However, over the past few years his work has spanned across many industries including NLP, ASR, and medical imaging.
Last year, Chuangsuwanich and his team developed the PYLON architecture, which can learn precise pixel-level object location with only image-level annotation. This is deployed across hospitals in Thailand to provide rapid COVID-19 severity assessments and to facilitate screening of tuberculosis in high-risk communities.
Additionally, he is working on NLP and ASR robots for medical use, including a speech therapy helper and call center robot with depression detection functionality. His startup, Gowajee, is also providing state-of-the-art ASR and TTS for the Thai language. These projects have been created using the NVIDIA NeMo framework and deployed on NVIDIA Jetson Nano devices.
Trillion atom quantum-accurate molecular dynamics simulations
Figure 5. Atomic radial cutoff used to generate descriptors, represented as fingerprints.
Researchers from the University of South Florida, NVIDIA, Sandia National Labs, NERSC, and the Royal Institute of Technology collaborated to produce a LAMMPS trained machine learning kernel with interatomic potentials named SNAP (Spectral Neighborhood Analysis Potential).
SNAP was found to be accurate across a huge pressure-temperature range, from 0-50Mbars or 300-20,000 Kelvin. The peak Molecular Dynamic performance was greater than 22x the previous record—done on a 20-billion-atom system, and simulated on Summit for 1ns in a day.
The project qualified as a Gordon Bell Prize finalist, and the near perfect weak scaling of SNAP MD highlights the potential to launch quantum-accurate MD to trillion atom simulations on upcoming exascale platforms. This dramatically expands the scientific return of X-ray free electron laser diffraction experiments.
BioInformatics, smart cities, and translational research
Figure 6. Dr. Ng See-Kiong.
Dr. Ng See-Kion is constantly in search of big data. A practicing data scientist, See-Kion is also a Professor of Practice and Director of Translational Research at the National University of Singapore.
Currently projects on his desk leverage the NVIDIA NeMo framework covering NLP for indigenous and vernacular languages across Singapore and New Zealand. See-Kion is also working on intelligent COVID-19 contact tracing and outbreak, intelligent social event sensing, and assessing the credibility of information in new media.
Meet The Spaghetti Detective, an AI-based failure-detection tool for 3D printer remote management and monitoring.
3D printing can be a quick and convenient way to prototype ideas and build useful everyday objects. But it can also be messy—and stressful—when a print job encounters an error that leaves your masterpiece buried in piles of plastic filament. Those tangles of twisted goop are known as “spaghetti monsters,” and they have the power to kill your project and raise your blood pressure.
Thankfully, there is a way to tame these monsters. Meet The Spaghetti Detective (TSD), an AI-based (deep learning) failure-detection tool for 3D printer remote management and monitoring. In other words, with TSD you can detect spaghetti monsters before they get out of hand. It issues an early warning that could save days of work and pounds and pounds of filament.
In fact, according to the team behind TSD, the tool has caught more than 560,000 failed prints by watching more than 47 million hours of 3D project printing time, saving more than 27,500 pounds of filament.
This short demo shows TSD in action:
Kenneth Jiang, founder of TSD, reported being “stunned” at just how outdated most 3D-printing software can be. So he and his team created TSD to bring new technologies to the world of 3D printing.
Every part of TSD is open source, including the plug-in, the backend, and the algorithm.
According to a post by Jiang in the NVIDIA Developer Forum, TSD is “based on a Convolutional Neural Network architecture called YOLO. It is essentially a super-fast objection-detection model.”
The Spaghetti Detective also communicates with OctoPrint, an open-source web interface for your 3D printer. The private TSD server has an array of advanced settings for all requirements, including enabling NVIDIA GPU acceleration, reverse proxies, NGINX settings, and more.
With more than 600 stars on GitHub, TSD is being used by hundreds of NVIDIA Jetson Nano fans who are also 3D printing enthusiasts. Inspired by their success, Jiang took it upon himself to set up TSD with Jetson Nano, and created a demo to show other users how to set it up.
The project requires an NVIDIA Jetson Nano with 4GB of memory to run (they do not advise trying to set this up with the 2GB model), an Ethernet cable to connect your network router, an HDMI cable, keyboard, and mouse. TSD is installed using Docker and Docker-compose, and the server uses e-mail delivery through SMTP for notifications. The web interface is written in Django and you can log in and create a password-secured account. Notifications from TSD can also be sent by SMS.
TSD is available as a free service for occasional 3D-print monitoring. If you expect to be printing daily, there is also a paid option starting at $4 per month.
The team working on TSD also plans to add event-based recording for fluid video capture, improvements to model accuracy and capability, and functionality to enable local hosting for increased data privacy. At the same time, they are clearly having fun figuring it all out, as you can see from their very popular videos on TikTok.
If you are interested in learning more about how Jetson Nano can be used to run The Spaghetti Detective, check out the code in GitHub.
The latest NVIDIA HPC SDK includes a variety of tools to maximize developer productivity, as well as the performance and portability of HPC applications.
Today, NVIDIA announced the upcoming HPC SDK 21.11 release with new Library enhancements. This software will be available free of charge in the coming weeks.
The NVIDIA HPC SDK is a comprehensive suite of compilers and libraries for high-performance computing development. It includes a wide variety of tools proven to maximize developer productivity, as well as the performance and portability of HPC applications.
The HPC SDK and its components are updated numerous times per year with new features, performance advancements, and other enhancements.
What’s new
This 21.11 release will include updates to HPC C++/Fortran compiler support and the developer environment, as well as new multinode mulitGPU library capabilities.
Compiler, build systems, and other enhancements
Introduced last year with version 20.11, the NVFORTRAN compiler automatically parallelizes code written using the DO CONCURRENT standard language feature as described in this post.
New in version 21.11, the programmer can use the REDUCE clause as described in the current working draft of the ISO Fortran Standard to perform reduction operations, a requirement of many scientific algorithms.
Starting with the 21.11 release, the HPC Compilers now support the –gcc-toolchain option, similarly to the clang-based compilers. This is provided in addition to the existing rc-file method of specifying nondefault GNU Compiler Collection (GCC) versions. The HPC Compilers leverage open source GCC libraries for things like common system operations and C++ standard library support.
Sometimes, a developer needs a different version of the GCC toolchain than the system default. Now 21.11 has both command line and file-based ways of making that specification. In addition to –gcc-toolchain, the 21.11 HPC Compilers add several GCC-compatible command line flags for specifying x86-64 target architecture details.
The 21.11 release now includes two new Fortran modules to integrate with NVIDIA libraries, Fortran applications maximize the benefit from NVIDIA platforms and Fortran developers be as productive as possible. HPC applications written in Fortran can directly use cufftX—a highly optimized multi-GPU FFT library from NVIDIA. It also enables easier use with the NVIDIA Tools Extension Library (NVTX) for performance and profiling studies with Nsight.
Version 21.11 will ship with CMake config files that define CMake targets for the various components of the HPC SDK. This offers application packagers and developers a more seamless code integration with the NVIDIA HPC SDK.
New multinode, multiGPU Math Libraries
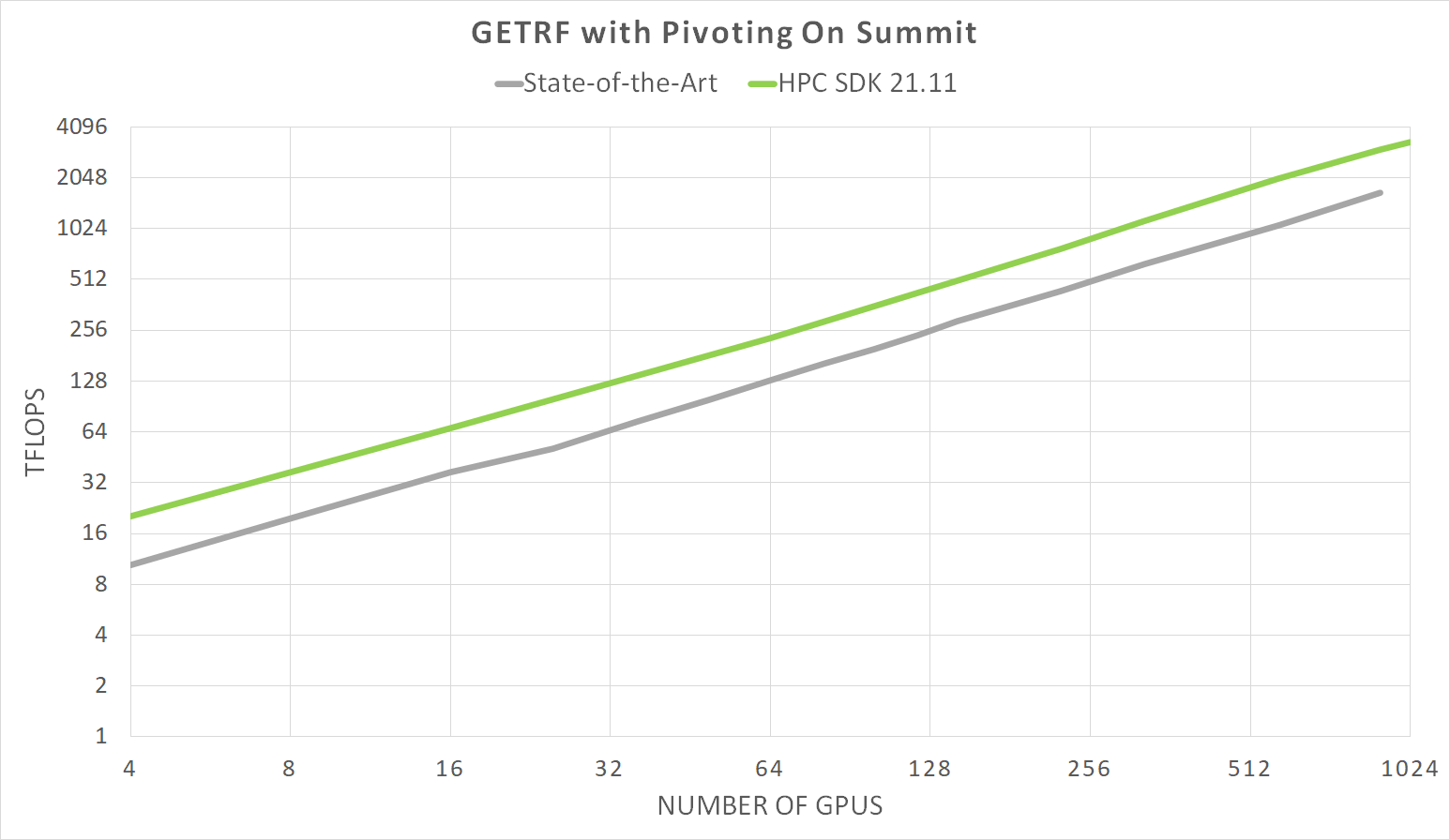
HPC SDK version 21.11 will include the first of our upcoming multinode, multiGPU Math Library functionality, cuSOLVERMp. Initial functionality will include Cholesky and LU Decomposition, with and without pivoting. Future releases will include LU, with multiple RHS.
Figure 1. Gain roughly 2x performance improvement against the current state-of-the-art multi-node software.
A partial differential equation is “the most powerful tool humanity has ever created,” Cornell University mathematician Steven Strogatz wrote in a 2009 New York Times opinion piece. This quote opened last week’s GTC talk AI4Science: The Convergence of AI and Scientific Computing, presented by Anima Anandkumar, director of machine learning research at NVIDIA and professor Read article >
Atos and NVIDIA today announced the Excellence AI Lab (EXAIL), which brings together scientists and researchers to help advance European computing technologies, education and research.





 Learn about the optimizations and techniques used across the full stack in the NVIDIA AI platform that led to a record-setting performance in MLPerf HPC v1.0.
Learn about the optimizations and techniques used across the full stack in the NVIDIA AI platform that led to a record-setting performance in MLPerf HPC v1.0.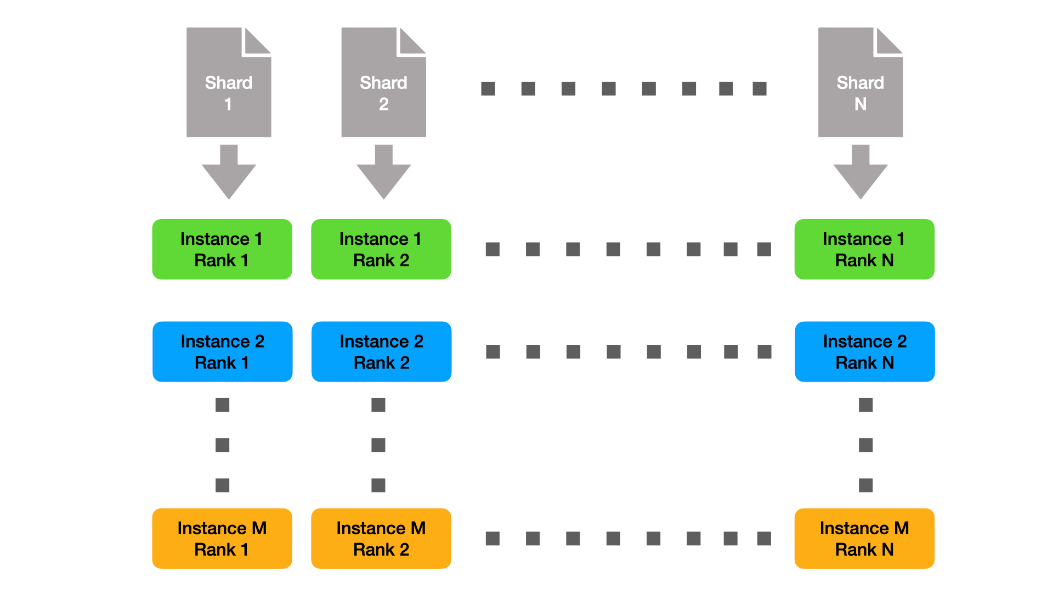
 v1.0 HPC Closed Strong & Weak Scaling – Result retrieved from
v1.0 HPC Closed Strong & Weak Scaling – Result retrieved from  Learn more about the many ways scientists are applying advancements in Million-X computing and solving global challenges.
Learn more about the many ways scientists are applying advancements in Million-X computing and solving global challenges.





 Meet The Spaghetti Detective, an AI-based failure-detection tool for 3D printer remote management and monitoring.
Meet The Spaghetti Detective, an AI-based failure-detection tool for 3D printer remote management and monitoring. The latest NVIDIA HPC SDK includes a variety of tools to maximize developer productivity, as well as the performance and portability of HPC applications.
The latest NVIDIA HPC SDK includes a variety of tools to maximize developer productivity, as well as the performance and portability of HPC applications.